Anstatt mitzumachen
Zu Beginn unseres Blogs haben wir geschrieben,
was IPONWEB tut - wir automatisieren die Anzeige von Anzeigen im Internet. Unsere Systeme treffen Entscheidungen nicht nur auf der Grundlage historischer Daten, sondern nutzen auch aktiv die in Echtzeit erhaltenen Informationen. Bei DSP (Demand Side Platform - eine Werbeplattform für Werbetreibende) muss der Werbetreibende (oder sein Vertreter) ein Werbebanner (Creative) in einem der Formate (Bild, Video, interaktives Banner, Bild + Text usw.) erstellen und hochladen. Wählen Sie die Zielgruppe der Benutzer aus, denen dieses Banner angezeigt werden soll, legen Sie fest, wie oft Werbung einem Benutzer, in welchen Ländern, auf welchen Websites, auf welchen Geräten angezeigt werden kann, und spiegeln Sie dies (und vieles mehr) in den Targeting-Einstellungen der Werbekampagne wider sowie verteilen Sie Werbung das Budget s. Für SSP (Supply Side Platform - eine Werbeplattform für Eigentümer von Werbeplattformen) muss der Websitebesitzer (mobile Anwendung, Werbetafel, Fernsehkanal) die Werbespots auf seiner Website bestimmen und beispielsweise angeben, welche Werbekategorien er auf diesen anzeigen möchte. Alle diese Einstellungen werden manuell im Voraus (nicht zum Zeitpunkt der Anzeigenschaltung) über die Benutzeroberfläche vorgenommen. In diesem Artikel werde ich über unseren Ansatz zum Aufbau solcher Schnittstellen sprechen, vorausgesetzt, es gibt viele, sie sind einander ähnlich und weisen gleichzeitig individuelle Merkmale auf.
Wie alles begann
Wir haben bereits 2007 mit dem Werbegeschäft begonnen, aber nicht sofort Schnittstellen erstellt, sondern erst 2014. Wir beschäftigen uns traditionell mit der Entwicklung kundenspezifischer Plattformen, die vollständig auf die Besonderheiten des Geschäfts jedes einzelnen Kunden zugeschnitten sind - unter den Dutzenden von Plattformen, die wir gebaut haben, gibt es keine zwei identischen. Und da unsere Werbeplattformen ohne Einschränkungen der Anpassungsmöglichkeiten gestaltet wurden, musste die Benutzeroberfläche die gleichen Anforderungen erfüllen.
Als wir vor fünf Jahren die erste Anfrage nach einer Werbeschnittstelle für DSP erhielten, fiel unsere Wahl auf den beliebten und praktischen Technologie-Stack: JavaScript und AngularJS im Frontend und das Backend auf Python, Django und Django Rest Framework (DRF). Daraus wurde das gewöhnlichste Projekt gemacht, dessen Hauptaufgabe darin bestand, CRUD-Funktionalität bereitzustellen. Das Ergebnis seiner Arbeit war eine Einstellungsdatei für das Werbesystem im XML-Format. Nun mag ein solches Interaktionsprotokoll seltsam erscheinen, aber wie wir bereits besprochen haben, haben wir mit den ersten Werbesystemen (auch ohne Benutzeroberfläche) begonnen, die „Null“ zu erstellen, und dieses Format wurde bis heute beibehalten.
Nach dem erfolgreichen Start des ersten Projekts dauerte Folgendes nicht lange. Dies war auch die Benutzeroberfläche für den DSP, und die Anforderungen für sie waren dieselben wie für das erste Projekt. Fast. Trotz der Tatsache, dass alles sehr ähnlich war, versteckte sich der Teufel in den Details - es gibt eine etwas andere Hierarchie von Objekten, ein paar Felder werden dort hinzugefügt ... Der naheliegendste Weg, um das zweite Projekt zu erhalten, das dem ersten sehr ähnlich ist, aber Verbesserungen aufweist, war die Replikationsmethode, die wir verwendet haben . Und es gab Probleme, die vielen bekannt waren - neben dem „guten“ Code wurden auch Fehler kopiert, für die Patches von Hand verteilt werden mussten. Dasselbe geschah mit all den neuen Funktionen, die in allen aktiven Projekten eingeführt wurden.
In diesem Modus war es möglich, zu arbeiten, während es nur wenige Projekte gab, aber als ihre Anzahl 20 überschritt, wurde der bekannte Ansatz nicht mehr skaliert. Aus diesem Grund haben wir beschlossen, die gemeinsamen Teile der Projekte in die Bibliothek zu übertragen, aus der das Projekt die benötigten Komponenten verbindet. Wenn ein Fehler erkannt wird, wird er einmal in der Bibliothek repariert und automatisch an Projekte verteilt, wenn die Bibliotheksversion aktualisiert wird. Dasselbe gilt für die Wiederverwendung neuer Funktionen.
Konfiguration und Terminologie
Wir hatten mehrere Iterationen bei der Implementierung dieses Ansatzes, und alle flossen evolutionär ineinander, beginnend mit unserem üblichen Projekt über reines DRF. In der neuesten Implementierung wird unser Projekt mit JSON-basiertem DSL beschrieben (siehe Bild). Dieser JSON beschreibt sowohl die Struktur der Projektkomponenten als auch deren Verbindungen, und sowohl das Frontend als auch das Backend können sie lesen.
Nach der Initialisierung der Angular-Anwendung fordert das Frontend eine JSON-Konfiguration vom Backend an. Das Backend gibt nicht nur eine statische Konfigurationsdatei an, sondern verarbeitet sie zusätzlich, indem es verschiedene Metadaten hinzufügt oder Teile der Konfiguration löscht, die für Teile des Systems verantwortlich sind, auf die der Benutzer nicht zugreifen kann. Auf diese Weise können Sie verschiedenen Benutzern die Benutzeroberfläche auf unterschiedliche Weise anzeigen, einschließlich interaktiver Formulare, CSS-Stile der gesamten Anwendung und spezifischer Designelemente. Letzteres gilt insbesondere für Benutzeroberflächen von Plattformen, die von verschiedenen Clienttypen mit unterschiedlichen Rollen und Zugriffsebenen verwendet werden.

Das Backend liest die Konfiguration im Gegensatz zum Frontend einmal in der Initialisierungsphase der Django-Anwendung. Auf diese Weise wird der gesamte Funktionsumfang im Backend aufgezeichnet und der Zugriff auf verschiedene Teile des Systems im laufenden Betrieb überprüft.
Bevor ich zum interessantesten Teil übergehe - der Datenbankstruktur - möchte ich einige Konzepte vorstellen, die wir verwenden, wenn wir über die Struktur unserer Projekte sprechen, um mit dem Leser auf der gleichen Wellenlänge zu sein.
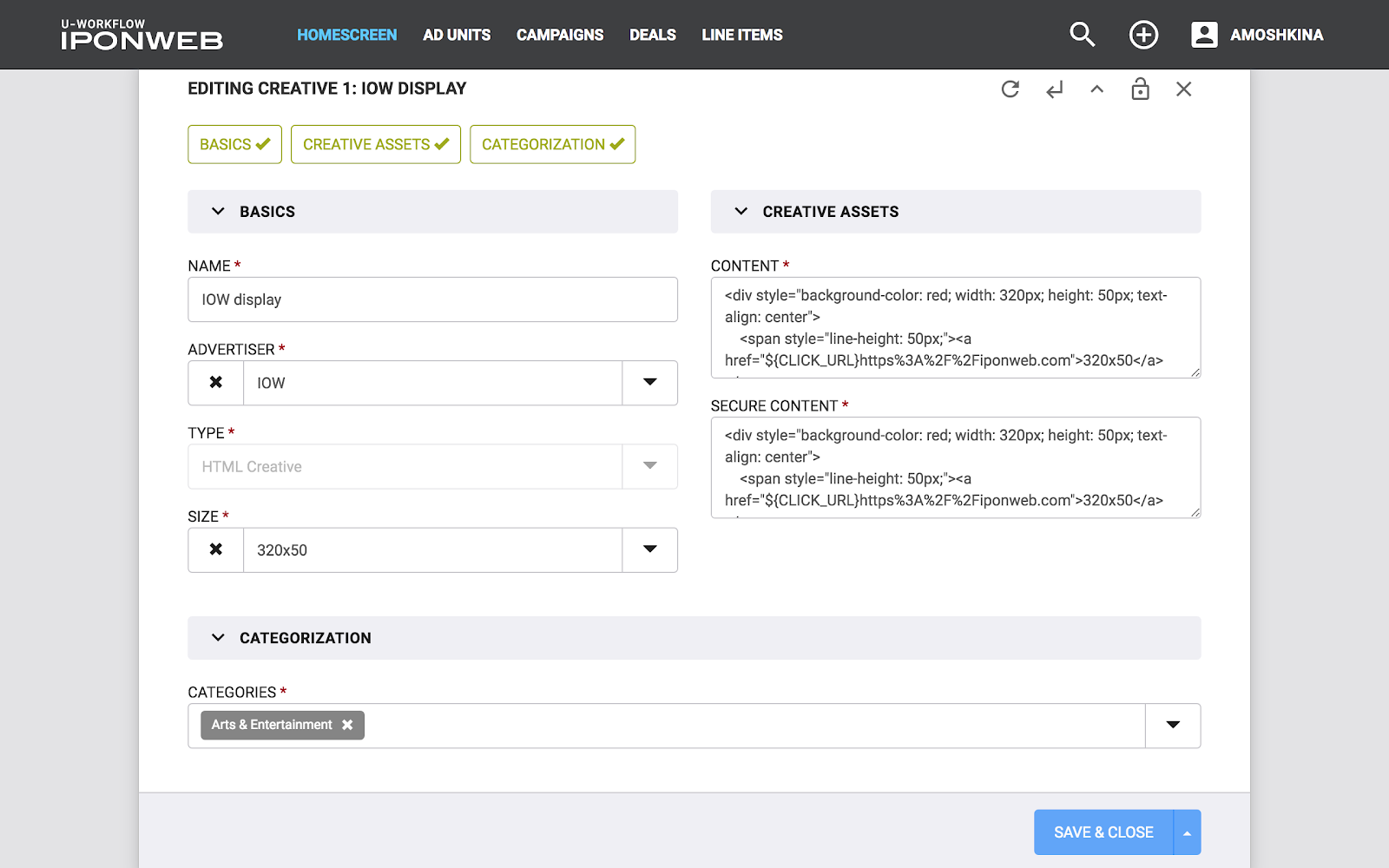
Diese Konzepte - Entität und Merkmal - sind auf dem Dateneingabeformular gut dargestellt (siehe Bild). Das gesamte Formular ist Entität, und die einzelnen Felder darauf sind Feature. Das Bild zeigt auch den Endpunkt (nur für den Fall). Entity ist also ein unabhängiges Objekt im System, an dem CRUD-Operationen ausgeführt werden können, während Feature nur Teil von „etwas mehr“, Teil von Entity ist. Mit Feature können Sie keine CRUD-Operationen ausführen, ohne an eine Entität gebunden zu sein. Beispiel: Das Budget einer Werbekampagne ohne Bezugnahme auf die Kampagne selbst ist einfach eine Zahl, die ohne Informationen zur übergeordneten Kampagne nicht verwendet werden kann.
Die gleichen Konzepte finden Sie in der JSON-Konfiguration des Projekts (siehe Abbildung).

Datenbankstruktur
Der interessanteste Teil unserer Projekte ist die Datenbankstruktur und die Mechanik, die sie unterstützt. Nachdem wir PostgreSQL für die ersten Versionen unserer Projekte verwendet haben, bleiben wir bei dieser Technologie bis heute. Gleichzeitig nutzen wir Django ORM aktiv. In frühen Implementierungen haben wir das Standardmodell der Beziehungen zwischen Objekten (Entitäten) auf dem Fremdschlüssel verwendet. Dieser Ansatz verursachte jedoch Schwierigkeiten, als die Hierarchie der Beziehungen geändert werden musste. So mussten beispielsweise in der Standardhierarchie der DSP-Geschäftseinheit -> Werbetreibenden -> Kampagne einige Kunden die Agenturebene eingeben (Geschäftseinheit -> Agentur -> Werbetreibender -> ...). Aus diesem Grund haben wir die Verwendung von Fremdschlüsseln schrittweise aufgegeben und Verknüpfungen zwischen Objekten mithilfe von Many To Many-Verknüpfungen über eine separate Tabelle organisiert, die wir als "LinkRegistry" bezeichnen.
Darüber hinaus haben wir den Hardcode zum Füllen von Entitäten nach und nach aufgegeben und begonnen, die meisten Felder in separaten Tabellen zu speichern und sie auch über "LinkRegistry" zu verknüpfen (siehe Bild). Warum wurde das gebraucht? Für jeden Client kann der Inhalt der Entität variieren - einige Felder werden hinzugefügt oder gelöscht. Es stellt sich heraus, dass wir in jeder Entität eine Obermenge von Feldern für alle unsere Kunden speichern müssen. Gleichzeitig müssen sie alle optional gemacht werden, damit die Pflichtfelder „Alien“ die Arbeit nicht beeinträchtigen.

Betrachten Sie das Beispiel im Bild: Hier wird die Datenbankstruktur für das Creative mit einem zusätzlichen Feld beschrieben - `image_url`. In der Kreativtabelle wird nur die ID gespeichert, und image_url wird in einer separaten Tabelle gespeichert. Ihre Beziehung wird durch einen anderen Eintrag in der Tabelle LinkRegistry beschrieben. Daher wird dieses Motiv durch drei Einträge beschrieben, einen in jeder der Tabellen. Um ein solches Motiv zu speichern, müssen Sie in jedem von ihnen einen Eintrag vornehmen und ihn auf die gleiche Weise lesen. Besuchen Sie 3 Tabellen. Es wäre sehr unpraktisch, eine solche Verarbeitung jedes Mal von Grund auf neu zu schreiben, daher abstrahiert unsere Bibliothek all diese Details vom Programmierer. Um mit Daten zu arbeiten, verwenden Django und DRF Modelle und Serialisierer, die durch Code beschrieben werden. In unseren Projekten wird der Satz von Feldern in Modellen und Serialisierern zur Laufzeit durch die JSON-Konfiguration bestimmt. Modellklassen werden dynamisch (mithilfe der Typfunktion) erstellt und in einem speziellen Register gespeichert, von wo aus sie während des Anwendungsbetriebs verfügbar sind. Für diese Modelle und Serializer verwenden wir auch spezielle Basisklassen, die bei der Arbeit mit nicht standardmäßigen Basisstrukturen hilfreich sind.
Wenn Sie ein neues Objekt speichern (oder ein vorhandenes aktualisieren), werden die vom Front-End empfangenen Daten in den Serializer übertragen, wo sie validiert werden. Es gibt keine ungewöhnlichen Standard-DRF-Mechanismen. Das Speichern und Aktualisieren wird hier jedoch neu definiert. Der Serializer weiß immer, mit welchem Modell er arbeitet, und gemäß der internen Darstellung unseres dynamischen Modells kann er verstehen, in welche Tabelle die Daten des nächsten Felds gestellt werden sollen. Wir codieren diese Informationen in benutzerdefinierten Modellfeldern (denken Sie daran, wie der "ForeignKey" in Django beschrieben wird - ein verwandtes Modell wird innerhalb des Feldes übergeben, wir tun dasselbe). In diesen speziellen Feldern wird auch die Notwendigkeit abstrahiert, LinkRegistry mithilfe des Deskriptormechanismus einen dritten Bindungsdatensatz hinzuzufügen - in dem Code, den Sie "creative.image_url =" http: // foo.bar "schreiben, und in der überschriebenen Methode" __set__ ", in der wir aufzeichnen `LinkRegistry`.
Dies gilt für das Schreiben in die Datenbank. Und jetzt beschäftigen wir uns mit dem Lesen. Wie wird ein Tupel aus einer Datenbank gezogen, das in eine Django-Modellinstanz konvertiert wurde? Im Basis-Django-Modell gibt es eine "from_db" -Methode, die für jedes Tupel aufgerufen wird, das empfangen wird, wenn eine Abfrage in "queryset" ausgeführt wird. Am Eingang erhält es ein Tupel und gibt die Instanz des Django-Modells zurück. Wir haben diese Methode in unserem Basismodell neu definiert, wobei wir gemäß dem Tupel des Hauptmodells (wo nur "id" eingeht) Daten aus anderen verwandten Tabellen abrufen und mit diesem vollständigen Satz das Modell instanziieren. Natürlich haben wir auch daran gearbeitet, den Django-Prefetching-Mechanismus für unseren nicht standardmäßigen Anwendungsfall zu optimieren.
Testen
Unser Framework ist ziemlich komplex, deshalb schreiben wir viele Tests. Wir haben Tests sowohl für das Frontend als auch für das Backend. Ich werde im Detail auf Backend-Tests eingehen.
Um die Tests durchzuführen, verwenden wir pytest. Im Backend gibt es zwei große Testklassen: Tests unseres Frameworks (wir nennen es auch den „Kern“) und Projekttests.
Im Kernel schreiben wir sowohl isolierte als auch funktionale Komponententests zum Testen von Endpunkten mit dem Pytest-Django-Plugin. Im Allgemeinen wird die gesamte Arbeit mit der Datenbank hauptsächlich durch Anforderungen an die API getestet - wie dies in der Produktion der Fall ist.
Funktionstests können eine JSON-Konfiguration angeben. Um nicht an die Designterminologie gebunden zu werden, verwenden wir "Dummy" -Namen für Entitäten, mit denen wir unsere Funktionen im Kernel testen ("Emma", "Alla", "Karl", "Maria" usw.). Da wir durch das Schreiben der image_url-Funktion das Bewusstsein des Entwicklers nicht auf die Tatsache beschränken möchten, dass sie nur mit der Creative-Entität verwendet werden kann - die Features und Entitäten sind universell und können in beliebigen Kombinationen miteinander verbunden werden, die für einen bestimmten Client relevant sind.
Bei Testprojekten werden in allen Testfällen die Produktionskonfiguration ausgeführt, keine Dummy-Entitäten, da es für uns wichtig ist, genau zu überprüfen, mit was der Client arbeiten wird. Im Projekt können Sie alle Tests schreiben, die die Funktionen der Geschäftslogik des Projekts abdecken. Gleichzeitig können grundlegende CRUD-Tests vom Kernel aus mit dem Projekt verbunden werden. Sie sind allgemein geschrieben und können mit jedem Projekt verbunden werden: Ein Feature-Test kann die JSON-Konfiguration eines Projekts lesen, bestimmen, mit welchen Entitäten dieses Feature verbunden ist, und nur die erforderlichen Entitäten überprüfen. Zur Erleichterung der Vorbereitung von Testdaten haben wir ein System von Helfern entwickelt, die auch Testdatensätze basierend auf der JSON-Konfiguration erstellen können. Einen besonderen Platz beim Testen von Projekten einnehmen E2E-Tests an Winkelmessern, die alle Grundfunktionen des Projekts testen. Diese Tests werden auch mit JSON beschrieben. Sie werden von Front-End-Entwicklern geschrieben und unterstützt.
Nachwort
In diesem Artikel haben wir den von IPONWEB in der UI-Abteilung entwickelten modularen Entwurfsansatz untersucht. Diese Lösung ist seit drei Jahren erfolgreich in der Produktion tätig. Diese Lösung weist jedoch noch eine Reihe von Einschränkungen auf, die es uns nicht ermöglichen, uns auf unseren Lorbeeren auszuruhen. Erstens ist unsere Codebasis immer noch recht komplex. Zweitens ist der Basiscode, der dynamische Modelle unterstützt, mit kritischen Komponenten wie Suche, Massenladen von Objekten, Zugriffsrechten und anderen verknüpft. Aus diesem Grund können Änderungen an einer der Komponenten die anderen erheblich beeinflussen. Um diese Einschränkungen zu beseitigen, verarbeiten wir unsere Bibliothek weiterhin aktiv, teilen sie in viele unabhängige Teile auf und reduzieren die Komplexität des Codes. Wir werden Sie in den folgenden Artikeln über die Ergebnisse informieren.
Dieser Artikel ist eine erweiterte Abschrift meiner Präsentation auf der MoscowPythonConf ++ 2019, daher teile ich auch Links zu
Videos und
Folien .