Kürzlich wurde
ein Artikel veröffentlicht, der einen guten Trend beim maschinellen Lernen in den letzten Jahren zeigt. Kurzum: Die Zahl der Startups im Bereich des maschinellen Lernens ist in den letzten zwei Jahren stark zurückgegangen.
Und was. Lassen Sie uns analysieren, ob die Blase platzt, wie man weiterlebt und wie ein solcher Kringel herkommt.
Lassen Sie uns zunächst darüber sprechen, was der Booster dieser Kurve war. Woher kam sie? Wahrscheinlich wird sich jeder an den
Sieg des maschinellen Lernens 2012 beim ImageNet-Wettbewerb erinnern. Immerhin ist dies das erste globale Ereignis! In Wirklichkeit ist dies jedoch nicht der Fall. Und das Wachstum der Kurve beginnt etwas früher. Ich würde es in mehrere Punkte aufteilen.
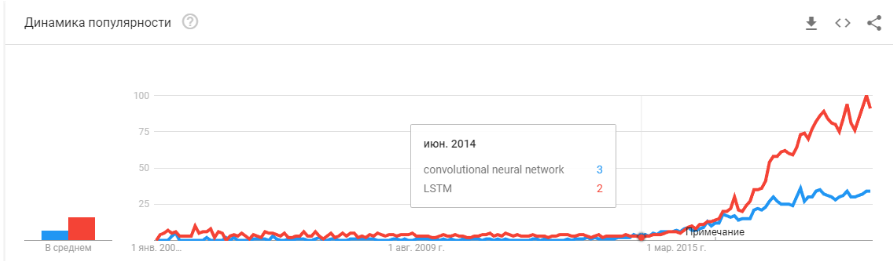
- 2008 taucht der Begriff „Big Data“ auf. Seit 2010 erscheinen echte Produkte. Big Data steht in direktem Zusammenhang mit maschinellem Lernen. Ohne Big Data ist der stabile Betrieb der damals existierenden Algorithmen nicht möglich. Und das sind keine neuronalen Netze. Bis 2012 sind neuronale Netze das Los einer marginalen Minderheit. Aber dann begannen völlig andere Algorithmen zu funktionieren, die es seit Jahren oder sogar Jahrzehnten gab: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... Startups dieser Jahre sind hauptsächlich mit der automatischen Verarbeitung strukturierter Daten verbunden : Ticketschalter, Benutzer, Werbung, vieles mehr.
Die Ableitung dieser ersten Welle ist eine Reihe von Frameworks wie XGBoost, CatBoost, LightGBM usw.
- In den Jahren 2011-2012 gewannen Faltungs-Neuronale Netze eine Reihe von Bilderkennungswettbewerben. Ihre tatsächliche Verwendung war etwas verzögert. Ich würde sagen, dass 2014 massiv bedeutsame Startups und Lösungen auftauchten. Es dauerte zwei Jahre, um zu verdauen, dass Neuronen noch funktionieren, um bequeme Frameworks zu erstellen, die in angemessener Zeit installiert und gestartet werden konnten, um Methoden zu entwickeln, die die Konvergenzzeit stabilisieren und beschleunigen.
Faltungsnetzwerke ermöglichten die Lösung von Bildverarbeitungsproblemen: Klassifizierung von Bildern und Objekten in einem Bild, Erkennung von Objekten, Erkennung von Objekten und Personen, Bildverbesserung usw. usw. - 2015-2017 Jahre. Der Boom von Algorithmen und Projekten, die an wiederkehrende Netzwerke oder deren Analoga (LSTM, GRU, TransformerNet usw.) gebunden sind. Es sind gut funktionierende Sprach-Text-Algorithmen und maschinelle Übersetzungssysteme erschienen. Zum Teil basieren sie auf Faltungsnetzwerken, um grundlegende Merkmale hervorzuheben. Teilweise aufgrund der Tatsache, dass sie gelernt haben, wirklich große und gute Datensätze zu sammeln.
"Ist die Blase geplatzt?" Ist Hype überhitzt? Sind sie wie eine Blockchain gestorben? “
Na dann! Morgen wird Siri aufhören, an Ihrem Telefon zu arbeiten, und übermorgen wird Tesla keine Wendung von einem Känguru unterscheiden.
Neuronale Netze funktionieren bereits. Sie sind in Dutzenden von Geräten. Sie ermöglichen es Ihnen wirklich, Geld zu verdienen, den Markt und die Welt um Sie herum zu verändern. Hype sieht ein bisschen anders aus:
Es ist nur so, dass neuronale Netze aufgehört haben, etwas Neues zu sein. Ja, viele Menschen haben hohe Erwartungen. Aber eine große Anzahl von Unternehmen hat gelernt, ihre Neuronen zu nutzen und darauf basierende Produkte herzustellen. Neuronen bieten neue Funktionen, können Arbeitsplätze reduzieren und den Preis für Dienstleistungen senken:
- Fertigungsunternehmen integrieren Algorithmen zur Analyse von Ausschuss auf dem Förderband.
- Tierfarmen kaufen Systeme zur Kontrolle von Kühen.
- Automatische Erntemaschinen.
- Automatisierte Call Center.
- Filter in Snapchat. (
Na ja, zumindest etwas Vernünftiges! )
Aber die Hauptsache und nicht die offensichtlichste: "Es gibt keine neuen Ideen mehr, oder sie bringen kein sofortiges Kapital." Neuronale Netze haben Dutzende von Problemen gelöst. Und sie werden noch mehr entscheiden. All die offensichtlichen Ideen, die daraus entstanden sind, haben viele Startups hervorgebracht. Aber alles, was an der Oberfläche war, wurde bereits gesammelt. In den letzten zwei Jahren habe ich keine einzige neue Idee für die Verwendung neuronaler Netze kennengelernt. Kein einziger neuer Ansatz (na ja, es gibt ein paar Probleme mit GANs).
Und jedes nächste Startup wird immer komplizierter. Es sind nicht mehr zwei Leute erforderlich, die ein Neuron auf offene Daten trainieren. Es erfordert Programmierer, einen Server, ein Team von Schreibern, komplexe Unterstützung usw.
Infolgedessen gibt es weniger Startups. Aber die Produktion ist mehr. Müssen Kennzeichenerkennung beigefügt werden? Es gibt Hunderte von Fachleuten mit einschlägiger Erfahrung auf dem Markt. Sie können einstellen und in ein paar Monaten wird Ihr Mitarbeiter ein System erstellen. Oder kaufen Sie eine fertige. Aber ein neues Startup machen? .. Wahnsinn!
Wir müssen ein System zur Verfolgung von Besuchern entwickeln - warum für eine Reihe von Lizenzen bezahlen, wenn Sie 3-4 Monate lang Ihre eigenen Lizenzen erstellen können, schärfen Sie es für Ihr Unternehmen.
Jetzt gehen neuronale Netze den gleichen Weg wie Dutzende anderer Technologien.
Erinnern Sie sich, wie sich das Konzept des "Site-Entwicklers" seit 1995 geändert hat? Während der Markt nicht mit Spezialisten gesättigt ist. Es gibt nur sehr wenige Fachleute. Aber ich kann wetten, dass es in 5-10 Jahren keinen großen Unterschied zwischen einem Java-Programmierer und einem Entwickler eines neuronalen Netzwerks geben wird. Und diese und jene Spezialisten werden auf dem Markt ausreichen.
Es wird einfach eine Klasse von Aufgaben geben, für die Neuronen lösen. Es gab eine Aufgabe - einen Spezialisten einstellen.
„Und was dann? Wo ist die versprochene künstliche Intelligenz? “Und hier gibt es eine kleine aber interessante Neponyatchka :)
Der heutige Technologie-Stack wird uns offenbar immer noch nicht zu künstlicher Intelligenz führen. Ideen, ihre Neuheit, haben sich weitgehend erschöpft. Lassen Sie uns darüber sprechen, was den aktuellen Entwicklungsstand hält.
Einschränkungen
Beginnen wir mit Auto-Drohnen. Es scheint klar zu sein, dass es mit den heutigen Technologien möglich ist, vollständig autonome Autos herzustellen. Aber nach wie vielen Jahren dies geschehen wird, ist nicht klar. Tesla glaubt, dass dies in ein paar Jahren geschehen wird -
Es gibt viele andere
Spezialisten, die dies als 5-10 Jahre alt bewerten.
Meiner Meinung nach wird sich die Infrastruktur der Städte nach 15 Jahren höchstwahrscheinlich selbst ändern, so dass die Entstehung autonomer Autos unvermeidlich wird und ihre Fortsetzung sein wird. Dies kann jedoch nicht als Intelligenz angesehen werden. Modern Tesla ist eine sehr komplexe Pipeline zum Filtern, Suchen und Umschulen von Daten. Dies sind Regeln, Regeln, Regeln, Datenerfassung und Filter darüber (
hier habe ich etwas mehr darüber geschrieben oder schaue von
diesem Punkt aus).
Erstes Problem
Und hier sehen wir das
erste grundlegende Problem . Big Data. Genau dies hat die aktuelle Welle neuronaler Netze und maschinellen Lernens ausgelöst. Um etwas Komplexes und Automatisches zu tun, benötigen Sie viele Daten. Nicht nur viel, sondern sehr, sehr viel. Wir benötigen automatisierte Algorithmen für deren Erfassung, Markup und Verwendung. Wir wollen, dass das Auto Lastwagen gegen die Sonne sieht - wir müssen zuerst eine ausreichende Anzahl von ihnen sammeln. Wir wollen, dass das Auto nicht verrückt wird, wenn ein Fahrrad am Kofferraum festgeschraubt ist - mehr Proben.
Darüber hinaus reicht ein Beispiel nicht aus. Hunderte? Tausende?

Zweites Problem
Das zweite Problem ist die Visualisierung dessen, was unser neuronales Netzwerk verstanden hat. Dies ist eine sehr nicht triviale Aufgabe. Bisher verstehen nur wenige Menschen, wie man dies visualisiert. Diese Artikel sind sehr neu, dies sind nur einige Beispiele, auch entfernte:
Visualisierung der Fixierung auf Texturen. Es zeigt gut, was das Neuron in Zyklen tendenziell macht + was es als Anfangsinformation wahrnimmt.
 Visualisierung der
Visualisierung der Dämpfung während der
Übersetzung . Tatsächlich kann die Dämpfung oft genau verwendet werden, um zu zeigen, was eine solche Netzwerkreaktion verursacht hat. Ich habe solche Dinge zum Debuggen und für Produktlösungen getroffen. Es gibt viele Artikel zu diesem Thema. Je komplexer die Daten sind, desto schwieriger ist es zu verstehen, wie eine nachhaltige Visualisierung erreicht werden kann.

Nun ja, der gute alte Satz von "Schau dir an, was das Gitter in den
Filtern ist ". Diese Bilder waren vor ungefähr 3-4 Jahren beliebt, aber jeder erkannte schnell, dass die Bilder schön sind, aber es macht nicht viel Sinn.

Ich habe nicht Dutzende anderer Lotionen, Methoden, Hacks und Studien zur Darstellung der Innenseiten des Netzwerks genannt. Funktionieren diese Tools? Helfen sie Ihnen, das Problem schnell zu verstehen und das Netzwerk zu debuggen? Ziehen Sie das letzte Prozent heraus? So etwas in der Art:

Sie können jeden Wettbewerb bei Kaggle sehen. Und eine Beschreibung, wie Menschen endgültige Entscheidungen treffen. Wir kamen 100-500-800 mulenov Modell und es hat funktioniert!
Natürlich übertreibe ich. Diese Ansätze geben jedoch keine schnellen und direkten Antworten.
Wenn Sie über genügend Erfahrung verfügen und verschiedene Optionen ausgewählt haben, können Sie ein Urteil darüber abgeben, warum Ihr System eine solche Entscheidung getroffen hat. Es wird jedoch schwierig sein, das Verhalten des Systems zu korrigieren. Setzen Sie eine Krücke, verschieben Sie den Schwellenwert, fügen Sie einen Datensatz hinzu und nehmen Sie ein anderes Backend-Netzwerk.
Drittes Problem
Das dritte grundlegende Problem ist, dass Gitter keine Logik, sondern Statistiken lehren. Statistisch gesehen diese
Person :

Logisch - nicht sehr ähnlich. Neuronale Netze lernen nichts Kompliziertes, wenn sie nicht gezwungen werden. Sie lernen immer die einfachsten Symptome. Haben Sie Augen, Nase, Kopf? Also dieses Gesicht! Oder geben Sie ein Beispiel, bei dem die Augen nicht das Gesicht bedeuten. Und wieder Millionen von Beispielen.
Unten ist viel Platz
Ich würde sagen, dass es diese drei globalen Probleme sind, die heute die Entwicklung neuronaler Netze und das maschinelle Lernen einschränken. Und wo diese Probleme nicht beschränkt waren, wird bereits aktiv genutzt.
Dies ist das Ende? Neuronale Netze aufgestanden?Unbekannt Aber natürlich hofft jeder nicht.
Es gibt viele Ansätze und Richtungen zur Lösung dieser grundlegenden Probleme, die ich oben behandelt habe. Bisher hat uns keiner dieser Ansätze erlaubt, etwas grundlegend Neues zu tun, um etwas zu lösen, das noch nicht gelöst wurde. Bisher werden alle grundlegenden Projekte auf der Grundlage stabiler Ansätze (Tesla) durchgeführt oder bleiben Testprojekte von Instituten oder Unternehmen (Google Brain, OpenAI).
Grob gesagt ist die Hauptrichtung die Erstellung einer allgemeinen Darstellung der Eingabedaten. In gewissem Sinne "Erinnerung". Das einfachste Beispiel für Speicher sind die verschiedenen "Einbettungs" -Darstellungen von Bildern. Nun, zum Beispiel alle Gesichtserkennungssysteme. Das Netzwerk lernt, eine bestimmte stabile Idee aus dem Gesicht zu bekommen, die nicht von Rotation, Beleuchtung und Auflösung abhängt. Tatsächlich minimiert das Netzwerk die Metrik "verschiedene Gesichter - weit weg" und "identisch - nah".

Ein solches Training erfordert Zehntausende von Beispielen. Das Ergebnis bringt jedoch einige Grundlagen des „One-Shot-Lernens“ mit sich. Jetzt brauchen wir nicht Hunderte von Gesichtern, um uns an eine Person zu erinnern. Nur ein Gesicht, und das war's - wir werden es
herausfinden !
Nur hier ist das Problem ... Das Gitter kann nur ziemlich einfache Objekte lernen. Bei dem Versuch, nicht Gesichter zu unterscheiden, sondern beispielsweise „Menschen nach Kleidung“ (die
Aufgabe der erneuten Identifizierung ), versagt die Qualität um viele Größenordnungen. Und das Netzwerk kann nicht mehr genug offensichtliche Winkeländerungen lernen.
Und aus Millionen von Beispielen zu lernen, ist auch irgendwie mittelmäßige Unterhaltung.
Es wird daran gearbeitet, die Wahlen deutlich zu reduzieren. Sie können beispielsweise sofort eine der ersten
Arbeiten von
Google OneShot Learning abrufen :
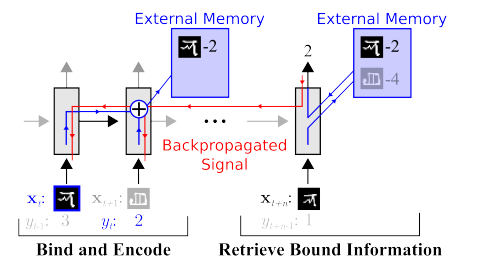
Es gibt viele solcher Werke, zum Beispiel
1 oder
2 oder
3 .
Es gibt ein Minus - normalerweise funktioniert das Training gut an einigen einfachen „MNIST'ovskie-Beispielen“. Und beim Übergang zu komplexen Aufgaben benötigen Sie eine große Basis, ein Objektmodell oder eine Art Magie.
Im Allgemeinen ist die Arbeit am One-Shot-Training ein sehr interessantes Thema. Sie finden viele Ideen. Aber zum größten Teil behindern die beiden Probleme, die ich aufgelistet habe (Vorschulung eines riesigen Datensatzes / Instabilität komplexer Daten), das Lernen sehr.
Auf der anderen Seite nähert sich GAN - generativ wettbewerbsfähige Netzwerke - Embedding. Sie haben wahrscheinlich eine Reihe von Artikeln zu diesem Thema auf Habré gelesen. (
1 ,
2 ,
3 )
Ein Merkmal des GAN ist die Bildung eines internen Zustandsraums (im Wesentlichen dieselbe Einbettung), mit dem Sie ein Bild zeichnen können. Es können
Personen sein , es kann
Handlungen geben .
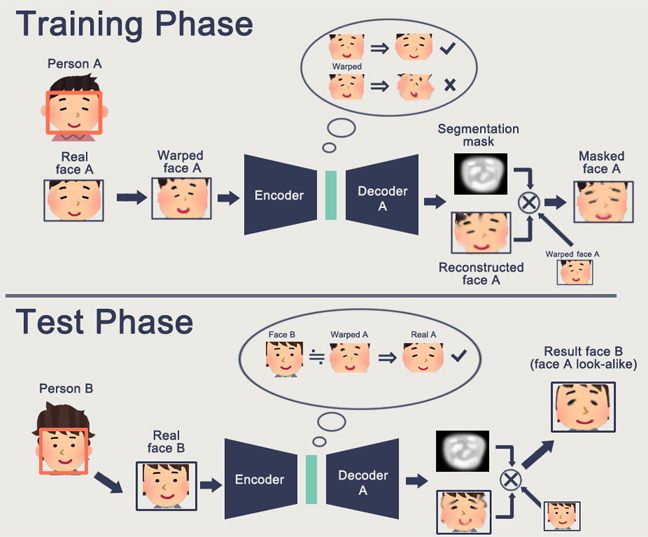
Das GAN-Problem besteht darin, dass es umso schwieriger ist, es in der "Generator-Diskriminator" -Logik zu beschreiben, je komplexer das generierte Objekt ist. Infolgedessen aus realen Anwendungen von GAN, die nur DeepFake zu hören sind, die wiederum die Darstellungen von Individuen manipulieren (für die es eine riesige Basis gibt).
Ich habe nur sehr wenige andere nützliche Anwendungen gefunden. Normalerweise eine Art Pfeifenfälschung beim Zeichnen von Bildern.
Und wieder. Niemand hat ein Verständnis dafür, wie wir uns auf eine bessere Zukunft zubewegen können. Die Darstellung von Logik / Raum in einem neuronalen Netzwerk ist gut. Aber wir brauchen eine große Anzahl von Beispielen, wir verstehen nicht, wie dieses Neuron an sich darstellt, wir verstehen nicht, wie wir das Neuron an eine wirklich komplizierte Idee erinnern können.
Reinforcement Learning ist ein völlig anderer Ansatz. Sicher erinnern Sie sich, wie Google alle in Go geschlagen hat. Jüngste Siege in Starcraft und Dota. Aber hier ist alles andere als rosig und vielversprechend. Das Beste an RL und seiner Komplexität ist
dieser Artikel .
Um kurz zusammenzufassen, was der Autor geschrieben hat:
- Modelle, die sofort einsatzbereit sind, passen in den meisten Fällen nicht schlecht
- Praktische Aufgaben sind auf andere Weise einfacher zu lösen. Boston Dynamics verwendet RL aufgrund seiner Komplexität / Unvorhersehbarkeit / Rechenkomplexität nicht
- Damit RL funktioniert, benötigen Sie eine komplexe Funktion. Es ist oft schwierig zu erstellen / schreiben.
- Es ist schwer, Modelle zu trainieren. Wir müssen viel Zeit damit verbringen, zu schwingen und aus den lokalen Optima herauszukommen
- Infolgedessen ist es schwierig, das Modell zu wiederholen, die Instabilität des Modells bei der geringsten Änderung
- Einige linke Muster werden häufig bis zum Zufallszahlengenerator überfüllt
Der entscheidende Punkt ist, dass RL in der Produktion noch nicht funktioniert. Google hat einige Experimente (
1 ,
2 ). Aber ich habe kein einziges Lebensmittelsystem gesehen.
Speicher Der Nachteil von allem, was oben beschrieben wurde, ist unstrukturiert. Ein Ansatz, um all dies aufzuräumen, besteht darin, dem neuronalen Netzwerk Zugriff auf einen separaten Speicher zu gewähren. Damit sie die Ergebnisse ihrer Schritte dort aufzeichnen und neu schreiben kann. Dann kann das neuronale Netzwerk durch den aktuellen Speicherzustand bestimmt werden. Dies ist klassischen Prozessoren und Computern sehr ähnlich.
Der bekannteste und beliebteste
Artikel stammt von DeepMind:
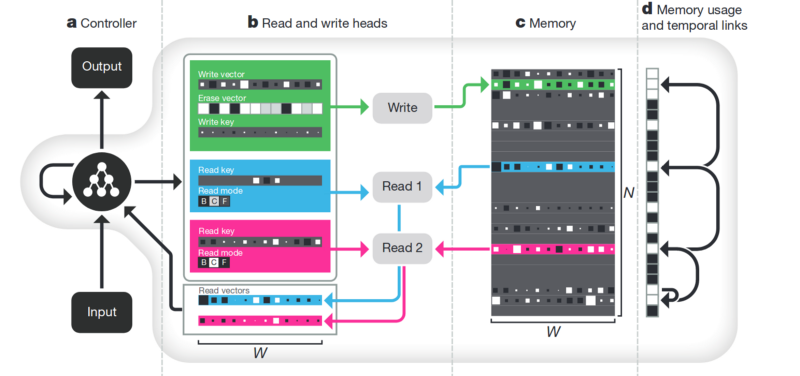
Es scheint, dass hier der Schlüssel zum Verständnis der Intelligenz liegt? Sondern nein. Das System benötigt noch eine große Datenmenge für das Training. Und es funktioniert hauptsächlich mit strukturierten tabellarischen Daten. Zur gleichen Zeit, als Facebook
ein ähnliches Problem
löste , gingen sie den Weg entlang: „Sehen Sie sich die Erinnerung an, machen Sie das Neuron nur komplizierter, aber mehr Beispiele - und es wird sich selbst lernen.“
Entflechtung . Eine andere Möglichkeit, ein aussagekräftiges Gedächtnis zu schaffen, besteht darin, dieselben Einbettungen vorzunehmen, aber wenn Sie lernen, zusätzliche Kriterien einzuführen, die es ihnen ermöglichen, „Bedeutungen“ in ihnen hervorzuheben. Zum Beispiel möchten wir ein neuronales Netzwerk trainieren, um zwischen dem Verhalten einer Person in einem Geschäft zu unterscheiden. Wenn wir dem Standardpfad folgen würden, müssten wir ein Dutzend Netzwerke erstellen. Einer sucht eine Person, der zweite bestimmt, was er tut, der dritte ist sein Alter, der vierte ist das Geschlecht. Separate Logik betrachtet den Teil des Geschäfts, in dem er dafür arbeitet / lernt. Der dritte bestimmt seine Flugbahn usw.
Oder wenn es unendlich viele Daten gäbe, wäre es möglich, ein Netzwerk für alle Arten von Ergebnissen zu trainieren (es ist offensichtlich, dass ein solches Datenarray nicht eingegeben werden kann).
Der Disenthelment-Ansatz sagt es uns - und lassen Sie uns das Netzwerk so trainieren, dass es selbst zwischen Konzepten unterscheiden kann. Damit sie eine Einbettung in das Video bilden kann, in der ein Bereich die Aktion bestimmt, einer - die Position auf dem Boden in der Zeit, einer - die Größe der Person und ein anderer - ihr Geschlecht. Gleichzeitig möchte ich dem Netzwerk während des Trainings fast nie solche Schlüsselkonzepte vorschlagen, sondern es selbst identifizieren und gruppieren. Es gibt nur wenige solcher Artikel (einige davon sind
1 ,
2 ,
3 ) und im Allgemeinen sind sie ziemlich theoretisch.
Diese Richtung sollte jedoch zumindest theoretisch die eingangs aufgeführten Probleme abdecken.
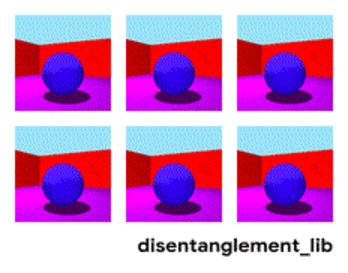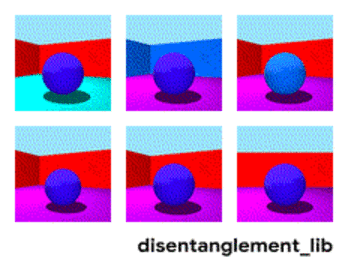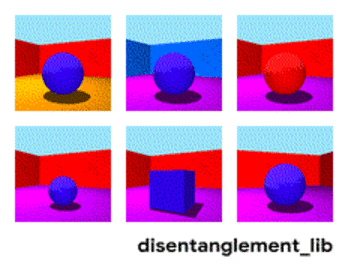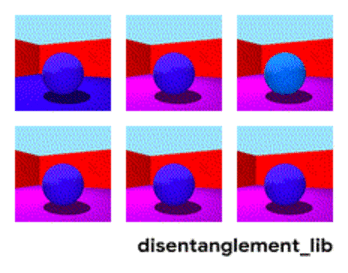
Zerlegung des Bildes nach den Parametern „Wandfarbe / Bodenfarbe / Objektform / Objektfarbe / etc.“

Zersetzung des Gesichts nach den Parametern „Größe, Augenbrauen, Orientierung, Hautfarbe usw.“
Andere
Es gibt viele andere nicht so globale Richtungen, die es uns ermöglichen, die Basis irgendwie zu verkleinern, mit heterogeneren Daten zu arbeiten usw.
Achtung . Es ist wahrscheinlich nicht sinnvoll, dies als separate Methode zu isolieren. Nur ein Ansatz, der andere stärkt. Ihm sind viele Artikel gewidmet (
1 ,
2 ,
3 ). Die Bedeutung von Aufmerksamkeit besteht darin, die Reaktion des Netzwerks auf wichtige Objekte während des Trainings zu stärken. Oft durch eine externe Zielbezeichnung oder ein kleines externes Netzwerk.
3D-Simulation . Wenn Sie eine gute 3D-Engine erstellen, können Sie häufig 90% der Trainingsdaten damit schließen (ich habe sogar ein Beispiel gesehen, in dem fast 99% der Daten mit einer guten Engine geschlossen wurden). Es gibt viele Ideen und Hacks, wie ein auf einer 3D-Engine trainiertes Netzwerk mit realen Daten (Feinabstimmung, Stilübertragung usw.) arbeiten kann. Oft ist es jedoch um mehrere Größenordnungen schwieriger, einen guten Motor herzustellen, als Daten zu sammeln. Beispiele bei der Herstellung von Motoren:
Robotertraining (
Google ,
Braingarden )
Lernen, Waren in einem Geschäft zu
erkennen (aber in zwei Projekten, die wir durchgeführt haben, haben wir ruhig darauf verzichtet).
Training bei Tesla (wieder das Video, das oben war).
Schlussfolgerungen
Der ganze Artikel ist gewissermaßen eine Schlussfolgerung. Wahrscheinlich war die Hauptbotschaft, die ich machen wollte, "das Werbegeschenk ist vorbei, die Neuronen geben keine einfacheren Lösungen." Jetzt müssen wir hart arbeiten, um komplexe Lösungen zu entwickeln. Oder arbeiten Sie hart an komplexen wissenschaftlichen Berichten.
Im Allgemeinen ist das Thema umstritten. Vielleicht haben Leser interessantere Beispiele?