Teil 1 >>
Teil 2 >>
Teil 3
Einer der beliebtesten Prozessoren des letzten Jahrzehnts war der Intel Core i7-2600K. Das Design war revolutionär, da es einen signifikanten Sprung in der Leistung und Effizienz eines Single-Core-Prozessors bot und der Prozessor auch gut auf Übertaktung reagierte. Die nächsten Generationen von Intel-Prozessoren sahen nicht mehr so interessant aus und gaben den Benutzern oft keinen Grund für ein Upgrade. Daher ist der Satz "Ich werde bei meinem 2600K bleiben" in den Foren und Sounds auch heute noch allgegenwärtig. In diesem Test haben wir mit den alten Prozessoren den Staub von der Box geschüttelt und den Veteranen 2019 durch eine Reihe von Benchmarks geführt, sowohl hinsichtlich der Werksparameter als auch beim Übertakten, um sicherzustellen, dass er immer noch der Champion ist.
 Familienfoto Core i7
Familienfoto Core i7Warum der 2600K für die Generation von entscheidender Bedeutung ist
Setzen Sie sich auf einen Stuhl, lehnen Sie sich zurück und stellen Sie sich 2010 vor. In diesem Jahr haben Sie sich Ihr altes Core 2 Duo- oder Athlon II-System angesehen und festgestellt, dass es Zeit für ein Upgrade ist. Sie sind bereits mit der Architektur von Nehalem vertraut und wissen, dass der Core i7-920 gut beschleunigt und Konkurrenten Konkurrenz macht. Es war eine gute Zeit, aber plötzlich brachte Intel die Branche wieder ins Gleichgewicht und schuf ein wirklich revolutionäres Produkt. Die Echos der Nostalgie, für die noch zu hören sind.
 Core i7-2600K: die schnellste Sandy Bridge (bis zu 2700K)
Core i7-2600K: die schnellste Sandy Bridge (bis zu 2700K)Dieses neue Produkt war Sandy Bridge. AnandTech veröffentlichte eine exklusive Bewertung, und die Ergebnisse waren aus vielen Gründen kaum zu glauben. Nach unseren damaligen Tests war der Prozessor einfach unvergleichlich höher als alles, was wir zuvor gesehen haben, insbesondere angesichts der Pentium 4-Thermomonster, die einige Jahre zuvor herauskamen. Das Kern-Upgrade, das auf dem 32-nm-Prozess von Intel basiert, war der größte Wendepunkt in der x86-Leistung, und wir haben seitdem keine solchen Durchbrüche mehr gesehen. AMD wird weitere 8 Jahre brauchen, um mit der Ryzen-Serie berühmt zu werden. Intel hat es geschafft, den Erfolg seines besten Produkts zu nutzen und sich einen Championplatz zu sichern.
Bei diesem grundlegenden Design hat Intel nicht an Innovationen gespart. Eines der Schlüsselelemente war der Mikrooperations-Cache. Dies bedeutete, dass die neu decodierten Anweisungen, die erneut benötigt wurden, bereits decodiert sind, anstatt Energie beim erneuten Decodieren zu verschwenden. Für Intel mit Sandy Bridge und viel später für AMD mit Ryzen war die Aktivierung des mikrooperativen Caches ein Wunder für die Single-Threaded-Leistung. Intel hat auch begonnen, das simultane Multithreading (das seit mehreren Generationen als HyperThreading bezeichnet wird) zu verbessern und schrittweise an der dynamischen Zuweisung von Computer-Threads zu arbeiten.
Das Quad-Core-Design des besten Prozessors zum Start, des Core i7-2600K, wurde zur Grundlage für Produkte in den nächsten fünf Generationen der Intel-Architektur, darunter Ivy Bridge, Haswell, Broadwell, Skylake und Kaby Lake. Obwohl Sandy Bridge auf einen kleineren Prozess umgestellt und den geringeren Stromverbrauch genutzt hat, konnte das Unternehmen diesen außergewöhnlichen Sprung in der Nettobandbreite von Teams seit Sandy Bridge nicht mehr nachvollziehen. Später betrug das Wachstum des Jahres 1-7%, hauptsächlich aufgrund der Zunahme von Betriebspuffern, Ausführungsports und Befehlsunterstützung.
Da Intel den Durchbruch von Sandy Bridge nicht replizieren konnte und die Kernmikroarchitektur ein entscheidender Punkt für die x86-Leistung war, blieben Benutzer, die den Core i7-2600K gekauft hatten (ich kaufte zwei), lange Zeit darauf. Vor allem wegen der Erwartung eines weiteren großen Leistungssprungs. Und im Laufe der Jahre wächst ihre Frustration: Warum in einen Quad-Core-Kaby-Lake-Core i7-7700K mit einer Taktfrequenz von 4,7 GHz investieren, wenn Ihr Quad-Core-Sandy-Bridge-Core i7-2600K noch auf 5,0 GHz übertaktet ist?
(Intels Antworten beziehen sich normalerweise auf den Stromverbrauch und neue Funktionen wie GPUs und Laufwerke über PCIe 3.0. Einige Benutzer sind jedoch mit diesen Erklärungen nicht zufrieden.)
Aus diesem Grund hat der Core i7-2600K eine Generation definiert. Es blieb gültig, zunächst zur Freude von Intel und dann zur Enttäuschung, wenn Benutzer nicht aktualisieren wollten. Jetzt, im Jahr 2019, wissen wir, dass Intel die vier Kerne in seinen Hauptprozessoren bereits überschritten hat. Wenn der Benutzer für DDR4 zu teuer ist, kann er entweder auf das neue Intel-System umsteigen oder den AMD-Pfad wählen. Aber hier ist die Frage, wie der Core i7-2600K mit den Workloads und Spielen von 2019 umgeht. oder genauer gesagt, wie geht der übertaktete Core i7-2600K damit um?
Finden Sie die Unterschiede: Sandy Bridge, Kaby Lake, Coffee Lake
In Wahrheit war der Core i7-2600K nicht der schnellste Mainstream-Sandy-Bridge-Prozessor. Einige Monate später brachte Intel einen etwas höherfrequenten 2700K auf den Markt. Es funktionierte fast genauso und beschleunigte ähnlich wie 2600K, kostete aber etwas mehr. Zu diesem Zeitpunkt waren Benutzer, die einen Leistungssprung sahen und ein Upgrade durchführten, bereits bei 2600.000 und blieben dabei.
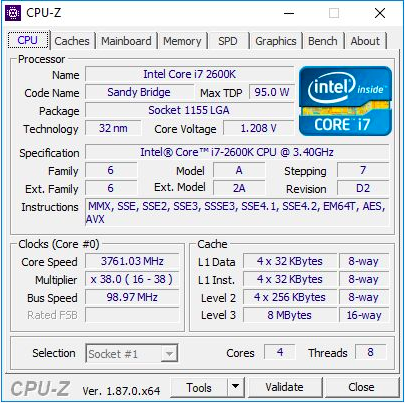
Der Core i7-2600K war ein 32-nm-Quad-Core-Prozessor mit HyperThreading-Technologie mit einer Grundfrequenz von 3,4 GHz, einer Turbofrequenz von 3,8 GHz und einer nominalen TDP von 95 Watt. Dann war Intels TDP noch nicht von der Realität getrennt: Bei unseren Tests für diesen Artikel haben wir einen Spitzenstromverbrauch von 88 W auf einer nicht getakteten CPU festgestellt. Der Prozessor wurde mit integrierter Intel HD 3000-Grafikkarte geliefert und unterstützt standardmäßig DDR3-1333-Speicher. Intel hat beim Start des Chips einen Preis von 317 US-Dollar festgelegt.
Für diesen Artikel habe ich den zweiten i7-2600K verwendet, den ich gekauft habe, als sie zum ersten Mal erschienen sind. Es wurde sowohl bei der Standardfrequenz getestet als auch auf allen Kernen auf 4,7 GHz übertaktet. Dies ist durchschnittliches Übertakten - die besten dieser Chips arbeiten im Alltagsmodus mit einer Frequenz von 5,0 GHz - 5,1 GHz. Tatsächlich erinnere ich mich gut daran, wie mein erster Core i7-2600K bei 5,1 GHz auf allen Kernen und sogar bei 5,3 GHz (auch auf allen Kernen) bei Übertaktungswettbewerben mitten im Winter bei Raumtemperatur arbeitete Bei einer Temperatur von ca. 2 ° C verwendete ich einen leistungsstarken Flüssigkeitskühler und 720-mm-Kühler. Leider habe ich diesen Chip im Laufe der Zeit beschädigt und jetzt wird er auch bei der Nennfrequenz und Spannung nicht mehr geladen. Daher sollten wir meinen zweiten Chip verwenden, der nicht so gut war, aber dennoch eine Vorstellung vom übertakteten Prozessor vermitteln konnte. Beim Übertakten haben wir auch den übertakteten Speicher DDR3-2400 C11 verwendet.
Es ist erwähnenswert, dass wir seit dem Start des Core i7-2600K von Windows 7 auf Windows 10 umgestellt haben. Der Core i7-2600K unterstützt die AVX2-Anweisungen nicht und wurde nicht für Windows 10 erstellt. Daher ist es besonders interessant zu sehen, wie dies in den Ergebnissen angezeigt wird.

 Core i7-7700K: Neuester Intel Core i7 Quad-Core-Prozessor mit HyperThreading-Technologie
Core i7-7700K: Neuester Intel Core i7 Quad-Core-Prozessor mit HyperThreading-TechnologieDer schnellste und neueste (und neueste?) Quad-Core-Prozessor mit HyperThreading, der von Intel veröffentlicht wurde, war der Core i7-7700K, ein Mitglied der Kaby Lake-Familie. Dieser Prozessor basiert auf der verbesserten 14-nm-Prozesstechnologie von Intel und läuft mit einer Grundfrequenz von 4,2 GHz und einer Turbofrequenz von 4,5 GHz. Sein TDP mit einer Nennleistung von 91 Watt in unserem Test zeigte einen Stromverbrauch von 95 Watt. Es wird mit Intel Gen9 HD 630-Grafikkarte geliefert und unterstützt Standard-DDR4-2400-Speicher. Intel hat einen Chip mit einem angegebenen Preis von 339 Dollar veröffentlicht.
Neben dem 7700K hat Intel auch seinen ersten übertakteten Dual-Core-Prozessor mit Hypertreading veröffentlicht - den Core i3-7350K. Im Verlauf dieses Tests haben wir einen solchen Core i3 übertaktet und ihn in den Werkseinstellungen mit dem Core i7-2600K verglichen, um die Frage zu beantworten, ob es Intel gelungen ist, eine Dual-Core-Prozessorleistung zu erzielen, die der ihres alten Quad-Core-Flaggschiffs ähnelt. Während sich i3 in der Single-Thread-Leistung und bei der Arbeit mit dem Speicher durchgesetzt hat, machte das Fehlen einiger Kerne im Konto die meisten Aufgaben für Core i3 zu schwierig.

 Core i7-9700K: Das neueste Top des Intel Core i7 (jetzt mit 8 Kernen)
Core i7-9700K: Das neueste Top des Intel Core i7 (jetzt mit 8 Kernen)Unser neuester Testprozessor ist der Core i7-9700K. In der aktuellen Generation ist es nicht mehr das Flaggschiff von Coffee Lake (jetzt ist es i9-9900K), aber es hat acht Kerne ohne Hypertreading. Ein Vergleich mit dem 9900K, der doppelt so viele Kerne und Threads hat, erscheint sinnlos, insbesondere wenn der Preis für i9 488 US-Dollar beträgt. Im Gegensatz dazu wird der Core i7-9700K für "nur" 374 US-Dollar mit einer Grundfrequenz von 3,6 GHz und einer Turbofrequenz von 4,9 GHz in großen Mengen verkauft. Die TDP wird von Intel mit 95 Watt definiert, aber auf dem Consumer-Motherboard verbraucht der Chip bei Volllast ~ 125 Watt. DDR4-2666-Speicher wird standardmäßig unterstützt.
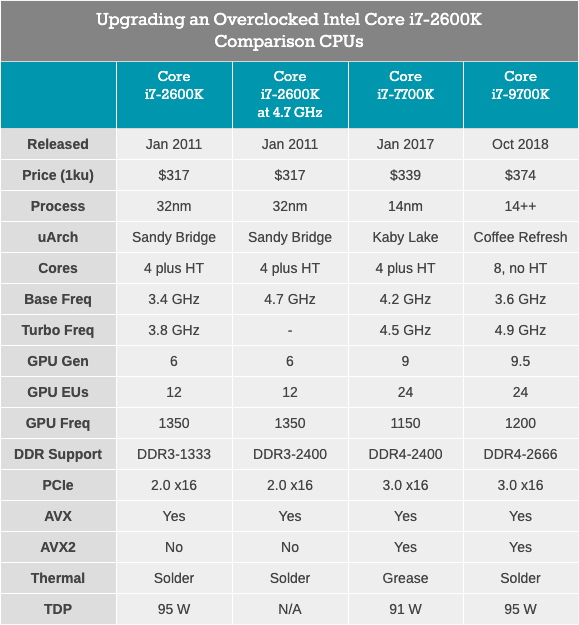
Der Core i7-2600K muss mit DDR3 arbeiten, unterstützt PCIe 2.0 und nicht PCIe 3.0 und ist nicht für die Verwendung mit NVMe-Laufwerken ausgelegt (die an diesen Tests nicht beteiligt sind). Es wird interessant sein zu sehen, wie nah der übertaktete Veteran am Core i7-7700K ist und welche Art von Wachstum wir sehen werden, wenn wir auf etwas wie den Core i7-9700K umsteigen.
Sandy Bridge: Kernarchitektur
Im Jahr 2019 handelt es sich um 100-200 mm2-Chips mit bis zu acht Hochleistungskernen, die mit der neuesten Intel-Prozesstechnologie oder AMD GlobalFoundries / TSMC erstellt wurden. Aber die 32-nm-Sandy Bridge war ein ganz anderes Tier. Der Produktionsprozess war ohne FinFET-Transistoren immer noch „flach“. In der neuen CPU wurde die zweite Generation von High-K implementiert und eine 0,7-fache Skalierung im Vergleich zur vorherigen größeren 45-nm-Prozesstechnologie erreicht. Der Core i7-2600K war der größte Quad-Core-Chip und enthielt 1,16 Milliarden Transistoren pro 216 mm2. Zum Vergleich: Der neueste Coffee Lake-Prozessor bei 14 nm verfügt über acht Kerne und mehr als 2 Milliarden Transistoren auf einer Fläche von ~ 170 mm2.
Das Geheimnis des enormen Leistungssprungs liegt in der Mikroarchitektur des Prozessors. Sandy Bridge versprach (und stellte) eine signifikante Leistung bei gleichen Taktraten im Vergleich zu Westmere-Prozessoren der vorherigen Generation sicher und bildete auch die Basisschaltung für Intel-Chips für das nächste Jahrzehnt. Mit dem Aufkommen von Sandy Bridge wurden viele wichtige Innovationen erstmals im Einzelhandel eingeführt. Anschließend wurden viele Iterationen wiederholt und verbessert, um schrittweise die heute verwendete hohe Leistung zu erzielen.
In der aktuellen Überprüfung habe ich mich stark auf Anandtechs ersten 2600K-Mikroarchitekturbericht verlassen, der 2010 veröffentlicht wurde. Natürlich mit einigen Ergänzungen, die auf einem modernen Aussehen dieses Prozessors basieren.
Kurzer Rückblick: CPU-Kern mit außergewöhnlicher Ausführung von Anweisungen
Für diejenigen, die neu im Prozessordesign sind, finden Sie hier einen kurzen Überblick über die Funktionsweise eines Prozessors mit zusätzlichem Prozessor. Kurz gesagt, der Kernel ist in externe und interne Schnittstellen (Front-End und Back-End) unterteilt, und die Daten werden zuerst an die externe Schnittstelle gesendet.
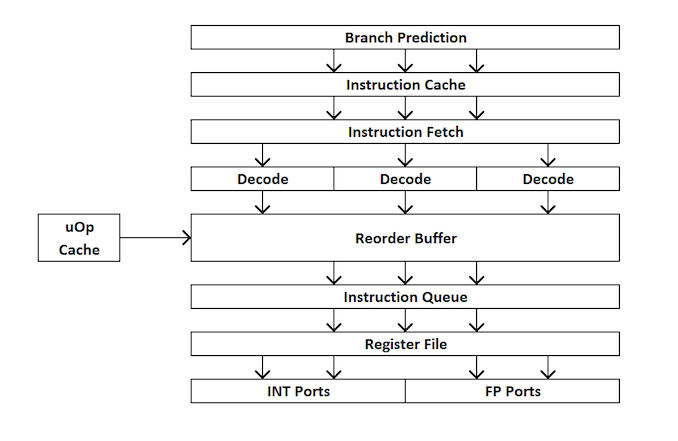
In der externen Schnittstelle haben wir Prefetchers und Branch Predictors, die Anweisungen vorhersagen und aus dem Hauptspeicher abrufen. Die Idee ist, dass Sie Zeit sparen können, wenn Sie vorhersagen können, welche Daten und Anweisungen in naher Zukunft benötigt werden (bevor sie benötigt werden), indem Sie diese Daten in der Nähe des Kernels platzieren. Dann werden die Anweisungen in einen Decoder gestellt, der die Bytecode-Anweisung in eine Reihe von "Mikrooperationen" umwandelt, die der Kernel dann verarbeiten kann.
Es gibt verschiedene Arten von Decodern für einfache und komplexe Anweisungen - einfache x86-Anweisungen können problemlos einer einzelnen Mikrooperation zugeordnet werden, während komplexere Anweisungen für mehr Operationen decodiert werden können. Die ideale Situation ist der möglichst niedrige Decodierungskoeffizient, obwohl Befehle manchmal in eine größere Anzahl von Mikrooperationen unterteilt werden können, wenn diese Operationen parallel ausgeführt werden können (Parallelität auf Befehlsebene oder ILP).
Wenn der Kernel einen Mikrooperations-Cache hat, ist er auch ein uOp-Cache, dann werden die Ergebnisse jeder decodierten Anweisung darin gespeichert. Bevor der Befehl decodiert wird, prüft der Kernel, ob dieser bestimmte Befehl kürzlich decodiert wurde, und verwendet bei Erfolg das Ergebnis aus dem Cache anstelle einer erneuten Dekodierung, die Energie verbraucht.
Jetzt stellen Mikrooperationen "Warteschlangen für die Zuweisung" - Zuordnungswarteschlange. Der moderne Kern kann bestimmen, ob Anweisungen Teil eines einfachen Zyklus sind oder ob uOps (Mikrooperationen) kombiniert werden können, um den gesamten Prozess zu beschleunigen. Dann werden uOps in den Nachbestellungspuffer eingespeist, der das „Back-End“ des Kernels bildet.
Im Backend können uOps, beginnend mit dem Neuordnungspuffer, neu angeordnet werden, je nachdem, wo sich die für jede Mikrooperation benötigten Daten befinden. Dieser Puffer kann Mikrooperationen umbenennen und verteilen, je nachdem, wohin sie gehen sollen (Integer-Operationen oder FP), und je nach Kernel kann er auch als Mechanismus zum Löschen abgeschlossener Anweisungen dienen. Nach der Nachbestellung werden die uOps-Puffer in der erforderlichen Reihenfolge an den Scheduler gesendet, um sicherzustellen, dass die Daten bereit sind, und um den Durchsatz von uOp zu maximieren.
Der Scheduler sendet nach Bedarf uOps an die Ausführungsports (zur Durchführung von Berechnungen). Einige Kernel haben einen einzigen Scheduler für alle Ports, in einigen Fällen ist er jedoch in einen Scheduler für Ganzzahl- / Vektoroperationen unterteilt. Die meisten Kernel mit außergewöhnlicher Ausführung haben 4 bis 10 Ports (einige mehr), und diese Ports führen die erforderlichen Berechnungen durch, damit der Befehl den Kernel „durchläuft“. Ausführungsports können die Form eines Lademoduls (Laden aus einem Cache), eines Speichermoduls (Speichern in einem Cache), eines Moduls für ganzzahlige mathematische Operationen, eines Moduls für mathematische Operationen mit Gleitkomma sowie von vektormathematischen Operationen, speziellen Teilungsmodulen und einigen anderen für spezielle Operationen haben . Nachdem der Ausführungsport funktioniert hat, können die Daten zur Wiederverwendung in einem Cache gespeichert und im Hauptspeicher abgelegt werden. Zu diesem Zeitpunkt wird die Anweisung an die Löschwarteschlange gesendet und schließlich gelöscht.
Diese Übersicht behandelt nicht einige der Mechanismen, die moderne Kernel verwenden, um das Caching und das Abrufen von Daten zu erleichtern, wie Transaktionspuffer, Stream-Puffer, Tagging usw. Einige Mechanismen verbessern sich iterativ mit jeder Generation, aber normalerweise, wenn wir über "Anweisungen" sprechen. pro Uhr “als Leistungsindikator bemühen wir uns, so viele Anweisungen wie möglich über den Kernel (über das Frontend und das Backend) zu„ überspringen “. Diese Anzeige hängt von der Decodierungsgeschwindigkeit am Prozessor-Frontend, den Vorabrufanweisungen, dem Nachbestellungspuffer und der maximalen Verwendung der Ausführungsports sowie der Entfernung der maximalen Anzahl ausgeführter Anweisungen für jeden Taktzyklus ab.
Auf der Grundlage des Vorstehenden hoffen wir, dass der Leser die Anandtech-Testergebnisse, die beim Start von Sandy Bridge erhalten wurden, besser verstehen kann.
Sandy Bridge: Frontend
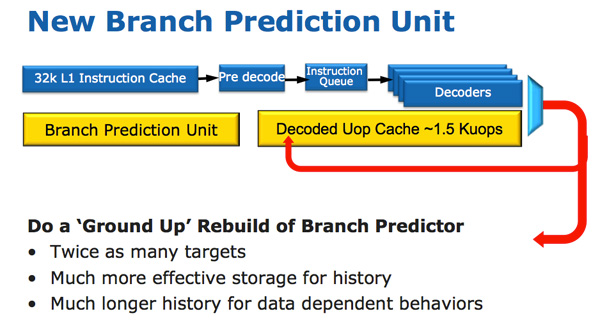
Die Sandy Bridge-CPU-Architektur sieht auf den ersten Blick evolutionär aus, ist jedoch hinsichtlich der Anzahl der Transistoren, die sich seit Nehalem / Westmere geändert haben, revolutionär. Die wichtigste Änderung für Sandy Bridge (und alle nachfolgenden Mikroarchitekturen) ist der mikrooperative Cache (uOp-Cache).

In Sandy Bridge wurde ein mikrooperativer Cache angezeigt, der Anweisungen nach dem Decodieren zwischenspeichert. Es gibt keinen komplizierten Algorithmus, dekodierte Anweisungen werden einfach gespeichert. Wenn der Prefetter Sandy Bridge einen neuen Befehl empfängt, wird der Befehl zuerst im Mikrooperations-Cache durchsucht. Wenn er gefunden wird, arbeitet der Rest der Pipeline mit dem Cache und das Frontend ist deaktiviert. Das Dekodieren von Hardware ist ein sehr komplexer Teil der x86-Pipeline, und das Ausschalten spart viel Energie.
Dies ist ein direkter Zuordnungscache, in dem ungefähr 1,5 KB Mikrooperationen gespeichert werden können, was tatsächlich einem 6-KB-Anweisungscache entspricht. Der Mikrooperations-Cache ist im L1-Befehls-Cache enthalten, und seine Trefferquote für die meisten Anwendungen erreicht 80%. Der Mikrooperations-Cache hat eine etwas höhere und stabilere Bandbreite als der Befehls-Cache. Die tatsächlichen L1-Befehls- und Datencaches haben sich nicht geändert, sie sind immer noch jeweils 32 KB groß (insgesamt 64 KB L1).
Alle Anweisungen, die vom Decoder kommen, können von diesem Mechanismus zwischengespeichert werden, und wie ich bereits sagte, gibt es einige spezielle Algorithmen - einfach alle Anweisungen werden zwischengespeichert. Lange nicht verwendete Daten werden gelöscht, wenn der Platz leer ist. Der mikrooperative Cache ähnelt möglicherweise dem Trace-Cache in Pentium 4, weist jedoch einen wesentlichen Unterschied auf: Er speichert keine Traces. Dies ist einfach ein Befehls-Cache, in dem Mikrooperationen anstelle von Makrooperationen (x86-Befehle) gespeichert werden.
Zusammen mit dem neuen mikrooperativen Cache führte Intel auch ein komplett überarbeitetes Modul zur Vorhersage von Zweigen ein. Die neue BPU ist ungefähr die gleiche wie ihre Vorgängerin, aber viel genauer. Eine höhere Genauigkeit ist das Ergebnis von drei wichtigen Innovationen.
Der Standard-Verzweigungsprädiktor ist ein 2-Bit-Prädiktor. Jeder Zweig wird in der Tabelle mit angemessener Zuverlässigkeit (stark / schwach) als akzeptiert / nicht akzeptiert markiert. Intel stellte fest, dass fast alle von diesem bimodalen Prädiktor vorhergesagten Zweige ein „hohes“ Vertrauen haben. Daher verwendet ein bimodaler Zweigprädiktor in der Sandy Bridge ein Konfidenzbit für mehrere Zweige anstelle eines Konfidenzbits für jeden Zweig. Infolgedessen enthält Ihre Zweigverlaufstabelle die gleiche Anzahl von Bits, die viel mehr Zweige darstellen, was in Zukunft zu genaueren Vorhersagen führen wird.
Sandy Bridge: in der Nähe des Kerns
Mit dem Wachstum von Multi-Core-Prozessoren ist die Verwaltung des Datenflusses zwischen Kernen und Speicher zu einem wichtigen Thema geworden. Wir haben viele verschiedene Möglichkeiten gesehen, Daten in der CPU zu verschieben, z. B. Crossbar, Ring, Mesh und später vollständig getrennte E / A-Chips. Der Kampf des nächsten Jahrzehnts (2020+), wie bereits von AnandTech erwähnt, wird ein Kampf der internuklearen Verbindungen sein, und jetzt beginnt er bereits.
Ein Merkmal von Sandy Bridge ist genau, dass es die erste Consumer-CPU von Intel war, die einen Ringbus verwendete, der alle Kerne, den Speicher, den Cache der letzten Ebene und die integrierte Grafik miteinander verband. Dies ist immer noch das gleiche Design, das wir in modernen Coffee Lake-Prozessoren sehen.
Ringreifen
Nehalem / Westmery Bridge fügt dem Chip, der sich den L3-Cache teilt, einen Grafikprozessor und eine Video-Transcodierungs-Engine hinzu. Und anstatt mehr Kabel zum L3 zu verlegen, führte Intel den Ringbus ein.
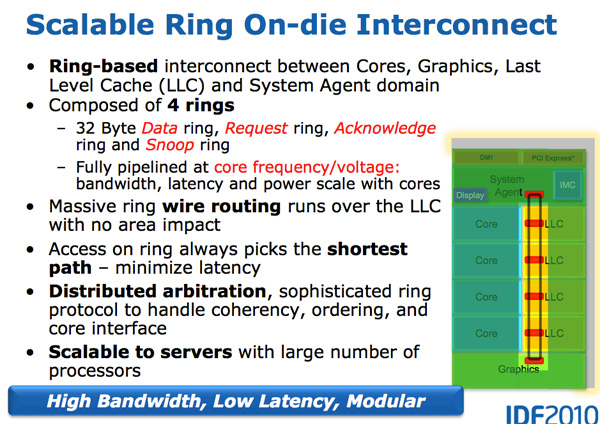
Architektonisch ist dies der gleiche Ringbus, der in Nehalem EX und Westmere EX verwendet wird. Jeder Kern, jedes Fragment des L3-Cache (LLC), der integrierte Grafikprozessor, die Medien-Engine und der Systemagent (ein lustiger Name für die Nordbrücke) sind mit dem Ringbus verbunden. : , , . 32 . .
L3, Westmere — 96 /. Sandy Bridge 4 , Westmere, , 384 /.
, L3 36 Westmere 26 — 31 Sandy Bridge ( , , ). , Westmere, - L3 — un-Core , Intel « », - L3. ( «un-Core» .)
- L3, , . , L3 , . L3, , L3 , . .
L3 , . Sandy Bridge L3, . , . Westmere , , Sandy Bridge . , . , , . , «», .
- Intel un-core SB, Sandy Bridge « ». (-, un-core , - ). . 16 PCIe 2.0, x8. DDR3, , , Lynnfield (Clarkdale ).
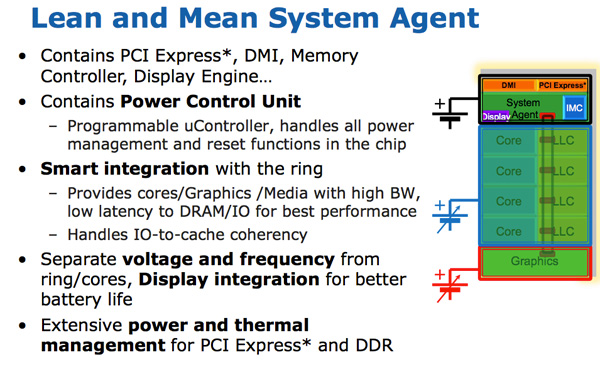
DMI, PCU ( ). SA , , .
Sandy Bridge
Sandy Bridge Westmere . 10-30%, Sandy Bridge , Intel Westmere (Clarkdale / Arrandale). 45 32 , IPC.
Sandy Bridge 32- , . . GPU . , .
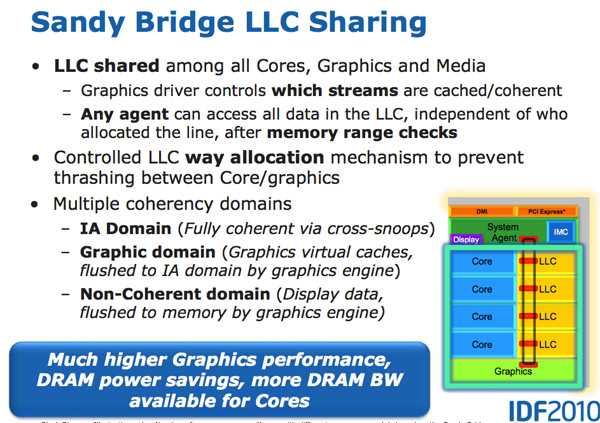
GPU Sandy Bridge, - L3. , L3, , . , , , . .
SNB ( Gen 6) . : , , . – , , .
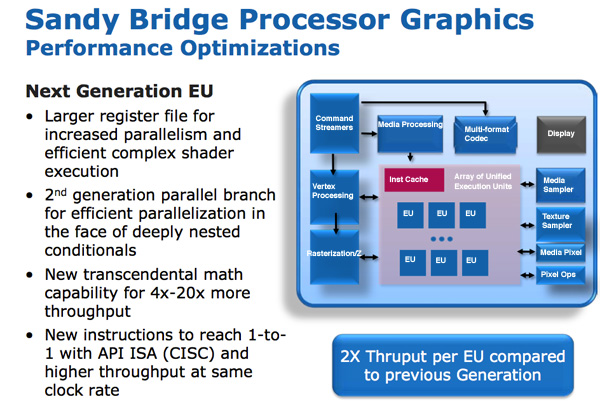
/ / (execution units), Intel EU. EU . ISA -- API DirectX 10, CISC- . - API IPC EU.
EU . EU, . Intel , , Westmere.
Intel « ». , . , , . , . Intel 64 80, , , 120 Sandy Bridge. - .

, EU.
GPU Sandy Bridge: 6 EU 12 EU. ( ) 12 EU, SKU 6 12 . Sandy Bridge Intel, , Intel , GPU. (2019 .) 24 EU (Gen 9.5), 10- ~ 64 EU (Gen11).
Sandy Bridge Media Engine
GPU Sandy Bridge -. SNB : .
: . Intel SNB, EU. Intel , SNB HD-.
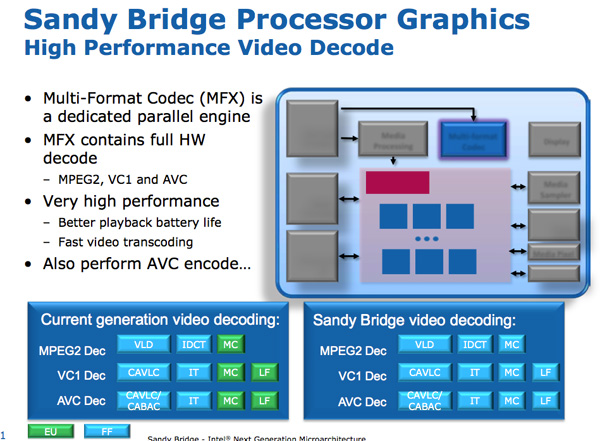
Sandy Bridge. Intel ~ 3- 1080p 30 / iPhone 640 x 360. 14 400 .
/ . Sandy Bridge 3 2 / .
,
Lynnfield Intel, . , TDP 95 , , , -.
, - . , , — , .
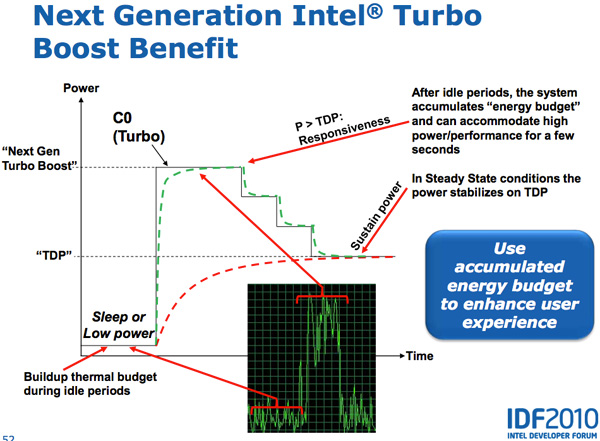
Sandy Bridge , PCU TDP ( 25 ). PCU , . , , TDP. , , TDP, , , TDP. SNB TDP, PCU .

CPU, GPU Turbo . , GPU, SNB, CPU, GPU. , CPU, GPU CPU. Sandy Bridge , , .
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?