Mein Name ist Marko und ich habe dieses Jahr auf der
Gophercon Russia einen Vortrag über eine sehr interessante Art von Indizes gehalten, die "Bitmap-Indizes" genannt werden. Ich wollte es mit der Community teilen, nicht nur im Videoformat, sondern auch als Artikel. Es ist eine englische Version und Sie können
hier Russisch lesen. Bitte viel Spaß!

Weitere Materialien, Folien und den gesamten Quellcode finden Sie hier:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Original Videoaufnahme:
Fangen wir an!
Einführung

Heute werde ich darüber sprechen
- Was sind Indizes?
- Was ist ein Bitmap-Index?
- Wo es verwendet wird. Warum es nicht verwendet wird, wo es nicht verwendet wird.
- Wir werden eine einfache Implementierung in Go sehen und dann den Compiler ausprobieren.
- Dann werden wir uns eine etwas weniger einfache, aber merklich schnellere Implementierung in der Go-Assembly ansehen.
- Und danach werde ich die "Probleme" der Bitmap-Indizes einzeln ansprechen.
- Und schließlich werden wir sehen, welche bestehenden Lösungen es gibt.
Was sind Indizes?
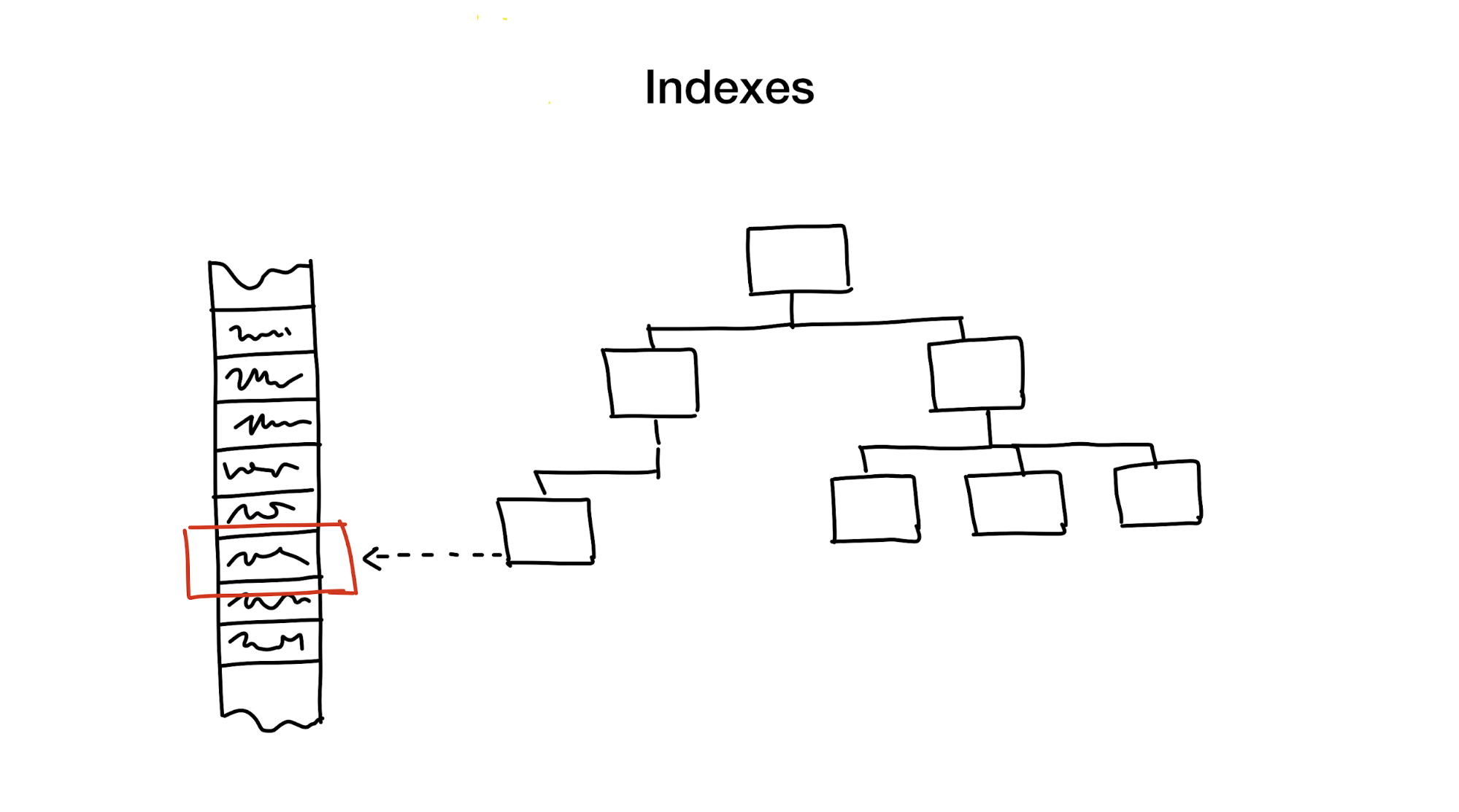
Ein Index ist eine eindeutige Datenstruktur, die zusätzlich zu den Hauptdaten aktualisiert wird, um Suchanforderungen zu beschleunigen. Ohne Indizes würde die Suche das Durchlaufen aller Daten beinhalten (in einem Prozess, der auch als "vollständiger Scan" bezeichnet wird), und dieser Prozess weist eine lineare algorithmische Komplexität auf. Datenbanken enthalten jedoch normalerweise große Datenmengen, sodass die lineare Komplexität zu langsam ist. Idealerweise möchten wir logarithmische oder sogar konstante Komplexitätsgeschwindigkeiten erreichen.
Dies ist ein enormes und komplexes Thema, das viele Kompromisse mit sich bringt. Wenn ich jedoch auf jahrzehntelange Datenbankimplementierungen und -recherchen zurückblicke, würde ich argumentieren, dass es nur wenige Ansätze gibt, die häufig verwendet werden:

Erstens wird der Suchbereich reduziert, indem der gesamte Bereich hierarchisch in kleinere Teile geschnitten wird.
Im Allgemeinen wird dies mit Bäumen erreicht. Es ist ähnlich wie Kisten mit Kisten in Ihrem Kleiderschrank. Jede Box enthält Materialien, die für eine bestimmte Verwendung in kleinere Boxen sortiert sind. Wenn wir Materialien benötigen, sollten wir besser nach der Box mit der Bezeichnung "Material" suchen als nach einer Box mit der Bezeichnung "Cookies".
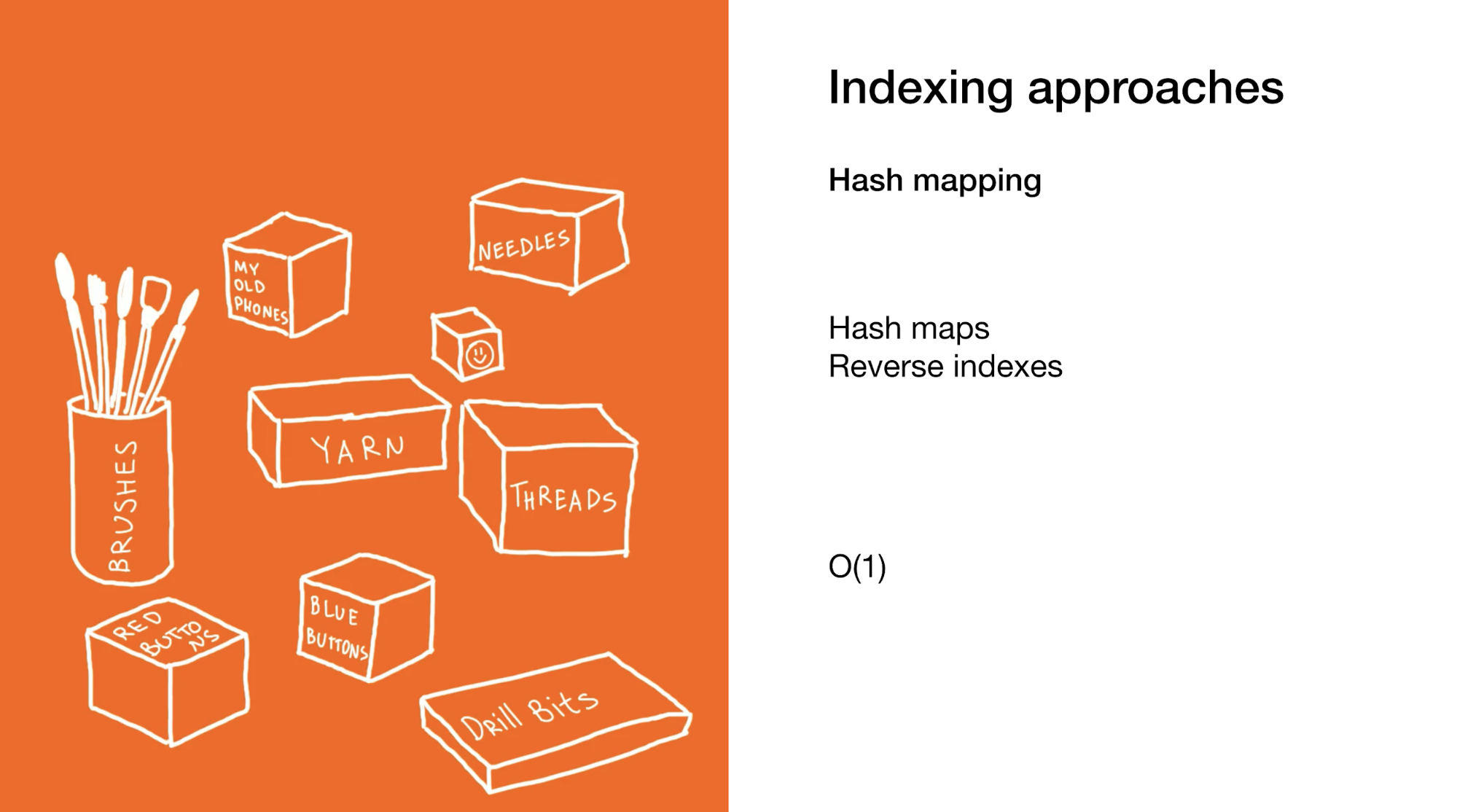
Zweitens müssen Sie ein bestimmtes Element oder eine Gruppe von Elementen wie in Hash-Maps oder umgekehrten Indizes sofort lokalisieren. Die Verwendung von Hash-Maps ähnelt dem vorherigen Beispiel, Sie verwenden jedoch viele kleinere Felder, die keine Felder selbst enthalten, sondern Endelemente.

Der dritte Ansatz besteht darin, die Notwendigkeit zu beseitigen, überhaupt zu suchen, wie bei Blütenfiltern oder Kuckucksfiltern. Bloom-Filter können Ihnen sofort eine Antwort geben und Ihnen die Zeit sparen, die Sie sonst für die Suche aufgewendet haben.
Der letzte Schritt ist die Beschleunigung der Suche, indem unsere Hardwarefunktionen wie in Bitmap-Indizes besser genutzt werden. Bei Bitmap-Indizes wird manchmal der gesamte Index durchlaufen, ja, aber dies geschieht auf sehr effiziente Weise.
Wie ich bereits sagte, hat die Suche eine Menge Kompromisse, so dass wir oft verschiedene Ansätze verwenden, um die Geschwindigkeit noch weiter zu verbessern oder alle unsere potenziellen Suchtypen abzudecken.
Heute möchte ich über einen dieser weniger bekannten Ansätze sprechen: Bitmap-Indizes.
Aber wer soll ich über dieses Thema sprechen?
Ich bin Teamleiter bei Badoo (vielleicht kennen Sie eine andere unserer Marken: Bumble). Wir haben weltweit mehr als 400 Millionen Benutzer und viele der Funktionen, die wir haben, beinhalten die Suche nach der besten Übereinstimmung für Sie! Für diese Aufgaben verwenden wir maßgeschneiderte Dienste, die unter anderem Bitmap-Indizes verwenden.
Was ist nun ein Bitmap-Index?
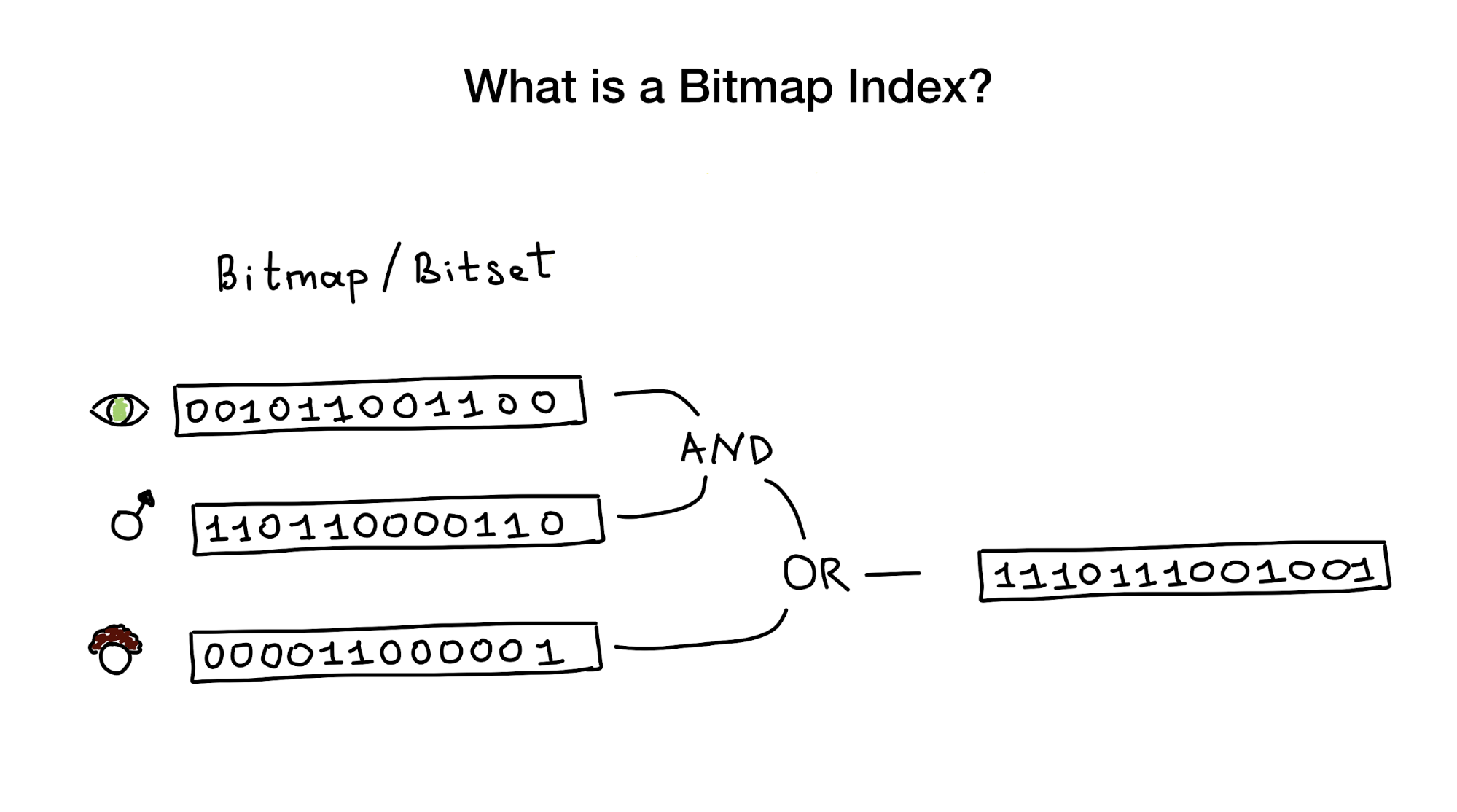
Wie der Name schon sagt, verwenden Bitmap-Indizes Bitmaps, auch Bitsets genannt, um den Suchindex zu implementieren. Aus der Vogelperspektive besteht dieser Index aus einer oder mehreren Bitmaps, die Entitäten (z. B. Personen) und deren Parameter (z. B. Alter oder Augenfarbe) darstellen, und einem Algorithmus zur Beantwortung von Suchanfragen mit bitweisen Operationen wie AND, OR, NOT usw. .

Bitmap-Indizes werden als sehr nützlich und leistungsstark angesehen, wenn Sie eine Suche durchführen, bei der Abfragen aus mehreren Spalten mit geringer Kardinalität (möglicherweise Augenfarbe oder Familienstand) und einer Entfernung zum Stadtzentrum mit unendlicher Kardinalität kombiniert werden müssen.
Aber später in diesem Artikel werde ich zeigen, dass Bitmap-Indizes sogar mit Spalten mit hoher Kardinalität funktionieren.
Schauen wir uns das einfachste Beispiel eines Bitmap-Index an ...

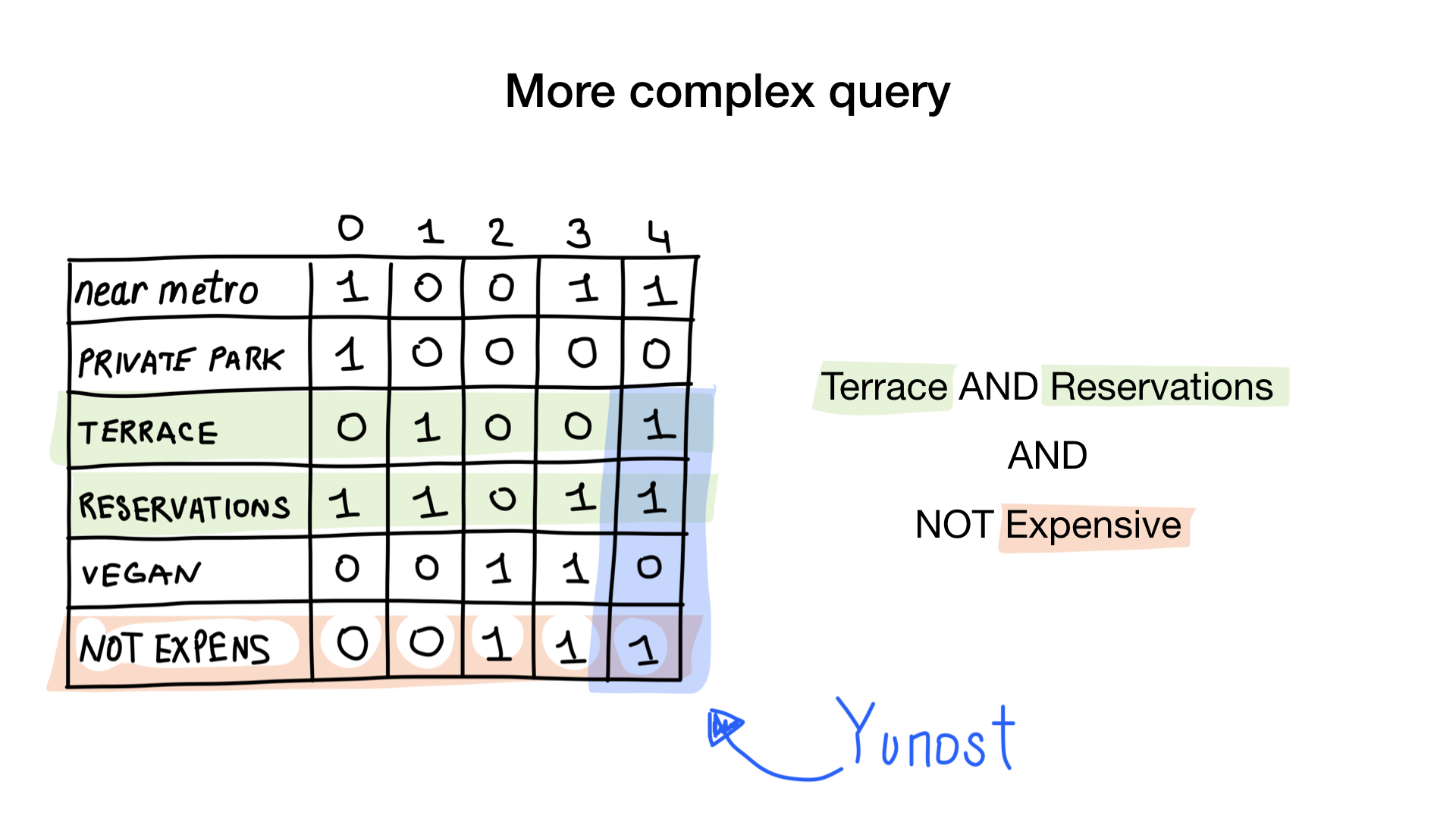
Stellen Sie sich vor, wir haben eine Liste von Moskauer Restaurants mit binären Merkmalen:
- in der Nähe der U-Bahn
- hat einen privaten Parkplatz
- hat Terrasse
- nimmt Reservierungen entgegen
- vegan-freundlich
- teuer
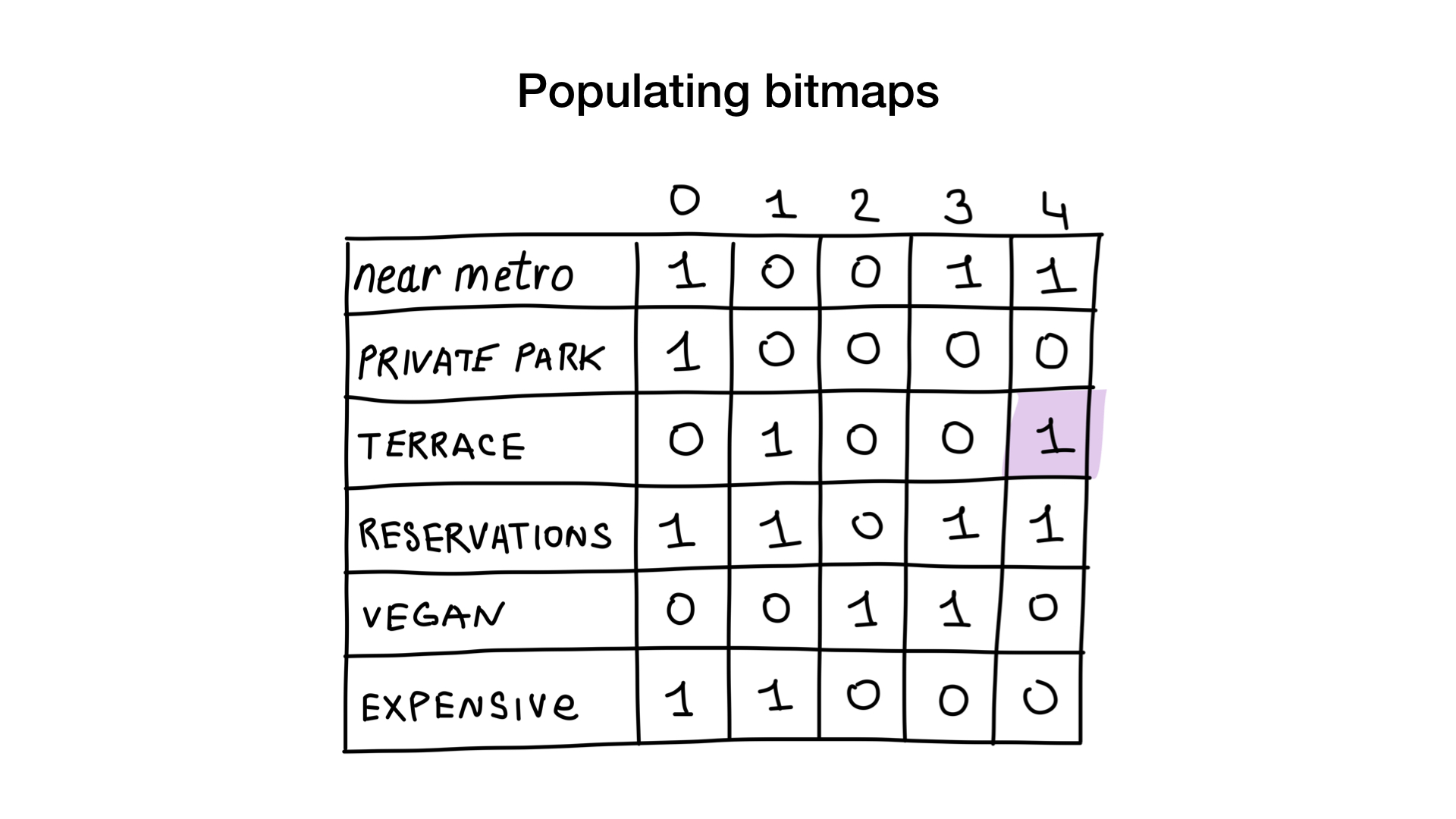
Geben Sie jedem Restaurant einen Index ab 0 und weisen Sie 6 Bitmaps zu (eine für jedes Merkmal). Dann würden wir diese Bitmaps danach füllen, ob das Restaurant eine bestimmte Eigenschaft hat oder nicht. Wenn das Restaurant Nummer 4 die Terrasse hat, wird Bit Nummer 4 in der Bitmap "Terrasse" auf 1 gesetzt (0, wenn nicht).

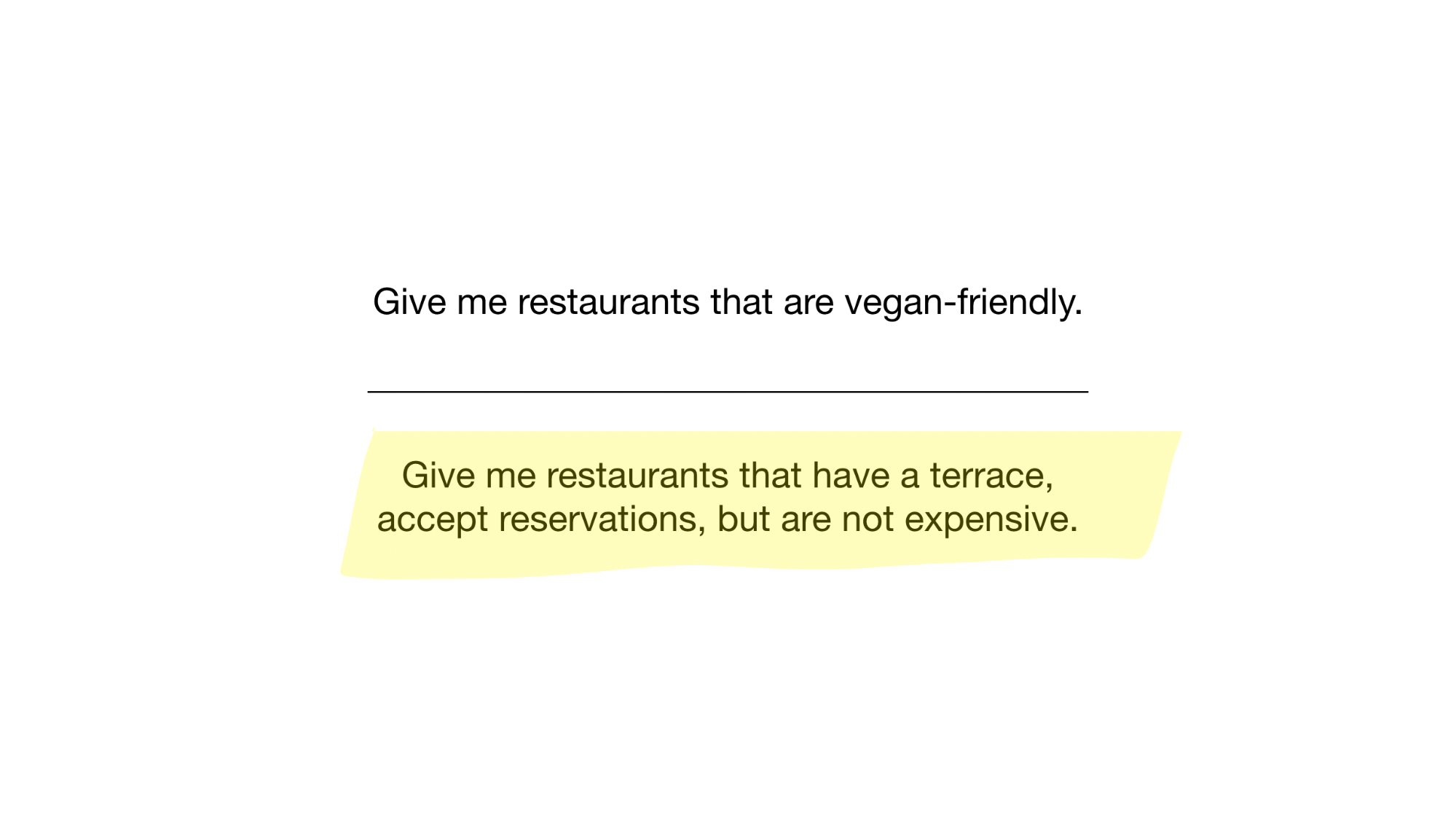
Wir haben jetzt den einfachsten möglichen Bitmap-Index, mit dem wir Fragen wie beantworten können
- Gib mir Restaurants, die vegan freundlich sind
- Geben Sie mir Restaurants mit einer Terrasse, die Reservierungen annehmen, aber nicht teuer sind


Wie? Mal sehen. Die erste Frage ist einfach. Wir nehmen einfach eine "vegan-freundliche" Bitmap und geben alle Indizes zurück, die ein Bit gesetzt haben.

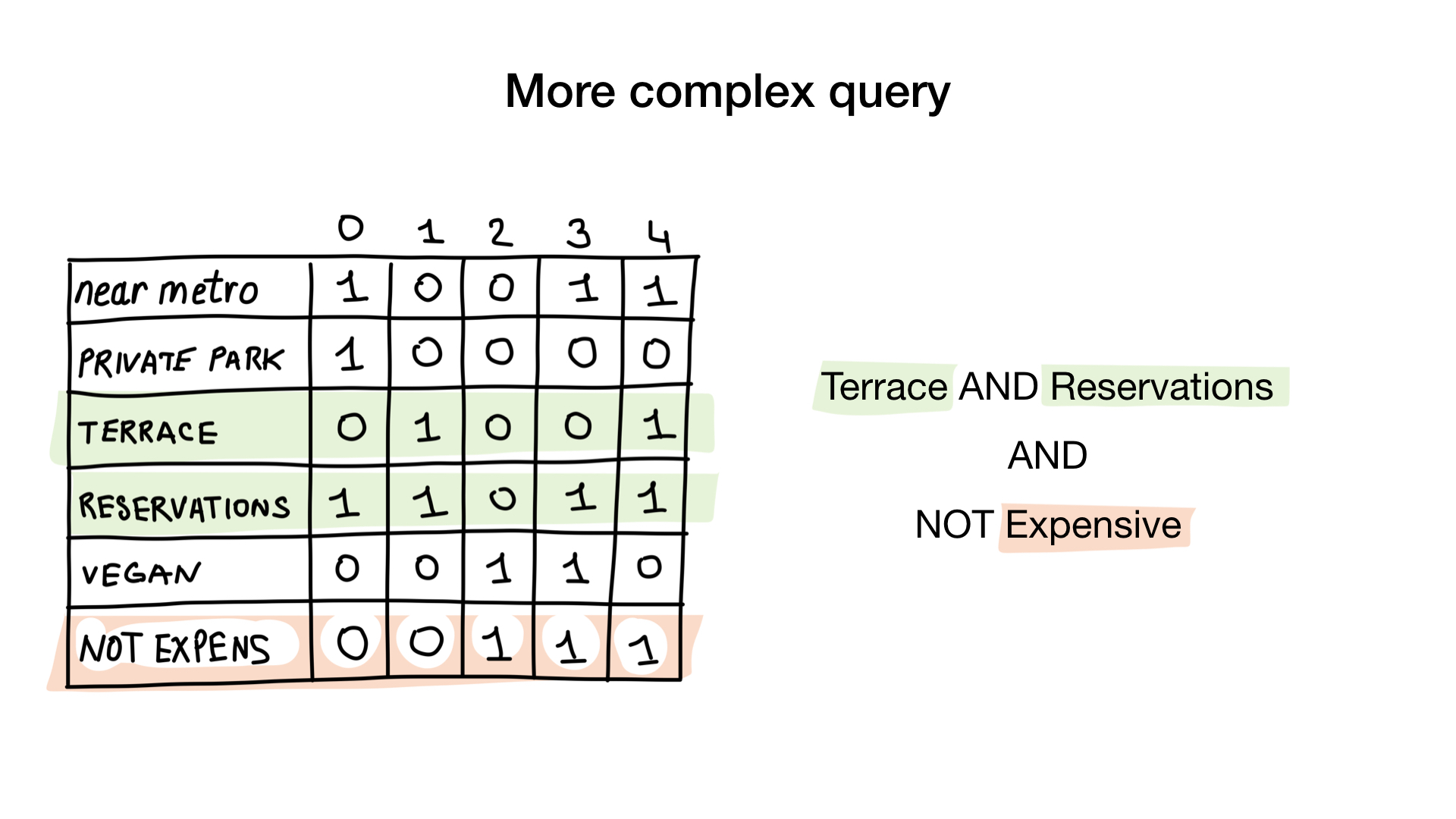
Die zweite Frage ist etwas komplizierter. Wir werden die bitweise Operation NICHT für die "teure" Bitmap verwenden, um nicht teure Restaurants zu erhalten, UND sie mit der Bitmap "Reservierung annehmen" und UND mit der Bitmap "Terrasse". Die resultierende Bitmap besteht aus Restaurants mit all den Eigenschaften, die wir wollten. Hier sehen wir, dass nur Yunost all diese Eigenschaften hat.
Dies mag etwas theoretisch aussehen, aber keine Sorge, wir werden in Kürze auf den Code eingehen.
Wo Bitmap-Indizes verwendet werden

Wenn Sie den "Bitmap-Index" googeln, verweisen 90% der Ergebnisse auf Oracle DB mit grundlegenden Bitmap-Indizes. Aber sicherlich verwenden auch andere DBMS Bitmap-Indizes, nicht wahr? Nein, eigentlich nicht. Lassen Sie uns die üblichen Verdächtigen einzeln durchgehen.


- Aber es gibt einen neuen Jungen auf dem Block: Pilosa. Pilosa ist ein neues DBMS, das in Go geschrieben wurde (beachten Sie, dass es kein R gibt, es ist nicht relational), das alles auf Bitmap-Indizes basiert. Und wir werden später über Pilosa sprechen.
Implementierung in go
Aber warum? Warum werden Bitmap-Indizes so selten verwendet? Bevor ich diese Frage beantworte, möchte ich Sie durch die grundlegende Implementierung des Bitmap-Index in Go führen.

Bitmap wird als Speicherblock dargestellt. In Go verwenden wir dafür ein Stück Bytes.
Wir haben eine Bitmap pro Restaurantmerkmal. Jedes Bit in einer Bitmap gibt an, ob ein bestimmtes Restaurant diese Eigenschaft aufweist oder nicht.

Wir würden zwei Hilfsfunktionen benötigen. Eine wird verwendet, um die Bitmap zufällig zu füllen, jedoch mit einer bestimmten Wahrscheinlichkeit, die Charakteristik zu haben. Ich denke zum Beispiel, dass es nur sehr wenige Restaurants gibt, die keine Reservierungen annehmen, und ungefähr 20% sind vegan-freundlich.
Eine andere Funktion gibt uns die Liste der Restaurants aus einer Bitmap.


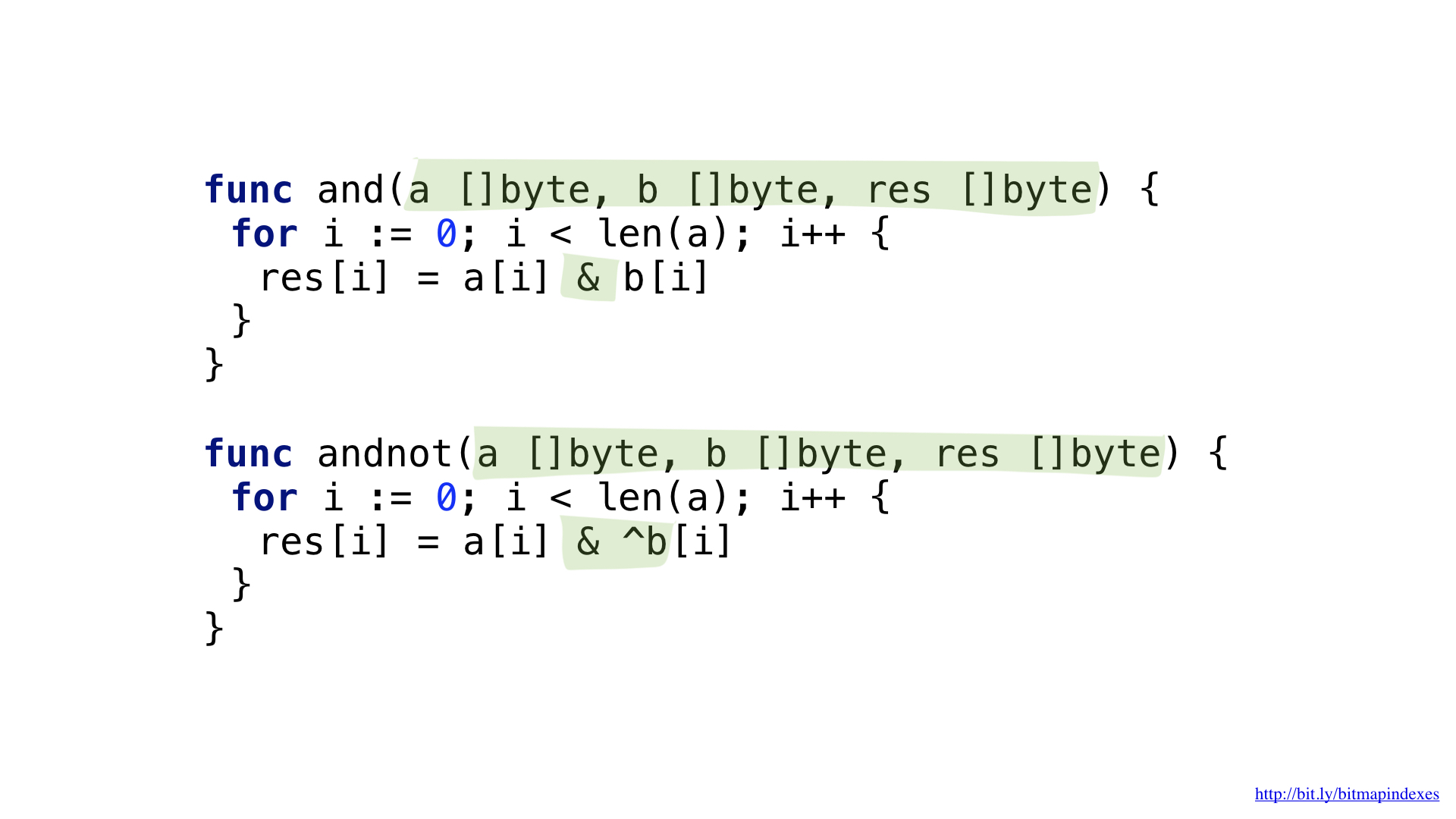
Um die Frage "Gib mir Restaurants mit einer Terrasse, die Reservierungen annehmen, aber nicht teuer sind" zu beantworten, benötigen wir zwei Operationen: NICHT und UND.
Wir können den Code leicht vereinfachen, indem wir eine komplexe Operation UND NICHT einführen.
Wir haben die Funktionen für jede von diesen. Beide Funktionen durchlaufen unsere Slices, indem sie jeweils entsprechende Elemente entnehmen, die Operation ausführen und das Ergebnis in das resultierende Slice schreiben.
Und jetzt können wir unsere Bitmaps und unsere Funktionen verwenden, um die Antwort zu erhalten.

Die Leistung ist hier nicht so gut, obwohl unsere Funktionen sehr einfach sind und wir viel bei der Zuweisung gespart haben, indem wir nicht bei jedem Funktionsaufruf ein neues Slice zurückgegeben haben.
Nach einigen Profilen mit pprof stellte ich fest, dass der go-Compiler eine der grundlegenden Optimierungen übersehen hatte: das Inlining von Funktionen.
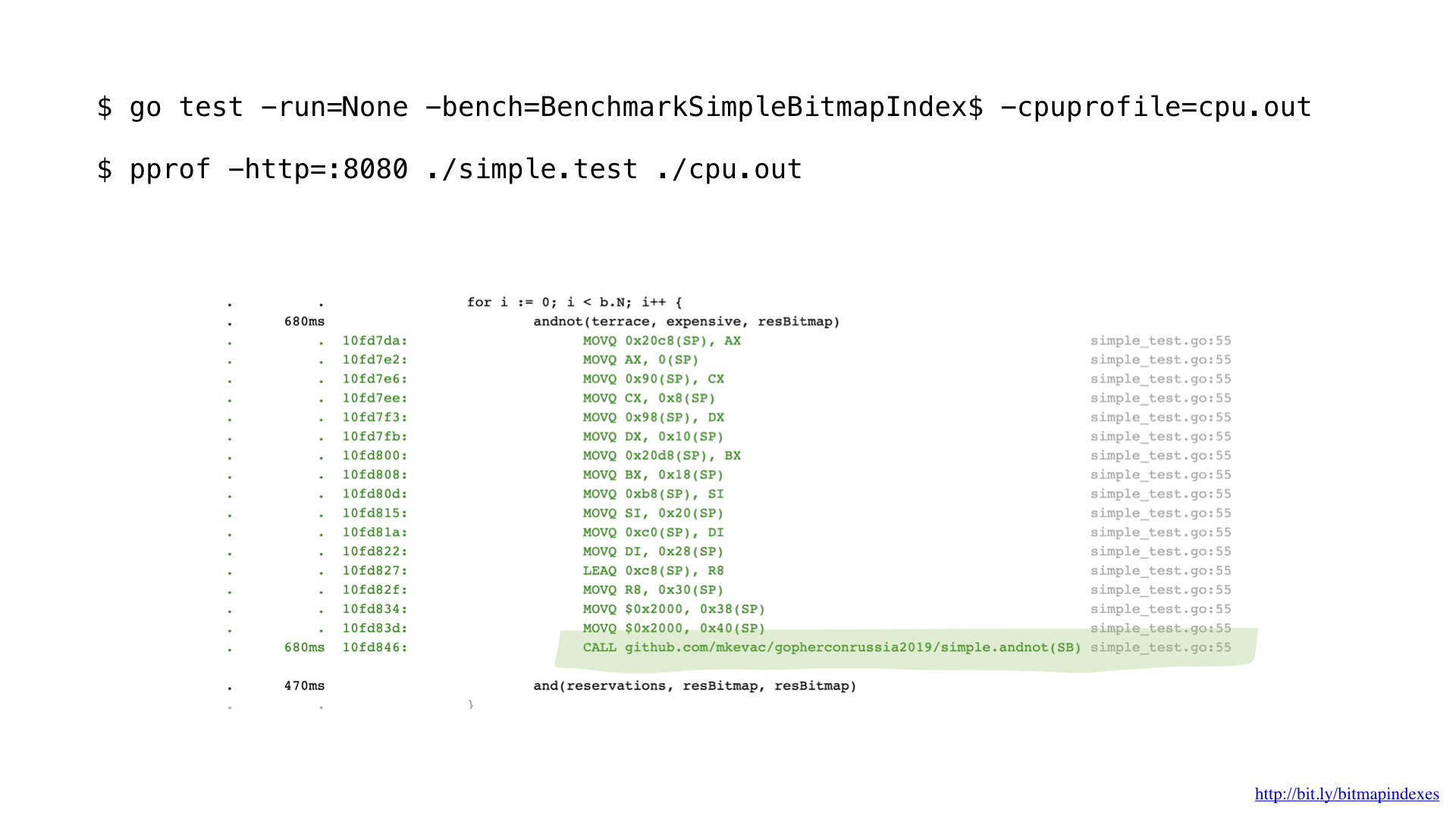
Sie sehen, der Go-Compiler hat pathologische Angst vor Schleifen durch Slices und weigert sich, jede Funktion mit diesen zu inline.
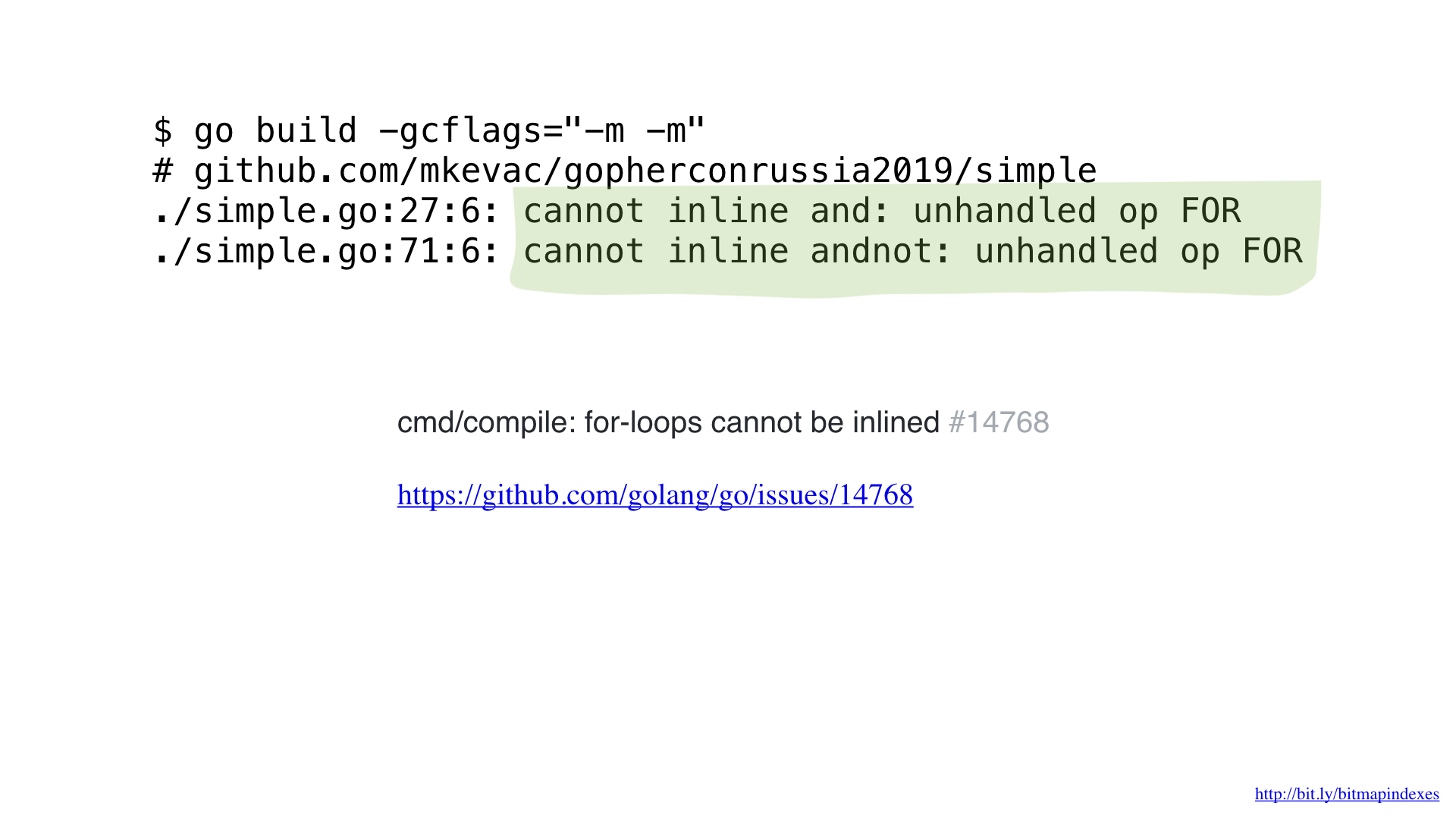
Aber ich habe keine Angst vor ihnen und kann den Compiler täuschen, indem ich goto für meine Schleife verwende.


Wie Sie sehen können, hat uns das Inlining etwa 2 Mikrosekunden erspart. Nicht schlecht!

Ein weiterer Engpass ist leicht zu erkennen, wenn Sie sich die Baugruppenleistung genauer ansehen. Der Go-Compiler hat Bereichsprüfungen in unsere Schleife aufgenommen. Go ist eine sichere Sprache und der Compiler befürchtet, dass meine drei Bitmaps unterschiedliche Längen haben und ein Pufferüberlauf auftreten könnte.
Lassen Sie uns den Compiler beruhigen und zeigen, dass alle meine Bitmaps gleich lang sind. Dazu können wir am Anfang der Funktion eine einfache Prüfung hinzufügen.
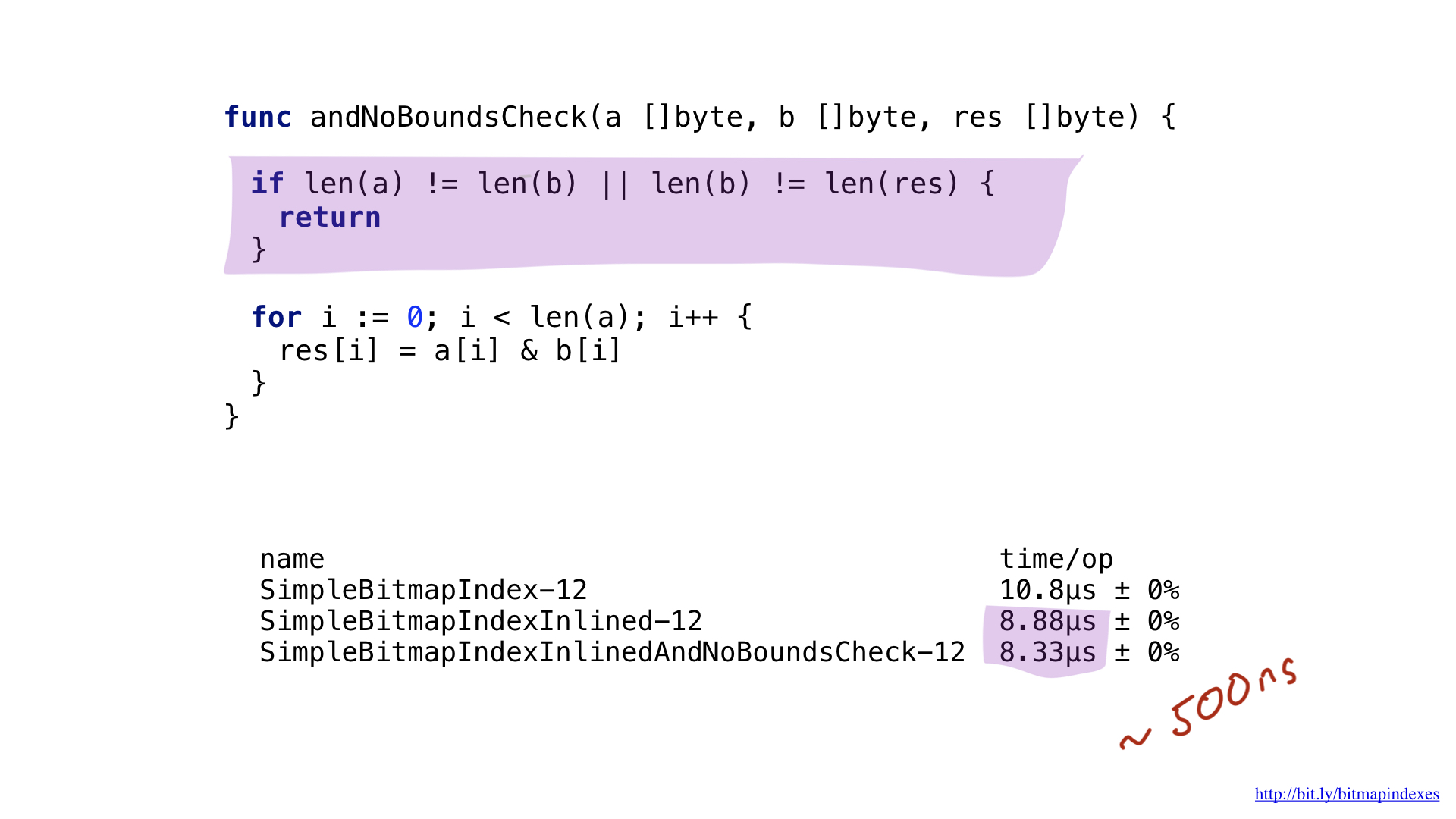
Mit dieser Prüfung überspringt der go-Compiler gerne Bereichsprüfungen und wir sparen einige Nanosekunden.
Implementierung in der Montage
Okay, wir haben es also geschafft, durch unsere einfache Implementierung ein bisschen mehr Leistung zu erzielen, aber dieses Ergebnis ist weitaus schlechter als das, was mit aktueller Hardware möglich ist.
Sie sehen, was wir tun, sind sehr grundlegende bitweise Operationen, und unsere CPUs sind mit diesen sehr effektiv.
Leider versorgen wir unsere CPU mit sehr kleinen Arbeitsblöcken. Unsere Funktion führt Operationen byteweise aus. Wir können unsere Implementierung leicht anpassen, um mit 8-Byte-Chunks zu arbeiten, indem wir Slices von uint64 verwenden.

Wie Sie hier sehen können, haben wir bei 8-facher Stapelgröße etwa die 8-fache Leistung erzielt, sodass die Leistungssteigerungen ziemlich linear sind.
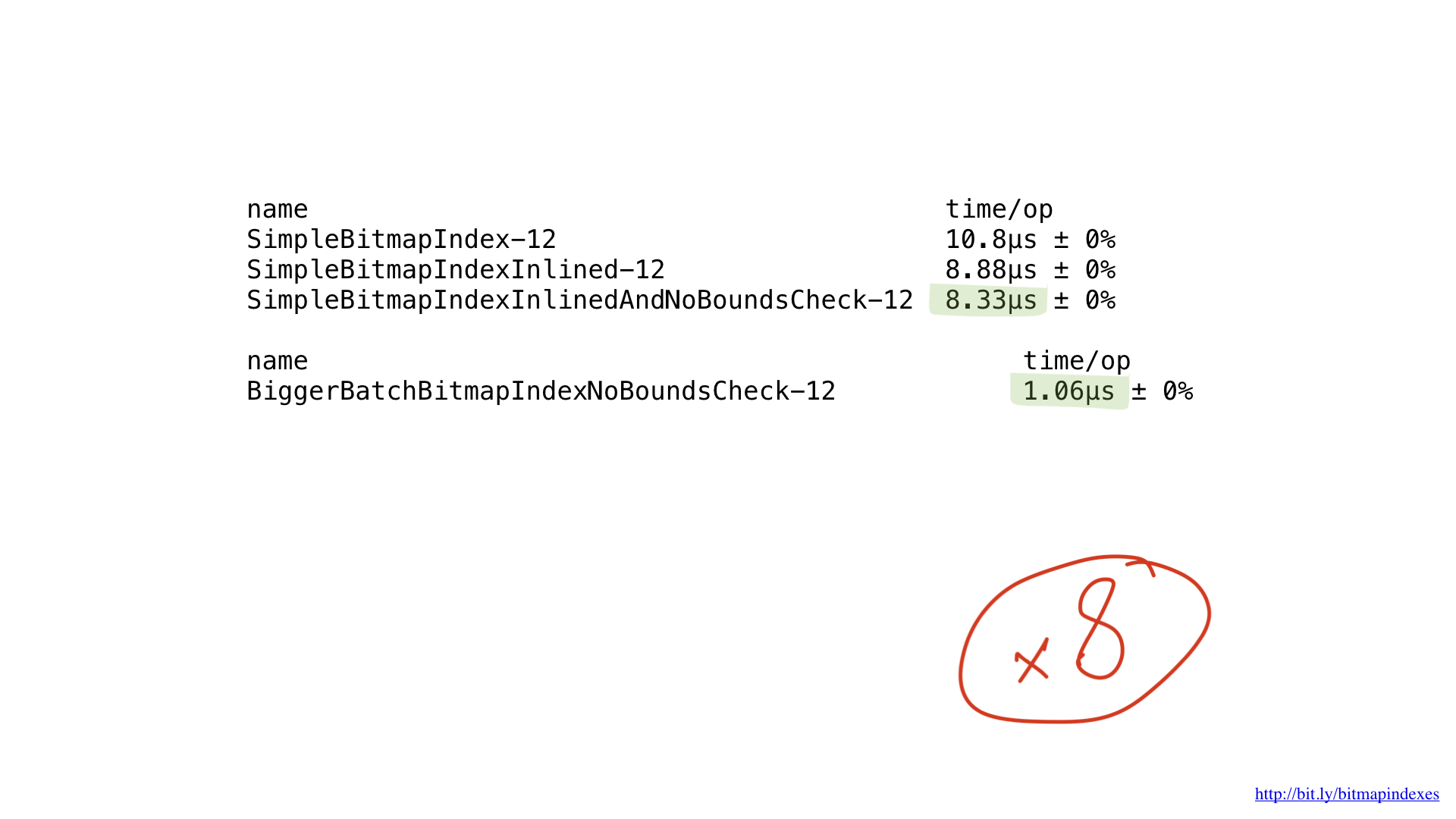

Dies ist jedoch nicht das Ende der Straße. Unsere CPUs können mit 16-Byte-, 32-Byte- und sogar 64-Byte-Blöcken arbeiten. Diese Operationen werden als SIMD (Single Instruction Multiple Data) bezeichnet, und der Prozess der Verwendung solcher CPU-Operationen wird als Vektorisierung bezeichnet.
Leider ist der Go-Compiler nicht sehr gut in der Vektorisierung. Und das einzige, was wir heutzutage tun können, um unseren Code zu vektorisieren, ist, die Go-Assembly zu verwenden und diese SIMD-Anweisungen selbst hinzuzufügen.

Go Assembly ist ein seltsames Tier. Sie würden denken, dass Assembly etwas ist, das an die Architektur gebunden ist, für die Sie schreiben, aber die Assembly von Go ähnelt eher IRL (Intermediate Representation Language): Sie ist plattformunabhängig. Rob Pike hat vor einigen Jahren einen erstaunlichen Vortrag darüber gehalten.
Darüber hinaus verwendet Go ein ungewöhnliches Plan9-Format, das sich sowohl vom AT & T- als auch vom Intel-Format unterscheidet.

Man kann mit Sicherheit sagen, dass das Schreiben von Go-Assembler-Code keinen Spaß macht.
Zum Glück gibt es bereits zwei übergeordnete Tools, die beim Schreiben der Go-Assemblierung helfen: PeachPy und Avo. Beide generieren eine Go-Assembly aus einem übergeordneten Code, der in Python bzw. Go geschrieben ist.

Diese Tools vereinfachen Dinge wie die Zuweisung von Registern und Schleifen und reduzieren insgesamt die Komplexität des Einstiegs in den Bereich der Assembly-Programmierung für Go.
Wir werden das Vermeiden für diesen Beitrag verwenden, damit unsere Programme fast wie gewöhnlicher Go-Code aussehen.

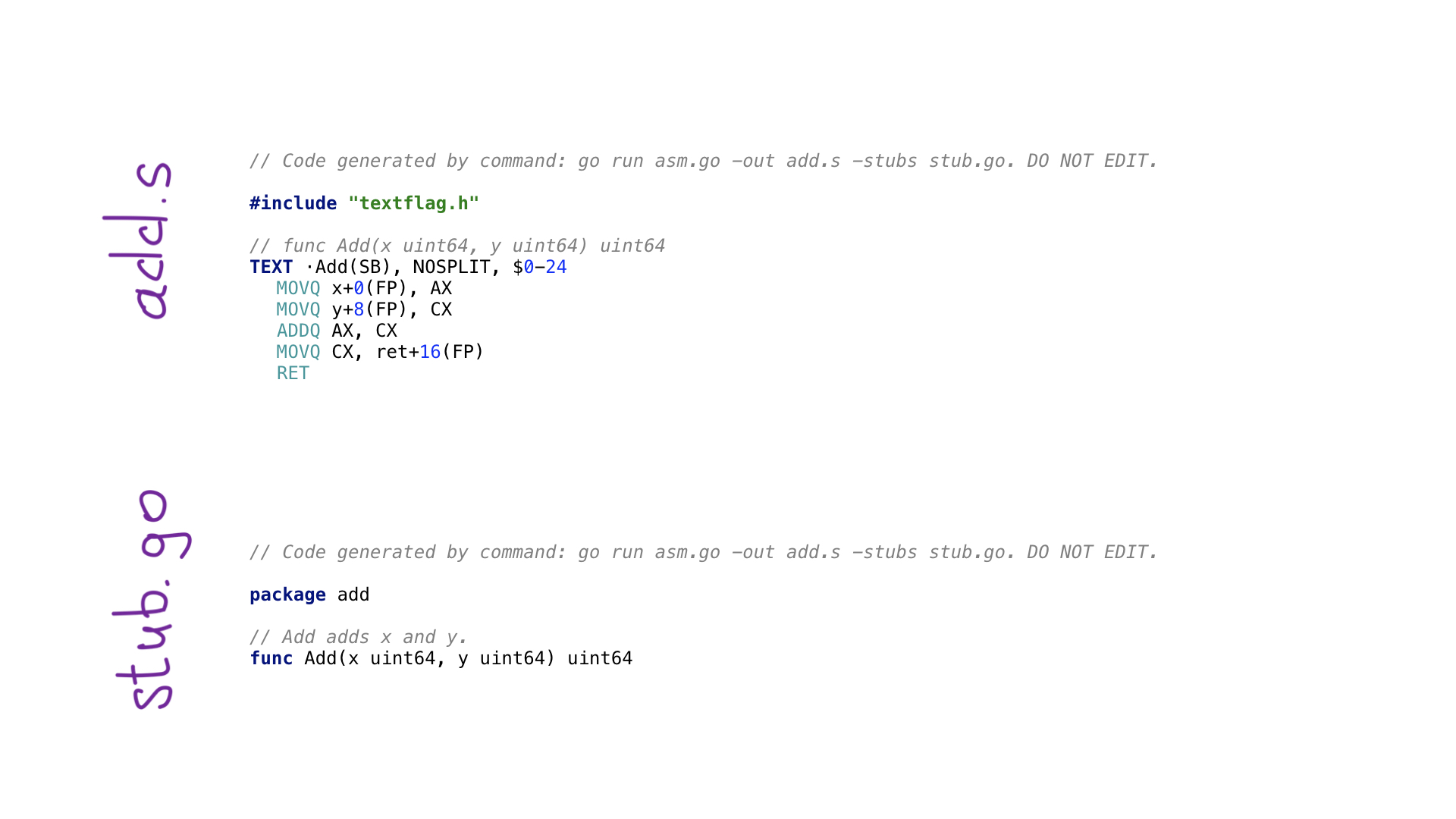
Dies ist das einfachste Beispiel für ein Avo-Programm. Wir haben eine main () - Funktion, die eine Funktion namens Add () definiert, die zwei Zahlen hinzufügt. Es gibt Hilfsfunktionen, um Parameter nach Namen abzurufen und eines der verfügbaren allgemeinen Register abzurufen. Hier gibt es Funktionen für jede Assemblierungsoperation wie ADDQ, und es gibt Hilfsfunktionen, um das Ergebnis aus einem Register auf den resultierenden Wert zu speichern.

Wenn Sie go generate aufrufen, wird dieses avo-Programm ausgeführt und zwei Dateien werden erstellt
- add.s mit generiertem Assemblycode
- stub.go mit Funktionsheadern, die zum Verbinden unseres Go- und Assembly-Codes benötigt werden
Nachdem wir gesehen haben, was Avo tut, schauen wir uns unsere Funktionen an. Ich habe sowohl skalare als auch SIMD (Vektor) -Versionen unserer Funktionen implementiert.
Mal sehen, wie die skalare Version zuerst aussieht.

Wie in einem vorherigen Beispiel können wir ein allgemeines Register anfordern und vermeiden, dass wir das richtige erhalten, das verfügbar ist. Wir müssen für unsere Argumente keine Offsets in Bytes verfolgen, um dies für uns zu vermeiden.

Zuvor haben wir aus Leistungsgründen von Schleifen auf goto umgestellt und den go-Compiler getäuscht. Hier verwenden wir von Anfang an goto (Sprünge) und Beschriftungen, da Schleifen übergeordnete Konstrukte sind. In der Montage haben wir nur Sprünge.

Anderer Code sollte ziemlich klar sein. Wir emulieren die Schleife mit Sprüngen und Beschriftungen, nehmen einen kleinen Teil unserer Daten aus unseren beiden Bitmaps, kombinieren sie mit einer der bitweisen Operationen und fügen das Ergebnis in die resultierende Bitmap ein.

Dies ist ein resultierender asm-Code, den wir erhalten. Wir mussten keine Offsets und Größen (in grün) berechnen, wir mussten uns nicht mit bestimmten Registern (in rot) befassen.
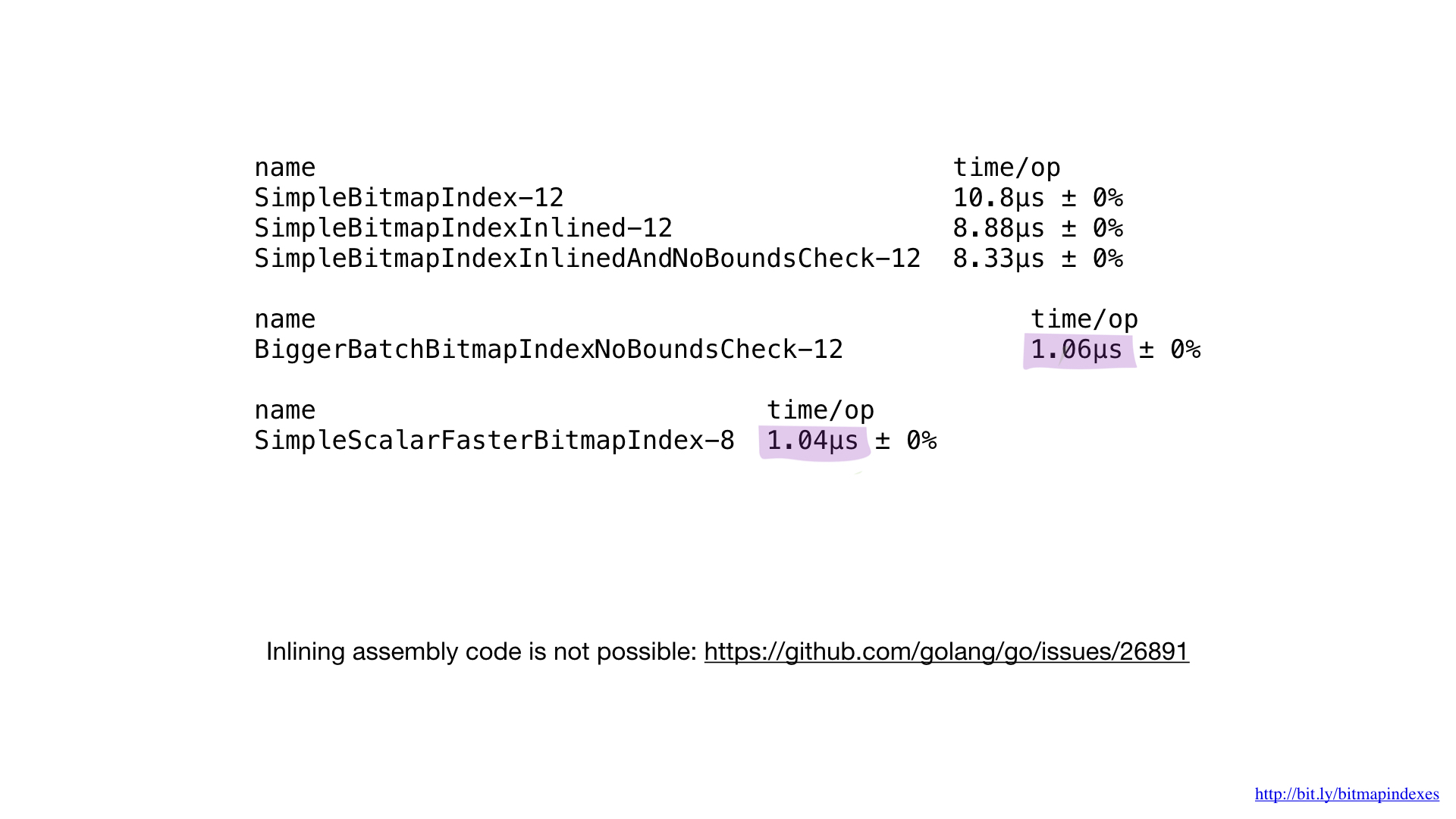
Wenn wir diese Implementierung in Assembly mit der zuvor besten Implementierung vergleichen, die in go geschrieben wurde, würden wir feststellen, dass die Leistung dieselbe ist wie erwartet. Wir haben nichts anders gemacht.
Leider können wir den Go-Compiler nicht zwingen, unsere in asm geschriebenen Funktionen zu integrieren. Es fehlt völlig die Unterstützung dafür und die Anfrage für diese Funktion besteht seit einiger Zeit. Deshalb bieten kleine asm-Funktionen in go keinen Nutzen. Sie müssen entweder größere Funktionen schreiben, ein neues Paket math / bits verwenden oder asm insgesamt überspringen.
Schreiben wir jetzt eine Vektorversion unserer Funktionen.

Ich habe mich für AVX2 entschieden, daher werden wir 32-Byte-Chunks verwenden. Es ist dem Skalar in seiner Struktur sehr ähnlich. Wir laden Parameter aus, fragen nach allgemeinen Registern usw.
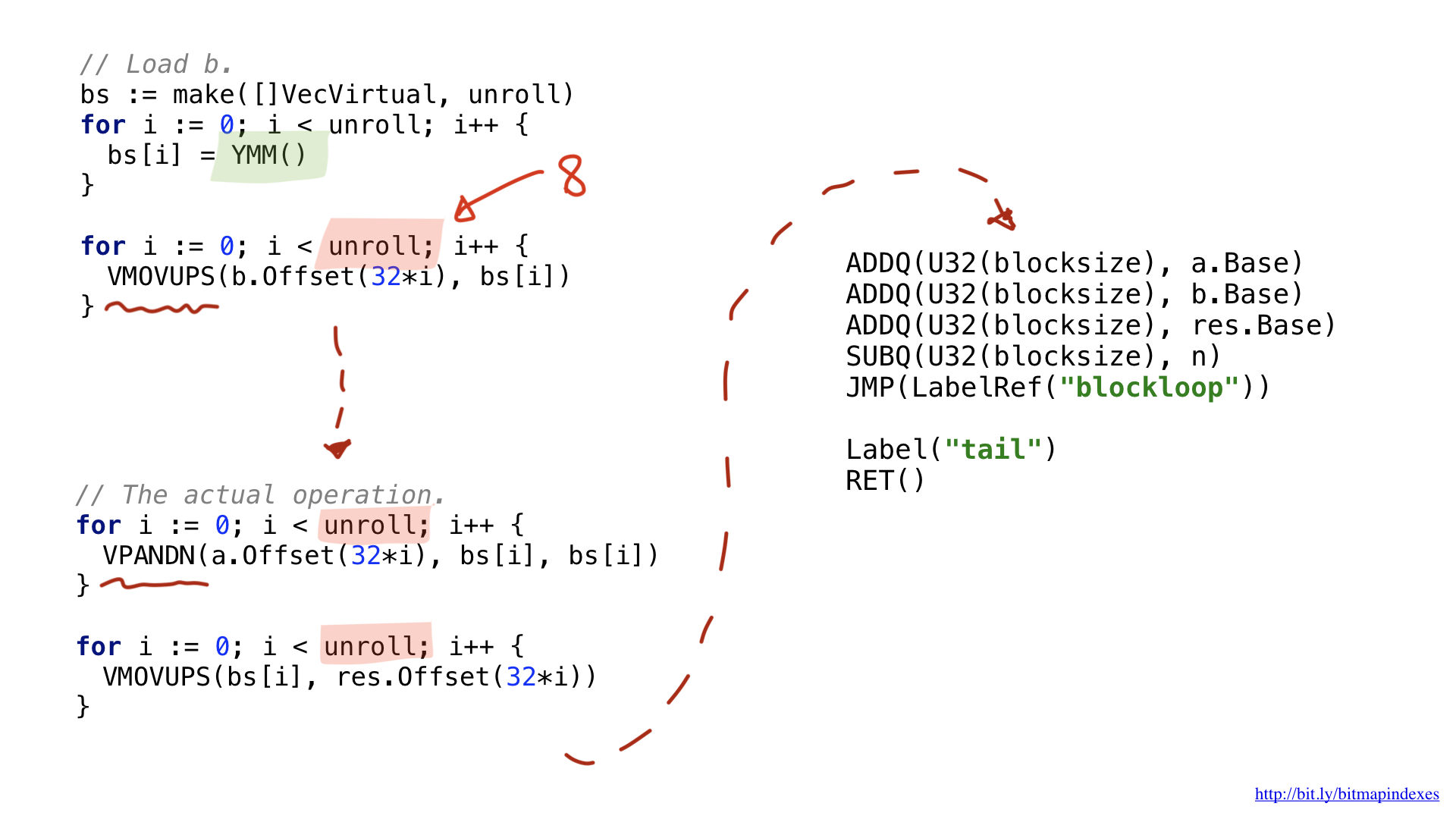
Eine der Änderungen hat mit der Tatsache zu tun, dass Vektoroperationen bestimmte breite Register verwenden. Für 32 Bytes haben sie das Y-Präfix. Deshalb sehen Sie dort YMM (). Für 64 Byte hätten sie das Z-Präfix gehabt.
Ein weiterer Unterschied hat mit der von mir durchgeführten Optimierung zu tun, die als Abrollen oder Schleifenabwickeln bezeichnet wird. Ich entschied mich, unsere Schleife teilweise abzuwickeln und 8 Schleifenoperationen nacheinander auszuführen, bevor ich zurückschleife. Diese Technik beschleunigt den Code, indem sie die vorhandenen Verzweigungen reduziert, und ist durch die Anzahl der verfügbaren Register ziemlich begrenzt.
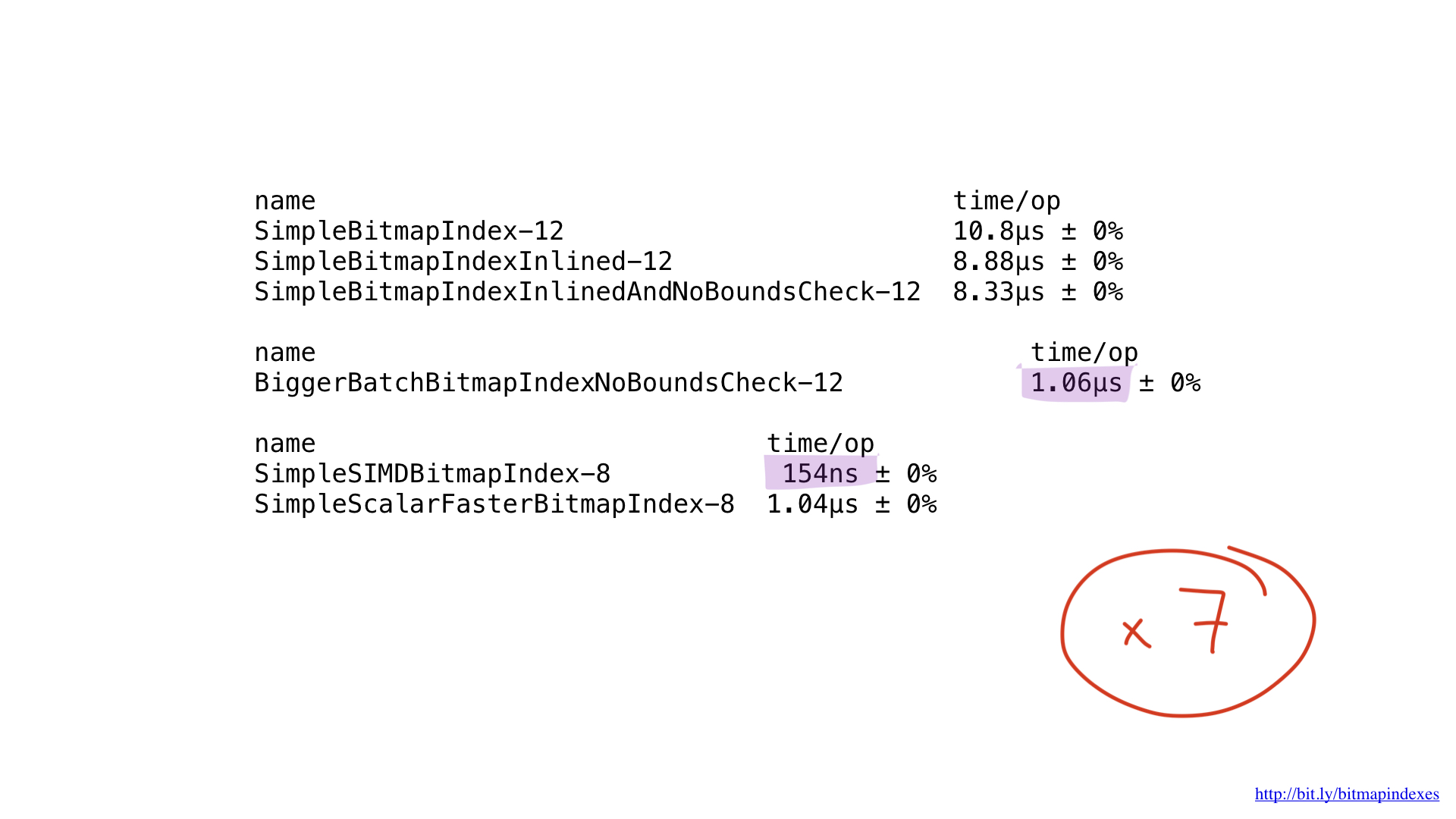
Was die Leistung betrifft ... ist es erstaunlich. Wir haben uns im Vergleich zum vorherigen Besten um das 7-fache verbessert. Ziemlich beeindruckend, oder?
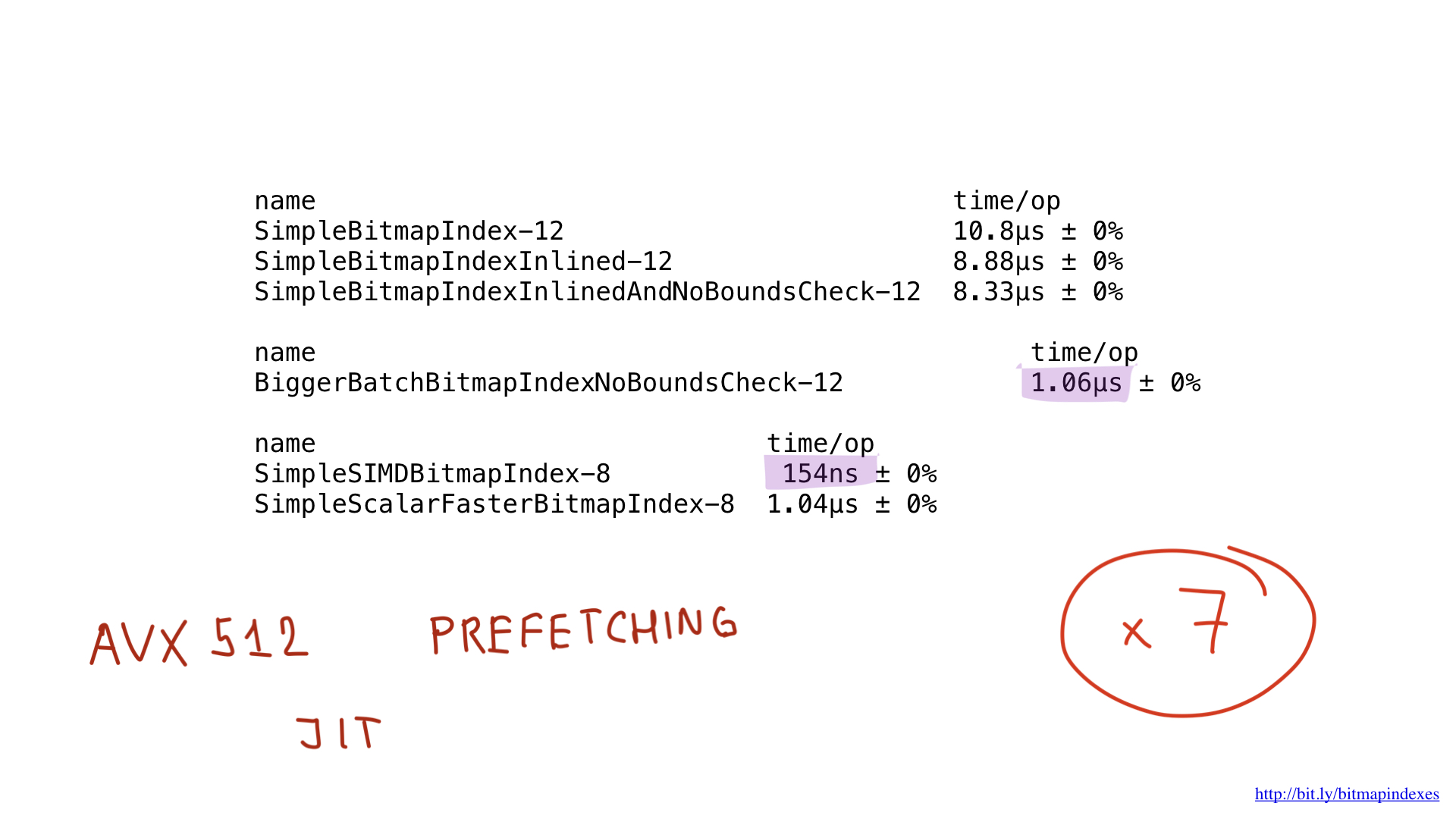
Es sollte möglich sein, diese Ergebnisse durch die Verwendung von AVX512, Prefetching und möglicherweise sogar durch die Verwendung der JIT-Kompilierung (just in time) anstelle des "manuellen" Abfrageplan-Builders noch weiter zu verbessern. Dies wäre jedoch ein Thema für einen völlig anderen Beitrag.
Probleme mit dem Bitmap-Index
Nachdem wir die grundlegende Implementierung und die beeindruckende Geschwindigkeit der asm-Implementierung gesehen haben, sprechen wir über die Tatsache, dass Bitmap-Indizes nicht sehr häufig verwendet werden. Warum ist das so?

Ältere Veröffentlichungen geben uns diese drei Gründe. Aber die jüngsten und ich argumentieren, dass diese inzwischen "behoben" oder behandelt wurden. Ich werde hier nicht auf viele Details eingehen, weil wir nicht viel Zeit haben, aber es ist auf jeden Fall einen kurzen Blick wert.
Problem mit hoher Kardinalität
Wir haben also erfahren, dass Bitmap-Indizes nur für Felder mit niedriger Kardinalität möglich sind. dh Felder mit wenigen unterschiedlichen Werten wie Geschlecht oder Augenfarbe. Der Grund dafür ist, dass die allgemeine Darstellung (ein Bit pro eindeutigem Wert) für Werte mit hoher Kardinalität ziemlich groß werden kann. Infolgedessen kann die Bitmap auch bei geringer Bevölkerungszahl sehr groß werden.
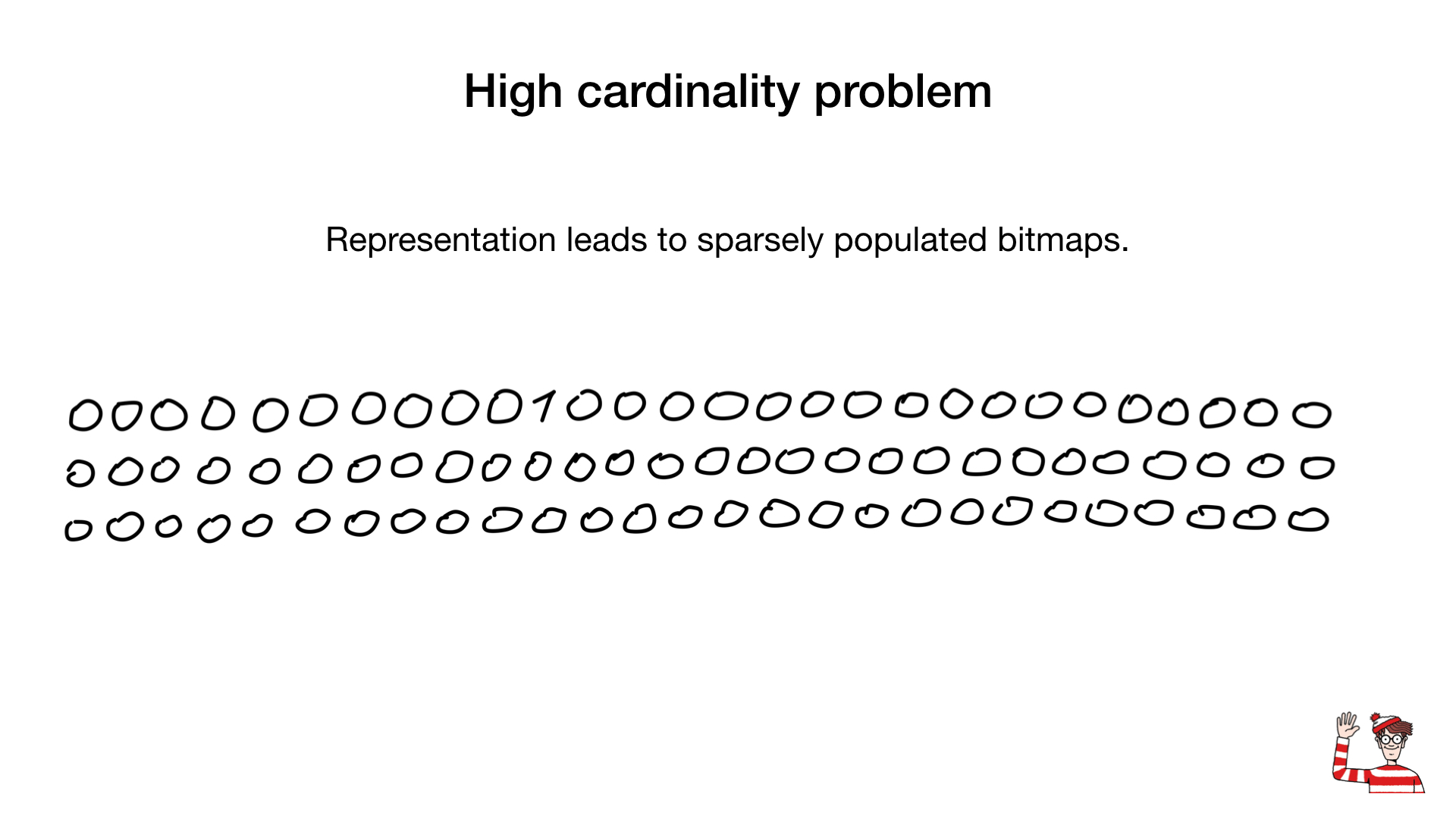
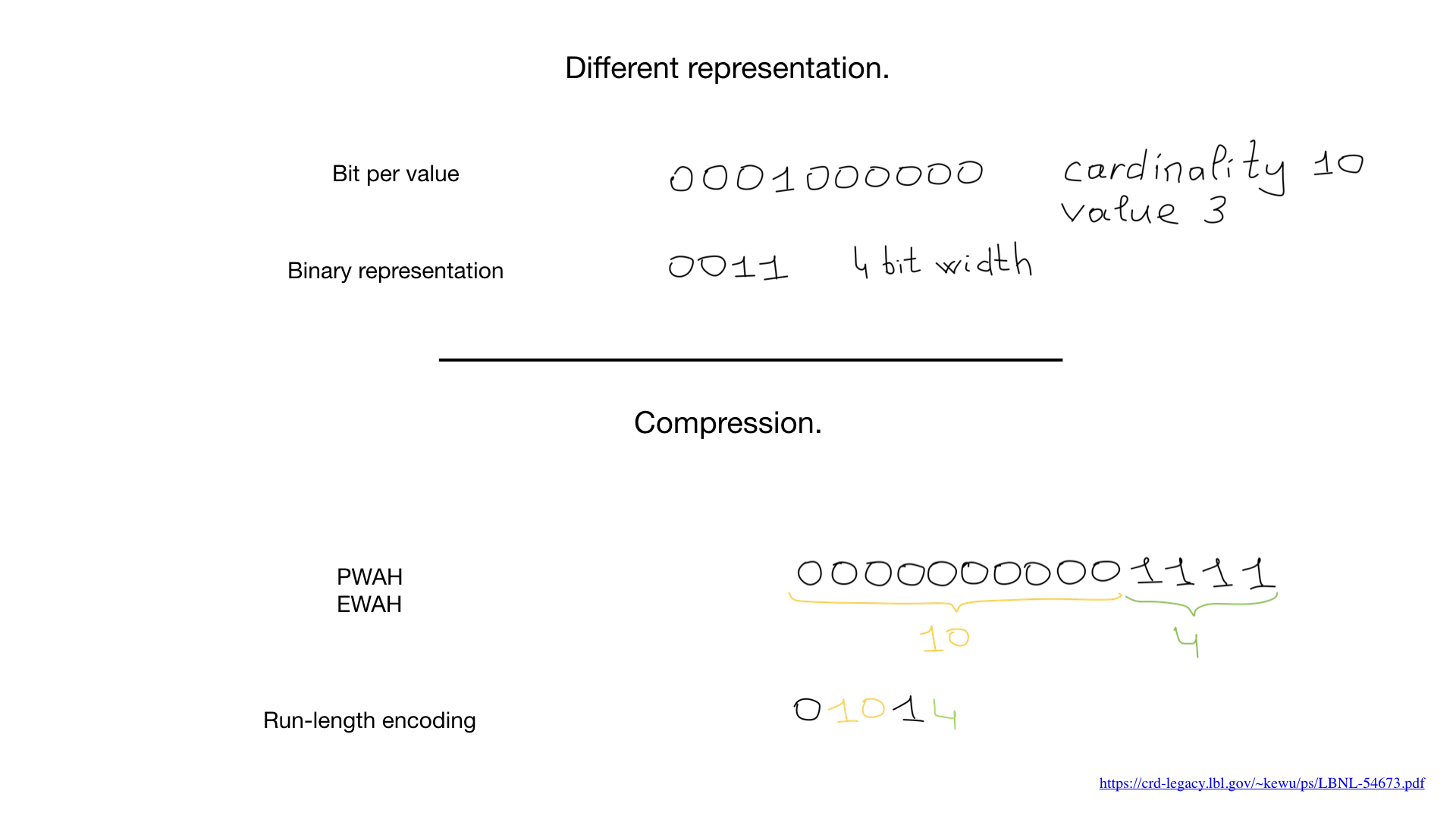
Manchmal kann für diese Felder eine andere Darstellung verwendet werden, z. B. eine Binärzahldarstellung, wie hier gezeigt, aber der größte Game Changer ist eine Komprimierung. Wissenschaftler haben erstaunliche Komprimierungsalgorithmen entwickelt. Fast alle basieren auf weit verbreiteten Lauflängenalgorithmen, aber was noch erstaunlicher ist, ist, dass wir keine Bitmaps dekomprimieren müssen, um bitweise Operationen an ihnen durchzuführen. Normale bitweise Operationen funktionieren mit komprimierten Bitmaps.

Vor kurzem haben wir gesehen, dass hybride Ansätze wie "brüllende Bitmaps" erscheinen. Roaring-Bitmaps verwenden drei separate Darstellungen für Bitmaps: Bitmaps, Arrays und "Bitläufe". Sie gleichen die Verwendung dieser drei Darstellungen aus, um die Geschwindigkeit zu maximieren und die Speichernutzung zu minimieren.
Brüllende Bitmaps finden sich in einigen der am häufigsten verwendeten Anwendungen, und es gibt Implementierungen für viele Sprachen, einschließlich mehrerer Implementierungen für Go.
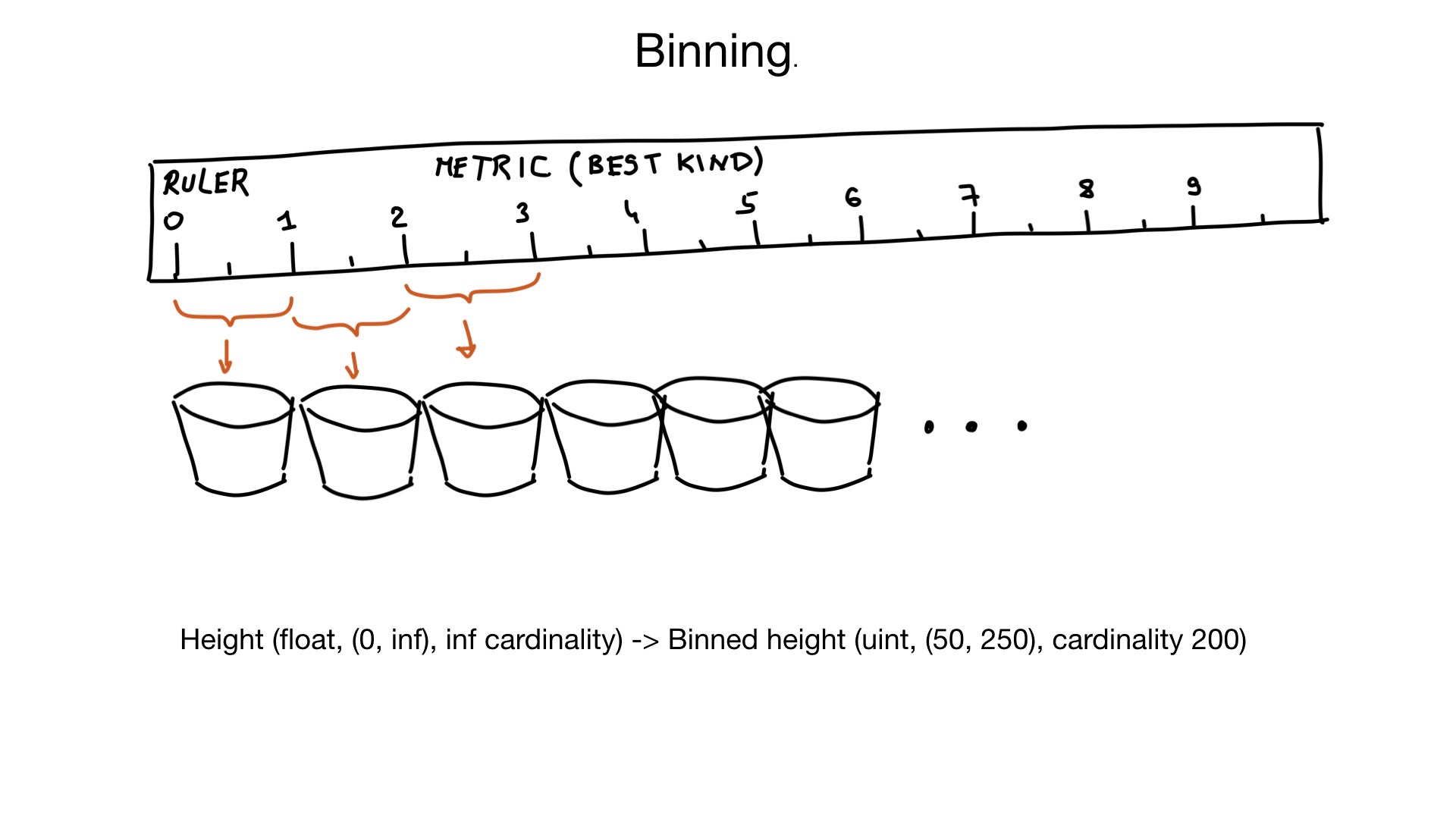
Ein anderer Ansatz, der bei Feldern mit hoher Kardinalität helfen kann, ist das Binning. Stellen Sie sich vor, wir haben ein Feld, das die Größe einer Person darstellt. Höhe ist ein Schwimmer, aber wir sehen das nicht so. Es interessiert niemanden, ob Ihre Größe 185,2 oder 185,3 cm beträgt. Wir können also "virtuelle Behälter" verwenden, um ähnliche Höhen in denselben Behälter zu drücken: in diesem Fall den 1-cm-Behälter. Und wenn Sie davon ausgehen, dass es nur sehr wenige Menschen mit einer Größe von weniger als 50 cm oder mehr als 250 cm gibt, können wir unsere Größe mit einer Kardinalität von ungefähr 200 Elementen anstelle einer nahezu unendlichen Kardinalität in das Feld umwandeln. Bei Bedarf können wir die Ergebnisse später zusätzlich filtern.
Problem mit hohem Durchsatz
Ein weiterer Grund, warum Bitmap-Indizes schlecht sind, ist, dass das Aktualisieren von Bitmaps teuer sein kann.
Datenbanken führen Aktualisierungen und Suchen parallel durch, sodass Sie in der Lage sein müssen, die Daten zu aktualisieren, während möglicherweise Hunderte von Threads Bitmaps durchlaufen, um eine Suche durchzuführen. Sperren wären Sperren erforderlich, um Datenrennen oder Datenkonsistenzprobleme zu vermeiden. Und wo es ein einziges großes Schloss gibt, gibt es einen Schlosskonflikt.
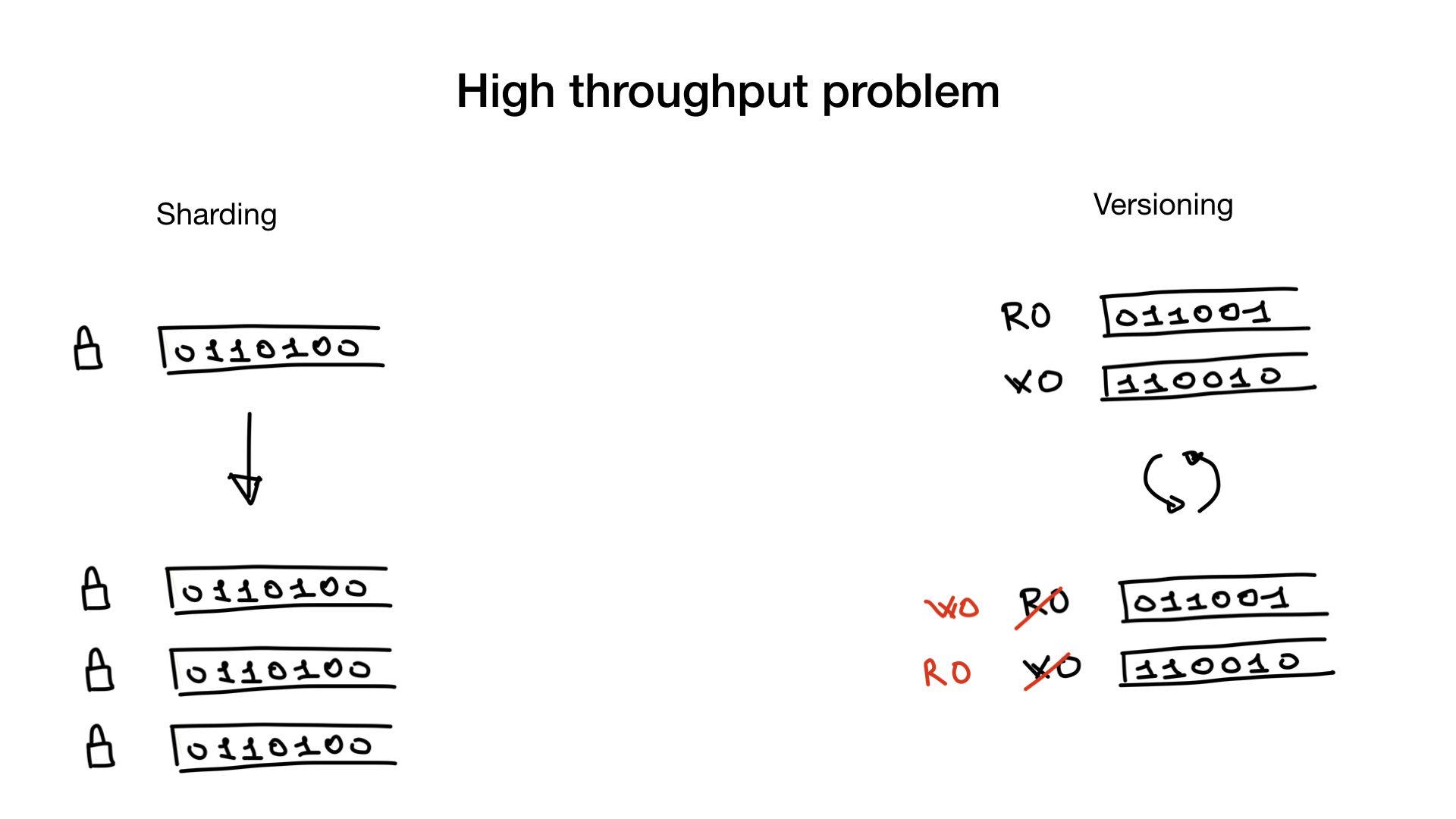
Dieses Problem kann, falls vorhanden, durch Sharding Ihrer Indizes oder gegebenenfalls durch Indexversionen behoben werden.
Scherben ist unkompliziert. Sie teilen sie wie Benutzer in einer Datenbank und jetzt haben Sie anstelle einer Sperre mehrere Sperren, wodurch Ihre Sperrenkonflikte erheblich reduziert werden.
Ein anderer Ansatz, der manchmal machbar ist, besteht darin, versionierte Indizes zu haben. Sie haben den Index, den Sie für die Suche verwenden, und Sie haben einen Index, den Sie für Schreibvorgänge und Aktualisierungen verwenden. Und Sie kopieren und schalten sie mit einer niedrigen Frequenz, z. B. 100 oder 500 ms.
Dieser Ansatz ist jedoch nur möglich, wenn Ihre App veraltete Suchindizes toleriert, die etwas veraltet sind.
Natürlich können diese beiden Ansätze auch zusammen verwendet werden. Sie können versionierte Indizes gesplittert haben.
Nicht triviale Abfragen
Ein weiteres Problem mit dem Bitmap-Index betrifft die Verwendung von Bitmap-Indizes mit Bereichsabfragen. Und auf den ersten Blick scheinen bitweise Operationen wie UND und ODER nicht sehr nützlich für Bereichsabfragen wie "Gib mir Hotelzimmer, die zwischen 200 und 300 Dollar pro Nacht kosten" zu sein.

Eine naive und sehr ineffiziente Lösung wäre, Ergebnisse für jeden Preispunkt von 200 bis 300 zu erhalten und die Ergebnisse zu ODER.

Ein etwas besserer Ansatz wäre es, Binning zu verwenden und unsere Hotels in Preisklassen mit Reichweiten von beispielsweise 50 Dollar einzuteilen. Dieser Ansatz würde unsere Suchkosten um etwa das 50-fache reduzieren.
Dieses Problem kann aber auch sehr einfach gelöst werden, indem eine spezielle Codierung verwendet wird, die Bereichsabfragen möglich und schnell macht. In der Literatur werden solche Bitmaps als bereichscodierte Bitmaps bezeichnet.

In bereichskodierten Bitmaps setzen wir nicht nur ein bestimmtes Bit für beispielsweise den Wert 200, sondern setzen alle Bits auf 200 und höher. Das gleiche gilt für 300.
Mit dieser bereichskodierten Bitmap-Darstellung kann die Bereichsabfrage mit nur zwei Durchgängen durch die Bitmap beantwortet werden. Wir erhalten alle Hotels, die weniger als oder gleich 300 Dollar kosten, und entfernen alle Hotels, die weniger als oder gleich 199 Dollar kosten, aus dem Ergebnis. Fertig

Sie werden erstaunt sein, aber mit Bitmaps sind auch Geo-Abfragen möglich. Der Trick besteht darin, eine Darstellung wie Google S2 oder ähnliches zu verwenden, die eine Koordinate in einer geometrischen Figur einschließt, die als drei oder mehr indizierte Linien dargestellt werden kann. Wenn Sie eine solche Darstellung verwenden, können Sie die Geoabfrage als mehrere Bereichsabfragen in diesen Zeilenindizes darstellen.
Fertige Lösungen
Nun, ich hoffe, dass ich Ihr Interesse ein wenig geweckt habe. Sie haben jetzt ein weiteres Tool unter Ihrem Gürtel und wenn Sie jemals so etwas in Ihrem Service implementieren müssen, wissen Sie, wo Sie suchen müssen.
Das ist alles schön und gut, aber nicht jeder hat die Zeit, die Geduld und die Ressourcen, um den Bitmap-Index selbst zu implementieren, insbesondere wenn es um fortgeschrittenere Dinge wie SIMD-Anweisungen geht.
Fürchte dich nicht, es gibt zwei Open Source-Produkte, die dir bei deinen Bemühungen helfen können.

Brüllend
Erstens gibt es eine Bibliothek, die ich bereits erwähnt habe und die "brüllende Bitmaps" heißt. Diese Bibliothek implementiert brüllenden "Container" und alle bitweisen Operationen, die Sie benötigen würden, wenn Sie einen vollständigen Bitmap-Index implementieren würden.
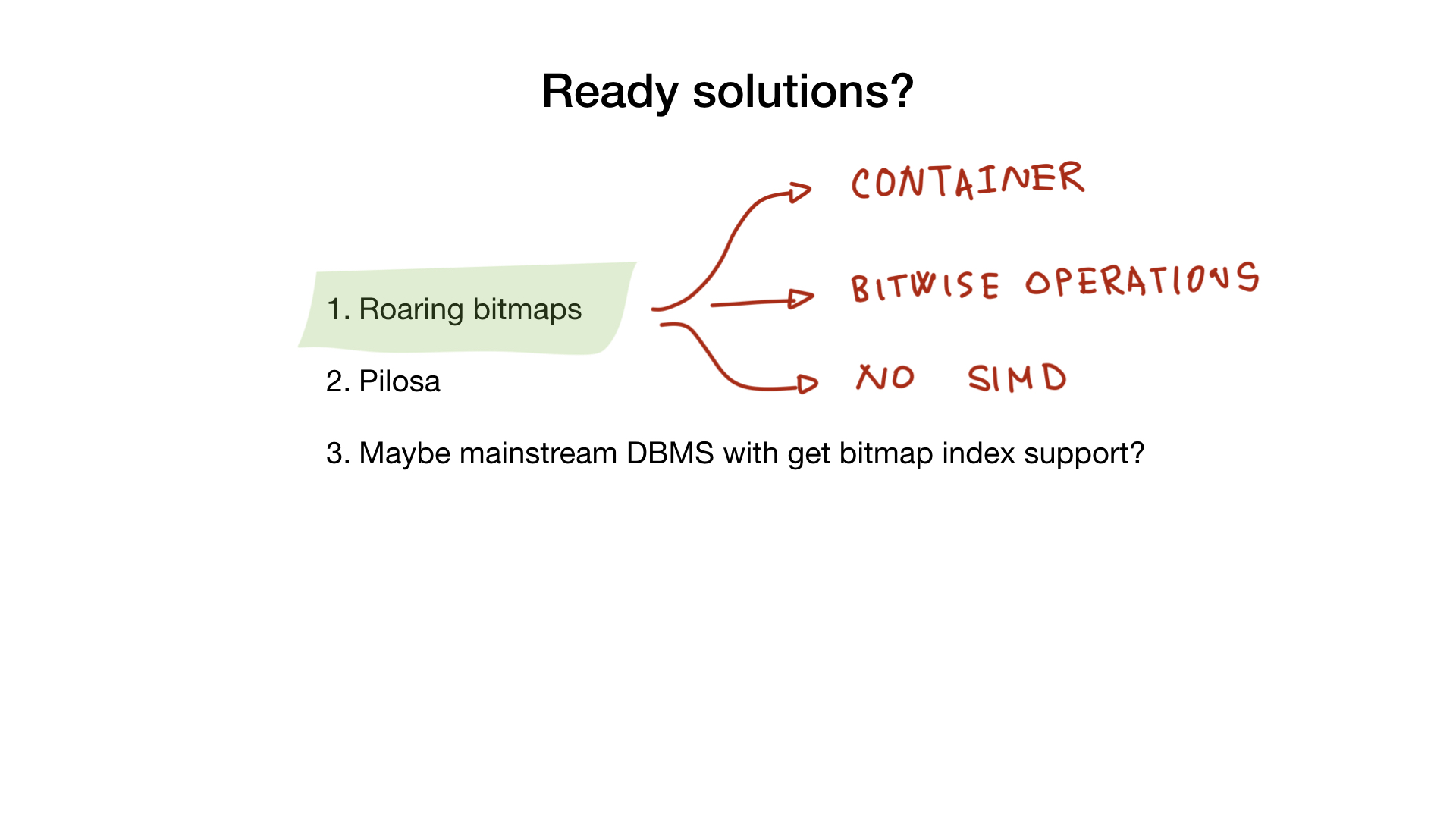
Leider verwenden Go-Implementierungen kein SIMD, sodass sie eine etwas geringere Leistung bieten als beispielsweise die C-Implementierung.
Pilosa
Ein weiteres Produkt ist ein DBMS namens Pilosa, das nur Bitmap-Indizes enthält. Es ist ein aktuelles Projekt, aber es hat in letzter Zeit viel Zugkraft gewonnen.
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0 ">
Pilosa verwendet brüllende Bitmaps darunter und gibt, vereinfacht oder erklärt fast alle Dinge, über die ich Ihnen heute erzählt habe: Binning, bereichskodierte Bitmaps, die Vorstellung von Feldern usw.
Schauen wir uns kurz ein Beispiel für Pilosa an ...

Das Beispiel, das Sie sehen, ist dem, was wir zuvor gesehen haben, sehr, sehr ähnlich. Wir erstellen einen Client für den Pilosa-Server, erstellen einen Index und Felder für unsere Merkmale. Wir füllen die Felder mit zufälligen Daten mit einigen Wahrscheinlichkeiten wie zuvor und führen dann unsere Suchabfrage aus.
Sie sehen hier das gleiche Grundmuster. NICHT teuer gekreuzt oder UND-ed mit Terrasse und gekreuzt mit Reservierungen.
Das Ergebnis ist wie erwartet.

Und schließlich hoffe ich, dass Datenbanken wie mysql und postgresql irgendwann in der Zukunft einen neuen Indextyp erhalten: den Bitmap-Index.

Schlussworte

Und wenn Sie noch wach sind, danke ich Ihnen dafür. Zeitmangel hat dazu geführt, dass ich viele Dinge in diesem Beitrag überfliegen musste, aber ich hoffe, es war nützlich und vielleicht sogar inspirierend.
Bitmap-Indizes sind eine nützliche Sache, die Sie kennen und verstehen sollten, auch wenn Sie sie gerade nicht benötigen. Behalten Sie sie als ein weiteres Werkzeug in Ihrem Portfolio.
Während meines Vortrags haben wir verschiedene Performance-Tricks gesehen, die wir anwenden können, und Dinge, mit denen Go im Moment zu kämpfen hat. Dies sind definitiv Dinge, die jeder Go-Programmierer da draußen wissen muss.
Und das ist alles, was ich jetzt für dich habe. Vielen Dank!