C ++ Enterprise Edition
Was ist die "Enterprise Edition"
Überraschenderweise habe ich während meiner gesamten IT-Zeit noch nie jemanden "Enterprise Edition" über eine Programmiersprache sagen hören, außer Java. Schließlich schreiben die Benutzer Anwendungen für das Unternehmenssegment in vielen Programmiersprachen, und die Entitäten, mit denen Programmierer arbeiten, sind ähnlich, wenn nicht identisch. Und insbesondere für c ++ möchte ich die Lücke des Unternehmertums schließen und zumindest darüber erzählen.
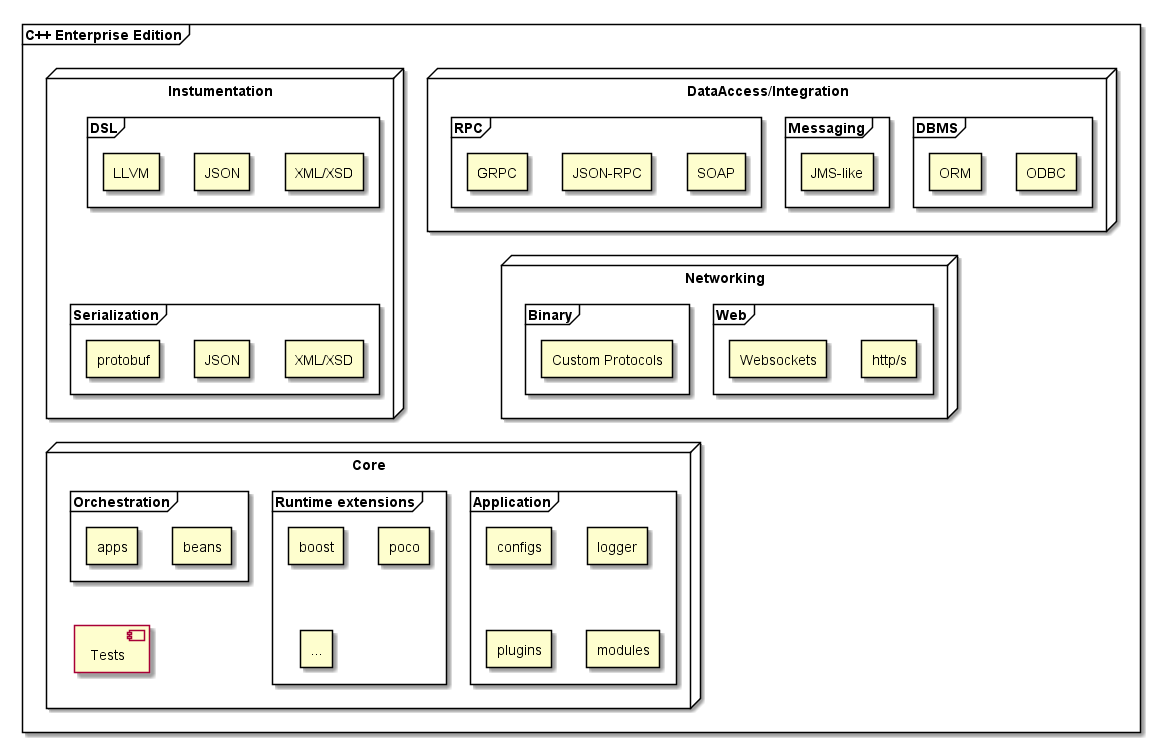
In C ++ ist die "Enterprise Edition" eine Teilmenge der Sprache und Bibliotheken, mit der Sie "schnell" [plattformübergreifende] Anwendungen für lose gekoppelte modulare Systeme mit verteilter und / oder Clusterarchitektur sowie mit angewandter Geschäftslogik und in der Regel hoher Last entwickeln können.
Um unser Gespräch fortzusetzen, müssen zunächst die Konzepte von Anwendung , Modul und Plug-In vorgestellt werden
- Eine Anwendung ist eine ausführbare Datei, die als Systemdienst ausgeführt werden kann, eine eigene Konfiguration hat, Eingabeparameter akzeptiert und eine modulare Plug-In-Struktur aufweist.
- Ein Modul ist eine Implementierung einer Schnittstelle, die sich in einer Anwendung oder Geschäftslogik befindet.
- Ein Plugin ist eine dynamisch geladene Bibliothek, die eine oder mehrere Schnittstellen oder einen Teil einer Geschäftslogik implementiert.
Alle Anwendungen, die ihre einzigartige Arbeit ausführen, benötigen normalerweise systemweite Mechanismen wie Datenzugriff (DBMS), Informationsaustausch über einen gemeinsamen Bus (JMS), Ausführung verteilter und lokaler Skripte unter Wahrung der Konsistenz (Transaktionen) und Verarbeitung eingehender Anforderungen Zum Beispiel über das http (s) (fastcgi) -Protokoll oder über Websockets usw. Jede Anwendung sollte in der Lage sein, ihre Module (OSGI) zu orchestrieren, und in einem verteilten System sollte sie in der Lage sein, Anwendungen zu orchestrieren.
Ein Beispiel für ein verteiltes schwach verbundenes System
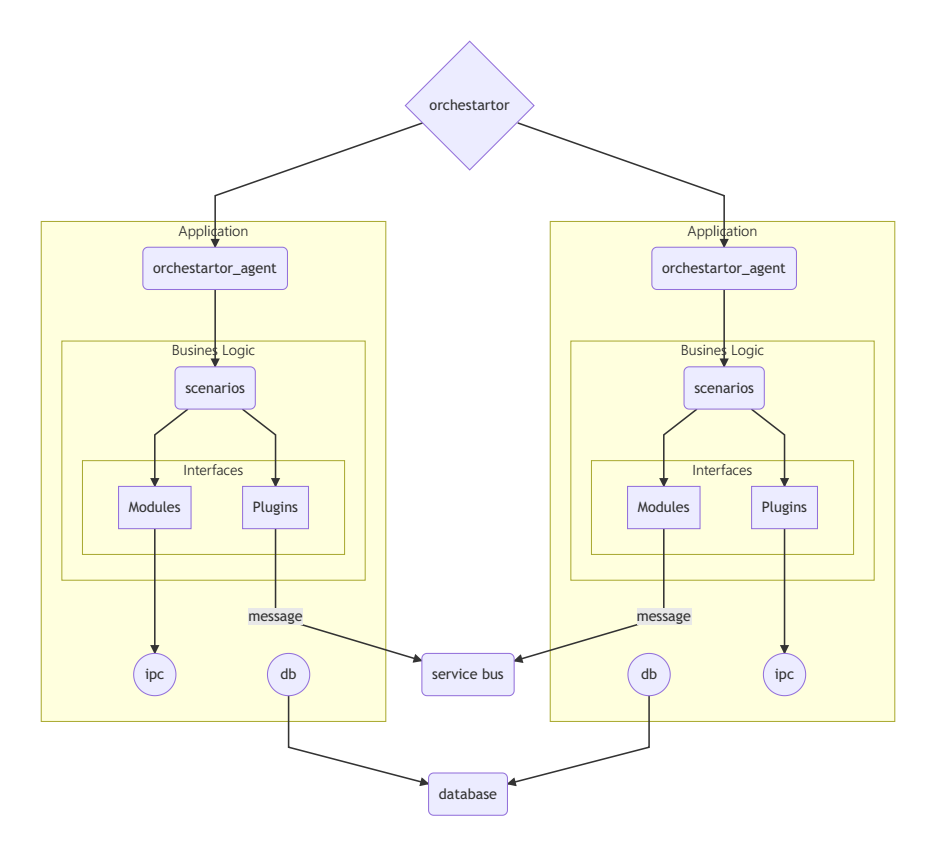
App
Ein Beispiel für ein Enterprise Enterprise Server-Anwendungsschema.

Ich habe bereits eine allgemeine Definition der Anwendung gegeben. Lassen Sie uns also sehen, was sich jetzt in der C ++ - Welt für die Implementierung dieses Konzepts befindet. Die ersten, die die Implementierung der Anwendung zeigten, waren grafische Frameworks wie Qt und GTK, aber ihre Anwendungsversionen gingen zunächst davon aus, dass die Anwendung ein grafisches „Fenster“ mit ihrem Kontext war, und erst nach einer Weile erschien eine allgemeine Vision der Anwendung, beispielsweise als Systemdienst, z. qtservice . Ich möchte jedoch kein bedingt grafisches Framework für eine Serviceaufgabe ziehen. Schauen wir uns also nicht-grafische Bibliotheken an. Und Boost kommt zuerst in den Sinn ... Aber leider gibt es keine Boost.Application und dergleichen in der Liste der offiziellen Bibliotheken. Es gibt ein separates Projekt Boost.Application . Das Projekt ist sehr interessant, aber meiner Meinung nach ausführlich, obwohl die Ideologie des Boost respektiert wird. Hier ist eine Beispielanwendung von Boost.Application
#define BOOST_ALL_DYN_LINK #define BOOST_LIB_DIAGNOSTIC #define BOOST_APPLICATION_FEATURE_NS_SELECT_BOOST #include <fstream> #include <iostream> #include <boost/application.hpp> using namespace boost; // my application code class myapp { public: myapp(application::context& context) : context_(context) {} void worker() { // ... while (st->state() != application::status::stopped) { boost::this_thread::sleep(boost::posix_time::seconds(1)); if (st->state() == application::status::paused) my_log_file_ << count++ << ", paused..." << std::endl; else my_log_file_ << count++ << ", running..." << std::endl; } } // param int operator()() { // launch a work thread boost::thread thread(&myapp::worker, this); context_.find<application::wait_for_termination_request>()->wait(); return 0; } bool stop() { my_log_file_ << "Stoping my application..." << std::endl; my_log_file_.close(); return true; // return true to stop, false to ignore } private: std::ofstream my_log_file_; application::context& context_; }; int main(int argc, char* argv[]) { application::context app_context; // auto_handler will automatically add termination, pause and resume (windows) // handlers application::auto_handler<myapp> app(app_context); // to handle args app_context.insert<application::args>( boost::make_shared<application::args>(argc, argv)); // my server instantiation boost::system::error_code ec; int result = application::launch<application::server>(app, app_context, ec); if (ec) { std::cout << "[E] " << ec.message() << " <" << ec.value() << "> " << std::endl; } return result; }
Das obige Beispiel definiert die myapp Anwendung mit ihrem Haupt-Worker-Thread und den Mechanismus zum Starten dieser Anwendung.
Als Ergänzung werde ich ein ähnliches Beispiel aus dem Pocoproject- Framework geben
#include <iostream> #include <sstream> #include "Poco/AutoPtr.h" #include "Poco/Util/AbstractConfiguration.h" #include "Poco/Util/Application.h" #include "Poco/Util/HelpFormatter.h" #include "Poco/Util/Option.h" #include "Poco/Util/OptionSet.h" using Poco::AutoPtr; using Poco::Util::AbstractConfiguration; using Poco::Util::Application; using Poco::Util::HelpFormatter; using Poco::Util::Option; using Poco::Util::OptionCallback; using Poco::Util::OptionSet; class SampleApp : public Application { public: SampleApp() : _helpRequested(false) {} protected: void initialize(Application &self) { loadConfiguration(); Application::initialize(self); } void uninitialize() { Application::uninitialize(); } void reinitialize(Application &self) { Application::reinitialize(self); } void defineOptions(OptionSet &options) { Application::defineOptions(options); options.addOption( Option("help", "h", "display help information on command line arguments") .required(false) .repeatable(false) .callback(OptionCallback<SampleApp>(this, &SampleApp::handleHelp))); } void handleHelp(const std::string &name, const std::string &value) { _helpRequested = true; displayHelp(); stopOptionsProcessing(); } void displayHelp() { HelpFormatter helpFormatter(options()); helpFormatter.setCommand(commandName()); helpFormatter.setUsage("OPTIONS"); helpFormatter.setHeader( "A sample application that demonstrates some of the features of the " "Poco::Util::Application class."); helpFormatter.format(std::cout); } int main(const ArgVec &args) { if (!_helpRequested) { logger().information("Command line:"); std::ostringstream ostr; logger().information(ostr.str()); logger().information("Arguments to main():"); for (const auto &it : args) { logger().information(it); } } return Application::EXIT_OK; } private: bool _helpRequested; }; POCO_APP_MAIN(SampleApp)
Ich mache Sie darauf aufmerksam, dass die Anwendung Mechanismen zum Protokollieren, Herunterladen von Konfigurationen und Verarbeitungsoptionen enthalten sollte.
Zum Verarbeiten von Optionen gibt es beispielsweise:
So konfigurieren Sie:
Für das Journaling:
Schwäche, Module und Plugins.
Eine Schwäche im "Unternehmens" -System ist die Möglichkeit einer schnellen und schmerzlosen Substitution bestimmter Mechanismen. Dies gilt sowohl für Module innerhalb der Anwendung als auch für die Anwendungen selbst sowie für Implementierungen, beispielsweise Microservices. Was haben wir aus Sicht von C ++? Mit Modulen ist alles schlecht, obwohl sie Schnittstellen implementieren, aber sie leben in einer "kompilierten" Anwendung, so dass es keine schnelle Änderung gibt, aber Plugins helfen! Mit Hilfe dynamischer Bibliotheken können Sie nicht nur eine schnelle Ersetzung organisieren, sondern auch den gleichzeitigen Betrieb von zwei verschiedenen Versionen. Es gibt eine ganze Welt von "Remote Procedure Call", auch bekannt als RPC. Die Suchmechanismen für Schnittstellenimplementierungen in Verbindung mit RPC haben etwas Ähnliches wie OSGI aus der Java-Welt hervorgebracht. Es ist großartig, dies im C ++ - Ökosystem zu unterstützen, und es gibt eines, hier einige Beispiele:
Beispielmodul für den POCO OSP "Anwendungsserver"
#include "Poco/OSP/BundleActivator.h" #include "Poco/OSP/BundleContext.h" #include "Poco/ClassLibrary.h" namespace HelloBundle { class BundleActivator: public Poco::OSP::BundleActivator { public: void start(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Hello, world!"); } void stop(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Goodbye!"); } }; }
Beispielmodul für Apache Celix "Anwendungsserver"
#include "Bar.h" #include "BarActivator.h" using namespace celix::dm; DmActivator* DmActivator::create(DependencyManager& mng) { return new BarActivator(mng); } void BarActivator::init() { std::shared_ptr<Bar> bar = std::shared_ptr<Bar>{new Bar{}}; Properties props; props["meta.info.key"] = "meta.info.value"; Properties cProps; cProps["also.meta.info.key"] = "also.meta.info.value"; this->cExample.handle = bar.get(); this->cExample.method = [](void *handle, int arg1, double arg2, double *out) { Bar* bar = static_cast<Bar*>(handle); return bar->cMethod(arg1, arg2, out); }; mng.createComponent(bar) //using a pointer a instance. Also supported is lazy initialization (default constructor needed) or a rvalue reference (move) .addInterface<IAnotherExample>(IANOTHER_EXAMPLE_VERSION, props) .addCInterface(&this->cExample, EXAMPLE_NAME, EXAMPLE_VERSION, cProps) .setCallbacks(&Bar::init, &Bar::start, &Bar::stop, &Bar::deinit); }
Es sollte beachtet werden, dass in verteilten schwach verbundenen Systemen Mechanismen erforderlich sind, die Transaktionsoperationen sicherstellen, aber im Moment gibt es für C ++ nichts Ähnliches. Das heißt, So wie es in einer Anwendung keine Möglichkeit gibt, innerhalb einer Transaktion eine Anforderung an die Datenbank, die Datei und den ESB zu stellen, gibt es keine Möglichkeit für verteilte Vorgänge. Natürlich kann alles geschrieben werden, aber es gibt nichts Verallgemeinertes. Jemand wird sagen, dass es natürlich software transactional memory gibt, aber es wird nur das Schreiben der Transaktionsmechanismen selbst erleichtern.
Toolkit
Von all den vielen Hilfstools möchte ich Serialisierung und DSL hervorheben, weil Durch ihre Anwesenheit können Sie viele andere Komponenten und Szenarien implementieren.
Serialisierung
Bei der Serialisierung wird eine Datenstruktur in eine Folge von Bits übersetzt. Die Umkehrung der Serialisierungsoperation ist die Deserialisierungsoperation (Strukturierungsoperation), bei der der Anfangszustand der Datenstruktur aus der Wikipedia- Bitsequenz wiederhergestellt wird. Im Kontext von C ++ ist es wichtig zu verstehen, dass es heute keine Möglichkeit gibt, Objekte zu serialisieren und an ein anderes Programm zu übertragen, das zuvor nichts über dieses Objekt wusste. In diesem Fall meine ich ein Objekt als Implementierung einer bestimmten Klasse mit Feldern und Methoden. Daher werde ich zwei Hauptansätze hervorheben, die in der C ++ - Welt verwendet werden:
- Serialisierung im Binärformat
- Serialisierung zum formalen Format
In der Literatur und im Internet gibt es häufig eine Trennung in Binär- und Textformat, aber ich denke, diese Trennung ist nicht ganz korrekt. Beispielsweise speichert MsgPack keine Informationen über den Objekttyp. Dementsprechend erhält der Programmierer die Kontrolle über die korrekte Anzeige und das MsgPack-Format ist binär. Im Gegensatz dazu speichert Protobuf alle Metainformationen in einer Zwischendarstellung, die die Verwendung zwischen verschiedenen Programmiersprachen ermöglicht, während Protobuf ebenfalls binär ist.
Also, der Serialisierungsprozess, warum brauchen wir ihn? Um alle Nuancen aufzudecken, brauchen wir einen weiteren Artikel, den ich anhand von Beispielen erklären möchte. Die Serialisierung ermöglicht es, unter Beibehaltung einer Programmiersprache, Software-Entitäten (Klassen, Strukturen) zu „packen“, um sie über das Netzwerk zu übertragen, um sie dauerhaft zu speichern, beispielsweise in Dateien und anderen Skripten, die uns ohne Serialisierung dazu zwingen, unsere eigenen Protokolle zu erfinden und Hardware zu berücksichtigen und Softwareplattform, Textcodierung usw.
Hier sind einige Beispielbibliotheken für die Serialisierung:
DSL
Domain Specific Language - eine Programmiersprache für Ihren Themenbereich. Wenn wir uns mit der Automatisierung eines bestimmten Unternehmens beschäftigen, werden wir mit dem Themenbereich des Kunden konfrontiert und beschreiben alle Geschäftsprozesse in Bezug auf den Themenbereich. Sobald es jedoch um die Programmierung geht, sind Programmierer zusammen mit Analysten damit beschäftigt, Geschäftsprozesskonzepte in Konzepte abzubilden Framework und Programmiersprache. Und wenn es nicht eine bestimmte Anzahl von Geschäftsprozessen gibt und der Themenbereich streng genug definiert ist, ist es sinnvoll, ein eigenes DSL zu erstellen, die meisten vorhandenen Szenarien zu implementieren und neue hinzuzufügen. In der C ++ - Welt gibt es nicht viele Möglichkeiten für eine "schnelle" Implementierung Ihres DSL. Es gibt natürlich Mechanismen zum Einbetten von Lua, Javascript und anderen Programmiersprachen in C ++ - ein Programm, aber wer braucht Schwachstellen und eine möglicherweise unkontrollierte Ausführungs-Engine für "alles" ?! Daher analysieren wir die Tools, mit denen Sie DSL selbst ausführen können.
Die Boost.Proto-Bibliothek wurde nur zum Erstellen Ihres eigenen DSL entwickelt. Dies ist der direkte Zweck. Hier ein Beispiel
#include <iostream> #include <boost/proto/proto.hpp> #include <boost/typeof/std/ostream.hpp> using namespace boost; proto::terminal< std::ostream & >::type cout_ = { std::cout }; template< typename Expr > void evaluate( Expr const & expr ) { proto::default_context ctx; proto::eval(expr, ctx); } int main() { evaluate( cout_ << "hello" << ',' << " world" ); return 0; }
Flex und Bison werden verwendet, um Lexer und Parser für Ihre Grammatik zu generieren. Die Syntax ist nicht einfach, löst das Problem jedoch effizient.
Beispielcode zum Generieren eines Lexers
%{ #include <math.h> %} DIGIT [0-9] ID [az][a-z0-9]* %% {DIGIT}+ { printf( "An integer: %s (%d)\n", yytext, atoi( yytext ) ); } {DIGIT}+"."{DIGIT}* { printf( "A float: %s (%g)\n", yytext, atof( yytext ) ); } if|then|begin|end|procedure|function { printf( "A keyword: %s\n", yytext ); } {ID} printf( "An identifier: %s\n", yytext ); "+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext ); "{"[^}\n]*"}" /* eat up one-line comments */ [ \t\n]+ /* eat up whitespace */ . printf( "Unrecognized character: %s\n", yytext ); %% main( argc, argv ) int argc; char **argv; { ++argv, --argc; /* skip over program name */ if ( argc > 0 ) yyin = fopen( argv[0], "r" ); else yyin = stdin; yylex(); }
Und doch gibt es die SCXML- Spezifikation - State Chart XML: State Machine Notation für Control Abstraction, eine Beschreibung einer State Machine in XML-ähnlichem Markup. Dies ist nicht gerade DSL, sondern auch ein praktischer Mechanismus zur Automatisierung von Prozessen ohne Programmierung. Qt SCXML hat eine hervorragende Implementierung. Es gibt andere Implementierungen, aber sie sind nicht so flexibel.
Dies ist ein Beispiel für einen FTP-Client in SCXML-Notation, ein Beispiel aus der Qt-Dokumentationssite
<scxml xmlns="http://www.w3.org/2005/07/scxml" version="1.0" name="FtpClient" datamodel="ecmascript"> <state id="G" initial="I"> <transition event="reply" target="E"/> <transition event="cmd" target="F"/> <state id="I"> <transition event="reply.2xx" target="S"/> </state> <state id="B"> <transition event="cmd.DELE cmd.CWD cmd.CDUP cmd.HELP cmd.NOOP cmd.QUIT cmd.SYST cmd.STAT cmd.RMD cmd.MKD cmd.PWD cmd.PORT" target="W.general"/> <transition event="cmd.APPE cmd.LIST cmd.NLST cmd.REIN cmd.RETR cmd.STOR cmd.STOU" target="W.1xx"/> <transition event="cmd.USER" target="W.user"/> <state id="S"/> <state id="F"/> </state> <state id="W"> <onentry> <send eventexpr=""submit." + _event.name"> <param name="params" expr="_event.data"/> </send> </onentry> <transition event="reply.2xx" target="S"/> <transition event="reply.4xx reply.5xx" target="F"/> <state id="W.1xx"> <transition event="reply.1xx" target="W.transfer"/> </state> <state id="W.transfer"/> <state id="W.general"/> <state id="W.user"> <transition event="reply.3xx" target="P"/> </state> <state id="W.login"/> </state> <state id="P"> <transition event="cmd.PASS" target="W.login"/> </state> </state> <final id="E"/> </scxml>
Und so sieht es im SCXML-Visualizer aus

Datenzugriff und Integration
Dies ist vielleicht eines der "wundesten" Themen der Welt mit ++. Die Welt der Daten für einen C ++ - Entwickler ist immer mit der Notwendigkeit verbunden, sie im Wesentlichen einer Programmiersprache anzeigen zu können. Eine Zeile in einer Tabelle befindet sich in einem Objekt oder einer Struktur, json befindet sich in einer Klasse und so weiter. In Ermangelung von Reflexion - das ist ein großes Problem, aber wir mit ++ - Spitznamen verzweifeln nicht und finden verschiedene Wege aus der Situation heraus. Beginnen wir mit dem DBMS.
Jetzt werde ich alltäglich sein, aber ODBC ist der einzige universelle Mechanismus für den Zugriff auf relationale DBMS. Es wurden noch keine anderen Optionen erfunden, aber C ++ - die Community steht nicht still und heute gibt es Bibliotheken und Frameworks, die allgemeine Zugriffsschnittstellen auf mehrere DBMS bereitstellen.
Zunächst möchte ich Bibliotheken erwähnen, die über Clientbibliotheken und SQL einen einheitlichen Zugriff auf das DBMS ermöglichen
Alle sind gut, aber sie erinnern Sie an die Nuancen der Anzeige von Daten aus der Datenbank in C ++ - Objekten und -Strukturen, und die Effizienz von SQL-Abfragen fällt Ihnen sofort auf die Schultern.
Die folgenden Beispiele sind ORMs in C ++. Ja gibt es! Übrigens unterstützt SOCI ORM-Mechanismen durch die Spezialisierung soci :: type_conversion, aber ich habe sie absichtlich nicht aufgenommen, da dies nicht ihr direkter Zweck ist.
- LiteSQL C ++ - ORM, mit dem Sie mit SQLite3, PostgreSQL, MySQL interagieren können. Für diese Bibliothek muss der Programmierer XML-Dateien mit einer Beschreibung von Objekten und Beziehungen vorab entwerfen, um mithilfe von litesql-gen zusätzliche Quellen zu generieren.
- ODB von Code Synthesis ist ein sehr interessantes ORM, mit dem Sie in C ++ bleiben können, ohne Zwischenbeschreibungsdateien zu verwenden. Hier ein kleines Beispiel:
#pragma db object class person {
- Wt ++ ist ein großes Framework, Sie können im Allgemeinen einen separaten Artikel darüber schreiben. Es enthält auch ORM, das mit DBMS Sqlite3, Firebird, MariaDB / MySQL, MSSQL Server, PostgreSQL und Oracle interagieren kann.
- Ich möchte auch ORM über sqlite sqlite_orm und hiberlite erwähnen . Da SQLite ein eingebettetes DBMS ist und ORM dafür Abfragen und die gesamte Interaktion mit der Datenbank während der Kompilierung überprüft, ist das Tool für die schnelle Bereitstellung und das Prototyping sehr praktisch.
- QHibernate - ORM für Qt5 mit Postgresql-Unterstützung. Durchnässt von Ideen aus dem Winterschlaf von Java.
Obwohl die Integration über ein DBMS als "Integration" betrachtet wird, lasse ich sie lieber außerhalb der Klammern und gehe zur Integration über Protokolle und APIs über.
RPC - Remote Porocess Call, eine bekannte Technik für die Interaktion des "Clients" mit dem "Server". Wie im Fall von ORM besteht die Hauptschwierigkeit darin, verschiedene Hilfsdateien zum Verknüpfen des Protokolls mit realen Funktionen im Code zu schreiben / zu erzeugen. Ich werde absichtlich nicht die verschiedenen RPCs erwähnen, die direkt im Betriebssystem implementiert sind, aber ich werde mich auf plattformübergreifende Lösungen konzentrieren.
- grpc ist ein Framework von Google für Remote Procedure Calls, ein sehr beliebtes und effizientes Framework von Google. Grundsätzlich wird Google Protobuf verwendet. Ich habe es im Abschnitt zur Serialisierung erwähnt. Es unterstützt viele Programmiersprachen, ist jedoch neu in der Unternehmensumgebung.
- json-rpc - RPC, bei dem JSON als Protokoll verwendet wird. Ein gutes Beispiel für die Implementierung ist die Bibliothek libjson-rpc-cpp . Hier ein Beispiel für eine Beschreibungsdatei:
[ { "name": "sayHello", "params": { "name": "Peter" }, "returns" : "Hello Peter" }, { "name" : "notifyServer" } ]
Basierend auf dieser Beschreibung werden Client- und Servercode generiert, der in Ihrer Anwendung verwendet werden kann. Im Allgemeinen gibt es eine Spezifikation für JSON-RPC 1.0 und 2.0 . Das Aufrufen einer Funktion aus einer Webanwendung und deren Verarbeitung in C ++ ist daher nicht schwierig.
- XML-RPC und SOAP - hier der klare Marktführer - ist gSOAP , eine sehr leistungsfähige Bibliothek. Ich glaube nicht, dass es würdige Alternativen gibt. Wie im vorherigen Beispiel erstellen wir eine Zwischendatei mit xml-rpc- oder Seifeninhalt, setzen den Generator darauf, holen den Code und verwenden ihn. Typische Anforderungs- und Antwortbeispiele in XML-RPC-Notation:
<?xml version="1.0"?> <methodCall> <methodName>examples.getState</methodName> <params> <param> <value><i4>41</i4></value> </param> </params> </methodCall> <methodResponse> <params> <param> <value><string>State-Ready</string></value> </param> </params> </methodResponse>
- Poco :: RemotingNG ist ein sehr interessantes Projekt von pocoproject. Hier können Sie bestimmen, welche Klassen, Funktionen usw. kann mithilfe von Anmerkungen in den Kommentaren remote aufgerufen werden. Hier ist ein Beispiel
typedef unsigned long GroupID; typedef std::string GroupName;
Zur Erzeugung von Hilfscode wird ein eigener "Compiler" verwendet. Diese Funktionalität war lange Zeit nur in der kostenpflichtigen Version des POCO-Frameworks verfügbar, aber mit dem Aufkommen des macchina.io- Projekts können Sie sie kostenlos nutzen.
Messaging ist ein ziemlich weit gefasstes Konzept, aber ich werde es unter dem Gesichtspunkt des Messaging über einen gemeinsamen Datenbus analysieren, dh ich werde Bibliotheken und Server durchgehen, die den Java Message Service unter Verwendung verschiedener Protokolle implementieren, beispielsweise AMQP oder STOMP . Der gemeinsame Datenbus, auch als Enterprise Servise Bus (ESB) bezeichnet, ist in Unternehmenssegmentlösungen sehr verbreitet Ermöglicht die schnelle Integration verschiedener Elemente der IT-Infrastruktur untereinander mithilfe eines Punkt-zu-Punkt- und Publish-Subscribe-Musters. Es gibt nur wenige industrielle Nachrichtenbroker, die in C ++ geschrieben sind. Ich kenne zwei: Apache Qpid und UPMQ , und der zweite wurde von mir geschrieben. Es gibt Eclipse Mosquitto , aber es ist in si geschrieben. Das Schöne an JMS für Java ist, dass Ihr Code nicht von dem Protokoll abhängt, das der Client und der Server verwenden. JMS als ODBC deklariert Funktionen und Verhalten, sodass Sie den JMS-Anbieter mindestens einmal am Tag wechseln und den Code nicht neu schreiben können C ++ ist das leider nicht. Sie müssen den Client-Teil für jeden Anbieter neu schreiben. Ich werde meiner Meinung nach die beliebtesten C ++ - Bibliotheken für nicht weniger beliebte Nachrichtenbroker auflisten:
Das Prinzip, dass diese Bibliotheken allgemeine Funktionen bereitstellen, stimmt im Allgemeinen mit der JMS-Spezifikation überein. In dieser Hinsicht besteht der Wunsch, eine Gruppe von Gleichgesinnten zusammenzustellen und eine Art ODBC zu schreiben, jedoch für Nachrichtenbroker, so dass jeder C ++ - Programmierer etwas weniger als gewöhnlich leidet.
Netzwerkkonnektivität
Ich habe bewusst alles, was direkt mit der Netzwerkinteraktion verbunden war, bis zum Ende belassen, weil In diesem Bereich haben C ++ - Entwickler meiner Meinung nach die geringsten Probleme. Es bleibt nur das Muster auszuwählen, das Ihrer Entscheidung am nächsten kommt, und das Framework, das sie umsetzt. Bevor ich die beliebtesten Bibliotheken aufführe, möchte ich ein wichtiges Detail bei der Entwicklung Ihrer eigenen Netzwerkanwendungen erwähnen. Wenn Sie sich dazu entschließen, ein eigenes Protokoll über TCP oder UDP zu erstellen, müssen Sie darauf vorbereitet sein, dass alle Arten von „intelligenten“ Sicherheitstools Ihren Datenverkehr blockieren. Seien Sie also vorsichtig, wenn Sie Ihr Protokoll beispielsweise in https packen, da sonst Probleme auftreten können. Also Bibliotheken:
- Boost.Asio und Boost.Beast - eine der beliebtesten Implementierungen für die asynchrone Netzwerkkommunikation. HTTP und WebSockets werden unterstützt
- Poco :: Net ist auch eine sehr beliebte Lösung. Zusätzlich zur Rohinteraktion können Sie vorgefertigte Klassen von TCP Server Framework, Reactor Framework sowie Client- und Serverklassen für HTTP, FTP und E-Mail verwenden. Es gibt auch Unterstützung für WebSockets
- ACE - hat diese Bibliothek nie verwendet, aber Kollegen sagen, dass sie auch eine würdige Bibliothek ist, mit einem integrierten Ansatz für die Implementierung von Netzwerkanwendungen und mehr.
- Qt-Netzwerk - In Qt ist der Netzwerkteil gut implementiert. Der einzige kontroverse Punkt sind die Signale und Slots für Serverlösungen, obwohl der Server auf Qt!?
Insgesamt
Ich wollte also einen Überblick über diese Bibliotheken geben. Wenn es mir gelungen ist, haben Sie den Eindruck, dass es sozusagen eine "Enterprise Edition" gibt, aber es gibt keine Lösungen für deren Implementierung und Verwendung, nur einen Zoo von Bibliotheken. So ist es wirklich. Es gibt mehr oder weniger vollständige Bibliotheken für die Entwicklung von Anwendungen für das Unternehmenssegment, aber es gibt keine Standardlösung. Ich allein kann pocoproject und maccina.io nur als Ausgangspunkt für die Suche nach Lösungen für das Backend und den Boost für jeden Fall empfehlen, und natürlich suche ich Gleichgesinnte, um das Konzept der "C ++ Enterprise Edition" zu fördern!