Je mehr Benutzer Ihres Dienstes sind, desto höher ist die Wahrscheinlichkeit, dass sie Hilfe benötigen. Der Chat des technischen Supports ist eine offensichtliche, aber recht teure Lösung. Wenn Sie jedoch Technologie für maschinelles Lernen verwenden, können Sie etwas Geld sparen.
Der Bot kann nun einfache Fragen beantworten. Darüber hinaus kann dem Chatbot beigebracht werden, die Absichten des Benutzers zu bestimmen und den Kontext zu erfassen, damit er die meisten Probleme der Benutzer ohne menschliches Eingreifen lösen kann. Wie das geht, werden Vladislav Blinov und Valery Baranova, Entwickler des beliebten Assistenten Oleg, helfen, es herauszufinden.
Beim Übergang von einfachen zu komplizierteren Methoden bei der Entwicklung eines Chat-Bots werden wir praktische Implementierungsprobleme analysieren und herausfinden, welcher Qualitätsgewinn erzielt werden kann und wie viel er kosten wird.
Vladislav Blinov ist ein leitender Entwickler von Dialogsystemen in
Tinkoff und verwendet häufig Abkürzungen: ML, NLP, DL usw. Darüber hinaus untersucht die Graduiertenschule die Modellierung von Humor durch maschinelles Lernen und neuronale Netze.
Valeria Baranova schreibt seit über 5 Jahren coole Dinge im NLP-Bereich in Python. Jetzt erstellt Tinkoff im Team interaktiver Systeme Chat-Bots und unterrichtet einen Kurs zum maschinellen Lernen für Studenten. Er forscht auch auf dem Gebiet des rechnerischen Humors, dh er lehrt die KI, Witze zu verstehen und neue zu erfinden - Valeria und Vladislav
werden darüber bei UseData Conf
sprechen .
Die Dienste der Tinkoff Bank werden von Millionen von Menschen genutzt. Um eine solche Anzahl von Benutzern rund um die Uhr zu unterstützen, wird ein großes Personal benötigt, was zu hohen Servicekosten führt. Es erscheint logisch, dass die beliebten Fragen der Benutzer mithilfe des Chat-Bots automatisch beantwortet werden können.
Benutzerabsicht oder Absicht
Das erste, was ein Chatbot braucht, ist zu verstehen,
was der Benutzer will . Diese Aufgabe wird als Klassifizierung von Absichten oder Absichten bezeichnet. Darüber hinaus werden alle Modelle und Ansätze im Rahmen dieser Aufgabe berücksichtigt.
Schauen wir uns ein Beispiel für die Klassifizierung von Absichten an. Wenn Sie schreiben: "Überweisen Sie hundert Lera", wird der Chat-Bot Oleg verstehen, dass dies die Absicht einer Geldüberweisung ist, dh die Absicht des Benutzers, Geld zu überweisen. Oder besser gesagt, dass Lera die Menge von 100 Rubel übertragen muss.
Wir werden Methoden vergleichen und die Qualität ihrer Arbeit an einem Testmuster testen, das aus echten Dialogen mit Benutzern besteht. Unsere Stichprobe enthält mehr als 30.000 markierte Beispiele und 170 Absichten, zum Beispiel: ins Kino gehen, nach Restaurants suchen, eine Kaution eröffnen oder schließen usw. Oleg hat auch seine eigene Meinung zu vielem und er kann einfach mit dir chatten.
Wörterbuchklassifikation
Das Einfachste, was bei der Klassifizierung von Absichten getan werden kann, ist die
Verwendung eines Wörterbuchs . Wenn beispielsweise das Wort "übersetzen" in der Phrase eines Benutzers vorkommt, sollten Sie eine Geldüberweisung in Betracht ziehen.
Schauen wir uns die Qualität eines so einfachen Ansatzes an.
Wenn der Klassifizierer die Absicht des Benutzers einfach als "Geldtransfer" mit dem Wort "übersetzen" definiert, ist die Qualität bereits recht hoch. Präzision - 88%, während die Vollständigkeit gering ist, entspricht nur 23%. Das ist verständlich: Das Wort „übersetzen“ beschreibt nicht alle Möglichkeiten, „Geld an jemanden überweisen“ zu sagen.
Dieser Ansatz hat jedoch Vorteile:
- Es ist keine gekennzeichnete Stichprobe erforderlich (wenn Sie das Modell nicht untersuchen, ist keine Stichprobe erforderlich).
- Sie können eine hohe Genauigkeit erzielen, wenn Sie Wörterbücher gut kompilieren (dies erfordert jedoch Zeit und Ressourcen).
Die Vollständigkeit einer solchen Lösung dürfte jedoch gering sein, da alle Variationen einer Klasse schwer zu beschreiben sind.
Betrachten Sie ein Gegenbeispiel. Wenn zusätzlich zur Geldtransferabsicht "Überweisung" auch die zweite Absicht enthalten kann - "Überweisung an den Betreiber". Wenn wir dem Operator eine neue Übersetzungsabsicht hinzufügen, erhalten wir unterschiedliche Ergebnisse.
Die Genauigkeit sinkt um 18 Punkte, während die Vollständigkeit natürlich nicht zunimmt. Dies zeigt, dass ein fortgeschrittener Ansatz erforderlich ist.
Textanalyse
Bevor Sie maschinelles Lernen verwenden, müssen Sie wissen, wie Sie Text als Vektor darstellen. Einer der einfachsten Ansätze ist die
Verwendung eines tf-idf-Vektors .
Der tf-idf-Vektor berücksichtigt das Auftreten jedes Wortes in der Phrase des Benutzers und das gesamte Auftreten von Wörtern in der Sammlung. Wörter, die häufig in verschiedenen Texten vorkommen, haben in dieser Vektordarstellung weniger Gewicht.
Betrachten wir die Qualität des linearen Modells für tf-idf-Darstellungen (in unserem Fall logistische Regression).
Infolgedessen nahm
die Vollständigkeit stark
zu , und die Genauigkeit blieb mit der Verwendung des Wörterbuchs vergleichbar. Das f1-Maß (gewichtetes harmonisches Mittel zwischen Genauigkeit und Vollständigkeit) nahm ebenfalls zu. Das heißt, das Modell selbst versteht bereits, welche Wörter für welche Absicht wichtig sind - Sie müssen selbst nichts erfinden.
Datenvisualisierung
Die Datenvisualisierung hilft zu verstehen, wie Absichten aussehen und wie gut sie im Raum gruppiert sind. Aufgrund der großen Dimension können wir tf-idf-Darstellungen jedoch nicht direkt visualisieren. Daher verwenden wir
die Dimensionskomprimierungsmethode - t-SNE .
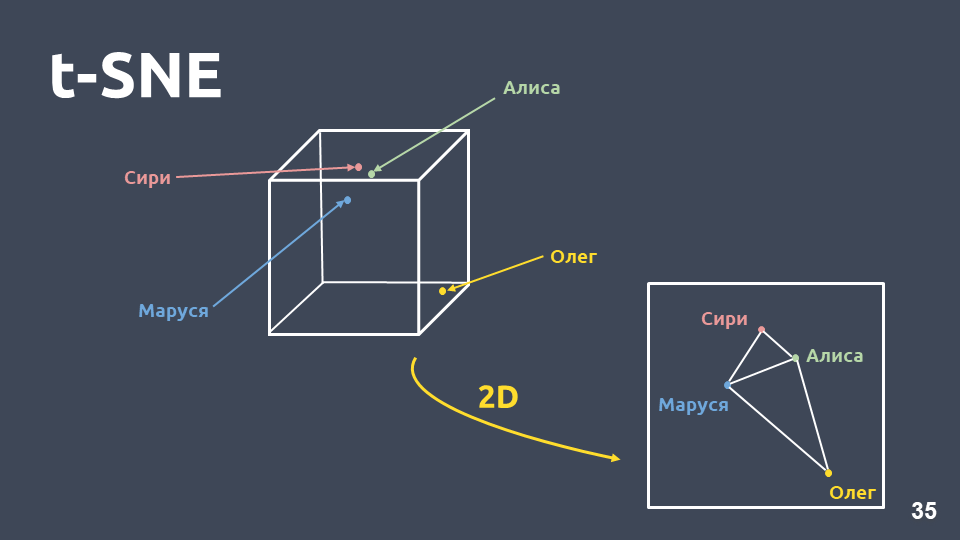
Der Hauptunterschied zwischen dieser Methode und PCA besteht darin, dass bei der Übertragung in den zweidimensionalen Raum der
relative Abstand zwischen den Objekten erhalten bleibt .
t-SNE auf tf-idf (Top 10 Absichten), F1-Punktzahl 0,92Die Top 10 Absichten nach Vorkommen in unserer Sammlung sind oben dargestellt. Es gibt grüne Punkte, die keiner Absicht angehören, und 10 Cluster, die mit unterschiedlichen Farben markiert sind, sind unterschiedliche Absichten. Es ist zu sehen, dass einige von ihnen sehr gut gruppiert sind. Das gewichtete
f1-Maß beträgt 0,92 - das ist ziemlich viel, man kann schon damit arbeiten.
Also mit einem linearen Klassifikator über tf-idf:
- viel höhere Vollständigkeit als die Verwendung eines Wörterbuchs mit vergleichbarer Genauigkeit;
- Sie müssen sich nicht überlegen, welche Wörter welcher Absicht entsprechen.
Es gibt aber auch Nachteile:
- Mit begrenztem Wortschatz können Sie nur für die Wörter Gewicht bekommen, die im Trainingsbeispiel vorhanden sind.
- Umformulierung wird nicht berücksichtigt;
- Die Reihenfolge, in der die Wörter im Text vorkommen, wird nicht berücksichtigt.
Umformulieren
Betrachten wir das Problem der Neuformulierung genauer.
Tf-idf-Vektoren können nur für Texte nahe sein, die sich in Wörtern schneiden. Die Nähe zwischen den Vektoren kann durch den Kosinus des Winkels zwischen ihnen berechnet werden. Die Kosinusnähe in der Vektordarstellung tf-idf wird für bestimmte Beispiele berechnet.
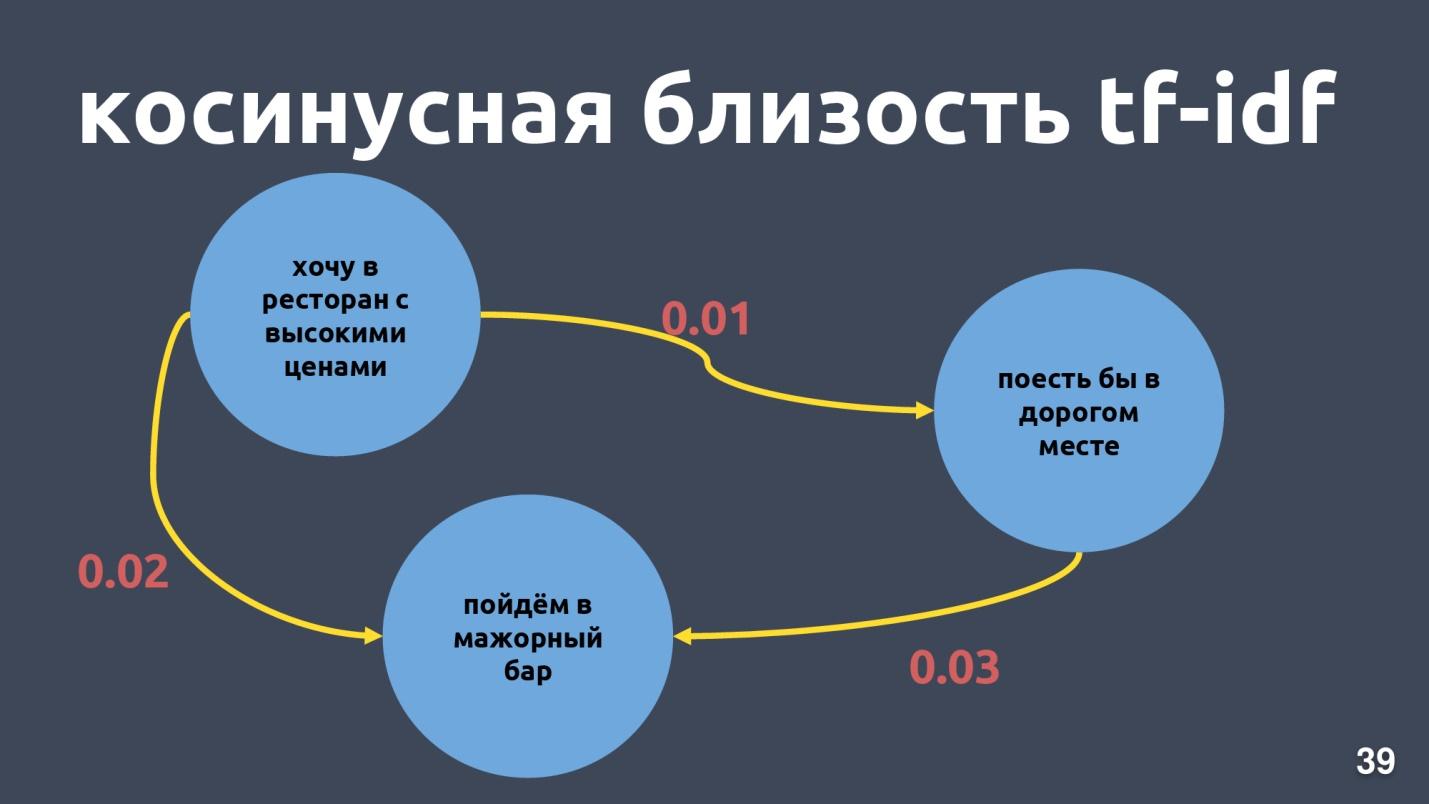
Dies sind keine sehr engen Sätze für die tf-idf-Vektordarstellung, obwohl es für uns dieselbe Absicht und dieselbe Klasse ist.
Was kann man dagegen tun? Anstelle einer Zahl können Sie beispielsweise ein Wort als ganzen Vektor darstellen - dies wird als "Worteinbettung" bezeichnet.
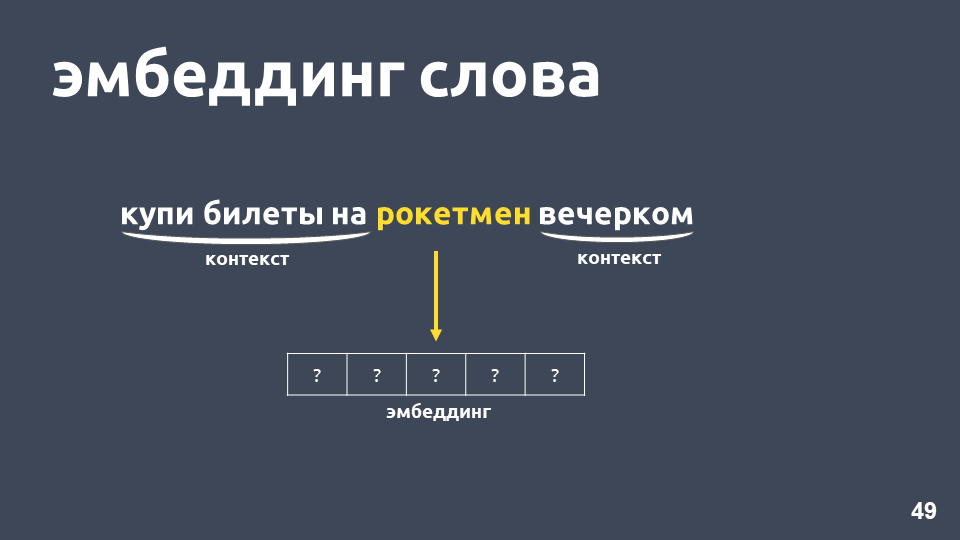
Eines der beliebtesten Modelle zur Lösung dieses Problems wurde 2013 vorgeschlagen. Es heißt
word2vec und ist seitdem weit verbreitet.
Eine der Möglichkeiten, Word2vec zu lernen, funktioniert ungefähr wie folgt: Wir nehmen den Text, nehmen ein Wort aus dem Kontext und werfen es weg, dann nehmen wir ein anderes zufälliges Wort aus dem Kontext und präsentieren beide Wörter als One-Hot-Vektoren. Ein heißer Vektor ist ein Vektor gemäß der Wörterbuchdimension, wobei nur die Koordinate, die dem Index des Wortes im Wörterbuch entspricht, den Wert 1 hat, die verbleibende 0.
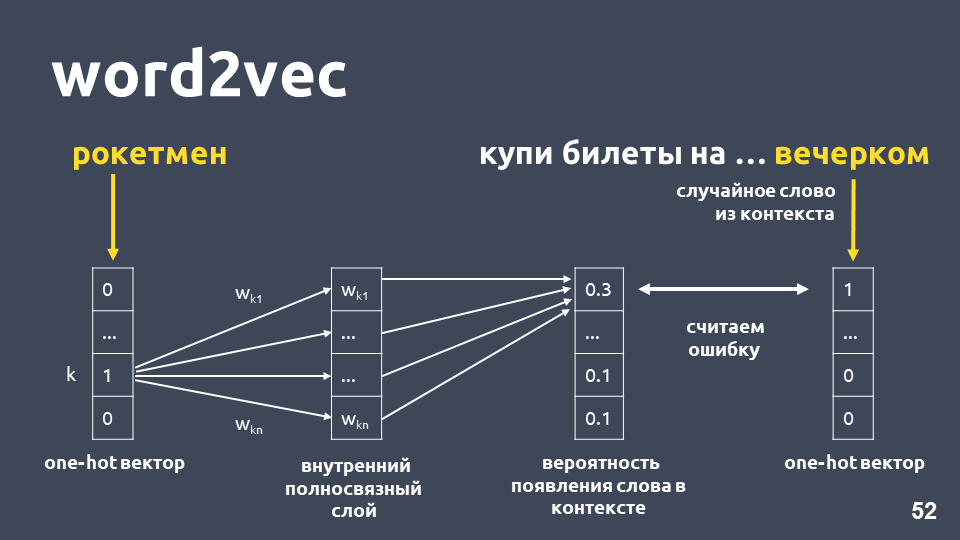
Als nächstes trainieren wir ein einfaches einschichtiges neuronales Netzwerk ohne Aktivierung auf der inneren Schicht, um das nächste Wort im Kontext vorherzusagen, dh das Wort "am Abend" unter Verwendung des Wortes "Rocketman" vorherzusagen. Am Ausgang erhalten wir die Wahrscheinlichkeitsverteilung für alle Wörter aus dem Wörterbuch wie folgt. Da wir wissen, was das Wort wirklich war, können wir den Fehler berechnen, die Gewichte aktualisieren usw.

Die aktualisierten Gewichte, die als Ergebnis des Trainings an unserer Stichprobe erhalten wurden, sind die Worteinbettung.
Der Vorteil der Verwendung der Einbettung anstelle der Zahl besteht zum einen darin,
dass der Kontext berücksichtigt wird . Ein beliebtes Beispiel: Trump und Putin stehen sich in word2vec nahe, weil sie beide Präsidenten sind und häufig zusammen in Texten verwendet werden.
Für die Wörter, die im Trainingsbeispiel gefunden wurden, nehmen Sie einfach die Einbettungsmatrix, nehmen ihren Vektor anhand des Index des Wortes und erhalten die Einbettung.
Es scheint, dass alles in Ordnung ist, außer dass einige Wörter in Ihrer Matrix möglicherweise nicht in Ordnung sind, da das Modell sie während des Trainings nicht gesehen hat. Um das Problem unbekannter Wörter (außerhalb des Wortschatzes) zu lösen, haben sie 2014 eine Modifikation von word2vec -
Fasttext entwickelt .
Fasttext funktioniert wie folgt: Wenn das Wort nicht im Wörterbuch enthalten ist, wird es in symbolische n-Gramm unterteilt. Für jede n-Gramm-Einbettung wird die Einbettungsmatrix von n-Gramm (die wie word2vec trainiert werden) entnommen, Einbettungen werden gemittelt und ein Vektor wird erhalten.
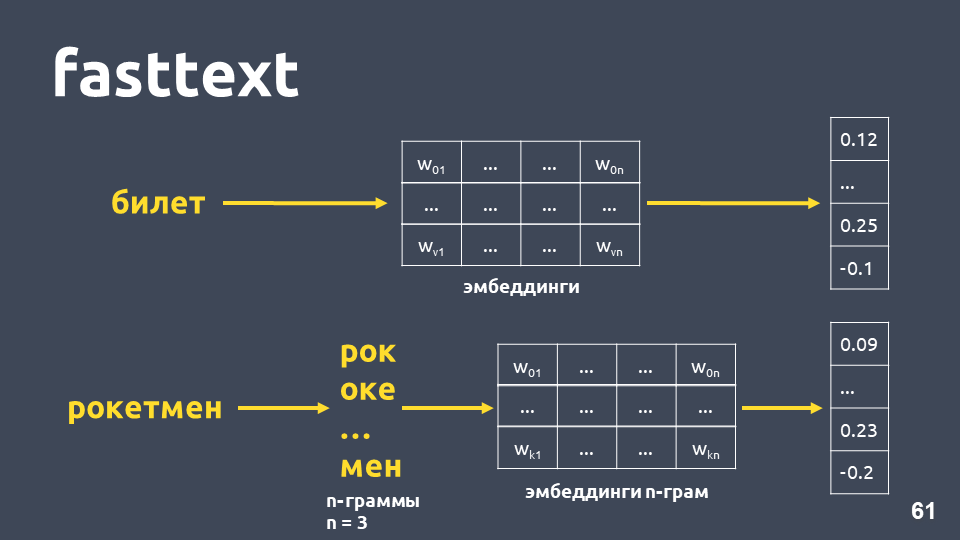
Insgesamt erhalten wir Vektoren für Wörter, die nicht in unserem Wörterbuch enthalten sind. Jetzt können wir die
Ähnlichkeit auch für unbekannte Wörter berechnen . Und vor allem gibt es geschulte Modelle für Russisch, Englisch und Chinesisch, zum Beispiel Facebook und das
DeepPavlov- Projekt, sodass Sie dies schnell in Ihre Pipeline aufnehmen können.
Die Nachteile bleiben jedoch bestehen:- Das Modell wird nicht für den gesamten Textvektor verwendet. Um einen gemeinsamen Textvektor zu erhalten, müssen Sie sich etwas überlegen: Durchschnitt oder Durchschnitt mit Multiplikation mit IDF-Gewichten, und bei verschiedenen Aufgaben kann dies auf unterschiedliche Weise funktionieren.
- Der Vektor für ein Wort ist unabhängig vom Kontext immer noch einer. Word2vec trainiert einen Wortvektor für jeden Kontext, in dem das Wort vorkommt. Für mehrwertige Wörter (wie zum Beispiel Sprache) gibt es ein und denselben Vektor.
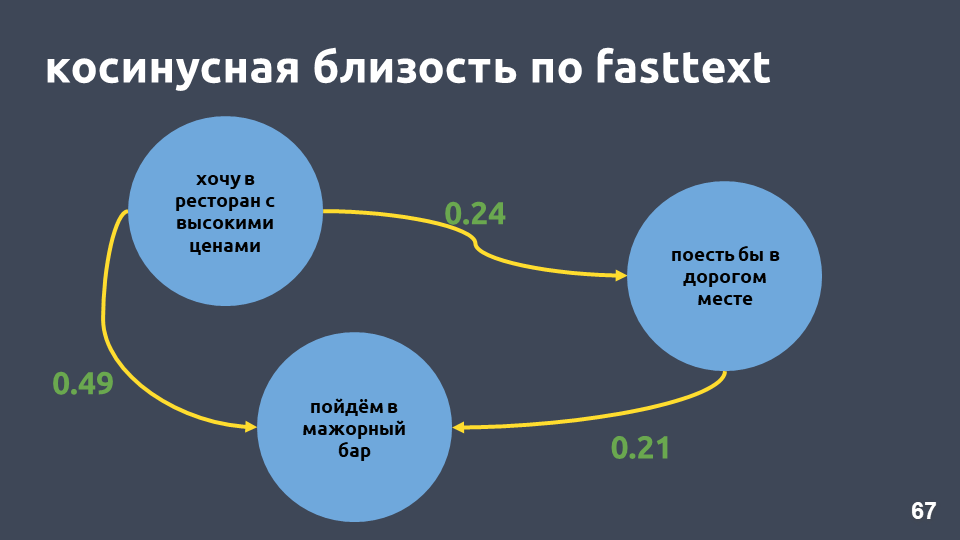
In der Tat ist die Kosinusnähe in unserem Beispiel im Fasttext höher als die Kosinusnähe in tf-idf, obwohl diese Phrasen nur „in“ gemeinsam haben.
t-SNE auf Fasttext (Top 10 Absichten), F1-Punktzahl: 0,86Bei der Visualisierung von Fasttextergebnissen bei der t-SNE-Zerlegung fallen Intent-Cluster jedoch viel schlechter auf als bei tf-idf. Das F1-Maß beträgt hier 0,86 statt 0,92.
Wir haben ein Experiment durchgeführt: kombinierte tf-idf- und Fasttext-Vektoren. Die Qualität ist absolut die gleiche wie bei Verwendung von nur tf-idf. Dies gilt nicht für alle Aufgaben. Es gibt Probleme, bei denen die Kombination aus tf-idf und Fasttext besser als nur tf-idf funktioniert oder bei denen Fasttext besser als tf-idf funktioniert. Sie müssen experimentieren und versuchen.
Versuchen wir, die Anzahl der Absichten zu erhöhen (denken Sie daran, dass wir 170 davon haben). Unten finden Sie Cluster für die 30 wichtigsten Absichten für tf-idf-Vektoren.
t-SNE bei tf-idf (Top 30 Absichten), F1 Punktzahl 0, 85 (bei 10 war es 0,92)Die Qualität sinkt um 7 Punkte, und jetzt sehen wir keine ausgeprägte Clusterstruktur.
Schauen wir uns Beispiele für Texte an, die verwirrt wurden, weil mehr Absichten hinzugefügt wurden, die sich semantisch und in Worten überschneiden.
Zum Beispiel: "Und wenn Sie eine Einzahlung eröffnen, wie hoch sind die Zinsen dafür?" und "Und ich möchte einen Beitrag bei 7 Prozent eröffnen." Sehr ähnliche Sätze, aber das sind unterschiedliche Absichten. Im ersten Fall möchte eine Person die Bedingungen für Einzahlungen kennen und im zweiten Fall eine Einzahlung eröffnen. Um solche Texte in verschiedene Klassen zu unterteilen, brauchen wir etwas Komplexeres -
tiefes Lernen .
Sprachmodell
Wir wollen einen Textvektor und insbesondere einen Wortvektor erhalten, der vom Verwendungskontext abhängt. Der Standardweg, um einen solchen Vektor zu erhalten, besteht darin
, Einbettungen aus dem Sprachmodell zu verwenden .
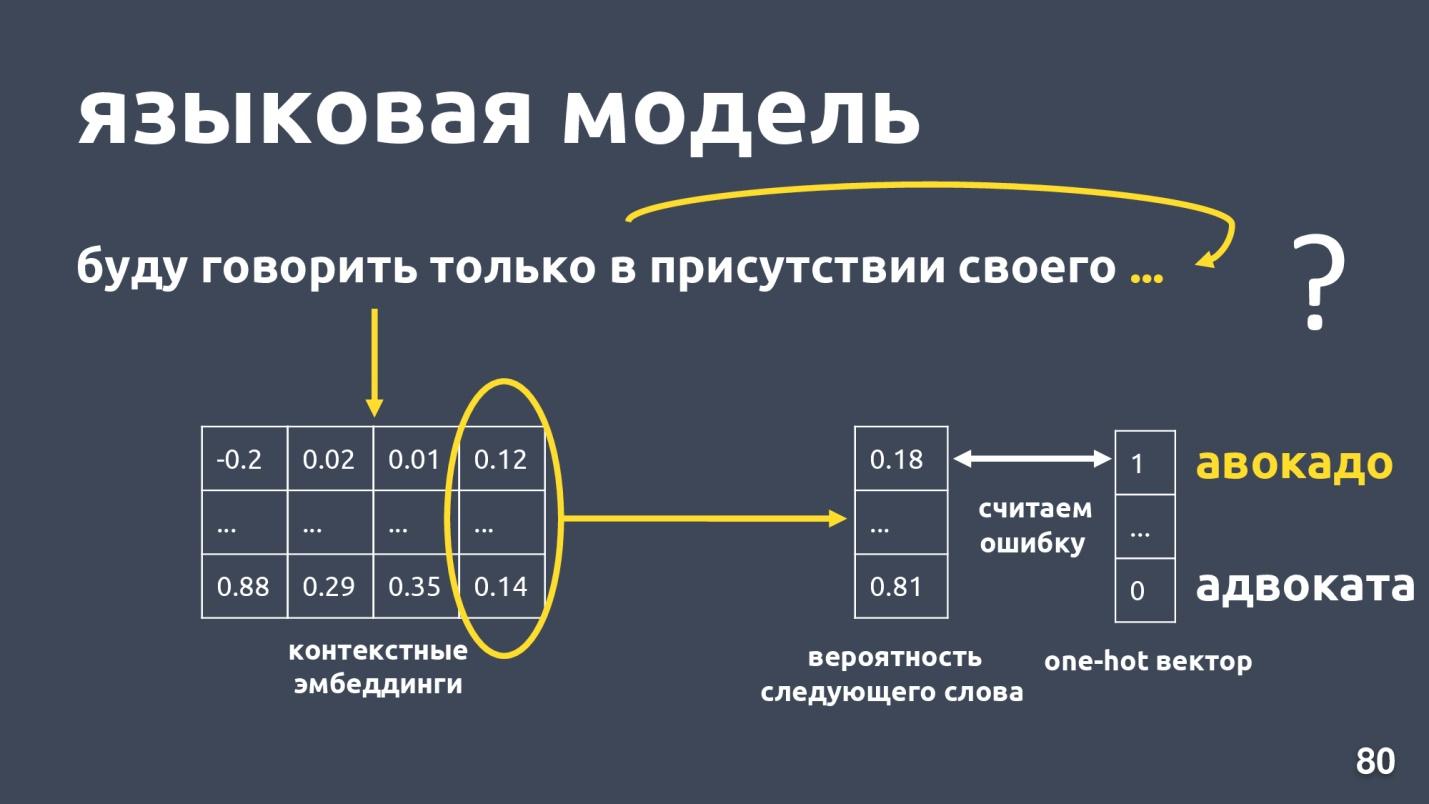
Das Sprachmodell löst das Problem der Sprachmodellierung. Und was ist diese Aufgabe? Lassen Sie es eine Folge von Wörtern geben, zum Beispiel: "Ich werde nur in Gegenwart meiner eigenen sprechen ...", und wir versuchen, das nächste Wort in der Folge vorherzusagen. Das Sprachmodell bietet Kontext für Einbettungen. Nachdem man für jedes Wort kontextbezogene Einbettungen und Vektoren erhalten hat, kann man die Wahrscheinlichkeit des nächsten Wortes vorhersagen.
Es gibt einen Wörterbuch-Dimensionsvektor, und jedem Wort wird die Wahrscheinlichkeit zugewiesen, dass es das nächste ist. Wir wissen wieder, welches Wort in Wirklichkeit war, betrachten einen Fehler und trainieren das Modell.
Es gibt einige Sprachmodelle. Gab es letztes Jahr einen Boom? und viele verschiedene Architekturen wurden vorgeschlagen. Einer von ihnen ist
ELMo .
ELMo
Die Idee des ELMo-Modells besteht darin , zunächst für jedes Wort im Text eine symbolische
Worteinbettung zu erstellen und dann ein
LSTM-Netzwerk für diese Wörter so anzuwenden, dass Einbettungen berücksichtigt werden, die den Kontext berücksichtigen, in dem das Wort vorkommt.
Lassen Sie uns untersuchen, wie eine symbolische Einbettung erhalten wird: Wir teilen das Wort in Symbole auf, wenden für jedes Symbol eine Einbettungsebene an und erhalten eine Einbettungsmatrix. Wenn es nur um Symbole geht, ist die Dimension einer solchen Matrix klein. Dann wird eine eindimensionale Faltung auf die Einbettungsmatrix angewendet, wie dies normalerweise in NLP durchgeführt wird, wobei am Ende eine maximale Poolbildung erfolgt und ein Vektor erhalten wird. Auf diesen Vektor wird ein zweischichtiges sogenanntes
Autobahnnetz angewendet, das den
allgemeinen Vektor eines Wortes berechnet.
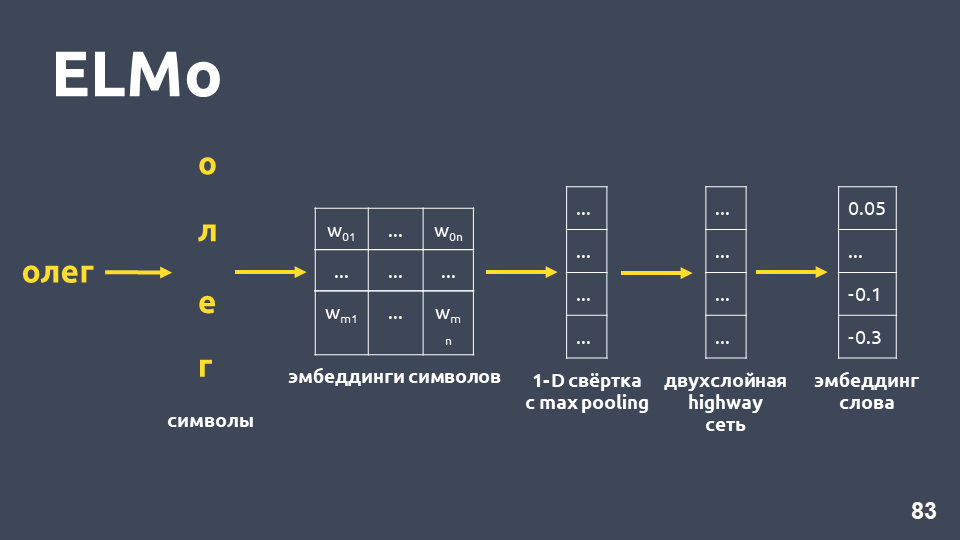
Darüber hinaus wird das Modell eine Art Hypothese der Einbettung selbst für ein Wort erstellen, das nicht im Trainingssatz gefunden wurde.
Nachdem wir für jedes Wort symbolische Einbettungen erhalten haben, wenden wir ein zweischichtiges BiLSTM-Netzwerk auf sie an.
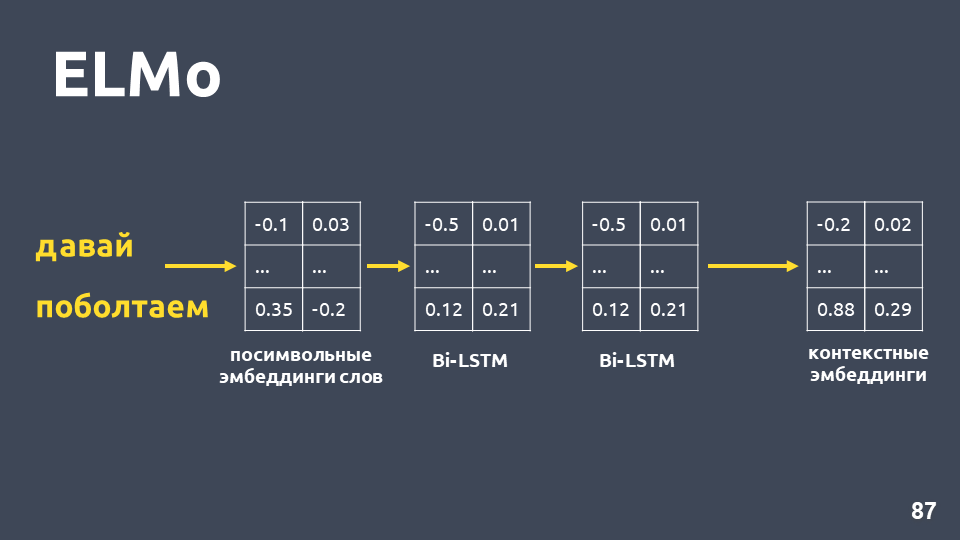
Nach dem Anwenden eines zweischichtigen BiLSTM-Netzwerks werden normalerweise die verborgenen Zustände der letzten Schicht genommen, und es wird angenommen, dass dies eine kontextbezogene Einbettung ist. ELMo bietet jedoch zwei Funktionen:
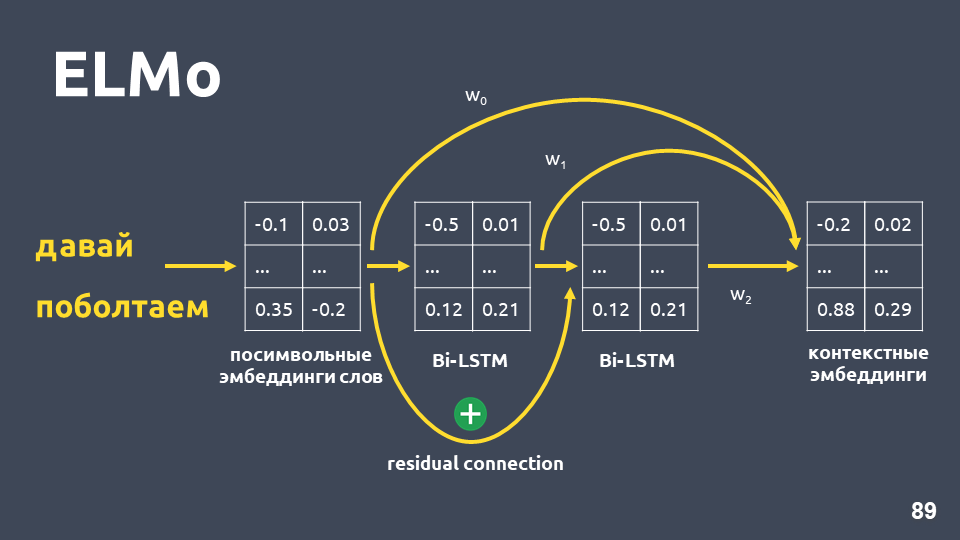
- Restverbindung zwischen dem Eingang der ersten LSTM-Schicht und ihrem Ausgang. Der LSTM-Eingang wird dem Ausgang hinzugefügt, um das Problem von Fading-Verläufen zu vermeiden.
- Die Autoren von ELMo schlagen vor, die symbolische Einbettung für jedes Wort, die Ausgabe der ersten LSTM-Schicht und die Ausgabe der zweiten LSTM-Schicht mit einigen Gewichten zu kombinieren, die für jede Aufgabe ausgewählt werden. Dies ist erforderlich, um sowohl Funktionen auf niedriger Ebene als auch Funktionen auf höherer Ebene zu berücksichtigen, die die erste und zweite Schicht von LSTM ergeben.
In unserem Problem haben wir eine einfache Mittelung dieser drei Einbettungen verwendet und so für jedes Wort eine kontextbezogene Einbettung erhalten.
Das Sprachmodell bietet folgende Vorteile:
- Der Vektor eines Wortes hängt vom Kontext ab, in dem das Wort verwendet wird. Das heißt, für das Wort "Sprache" im Sinne des Körperteils und des sprachlichen Begriffs erhalten wir unterschiedliche Vektoren.
- Wie bei word2vec und fasttext gibt es viele trainierte Modelle, zum Beispiel aus dem DeepPavlov- Projekt. Sie können das fertige Modell nehmen und versuchen, es in Ihrer Aufgabe anzuwenden.
- Sie müssen nicht mehr darüber nachdenken, wie die Wortvektoren gemittelt werden. Das ELMo-Modell erzeugt sofort einen Vektor des gesamten Textes.
- Sie können das Sprachmodell für Ihre Aufgabe neu trainieren. Hierfür gibt es verschiedene Möglichkeiten, z. B. ULMFiT.
Das einzige Minus bleibt - das
Sprachmodell garantiert nicht, dass Texte, die zur selben Klasse gehören, dh zu einer Absicht, im Vektorraum nahe beieinander liegen.
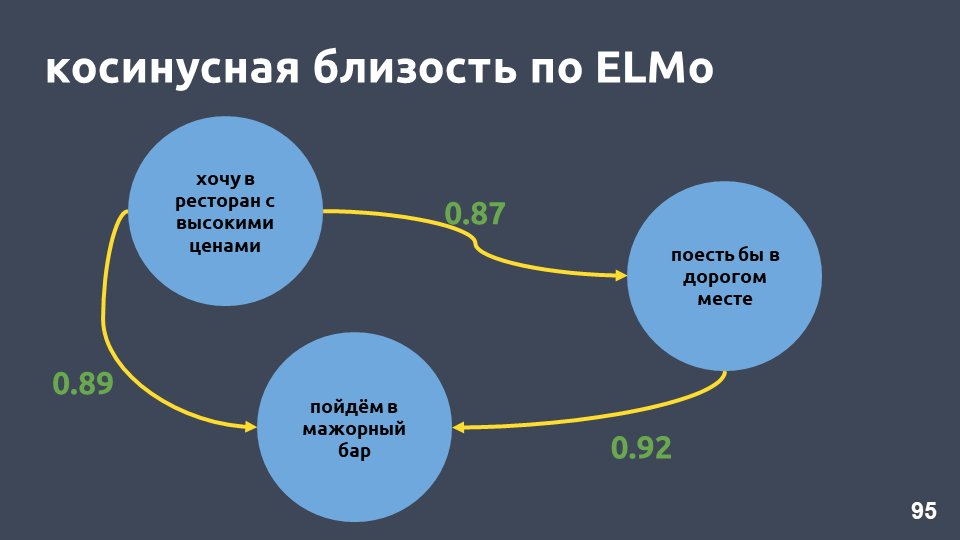
In unserem Restaurantbeispiel sind die Kosinuswerte nach dem ELMo-Modell wirklich höher geworden.
t-SNE auf ELMo (Top 10 Absichten), F1-Punktzahl 0,93 (0,92 von tf-idf)Cluster mit Top-10-Absichten sind ebenfalls ausgeprägter. In der obigen Abbildung sind alle 10 Cluster deutlich sichtbar, während die Genauigkeit leicht zugenommen hat.
t-SNE auf ELMo (Top 30 Absichten) F1-Punktzahl 0,86 (0,85 von tf-idf)Bei den Top-30-Absichten bleibt die Clusterstruktur erhalten, und die Qualität steigt um einen Punkt.
Aber in einem solchen Modell gibt es keine Garantie dafür, dass die Vorschläge "Und wenn Sie eine Einzahlung eröffnen, was sind die Zinsen auf sie?" und "Und ich möchte einen Beitrag bei 7 Prozent eröffnen" wird weit voneinander entfernt sein, obwohl sie in verschiedenen Klassen liegen. Mit ELMo lernen wir einfach das Sprachmodell, und wenn die semantisch ähnlichen Texte, dann sind sie nah.
ELMo weiß nichts über unsere Klassen , aber Sie können
Textvektoren mit derselben Absicht im Raum mithilfe von Klassenbeschriftungen zusammenführen.
Siamesisches Netzwerk
Nehmen Sie Ihre bevorzugte neuronale Netzwerkarchitektur für die Textvektorisierung und zwei Beispiele für Absichten. Für jedes der Beispiele erhalten wir Einbettungen und berechnen dann den Kosinusabstand zwischen ihnen.
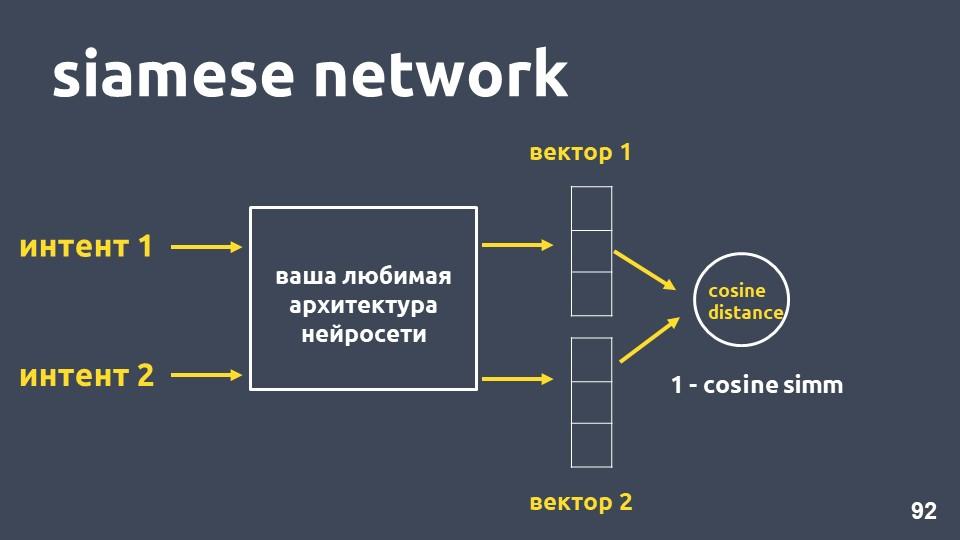
Der Kosinusabstand ist gleich eins minus der Kosinusnähe, die wir zuvor getroffen haben.
Dieser Ansatz wird als
siamesisches Netzwerk bezeichnet .
Wir möchten, dass Texte aus derselben Klasse, zum Beispiel „Überweisung machen“ und „Geld werfen“, dicht im Raum liegen. Das heißt, der Kosinusabstand zwischen ihren Vektoren sollte so klein wie möglich sein, idealerweise Null. Und Texte, die sich auf unterschiedliche Absichten beziehen, sollten so weit wie möglich voneinander entfernt sein.
In der Praxis funktioniert diese Trainingsmethode jedoch nicht so gut, da Objekte verschiedener Klassen nicht ausreichend voneinander entfernt sind. Die Verlustfunktion
"Triplettverlust" funktioniert viel besser. Es werden Tripel von Objekten verwendet, die als Drillinge bezeichnet werden.
Die Abbildung zeigt ein Triplett: ein Ankerobjekt in einem blauen Kreis, ein positives Objekt in Grün und ein negatives Objekt in einem roten Kreis. Das negative Objekt und der Anker befinden sich in verschiedenen Klassen, und das positive und der Anker befinden sich in einer.

Wir wollen sicherstellen, dass das positive Objekt nach dem Training näher am Anker liegt als das negative. Dazu betrachten wir den Kosinusabstand zwischen den Objektpaaren und geben den Hyperparameter - "Rand" - den Abstand ein, den wir zwischen den positiven und negativen Objekten erwarten.

Die Verlustfunktion sieht folgendermaßen aus:
Mit anderen Worten, während des Trainings erreichen wir, dass das positive Objekt näher am Anker liegt als das negative, zumindest am Rand. Wenn die Verlustfunktion Null ist, funktioniert sie und wir beenden das Training, andernfalls minimieren wir weiterhin die Zielfunktion.
Nachdem wir das Modell trainiert haben, erhalten wir immer noch keinen Klassifikator. Es ist nur eine Methode, um solche Einbettungen zu erhalten, dass Objekte, die in einer Absicht liegen, höchstwahrscheinlich enge Vektoren haben.
Wenn wir das Modell erhalten haben, können wir zusätzlich zu den Einbettungen eine andere Klassifizierungsmethode verwenden.
KNN passt gut, da wir bereits festgestellt haben, dass Einbettungen eine unterschiedliche Clusterstruktur aufweisen.
Erinnern Sie sich daran, wie kNN für Texte funktioniert: Nehmen Sie ein Element des Textes, binden Sie es ein, übersetzen Sie es in den Vektorraum und sehen Sie dann, wer sein Nachbar ist. Unter den Nachbarn betrachten wir die häufigste Klasse und schließen daraus, dass das neue Objekt zu dieser Klasse gehört.
Die Dimension der von uns verwendeten Einbettungen beträgt 300, und im Trainingsbeispiel befinden sich etwa 500.000 Objekte. Standardmethoden zur Suche nach den nächsten Nachbarn passen in Bezug auf die Leistung nicht zu uns. Wir haben die
HNSW- Methode verwendet -
Hierarchical Navigable Small World .
Navigable Small World ist ein zusammenhängendes Diagramm, in dem nur wenige Kanten zwischen Scheitelpunkten in großer Entfernung und viele Kanten zwischen Scheitelpunkten in der Nähe vorhanden sind. In unserem Fall wird die Kantenlänge durch den Kosinusabstand bestimmt, d.h. Für ein Trainingsbeispiel berechnen wir den Abstand zwischen allen Beispielen von Absichten und werfen dann zufällig sehr große Entfernungen aus, damit der Graph weiterhin verbunden bleibt.
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
Nützliche Links:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .