
Das Problem, den Vorhersagen von Modellen des maschinellen Lernens zu vertrauen, wird immer relevanter. Je wichtiger die auf der Grundlage dieser Vorhersage getroffene Entscheidung ist, desto geringer ist das Vertrauen. Dies ist in erster Linie darauf zurückzuführen, dass nicht immer klar ist, was die endgültige Entscheidung beeinflusst hat, ob die ursprünglichen Daten, auf denen das Modell trainiert wurde, Verzerrungen aufwiesen und ob der Entwickler bei der Berechnung der Parameter Fehler gemacht hat. In der Praxis ist es nicht möglich, dies alles manuell zu überprüfen. Daher ist es für das Management oft einfacher, KI überhaupt nicht zu implementieren.
Was aber, wenn Sie diesen Prozess automatisieren?
Einführung von
Watson OpenScale , einer Cloud-basierten Lösung, mit der Sie nicht nur die Qualität Ihrer Modelle kontrollieren, sondern auch das Vorhandensein von Verzerrungen in Vorhersagen verfolgen und deren Ursachen erkennen und beseitigen können.
Wir sagen Ihnen, was es ist und wo Sie lernen, wie Sie damit arbeiten.
Bias - Ein verstecktes KI-Problem
Stellen Sie sich vor, Sie schauen sich ein Fußballspiel an und jemand fragt Sie, wer 2018 der beste Spieler war. Was würdest du antworten? Halten Sie inne und überlegen Sie eine Sekunde, bevor Sie weiterlesen ... Wenn Sie ein Fan von Argentinien wären, würden Sie höchstwahrscheinlich "Messi" sagen, wenn Sie ein Fan von Portugal wären, wäre Ihre Antwort "Ronaldo". Jemand anderes würde sagen, dass Messi der Beste ist, oder vielleicht Dziuba. Jede dieser Antworten (einschließlich der Antwort, die in Ihrem Kopf erschien) spiegelt die Tendenz wider, die jeder Person innewohnt, die diese Frage beantwortet. Dies kann durch Bewunderung direkt durch den Spieler selbst oder durch die gesamte Mannschaft oder durch bestimmte Gefühle für das Land verursacht werden, für das die Mannschaft steht.
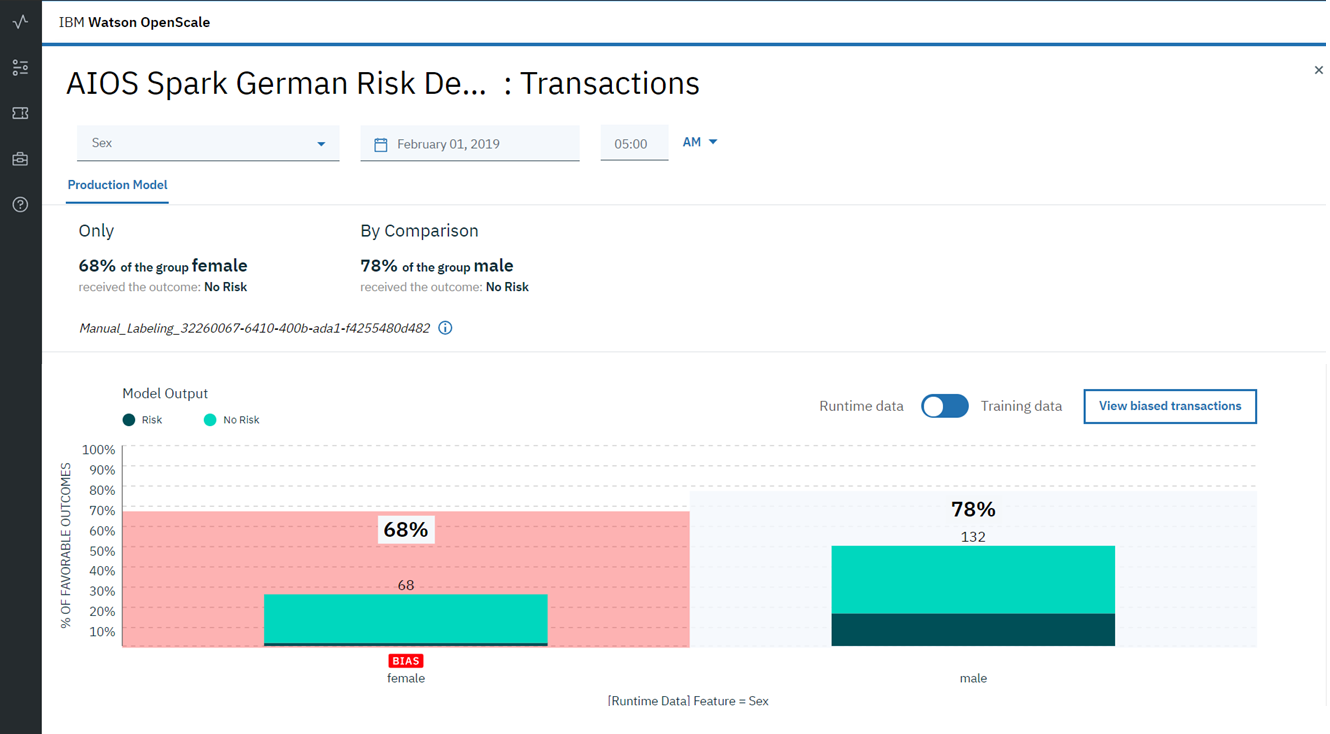
Bewusste und unbewusste Verzerrungen finden sich in fast allen Aspekten unseres Geschäfts. Bei der Entscheidungsfindung, einschließlich Algorithmen für künstliche Intelligenz, kann eine Verzerrung erhebliche Konsequenzen haben. Stellen Sie sich eine Bank vor, die KI verwendet, um betrügerische Aktivitäten zu erkennen. Stellen Sie sich vor, die Person, die dieses Modell entwickelt, hat einen Datensatz verwendet, in dem alle betrügerischen Transaktionen von Personen eines bestimmten Geschlechts, einer bestimmten Nationalität oder eines bestimmten Einkommensniveaus begangen wurden. Dann können wir mit großer Sicherheit sagen, dass ein Modell, das auf solchen verzerrten Daten trainiert wird, diese Verzerrung in seinen Vorhersagen berücksichtigt. Da die Metriken, die dieses Modell beschreiben (Präzision / Rückruf), nahezu ideal sind (schließlich erfolgt die Überprüfung anhand einer Teilstichprobe desselben Datensatzes), ist es für einen Mitarbeiter äußerst schwierig, das Vorhandensein von Verzerrungen als Ergebnis des Algorithmus zu erkennen. Infolgedessen funktioniert ein solches Modell trotz der hervorragenden Metrikwerte äußerst schlecht und wird als betrügerische Handlungen gekennzeichnet, die nicht so sind, und umgekehrt, wodurch wirklich gefährliche Transaktionen übersprungen werden. Und all dies ist auf eine Verzerrung (Verzerrung) in den Quelldaten zurückzuführen, auf die das Modell trainiert wurde.
Ein noch größeres Problem kann das Vorhandensein einer Verzerrung in den Ergebnissen des Modells sein, wenn keine Verzerrung in den Daten vorliegt. Dies kann durch einen Fehler in der Verteilung der Parametergewichte oder durch nichtlineare Transformationen während des Trainings oder des weiteren Trainings des Modells verursacht werden. Daher ist es sehr wichtig, nicht nur in der Phase der Datenvorverarbeitung eine Verzerrung zu finden, sondern auch die Vorhersagen während des Testens und der Verwendung im Produkt ständig zu überwachen, um zu verhindern, dass in den Ergebnissen des Algorithmus eine Verzerrung auftritt.
Aufgrund solcher Probleme sehen AIs in den Augen vieler Firmeninhaber
unzuverlässig aus .
Kann KI helfen, KI zu verbessern?
IBM bietet die
Watson OpenScale- Cloud-Lösung an, die eine kontinuierliche Überwachung der Modellleistung und der Echtzeit-Vorhersageverzerrung ermöglicht. Es erkennt nicht nur das Auftreten von Problemen, sondern findet auch die Ursache für deren Auftreten und bietet eine Option zur Korrektur der Anfangsdaten, um das Auftreten von Verzerrungen in den Vorhersagen zu vermeiden. Mit IBM Watson OpenScale können Sie den Betrieb des Modells kontinuierlich überwachen und auf Verzerrungen prüfen.
Eine weitere große Frage für Unternehmen, die Modelle mit künstlicher Intelligenz verwenden, ist die Black-Box-Natur der Modelle. Wie kann ein Geschäftsinhaber überprüfen, ob AI auf der Grundlage der richtigen Daten die richtige Entscheidung trifft? Wie lässt sich das „Verhalten“ des Modells der künstlichen Intelligenz erklären? Das Fehlen „einfacher“ Antworten auf diese Fragen ist ein großes Problem, auf das Experten kürzlich gestoßen sind. IBM Watson OpenScale löst das Problem. Die fertige Vorhersage des Modells IBM Watson OpenScale wird von zwei verschiedenen Erklärungen begleitet, mit denen Sie das Verhalten des Algorithmus verstehen können. Aus diesem Grund scheint eine völlig greifbare Chance das Vertrauen der Manager zu erhöhen und infolgedessen die Implementierung von KI in Unternehmen zu beschleunigen.
Was ist Watson OpenScale überhaupt?
- Cloud-Service in der IBM Cloud verfügbarMit
kostenloser Nutzung im Rahmen des Lite-Kontos
- Überwachung und Verfolgung der Ergebnisse des ModellsMessung der Geschwindigkeit des Modells und Verfolgung der Ergebnisse bei der Projektion auf ein Geschäftsziel mit einer übersichtlichen und praktischen grafischen Oberfläche
- Optimierungsmodelle für geschäftliche ZweckeDie Geschäftsergebnisse des Modells arbeiten ständig daran, Daten anzupassen, um die Ergebnisse von Modellen für maschinelles Lernen zu verbessern
 - Verwaltung und Dekodierung des Modells
- Verwaltung und Dekodierung des ModellsUnterstützen Sie die Einhaltung gesetzlicher Vorschriften, indem Sie KI-Lösungen in Geschäftsprozessen verfolgen und erläutern sowie intelligente Fehler erkennen und korrigieren, um die Ergebnisse zu verbessern.

Möchten Sie Ihr Bias-Modell mit IBM Watson OpenScale testen?
Oder vielleicht herausfinden, warum sie diese oder jene Entscheidung für bestimmte Daten getroffen hat?
Besuchen Sie
am 9. Juli einen
kostenlosen eintägigen Workshop in Moskau und Sie können:
- Sich mit den Prinzipien und Merkmalen des Trainings und des Betriebs neuronaler Netze vertraut machen
- Trainieren Sie verschiedene Arten von neuronalen Netzen anhand der bereitgestellten Datensätze und detaillierten Anweisungen
- Testen Sie den Betrieb neuronaler Netze mithilfe der Watson OpenScale-Plattform und der IBM ART Open Source-Bibliothek (IBM Adversarial Robustness Toolbox)
- Probieren Sie KI-Funktionen aus, um mithilfe der NeuNetS-Engine schnell neuronale Netzwerkmodelle zu erstellen
Die gesamte Datenverarbeitung findet in der IBM Cloud statt - Sie benötigen lediglich einen Laptop und einen Browser. Anmeldung und detaillierte Informationen -
hier klicken .