In jüngster Zeit haben FPGA-Hersteller und Drittunternehmen aktiv Entwicklungsmethoden für FPGAs entwickelt, die sich von herkömmlichen Ansätzen unter Verwendung von Entwicklungswerkzeugen auf hoher Ebene unterscheiden.
Als FPGA-Entwickler verwende ich die Hardwarebeschreibungssprache (
HDL ) von Verilog als Hauptwerkzeug, aber die wachsende Beliebtheit neuer Methoden hat mein großes Interesse geweckt. Deshalb habe ich mich in diesem Artikel entschlossen, herauszufinden, was passiert.
Dieser Artikel ist keine Anleitung oder Gebrauchsanweisung. Dies ist mein Rückblick und meine Schlussfolgerungen darüber, was verschiedene Entwicklungswerkzeuge auf hoher Ebene einem FPGA-Entwickler oder Programmierer bieten können, der in die Welt des FPGA eintauchen möchte. Um die meiner Meinung nach interessantesten Entwicklungswerkzeuge zu vergleichen, habe ich mehrere Tests geschrieben und die Ergebnisse analysiert. Unter dem Schnitt - was kam daraus.
Warum benötigen Sie hochwertige Entwicklungswerkzeuge für FPGA?
- Beschleunigen Sie die Projektentwicklung
- aufgrund der Wiederverwendung von Code, der bereits in Hochsprachen geschrieben wurde;
- durch die Nutzung aller Vorteile von Hochsprachen beim Schreiben von Code von Grund auf neu;
- durch Reduzierung der Kompilierungszeit und der Codeüberprüfung.
- Möglichkeit, universellen Code zu erstellen, der für jede FPGA-Familie geeignet ist.
- Reduzieren Sie beispielsweise den Entwicklungsschwellenwert für FPGAs, indem Sie die Konzepte der „Taktfrequenz“ und anderer Entitäten auf niedriger Ebene vermeiden. Möglichkeit, Code für FPGA an einen Entwickler zu schreiben, der mit HDL nicht vertraut ist.
Woher kommen die hochrangigen Entwicklungswerkzeuge?
Jetzt sind viele von der Idee einer hochrangigen Entwicklung angezogen. Sowohl Enthusiasten wie beispielsweise
Quokka und
der Python-Codegenerator als auch Unternehmen wie
Mathworks und die FPGA-Hersteller
Intel und
Xilinx sind daran beteiligt.
Jeder nutzt seine Methoden und Werkzeuge, um sein Ziel zu erreichen. Enthusiasten im Kampf um eine perfekte und schöne Welt verwenden ihre bevorzugten Entwicklungssprachen wie Python oder C #. Unternehmen, die versuchen, den Kunden zufrieden zu stellen, bieten ihre eigenen an oder passen vorhandene Tools an. Mathworks bietet ein eigenes HDL-Codierertool zum Generieren von HDL-Code aus M-Skripten und Simulink-Modellen an, während Intel und Xilinx Compiler für gängiges C / C ++ anbieten.
Derzeit haben Unternehmen mit erheblichen finanziellen und personellen Ressourcen größere Erfolge erzielt, während Enthusiasten etwas zurückbleiben. Dieser Artikel befasst sich mit dem Produkt HDL-Codierer von Mathworks und HLS Compiler von Intel.
Was ist mit Xilinx?In diesem Artikel werde ich HIL von Xilinx aufgrund der unterschiedlichen Architekturen und CAD-Systeme von Intel und Xilinx nicht berücksichtigen, was einen eindeutigen Vergleich der Ergebnisse unmöglich macht. Ich möchte jedoch darauf hinweisen, dass Xilinx HLS wie Intel HLS einen C / C ++ - Compiler bereitstellt und konzeptionell ähnlich ist.
Beginnen wir mit dem Vergleich des HDL-Codierers von Mathworks und Intel HLS Compiler, nachdem mehrere Probleme mit unterschiedlichen Ansätzen gelöst wurden.
Vergleich von Entwicklungswerkzeugen auf hoher Ebene
Testen Sie einen. "Zwei Multiplikatoren und ein Addierer"
Die Lösung dieses Problems hat keinen praktischen Wert, eignet sich aber gut als erster Test. Die Funktion verwendet 4 Parameter, multipliziert den ersten mit dem zweiten, den dritten mit dem vierten und addiert die Ergebnisse der Multiplikation. Nichts kompliziertes, aber mal sehen, wie unsere Probanden damit umgehen.
HDL-Codierer von Mathworks
Um dieses Problem zu lösen, sieht das M-Skript wie folgt aus:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
Mal sehen, was Mathworks uns bietet, um Code in HDL zu konvertieren.
Ich werde die Arbeit mit HDL-Codierern nicht im Detail betrachten, sondern mich nur auf die Einstellungen konzentrieren, die ich in Zukunft ändern werde, um unterschiedliche Ergebnisse in FPGA zu erzielen, und deren Änderungen von einem MATLAB-Programmierer berücksichtigt werden müssen, der seinen Code in FPGA ausführen muss.
Als erstes müssen Sie also den Typ und den Bereich der Eingabewerte festlegen. Es gibt kein bekanntes char, int, float, double im FPGA. Die Bittiefe der Zahl kann beliebig sein. Es ist logisch, sie basierend auf dem Bereich der Eingabewerte auszuwählen, die Sie verwenden möchten.
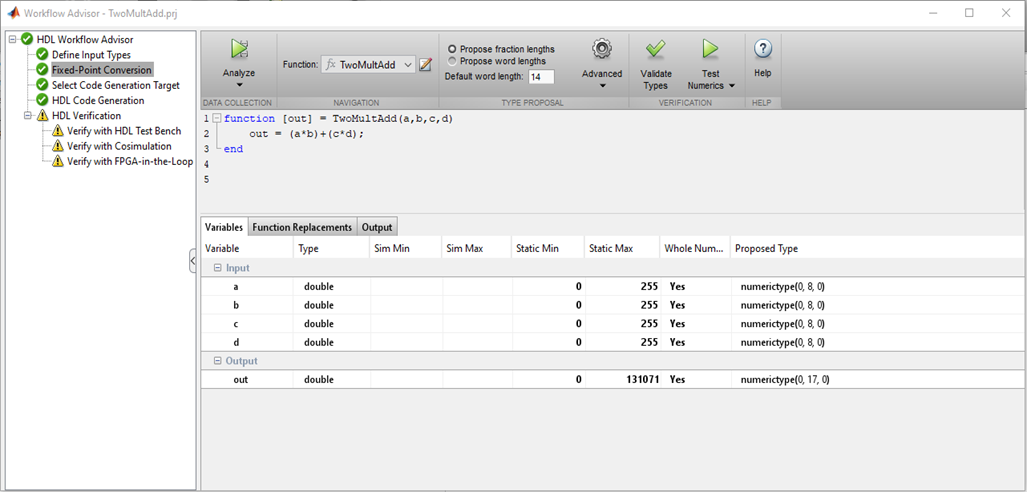 Abbildung 1
Abbildung 1MATLAB überprüft die Variablentypen und ihre Werte und wählt die richtigen Bitgrößen für Busse und Register aus, was sehr praktisch ist. Wenn es keine Probleme mit der Bittiefe und der Eingabe gibt, können Sie mit den folgenden Punkten fortfahren.
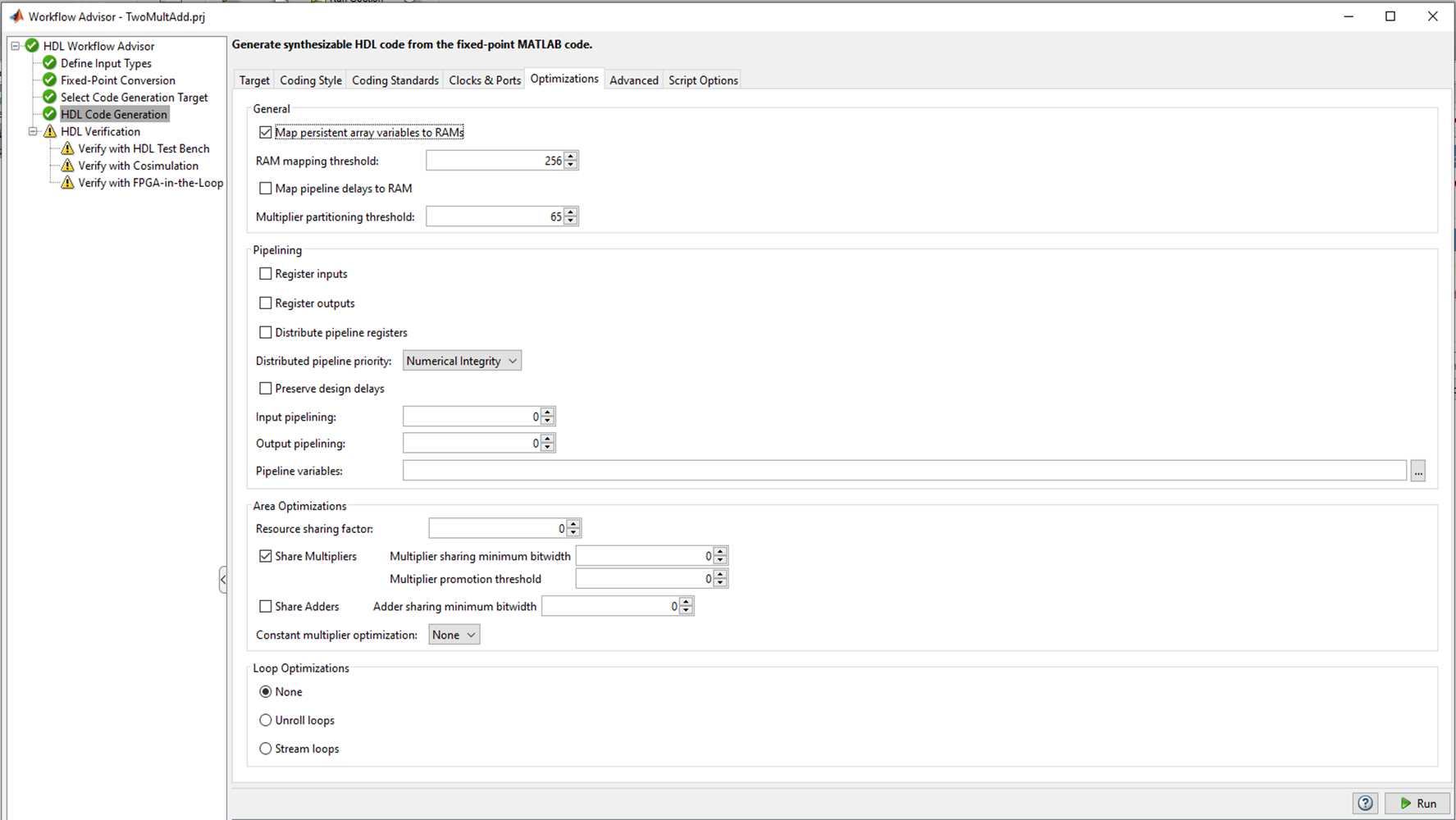 Abbildung 2
Abbildung 2In der HDL-Codegenerierung gibt es mehrere Registerkarten, auf denen Sie die Sprache auswählen können, in die konvertiert werden soll (Verilog oder VHDL). Codestil Namen von Signalen. Die meiner Meinung nach interessanteste Registerkarte ist die Optimierung, und ich werde damit experimentieren. Lassen Sie uns jedoch vorerst alle Standardeinstellungen belassen und sehen, was mit dem HDL-Codierer "out of the box" passiert.
Drücken Sie die Run-Taste und erhalten Sie den folgenden Code:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
Der Code sieht gut aus. MATLAB versteht, dass das Schreiben des gesamten Ausdrucks in einer einzelnen Zeile in Verilog eine schlechte Praxis ist. Erstellt separate
Drähte für den Multiplikator und den Addierer. Es gibt nichts zu beanstanden.
Es ist alarmierend, dass die Beschreibung der Register fehlt. Dies geschah, weil wir den HDL-Codierer nicht danach gefragt haben und alle Felder in den Einstellungen auf ihren Standardwerten belassen haben.
Hier ist, was Quartus aus einem solchen Code synthetisiert.
 Abbildung 3
Abbildung 3Keine Probleme, alles war wie geplant.
In FPGA implementieren wir synchrone Schaltungen, und trotzdem würde ich gerne die Register sehen. Der HDL-Codierer bietet einen Mechanismus zum Platzieren von Registern, aber wo sie platziert werden sollen, liegt beim Entwickler. Wir können die Register am Eingang der Multiplikatoren, am Ausgang der Multiplikatoren vor dem Addierer oder am Ausgang des Addierers platzieren.
Um die Beispiele zusammenzufassen, habe ich mich für die FPGA Cyclone V-Familie entschieden, bei der spezielle DSP-Blöcke mit integrierten Addierern und Multiplikatoren zur Implementierung von arithmetischen Operationen verwendet werden. Der DSP-Block sieht folgendermaßen aus:
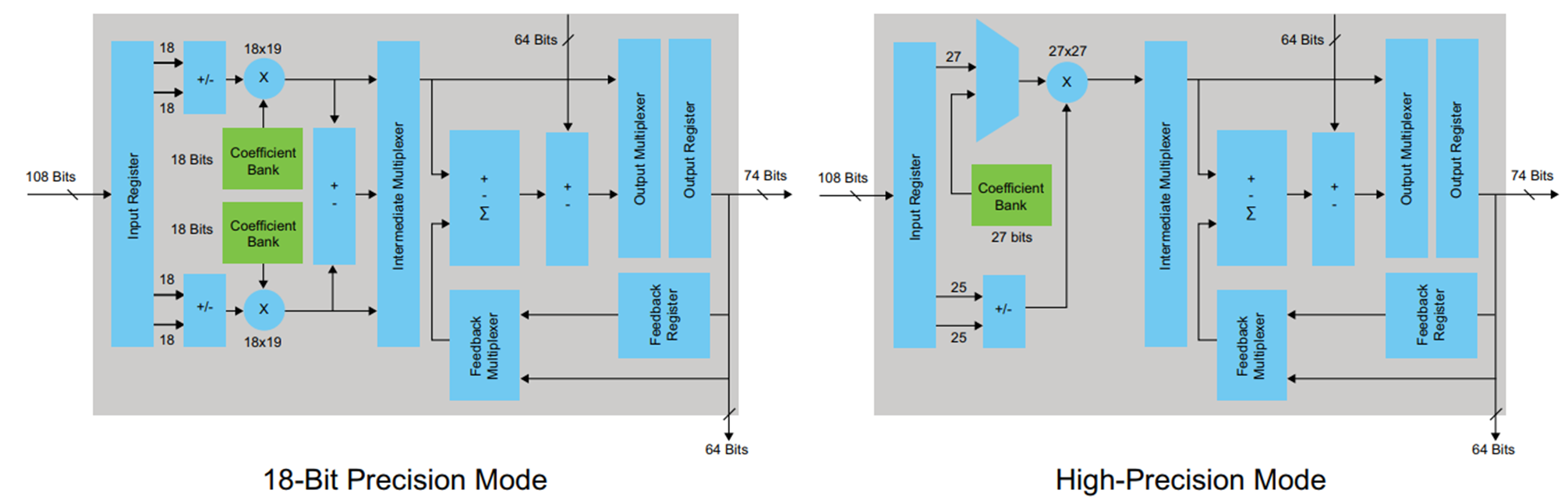 Abbildung 4
Abbildung 4Der DSP-Block hat Eingangs- und Ausgangsregister. Es ist nicht erforderlich, die Ergebnisse der Multiplikation vor dem Hinzufügen im Register abzufangen. Dies verstößt nur gegen die Architektur (in bestimmten Fällen ist diese Option möglich und wird sogar benötigt). Es ist Sache des Entwicklers, anhand der Latenzanforderungen und der erforderlichen maximalen Frequenz zu entscheiden, wie mit dem Eingangs- und Ausgangsregister umgegangen werden soll. Ich habe mich entschieden, nur das Ausgangsregister zu verwenden. Damit dieses Register in dem vom HDL-Codierer generierten Code beschrieben werden kann, müssen Sie auf der Registerkarte Optionen im HDL-Codierer das Kontrollkästchen Registerausgabe aktivieren und die Konvertierung neu starten.
Es stellt sich folgender Code heraus:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
Wie Sie sehen können, weist der Code grundlegende Unterschiede zur vorherigen Version auf. Es erschien ein Always-Block, der eine Beschreibung des Registers darstellt (genau das, was wir wollten). Für den Always-Block-Betrieb erschienen auch die Eingänge des Clk-Moduls (Taktfrequenz) und des Reset (Reset). Es ist ersichtlich, dass der Ausgang des Addierers in dem in immer beschriebenen Trigger zwischengespeichert ist. Es gibt auch ein paar Ena-Erlaubnis-Signale, aber sie sind für uns nicht sehr interessant.
Schauen wir uns das Diagramm an, das Quartus jetzt synthetisiert.
 Abbildung 5
Abbildung 5Auch hier sind die Ergebnisse gut und werden erwartet.
Die folgende Tabelle zeigt die Tabelle der verwendeten Ressourcen - wir berücksichtigen dies.
 Abbildung 6
Abbildung 6Für diese erste Quest erhält Mathworks eine Gutschrift. Alles ist nicht kompliziert, vorhersehbar und mit dem gewünschten Ergebnis.
Ich habe ein einfaches Beispiel ausführlich beschrieben, ein Diagramm eines DSP-Blocks bereitgestellt und die Möglichkeiten beschrieben, die Registerverwendungseinstellungen in HDL-Codierern außer den „Standardeinstellungen“ zu verwenden. Dies geschieht aus einem bestimmten Grund. An dieser Stelle möchte ich betonen, dass auch in einem so einfachen Beispiel bei Verwendung eines HDL-Codierers Kenntnisse der FPGA-Architektur und der Grundlagen digitaler Schaltkreise erforderlich sind und die Einstellungen bewusst geändert werden müssen.
Intel HLS Compiler
Versuchen wir, Code mit der gleichen Funktionalität zu kompilieren, die in C ++ geschrieben wurde, und sehen, was schließlich mit dem HLS-Compiler in FPGA synthetisiert wird.
Also C ++ Code
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
Ich habe Datentypen ausgewählt, um ein Überlaufen von Variablen zu vermeiden.
Es gibt fortschrittliche Methoden zum Festlegen von Bittiefen. Unser Ziel ist es jedoch, die Fähigkeit zu testen, Funktionen, die im C / C ++ - Stil unter FPGA geschrieben wurden, ohne Änderungen zusammenzustellen.
Da der HLS-Compiler ein natives Tool von Intel ist, sammeln wir den Code mit einem speziellen Compiler und überprüfen das Ergebnis sofort in Quartus.
Schauen wir uns die Schaltung an, die Quartus synthetisiert.
 Abbildung 7
Abbildung 7Der Compiler hat Register an der Ein- und Ausgabe erstellt, aber die Essenz ist im Wrapper-Modul verborgen. Wir beginnen mit der Bereitstellung des Wrappers und ... sehen immer mehr verschachtelte Module.
Die Struktur des Projekts sieht so aus.
 Abbildung 8
Abbildung 8Ein offensichtlicher Hinweis von Intel lautet: "Nehmen Sie es nicht in die Hand!". Aber wir werden versuchen, vor allem die Funktionalität ist nicht kompliziert.
In den Eingeweiden des Projektbaums | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 ist das Modul, nach dem Sie suchen.
Wir können uns das Diagramm des gewünschten Moduls ansehen, das von Quartus synthetisiert wurde.
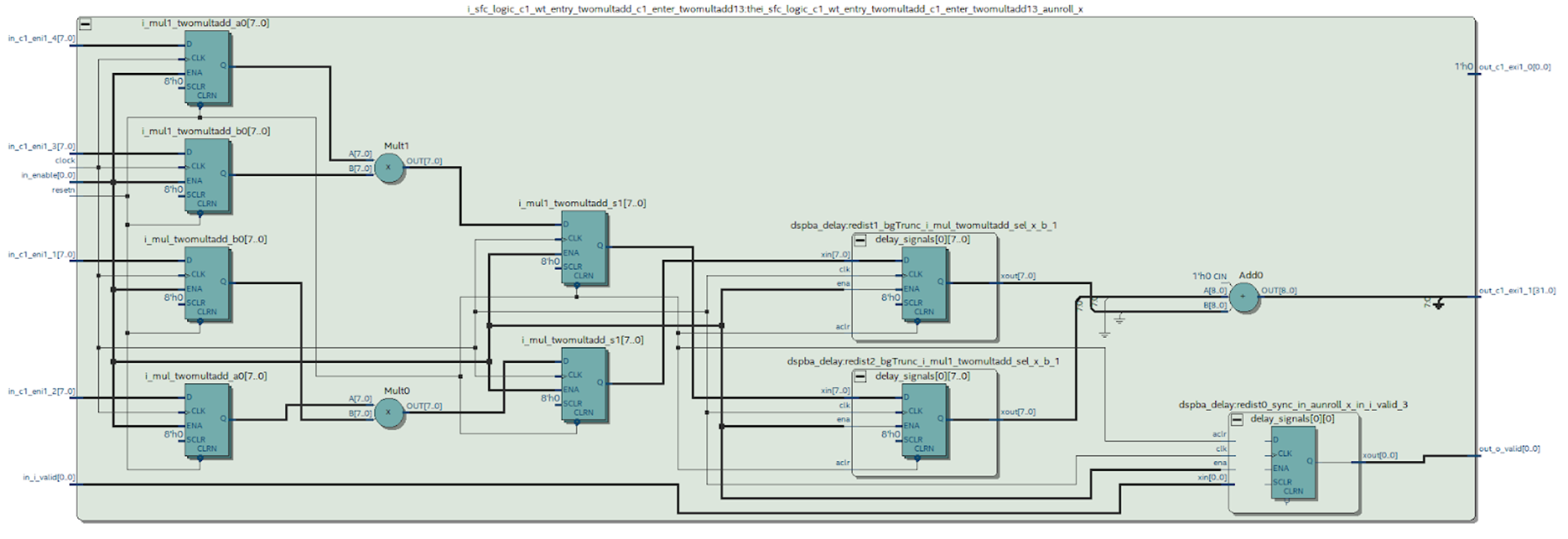 Abbildung 9
Abbildung 9Welche Schlussfolgerungen können aus diesem Schema gezogen werden?
Es ist offensichtlich, dass etwas passiert ist, das wir bei der Arbeit in MATLAB zu vermeiden versucht haben: Der Fall am Ausgang des Multiplikators wurde synthetisiert - das ist nicht sehr gut. Aus dem DSP-Blockdiagramm (Abbildung 4) ist ersichtlich, dass sich an seinem Ausgang nur ein Register befindet, was bedeutet, dass jede Multiplikation in einem separaten Block durchgeführt werden muss.
Die Tabelle der verwendeten Ressourcen zeigt, wozu dies führt.
 Abbildung 10
Abbildung 10Vergleichen Sie die Ergebnisse mit der HDL-Codierertabelle (Abbildung 6).
Wenn Sie eine größere Anzahl von Registern verwenden, die Sie ertragen können, ist es sehr unangenehm, wertvolle DSP-Blöcke für solch einfache Funktionen auszugeben.
Intel HLS bietet jedoch ein großes Plus im Vergleich zu HDL-Codierern. Mit den Standardeinstellungen entwickelte der HLS-Compiler ein synchrones Design in FPGA, obwohl er mehr Ressourcen verbrauchte. Eine solche Architektur ist möglich, es ist klar, dass Intel HLS so konfiguriert ist, dass maximale Leistung erzielt wird und keine Ressourcen gespart werden.
Mal sehen, wie sich unsere Themen bei komplexeren Projekten verhalten.
Der zweite Test. "Elementweise Multiplikation von Matrizen mit Summation des Ergebnisses"
Diese Funktion ist in der Bildverarbeitung weit verbreitet: der sogenannte
„Matrixfilter“ . Wir verkaufen es mit hochwertigen Werkzeugen.
HDL-Codierer von Mathwork
Die Arbeit beginnt sofort mit einer Einschränkung. Der HDL-Codierer kann keine 2D-Matrixfunktionen als Eingänge akzeptieren. Angesichts der Tatsache, dass MATLAB ein Werkzeug für die Arbeit mit Matrizen ist, ist dies ein schwerer Schlag für den gesamten geerbten Code, der zu einem ernsthaften Problem werden kann. Wenn der Code von Grund auf neu geschrieben wurde, ist dies eine unangenehme Funktion, die berücksichtigt werden muss. Sie müssen also alle Matrizen in einem Vektor bereitstellen und die Funktionen unter Berücksichtigung der Eingabevektoren implementieren.
Der Code für die Funktion in MATLAB lautet wie folgt
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
Der generierte HDL-Code erwies sich als sehr aufgebläht und enthält Hunderte von Zeilen, daher werde ich ihn hier nicht angeben. Mal sehen, welches Schema Quartus aus diesem Code synthetisiert.
 Abbildung 11
Abbildung 11Dieses Schema sieht nicht erfolgreich aus. Formal funktioniert es, aber ich gehe davon aus, dass es mit einer sehr niedrigen Frequenz funktioniert und in realer Hardware kaum verwendet werden kann. Jede Annahme muss jedoch überprüft werden. Dazu platzieren wir die Register am Eingang und Ausgang dieser Schaltung und bewerten mit Hilfe des Timing Analyzer die reale Situation. Um die Analyse durchzuführen, müssen Sie die gewünschte Betriebsfrequenz des Stromkreises angeben, damit Quartus weiß, worauf bei der Verkabelung zu achten ist, und im Fehlerfall Berichte über Verstöße liefert.
Wir stellen die Frequenz auf 100 MHz ein. Mal sehen, was Quartus aus der vorgeschlagenen Schaltung herausdrücken kann.
 Abbildung 12
Abbildung 12Es ist zu sehen, dass es sich ein wenig herausstellte: 33 MHz sehen leichtfertig aus. Die Verzögerung in der Kette von Multiplikatoren und Addierern beträgt etwa 30 ns. Um diesen „Engpass“ zu beseitigen, müssen Sie den Förderer verwenden: Register nach arithmetischen Operationen einfügen, wodurch der kritische Pfad verringert wird.
Der HDL-Codierer bietet uns diese Möglichkeit. Auf der Registerkarte Optionen können Sie Pipeline-Variablen festlegen. Da der betreffende Code im MATLAB-Stil geschrieben ist, gibt es keine Möglichkeit zu Pipeline-Variablen (außer Multi- und Summ-Variablen), die nicht zu uns passen. Es ist notwendig, die Register in die in unserem HDL-Code verborgenen Zwischenkreise einzufügen.
Darüber hinaus könnte sich die Situation bei der Optimierung verschlechtern. Zum Beispiel hindert uns nichts daran, Code zu schreiben
out = (sum(target.*kernel))/len;
es ist für MATLAB völlig ausreichend, beraubt uns jedoch völlig der Möglichkeit, HDL zu optimieren.
Der nächste Ausweg besteht darin, den Code von Hand zu bearbeiten. Dies ist ein sehr wichtiger Punkt, da wir uns weigern, das M-Skript zu erben und neu zu schreiben, und NICHT im MATLAB-Stil.
Der neue Code lautet wie folgt
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
In Quartus sammeln wir den vom HDL-Codierer generierten Code. Es ist ersichtlich, dass die Anzahl der Schichten mit Grundelementen abgenommen hat und das Schema viel besser aussieht.
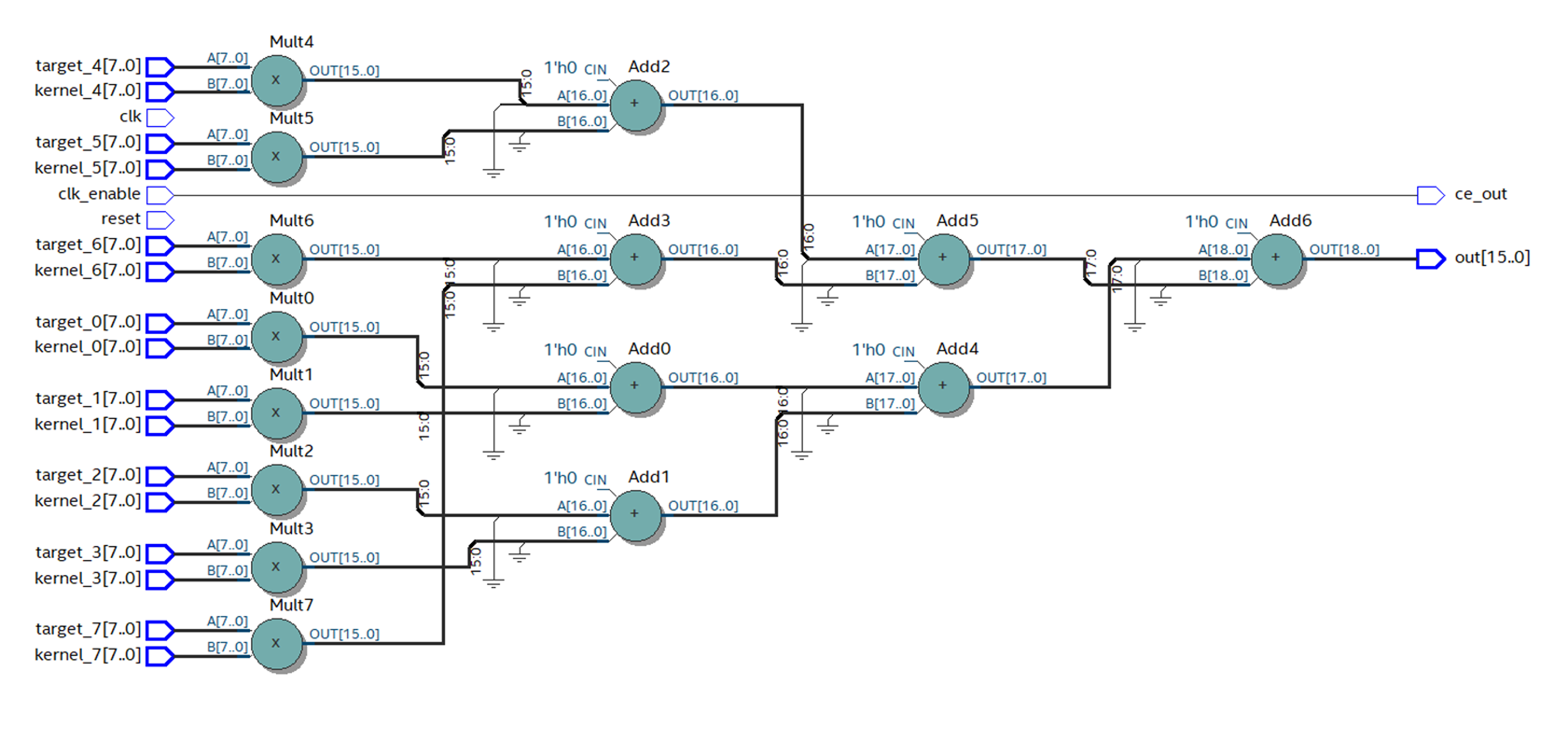 Abbildung 12
Abbildung 12Bei korrekter Anordnung der Grundelemente wächst die Frequenz fast dreimal auf 88 MHz.
 Abbildung 13
Abbildung 13Jetzt der letzte Schliff: Geben Sie in den Optimierungseinstellungen summ_1, summ_2 und summ_3 als Elemente der Pipeline an. Wir sammeln den resultierenden Code in Quartus. Das Schema ändert sich wie folgt:
 Abbildung 14
Abbildung 14Die maximale Frequenz steigt wieder an und liegt nun bei ca. 195 MHz.
 Abbildung 15
Abbildung 15Wie viele Ressourcen auf dem Chip benötigen ein solches Design? Abbildung 16 zeigt die Tabelle der verwendeten Ressourcen für den beschriebenen Fall.
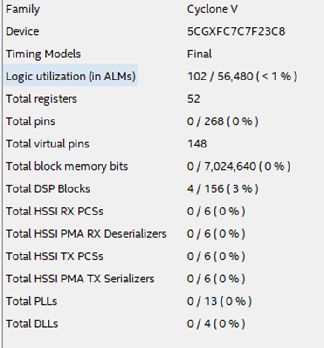 Abbildung 16
Abbildung 16Welche Schlussfolgerungen können nach Betrachtung dieses Beispiels gezogen werden?
Der Hauptnachteil des HDL-Codierers besteht darin, dass MATLAB-Code wahrscheinlich nicht in seiner reinen Form verwendet wird.
Es gibt keine Unterstützung für Matrizen als Funktionseingaben, das Layout des Codes im MATLAB-Stil ist mittelmäßig.
Die Hauptgefahr ist das Fehlen von Registern im Code, der ohne zusätzliche Einstellungen generiert wird. Ohne diese Register ist die Verwendung eines solchen Codes in modernen Realitäten und Entwicklungen unerwünscht, selbst wenn formal funktionierender HDL-Code ohne Syntaxfehler empfangen wurde.
Es ist ratsam, sofort Code zu schreiben, der für die Konvertierung in HDL geschärft wurde. In diesem Fall können Sie in Bezug auf Geschwindigkeit und Ressourcenintensität durchaus akzeptable Ergebnisse erzielen.
Wenn Sie ein MATLAB-Entwickler sind, klicken Sie nicht schnell auf die Schaltfläche Ausführen und kompilieren Sie Ihren Code unter FPGA. Denken Sie daran, dass Ihr Code zu einer realen Schaltung synthetisiert wird. =)
Intel HLS Compiler
Für die gleiche Funktionalität habe ich den folgenden C / C ++ - Code geschrieben
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
Das erste, was auffällt, ist die Menge der verwendeten Ressourcen.
 Abbildung 17
Abbildung 17Aus der Tabelle ist ersichtlich, dass nur 1 DSP-Block verwendet wurde, sodass ein Fehler aufgetreten ist und Multiplikationen nicht parallel durchgeführt werden. Die Anzahl der verwendeten Register ist ebenfalls überraschend, und es ist sogar Speicher erforderlich, aber wir werden dies dem Gewissen des HLS-Compilers überlassen.
Es ist erwähnenswert, dass der HLS-Compiler ein Suboptimum entwickelt hat, das eine große Menge zusätzlicher Ressourcen verwendet, aber dennoch eine Arbeitsschaltung, die laut Quartus-Berichten mit einer akzeptablen Frequenz arbeitet, und ein Fehler wie der HDL-Codierer nicht.
 Abbildung 18
Abbildung 18Versuchen wir, die Situation zu verbessern. Was wird dafür benötigt? Richtig, schließen Sie die Augen vor der Vererbung und kriechen Sie in den Code, aber bisher ist es nicht viel.
HLS verfügt über spezielle Anweisungen zur Optimierung des Codes für FPGA. Wir fügen die Unroll-Direktive ein, die unsere Schleife parallel erweitern soll:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
Mal sehen, wie Quartus darauf reagiert hat
 Abbildung 19
Abbildung 19Achten Sie zunächst auf die Anzahl der DSP-Blöcke - es gibt 16 davon, was bedeutet, dass Multiplikationen parallel durchgeführt werden.
Hurra! abrollen funktioniert! Es ist jedoch bereits schwer zu ertragen, wie stark die Nutzung anderer Ressourcen zugenommen hat. Die Schaltung ist völlig unlesbar geworden.
 Abbildung 20
Abbildung 20Ich glaube, das lag an der Tatsache, dass niemand den Compiler darauf hinwies, dass Berechnungen in Festkommazahlen für uns gut geeignet sind, und er hat ehrlich gesagt alle Gleitkomma-Mathematik in Logik und Registern implementiert. Wir müssen dem Compiler erklären, was davon verlangt wird, und dafür tauchen wir wieder in den Code ein.
Zur Verwendung von Festkomma werden Vorlagenklassen implementiert.
 Abbildung 21
Abbildung 21In unseren eigenen Worten können wir Variablen verwenden, deren Bittiefe manuell auf ein Bit eingestellt wird. Für diejenigen, die in HDL schreiben, kann man sich nicht daran gewöhnen, aber C / C ++ - Programmierer werden wahrscheinlich ihre Köpfe umklammern. Bittiefen, wie in MATLAB, wird in diesem Fall niemand sagen, und der Entwickler selbst muss die Anzahl der Bits zählen.
Mal sehen, wie es in der Praxis aussieht.
Wir bearbeiten den Code wie folgt:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
Und anstelle der gruseligen Nudeln aus Abbildung 20 erhalten wir diese Schönheit:
 Abbildung 22
Abbildung 22Leider passiert mit den verwendeten Ressourcen weiterhin etwas Seltsames.
 Abbildung 23
Abbildung 23Eine detaillierte Überprüfung der Berichte zeigt jedoch, dass das Modul, das uns direkt interessiert, mehr als angemessen aussieht:
 Abbildung 24
Abbildung 24Der enorme Verbrauch an Registern und Blockspeicher ist mit einer großen Anzahl von Peripheriemodulen verbunden. Ich verstehe die tiefe Bedeutung ihrer Existenz immer noch nicht vollständig, und dies muss geklärt werden, aber das Problem ist gelöst. Im Extremfall können Sie ein für uns interessantes Modul sorgfältig aus der allgemeinen Struktur des Projekts herausschneiden, um uns vor peripheren Modulen zu schützen, die Ressourcen verschlingen.
Der dritte Test. "Übergang von RGB zu HSV"
Als ich anfing, diesen Artikel zu schreiben, hatte ich nicht erwartet, dass er so umfangreich sein würde. Aber ich kann den dritten und den letzten im Rahmen dieses Artikels, ein Beispiel, nicht ablehnen.
Erstens ist dies ein echtes Beispiel aus meiner Praxis, und aus diesem Grund begann ich, mich mit hochrangigen Entwicklungswerkzeugen zu befassen.
Zweitens könnten wir anhand der ersten beiden Beispiele davon ausgehen, dass die Werkzeuge auf hoher Ebene die Aufgabe umso schlechter bewältigen, je komplexer das Design ist.
Ich möchte zeigen, dass dieses Urteil falsch ist. Je komplexer die Aufgabe ist, desto mehr manifestieren sich die Vorteile von Entwicklungswerkzeugen auf hoher Ebene.
Letztes Jahr, als ich an einem der Projekte arbeitete, mochte ich die bei Aliexpress gekaufte Kamera nicht, nämlich, dass die Farben nicht gesättigt genug waren. Eine der beliebtesten Möglichkeiten, die Farbsättigung zu variieren, besteht darin, vom RGB-Farbraum zum HSV-Raum zu wechseln, wobei einer der Parameter die Sättigung ist. Ich erinnere mich, wie ich die Übergangsformel geöffnet und tief durchgeatmet habe ... Die Implementierung solcher Berechnungen in FPGA ist nichts Außergewöhnliches, aber es wird natürlich einige Zeit dauern, Code zu schreiben. Die Formel für den Wechsel von RGB zu HSV lautet also wie folgt:
 Abbildung 25
Abbildung 25Die Implementierung eines solchen Algorithmus in FPGA wird nicht Tage, sondern Stunden dauern, und all dies muss aufgrund der Besonderheiten von HDL sehr sorgfältig durchgeführt werden, und die Implementierung in C ++ oder MATLAB wird, glaube ich, Minuten dauern.
In C ++ können Sie Code direkt in die Stirn schreiben und trotzdem ein funktionierendes Ergebnis erhalten.
Ich habe die folgende Option in C ++ geschrieben
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
Und Quartus hat das Ergebnis erfolgreich implementiert, wie aus der Tabelle der verwendeten Ressourcen hervorgeht.
 Abbildung 26
Abbildung 26Die Frequenz ist sehr gut.
 Abbildung 27
Abbildung 27Mit dem HDL-Codierer sind die Dinge etwas komplizierter.
Um den Artikel nicht aufzublasen, werde ich kein M-Skript für diese Aufgabe bereitstellen, es sollte keine Schwierigkeiten verursachen. Ein in die Stirn geschriebenes M-Skript kann kaum erfolgreich verwendet werden. Wenn Sie jedoch den Code bearbeiten und die Stellen für das Pipelining korrekt angeben, erhalten Sie ein Arbeitsergebnis. Dies dauert natürlich einige zehn Minuten, aber nicht Stunden.
C++ , .
, , , , — , FPGA , HDL.
Fazit
.
, , , .
, , . , , HDL, .
, FPGA FPGA . .
, — FPGA.
HLS compiler : , , , “best practices” .. MATLAB, , GUI , , , , , .
? — Intel HLS compiler. . HDL coder . , HDL coder , , . HLS, , , FPGA , .
Xilinx , — FPGA. , , Verilog/VHDL , . ( ), .
? , , , HDL .
, , , , .