In einer echten ML-Implementierung macht das Lernen selbst ein Viertel des Aufwands aus. Die verbleibenden drei Viertel sind Datenaufbereitung durch Schmerz und Bürokratie, eine komplexe Bereitstellung, die häufig in einem geschlossenen Kreislauf ohne Internetzugang, Einrichtung der Infrastruktur, Testen und Überwachen erfolgt. Dokumente auf Hunderten von Blättern, manueller Modus, Modellversionskonflikte, Open Source und hartes Unternehmertum - all dies erwartet einen Datenwissenschaftler. Aber er ist nicht an solchen „langweiligen“ betrieblichen Problemen interessiert, er möchte einen Algorithmus entwickeln, hohe Qualität erreichen, etwas zurückgeben und sich nicht mehr erinnern.
Vielleicht ist ML irgendwo einfacher, einfacher, schneller und mit einem Knopf implementiert, aber wir haben solche Beispiele nicht gesehen. Alles, was oben steht, ist die Erfahrung von Front Tier in den Bereichen Fintech und Telekommunikation. Sergey Vinogradov, Experte für die Architektur hoch belasteter Systeme, für große Speicher und für die Analyse schwerer Datenmengen, sprach bei
HighLoad ++ über ihn.

Modelllebenszyklus
Normalerweise besteht der Lebenszyklus in unserem Fachgebiet aus drei Teilen. Im ersten
Fall kommt eine Aufgabe aus dem Geschäft . Im zweiten
Schritt bereiten ein
Dateningenieur und / oder ein Datenwissenschaftler Daten vor und erstellen ein Modell. Im dritten Teil beginnt das
Chaos . In den letzten beiden Fällen treten unterschiedliche interessante Situationen auf.
Alleskönner
Die erste häufige Situation ist, dass ein Datenwissenschaftler oder Dateningenieur Zugriff auf die Produkte hat, und sie sagen zu ihm: "Sie haben das alles getan, Sie wetten darauf."
Eine Person nimmt ein
Jupyter-Notizbuch oder ein Bündel von Notizbüchern, betrachtet sie ausschließlich als Bereitstellungsartefakt und beginnt auf einigen Servern freudig zu replizieren.
Alles scheint in Ordnung zu sein, aber nicht immer. Ich werde dir später sagen warum.
Gnadenlose Ausbeutung
Die zweite Geschichte ist komplizierter und findet normalerweise in Unternehmen statt, in denen die Ausbeutung einen Zustand leichten Wahnsinns erreicht hat. Data Scientist bringt seine Lösung in Betrieb. Sie öffnen diese Black Box und sehen etwas Schreckliches:
- Notizbücher
- Essiggurke verschiedener Versionen;
- Haufen von Skripten: Es ist nicht klar, wo und wann sie ausgeführt werden sollen und wo die von ihnen generierten Daten gespeichert werden sollen.
In diesem Puzzle stößt die Ausnutzung auf Versionsinkompatibilität. Beispielsweise hat ein Datenwissenschaftler keine bestimmte Version der Bibliothek angegeben, und die Operation wurde spätestens ausgeführt. Nach einer Weile greift der Datenwissenschaftler zurück:
- Sie haben scikit-learn auf die falsche Version eingestellt, jetzt sind alle Metriken weg! Sie müssen auf die vorherige Version zurücksetzen.Dies bricht den Stoß vollständig und die Ausbeutung leidet.
Bürokratie
In Unternehmen mit grünen Logos erhält der Datenwissenschaftler, wenn er in Betrieb genommen wird und das Modell mitbringt, normalerweise ein 800-Blatt-Dokument als Antwort: „Befolgen Sie diese Anweisung, sonst wird Ihr Produkt nie das Licht der Welt erblicken.“
Der traurige Datenwissenschaftler geht, wirft alles auf die Hälfte und gibt dann auf - er ist nicht daran interessiert.
Bereitstellen
Angenommen, ein Datenwissenschaftler hat alle Kreise durchlaufen und am Ende wurde alles bereitgestellt. Aber er wird nicht verstehen können, dass alles so funktioniert, wie es sollte. Nach meiner Erfahrung gibt es in denselben gesegneten Banken keine Überwachung von Data-Science-Produkten.
Es ist gut, wenn der Spezialist die Ergebnisse seiner Arbeit in die Datenbank schreibt. Nach einer Weile wird er sie empfangen und sehen, was im Inneren passiert. Dies ist jedoch nicht immer der Fall. Wenn ein Unternehmen und ein Datenwissenschaftler einfach glauben, dass alles gut und gut funktioniert, führt dies zu erfolglosen Fällen.
MFI
Irgendwie haben wir eine Scoring-Engine für eine große Mikrofinanzorganisation entwickelt. Sie ließen uns nicht zum Produkt gehen, sondern nahmen uns einfach eine Kaskade von Modellen ab, installierten sie und starteten sie. Die Testergebnisse der Modelle haben sie zufriedengestellt. Aber nach 6 Monaten kamen sie zurück:
- Alles ist schlecht. Das Geschäft läuft nicht, wir werden immer schlechter. Es scheint, dass die Modelle ausgezeichnet sind, aber die Ergebnisse fallen, Betrug und Ausfall immer mehr und weniger Geld. Wofür haben wir dich bezahlt? Lass es uns richtig machen.Gleichzeitig wird wieder kein Zugriff auf das Modell gewährt. Die Protokolle wurden vor sechs Monaten für einen Monat entladen. Wir haben das Entladen für einen weiteren Monat untersucht und sind zu dem Schluss gekommen, dass die IT-Abteilung des MFI irgendwann die Eingabedaten geändert hat und anstelle von Dokumenten in JSON begonnen hat, Dokumente in XML zu senden. Das Modell erwartete json, erhielt aber XML, war traurig und dachte, dass es keine Daten an der Eingabe gab.
Wenn keine Daten vorliegen, ist die Einschätzung des Geschehens anders. Ohne Überwachung kann dies nicht erkannt werden.
Neue Version, Kaskade und Tests
Oft sind wir mit der Tatsache konfrontiert, dass das Modell gut funktioniert, aber aus irgendeinem Grund wurde eine
neue Version entwickelt. Das Modell muss wieder irgendwie hereingebracht werden und wieder durch alle Kreise der Hölle gehen. Es ist gut, wenn die Bibliotheksversionen mit denen des Vorgängermodells identisch sind. Wenn nicht, beginnt die Bereitstellung von neuem ...
Manchmal möchten wir eine neue Version
testen, bevor wir
sie in den Kampf ziehen. Legen
Sie sie auf den
Prüfstand , sehen Sie sich denselben Verkehrsstrom an und stellen Sie sicher, dass sie gut ist. Dies ist wieder die vollständige Bereitstellungskette. Darüber hinaus haben wir die Systeme so eingerichtet, dass nach diesem Modell keine realen Ergebnisse erzielt werden, wenn es um die Bewertung geht, sondern nur die Ergebnisse zur weiteren Analyse überwacht und analysiert wurden.
Es gibt Situationen, in denen eine
Modellkaskade verwendet wird. Wenn die Ergebnisse der folgenden Modelle von den vorherigen abhängen, müssen Sie irgendwie eine Interaktion zwischen ihnen herstellen und dies alles irgendwo behalten.
Wie löse ich solche Probleme?
Oft löst eine Person Probleme
manuell , insbesondere in kleinen Unternehmen. Er weiß, wie alles funktioniert, denkt an alle Versionen von Modellen und Bibliotheken, weiß, wo und welche Skripte funktionieren, welche Storefronts sie erstellen. Das ist alles wunderbar. Besonders schön sind die Geschichten, die der manuelle Modus hinterlässt.
Die Geschichte des Erbes . Ein guter Mann arbeitete in einer kleinen Bank. Einmal ging er in ein südliches Land und kehrte nicht zurück. Danach haben wir eine Vererbung erhalten: eine Reihe von Code, der Storefronts generiert, an denen Modellmodelle arbeiten. Der Code ist wunderschön, er funktioniert, aber wir kennen nicht die genaue Version des Skripts, das diese oder jene Storefront generiert. In der Schlacht sind alle Schaufenster vorhanden und alle werden gestartet. Wir haben zwei Monate lang versucht, dieses komplizierte Gewirr zu erkennen und es irgendwie zu strukturieren.
In einem harten Unternehmen wollen sich die Leute nicht mit allen Arten von Python, Jupitern usw. beschäftigen. Sie sagen:
- Kaufen wir IBM SPSS, installieren und alles wird großartig. Probleme mit der Versionierung, mit Datenquellen, mit der Bereitstellung dort irgendwie gelöst.Dieser Ansatz hat ein Existenzrecht, aber nicht jeder kann es sich leisten. In jedem Fall ist dies eine so hochwertige gezackte Nadel. Sie sitzen darauf, aber es klappt nicht, auszusteigen - Kerben. Und es kostet normalerweise viel.
Open Source ist das Gegenteil des vorherigen Ansatzes. Die Entwickler surften im Internet und fanden viele Open Source-Lösungen, die ihre Aufgaben in unterschiedlichem Maße lösen. Dies ist ein großartiger Weg, aber für uns selbst haben wir keine Lösungen gefunden, die unsere Anforderungen zu 100% erfüllen.
Deshalb haben wir uns für die klassische Option entschieden -
unsere Entscheidung . Seine Krücken, Fahrräder, alle ihre eigenen, einheimischen.
Was wollen wir von unserer Entscheidung?
Schreiben Sie nicht alles selbst . Wir möchten Komponenten, insbesondere Infrastrukturkomponenten, verwenden, die sich bewährt haben und mit der Funktionsweise in den Institutionen vertraut sind, mit denen wir zusammenarbeiten. Wir schreiben nur eine Umgebung, die die Arbeit des Datenwissenschaftlers leicht von der Arbeit von DevOps isoliert.
Verarbeiten Sie Daten in zwei Modi: sowohl im Batch-Modus - Batch als auch in Echtzeit . Unsere Aufgaben umfassen beide Betriebsarten.
Einfache Bereitstellung und in einem geschlossenen Umkreis . Bei der Arbeit mit vertraulichen privaten Daten besteht keine Internetverbindung. Zu diesem Zeitpunkt sollte alles schnell und genau zur Produktion gelangen. Aus diesem Grund haben wir uns mit Gitlab, der darin enthaltenen CI / CD-Pipeline und Docker befasst.
Ein Modell ist kein Selbstzweck. Wir lösen nicht das Problem des Modellbaus, sondern ein Geschäftsproblem.
Innerhalb der Pipeline müssen Regeln und ein Konglomerat von Modellen vorhanden sein, die die
Versionierung aller Pipelinekomponenten unterstützen.
Was ist mit Pipeline gemeint? In Russland ist das Bundesgesetz 115 zur Bekämpfung der Geldwäsche und der Finanzierung des Terrorismus in Kraft. Nur das Inhaltsverzeichnis der Empfehlungen der Zentralbank belegt 16 Bildschirme. Dies sind einfache Regeln, die eine Bank erfüllen kann, wenn sie über solche Daten verfügt, oder nicht, wenn sie keine Daten hat.
Die Bewertung eines Kreditnehmers, einer Finanztransaktion oder eines anderen Geschäftsprozesses ist ein Datenstrom, den wir verarbeiten. Ein Stream muss diese Art von Regel durchlaufen. Diese Regeln werden vom Analysten auf einfache Weise beschrieben. Er ist kein Datenwissenschaftler, kennt aber das Gesetz oder andere Anweisungen gut. Der Analyst setzt sich und beschreibt im Klartext die Überprüfung der Daten.
Erstellen Sie Kaskaden von Modellen . Oft entsteht eine Situation, in der das nächste Modell die in früheren Modellen erhaltenen Werte für seine Arbeit verwendet.
Testen Sie Hypothesen schnell. Ich wiederhole die vorherige These: Ein Datenwissenschaftler hat eine Art Modell erstellt, es dreht sich im Kampf und funktioniert gut. Aus irgendeinem Grund hat der Spezialist eine bessere Lösung gefunden, möchte aber den etablierten Workflow nicht ruinieren. Der Datenwissenschaftler hängt ein neues Modell an denselben Kampfverkehr im Kampfsystem. Sie beteiligt sich nicht direkt an der Entscheidungsfindung, sondern bedient denselben Verkehr, berücksichtigt einige Schlussfolgerungen und diese Schlussfolgerungen werden irgendwo gespeichert.
Einfache Wiederverwendungsfunktion. Viele Aufgaben haben den gleichen Komponententyp, insbesondere diejenigen, die sich auf das Extrahieren von Features oder Regeln beziehen. Wir möchten diese Komponenten in andere Pipelines ziehen.
Was hast du beschlossen zu tun?
Zuerst wollen wir überwachen. Und zwei seiner Art.
Überwachung
Technische Überwachung. Wenn Pipeline-Komponenten bereitgestellt werden, sollten sie im Betrieb sehen, was mit der Komponente passiert: wie sie Speicher, CPU und Festplatte verbraucht.
Geschäftsüberwachung. Dies ist ein Tool für Datenwissenschaftler, mit dem Sie von den technischen Nuancen der Implementierung abstrahieren können. Auf der Entwurfsebene hilft die Konstruktion dabei, zu bestimmen, welche Modellmetriken für die Überwachung verfügbar sein sollen, z. B. die Verteilung von Features oder die Bewertung von Serviceergebnissen.
Ein Datenwissenschaftler definiert Metriken und sollte sich keine Gedanken darüber machen, wie sie in das Überwachungssystem gelangen. Das einzig Wichtige ist, dass er diese Metriken und das Erscheinungsbild des Dashboards definiert hat, auf dem die Metriken angezeigt werden. Dann startete der Spezialist alles in der Produktion, setzte es ein und nach einer Weile flossen die Metriken in die Überwachung ein. Ein Datenwissenschaftler ohne Zugriff auf das Produkt kann also sehen, was im Modell geschieht.
Testen
Testen Sie die
Pipeline auf Konsistenz . Angesichts der Besonderheiten der Pipeline ist dies eine Art Rechengraph. Wir wollen verstehen, dass wir ein Diagramm implementieren, wir können es umgehen und einen Ausweg finden.
Das Diagramm enthält Komponenten - Module. Alle Module müssen den Unit- und Integrationstest bestehen. Der Prozess sollte für einen Datenwissenschaftler transparent und einfach sein.
Der Entwickler beschreibt das Modell und testet es alleine oder mit Hilfe eines anderen. Fügt alles in Gitlab ein, die durch Continuous Integration konfigurierte Pipeline wird ausgelöst, getestet und sieht Ergebnisse. Wenn alles gut ist - es geht weiter, nein - es beginnt von neuem.
Der Datenwissenschaftler konzentriert sich auf das Modell und weiß nicht, was sich unter der Haube befindet. Dafür bekommt er mehrere Dinge.
- Eine API zur Integration in den Kern des Systems selbst über den Datenbus - Nachrichtenbus. In diesem Fall muss der Spezialist beschreiben, was in seinem Modell, dem Einstiegspunkt und der Verbindung mit verschiedenen Komponenten innerhalb der Pipeline ein- und ausgeht.
- Nach dem Training des Modells wird ein Artefakt angezeigt - eine XGBoost- oder Pickle- Datei . Der Datenwissenschaftler hat einen Executer für die Arbeit mit Artefakten - er muss die Pipelinekomponenten in das System integrieren.
- Einfache und transparente API für Datenwissenschaftler zur Überwachung des Betriebs von Pipelinekomponenten - technische und geschäftliche Überwachung.
- Eine einfache und transparente Infrastruktur zur Integration in Datenquellen und zur Erhaltung der Arbeitsergebnisse.
Oft arbeiten Modelle für uns, und nach einer Weile kommt ein Audit, das die gesamte Geschichte des Dienstes auffrischen möchte. Das Audit möchte die Richtigkeit der Arbeit und die Abwesenheit von Betrug unsererseits überprüfen. Es werden einfache Tools benötigt, damit jeder Auditor, der sich mit SQL auskennt, in ein spezielles Repository gelangen und sehen kann, wie alles funktioniert, welche Entscheidungen getroffen wurden und warum.
Wir haben den Grundstein für zwei wichtige Geschichten für uns gelegt.
Customer Journey. Dies ist eine Gelegenheit, die Mechanismen zur Aufbewahrung der gesamten Kundenhistorie zu nutzen - was mit dem Kunden als Teil der Geschäftsprozesse passiert ist, die auf diesem System implementiert sind.
Möglicherweise verfügen wir über externe Datenquellen, z. B. DMP-Plattformen. Von ihnen erhalten wir Informationen über menschliches Verhalten im Netzwerk und auf mobilen Geräten. Dies kann sich auf den LTV und die Bewertungsmodelle seines Modells auswirken. Wenn der Kreditnehmer zu spät bezahlt, können wir vorhersagen, dass dies keine böswillige Absicht ist - es gibt einfach Probleme. In diesem Fall wenden wir weiche Expositionsmethoden gegenüber dem Kreditnehmer an. Wenn die Probleme behoben sind, schließt der Kunde das Darlehen. Wenn er das nächste Mal kommt, werden wir seine ganze Geschichte kennen. Datenwissenschaftler erhalten eine visuelle Historie aus dem Modell und führen die Bewertung im Lichtmodus durch.
Identifizierung von Anomalien . Wir sind ständig mit einer sehr komplexen Welt konfrontiert. Beispielsweise können Schwachstellen bei der beschleunigten Bewertung von MFIs eine Quelle für automatischen Betrug sein.
Customer Journey ist ein Konzept für den schnellen und einfachen Zugriff auf den Datenstrom, der das Modell durchläuft. Das Modell macht es einfach, Anomalien zu erkennen, die zum Zeitpunkt des Massenauftretens für Betrug charakteristisch sind.
Wie ist alles angeordnet?
Ohne zu zögern haben wir
Kafka als Message Bus Patch genommen. Dies ist eine gute Lösung, die von vielen unserer Kunden verwendet wird. Der Betrieb kann damit arbeiten.
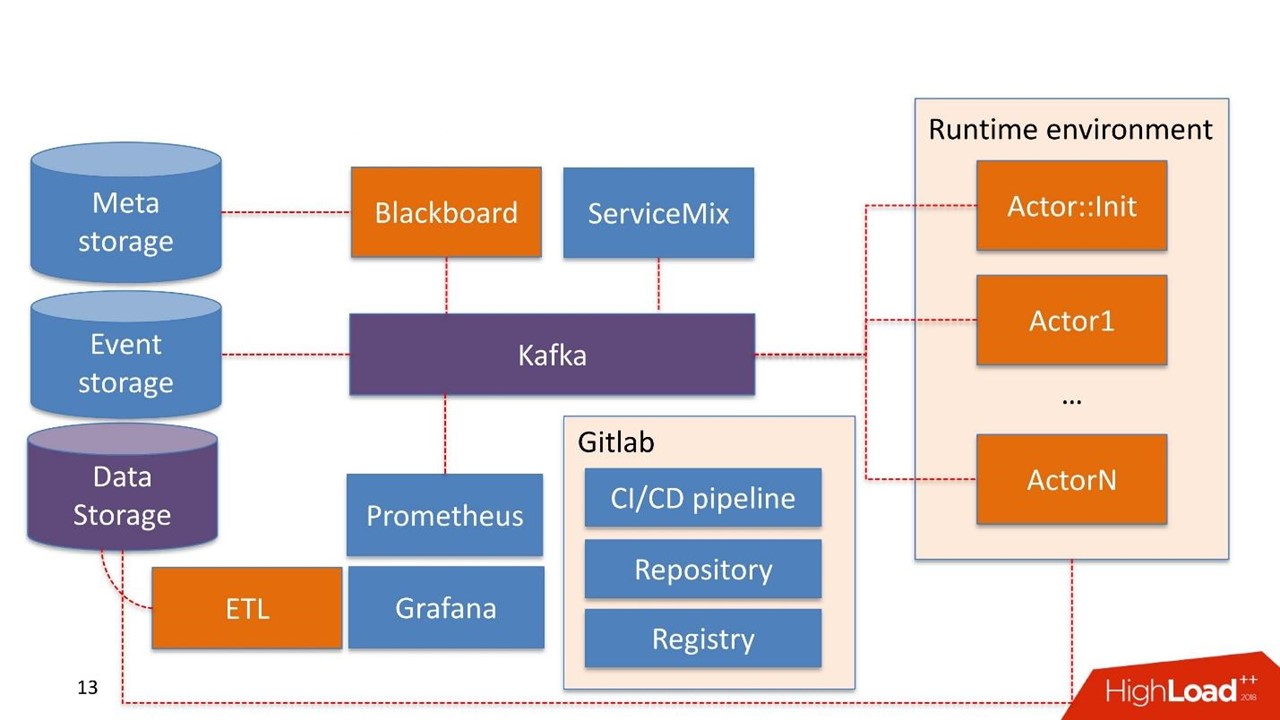
Einige Systemkomponenten werden möglicherweise bereits im Unternehmen selbst verwendet. Wir bauen das System nicht erneut auf, sondern verwenden das, was sie bereits haben.
Datenspeicherung ist in diesem Fall der Speicher, über den der Client normalerweise bereits verfügt. Dies können Hadoop-, relationale und nicht relationale Datenbanken sein. Wir können mit HDFS, Hive, Impala, Greenplum und PostgreSQL sofort arbeiten. Wir betrachten diese Speicher als Quelle für Schaufenster.
Daten kommen im Lager an, durchlaufen unsere ETL oder die ETL des Kunden, falls er eine hat. Wir bauen Schaufenster, die in Modellen weiter verwendet werden. Die Datenspeicherung wird im schreibgeschützten Modus verwendet.
Unsere Entwicklungen
Tafel Der Name stammt von einer ziemlich seltsamen Praxis von Mathematikern der 30-40er Jahre. Dies ist der Manager von Pipelines, die im Administrationssystem leben. Blackboard hat eine Art Meta-Speicher. Es speichert die Pipelines selbst und die Konfigurationen, die zum Initialisieren aller Komponenten erforderlich sind.
Alle Systemarbeiten beginnen mit der Tafel. Wie durch ein Wunder landete die Pipeline in Meta Storage, Blackboard hat dies nach einer Weile verstanden, zieht die aktuelle Version der Pipeline heraus, initialisiert sie und sendet ein Signal in Kafka.
Es gibt eine
Laufzeitumgebung . Es basiert auf Dockern und kann auf Server repliziert werden, auch in der privaten Cloud des Kunden.
Aus der Box kommt der
Hauptdarsteller :: Init - dies ist der Initialisierer. Dies ist ein Geist, der nur zwei Dinge tun kann:
Komponenten bauen und
zerstören . Er erhält einen Befehl von Blackboard: "Hier ist die Pipeline, sie muss auf solchen und solchen Servern mit solchen und solchen Ressourcen in solchen und solchen Mengen gestartet werden - Arbeit!" Dann beginnt der Schauspieler alles.
Mathematisch gesehen ist ein Akteur eine Funktion, die ein oder mehrere Objekte als Eingabe verwendet, den Status von Objekten mithilfe eines darin enthaltenen Algorithmus ändert, am Ausgang ein neues Objekt generiert oder den Status eines vorhandenen Objekts ändert.
Technisch gesehen ist ein Schauspieler ein Python-Programm. Läuft in einem Docker-Container mit seiner Umgebung.
Der Schauspieler weiß nichts über die Existenz anderer Schauspieler. Die einzige Entität, die weiß, dass zusätzlich zum Akteur die gesamte Pipeline als Ganzes existiert - dies ist Blackboard. Es überwacht den Ausführungsstatus aller Akteure innerhalb des Systems und behält den aktuellen Status bei, der sich in der Überwachung als Bild des gesamten Geschäftsprozesses als Ganzes ausdrückt.
Actor :: Init erzeugt viele Docker-Container. Darüber hinaus können Akteure mit der Datenspeicherung arbeiten.
Das System selbst verfügt über eine
Ereignisspeicherkomponente . Als Ereignisspeicher verwenden wir
ClickHouse . Die Aufgabe ist einfach: Alle Informationen, die zwischen dem Schauspieler über Kafka ausgetauscht werden, werden in ClickHouse gespeichert. Dies erfolgt
zur weiteren Prüfung . Dies ist das Pipeline-Betriebsprotokoll.
Schauspieler können auch für
Customer Journey entwickelt werden . Sie sehen Änderungen im Pipeline-Protokoll und können im laufenden Betrieb die Fenster neu erstellen, die erforderlich sind, damit Modelle oder Komponenten mit den Regeln arbeiten können, die sich bereits in der Pipeline befinden. Dies ist ein fortlaufender Prozess zum Ändern von Daten.
Die Überwachung basiert eher primitiv auf
Prometheus . Der Akteur erhält eine grundlegende API und sendet in einem geschlossenen Modus, der für den Entwickler transparent genug ist, Nachrichten mit Metriken an Kafka. Prometheus liest Metriken aus Kafka und speichert sie in seinem Repository.
Zur Visualisierung verwenden wir
Grafana .
Zwei Integrationspunkte
Der erste ist der Punkt der Integration mit Datenquellen, die über ETLs zum Data Warehouse gelangen. Der zweite Integrationspunkt, wenn ein Dienst bereits von einem Datenkonsumenten verwendet wird, z. B. ein Scoring-Dienst.
Wir haben
Apache ServiceMix genommen. Erfahrungsgemäß sind diese Integrationspunkte vom gleichen Typ mit demselben Protokolltyp: SOAP, RESTful, seltener Warteschlangen. Jedes Mal möchten wir keinen eigenen Konstruktor oder Service entwickeln, um den nächsten SOAP-Service zu generieren. Daher nehmen wir ServiceMix und beschreiben es in der SDL, in der die Datenmodelle dieses Dienstes und die darin vorhandenen Methoden erstellt werden. Dann schieben wir den Router in ServiceMix durch und er generiert den Service selbst.
Von uns selbst haben wir eine schwierige Synchron-Asynchron-Konvertierung hinzugefügt. Alle Anforderungen, die im System gespeichert sind, sind asynchron und werden über den Nachrichtenbus gesendet.
Die meisten Bewertungsdienste sind synchron. ServiceMix-Anforderungen kommen entweder über REST oder SOAP. Zu diesem Zeitpunkt durchläuft er unser Gateway, das das Wissen über die HTTP-Sitzung beibehält. Dann sendet er eine Nachricht an Kafka, sie läuft durch eine Pipeline und eine Lösung wird generiert.
Möglicherweise gibt es jedoch noch keine Lösung. Zum Beispiel ist etwas abgefallen oder es gibt eine schwierige SLA, um eine Entscheidung zu treffen, und Gateway überwacht: "OK, ich habe eine Anfrage erhalten, er ist in einem anderen Kafka-Thema zu mir gekommen, oder es ist nichts zu mir gekommen, aber mein Timeout-Auslöser hat funktioniert." Andererseits erfolgt die Konvertierung von synchron zu asynchron, und innerhalb derselben HTTP-Sitzung gibt es eine Antwort an den Verbraucher mit dem Ergebnis der Arbeit. Dies kann ein Fehler oder eine normale Prognose sein.
An diesem Ort haben wir übrigens dank der großartigen und leistungsstarken Open Source einen geschmacklosen Hund gefressen. Wir haben ServiceMix aus einer der neuesten Versionen und Kafka aus früheren Versionen verwendet und alles hat perfekt funktioniert. Wir haben in diesem Gateway geschrieben, basierend auf den Cubes, die bereits in ServiceMix enthalten waren. Als die neue Version von Kafka herauskam, haben wir sie gerne aufgenommen, aber es stellte sich heraus, dass sich die Unterstützung für die Überschriften in der zuvor existierenden Nachricht in Kafka geändert hatte. Das Gateway in ServiceMix kann nicht mehr mit ihnen arbeiten. Um dies zu verstehen, haben wir viel Zeit verbracht. Aus diesem Grund haben wir unser Gateway erstellt, das mit neuen Versionen von Kafka kompatibel ist. Wir haben den ServiceMix-Entwicklern über das Problem geschrieben und die Antwort erhalten: "Danke, wir werden Ihnen in den nächsten Versionen definitiv helfen!"
Daher sind wir gezwungen, Aktualisierungen zu überwachen und regelmäßig etwas zu ändern.
Infrastruktur ist Gitlab. Wir verwenden fast alles, was darin enthalten ist.
- Code-Repository.
- Setzt die Integration fort / setzt die Lieferpipeline fort.
- Registrierung zum Verwalten einer Registrierung von Docker-Containern.
Komponenten
Wir haben 5 Komponenten entwickelt:
- Blackboard - Pipeline-Lebenszyklusmanagement. Wo, was und mit welchen Parametern soll von der Pipeline ausgeführt werden.
- Der Feature-Extraktor funktioniert einfach - wir informieren den Feature-Extraktor darüber, dass wir an der Eingabe ein solches und ein solches Datenmodell erhalten, wählen die erforderlichen Felder aus den Daten aus und ordnen sie bestimmten Werten zu. Zum Beispiel erhalten wir das Geburtsdatum des Kunden, konvertieren es in das Alter und verwenden es als Funktion in unserem Modell. Der Feature-Extraktor ist für die Datenanreicherung verantwortlich.
- Regelbasierte Engine - Überprüfung der Daten gemäß den Regeln. Dies ist eine einfache Beschreibungssprache, mit der eine Person, die mit der Konstruktion von <code> if, else <code /> -Blöcken vertraut ist, die Regeln für die Überprüfung innerhalb des Systems beschreiben kann.
- Machine Learning Engine - Ermöglicht es Ihnen, den Executor auszuführen, das trainierte Modell zu initialisieren und es an die Eingabedaten zu senden. Am Ausgang nimmt das Modell Daten auf.
- Entscheidungsmodul - Entscheidungsmodul, Verlassen des Diagramms. Wenn Sie eine Kaskade von Modellen haben, zum Beispiel verschiedene Zweige der Kreditnehmerbewertung, müssen Sie sich irgendwo für das Thema Geld entscheiden. Das Regelwerk für die Lösung sollte einfach sein. , LTV- — , , .
. — , . — , .
pipeline .
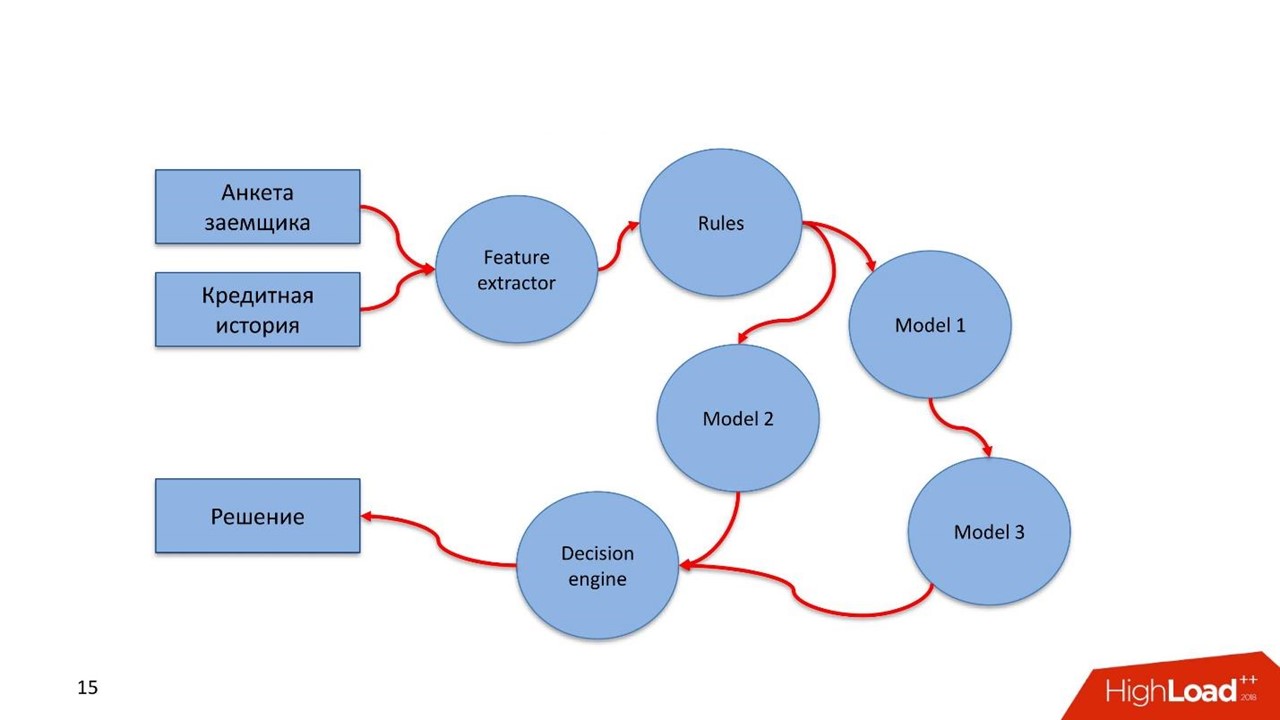
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
Pipeline
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
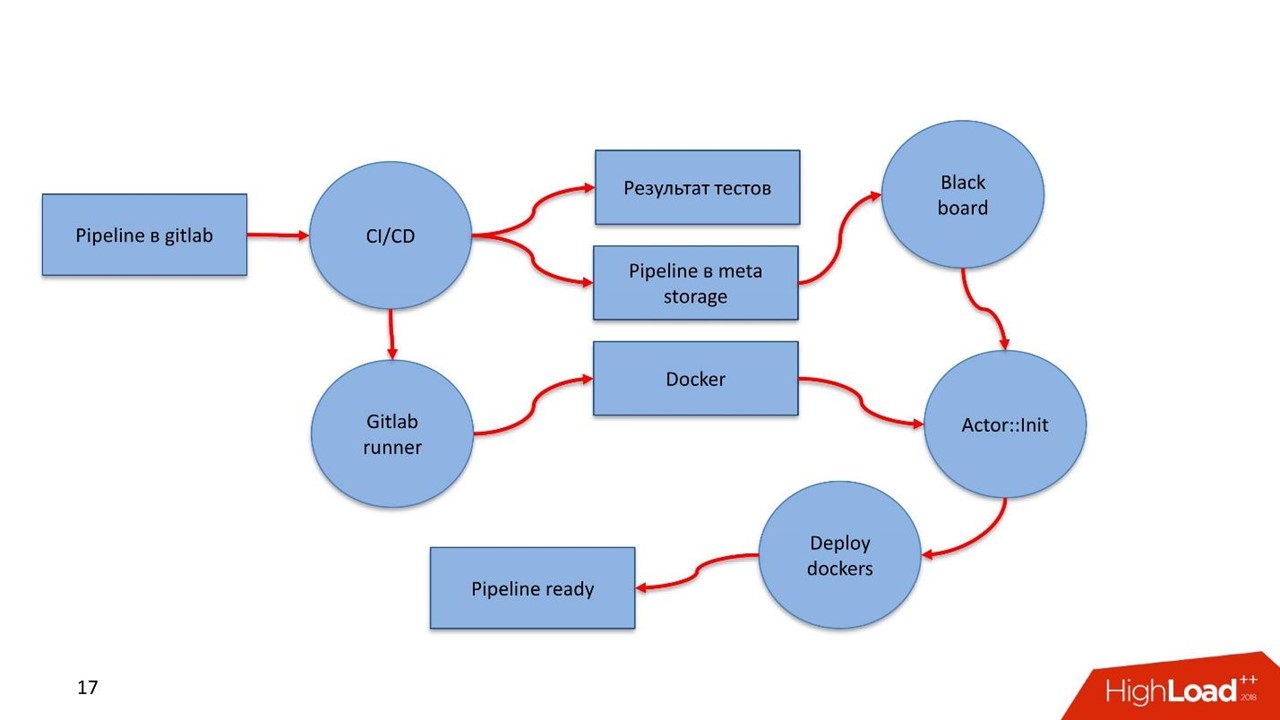
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
Was ist das Ergebnis?
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .