Hallo Habr! Ich präsentiere Ihnen die kostenlose Übersetzung von "Guide to App Architecture" von
JetPack . Ich bitte Sie, alle Kommentare zur Übersetzung in den Kommentaren zu hinterlassen, und sie werden behoben. Auch Kommentare von Personen, die die vorgestellte Architektur mit Empfehlungen für ihre Verwendung verwendet haben, sind für alle nützlich.
Dieses Handbuch behandelt Best Practices und empfohlene Architekturen zum Erstellen robuster Anwendungen. Diese Seite setzt eine grundlegende Einführung in das Android Framework voraus. Wenn Sie mit der Entwicklung von Android-Apps noch nicht vertraut sind, lesen Sie zunächst unsere
Entwicklerhandbücher , um mehr über die in diesem Handbuch genannten Konzepte zu erfahren. Wenn Sie sich für Anwendungsarchitektur interessieren und sich mit den Materialien in diesem Handbuch in Bezug auf die Programmierung auf Kotlin vertraut machen möchten, lesen Sie den Udacity-Kurs
„Entwickeln von Anwendungen für Android mit Kotlin“ .
Mobile App Benutzererfahrung
In den meisten Fällen haben Desktopanwendungen einen einzigen Einstiegspunkt vom Desktop oder Launcher und werden dann als einzelner monolithischer Prozess ausgeführt. Android-Anwendungen haben eine viel komplexere Struktur. Eine typische Android-Anwendung enthält mehrere
Anwendungskomponenten , darunter
Aktivitäten ,
Fragmente ,
Dienste ,
ContentProvider und
BroadcastReceiver .
Sie deklarieren alle oder einige dieser Anwendungskomponenten im Anwendungsmanifest. Android verwendet diese Datei dann, um zu entscheiden, wie Ihre Anwendung in die allgemeine Benutzeroberfläche des Geräts integriert werden soll. Da eine gut geschriebene Android-Anwendung mehrere Komponenten enthält und Benutzer häufig in kurzer Zeit mit mehreren Anwendungen interagieren, müssen sich Anwendungen an verschiedene Arten von Workflows und benutzergesteuerten Aufgaben anpassen.
Überlegen Sie beispielsweise, was passiert, wenn Sie ein Foto in Ihrer bevorzugten Social Media-Anwendung freigeben:
- Die Anwendung löst die Absicht der Kamera aus. Android startet eine Kameraanwendung, um die Anfrage zu verarbeiten. Im Moment hat der Benutzer die Anwendung für soziale Netzwerke verlassen, und seine Erfahrung als Benutzer ist einwandfrei.
- Eine Kameraanwendung kann andere Absichten auslösen, z. B. das Starten einer Dateiauswahl, mit der möglicherweise eine andere Anwendung gestartet wird.
- Am Ende kehrt der Benutzer zur Anwendung für soziale Netzwerke zurück und teilt das Foto.
Der Benutzer kann jederzeit durch einen Anruf oder eine Benachrichtigung unterbrochen werden. Nach der mit diesem Interrupt verbundenen Aktion erwartet der Benutzer, dass er diesen Fotofreigabeprozess zurückgeben und fortsetzen kann. Dieses Anwendungswechselverhalten ist auf Mobilgeräten üblich, daher muss Ihre Anwendung diese Punkte (Aufgaben) korrekt behandeln.
Denken Sie daran, dass die Ressourcen mobiler Geräte ebenfalls begrenzt sind. Daher kann das Betriebssystem jederzeit einige Anwendungsprozesse zerstören, um Speicherplatz für neue freizugeben.
Unter den Bedingungen dieser Umgebung können die Komponenten Ihrer Anwendung einzeln und nicht in der richtigen Reihenfolge gestartet werden, und das Betriebssystem oder der Benutzer können sie jederzeit zerstören. Da diese Ereignisse nicht unter Ihrer Kontrolle stehen,
sollten Sie keine Daten oder Zustände in Ihren Anwendungskomponenten speichern und Ihre Anwendungskomponenten sollten nicht voneinander abhängig sein.
Allgemeine architektonische Prinzipien
Wie sollten Sie Ihre Anwendung entwickeln, wenn Sie keine Anwendungskomponenten zum Speichern von Daten und Anwendungsstatus verwenden sollten?
Aufteilung der Verantwortung
Das wichtigste Prinzip ist
die Aufteilung der Verantwortlichkeiten . Ein häufiger Fehler ist, wenn Sie Ihren gesamten Code in
Aktivität oder
Fragment schreiben. Dies sind Benutzeroberflächenklassen, die nur eine Logik enthalten sollten, die die Interaktion der Benutzeroberfläche und des Betriebssystems verarbeitet. Indem Sie die Verantwortung in diesen Klassen
(SRPs) so weit wie möglich
teilen , können Sie viele der Probleme vermeiden, die mit dem Anwendungslebenszyklus verbunden sind.
Steuerung der Benutzeroberfläche vom Modell
Ein weiteres wichtiges Prinzip ist, dass Sie
Ihre Benutzeroberfläche von einem Modell aus
steuern müssen, vorzugsweise von einem permanenten Modell aus. Modelle sind die Komponenten, die für die Verarbeitung der Daten für die Anwendung verantwortlich sind. Sie sind unabhängig von
View- Objekten und Anwendungskomponenten und daher nicht vom Anwendungslebenszyklus und den damit verbundenen Problemen betroffen.
Ein permanentes Modell ist aus folgenden Gründen ideal:
- Ihre Benutzer verlieren keine Daten, wenn das Android-Betriebssystem Ihre Anwendung zerstört, um Ressourcen freizugeben.
- Ihre Anwendung funktioniert weiterhin, wenn die Netzwerkverbindung instabil oder nicht verfügbar ist.
Durch die Organisation der Grundlage Ihrer Anwendung in Modellklassen mit einer klar definierten Verantwortung für das Datenmanagement wird Ihre Anwendung testbarer und unterstützbarer.
Empfohlene Anwendungsarchitektur
In diesem Abschnitt wird gezeigt, wie Sie eine Anwendung mithilfe von
Architekturkomponenten strukturieren und in einem
End- to-
End-Nutzungsszenario arbeiten .
Hinweis Es ist nicht möglich, Anwendungen zu schreiben, die für jedes Szenario am besten geeignet sind. Die empfohlene Architektur ist jedoch ein guter Ausgangspunkt für die meisten Situationen und Workflows. Wenn Sie bereits eine gute Möglichkeit haben, Android-Anwendungen zu schreiben, die den allgemeinen Architekturprinzipien entsprechen, sollten Sie diese nicht ändern.Stellen Sie sich vor, wir erstellen eine Benutzeroberfläche, in der ein Benutzerprofil angezeigt wird. Wir verwenden eine private API und eine REST-API, um Profildaten abzurufen.
Rückblick
Betrachten Sie zunächst das Interaktionsschema der Module der Architektur der fertigen Anwendung:
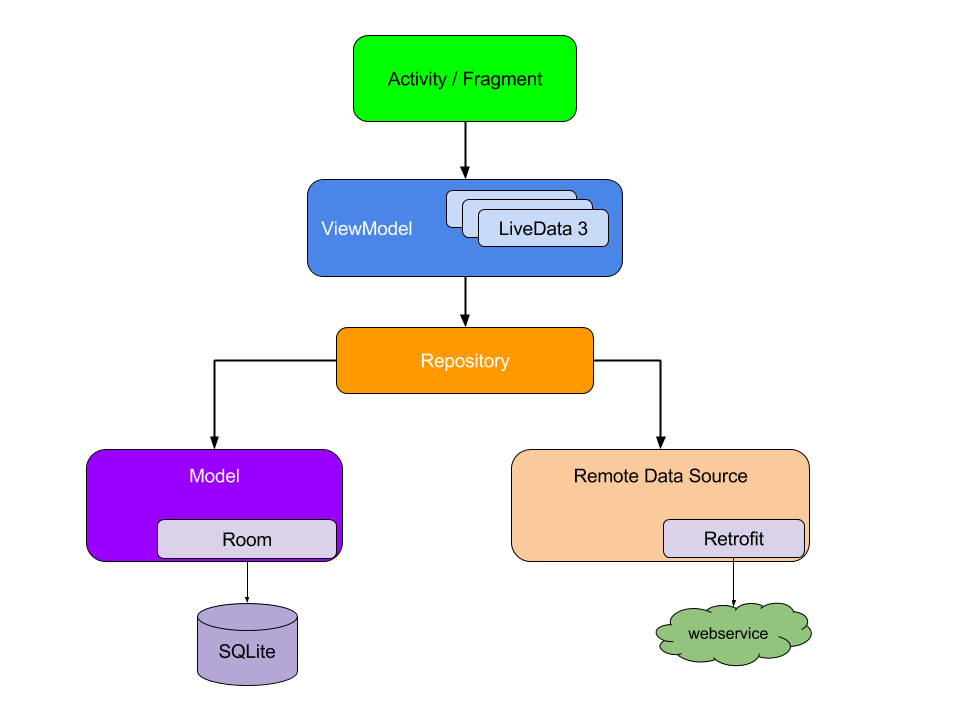
Bitte beachten Sie, dass jede Komponente nur eine Ebene darunter von der Komponente abhängt. Beispielsweise hängen Aktivität und Fragmente nur vom Ansichtsmodell ab. Repository ist die einzige Klasse, die von vielen anderen Klassen abhängt. In diesem Beispiel hängt der Speicher von einem persistenten Datenmodell und einer internen Remote-Datenquelle ab.
Dieses Entwurfsmuster schafft eine konsistente und angenehme Benutzererfahrung. Unabhängig davon, ob der Benutzer einige Minuten nach dem Schließen oder einige Tage später zur Anwendung zurückkehrt, werden ihm sofort Benutzerinformationen angezeigt, dass die Anwendung lokal gespeichert ist. Wenn diese Daten nicht mehr aktuell sind, aktualisiert das Anwendungsspeichermodul die Daten im Hintergrund.
Erstellen Sie eine Benutzeroberfläche
Die Benutzeroberfläche besteht aus dem Fragment
UserProfileFragment und der entsprechenden
user_profile_layout.xml .
Zur Verwaltung der Benutzeroberfläche muss unser Datenmodell die folgenden Datenelemente enthalten:
- Benutzer-ID: Benutzer-ID. Die beste Lösung besteht darin, diese Informationen mit den Argumenten des Fragments an das Fragment zu übergeben. Wenn das Android-Betriebssystem unseren Prozess zerstört, werden diese Informationen gespeichert, sodass die Kennung beim nächsten Start unserer Anwendung verfügbar ist.
- Benutzerobjekt: Eine Datenklasse, die Benutzerinformationen enthält.
Wir verwenden ein
UserProfileViewModel das auf einer Komponente der ViewModel-Architektur basiert, um diese Informationen zu speichern.
Das ViewModel- Objekt stellt Daten für eine bestimmte Benutzeroberflächenkomponente bereit, z. B. ein Fragment oder eine Aktivität, und enthält eine Geschäftsdatenverarbeitungslogik für die Interaktion mit dem Modell. Beispielsweise kann das ViewModel andere Komponenten aufrufen, um Daten zu laden, und Benutzeranforderungen für Datenänderungen weiterleiten. ViewModel kennt die Komponenten der Benutzeroberfläche nicht und ist daher nicht von Konfigurationsänderungen betroffen, z. B. der Neuerstellung von Aktivitäten beim Drehen des Geräts.Jetzt haben wir die folgenden Dateien identifiziert:
user_profile.xml : Definiertes Layout der Benutzeroberfläche.UserProfileFragment : beschreibt einen Benutzeroberflächen-Controller, der für die Anzeige von Informationen für den Benutzer verantwortlich ist.UserProfileViewModel : Eine Klasse, die dafür verantwortlich ist, Daten für die Anzeige in UserProfileFragment und auf Benutzerinteraktionen zu reagieren.
Die folgenden Codefragmente zeigen den ursprünglichen Inhalt dieser Dateien. (Die Layoutdatei ist der Einfachheit halber weggelassen.)
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } class UserProfileFragment : Fragment() { private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } }
Wie verbinden wir diese Codemodule, nachdem wir sie haben? Nachdem das Benutzerfeld in der UserProfileViewModel-Klasse festgelegt wurde, benötigen wir eine Möglichkeit, die Benutzeroberfläche zu informieren.
Hinweis Mit SavedStateHandle kann das ViewModel auf den gespeicherten Status und die Argumente des zugeordneten Fragments oder der zugeordneten Aktion zugreifen.
Jetzt müssen wir unser Fragment informieren, wenn das Benutzerobjekt empfangen wird. Hier wird die Komponente der LiveData-Architektur angezeigt.
LiveData ist ein beobachtbarer Dateninhaber. Andere Komponenten in Ihrer Anwendung können Änderungen an Objekten mithilfe dieses Halters verfolgen, ohne explizite und harte Abhängigkeitspfade zwischen ihnen zu erstellen. Die LiveData-Komponente berücksichtigt auch den Lebenszyklusstatus der Komponenten Ihrer Anwendung, z. B. Aktivitäten, Fragmente und Dienste, und enthält eine Bereinigungslogik, um Objektverluste und übermäßigen Speicherverbrauch zu verhindern.
Hinweis Wenn Sie bereits Bibliotheken wie RxJava oder Agera verwenden, können Sie diese anstelle von LiveData weiterhin verwenden. Stellen Sie jedoch bei Verwendung von Bibliotheken und ähnlichen Ansätzen sicher, dass Sie den Lebenszyklus Ihrer Anwendung ordnungsgemäß handhaben. Stellen Sie insbesondere sicher, dass Sie Ihre Datenströme anhalten, wenn der zugeordnete LifecycleOwner gestoppt wird, und diese Streams zerstören, wenn der zugeordnete LifecycleOwner zerstört wurde. Sie können auch das Artefakt android.arch.lifecycle: Jetstreams hinzufügen, um LiveData mit einer anderen Jetstream-Bibliothek wie RxJava2 zu verwenden.Um die LiveData-Komponente in unsere Anwendung aufzunehmen, ändern wir den
UserProfileViewModel in
UserProfileViewModel in LiveData.
UserProfileFragment jetzt über
UserProfileFragment informiert. Da dieses
LiveData- Feld den Lebenszyklus unterstützt, werden Links automatisch
gelöscht , wenn sie nicht mehr benötigt werden.
class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() }
Jetzt ändern wir das
UserProfileFragment , um die Daten im
ViewModel zu beobachten und die Benutzeroberfläche entsprechend den Änderungen zu aktualisieren:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) {
Jedes Mal, wenn die Benutzerprofildaten aktualisiert werden, wird der Rückruf
onChanged () aufgerufen und die Benutzeroberfläche aktualisiert.
Wenn Sie mit anderen Bibliotheken vertraut sind, die beobachtbare Rückrufe verwenden, haben Sie möglicherweise festgestellt, dass wir die
onStop () -Methode des Fragments nicht neu definiert haben, um die Beobachtung der Daten zu beenden. Dieser Schritt ist für LiveData optional, da er den Lebenszyklus unterstützt. Dies bedeutet, dass der Rückruf
onChanged() nicht aufgerufen wird, wenn sich das Fragment in einem inaktiven Zustand befindet. Das heißt, er hat einen Aufruf von
onStart () erhalten , aber noch keinen
onStop() ) erhalten. LiveData entfernt den Beobachter auch automatisch, wenn die
onDestroy () -Methode für das Fragment
aufgerufen wird .
Wir haben keine Logik hinzugefügt, um Konfigurationsänderungen zu behandeln, z. B. das Drehen des Gerätebildschirms durch den Benutzer.
UserProfileViewModel automatisch wiederhergestellt, wenn die Konfiguration geändert wird. Sobald ein neues Fragment erstellt wird, erhält es dieselbe
ViewModel Instanz und der Rückruf wird sofort unter Verwendung der aktuellen Daten aufgerufen. Da
ViewModel Objekte so konzipiert sind, dass sie die entsprechenden
View Objekte überleben, die sie aktualisieren, sollten Sie keine direkten Verweise auf
View Objekte in Ihre ViewModel-Implementierung aufnehmen. Weitere Informationen zur Lebensdauer des
ViewModel im Lebenszyklus der Komponenten der Benutzeroberfläche (siehe
ViewModel-Lebenszyklus).Datenabruf
Wie können wir Benutzerprofildaten
UserProfileViewModel ,
UserProfileFragment wir LiveData verwendet haben, um
UserProfileViewModel mit UserProfileFragment zu verbinden?
In diesem Beispiel wird davon ausgegangen, dass unser Backend eine REST-API bereitstellt. Wir verwenden die Retrofit-Bibliothek, um auf unser Backend zuzugreifen. Sie können jedoch auch eine andere Bibliothek verwenden, die denselben Zweck erfüllt.
Hier ist unsere Definition eines
Webservice , der auf unser Backend verweist:
interface Webservice { @GET("/users/{user}") fun getUser(@Path("user") userId: String): Call<User> }
Eine erste Idee für die Implementierung eines
ViewModel könnte darin bestehen, den
Webservice aufzurufen, um die Daten abzurufen und diese Daten unserem
LiveData Objekt
LiveData . Dieses Design funktioniert, aber die Verwendung macht es schwieriger, unsere Anwendung zu warten, wenn sie wächst. Dies gibt der
UserProfileViewModel Klasse zu viel Verantwortung, was gegen das Prinzip
der Interessentrennung verstößt. Darüber hinaus ist der Bereich des ViewModel dem Lebenszyklus
Aktivität oder
Fragment zugeordnet. Dies bedeutet, dass Daten vom
Webservice verloren gehen, wenn der Lebenszyklus des zugeordneten Benutzeroberflächenobjekts endet. Dieses Verhalten führt zu einer unerwünschten Benutzererfahrung.
Stattdessen delegiert unser
ViewModel den Prozess des Abrufs von Daten an ein neues Speichermodul.
Repository- Module verarbeiten Datenoperationen. Sie bieten eine saubere API, damit der Rest der Anwendung diese Daten problemlos abrufen kann. Sie wissen, woher sie die Daten beziehen und welche API-Aufrufe beim Aktualisieren der Daten ausgeführt werden müssen. Sie können sich Repositorys als Vermittler zwischen verschiedenen Datenquellen vorstellen, z. B. persistenten Modellen, Webdiensten und Caches.Unsere
UserRepository Klasse, die im folgenden
UserRepository gezeigt wird, verwendet eine Instanz von
WebService , um Benutzerdaten abzurufen:
class UserRepository { private val webservice: Webservice = TODO()
Obwohl das Speichermodul unnötig erscheint, dient es einem wichtigen Zweck: Es abstrahiert Datenquellen vom Rest der Anwendung. Jetzt weiß unser
UserProfileViewModel nicht, wie Daten abgerufen werden sollen, sodass wir Präsentationsmodelle mit Daten aus verschiedenen Datenextraktionsimplementierungen bereitstellen können.
Hinweis Der Einfachheit halber haben wir den Fall von Netzwerkfehlern übersehen. Eine alternative Implementierung, die Fehler und den Download-Status aufdeckt, finden Sie im Anhang: Offenlegung des Netzwerkstatus.
Verwalten von Abhängigkeiten zwischen KomponentenDie
UserRepository genannte
UserRepository Klasse benötigt eine Instanz von
Webservice , um Benutzerdaten abzurufen. Er könnte nur eine Instanz erstellen, muss dafür aber auch die Abhängigkeiten der
Webservice Klasse kennen. Darüber hinaus ist
UserRepository wahrscheinlich nicht die einzige Klasse, die einen Webdienst benötigt. In dieser Situation müssen wir den Code duplizieren, da jede Klasse, die einen Link zum
Webservice benötigt, wissen muss, wie er und seine Abhängigkeiten erstellt werden. Wenn jede Klasse einen neuen
WebService , kann unsere Anwendung sehr ressourcenintensiv werden.
Um dieses Problem zu lösen, können Sie die folgenden Entwurfsmuster verwenden:
- Abhängigkeitsinjektion (DI) . Mit der Abhängigkeitsinjektion können Klassen ihre Abhängigkeiten definieren, ohne sie zu erstellen. Zur Laufzeit ist eine andere Klasse für die Bereitstellung dieser Abhängigkeiten verantwortlich. Wir empfehlen die Dagger 2- Bibliothek für die Implementierung der Abhängigkeitsinjektion in Android-Anwendungen. Dolch 2 erstellt automatisch Objekte unter Umgehung des Abhängigkeitsbaums und bietet Garantien zur Kompilierungszeit für Abhängigkeiten.
- (Service Location) Service Locator: Die Service Locator-Vorlage bietet eine Registrierung, in der Klassen ihre Abhängigkeiten abrufen können, anstatt sie zu erstellen.
Das Implementieren einer Dienstregistrierung ist einfacher als die Verwendung von DI. Wenn Sie DI noch nicht kennen, verwenden Sie stattdessen die Vorlage: Dienstort.
Mit diesen Vorlagen können Sie Ihren Code skalieren, da sie eindeutige Vorlagen zum Verwalten von Abhängigkeiten enthalten, ohne den Code zu duplizieren oder zu komplizieren. Darüber hinaus können Sie mit diesen Vorlagen schnell zwischen Test- und Produktionsimplementierungen für die Datenerfassung wechseln.
Unsere Beispielanwendung verwendet
Dolch 2 , um die Abhängigkeiten des
Webservice Objekts zu verwalten.
Verbinden Sie ViewModel und Storage
Jetzt ändern wir unser
UserProfileViewModel , um das
UserRepository Objekt zu verwenden:
class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = userRepository.getUser(userId) }
Caching
Die
UserRepository Implementierung abstrahiert den Aufruf des
Webservice Objekts. Da sie jedoch nur auf einer Datenquelle basiert, ist sie nicht sehr flexibel.
Das Hauptproblem bei der Implementierung von
UserRepository besteht darin, dass diese Daten nach dem Empfang von Daten aus unserem Backend nirgendwo gespeichert werden. Wenn der Benutzer
UserProfileFragment verlässt und dann zu ihm zurückkehrt, muss unsere Anwendung die Daten abrufen, auch wenn sie sich nicht geändert haben.
Dieses Design ist aus folgenden Gründen nicht optimal:
- Es verbraucht wertvolle Verkehrsressourcen.
- Dadurch wartet der Benutzer auf den Abschluss einer neuen Anforderung.
Um diese Mängel zu
UserRepository , fügen wir unserem
UserRepository eine neue Datenquelle
UserRepository , die
User im Speicher zwischenspeichert:
Persistente Daten
Wenn der Benutzer in unserer aktuellen Implementierung das Gerät dreht oder das Gerät verlässt und sofort zur Anwendung zurückkehrt, wird die vorhandene Benutzeroberfläche sofort sichtbar, da der Speicher Daten aus unserem Cache im Speicher abruft.
Was passiert jedoch, wenn ein Benutzer die Anwendung verlässt und einige Stunden nach Abschluss des Vorgangs durch das Android-Betriebssystem zurückkehrt? Basierend auf unserer aktuellen Implementierung in dieser Situation müssen wir erneut Daten aus dem Netzwerk abrufen. Dieser Upgrade-Prozess ist nicht nur eine schlechte Benutzererfahrung. Es ist auch verschwenderisch, weil es wertvolle mobile Daten verbraucht.
Sie können dieses Problem lösen, indem Sie Webanfragen zwischenspeichern. Dies führt jedoch zu einem neuen Schlüsselproblem: Was passiert, wenn dieselben Benutzerdaten in einer Anfrage eines anderen Typs angezeigt werden, z. B. beim Empfang einer Freundesliste? Die Anwendung zeigt widersprüchliche Daten an, was bestenfalls verwirrend ist. Beispielsweise kann unsere Anwendung zwei verschiedene Versionen der Daten desselben Benutzers anzeigen, wenn der Benutzer zu unterschiedlichen Zeiten eine Freundschaftslistenanforderung und eine Einzelbenutzeranforderung gesendet hat. Unsere Anwendung müsste herausfinden, wie diese widersprüchlichen Daten kombiniert werden können.
Der richtige Weg, um mit dieser Situation umzugehen, ist die Verwendung eines konstanten Modells. Die
Room Permanent Data Library (DB) hilft uns dabei.
Room ist eine Objektzuordnungsbibliothek, die die lokale Datenspeicherung mit einem Mindeststandardcode bereitstellt. Zur Kompilierungszeit wird jede Abfrage auf Übereinstimmung mit Ihrem Datenschema überprüft, sodass fehlerhafte SQL-Abfragen zu Fehlern beim Kompilieren führen und nicht zur Laufzeit abstürzen. Raumzusammenfassungen von einigen grundlegenden Implementierungsdetails von SQL-Rohtabellen und -Abfragen. Außerdem können Sie Änderungen an Datenbankdaten, einschließlich Sammlungen und Verbindungsanforderungen, beobachten und solche Änderungen mithilfe von LiveData-Objekten offenlegen. Es werden sogar explizit Ausführungsbeschränkungen definiert, die häufig auftretende Threading-Probleme lösen, z. B. den Zugriff auf den Speicher im Haupt-Thread.
Hinweis Wenn Ihre Anwendung bereits eine andere Lösung verwendet, z. B. ORM (SQLite Object Relational Mapping), müssen Sie die vorhandene Lösung nicht durch Room ersetzen. Wenn Sie jedoch eine neue Anwendung schreiben oder eine vorhandene Anwendung neu organisieren, empfehlen wir, Room zum Speichern Ihrer Anwendungsdaten zu verwenden. So können Sie die Abstraktion der Bibliothek und die Abfragevalidierung nutzen.Um Room nutzen zu können, müssen wir unser lokales Layout definieren. Zuerst fügen wir die Annotation
@Entity zu unserer
User und
@PrimaryKey Annotation
@PrimaryKey im Feld Klassen-
id . Diese Anmerkungen markieren
User als Tabelle in unserer Datenbank und
id als Primärschlüssel der Tabelle:
@Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String )
Anschließend erstellen wir die Datenbankklasse, indem wir
RoomDatabase für unsere Anwendung implementieren:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase()
Beachten Sie, dass
UserDatabase abstrakt ist. Die Raumbibliothek bietet automatisch eine Implementierung davon. Weitere Informationen finden Sie in der Dokumentation zu
Room .
Jetzt brauchen wir eine Möglichkeit, Benutzerdaten in die Datenbank einzufügen. Für diese Aufgabe erstellen wir
ein Datenzugriffsobjekt (DAO) .
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): LiveData<User> }
Beachten Sie, dass die Lademethode ein Objekt vom Typ LiveData zurückgibt. Room weiß, wann die Datenbank geändert wird, und benachrichtigt automatisch alle aktiven Beobachter über Datenänderungen. Da Room
LiveData verwendet , ist dieser Vorgang effizient. Daten werden nur aktualisiert, wenn mindestens ein Beobachter aktiv ist.
Hinweis: Der Raum prüft auf Ungültigmachung aufgrund von Tabellenänderungen. Dies bedeutet, dass falsch positive Benachrichtigungen gesendet werden können.Nachdem wir unsere
UserDao Klasse definiert haben,
UserDao wir auf das DAO aus unserer Datenbankklasse:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao }
Jetzt können wir unser
UserRepository so ändern, dass es die
UserRepository enthält:
Bitte beachten Sie, dass wir unser
UserProfileViewModel oder
UserProfileFragment nicht ändern
UserProfileViewModel , auch wenn wir die Datenquelle in
UserRepository UserProfileFragment . Dieses kleine Update zeigt die Flexibilität unserer Anwendungsarchitektur. Es eignet sich auch hervorragend zum Testen, da wir ein gefälschtes
UserRepository und gleichzeitig unser Produktions-
UserProfileViewModel testen können.
Wenn Benutzer innerhalb weniger Tage zurückkehren, zeigt eine Anwendung, die diese Architektur verwendet, wahrscheinlich veraltete Informationen an, bis das Repository aktualisierte Informationen erhält. Abhängig von Ihrem Anwendungsfall werden möglicherweise keine veralteten Informationen angezeigt. Stattdessen können Sie
Platzhalterdaten anzeigen, die Dummy-Werte anzeigen und anzeigen, dass Ihre Anwendung gerade aktuelle Informationen lädt und lädt.
Die einzige Quelle der WahrheitIn der Regel geben verschiedene REST-API-Endpunkte dieselben Daten zurück. Wenn unser Backend beispielsweise über einen anderen Endpunkt verfügt, der eine Liste von Freunden zurückgibt, kann dasselbe Benutzerobjekt von zwei verschiedenen API-Endpunkten stammen, möglicherweise sogar mit unterschiedlichen Detaillierungsgraden. Wenn wir UserRepositorydie Antwort von der Anforderung Webserviceunverändert zurückgeben, ohne die Konsistenz zu überprüfen, können unsere Benutzeroberflächen verwirrende Informationen anzeigen, da die Version und das Format der Daten aus dem Speicher vom zuletzt aufgerufenen Endpunkt abhängen.Aus diesem Grund UserRepositoryspeichert unsere Implementierung Webdienstantworten in einer Datenbank. Änderungen an der Datenbank lösen dann Rückrufe für aktive LiveData- Objekte aus . Mit diesem Modell,Die Datenbank ist die einzige Quelle der Wahrheit , und andere Teile der Anwendung greifen über unsere darauf zu UserRepository. Unabhängig davon, ob Sie einen Festplatten-Cache verwenden, empfehlen wir, dass Ihr Repository die Datenquelle als einzige Wahrheitsquelle für den Rest Ihrer Anwendung identifiziert.Betriebsfortschritt anzeigen
In einigen Anwendungsfällen, z. B. beim Pull-to-Refresh, ist es wichtig, dass die Benutzeroberfläche dem Benutzer anzeigt, dass gerade ein Netzwerkvorgang ausgeführt wird. Es wird empfohlen, die Benutzeroberflächenaktion von den tatsächlichen Daten zu trennen, da die Daten aus verschiedenen Gründen aktualisiert werden können. Wenn wir beispielsweise eine Liste mit Freunden erhalten, kann derselbe Benutzer programmgesteuert erneut ausgewählt werden, was zu einer Aktualisierung von LiveData führt. Aus Sicht der Benutzeroberfläche ist die Tatsache, dass eine Anfrage im Flug ist, nur ein weiterer Datenpunkt, ähnlich wie bei jedem anderen Datenelement im Objekt selbst User.Wir können eine der folgenden Strategien verwenden, um den vereinbarten Datenaktualisierungsstatus in der Benutzeroberfläche anzuzeigen, unabhängig davon, woher die Datenaktualisierungsanforderung stammt:Im Abschnitt über die Trennung von Interessen haben wir erwähnt, dass einer der Hauptvorteile der Befolgung dieses Prinzips die Testbarkeit ist.Die folgende Liste zeigt, wie Sie jedes Codemodul anhand unseres erweiterten Beispiels testen:- Benutzeroberfläche und Interaktion : Verwenden Sie das Android UI Test Toolkit . Der beste Weg, um diesen Test zu erstellen, ist die Verwendung der Espresso- Bibliothek . Sie können ein Fragment erstellen und es mit einem Layout versehen
UserProfileViewModel. Da das Fragment nur mit verknüpft ist, reicht es aus, nur diese Klasse zu UserProfileViewModelverspotten (zu imitieren) , um die Benutzeroberfläche Ihrer Anwendung vollständig zu testen. - ViewModel:
UserProfileViewModel JUnit . , UserRepository . - UserRepository:
UserRepository JUnit. Webservice UserDao . :
Webservice , UserDao , .- UserDao: DAO . - , . , , , …
: Room , DAO, JSQL SupportSQLiteOpenHelper . , SQLite SQLite . - -: . , -, . , MockWebServer , .
- : maven .
androidx.arch.core : JUnit:
InstantTaskExecutorRule: .CountingTaskExecutorRule: . Espresso .
Die Programmierung ist ein kreatives Feld, und die Erstellung von Android-Anwendungen ist keine Ausnahme. Es gibt viele Möglichkeiten, das Problem zu lösen, sei es das Übertragen von Daten zwischen mehreren Aktionen oder Fragmenten, das Abrufen gelöschter Daten und das lokale Speichern offline oder eine beliebige Anzahl anderer häufiger Szenarien, auf die nicht triviale Anwendungen stoßen.Obwohl die folgenden Empfehlungen nicht erforderlich sind, zeigt unsere Erfahrung, dass ihre Implementierung Ihre Codebasis auf lange Sicht zuverlässiger, testbarer und unterstützter macht:Vermeiden Sie es, die Einstiegspunkte Ihrer Anwendung - wie Aktionen, Dienste und Rundfunkempfänger - als Datenquellen festzulegen.Stattdessen müssen sie nur mit anderen Komponenten koordinieren, um eine Teilmenge der Daten zu diesem Einstiegspunkt zu erhalten. Jede Komponente der Anwendung ist von kurzer Dauer, abhängig von der Interaktion des Benutzers mit seinem Gerät und dem allgemeinen aktuellen Status des Systems.Erstellen Sie klare Verantwortungsbereiche zwischen den verschiedenen Modulen Ihrer Anwendung.Verteilen Sie beispielsweise keinen Code, der Daten aus dem Netzwerk herunterlädt, an mehrere Klassen oder Pakete in Ihrer Codebasis. Definieren Sie in ähnlicher Weise nicht mehrere nicht miteinander verbundene Verantwortlichkeiten wie Daten-Caching und Datenbindung in derselben Klasse.Belichten Sie jedes Modul so wenig wie möglich.Widerstehen Sie der Versuchung, ein "nur ein" Etikett zu erstellen, das die Details einer internen Implementierung aus einem Modul enthüllt. Sie können kurzfristig etwas Zeit gewinnen, aber dann werden Sie viele Male eine technische Verschuldung erleiden, wenn sich Ihre Codebasis entwickelt.Überlegen Sie, wie Sie jedes Modul einzeln testbar machen können.Eine gut definierte API zum Abrufen von Daten aus dem Netzwerk erleichtert beispielsweise das Testen eines Moduls, das diese Daten in einer lokalen Datenbank speichert. Wenn Sie stattdessen die Logik dieser beiden Module an einem Ort mischen oder Ihren Netzwerkcode in der Codebasis verteilen, wird das Testen viel schwieriger - in einigen Fällen sogar unmöglich.Konzentrieren Sie sich auf den einzigartigen Kern Ihrer Anwendung, um sich von anderen Anwendungen abzuheben.Erfinden Sie das Rad nicht neu, indem Sie immer wieder dasselbe Muster schreiben. Konzentrieren Sie stattdessen Ihre Zeit und Energie auf das, was Ihre Anwendung einzigartig macht, und lassen Sie die Komponenten der Android-Architektur und anderer empfohlener Bibliotheken mit einem sich wiederholenden Muster fertig werden.Bewahren Sie so viele relevante und aktuelle Daten wie möglich auf.So können Benutzer die Funktionalität Ihrer Anwendung nutzen, auch wenn ihr Gerät offline ist. Denken Sie daran, dass nicht alle Benutzer eine konstante Hochgeschwindigkeitsverbindung verwenden.Legen Sie eine einzelne Datenquelle als einzig wahre Quelle fest.Wann immer Ihre Anwendung Zugriff auf diese Daten benötigt, sollte sie immer aus dieser einzigen Quelle der Wahrheit stammen.Nachtrag: Offenlegung des Netzwerkstatus
Im obigen Abschnitt der empfohlenen Anwendungsarchitektur haben wir Netzwerkfehler und Startzustände übersprungen, um Codefragmente zu vereinfachen.In diesem Abschnitt wird gezeigt, wie der Netzwerkstatus mithilfe der Ressourcenklasse angezeigt wird, die sowohl Daten als auch deren Status kapselt.Das folgende Codefragment enthält eine BeispielimplementierungResource:
Da das Herunterladen von Daten aus dem Netzwerk beim Anzeigen einer Kopie dieser Daten gängige Praxis ist, ist es hilfreich, eine Hilfsklasse zu erstellen, die an mehreren Stellen wiederverwendet werden kann. In diesem Beispiel erstellen wir eine Klasse mit dem Namen NetworkBoundResource.Das folgende Diagramm zeigt den Entscheidungsbaum für NetworkBoundResource: Es beginnt mit der Beobachtung der Datenbank für die Ressource. Wenn ein Datensatz zum ersten Mal aus der Datenbank heruntergeladen wird, wird
Es beginnt mit der Beobachtung der Datenbank für die Ressource. Wenn ein Datensatz zum ersten Mal aus der Datenbank heruntergeladen wird, wird NetworkBoundResourceüberprüft, ob das Ergebnis zum Senden gut genug ist oder ob es aus dem Netzwerk abgerufen werden muss. Bitte beachten Sie, dass beide Situationen gleichzeitig auftreten können, da Sie wahrscheinlich zwischengespeicherte Daten anzeigen möchten, wenn Sie sie aus dem Netzwerk aktualisieren.Wenn der Netzwerkaufruf erfolgreich ist, speichert er die Antwort in der Datenbank und initialisiert den Stream neu. Bei einem Netzwerkanforderungsfehler wird NetworkBoundResourceder Fehler direkt gesendet .. . , .Beachten Sie, dass das Verlassen einer Datenbank zum Senden von Änderungen die Verwendung verwandter Nebenwirkungen erfordert. Dies ist nicht sehr gut, da das undefinierte Verhalten dieser Nebenwirkungen auftreten kann, wenn die Datenbank die Änderungen nicht sendet, weil sich die Daten nicht geändert haben.Senden Sie auch keine vom Netzwerk empfangenen Ergebnisse, da dies gegen das Prinzip einer einzigen Wahrheitsquelle verstößt. Am Ende ist es möglich, dass die Datenbank Trigger enthält, die Datenwerte während des Speichervorgangs ändern. Senden Sie in ähnlicher Weise nicht "ERFOLG" ohne neue Daten, da der Client dann die falsche Version der Daten erhält.Das folgende Codefragment zeigt die offene API, die von der Klasse NetworkBoundResourcefür ihre Unterklassen bereitgestellt wird :
Beachten Sie die folgenden wichtigen Details der Klassendefinition:- Es definiert zwei Typparameter,
ResultTypeund RequestTypeda der von der API zurückgegebene Datentyp möglicherweise nicht dem lokal verwendeten Datentyp entspricht. - Es verwendet eine Klasse
ApiResponsefür Netzwerkanforderungen. ApiResponseIst ein einfacher Wrapper für eine Klasse Retrofit2.Call, die Antworten in Instanzen konvertiert LiveData.
Die vollständige Implementierung der Klasse wird NetworkBoundResourceals Teil des GitHub- Projekts für Android-Architektur-Komponenten angezeigt .Nach der NetworkBoundResourceErstellung können wir damit unsere festplatten- und netzwerkgebundenen Implementierungen Userin die Klasse schreiben UserRepository: