Bei der Lokalisierung des Dienstes ist es wichtig, die Koordination der Übertragungen untereinander sorgfältig zu berücksichtigen. Der Leiter des Android-Entwicklungsteams des Yandex.Taxi-Clients, Alexander Bonel, sprach über die Praktiken und Tools, die die Lokalisierung vereinfachen. Im zweiten Teil des Berichts teilte Sasha die Erfahrungen mit der Unterstützung von RTL in der Anwendung mit: Was ist gut und was funktioniert nicht sofort für Android, welche Probleme treten aufgrund der RTL-Unterstützung auf und wie können sie in Zukunft minimiert werden?
- In meinem Bericht möchte ich Ihnen erläutern, welche grundlegenden Ideen und Praktiken wir in den Entwicklungsteams von Taxis für mobile Anwendungen verwenden, um Probleme im Zusammenhang mit der Lokalisierung und Aktualisierung von Übersetzungen in unseren Anwendungen zu lösen. Dann werde ich Ihnen sagen, wie wir die Unterstützung für das Arbeiten im Zeichenmodus von rechts nach links in der Anwendung implementiert haben.

Ich werde mit der Lokalisierung beginnen. Zunächst möchte ich die Terminologie klarstellen. Nach meinen Beobachtungen ist eine große Anzahl von Menschen der Ansicht, dass die Lokalisierung nur auf Übersetzungen beschränkt ist, obwohl sie auch die Probleme löst, die mit der Formatierung von Zahlen, Datumsangaben, Uhrzeit, der Arbeit mit Text und Symbolen, rechtlichen Aspekten und der Bereitstellung von Inhalten für den Verbraucher auf diese Weise verbunden sind dass er einen semantischen Wert für ihn hatte und nicht mehrdeutig wahrgenommen wurde. Und vieles mehr.
(Kommunikation mit dem Publikum darüber, wer wie viele Sprachen in Anwendungen unterstützt - Ed.)Ich möchte Ihnen eine Geschichte erzählen, die 2014 bei uns passiert ist. Wir haben dann die Taxi-Anwendung grundlegend überarbeitet. In einer der nächsten Versionen gaben wir den Benutzern die Möglichkeit, die Eingangsnummer anzugeben und diese Informationen auf dem Reiseinformationsbildschirm und vor allem auf dem Bestellbewertungsbildschirm anzuzeigen, den wir allen Benutzern zeigten, da wir definitiv eine Bewertung für die Reise erhalten wollten .
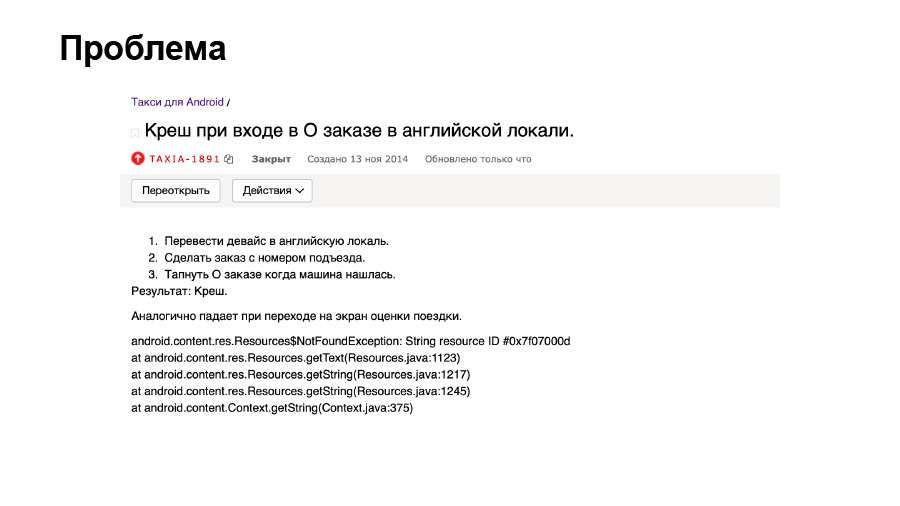
Zu dieser Zeit waren wir ziemlich frivol in Bezug auf den Lokalisierungsprozess und die Übersetzungen. Der gesamte Prozess war größtenteils manuell. Das Aktualisieren der Texte in den erforderlichen XML-Dateien und das Hinzufügen neuer Übersetzungen wurde manuell durchgeführt. Und der menschliche Faktor spielte eine Rolle. Der Entwickler hat festgestellt, dass die nächste Übertragung nicht im Standardgebietsschema erfolgt. Dies führte dazu, dass für Benutzer mit einem anderen Systemgebietsschema als der russischen Sprache die Anwendung am Ende der Reise abstürzte, wenn sie nach dem Eingang fragten. Und die Leute konnten keine andere Bestellung aufgeben.
Zu diesem Zeitpunkt wurden in der Anwendung zwei Sprachen unterstützt: Russisch und Englisch. Und wir haben nur in Russland in drei Städten gearbeitet: Moskau, Jekaterinburg, St. Petersburg.

Wir sind derzeit in 16 Ländern tätig und in 18 Sprachen übersetzt. Ich denke, Sie verstehen das ganze Problem, wenn wir zu diesem Zeitpunkt in diesem Zustand wären. Wir haben damals schon gemerkt, dass etwas geändert werden muss.

In Yandex verwenden die meisten Entwickler mobiler Anwendungen den intern entwickelten Dienst, um Probleme im Zusammenhang mit der Lokalisierung zu lösen. Es hat eine sehr praktische Benutzeroberfläche, es ist möglich, Ihr Projekt zu definieren, eine Reihe von Schlüsseln festzulegen, eine Reihe von Sprachen, in die Sie das Projekt übersetzen müssen. Und nachdem die Übersetzungen angezeigt wurden, können sie in jedem geeigneten Format hochgeladen werden. Er hat auch eine sehr gute Integration mit unseren internen Diensten. Es gibt eine Versionierung. Für mich als Entwickler ist es jedoch am wichtigsten, dass er über eine API verfügt, da dies bereits darauf hindeutet, dass alle mit Übersetzungen verbundenen manuellen Arbeiten automatisiert werden können. Was wir getan haben. Wir haben ein Plugin für Gradle entwickelt. Das Aktualisieren der Übersetzung in der Anwendung beruht nun darauf, dass der Entwickler eine einzige Aufgabe ausführt: updateTranslations.

In erster Näherung geht er zu einem Lokalisierungsdienst. Überprüft, ob aktuelle Übersetzungen vorliegen, lädt sie in das Projekt hoch und legt sie in den erforderlichen Dateien ab. Darüber hinaus überprüft er aber auch den Status der Übersetzungen im Lokalisierungsdienst in Bezug auf das, was jetzt im Projekt ist.

Bei der nächsten Ausführung des Git-Status sieht der Entwickler in seinem Arbeitsverzeichnis, welche Dateien sich geändert haben.
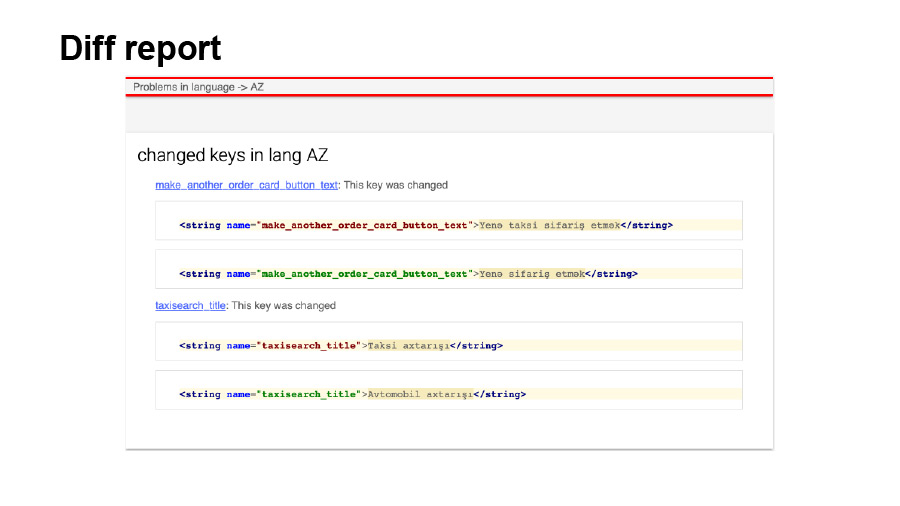
Er kann auch im generierten HTML-Bericht nachsehen, welcher Schlüssel für welchen Wert in welcher Sprache sich geändert hat.

Und er kann auch sehen, welche Probleme derzeit in den Übersetzungen seines Projekts vorhanden sind.

Das Plugin ist konfigurierbar. Wir können die Anzahl der Sprachen bestimmen, die unsere Anwendung unterstützt. Es ist sehr wichtig, dass die Lokalisierer eine neue Sprache starten und diese versehentlich in das Projekt eindringt, nachdem sie das Korrekturlesen und Korrekturlesen nicht durchlaufen hat.

Es gibt auch eine spezielle Neuzuordnungsfunktion. Ich werde etwas später ausführlicher darüber sprechen, wenn ich über RTL spreche.
Welche Probleme analysiert dieses Plugin jetzt? Das Problem, auf das wir 2014 gestoßen sind, ist alltäglich, mangelnde Übersetzung. Um dem Projekt eine neue Zeile und eine neue Übersetzung hinzuzufügen, reicht es für den Entwickler nicht aus, sie einfach in der XML-Datei zu definieren.

Erstens, wenn er dies nicht im Standardgebietsschema tut, verschwindet sein neu aufgewickelter Schlüssel bei der nächsten Synchronisation einfach und er weiß es in der Kompilierungsphase.

Wenn er den Schlüssel in der Standarddatei ermittelt, dies jedoch im Lokalisierungsdienst vergisst, erhält er bei der nächsten Ausführung der Aktualisierungsübersetzungen eine Fehlermeldung vom Plug-In, die ihn darüber informiert: „Dieser Schlüssel befindet sich in Ihrem Projekt, ist jedoch nicht im Lokalisierungsdienst vorhanden muss anfangen. "

Das zweite typische Problem ist der Mangel an Übersetzung. Wir erhalten eine Liste mit Links zu den Schlüsseln, für die es keine Übersetzung gibt, und verweisen sie in der Regel an unseren Manager, damit diese später die Kommunikation mit den Übersetzern einrichten. Der dritte Punkt tritt häufig auf, wenn sie beschlossen, die Verwendung von Formatargumenten auf irgendeine Weise zu überdenken, und beispielsweise anstelle eines Ganzzahlformats das Zeichenfolgenformat verwendeten.
Gleichzeitig vergaßen sie in einigen Übersetzungen, die Nummer in der Zeile zu ändern.

Und das vierte Problem wird auch durch den menschlichen Faktor verursacht, hauptsächlich bei der Übersetzung. Wenn Unicode-Zeichen in der Übersetzung verwendet werden, ist es sehr leicht, bei der Positionierung von Zeichen verwirrt zu werden und anstelle eines untrennbaren Leerzeichens eine Silbentrennung in eine andere Zeile zu setzen - dies versuchen wir loszuwerden.
Hier dreht sich alles um Lokalisierung.
Jetzt möchte ich über die Erfahrungen bei der Implementierung der Unterstützung für das Rendern von rechts nach links in der Anwendung am Beispiel Israels sprechen. Wir starteten 2018 unter dem Markennamen Yango in Israel. Wie sich herausstellte, lesen die Menschen in Israel anders als Sie und ich. Sie lesen von rechts nach links.

Wo willst du anfangen? Mit Android ist die Unterstützung für das Rendern von rechts nach links im Prinzip sofort einsatzbereit.
Es beginnt mit der Tatsache, dass Sie im Anwendungsmanifest im Anwendungselement das Attribut supportRtl = "true" deklarieren müssen. Aber ich möchte Ihnen gefallen: Wenn Sie das Facebook SDK für die soziale Autorisierung in Ihre Anwendungen integrieren, haben die fürsorglichen Facebook-Entwickler dies bereits für Sie getan. Wenn Sie das Manifest beim Zusammenführen nicht validieren, passt dieses Attribut mit dem Wert true in Ihre Anwendung und kann bereits in RTL verwendet werden. Das ist etwas zum Nachdenken.
Ich denke, dass die meisten, die im Publikum sitzen, wahrscheinlich nur minimale Unterstützung für Android 4.4 haben. Jemand hat mehr Glück - das ist 5.0 und höher. Jemand könnte weniger Glück haben und sie unterstützen 4.0 oder, Gott bewahre, 2.3. In diesem Fall treten große Probleme auf, da seit Version 4.2 eine umfassende RTL-Unterstützung für Android verfügbar ist. Daher werden Sie mit minSdk 17 Ihr Leben um eine Größenordnung vereinfachen.
Das Übertragen eines Projekts zur Arbeit mit RTL beginnt mit dem Refactoring-Tool in Android Studio - Fügen Sie nach Möglichkeit RTL-Unterstützung hinzu. Wir müssen Tribut zollen, es funktioniert ganz gut. Es geht die XML-Dateien Ihres Markups durch, untersucht das Vorhandensein von Attributen mit linken und rechten Werten für die Schwerkraft, für Auffüllungen und Ränder und ersetzt sie durch Start und Ende. Wenn Sie sehen möchten, wie Ihre Anwendung standardmäßig im Modus von rechts nach links funktioniert, benötigen Sie keinen Inhalt mit den sogenannten RTL-starken Zeichen - auf Hebräisch oder Arabisch. Sie müssen lediglich die RTL-Layoutrichtung erzwingen in den Einstellungen des Entwicklers aktivieren.
Welche Optionen gibt es zum Anpassen der Benutzeroberfläche und zum Rendern von Text, den Android für RTL bereitstellt?

Der erste Punkt ist das Attribut layoutDirection, das die beschriebene Option RTL-Layoutrichtung erzwingen verwendet. Sie hat nur vier mögliche Bedeutungen. Das heißt, es wird standardmäßig vom übergeordneten Element geerbt. Wir können sagen, dass das Layout basierend auf dem ausgewählten Gebietsschema gezeichnet wird. Sie können deutlich sagen, dass es von rechts nach links oder von links nach rechts gezeichnet wird.
Das zweite Element, das viele Menschen höchstwahrscheinlich aus Gewohnheit umgehen, wenn sie sich mit der Textausrichtung befassen, ist die Textausrichtung. Viele nutzen immer noch die Schwerkraft. Verwenden Sie nicht die Schwerkraft, um Text auszurichten, sondern verwenden Sie textAlignment.
Das dritte Attribut ist die Textwiedergaberichtung textDirection. Es hat eine ziemlich flexible Konfiguration. Hier können Sie bestimmen, wie der Text gerendert wird, je nachdem, welches erste starke Zeichen im Text enthalten ist, ob es sich um einen lateinischen starken LTR-Zeichensatz oder um eine hebräische starke RTL handelt. Wenn Sie RTL in der Anwendung vollständig unterstützen, müssen Sie es nicht umgehen, da das Ignorieren eines so lustigen Artefakts auftritt.

Entweder ist dies ein Osterei, oder es ist ein solcher Nebeneffekt bei der Implementierung von editText: Ihr Hinweis auf editText beginnt sich zu zerstreuen. Daher müssen Sie auf jeden Fall einen Wert für ihn festlegen.

Wenn Sie ein bestimmtes Rendering einiger grafischer Ressourcen oder ein Markup im RTL-Modus beobachten müssen, bietet Android die Möglichkeit, das Qualifikationsmerkmal ldrtl in Ihrem Daddy festzulegen, in das Sie eine beliebige Ressource einfügen können, und es wird im RTL-Rendering-Modus wie angegeben gezeichnet.
Manchmal muss zur Laufzeit der vom Backend kommende Text so wie er ist gezeichnet werden, wobei der Modus ignoriert wird, in dem Ihre Anwendung gerade arbeitet. Tatsächlich erfolgt dies im Text-Renderer aufgrund der Tatsache, dass der Text von den sogenannten Bidi-Unicode-Steuerzeichen umrahmt wird. Die Logik für die Arbeit mit diesen Zeichen an sich enthält die BidiFormatter-Klasse, die nur eine UnicodeWrap-Methode bereitstellt. Es nimmt CharSequence als Eingabe und gibt eine Zeichenfolge zurück, die von diesen Zeichen umrahmt wird. Es gibt eine erschöpfende Anzahl von ihnen, und im Prinzip sollte es die meisten Ihrer Probleme lösen.
Aber wenn es etwas so Spezifisches gibt, hat w3.org einen
guten Artikel darüber, wie man diese Symbole verwendet.
Welche Probleme hatten wir, als wir den RTL-Support in unserer Anwendung starteten? Erstens handelt es sich um einen Konflikt zwischen Lokalisierungsstandards.
BCP47 ist ein neuerer Lokalisierungsstandard, der insbesondere die Codes einiger Gebietsschemas geändert hat. Tatsache ist, dass es ein Problem mit der Gebietsschema-Java-Klasse gibt. Es funktioniert standardmäßig im Abwärtskompatibilitätsmodus und konvertiert Gebietsschema-Codes von BCP in ISO. Das heißt, wir haben dies gesehen, als der iw-Code anstelle des he-Codes in unser Backend im Accept-Language-Header verschoben wurde.

Wenn Sie sich an die Folie mit der Konfiguration unseres Plugins erinnern, war nur dafür eine Neuzuordnung erforderlich - um Inhalte von ihm nach iw zu übersetzen.
Wenn Sie das BCP-Format verwenden müssen, ist dies vollständig im Apache Cordova-Projekt implementiert. Sie haben eine Globalisierungsklasse und eine Implementierung von localeToBcp47Language.

Ein weiterer Punkt, der mit RTL-Unterstützung in der Anwendung „liefert“, sind Animationen. Hier besteht der Vorteil darin, dass nur Animationen entlang der X-Achse betroffen sind. Die einzige Lösung oder Vorgehensweise, mit der Sie weitere Probleme vermeiden können, ist möglicherweise die Möglichkeit, die absoluten Animationen in Richtung relativer Animationen zu überdenken.
Ein Problem, das möglicherweise nur durch Reflexion gelöst wird, weil es starr in der Komponente selbst implementiert ist, ist die Hinweisausrichtung von TextInputLayout. Tatsache ist, dass ein Hinweis, der in RTL-starken Zeichen auf Hebräisch angegeben ist, deutlich nach rechts ausgerichtet ist, obwohl der Inhalt, den Sie in den Bearbeitungstext eingeben, aus lateinischen Zeichen stammen kann. Umgekehrt. Wenn Ihr Hinweis lateinisch ist, wird er deutlich nach links ausgerichtet. Dies kann nur durch Reflexion gelöst werden.

Nachdem Sie RTL in Ihrer Anwendung implementiert haben, ist es letztendlich sinnvoll, die Schweregrade für RTL-Probleme, die Lint analysiert, zu überdenken. Es gibt nur vier von ihnen. Wenn Sie RTL in Ihrer Anwendung nicht unterstützen, aber irgendwo explizit RTL-spezifische Attribute verwenden, ist dies RtlEnabled (Lint wird Sie darüber informieren).

Wenn Sie RTL in der Anwendung unterstützen, die minSdkVersion Ihrer Anwendung jedoch unter 17 liegt, müssen Sie auch weiterhin Attribute des linken und rechten Typs verwenden. Sie können nicht nur die Start- und Endattribute in Ihrem Markup verwenden. Dies ist, was RtlCompat analysiert. RtlSymmetry schwört, wenn es asymmetrische Polsterungen sieht. Im Allgemeinen ist meine Meinung, dass aapt bei der Verarbeitung von Ressourcen abstürzen sollte, wenn es auf symmetrische Auffüllungen stößt. Wenn Sie asymmetrische Zugriffe benötigen, verwenden Sie Ränder als vollwertigen Layoutparameter.
Schließlich ist das vierte Problem die fest codierte RTL. Dies ist nur so, dass in den Attributen nur die Werte von links und rechts angezeigt werden. Dies negiert im Wesentlichen das Refactoring-Tool. Fügen Sie nach Möglichkeit RTL-Unterstützung hinzu. Alles kommt von Lint beim Betreten von RTL. Eine Analyseimplementierung ist auch in AOSP in der Klasse RtlDetector verfügbar. Das heißt, wenn die Vorstellungskraft es Ihnen erlaubt, können Sie sich etwas Eigenes einfallen lassen, indem Sie sich ansehen, wie die Analyse jetzt abläuft.
Mein Bericht neigt sich dem Ende zu. Ich möchte einige Thesen zum Aufbau der richtigen Lokalisierung in unserer Anwendung geben, zu denen wir im Laufe der Zeit gekommen sind.

Denken Sie zu Beginn des Projekts zunächst an die Internationalisierung. Ich habe es nicht wirklich erwähnt. Dies ist überhaupt nicht dasselbe wie Lokalisierung. Tatsächlich ermöglicht die Internationalisierung die Lokalisierung in der Anwendung, im Produkt. Dies funktioniert sofort in Java, da es vollständige Unicode-Unterstützung bietet, und in Android - aufgrund seines umfangreichen Ressourcensystems. Vielleicht ist das Einzige, was hier passieren kann, unsere Fixierung als Entwickler auf das Thema "Ich schreibe die Anwendung nur für Russisch, was bedeutet, dass ich sie nur mit der russischen Sprache überprüfen werde." Und wenn Sie anfangen, die armenische, georgische, hebräische oder arabische Sprache in der Anwendung zu verwenden, sieht das Bild völlig anders aus und zeigt Ihr übliches Paradigma.
Zweiter Moment. Erwägen Sie, die Lokalisierung in Ihr CI einzubetten. Es ist sehr enttäuschend, während der Testphase des Release Candidate, auf die Sie sich für mehrere Wochen vorbereiten können, etwas über die mit Übersetzungen verbundenen Probleme zu erfahren. Das heißt, wir führen diese Aufgabe jetzt für jede Poolanforderung aus, damit wir im Voraus sicher sein können, dass mit Übersetzungen alles in Ordnung ist und wir den neuen Code in den Hauptzweig des Projekts einfrieren können.
Der dritte Punkt. Respektieren Sie die Arbeit der Übersetzer und Ihr Budget. Löschen Sie zunächst nicht verwendete Ressourcen, da die Benutzer weiterhin Zeit und Geld für die Übersetzung von Zeichenfolgen aufwenden können, die Sie letztendlich nicht in Ihrem Projekt verwenden. Zweitens folgen Sie den Übersetzungen, die sich in Ihrem Repository im Lokalisierungsdienst befinden, aber nicht in Ihrem Code enthalten sind.
Wenn die API Ihres Lokalisierungsdienstes Informationen darüber enthält, wann ein bestimmter Schlüssel geöffnet wurde, und Sie Heuristiken wie "Wenn der Schlüssel vor mehr als einem Monat geöffnet wurde" verwenden können, überprüfen Sie dessen Vorhandensein in der neuesten Version des Master-Brunchs. Wenn er nicht da ist, ist dies höchstwahrscheinlich ein klarer Kandidat, um es zu entfernen, damit die Lokalisierer keine Zeit damit verbringen.
Ein mehr oder weniger universeller Kandidat für eine Silberkugel besteht darin, Zeichenfolgen im Backend und nicht auf dem Client zu speichern. Dies gibt Ihnen zumindest die Möglichkeit, sie auf der Anwendungsseite immer relevant zu halten.
Wir haben ein sehr vielfältiges Benutzerpublikum, jeder nimmt die Welt und den Anwendungsinhalt auf seine Weise wahr. Unsere Aufgabe als Entwickler ist es, diese Wahrnehmung aufrechtzuerhalten. Mein Bericht darüber ist vorbei. Vielen Dank!