Artikel über Computer Vision, Interpretierbarkeit, NLP - Wir haben die AISTATS-Konferenz in Japan besucht und möchten einen Überblick über die Artikel geben. Dies ist eine große Konferenz über Statistik und maschinelles Lernen. Dieses Jahr findet sie auf Okinawa, einer Insel in der Nähe von Taiwan, statt. In diesem Beitrag hat Yulia Antokhina ( Yulia_chan ) eine Beschreibung der hellen Artikel aus dem Hauptteil vorbereitet. Im nächsten Beitrag wird sie zusammen mit Anna Papeta über die Berichte eingeladener Dozenten und theoretische Studien sprechen. Wir werden auch ein wenig darüber erzählen, wie die Konferenz selbst stattgefunden hat und über das „nicht-japanische“ Japan. Verteidigung gegen gegnerische Whitebox-Angriffe durch randomisierte Diskretisierung
Verteidigung gegen gegnerische Whitebox-Angriffe durch randomisierte DiskretisierungYuchen Zhang (Microsoft); Percy Liang (Stanford University)
→
Artikel→
CodeBeginnen wir mit einem Artikel über den Schutz vor gegnerischen Angriffen in der Bildverarbeitung. Dies sind gezielte Angriffe auf Modelle, wenn das Ziel des Angriffs darin besteht, dass das Modell einen Fehler macht, bis zu einem vorgegebenen Ergebnis. Algorithmen des Computer-Sehens können selbst bei geringfügigen Änderungen des Originalbilds für eine Person verwechselt werden. Die Aufgabe ist beispielsweise für die Bildverarbeitung relevant, die unter guten Bedingungen Verkehrszeichen schneller erkennt als eine Person, bei Angriffen jedoch viel schlechter funktioniert.
Gegnerischer Angriff klar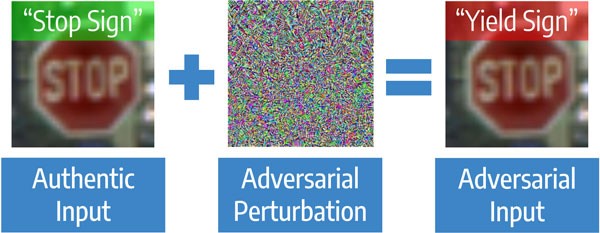
Die Angriffe sind Blackbox - wenn der Angreifer nichts über den Algorithmus weiß und Whitebox die umgekehrte Situation ist. Es gibt zwei Hauptansätze zum Schutz von Modellen. Der erste Ansatz besteht darin, das Modell auf regulären und „angegriffenen“ Bildern zu trainieren - dies wird als kontroverses Training bezeichnet. Dieser Ansatz funktioniert gut bei kleinen Bildern wie MNIST, aber es gibt Artikel, die zeigen, dass er bei großen Bildern wie ImageNet nicht gut funktioniert. Die zweite Art des Schutzes erfordert keine Umschulung des Modells. Es reicht aus, das Bild vor der Übermittlung an das Modell vorzuverarbeiten. Beispiele für Konvertierungen: JPEG-Komprimierung, Größenänderung. Diese Methoden erfordern weniger Rechenaufwand, funktionieren jetzt jedoch nur noch gegen Blackbox-Angriffe, da bei bekannter Konvertierung das Gegenteil angewendet werden kann.
MethodeIn dem Artikel schlagen die Autoren eine Methode vor, die kein Übertraining des Modells erfordert und für Whitebox-Angriffe funktioniert. Ziel ist es, den Kullback-Leibner-Abstand zwischen gewöhnlichen und „verwöhnten“ Beispielen durch eine zufällige Transformation zu verringern. Es stellt sich heraus, dass es ausreicht, zufälliges Rauschen hinzuzufügen und dann die Farben zufällig abzutasten. Das heißt, dem Algorithmeneingang wird eine "beeinträchtigte" Bildqualität zugeführt, die jedoch immer noch ausreicht, damit der Algorithmus funktioniert. Und aufgrund des Zufalls besteht das Potenzial, Whitebox-Angriffen standzuhalten.
Links ist das Originalbild, in der Mitte ein Beispiel für das Clustering von Pixelfarben im Laborbereich, rechts ein Bild in mehreren Farben (z. B. anstelle von 40 Blautönen - eine) Ergebnisse
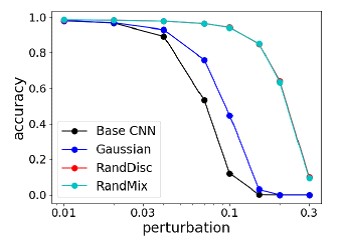
ErgebnisseDiese Methode wurde mit den stärksten Angriffen auf den NIPS 2017 Adversarial Attacks & Defenses Competition verglichen. Sie zeigt im Durchschnitt die beste Qualität und trainiert nicht unter dem „Angreifer“.
Vergleich der stärksten Verteidigungsmethoden gegen die stärksten Angriffe auf den NIPS-Wettbewerb Vergleich der Genauigkeit von Methoden auf MNIST mit verschiedenen Bildänderungen
Vergleich der Genauigkeit von Methoden auf MNIST mit verschiedenen Bildänderungen
 Abschwächung der Verzerrung in Wortvektoren
Abschwächung der Verzerrung in WortvektorenSunipa Dev (Universität von Utah); Jeff Phillips (Universität von Utah)
→
ArtikelDas "trendige" Gespräch drehte sich um unvoreingenommene Wortvektoren. In diesem Fall bedeutet Verzerrung Verzerrungen nach Geschlecht oder Nationalität bei der Darstellung von Wörtern. Alle Regulierungsbehörden können sich einer solchen "Diskriminierung" widersetzen, und deshalb haben Wissenschaftler der Universität von Utah beschlossen, die Möglichkeit eines "Rechtsausgleichs" für die NLP zu untersuchen. Warum kann ein Mann nicht „glamourös“ und eine Frau ein „Data Scientist“ sein?
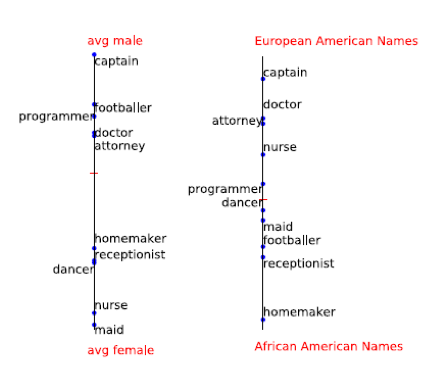
Original - das Ergebnis, das jetzt erhalten wird, der Rest - die Ergebnisse des unvoreingenommenen Algorithmus

Der Artikel beschreibt eine Methode zum Auffinden einer solchen Verzerrung. Sie entschieden, dass Geschlecht und Nationalität gut durch Namen gekennzeichnet sind. Wenn Sie also den Versatz nach Namen finden und subtrahieren, können Sie wahrscheinlich die Verzerrung des Algorithmus beseitigen.
Ein Beispiel für "männliche" und "weibliche" Wörter:
 Namen für die Suche nach geschlechtsspezifischen Offsets:
Namen für die Suche nach geschlechtsspezifischen Offsets:
Seltsamerweise funktioniert eine so einfache Methode. Die Autoren trainierten einen unvoreingenommenen Handschuh und legten ihn in Git an.
Warum hast du das gemacht? Black-Box-Entscheidungen mit ausreichenden Eingabe-Teilmengen verstehenBrandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→
Artikel→
Code ein- und
zweimalDer folgende Artikel befasst sich mit dem Algorithmus für ausreichende Teilmengen. SIS sind die minimalen Teilmengen von Features, bei denen das Modell ein bestimmtes Ergebnis erzielt, selbst wenn alle anderen Features zurückgesetzt werden. Dies ist eine andere Möglichkeit, die Ergebnisse komplexer Modelle irgendwie zu interpretieren. Funktioniert sowohl mit Texten als auch mit Bildern.
SIS-Suchalgorithmus im Detail: Anwendungsbeispiel zum Text mit Rezensionen zu Bier:
Anwendungsbeispiel zum Text mit Rezensionen zu Bier: Anwendungsbeispiel für MNIST:
Anwendungsbeispiel für MNIST: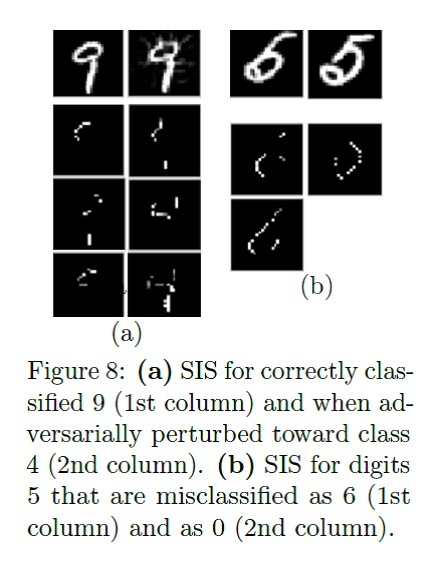 Vergleich der Methoden zur "Interpretation" der Kullback-Leibler-Distanz mit dem "idealen" Ergebnis:
Vergleich der Methoden zur "Interpretation" der Kullback-Leibler-Distanz mit dem "idealen" Ergebnis: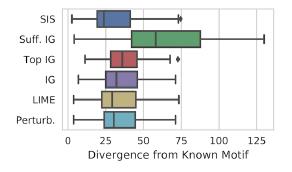
Features werden zuerst nach Auswirkungen auf das Modell eingestuft und dann in disjunkte Teilmengen unterteilt, beginnend mit den einflussreichsten. Es funktioniert mit brutaler Gewalt, und bei einem beschrifteten Datensatz wird das Ergebnis besser interpretiert als bei LIME. Es gibt eine bequeme Implementierung der SIS-Suche von Google Research.
Empirische Risikominimierung und stochastischer Gradientenabstieg für relationale DatenVictor Veitch (Columbia University); Morgane Austern (Columbia University); Wenda Zhou (Columbia University); David Blei (Columbia University); Peter Orbanz (Columbia University)
→
Artikel→
CodeIm Abschnitt zur Optimierung gab es einen Bericht über die empirische Risikominimierung, in dem die Autoren Möglichkeiten zur Anwendung des stochastischen Gradientenabfalls auf Diagramme untersuchten. Wenn Sie beispielsweise ein Modell auf Daten sozialer Netzwerke erstellen, können Sie nur feste Funktionen des Profils (die Anzahl der Abonnenten) verwenden, aber dann gehen Informationen über die Verbindungen zwischen den Profilen (die abonniert sind) verloren. Darüber hinaus ist es meistens schwierig, den gesamten Graphen zu verarbeiten - zum Beispiel passt er nicht in den Speicher. Wenn diese Situation bei Tabellendaten auftritt, kann das Modell für Teilproben ausgeführt werden. Und wie man das Analogon der Teilstichprobe in der Grafik auswählt, war nicht klar. Die Autoren begründeten theoretisch die Möglichkeit, zufällige Untergraphen als Analogon von Unterproben zu verwenden, und dies stellte sich als „nicht verrückte Idee“ heraus. Es gibt reproduzierbare Beispiele aus dem Artikel über Github, einschließlich des Wikipedia-Beispiels.
Kategorie Einbettungen in die Daten von „Wikipedia“ unter Berücksichtigung der Grafikstruktur sind die ausgewählten Artikel dem Thema „Französische Physiker“ am nächsten: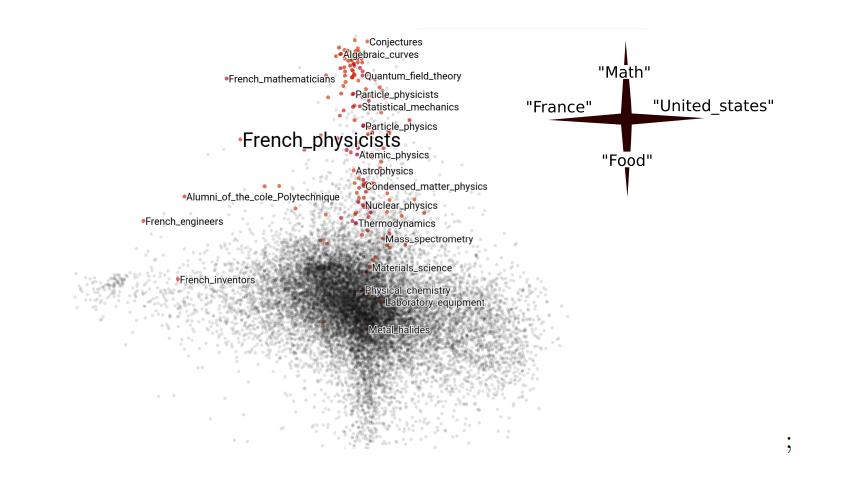
→
Data Science für vernetzte DatenDiskrete Datengraphen waren ein weiterer Überprüfungsbericht von Data Science für vernetzte Daten von Gastredner Poling Loh (Universität von Wisconsin-Madison). Die Präsentation behandelte die Themen statistische Inferenz, Ressourcenzuweisung, lokale Algorithmen. In der statistischen Inferenz ging es beispielsweise darum, zu verstehen, welche Struktur der Graph in Bezug auf die Daten zu Infektionskrankheiten hat. Es wird vorgeschlagen, Statistiken über die Anzahl der Verbindungen zwischen infizierten Knoten zu verwenden - und der Satz wird für den entsprechenden statistischen Test bewiesen.
Im Allgemeinen ist der Bericht interessanter für diejenigen, die nicht an Diagrammmodellen beteiligt sind, aber versuchen möchten, sich für das korrekte Testen von Hypothesen für Diagramme zu interessieren.
Wie verlief die Konferenz?AISTATS 2019 ist eine dreitägige Konferenz in Okinawa. Dies ist Japan, aber Okinawas Kultur ist näher an China. Die Haupteinkaufsstraße erinnert an ein so kleines Miami, es gibt lange Autos auf den Straßen, Country-Musik, und man kommt ein wenig zur Seite - ein Dschungel mit Schlangen, Mangrovenbäumen, die von Taifunen verdreht werden. Das lokale Flair wird durch die Kultur von Ryukyu geschaffen - einem Königreich, das sich in Okinawa befand, aber zuerst ein Vasallen- und Handelspartner Chinas wurde und dann von den Japanern gefangen genommen wurde.
Und in Okinawa finden anscheinend oft Hochzeiten statt, weil es viele Hochzeitssalons gibt und die Konferenz in den Räumlichkeiten des Hochzeitssaals stattfand.
Mehr als 500 Menschen haben Wissenschaftler, Artikelautoren, Zuhörer und Redner versammelt. In drei Tagen haben Sie Zeit, mit fast allen zu sprechen. Obwohl die Konferenz "am Ende der Welt" stattfand, kamen Vertreter aus aller Welt. Trotz der großen geografischen Lage stellte sich heraus, dass die Interessen von uns allen ähnlich sind. Es war zum Beispiel eine Überraschung für uns, dass Wissenschaftler aus Australien dieselben Data Science-Probleme und dieselben Methoden lösen wie wir in unserem Team. Aber schließlich leben wir auf fast entgegengesetzten Seiten des Planeten ... Es gab nicht so viele Teilnehmer aus der Branche: Google, Amazon, MTS und mehrere andere Top-Unternehmen.
Es gab Vertreter japanischer Sponsoring-Unternehmen, die meistens zuschauten und zuhörten und wahrscheinlich jemanden suchten, obwohl die „Nicht-Japaner“ in Japan sehr schwer zu arbeiten waren.
Auf der Konferenz eingereichte Artikel zu folgenden Themen:
Alles andere steht in unserem nächsten Beitrag. Verpassen Sie es nicht!
Ankündigung: