
Hallo Leser von Habr! Das Thema dieses Artikels ist die Implementierung von Katastrophenschutz in AERODISK Engine-Speichersystemen. Anfangs wollten wir in einem Artikel über beide Mittel schreiben: Replikation und Metro-Cluster, aber leider stellte sich heraus, dass der Artikel zu groß war, und so teilten wir den Artikel in zwei Teile. Gehen wir von einfach zu komplex. In diesem Artikel konfigurieren und testen wir die synchrone Replikation - löschen Sie ein Rechenzentrum und unterbrechen Sie den Kommunikationskanal zwischen den Rechenzentren, um zu sehen, was passiert.
Unsere Kunden stellen uns häufig unterschiedliche Fragen zur Replikation. Bevor Sie mit dem Einrichten und Testen der Replikationsimplementierung fortfahren, werden wir Ihnen ein wenig über die Replikation in Speichersystemen erzählen.
Ein bisschen Theorie
Die Replikation in den Speicher ist ein fortlaufender Prozess zur Sicherstellung der Datenidentität auf mehreren Speichersystemen gleichzeitig. Technisch wird die Replikation mit zwei Methoden durchgeführt.
Die synchrone Replikation ist das Kopieren von Daten vom Hauptspeichersystem in das Sicherungssystem, gefolgt von der obligatorischen Bestätigung beider Speichersysteme, dass die Daten aufgezeichnet und bestätigt wurden. Nach Bestätigung von beiden Seiten (auf beiden Speichersystemen) gelten die Daten als aufgezeichnet, und Sie können mit ihnen arbeiten. Dies stellt eine garantierte Datenidentität auf allen am Replikat beteiligten Speichersystemen sicher.
Die Vorteile dieser Methode:
- Die Daten sind auf allen Speichersystemen immer identisch.
Nachteile:
- Hohe Kosten der Lösung (schnelle Kommunikationskanäle, teure Glasfaser, langwellige Transceiver usw.)
- Entfernungsbeschränkungen (innerhalb weniger zehn Kilometer)
- Es gibt keinen Schutz gegen logische Datenbeschädigung (wenn die Daten (wissentlich oder versehentlich) auf dem Hauptspeichersystem beschädigt sind, werden sie automatisch und sofort im Sicherungsspeicher beschädigt, da die Daten immer identisch sind (dies ist ein Paradoxon).
Bei der asynchronen Replikation werden auch Daten vom Hauptspeicher in die Sicherung kopiert, jedoch mit einer gewissen Verzögerung und ohne dass der Datensatz auf der anderen Seite bestätigt werden muss. Sie können sofort nach dem Schreiben in den Hauptspeicher mit Daten arbeiten. Im Sicherungsspeicher sind die Daten nach einer Weile verfügbar. Die Identität der Daten wird in diesem Fall natürlich überhaupt nicht angegeben. Daten im Backup-Speicher sind immer etwas "in der Vergangenheit".
Vorteile der asynchronen Replikation:
- Niedrige Lösungskosten (alle Kommunikationskanäle, Optik optional)
- Keine Entfernungsbegrenzung
- Daten im Sicherungsspeicher sind nicht beschädigt, wenn sie auf dem Hauptspeicher beschädigt sind (zumindest für einige Zeit). Wenn die Daten beschädigt wurden, können Sie das Replikat jederzeit stoppen, um eine Beschädigung der Daten im Sicherungsspeicher zu verhindern
Nachteile:
- Daten in verschiedenen Rechenzentren sind immer nicht identisch
Daher hängt die Wahl des Replikationsmodus von den Aufgaben des Unternehmens ab. Wenn es für Sie von entscheidender Bedeutung ist, dass das Backup-Rechenzentrum genau dieselben Daten wie die Hauptdaten enthält (d. H. Geschäftsanforderung für RPO = 0), müssen Sie die Einschränkungen des synchronen Replikats in Kauf nehmen. Und wenn die Verzögerung des Status der Daten zulässig ist oder einfach kein Geld vorhanden ist, müssen Sie auf jeden Fall die asynchrone Methode verwenden.
Wir unterscheiden ein solches Regime (genauer gesagt bereits eine Topologie) auch separat als Metro-Cluster. Der Metro-Cluster-Modus verwendet die synchrone Replikation. Im Gegensatz zu einem regulären Replikat ermöglicht der Metro-Cluster jedoch, dass beide Speichersysteme im aktiven Modus arbeiten. Das heißt, Sie haben keine Trennung von Active-Standby-Rechenzentren. Anwendungen arbeiten gleichzeitig mit zwei Speichersystemen, die sich physisch in verschiedenen Rechenzentren befinden. Unfallausfallzeiten in einer solchen Topologie sind sehr gering (RTO, normalerweise Minuten). In diesem Artikel werden wir unsere Implementierung des U-Bahn-Clusters nicht berücksichtigen, da dies ein sehr großes und umfangreiches Thema ist. Daher werden wir ihm in Fortsetzung einen separaten, folgenden Artikel widmen.
Auch wenn wir sehr oft über die Replikation mit Speichersystemen sprechen, haben viele eine vernünftige Frage:> „Viele Anwendungen haben ihre eigenen Replikationstools. Warum sollte die Replikation auf Speichersystemen verwendet werden? Ist es besser oder schlechter? "
Es gibt keine einzige Antwort, daher hier die Vor- und Nachteile:
Argumente für die Speicherreplikation:
- Die Einfachheit der Lösung. Auf eine Weise können Sie ein ganzes Datenarray replizieren, unabhängig vom Lasttyp oder der Anwendung. Wenn Sie ein Replikat von Anwendungen verwenden, müssen Sie jede Anwendung separat konfigurieren. Wenn es mehr als zwei davon gibt, ist dies äußerst zeitaufwändig und teuer (für die Anwendungsreplikation ist in der Regel eine separate und nicht kostenlose Lizenz für jede Anwendung erforderlich. Mehr dazu weiter unten).
- Sie können alles replizieren - alle Anwendungen, alle Daten - und sie sind immer konsistent. Viele (die meisten) Anwendungen verfügen nicht über Replikationsfunktionen, und Replikate von der Speicherseite sind die einzige Möglichkeit, Schutz vor Katastrophen zu bieten.
- Keine Überzahlung für Anwendungsreplikationsfunktionen erforderlich. In der Regel kostet es viel, genau wie Lizenzen für ein Replikatspeichersystem. Sie müssen die Speicherreplikationslizenz jedoch nur einmal bezahlen und die Lizenz für das Anwendungsreplikat für jede Anwendung separat erwerben. Wenn es viele solcher Anwendungen gibt, kostet es einen hübschen Cent und die Kosten für Lizenzen für die Replikation von Speicher werden zu einem Tropfen auf den heißen Stein.
Argumente GEGEN Speicherreplikation:
- Das Replikat, das Anwendungstools verwendet, verfügt aus Sicht der Anwendungen selbst über mehr Funktionen. Die Anwendung kennt ihre Daten besser (was offensichtlich ist), sodass mehr Optionen für die Arbeit mit ihnen vorhanden sind.
- Hersteller einiger Anwendungen garantieren nicht die Konsistenz ihrer Daten, wenn die Replikation mit Tools von Drittanbietern erfolgt. * *
* - eine kontroverse These. Zum Beispiel hat ein bekanntes DBMS-Fertigungsunternehmen lange Zeit offiziell erklärt, dass sein DBMS normalerweise nur mit seinen Mitteln repliziert werden kann und der Rest der Replikation (einschließlich SHD-shnaya) „nicht wahr“ ist. Aber das Leben hat gezeigt, dass dies nicht so ist. Höchstwahrscheinlich (aber das ist nicht korrekt) ist dies einfach nicht der ehrlichste Versuch, mehr Lizenzen an Kunden zu verkaufen.
Infolgedessen ist die Replikation von der Speicherseite in den meisten Fällen besser, weil Dies ist eine einfachere und kostengünstigere Option. Es gibt jedoch komplexe Fälle, in denen Sie bestimmte Anwendungsfunktionen benötigen und mit der Replikation auf Anwendungsebene arbeiten müssen.
Wenn die Theorie fertig ist, jetzt die Praxis
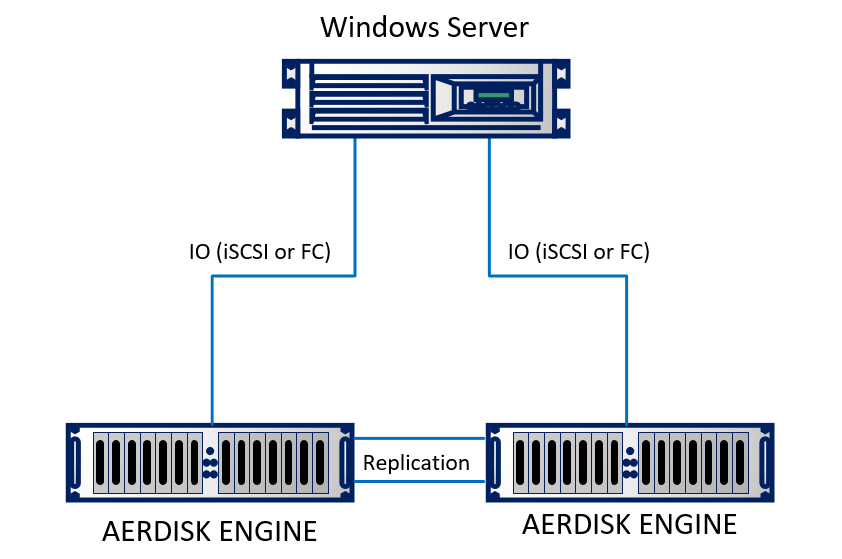
Wir werden in unserem Labor eine Replik erstellen. Im Labor haben wir zwei Rechenzentren emuliert (tatsächlich zwei benachbarte Racks, die sich in unterschiedlichen Gebäuden zu befinden scheinen). Der Stand besteht aus zwei Engine N2-Speichersystemen, die durch optische Kabel miteinander verbunden sind. Ein physischer Server unter Windows Server 2016 mit 10-Gbit-Ethernet ist mit beiden Speichersystemen verbunden. Der Stand ist recht einfach, ändert aber nichts an der Essenz.
Schematisch sieht es so aus:
Die logische Replikation ist wie folgt organisiert:
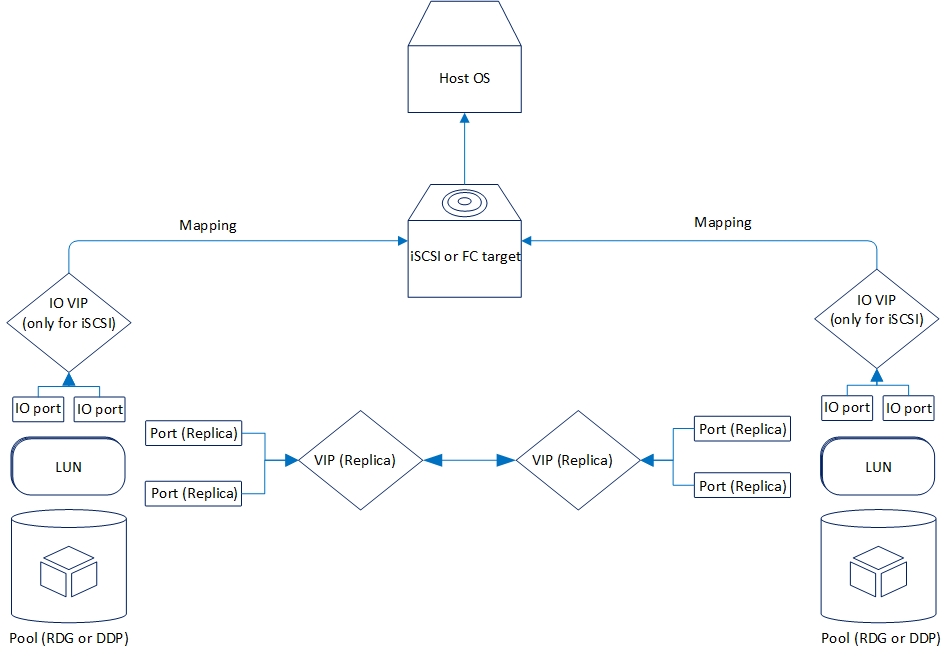
Schauen wir uns nun die Replikationsfunktionalität an, die wir jetzt haben.
Es werden zwei Modi unterstützt: asynchron und synchron. Es ist logisch, dass der Synchronmodus durch die Entfernung und den Kommunikationskanal begrenzt ist. Insbesondere erfordert der synchrone Modus die Verwendung von Glasfaser als Physik und 10-Gigabit-Ethernet (oder höher).
Die unterstützte Entfernung für die synchrone Replikation beträgt 40 Kilometer, die Verzögerung des Optikkanals zwischen den Rechenzentren beträgt bis zu 2 Millisekunden. Im Allgemeinen funktioniert es mit großen Verzögerungen, aber während der Aufzeichnung treten starke Bremsen auf (was ebenfalls logisch ist). Wenn Sie also eine synchrone Replikation zwischen Rechenzentren in Betracht ziehen, sollten Sie die Qualität der Optik und Verzögerungen überprüfen.
Asynchrone Replikationsanforderungen sind nicht so ernst. Genauer gesagt sind sie überhaupt nicht. Jede funktionierende Ethernet-Verbindung ist geeignet.
Derzeit unterstützt der AERODISK ENGINE-Speicher die Replikation für Blockgeräte (LUNs) mithilfe des Ethernet-Protokolls (Kupfer oder Optik). Für Projekte, die notwendigerweise eine Replikation über die Fibre Channel SAN-Factory erfordern, schließen wir jetzt die entsprechende Lösung ab, aber bisher ist sie noch nicht fertig, in unserem Fall nur Ethernet.
Die Replikation kann zwischen allen Speichersystemen der ENGINE-Serie (N1, N2, N4) von niedrigeren Systemen zu älteren und umgekehrt funktionieren.
Die Funktionalität beider Replikationsmodi ist völlig identisch. Im Folgenden erfahren Sie mehr darüber, was ist:
- Replikation "eins zu eins" oder "eins zu eins", dh die klassische Version mit zwei Rechenzentren, dem Haupt- und dem Backup
- Die Replikation ist "eins zu viele" oder "eins zu viele", d.h. Eine LUN kann gleichzeitig auf mehrere Speichersysteme repliziert werden
- Aktivierung, Deaktivierung und "Umkehrung" der Replikation, um die Replikationsrichtung zu aktivieren, zu deaktivieren oder zu ändern
- Die Replikation ist sowohl für RDG-Pools (Raid Distributed Group) als auch für DDP-Pools (Dynamic Disk Pool) verfügbar. Die RDG-Pool-LUN kann jedoch nur auf eine andere RDG repliziert werden. C DDP ist ähnlich.
Es gibt viel mehr kleine Funktionen, aber die Auflistung macht nicht viel Sinn. Wir werden sie während des Setups erwähnen.
Replikationssetup
Der Einrichtungsprozess ist recht einfach und besteht aus drei Schritten.
- Netzwerkeinrichtung
- Speicher-Setup
- Regeln (Links) einrichten und zuordnen
Ein wichtiger Punkt bei der Konfiguration der Replikation ist, dass die ersten beiden Stufen auf einem Remote-Speichersystem wiederholt werden sollten, die dritte Stufe - nur auf der Hauptstufe.
Konfiguration der Netzwerkressourcen
Der erste Schritt besteht darin, die Netzwerkports zu konfigurieren, über die der Replikationsverkehr übertragen wird. Dazu müssen Sie die Ports aktivieren und im Abschnitt Front-End-Adapter IP-Adressen festlegen.
Danach müssen wir einen Pool (in unserem Fall RDG) und eine virtuelle IP für die Replikation (VIP) erstellen. VIP ist eine Floating-IP-Adresse, die an zwei „physische“ Adressen von Speichercontrollern gebunden ist (die Ports, die wir gerade konfiguriert haben). Es wird die primäre Replikationsschnittstelle sein. Sie können auch nicht mit VIP, sondern mit VLAN arbeiten, wenn Sie mit markiertem Datenverkehr arbeiten müssen.
Das Erstellen eines VIP für ein Replikat unterscheidet sich nicht wesentlich vom Erstellen eines VIP für E / A (NFS, SMB, iSCSI). In diesem Fall erstellen wir ein VIP (ohne VLAN), geben jedoch unbedingt an, dass es für die Replikation vorgesehen ist (ohne diesen Zeiger können wir der Regel im nächsten Schritt kein VIP hinzufügen).
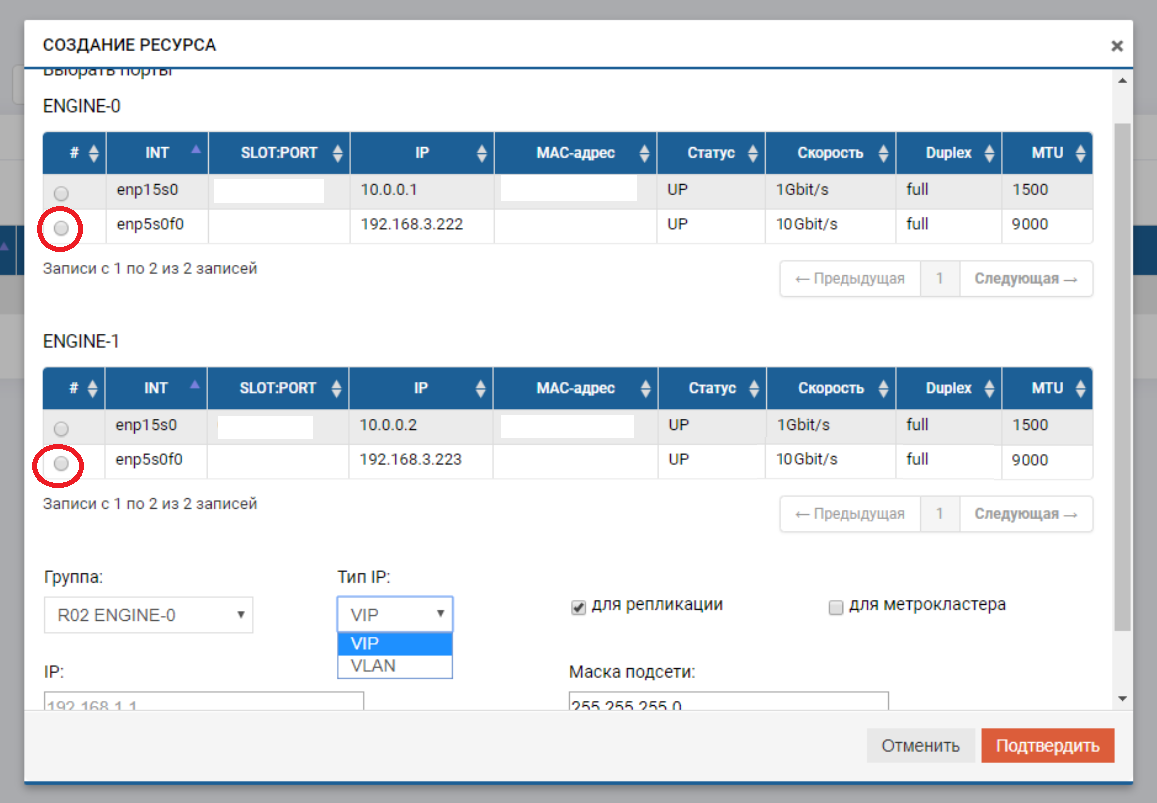
VIP muss sich im selben Subnetz befinden wie die IP-Ports, zwischen denen es „schwebt“.

Wir wiederholen diese Einstellungen auf dem Remote-Speichersystem mit einem anderen IP-Shnik für sich.
VIPs aus verschiedenen Speichersystemen können sich in verschiedenen Subnetzen befinden. Hauptsache, es sollte ein Routing zwischen ihnen bestehen. In unserem Fall wird dieses Beispiel nur gezeigt (192.168.3.XX und 192.168.2.XX).

Damit ist die Vorbereitung des Netzwerkteils abgeschlossen.
Speicher konfigurieren
Das Konfigurieren des Speichers für ein Replikat unterscheidet sich vom üblichen nur dadurch, dass wir die Zuordnung über das spezielle Menü „Replikationszuordnung“ vornehmen. Ansonsten ist alles wie bei der üblichen Einstellung. Jetzt in Ordnung.
Im zuvor erstellten R02-Pool müssen Sie eine LUN erstellen. Erstellen, nennen Sie es LUN1.
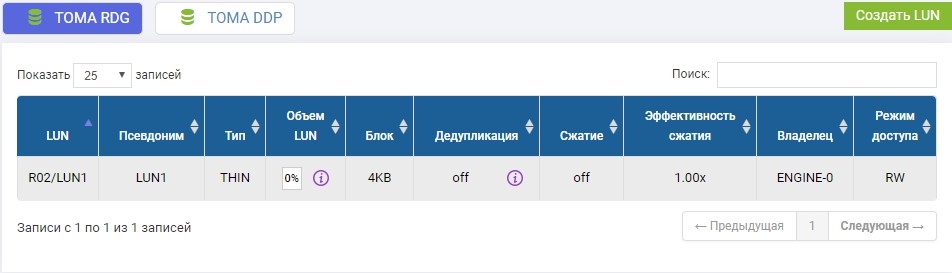
Wir müssen dieselbe LUN auch auf einem Remote-Speichersystem mit identischem Volumen erstellen. Wir schaffen. Um Verwirrung zu vermeiden, wird die Remote-LUN LUN1R genannt
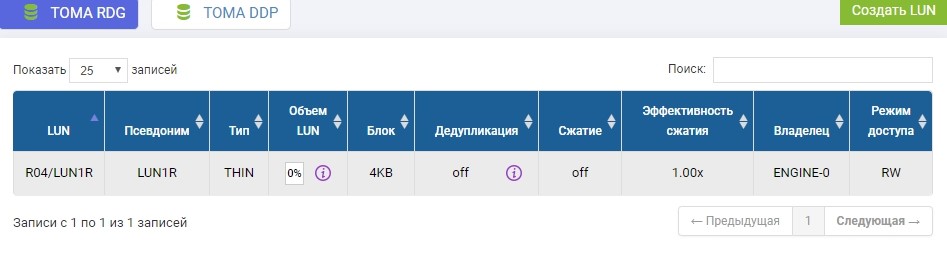
Wenn wir eine bereits vorhandene LUN verwenden müssten, müsste diese produktive LUN zum Zeitpunkt der Replikateinrichtung vom Host abgemeldet werden und auf dem Remote-Speichersystem einfach eine leere LUN mit identischer Größe erstellen.
Wenn das Speicher-Setup abgeschlossen ist, fahren wir mit der Erstellung der Replikationsregel fort.
Konfigurieren Sie Replikationsregeln oder Replikationslinks
Nach dem Erstellen von LUNs auf dem Speicher, der momentan die primäre sein wird, konfigurieren wir die Replikationsregel LUN1 auf SHD1 in LUN1R auf SHD2.
Die Konfiguration erfolgt im Menü Remote Replication.
Erstellen Sie eine Regel. Geben Sie dazu den Replikatempfänger an. Wir geben auch den Namen der Verbindung und den Replikationstyp (synchron oder asynchron) an.
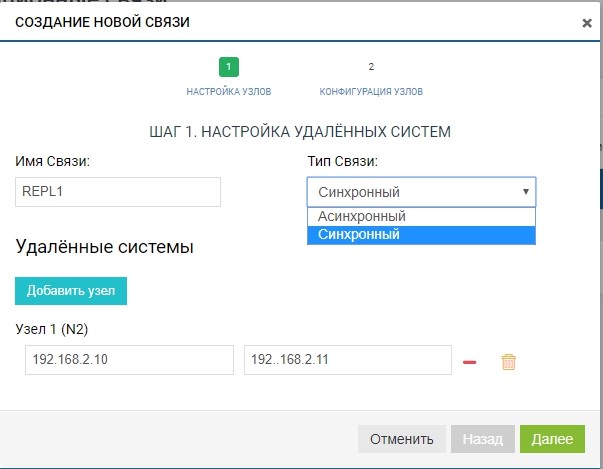
Fügen Sie im Feld "Remote-Systeme" unseren SHD2 hinzu. Zum Hinzufügen müssen Sie den verwaltenden IP-Speicher (MGR) und den Namen der Remote-LUN verwenden, auf die wir replizieren möchten (in unserem Fall LUN1R). Das Verwalten von IPs wird nur in der Phase des Hinzufügens von Kommunikation benötigt. Der Replikationsverkehr über diese IPs wird nicht übertragen. Hierzu wird der zuvor konfigurierte VIP verwendet.
Bereits zu diesem Zeitpunkt können wir mehr als ein Remote-System für die Topologie "Eins zu Viele" hinzufügen: Klicken Sie auf die Schaltfläche "Knoten hinzufügen", wie in der folgenden Abbildung dargestellt.
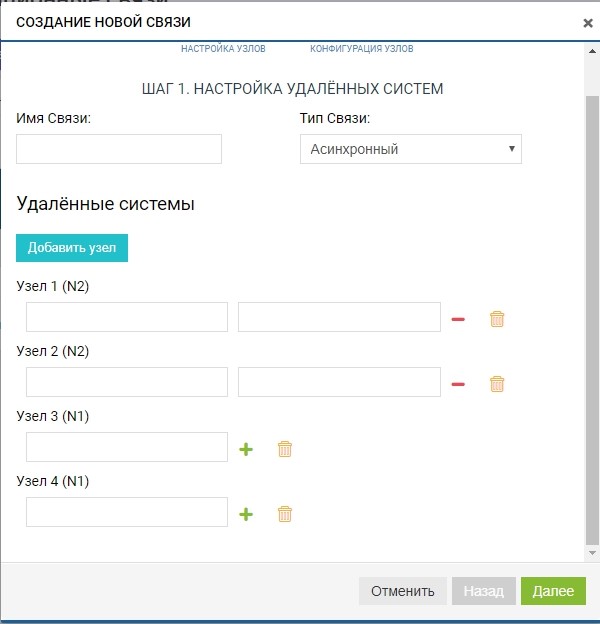
In unserem Fall ist das Remote-System eines, daher sind wir darauf beschränkt.
Die Regel ist fertig. Beachten Sie, dass es automatisch allen Replikationsteilnehmern hinzugefügt wird (in unserem Fall gibt es zwei davon). Sie können beliebig viele Regeln für eine beliebige Anzahl von LUNs und in eine beliebige Richtung erstellen. Um die Last auszugleichen, können wir beispielsweise einen Teil der LUNs von SHD1 nach SHD2 und den anderen Teil im Gegenteil von SHD2 nach SHD1 replizieren.
SHD1. Unmittelbar nach der Erstellung begann die Synchronisation.
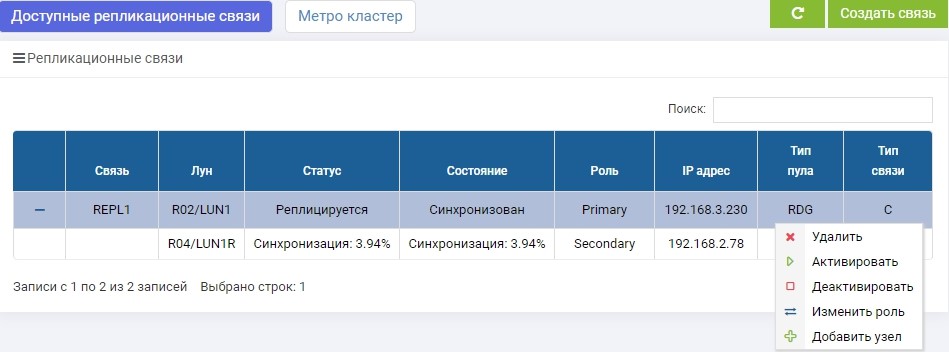
SHD2. Wir sehen die gleiche Regel, aber die Synchronisation ist bereits beendet.
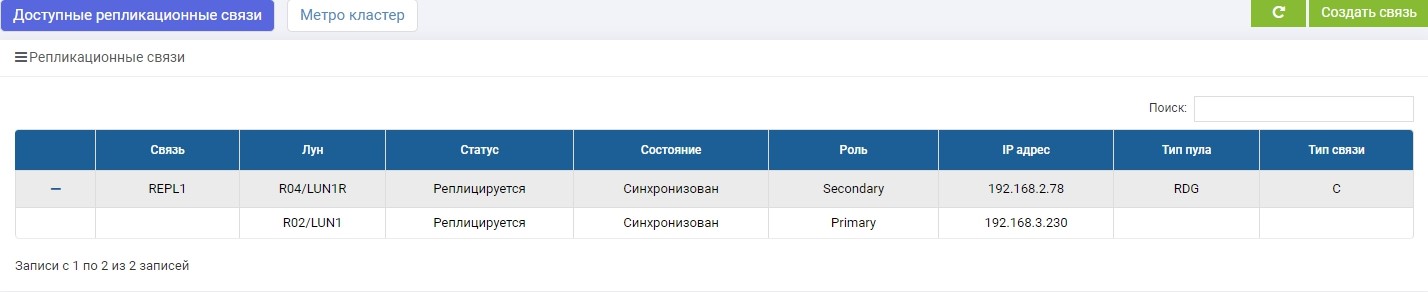
LUN1 auf SHD1 ist in der Rolle von Primary, dh es ist aktiv. LUN1R auf SHD2 spielt die Rolle des Sekundärs, dh es wird gehalten, wenn SHD1 ausfällt.
Jetzt können wir unsere LUN mit dem Host verbinden.
Wir werden die Verbindung über iSCSI herstellen, obwohl dies über FC erfolgen kann. Das Einrichten der Zuordnung für iSCSI-LUN in einem Replikat unterscheidet sich praktisch nicht vom üblichen Szenario, daher werden wir hier nicht näher darauf eingehen. Wenn überhaupt, wird dieser Vorgang im Artikel zur schnellen Einrichtung beschrieben.
Der einzige Unterschied besteht darin, dass wir die Zuordnung im Menü "Replikationszuordnung" erstellen.
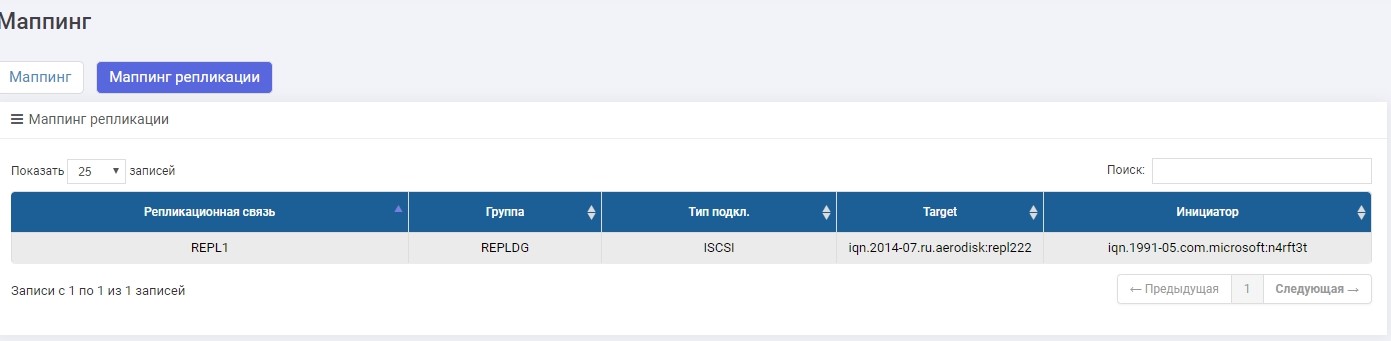
Richten Sie die Zuordnung ein und geben Sie dem Host die LUN. Der Gastgeber sah eine LUN.
Formatieren Sie es in das lokale Dateisystem.
Das Setup ist abgeschlossen. Als nächstes werden Tests gehen.
Testen
Wir werden drei Hauptszenarien testen.
- Personalwechselrollen Sekundär> Primär. Ein regelmäßiger Rollenwechsel ist erforderlich, wenn wir beispielsweise hauptsächlich ein Rechenzentrum benötigen, einige vorbeugende Vorgänge ausführen müssen und während dieser Zeit, damit die Daten verfügbar sind, die Last an das Backup-Rechenzentrum übertragen.
- Failover von Rollen Sekundär> Primär (Ausfall des Rechenzentrums). Dies ist das Hauptszenario für die Replikation, mit dessen Hilfe ein vollständiger Ausfall des Rechenzentrums überstanden werden kann, ohne das Unternehmen für längere Zeit anzuhalten.
- Unterbrochene Kommunikationskanäle zwischen Rechenzentren. Überprüfen des korrekten Verhaltens von zwei Speichersystemen unter Bedingungen, unter denen aus irgendeinem Grund der Kommunikationskanal zwischen den Rechenzentren nicht verfügbar ist (z. B. ein Bagger, der an der falschen Stelle gegraben wurde und die dunkle Optik defekt hat).
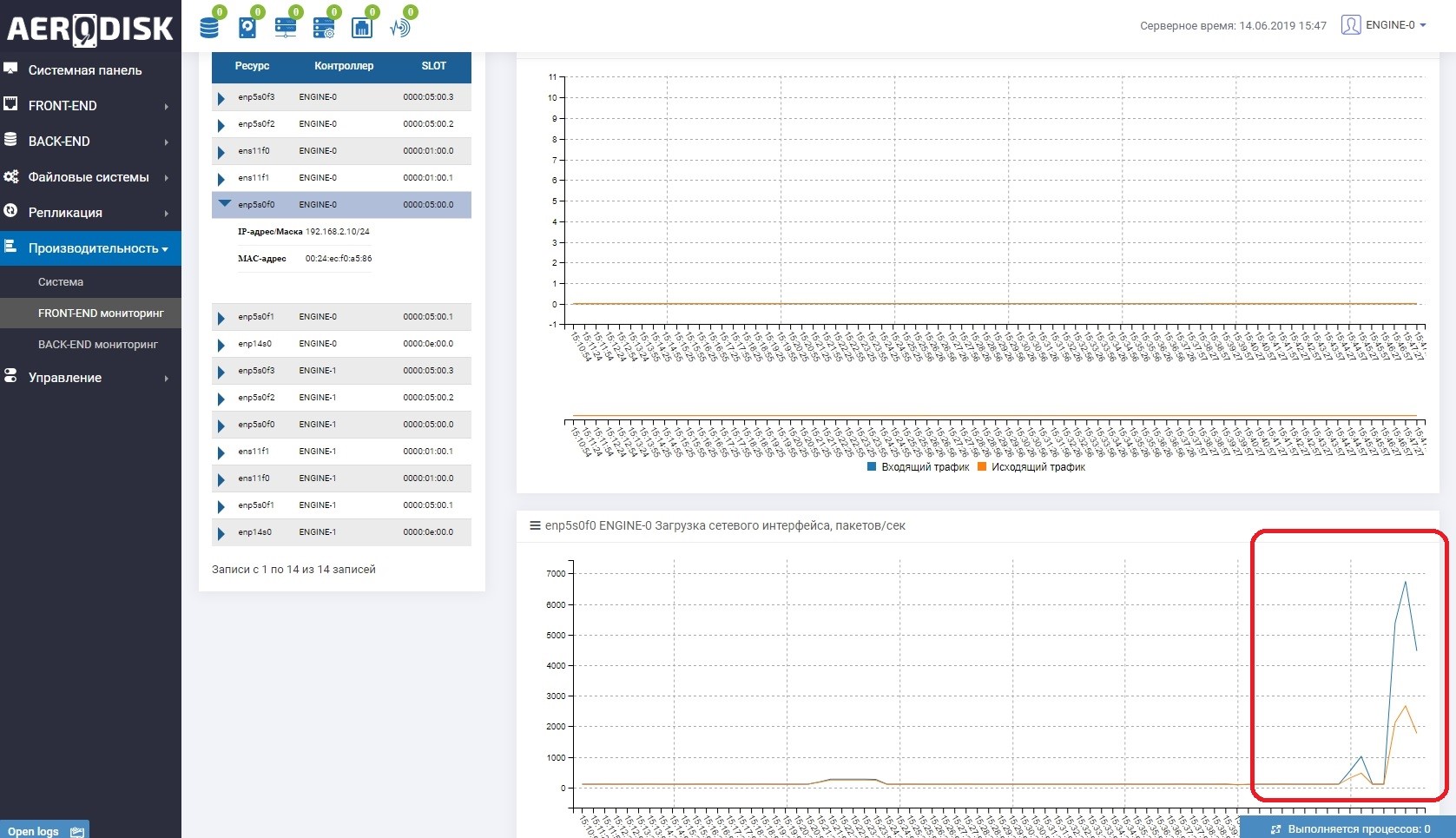
Zunächst beginnen wir, Daten in unsere LUN zu schreiben (wir schreiben Dateien mit zufälligen Daten). Wir sehen sofort, dass der Kommunikationskanal zwischen den Speichersystemen genutzt wird. Dies ist leicht zu verstehen, wenn Sie die Lastüberwachung der Ports öffnen, die für die Replikation verantwortlich sind.
Auf beiden Speichersystemen gibt es jetzt "nützliche" Daten, wir können den Test starten.
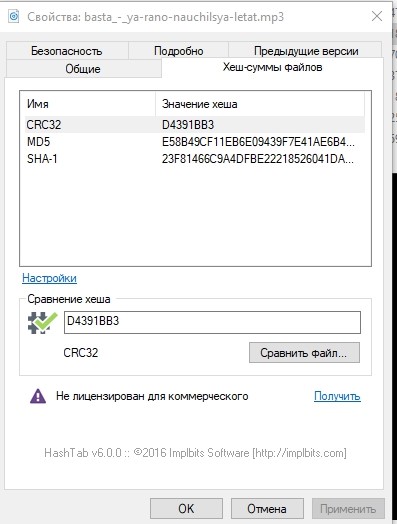
Schauen wir uns für alle Fälle die Hash-Summen einer der Dateien an und schreiben Sie sie auf.
Personalrollenwechsel
Das Wechseln der Rollen (Ändern der Replikationsrichtung) kann von jedem Speichersystem aus erfolgen. Sie müssen jedoch weiterhin zu beiden wechseln, da Sie die Zuordnung auf der Primärseite deaktivieren und auf der Sekundärseite aktivieren müssen (die zur Primärseite wird).
Vielleicht stellt sich jetzt eine vernünftige Frage: Warum nicht automatisieren? Wir antworten: Alles ist einfach, die Replikation ist ein einfaches Katastrophenschutz-Tool, das ausschließlich auf manuellen Vorgängen basiert. Um diese Vorgänge zu automatisieren, gibt es einen Metro-Cluster-Modus, der vollständig automatisiert ist, dessen Konfiguration jedoch viel komplizierter ist. Wir werden im nächsten Artikel über das Einrichten des U-Bahn-Clusters schreiben.
Deaktivieren Sie die Zuordnung im Hauptspeicher, um sicherzustellen, dass die Aufzeichnung gestoppt wird.
Wählen Sie dann auf einem der Speichersysteme (egal ob primär oder Backup) im Menü "Remote-Replikation" unsere REPL1-Verbindung aus und klicken Sie auf "Rolle ändern".
Nach einigen Sekunden wird LUN1R (Backup-Speicher) primär.
Wir machen das Mapping von LUN1R mit SHD2.
Danach klammert sich unser E: -Laufwerk automatisch an den Host, nur dass es diesmal mit LUN1R „geflogen“ ist.
Vergleichen Sie für alle Fälle die Hash-Mengen.
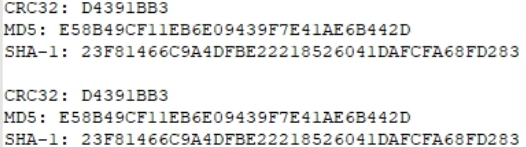
Identisch. Test bestanden.
Failover Rechenzentrumsfehler
Derzeit ist der Hauptspeicher nach dem regulären Umschalten SHD2 bzw. LUN1R. Um einen Unfall zu simulieren, schalten wir beide Controller SHD2 aus.
Der Zugang dazu ist nicht mehr möglich.
Wir schauen uns an, was auf dem Speicher 1 passiert (Backup im Moment).

Wir sehen, dass die primäre LUN (LUN1R) nicht verfügbar ist. Eine Fehlermeldung wurde in den Protokollen, im Informationsbereich sowie in der Replikationsregel selbst angezeigt. Dementsprechend sind Daten vom Host derzeit nicht verfügbar.
Ändern Sie die Rolle von LUN1 in Primary.
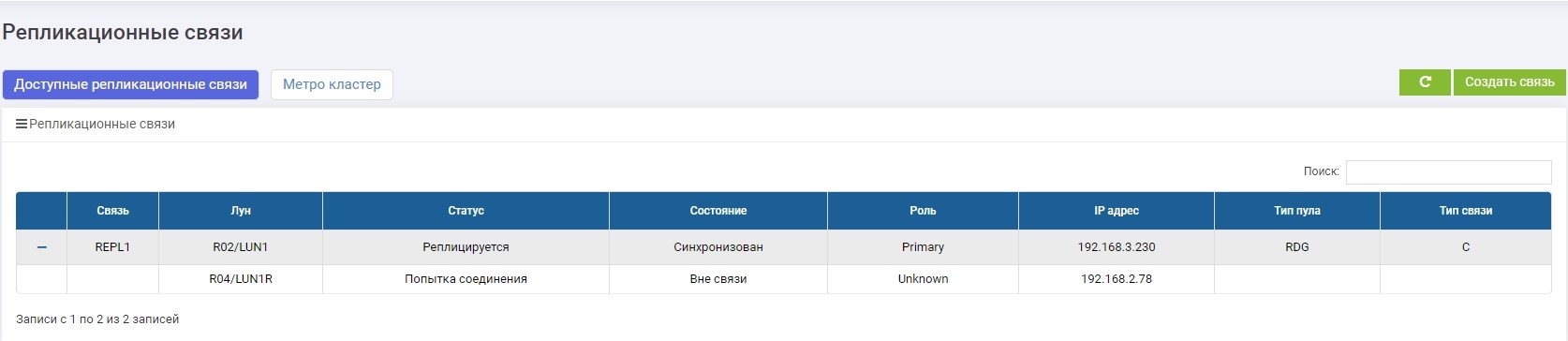
Angelegenheiten, die dem Gastgeber zugeordnet sind.

Stellen Sie sicher, dass Laufwerk E auf dem Host angezeigt wird.
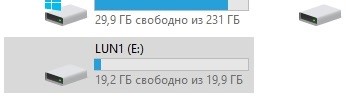
Überprüfen Sie den Hash.
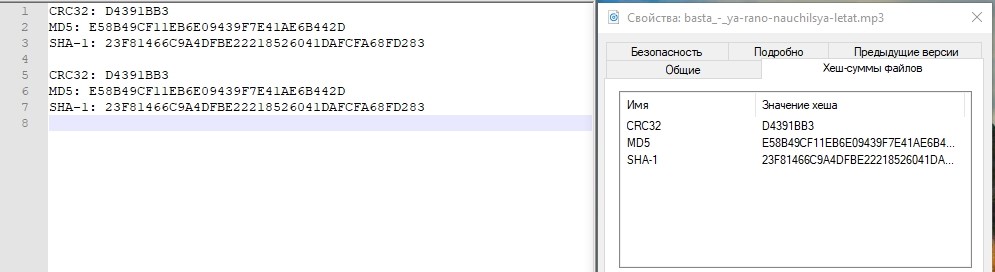
Alles ist in Ordnung. Das Speicherzentrum verzeichnete einen Rückgang des aktiven Rechenzentrums. Die ungefähre Zeit, die wir für das Verbinden der "Umkehrung" der Replikation und das Verbinden der LUN vom Backup-Rechenzentrum aufgewendet haben, betrug ungefähr 3 Minuten. Es ist klar, dass im realen Produkt alles viel komplizierter ist, und zusätzlich zu Aktionen mit Speichersystemen müssen Sie viel mehr Vorgänge im Netzwerk, auf Hosts und in Anwendungen ausführen. Und im Leben wird diese Zeitspanne viel länger sein.
Hier möchte ich schreiben, dass alles, der Test erfolgreich abgeschlossen wurde, aber lasst uns nicht eilen. Der Hauptspeicher "liegt", wir wissen, dass sie, als sie "fiel", in der Rolle der Grundschule war. Was passiert, wenn sie sich plötzlich einschaltet? Es wird zwei Hauptrollen geben, was einer Datenbeschädigung entspricht. Wir werden es jetzt überprüfen.
Wir werden plötzlich den zugrunde liegenden Speicher einschalten.
Es wird einige Minuten lang geladen und danach nach einer kurzen Synchronisation wieder in Betrieb genommen, jedoch bereits als sekundär.

Alles ok. Geteiltes Gehirn ist nicht passiert. Wir haben darüber nachgedacht und immer nach dem Fall des Speichersystems steigt die Rolle des Sekundärsystems an, unabhängig davon, welche Rolle es "im Leben" war. Jetzt können wir mit Sicherheit sagen, dass der Ausfalltest des Rechenzentrums erfolgreich war.
Ausfall von Kommunikationskanälen zwischen Rechenzentren
Die Hauptaufgabe dieses Tests besteht darin, sicherzustellen, dass das Speichersystem nicht ausflippt, wenn es vorübergehend die Kommunikationskanäle zwischen den beiden Speichersystemen verliert und dann wieder angezeigt wird.
Also. Wir trennen die Drähte zwischen den Speichersystemen (stellen Sie sich vor, ein Bagger hat sie gegraben).
Auf der Primärseite sehen wir, dass es keine Verbindung mit der Sekundarstufe gibt.
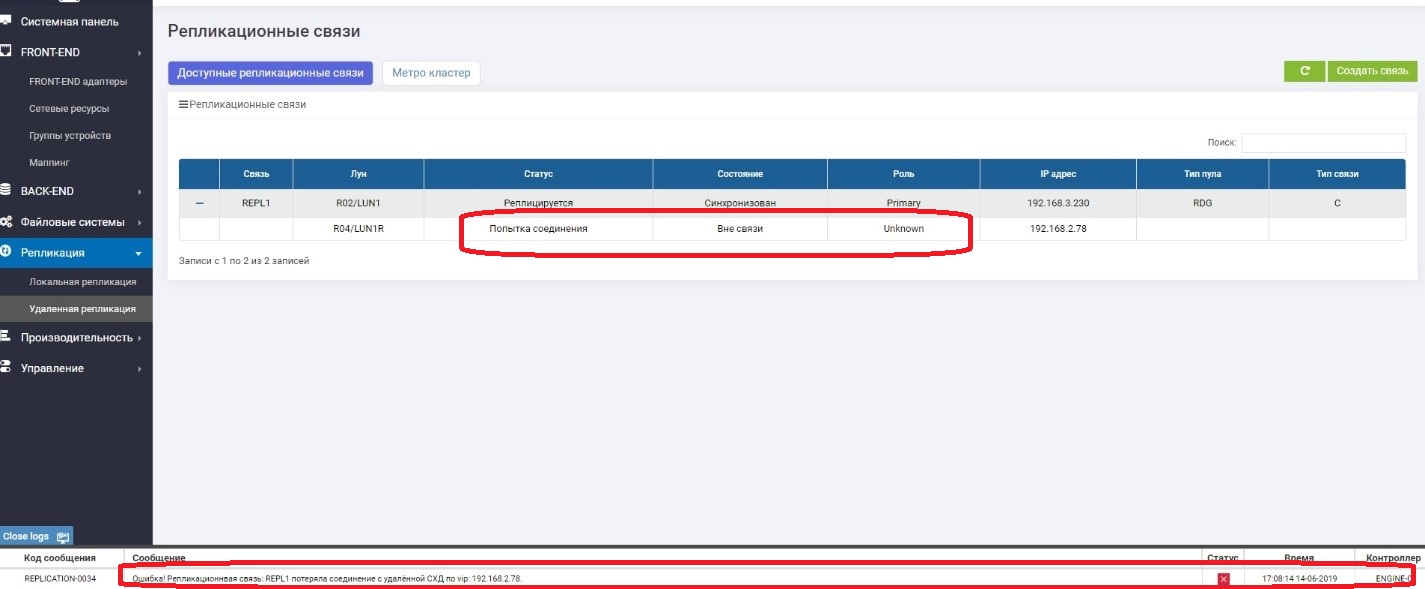
Auf Secondary sehen wir, dass es keine Verbindung zu Primary gibt.
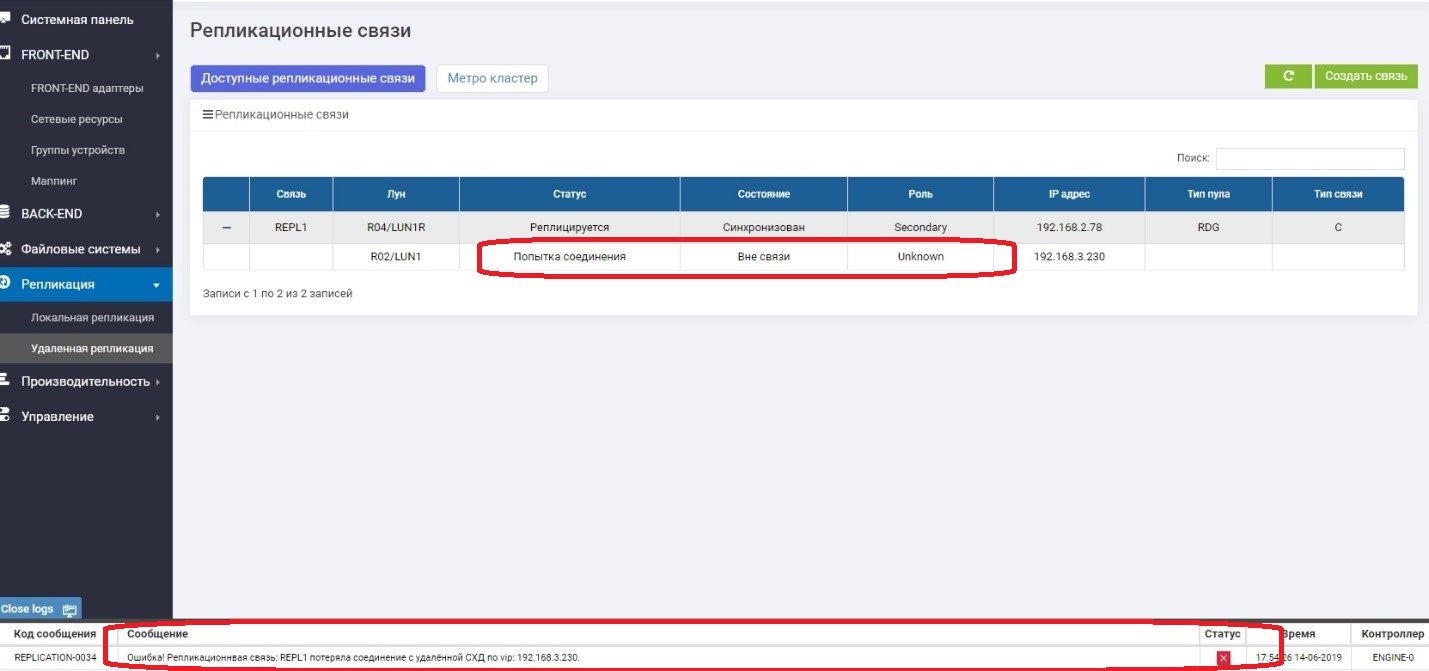
Alles funktioniert einwandfrei, und wir schreiben weiterhin Daten in das Hauptspeichersystem, dh es wird bereits garantiert, dass sie sich von dem Sicherungssystem unterscheiden, dh sie sind "übrig".
In wenigen Minuten reparieren wir den Kommunikationskanal. Sobald sich die Speichersysteme gesehen haben, wird die Datensynchronisation automatisch aktiviert. Der Administrator benötigt nichts.

.
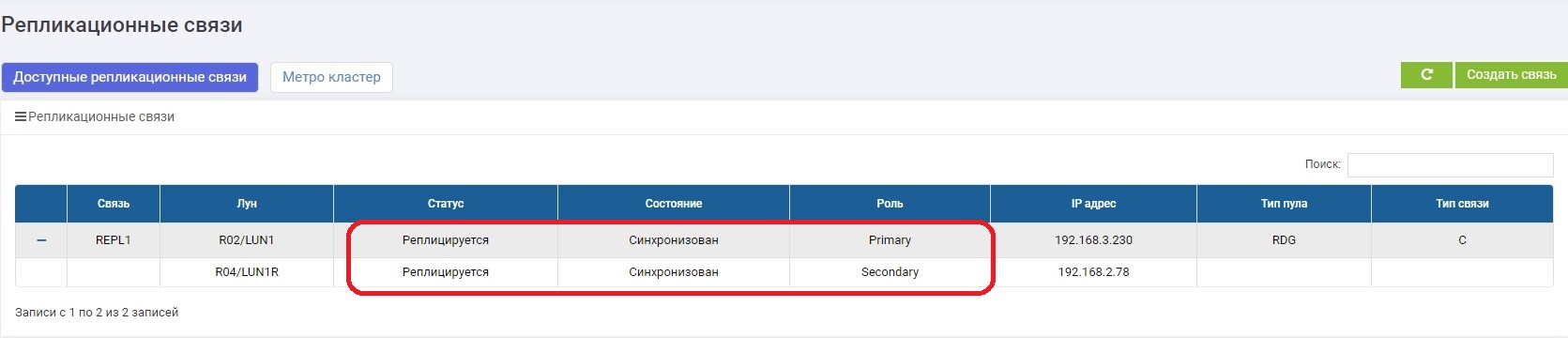
, , .
Schlussfolgerungen
– , , . .
, - . . , .
active-active, , .
, .
.