Theoretisch trägt der Einsatz von maschinellem Lernen (ML) dazu bei, die Beteiligung des Menschen an Prozessen und Vorgängen zu verringern, Ressourcen neu zuzuweisen und Kosten zu senken. Wie funktioniert das in einem bestimmten Unternehmen und einer bestimmten Branche? Wie unsere Erfahrung zeigt, funktioniert es.
In einem bestimmten Entwicklungsstadium standen wir bei VTB Capital vor der dringenden Notwendigkeit, die Zeit für die Bearbeitung von Anfragen nach technischem Support zu verkürzen. Nach der Analyse der Optionen wurde beschlossen, die ML-Technologie zu verwenden, um Anrufe von Geschäftsbenutzern von Calypso, der wichtigsten Anlageplattform des Unternehmens, zu kategorisieren. Die schnelle Bearbeitung solcher Anfragen ist entscheidend für die hohe Qualität des IT-Service. Wir haben unsere wichtigsten Partner,
EPAM, gebeten
, zur Lösung dieses Problems
beizutragen .

Supportanfragen werden also per E-Mail empfangen und in Jira in Tickets umgewandelt. Anschließend klassifizieren Support-Spezialisten sie manuell, priorisieren sie, geben zusätzliche Daten ein (z. B. von welcher Abteilung und an welchem Ort eine Anfrage eingegangen ist, zu welcher Funktionseinheit des Systems sie gehört) und weisen die Darsteller zu. Insgesamt werden ca. 10 Kategorien von Abfragen verwendet. Dies kann beispielsweise eine Anforderung sein, einige Daten zu analysieren und dem Anforderer Informationen bereitzustellen, einen neuen Benutzer hinzuzufügen usw. Darüber hinaus können Aktionen entweder Standard- oder Nicht-Standardaktionen sein. Daher ist es sehr wichtig, die Art der Anforderung sofort korrekt zu bestimmen und die Ausführung dem richtigen Spezialisten zuzuweisen.
Es ist wichtig zu beachten: VTB Capital wollte nicht nur eine angewandte technologische Lösung entwickeln, sondern auch die Fähigkeiten verschiedener Tools und Technologien auf dem Markt bewerten. Eine Aufgabe, zwei verschiedene Ansätze, zwei Technologieplattformen und dreieinhalb Wochen: Was war das Ergebnis?
Prototyp Nr. 1: Technologien und Modelle
Grundlage für die Entwicklung des Prototyps waren der vom EPAM-Team vorgeschlagene Ansatz und historische Daten - etwa 10.000 Tickets von Jira. Das Hauptaugenmerk lag auf den 3 erforderlichen Feldern, die jedes dieser Tickets enthält: Problemtyp (Art des Problems), Zusammenfassung ("Kopfzeile" des Briefes oder Betreffs der Anfrage) und Beschreibung (Beschreibung). Im Rahmen des Projekts war geplant, das Problem der Analyse des Textes aus den Feldern Zusammenfassung und Beschreibung zu lösen und die Art der Anforderung automatisch aus den Ergebnissen zu ermitteln.
Es sind die Merkmale des Textes in diesen beiden Ticketfeldern, die zur technischen Hauptschwierigkeit bei der Analyse von Daten und der Entwicklung von ML-Modellen wurden. Das Feld "Zusammenfassung" enthält möglicherweise recht "sauberen" Text, enthält jedoch bestimmte Wörter und Begriffe (z. B.
nicht ausgeführte CWS-Berichte). Das Beschreibungsfeld hingegen ist durch einen „schmutzigeren“ Text mit einer Fülle von Sonderzeichen, Symbolen, Schrägstrichen und Rückständen von Nicht-Text-Elementen gekennzeichnet:
Dera Kollegen,
Könnten Sie uns bitte erklären, was der Unterschied zwischen den Risikomaßnahmen FX_Opt_delta_all und FX_Opt_delta_cash ist?
! 01D39C59.62374C90_image001.png! )
Darüber hinaus kombiniert der Text häufig mehrere Sprachen (hauptsächlich natürlich Russisch und Englisch), Geschäftsterminologie, Ruglish und Programmierersprache. Und da Anfragen oft in Eile geschrieben werden, sind Tippfehler und Rechtschreibfehler in beiden Fällen nicht ausgeschlossen.
Zu den vom EPAM-Team ausgewählten Technologien gehörten Python 3.5 für die Prototypenentwicklung, NLTK + Gensim + Re für die Textverarbeitung, Pandas + Sklearn für die Datenanalyse und Modellentwicklung sowie Keras + Tensorflow als Deep-Learning-Framework und Backend.
Unter Berücksichtigung der möglichen Merkmale der Anfangsdaten wurden drei Darstellungen für die Zeichenextraktion aus dem Feld Zusammenfassung erstellt: auf Symbolebene eine Kombination von Symbolen und einzelne Wörter. Jede der Darstellungen wurde als Eingang zu einem wiederkehrenden neuronalen Netzwerk verwendet.
Die Darstellung der Dienstzeichenstatistik (wichtig für die Verarbeitung von Text mit Ausrufezeichen, Schrägstrichen usw.) und die Durchschnittswerte der Zeichenfolgen nach dem Filtern der Dienstzeichen und des Mülls (zur kompakten Beibehaltung der Textstruktur) wurden als Darstellung für das Feld Beschreibung ausgewählt. sowie Darstellung auf Wortebene nach dem Filtern von Stoppwörtern. Jede Darstellung diente als Zugang zu einem neuronalen Netzwerk: Statistiken in einer vollständig verbundenen Zeile für Zeile und auf der Ebene von Wörtern - in einer rekursiven.
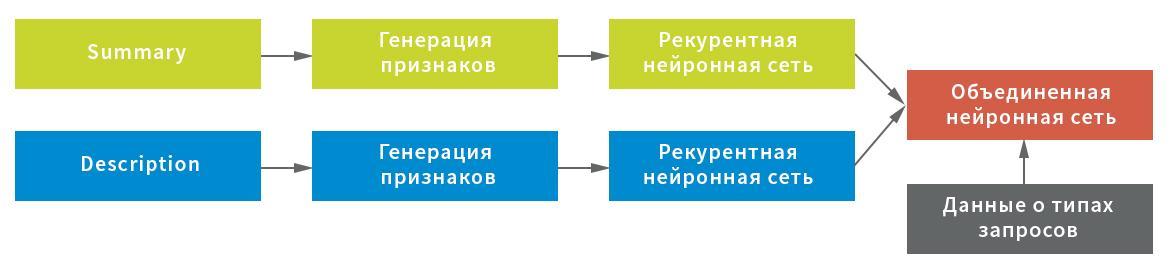
In diesem Schema wurde ein neuronales Netzwerk als wiederkehrendes Netzwerk verwendet, das aus einer bidirektionalen GRU-Schicht mit einem wiederkehrenden und normalen Ausfall, einem Pool verborgener Zustände des wiederkehrenden Netzwerks unter Verwendung der GlobalMaxPool1D-Schicht und einer vollständig verbundenen (dichten) Schicht mit einem Ausfall besteht. Für jede der Eingaben wurde ein eigener „Kopf“ des neuronalen Netzwerks erstellt, und dann wurden sie durch Verkettung kombiniert und an die Zielvariable gebunden.
Um das Endergebnis zu erhalten, gab das kombinierte neuronale Netzwerk die Wahrscheinlichkeiten einer bestimmten Anforderung zurück, die zu jedem Typ gehört. Die Daten wurden in fünf Blöcke ohne Schnittpunkte unterteilt: Das Modell wurde auf vier von ihnen aufgebaut und am fünften getestet. Da jeder Anforderung nur ein Anforderungstyp zugewiesen werden kann, war die Regel für die Entscheidungsfindung einfach - um den maximalen Wahrscheinlichkeitswert.
Prototyp Nr. 2: Algorithmen und Arbeitsprinzipien
Der zweite Prototyp, für den der vom VTB Capital-Team erstellte Vorschlag angenommen wurde, ist eine Anwendung auf Microsoft .NET Core mit Microsoft.ML-Bibliotheken zur Implementierung von Algorithmen für maschinelles Lernen und das Atlassian.Net SDK für die Interaktion mit Jira über die REST-API. Die Grundlage für den Bau von ML-Modellen wurden auch historische Daten - 50.000 Jira-Tickets. Wie im ersten Fall umfasste das maschinelle Lernen die Felder Zusammenfassung und Beschreibung. Vor dem Einsatz wurden beide Felder ebenfalls „gereinigt“. Grüße, Unterschriften, Korrespondenzverlauf und nicht-textuelle Elemente (z. B. Bilder) wurden aus dem Brief des Benutzers gelöscht. Darüber hinaus wurden mithilfe der in Microsoft ML integrierten Funktion Stoppwörter, die für die Verarbeitung und Analyse des Textes nicht relevant waren, aus dem englischen Text entfernt.
Das gemittelte Perceptron (binäre Klassifizierung) wurde als Algorithmus für maschinelles Lernen ausgewählt, der durch die One Versus All-Methode ergänzt wird, um eine Klassifizierung für mehrere Klassen bereitzustellen
Auswertung der Ergebnisse
Kein ML-Modell kann (möglicherweise noch) eine 100% ige Genauigkeit des Ergebnisses liefern.
Der Algorithmus Prototyp Nr. 1 liefert den Anteil der korrekten Klassifizierung (Genauigkeit), der 0,8003 der Gesamtzahl der Anforderungen oder 80% entspricht. Darüber hinaus erreicht der Wert einer ähnlichen Metrik in einer Situation, in der angenommen wird, dass die richtige Antwort von der Person aus den beiden von der Lösung dargestellten ausgewählt wird, 0,901 oder 90%. Natürlich gibt es Fälle, in denen die entwickelte Lösung schlechter funktioniert oder nicht die richtige Antwort geben kann - in der Regel aufgrund eines sehr kurzen Satzes von Wörtern oder der Spezifität der Informationen in der Anfrage selbst. Die Rolle spielt immer noch die unzureichend große Datenmenge, die im Lernprozess verwendet wird. Nach vorläufigen Schätzungen wird es durch eine Erhöhung des Volumens der verarbeiteten Informationen möglich sein, die Klassifizierungsgenauigkeit um weitere 0,01 bis 0,03 Punkte zu erhöhen.
Die Ergebnisse des besten Modells in den Metriken Genauigkeit (Präzision) und Vollständigkeit (Rückruf) werden wie folgt bewertet:

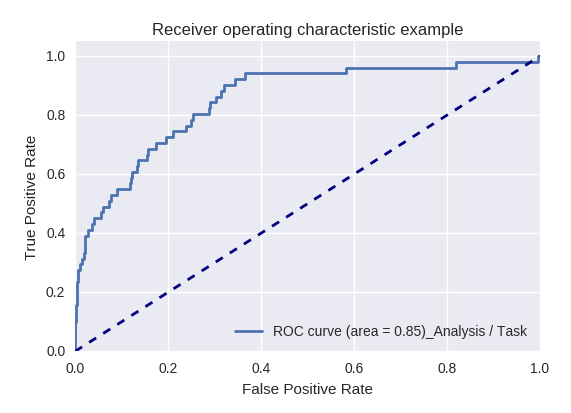
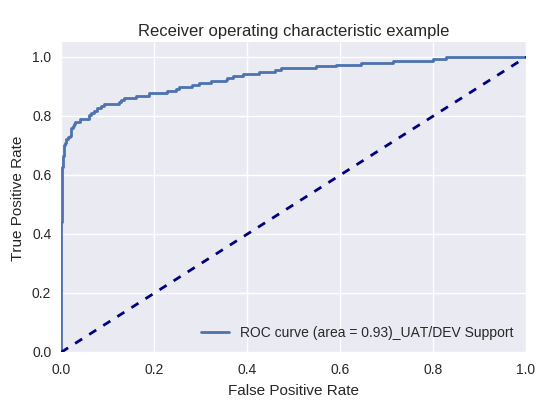
Wenn wir die Qualität des gesamten Modells für verschiedene Arten von Abfragen mithilfe von ROC-AUC-Kurven bewerten, sind die Ergebnisse wie folgt.
Handlungsanfragen (Aktionsanforderung) und Informationsanalyse (Analyse / Aufgabenanforderung)
 Anfragen nach Änderungen von Geschäftsdaten (Business Data Request) und nach Änderungen (Change Request)
Anfragen nach Änderungen von Geschäftsdaten (Business Data Request) und nach Änderungen (Change Request)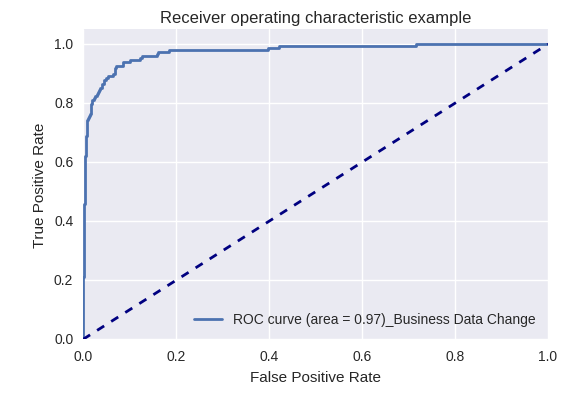
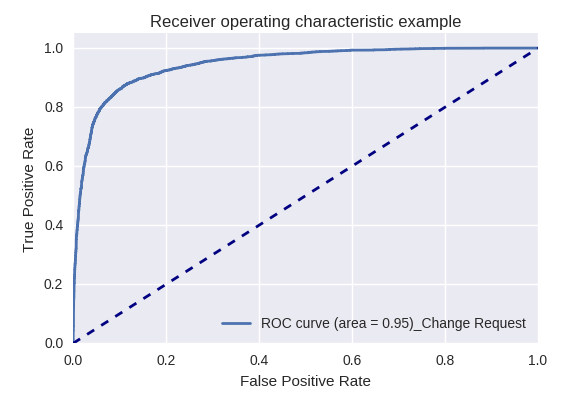 Entwicklungsanfrage und Anfrage
Entwicklungsanfrage und Anfrage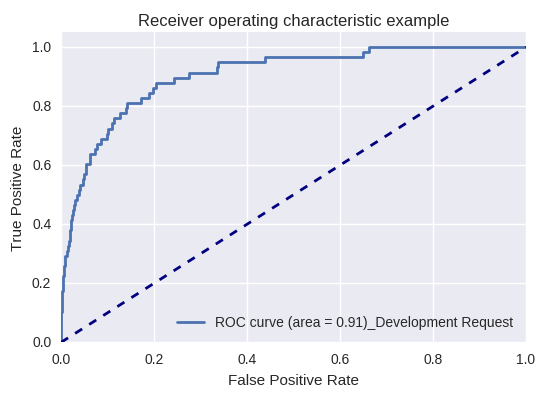
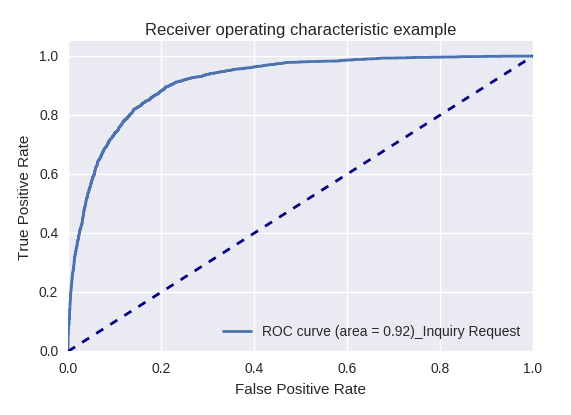 Anforderungen zum Erstellen eines neuen Objekts (Neue Objektanforderung) und Hinzufügen eines neuen Benutzers (Neue Benutzeranforderung)
Anforderungen zum Erstellen eines neuen Objekts (Neue Objektanforderung) und Hinzufügen eines neuen Benutzers (Neue Benutzeranforderung)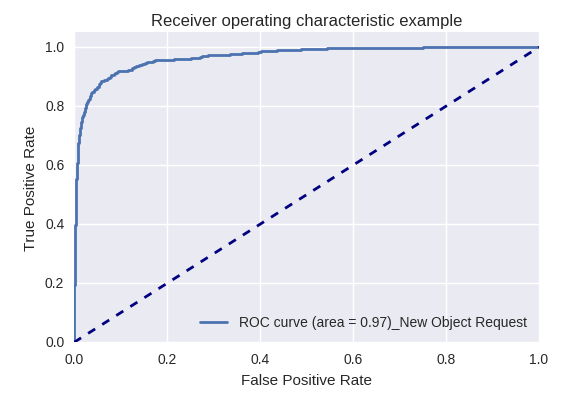
 Produktionsanforderung und UAT / DEV-Supportanforderung (UAT / Dev-Supportanforderung)
Produktionsanforderung und UAT / DEV-Supportanforderung (UAT / Dev-Supportanforderung)
Beispiele für die korrekte und falsche Klassifizierung einiger Arten von Abfragen sind nachstehend aufgeführt:
Anfrage Anfrage
Änderungsanforderung
Richtige Klassifizierung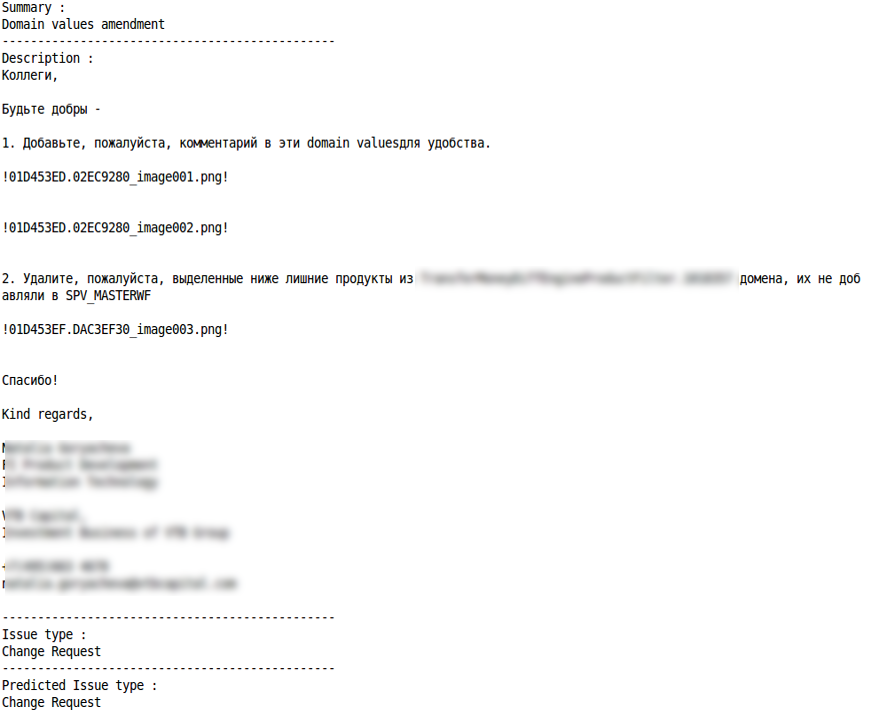 Fehlklassifizierung
Fehlklassifizierung AktionsanforderungRichtige Klassifizierung
AktionsanforderungRichtige Klassifizierung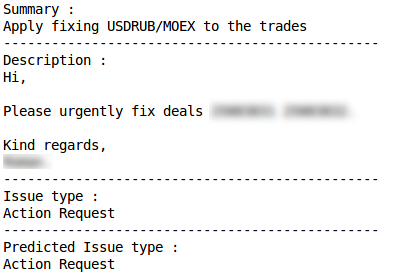 FehlklassifizierungProduktionsproblemRichtige Klassifizierung
FehlklassifizierungProduktionsproblemRichtige Klassifizierung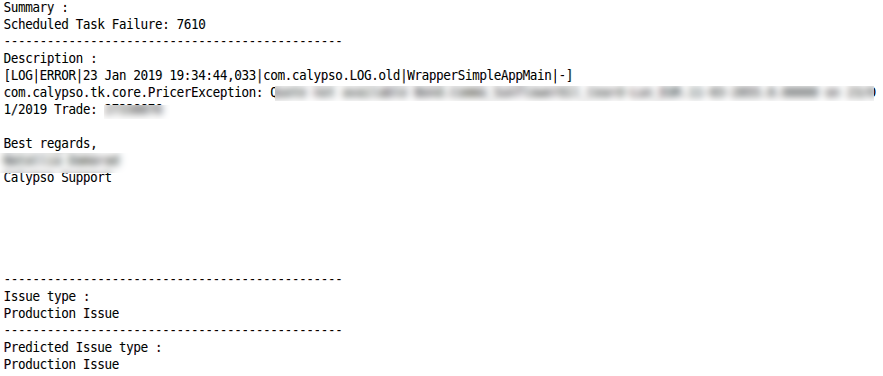 Fehlklassifizierung
Fehlklassifizierung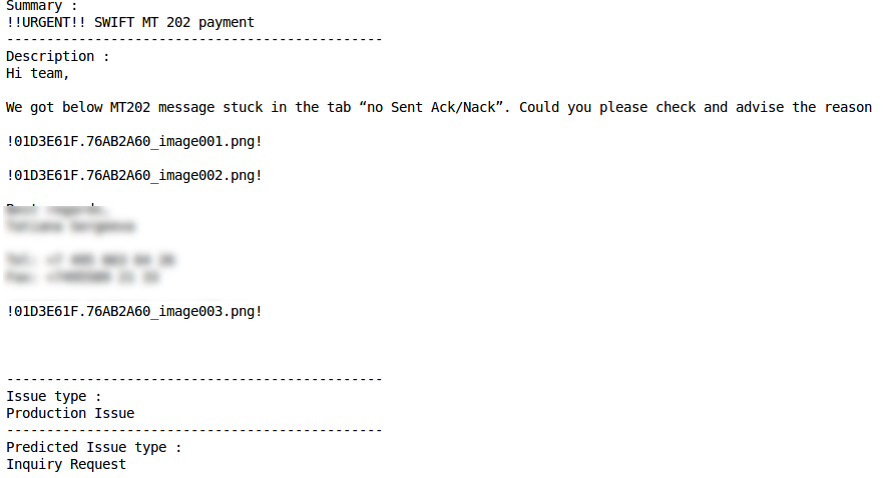
Der zweite Prototyp zeigte ebenfalls gute Ergebnisse: In ungefähr 75% der Fälle bestimmt ML den Abfragetyp korrekt (Genauigkeitsmetrik). Die Möglichkeit, den Indikator zu verbessern, ist mit einer Verbesserung der Qualität der Quelldaten verbunden, insbesondere durch die Beseitigung von Fällen, in denen dieselben Abfragen unterschiedlichen Typen zugewiesen wurden.
Zusammenfassend
Jeder der implementierten Prototypen hat seine Wirksamkeit gezeigt, und jetzt wurde eine Kombination aus zwei entwickelten Prototypen bei VTB Capital in die Pilotproduktion eingeführt. Ein kleines Experiment mit ML in weniger als einem Monat und zu minimalen Kosten ermöglichte es dem Unternehmen, sich mit maschinellen Lernwerkzeugen vertraut zu machen und ein wichtiges Anwendungsproblem für die Klassifizierung von Benutzeranforderungen zu lösen.
Die Erfahrungen der Entwickler von EPAM und VTB Capital - zusätzlich zur Verwendung implementierter Algorithmen zur Verarbeitung von Benutzeranforderungen für die weitere Entwicklung - können zur Lösung einer Vielzahl von Aufgaben im Zusammenhang mit der Stream-Verarbeitung von Informationen wiederverwendet werden. Die Bewegung in kleinen Iterationen und die Abdeckung eines Prozesses nach dem anderen ermöglicht es Ihnen, verschiedene Tools und Technologien schrittweise zu beherrschen und zu kombinieren, bewährte Optionen auszuwählen und weniger effektive aufzugeben. Dies ist für das IT-Team interessant und trägt gleichzeitig dazu bei, Ergebnisse zu erzielen, die für Management und Geschäft wichtig sind.