Effizientes und zuverlässiges Cluster-Management in jeder Größenordnung mit Tupperware

Heute haben wir auf der Systems @ Scale-Konferenz Tupperware vorgestellt, unser Cluster-Management-System, das Container auf Millionen von Servern orchestriert, auf denen fast alle unsere Services funktionieren. Wir haben Tupperware erstmals im Jahr 2011 eingeführt. Seitdem ist unsere Infrastruktur von einem Rechenzentrum auf bis zu 15 geoverteilte Rechenzentren angewachsen. Während dieser ganzen Zeit stand Tupperware nicht still und entwickelte sich mit uns. Wir werden Ihnen sagen, in welchen Situationen Tupperware erstklassiges Cluster-Management bietet, einschließlich praktischer Unterstützung für Stateful Services, eines einzigen Control Panels für alle Rechenzentren und der Möglichkeit, die Energie in Echtzeit auf die Services zu verteilen. Und wir werden die Lektionen teilen, die wir bei der Entwicklung unserer Infrastruktur gelernt haben.
Tupperware führt verschiedene Aufgaben aus. Anwendungsentwickler verwenden es, um Anwendungen bereitzustellen und zu verwalten. Es packt die Code- und Anwendungsabhängigkeiten in ein Image und liefert sie in Form von Containern an die Server. Container bieten Isolation zwischen Anwendungen auf demselben Server, sodass Entwickler mit der Anwendungslogik beschäftigt sind und nicht darüber nachdenken, wie Server gefunden oder Updates gesteuert werden. Tupperware überwacht auch die Leistung des Servers. Wenn ein Fehler festgestellt wird, werden Container vom problematischen Server übertragen.
Kapazitätsplanungsingenieure verwenden Tupperware, um die Serverkapazitäten je nach Budget und Einschränkungen in Teams zu verteilen. Sie verwenden es auch, um die Servernutzung zu verbessern. Betreiber von Rechenzentren wenden sich an Tupperware, um Container ordnungsgemäß auf Rechenzentren zu verteilen und Container während der Wartung anzuhalten oder zu verschieben. Aus diesem Grund erfordert die Wartung von Servern, Netzwerken und Geräten nur eine minimale menschliche Beteiligung.
Tupperware-Architektur
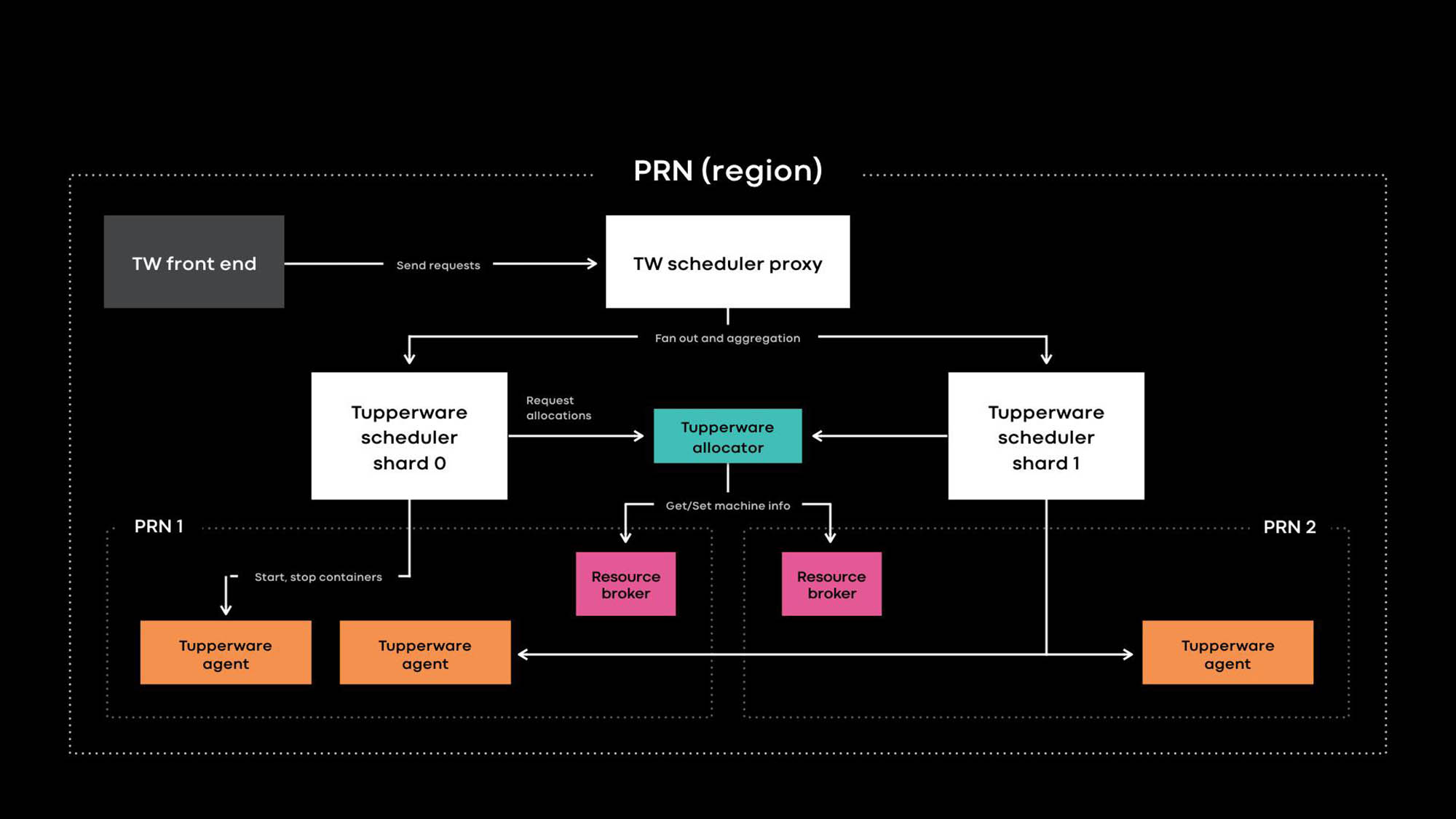
Architektur Tupperware PRN ist eine der Regionen unserer Rechenzentren. Die Region besteht aus mehreren Rechenzentrumsgebäuden (PRN1 und PRN2) in der Nähe. Wir planen ein Control Panel, das alle Server in einer Region verwaltet.
Anwendungsentwickler stellen Dienste in Form von Tupperware-Jobs bereit. Eine Aufgabe besteht aus mehreren Containern, die normalerweise denselben Anwendungscode ausführen.
Tupperware ist für die Containerbereitstellung und das Lebenszyklusmanagement verantwortlich. Es besteht aus mehreren Komponenten:
- Das Tupperware-Frontend bietet eine API für die Benutzeroberfläche, die CLI und andere Automatisierungstools, über die Sie mit Tupperware interagieren können. Sie verbergen die gesamte interne Struktur vor Tupperware-Jobbesitzern.
- Der Tupperware Scheduler ist das Control Panel, das für die Verwaltung des Container- und Joblebenszyklus verantwortlich ist. Es wird auf regionaler und globaler Ebene bereitgestellt, wobei ein regionaler Scheduler Server in einer Region verwaltet und ein globaler Scheduler Server aus verschiedenen Regionen verwaltet. Der Scheduler ist in Shards unterteilt, und jeder Shard steuert eine Reihe von Aufgaben.
- Der Scheduler-Proxy in Tupperware verbirgt das interne Sharding und bietet Tupperware-Benutzern ein praktisches einheitliches Kontrollfeld.
- Der Tupperware Distributor weist den Servern Container zu. Der Scheduler ist für das Stoppen, Starten, Aktualisieren und Fehlschlagen von Containern verantwortlich. Derzeit kann ein einzelner Distributor eine gesamte Region verwalten, ohne sich in Shards aufzuteilen. (Beachten Sie den Unterschied in der Terminologie. Beispielsweise entspricht der Scheduler in Tupperware dem Control Panel in Kubernetes , und der Tupperware-Distributor wird in Kubernetes als Scheduler bezeichnet.)
- Der Ressourcenbroker speichert die Wahrheitsquelle für die Server- und Serviceereignisse. Wir führen für jedes Rechenzentrum einen Ressourcenbroker aus, der alle Serverinformationen in diesem Rechenzentrum speichert. Ein Ressourcenbroker und ein Kapazitätsverwaltungssystem oder ein Ressourcenzuweisungssystem entscheiden dynamisch, welche Scheduler-Bereitstellung welchen Server steuert. Der Integritätsprüfungsdienst überwacht Server und speichert Daten zu ihrem Zustand im Ressourcenbroker. Wenn der Server Probleme hat oder gewartet werden muss, weist der Ressourcenbroker den Distributor und den Scheduler an, die Container anzuhalten oder auf andere Server zu übertragen.
- Tupperware Agent ist ein Daemon, der auf jedem Server ausgeführt wird und Container vorbereitet und entfernt. Anwendungen arbeiten im Container, wodurch sie besser isoliert und reproduzierbar sind. Auf der letztjährigen Systems @ Scale-Konferenz haben wir bereits beschrieben, wie einzelne Tupperware-Container mithilfe von Images, btrfs, cgroupv2 und systemd erstellt werden.
Besonderheiten von Tupperware
Tupperware ist anderen Cluster-Management-Systemen wie Kubernetes und Mesos sehr ähnlich, es gibt jedoch einige Unterschiede:
- Native Unterstützung für Stateful Services.
- Ein einziges Control Panel für Server in verschiedenen Rechenzentren zur Automatisierung der Lieferung von Containern basierend auf Absicht, Stilllegung von Clustern und Wartung.
- Klare Trennung des Bedienfelds zum Zoomen.
- Mit flexiblen Berechnungen können Sie die Leistung in Echtzeit auf die Dienste verteilen.
Wir haben diese coolen Funktionen entwickelt, um eine Vielzahl von zustandslosen und zustandsbehafteten Anwendungen in einem riesigen globalen gemeinsam genutzten Serverpark zu unterstützen.
Native Unterstützung für Stateful Services.
Tupperware verwaltet viele wichtige Stateful Services, die persistente Produktdaten für Facebook, Instagram, Messenger und WhatsApp speichern. Dies können große Schlüssel-Wert-Paare (z. B. ZippyDB ) und Überwachungsdatenspeicher (z. B. ODS Gorilla und Scuba ) sein. Die Aufrechterhaltung zustandsbehafteter Dienste ist nicht einfach, da das System sicherstellen muss, dass Containerlieferungen großen Ausfällen standhalten können, einschließlich eines Stromausfalls oder eines Stromausfalls. Obwohl herkömmliche Methoden wie das Verteilen von Containern über Fehlerdomänen für zustandslose Dienste gut geeignet sind, benötigen Stateful Services zusätzliche Unterstützung.
Wenn beispielsweise aufgrund eines Serverausfalls ein Replikat der Datenbank nicht mehr verfügbar ist, muss eine automatische Wartung zugelassen werden, mit der die Kernel auf 50 Servern aus einem 10-Tausendstel-Pool aktualisiert werden? Das hängt von der Situation ab. Wenn sich auf einem dieser 50 Server ein anderes Replikat derselben Datenbank befindet, ist es besser zu warten und nicht zwei Replikate gleichzeitig zu verlieren. Um dynamisch Entscheidungen über die Wartung und den Zustand des Systems treffen zu können, benötigen Sie Informationen zur internen Datenreplikation und zur Standortlogik jedes Stateful Service.
Über die TaskControl-Schnittstelle können Stateful Services Entscheidungen beeinflussen, die sich auf die Datenverfügbarkeit auswirken. Über diese Schnittstelle benachrichtigt der Scheduler externe Anwendungen über Containervorgänge (Neustart, Aktualisierung, Migration, Wartung). Der Stateful-Dienst implementiert einen Controller, der Tupperware mitteilt, wann jeder Vorgang sicher ausgeführt werden kann, und diese Vorgänge können ausgetauscht oder vorübergehend verzögert werden. Im obigen Beispiel weist der Datenbankcontroller Tupperware möglicherweise an, 49 der 50 Server zu aktualisieren, berührt jedoch bisher keinen bestimmten Server (X). Wenn der Kernel-Aktualisierungszeitraum verstrichen ist und die Datenbank das Problemreplikat immer noch nicht wiederherstellen kann, aktualisiert Tupperware den X-Server weiterhin.

Viele Stateful Services in Tupperware verwenden TaskControl nicht direkt, sondern über ShardManager, eine gängige Plattform zum Erstellen von Stateful Services auf Facebook. Mit Tupperware können Entwickler angeben, wie Container auf Rechenzentren verteilt werden sollen. Mit ShardManager geben Entwickler ihre Absicht an, wie Data Shards auf Container verteilt werden sollen. ShardManager ist sich des Datenhostings und der Replikation seiner Anwendungen bewusst und interagiert mit Tupperware über die TaskControl-Schnittstelle, um Containerbetriebe ohne direkte Anwendungsbeteiligung zu planen. Diese Integration vereinfacht die Verwaltung von Stateful Services erheblich, TaskControl bietet jedoch mehr. Unsere umfangreiche Webschicht ist beispielsweise zustandslos und verwendet TaskControl, um die Geschwindigkeit von Aktualisierungen in Containern dynamisch anzupassen. Infolgedessen kann die Webschicht schnell mehrere Softwareversionen pro Tag fertigstellen, ohne die Verfügbarkeit zu beeinträchtigen.
Serververwaltung in Rechenzentren
Als Tupperware 2011 zum ersten Mal erschien, kontrollierte ein separater Scheduler jeden Servercluster. Dann war der Facebook-Cluster eine Gruppe von Server-Racks, die mit einem Netzwerk-Switch verbunden waren, und das Rechenzentrum enthielt mehrere Cluster. Der Scheduler kann Server nur in einem Cluster verwalten, dh die Aufgabe kann nicht auf mehrere Cluster ausgedehnt werden. Unsere Infrastruktur wuchs, wir schrieben zunehmend Cluster ab. Da Tupperware die Aufgabe nicht ohne Änderungen vom stillgelegten Cluster auf andere Cluster übertragen konnte, war viel Aufwand und sorgfältige Koordination zwischen Anwendungsentwicklern und Rechenzentrumsbetreibern erforderlich. Dieser Prozess führte zu einer Verschwendung von Ressourcen, wenn die Server aufgrund des Stilllegungsverfahrens monatelang inaktiv waren.
Wir haben einen Ressourcenbroker erstellt, um das Problem der Außerbetriebnahme von Clustern zu lösen und andere Arten von Wartungsaufgaben zu koordinieren. Der Ressourcenbroker überwacht alle dem Server zugeordneten physischen Informationen und entscheidet dynamisch, welcher Scheduler jeden Server verwaltet. Durch die dynamische Bindung von Servern an Scheduler kann der Scheduler Server in verschiedenen Rechenzentren verwalten. Da der Tupperware-Job nicht mehr auf einen Cluster beschränkt ist, können Tupperware-Benutzer festlegen, wie Container auf die Fehlerdomänen verteilt werden sollen. Beispielsweise kann ein Entwickler seine Absicht erklären (z. B. "Meine Aufgabe auf 2 Fehlerdomänen in der PRN-Region ausführen"), ohne bestimmte Verfügbarkeitszonen anzugeben. Tupperware selbst findet die richtigen Server, um diese Absicht auch bei der Außerbetriebnahme eines Clusters oder Dienstes zu verwirklichen.
Skalierung zur Unterstützung des gesamten globalen Systems
In der Vergangenheit wurde unsere Infrastruktur in Hunderte dedizierter Serverpools für einzelne Teams unterteilt. Aufgrund der Fragmentierung und des Fehlens von Standards hatten wir hohe Transaktionskosten und es war schwieriger, nicht genutzte Server wieder zu verwenden. Auf der letztjährigen Systems @ Scale- Konferenz haben wir Infrastructure as a Service (IaaS) vorgestellt , mit dem unsere Infrastruktur in eine große, einheitliche Serverflotte integriert werden soll. Eine einzelne Serverflotte hat jedoch ihre eigenen Schwierigkeiten. Es muss bestimmte Anforderungen erfüllen:
- Skalierbarkeit. Unsere Infrastruktur wuchs durch die Hinzufügung von Rechenzentren in jeder Region. Server sind kleiner und energieeffizienter geworden, daher gibt es in jeder Region viel mehr. Infolgedessen kann ein einzelner Scheduler für eine Region die Anzahl der Container nicht bewältigen, die auf Hunderttausenden von Servern in jeder Region ausgeführt werden können.
- Zuverlässigkeit Selbst wenn der Umfang des Schedulers aufgrund des großen Umfangs des Schedulers so vergrößert werden kann, ist das Fehlerrisiko höher und der gesamte Bereich der Container kann unüberschaubar werden.
- Fehlertoleranz. Bei einem großen Infrastrukturausfall (z. B. aufgrund eines Netzwerkausfalls oder eines Stromausfalls fallen die Server, auf denen der Scheduler ausgeführt wird, aus) hat nur ein Teil der Server in der Region negative Folgen.
- Benutzerfreundlichkeit. Möglicherweise müssen Sie mehrere unabhängige Scheduler in einer Region ausführen. Aus praktischen Gründen vereinfacht ein einziger Einstiegspunkt in einen gemeinsamen Pool in der Region das Kapazitäts- und Jobmanagement.
Wir haben den Scheduler in Shards unterteilt, um Probleme bei der Unterstützung eines großen gemeinsamen Pools zu lösen. Jeder Scheduler-Shard verwaltet seine Aufgaben in der Region, wodurch das mit dem Scheduler verbundene Risiko verringert wird. Wenn der Gesamtpool wächst, können wir weitere Scheduler-Shards hinzufügen. Für Tupperware-Benutzer sehen Shards und Proxy-Scheduler wie ein einziges Bedienfeld aus. Sie müssen nicht mit einer Reihe von Shards arbeiten, die Aufgaben koordinieren. Die Scheduler-Shards unterscheiden sich grundlegend von den zuvor verwendeten Cluster-Schedulern, als das Control Panel ohne statische Trennung des gemeinsamen Serverpools gemäß der Netzwerktopologie aufgeteilt wurde.
Verbesserung der Nutzung durch Elastic Computing
Je größer unsere Infrastruktur ist, desto wichtiger ist es, unsere Server effizient zu nutzen, um die Infrastrukturkosten zu optimieren und die Last zu reduzieren. Es gibt zwei Möglichkeiten, die Servernutzung zu verbessern:
- Flexibles Computing - Reduzieren Sie den Umfang der Onlinedienste in ruhigen Stunden und verwenden Sie die freigegebenen Server für Offline-Lasten, z. B. für maschinelles Lernen und MapReduce-Aufgaben.
- Übermäßiges Laden - Hosten Sie Onlinedienste und Batch-Workloads auf denselben Servern, damit Batch-Ladevorgänge mit niedriger Priorität ausgeführt werden.
Der Engpass in unseren Rechenzentren ist der Energieverbrauch . Daher bevorzugen wir kleine, energieeffiziente Server, die zusammen mehr Rechenleistung bieten. Leider ist übermäßiges Laden auf kleinen Servern mit einer geringen Menge an Prozessorressourcen und Speicher weniger effizient. Natürlich können wir mehrere Container mit kleinen Diensten auf einem kleinen, energieeffizienten Server platzieren, die wenig Prozessorressourcen und Speicher verbrauchen, aber große Dienste weisen in dieser Situation eine geringe Leistung auf. Daher empfehlen wir den Entwicklern unserer großen Services, diese so zu optimieren, dass sie den gesamten Server nutzen.
Grundsätzlich verbessern wir die Auslastung mit Elastic Computing. Die Nutzungsintensität vieler unserer großen Dienste, z. B. Newsfeeds, Nachrichtenfunktionen und Front-End-Web-Level, hängt von der Tageszeit ab. Wir reduzieren absichtlich den Umfang von Onlinediensten während ruhiger Stunden und verwenden die freigegebenen Server für Offline-Lasten, beispielsweise für maschinelles Lernen und MapReduce-Aufgaben.
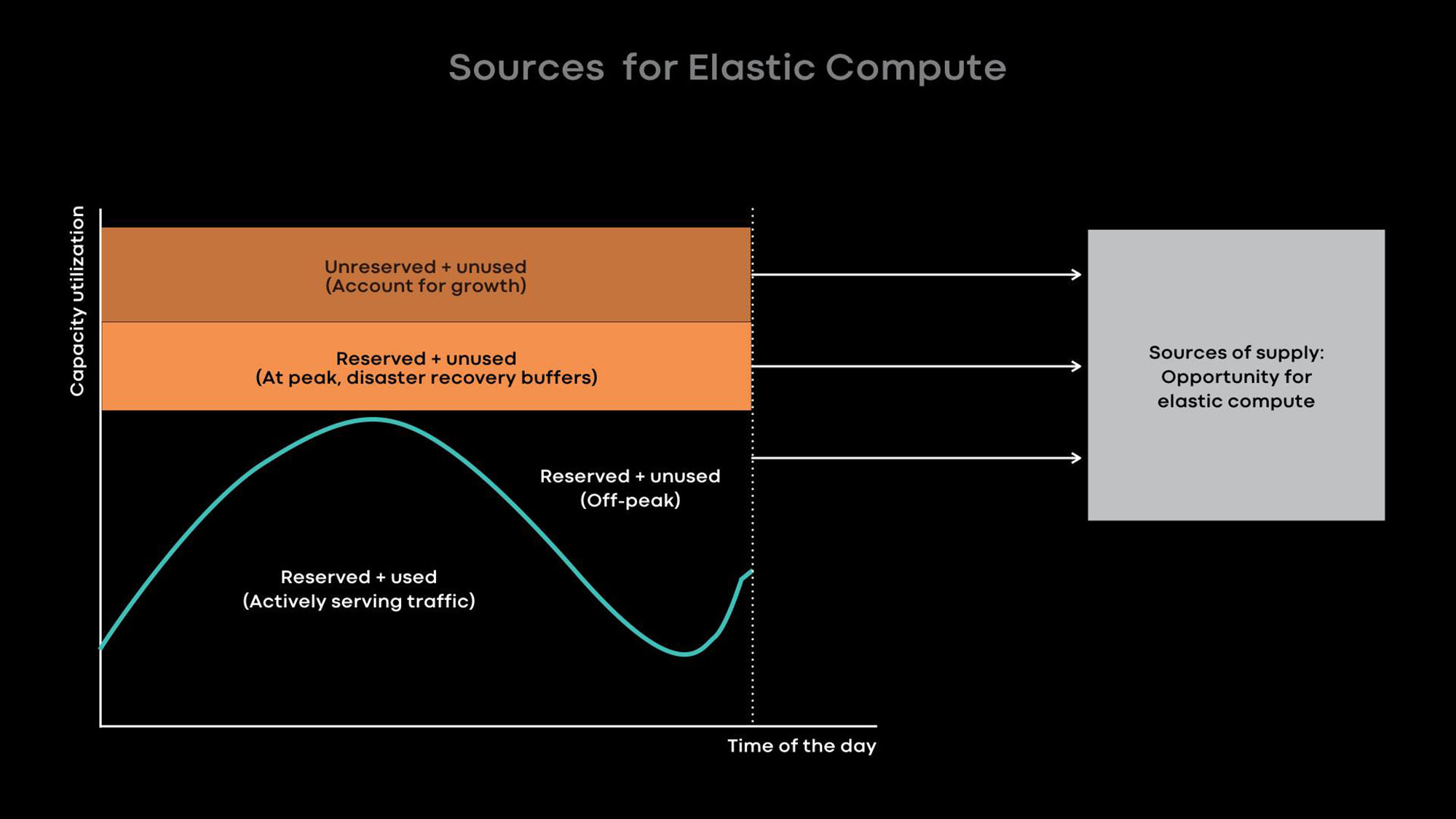
Aus Erfahrung wissen wir, dass es am besten ist, ganze Server als Einheiten elastischer Leistung bereitzustellen, da große Dienste sowohl die Hauptgeber als auch die Hauptverbraucher elastischer Leistung sind und für die Verwendung ganzer Server optimiert sind. Wenn der Server in den ruhigen Stunden vom Onlinedienst befreit wird, gibt der Ressourcenbroker den Server an den Scheduler zur vorübergehenden Verwendung weiter, damit er offline geladen wird. Wenn in einem Onlinedienst ein Lastpeak auftritt, ruft der Ressourcenbroker den ausgeliehenen Server schnell zurück und gibt ihn zusammen mit dem Planer an den Onlinedienst zurück.
Lessons Learned und Zukunftspläne
In den letzten 8 Jahren haben wir Tupperware entwickelt, um mit der rasanten Entwicklung von Facebook Schritt zu halten. Wir sprechen über das, was wir gelernt haben, und hoffen, dass es anderen hilft, schnell wachsende Infrastrukturen zu verwalten:
- Richten Sie eine flexible Kommunikation zwischen dem Control Panel und den von ihm verwalteten Servern ein. Diese Flexibilität ermöglicht es dem Control Panel, Server in verschiedenen Rechenzentren zu verwalten, die Außerbetriebnahme und Wartung von Clustern zu automatisieren und eine dynamische Energieverteilung mithilfe flexibler Datenverarbeitung bereitzustellen.
- Mit einem einzigen Bedienfeld in der Region wird es einfacher, mit Aufgaben zu arbeiten und eine große gemeinsame Serverflotte einfacher zu verwalten. Bitte beachten Sie, dass das Bedienfeld einen einzelnen Einstiegspunkt unterstützt, auch wenn seine interne Struktur aus Gründen der Skalierung oder Fehlertoleranz unterteilt ist.
- Mithilfe des Plug-In-Modells kann das Bedienfeld externe Anwendungen über bevorstehende Containerbetriebe informieren. Darüber hinaus können Stateful Services die Plugin-Schnittstelle verwenden, um die Containerverwaltung zu konfigurieren. Mit diesem Plug-In-Modell bietet das Bedienfeld Einfachheit und bedient effektiv viele verschiedene Stateful Services.
- Wir glauben, dass Elastic Computing, bei dem wir ganze Server für Batch-Jobs, maschinelles Lernen und andere nicht dringende Dienste von Geberdiensten übernehmen, der beste Weg ist, um die Effizienz der Verwendung kleiner und energieeffizienter Server zu steigern.
Wir beginnen gerade mit der Implementierung eines einzelnen globalen gemeinsamen Serverparks . Jetzt befinden sich ungefähr 20% unserer Server im gemeinsamen Pool. Um 100% zu erreichen, müssen Sie viele Probleme lösen, einschließlich der Unterstützung eines gemeinsamen Pools für Speichersysteme, der Automatisierung der Wartung, der Verwaltung der Anforderungen verschiedener Clients, der Verbesserung der Servernutzung und der Unterstützung für Workloads beim maschinellen Lernen. Wir können es kaum erwarten, diese Aufgaben zu bewältigen und unsere Erfolge zu teilen.