Hallo liebe Habrauser! In diesem Artikel geht es um Web 3.0, das Internet mit Dezentralisierung. Web 3.0 führt das Konzept der Dezentralisierung als Grundlage für das moderne Internet ein. Viele Computersysteme und Netzwerke benötigen für ihre Anforderungen Sicherheits- und Dezentralisierungseigenschaften. Die Dezentralisierungslösung wird als verteilte Registrierungstechnologie oder Blockchain bezeichnet.

Blockchain ist eine verteilte Registrierung. Es kann als eine riesige Datenbank betrachtet werden, die für immer lebt und sich in der Geschichte nicht ändert. Die Blockchain wird als Grundlage für dezentrale Webanwendungen oder -dienste verwendet.
Im Wesentlichen ist Blockchain nicht nur eine Datenbank, sondern bietet auch die Möglichkeit, das Vertrauen zwischen Netzwerkteilnehmern zu stärken und Geschäftslogik im Netzwerk auszuführen.
Byzantinischer Konsens erhöht die Netzwerkzuverlässigkeit und löst das Problem der Konsistenz
Die Skalierbarkeit, die DLT bietet, verändert bestehende Geschäftsnetzwerke.
Blockchain bietet neue sehr wichtige Vorteile:
- Vermeidung kostspieliger Fehler.
- Transparente Transaktionen.
- Digitalisierung für echte Güter.
- Intelligente Verträge.
- Geschwindigkeit und Sicherheit der Zahlungen.
Opporty PoE ist ein Projekt, dessen Ziel es ist, kryptografische Protokolle zu untersuchen und vorhandene DLT- und Blockchain-Lösungen zu verbessern.
Die meisten öffentlich verteilten Registrierungssysteme haben keine Skalierbarkeitseigenschaften - ihr Durchsatz ist eher gering. Zum Beispiel verarbeitet das Ethereum nur ~ 20 tx / s.
Viele Lösungen wurden entwickelt, um die Skalierbarkeitseigenschaft zu erhöhen und die Dezentralisierung nicht zu verlieren (wie Sie wissen, können nur 2 von 3 bekannt sein: Skalierbarkeit, Sicherheit, Dezentralisierung).
Eine der effektivsten ist eine Lösung mit Seitenketten.
Plasmakonzept
Das Konzept besteht darin, dass die Wurzelkette eine kleine Anzahl von Commits von untergeordneten Ketten verarbeitet, sodass die Wurzelkette als sicherste und letzte Schicht zum Speichern aller Zwischenzustände fungiert. Jede untergeordnete Kette fungiert als eigene Blockchain mit einem eigenen Konsensalgorithmus, es gibt jedoch einige wichtige Einschränkungen.
- Intelligente Verträge werden in der Stammkette erstellt und fungieren als Prüfpunkt für die untergeordnete Kette in der Stammkette.
- Es wird eine untergeordnete Kette erstellt, die als eigene Blockchain mit eigenem Konsens fungiert. Alle Zustände in der Kette der untergeordneten Prozesse sind durch Betrugsnachweise geschützt, die sicherstellen, dass alle Übergänge zwischen Zuständen gültig sind und ein Widerrufsprotokoll anwenden.
- Intelligente Verträge, die für dapp oder untergeordnete Kette (Anwendungslogik) spezifisch sind, können dann in untergeordneter Kette bereitgestellt werden.
- Die notwendigen Werkzeuge können von der Wurzelkette zur untergeordneten Kette übertragen werden.
Validatoren haben wirtschaftliche Anreize, ehrlich zu handeln und Kommentare an die Wurzelkette zu senden - die Ebene der endgültigen Abwicklung der Transaktion.
Daher sollten dapp-Benutzer, die in der untergeordneten Kette arbeiten, überhaupt nicht mit der Stammkette interagieren. Außerdem können sie ihr Geld jederzeit an die Wurzelkette abheben, selbst wenn die Kinderkette gehackt wird. Diese Ausgänge aus der Kinderkette ermöglichen es Benutzern, ihre Gelder mithilfe von Merkle-Beweisen sicher aufzubewahren, was den Besitz eines bestimmten Geldbetrags bestätigt.
Die Hauptvorteile von Plasma hängen mit seiner Fähigkeit zusammen, die Berechnungen, die derzeit die Hauptkette überlasten, erheblich zu vereinfachen. Darüber hinaus kann die Ethereum-Blockchain umfangreichere und parallelere Datensätze verarbeiten. Die aus der Wurzelkette entnommene Zeit wird auch an Ethereum-Knoten übertragen, die geringere Verarbeitungs- und Speicheranforderungen haben.
Plasma Cash ist ein Design, das Netzwerk-Token eindeutige Seriennummern gibt, die sie in eindeutige Token verwandeln. Zu den Vorteilen zählen das Fehlen von Bestätigungsbedürfnissen, eine einfachere Unterstützung für alle Arten von Token (einschließlich nicht fungibler Token) und die Abschwächung gegen Massenausgänge aus der Kinderkette.
Das Plasmaproblem hängt mit dem Konzept der "Massenausgänge" aus der Kinderkette zusammen. In diesem Szenario kann ein koordinierter gleichzeitiger Austritt aus der Tochterkette möglicherweise zu einem Mangel an Rechenleistung führen, um alle Gelder abzuheben. Infolgedessen können Benutzer Geld verlieren.
Plasma-Implementierungsoptionen

Das Basisplasma bietet viele Optionen für die Implementierung.
Die Hauptunterschiede sind:
- Speichern von Informationen über die Methode zum Speichern und Präsentieren des Zustands,
- Arten von Token (teilbar unteilbar),
- Transaktionssicherheit
- Art des Konsensalgorithmus usw.
Die Hauptvarianten von Plasma:
- UTXO-basiert - Jede Transaktion besteht aus Ein- und Ausgaben: Eine Transaktion kann ausgeführt und ausgegeben werden. Die Liste der nicht ausgegebenen Transaktionen ist ein Status der untergeordneten Kette.
- Kontobasiert - enthält lediglich eine Darstellung jedes Kontos und seines Kontostands. Dieser Typ wird im Ethereum verwendet, da jedes Konto zwei Typen haben kann - ein Benutzerkonto und ein intelligentes Vertragskonto. Der Vorteil dieser Art der Statusspeicherung ist ihre Einfachheit, und das Minus ist, dass diese Option nicht skalierbar ist (die spezielle Nonce-Eigenschaft wird verwendet, um zu verhindern, dass die Transaktion zweimal ausgeführt wird).
In diesem Artikel werden die Datenstrukturen erläutert, die in der Plasma Cash-Blockchain verwendet werden.
Um genau zu verstehen, wie Engagement funktioniert, müssen Sie das Konzept des Merkle-Baums klären.
Merkle Bäume ihre Verwendung in Plasma
Merkle-Bäume sind eine äußerst wichtige Datenstruktur in der Blockchain-Welt. Im Wesentlichen bieten Merkle-Bäume die Möglichkeit, einen Datensatz so zu erfassen, dass die Daten ausgeblendet werden. Benutzer können jedoch nachweisen, dass einige der Informationen im Satz enthalten waren. Wenn ich beispielsweise zehn Zahlen habe, kann ich einen Beweis für diese Zahlen erstellen und dann beweisen, dass eine bestimmte Zahl in diesem Satz von Zahlen enthalten war. Diese Proofs haben eine kleine konstante Größe, was die Veröffentlichung in Ethereum billig macht.
Sie können dies für eine Reihe von Transaktionen verwenden. Sie können auch nachweisen, dass sich eine bestimmte Transaktion in dieser Gruppe von Transaktionen befindet. Genau das macht der Bediener. Jeder Block besteht aus einer Reihe von Transaktionen, die sich in einen Merkle-Baum verwandeln. Die Wurzel dieses Baumes ist der Beweis, der zusammen mit jedem Plasmablock im Ethereum veröffentlicht wird.
Benutzer sollten in der Lage sein, ihr Geld aus der Plasmakette abzuheben. Wenn Benutzer die Plasmakette verlassen möchten, senden sie die Transaktion „Beenden“ an Ethereum.
Plasma Cash verwendet einen speziellen Merkle-Baum, der es ermöglicht, nicht den gesamten Block, sondern nur die Zweige zu validieren, die dem Token des Benutzers entsprechen.
Das heißt, um ein Token zu übertragen, müssen Sie den Verlauf durchgehen und nur die Token scannen, die ein bestimmter Benutzer benötigt. Beim Übertragen eines Tokens gibt der Benutzer einfach den gesamten Verlauf an einen anderen Benutzer weiter und kann die gesamte Geschichte bereits authentifizieren - und vor allem sehr schnell.

Plasma Cash-Datenstrukturen zum Speichern von Status und Verlauf
Es ist jedoch erforderlich, nur einige Merkle-Bäume zu verwenden, da beispielsweise ein Nachweis über die Aufnahme und auch ein Nachweis über die Nichteinbeziehung der Transaktion in den Block erforderlich ist.
- Spärlicher Merkle-Baum
- Patricia versucht
Opporty hat die Implementierung von Sparse Merkle Tree und Patricia Trie abgeschlossen
Ein spärlicher Merkle-Baum ähnelt einem Standard-Merkle-Baum, außer dass die darin enthaltenen Daten indiziert werden und jeder Datenpunkt auf einem Blatt platziert wird, das dem Index dieses Datenpunkts entspricht
Nehmen wir an, wir haben einen Merkle-Baum mit vier Blättern. Wir werden diesen Baum zur Demonstration mit ein paar Buchstaben (A, D) füllen. Der Buchstabe A ist der erste Buchstabe des Alphabets, daher müssen wir ihn auf das erste Blatt setzen. Ebenso können wir D auf das vierte Blatt setzen.
Was passiert also im zweiten und dritten Blatt? Wir lassen sie einfach leer. Genauer gesagt wird ein spezieller Wert (z. B. Null) anstelle des Buchstabens platziert.
Der Baum sieht letztendlich so aus:

Der Inklusionsnachweis funktioniert genau wie bei einem normalen Merkle-Baum. Was passiert, wenn wir beweisen wollen, dass C nicht Teil dieses Merkle-Baums ist? Das ist einfach! Wir wissen, dass wenn C Teil eines Baumes wäre, es auf dem dritten Blatt wäre. Wenn C nicht Teil des Baumes ist, muss das dritte Blatt Null sein.
Alles, was benötigt wird, ist der Standardnachweis für die Aufnahme von Merkle, der zeigt, dass das dritte Blatt Null ist.
Das Beste an einem spärlichen Merkle-Baum ist, dass sie wirklich Schlüsselwertspeicher im Merkle-Baum darstellen!
Hier ist ein Teil des PoE-Protokollcodes, der den Sparse Merkle Tree-Build implementiert.
class SparseTree { //... buildTree() { if (Object.keys(this.leaves).length > 0) { this.levels = [] this.levels.unshift(this.leaves) for (let level = 0; level < this.depth; level++) { let currentLevel = this.levels[0] let nextLevel = {} Object.keys(currentLevel).forEach((leafKey) => { let leafHash = currentLevel[leafKey] let isEvenLeaf = this.isEvenLeaf(leafKey) let parentLeafKey = leafKey.slice(0, -1) let neighborLeafKey = parentLeafKey + (isEvenLeaf ? '1' : '0') let neighborLeafHash = currentLevel[neighborLeafKey] if (!neighborLeafHash) { neighborLeafHash = this.defaultHashes[level] } if (!nextLevel[parentLeafKey]) { let parentLeafHash = isEvenLeaf ? ethUtil.sha3(Buffer.concat([leafHash, neighborLeafHash])) : ethUtil.sha3(Buffer.concat([neighborLeafHash, leafHash])) if (level == this.depth - 1) { nextLevel['merkleRoot'] = parentLeafHash } else { nextLevel[parentLeafKey] = parentLeafHash } } }) this.levels.unshift(nextLevel) } } } }
Dieser Code ist ziemlich trivial. Wir haben einen Schlüsselwertspeicher mit Nachweis der Einbeziehung / Nichteinbeziehung.
In jeder Iteration wird eine bestimmte Ebene des endgültigen Baums gefüllt, beginnend mit der letzten. Je nachdem, welcher Schlüssel des aktuellen Blattes gerade oder ungerade ist, nehmen wir zwei benachbarte Blätter und betrachten den Hash der aktuellen Ebene. Wenn wir das Ende erreichen, schreiben wir einen einzelnen merkleRoot - einen gemeinsamen Hash.
Sie müssen verstehen, dass dieser Baum bereits mit anfänglich leeren Werten gefüllt ist! Und wenn wir eine große Menge an IDS-Token speichern. Wir haben eine riesige Baumgröße und die Generierung dauert sehr lange!
Es gibt viele Lösungen für diese Unoptimierung, aber Opporty hat beschlossen, diesen Baum in Patricia Trie zu ändern.
Patricia Trie ist eine Mischung aus Radix Trie und Merkle Trie.
Der Radix Trie-Datenschlüssel speichert den Datenpfad selbst! Auf diese Weise können Sie eine optimierte Datenstruktur für den Speicher erstellen!
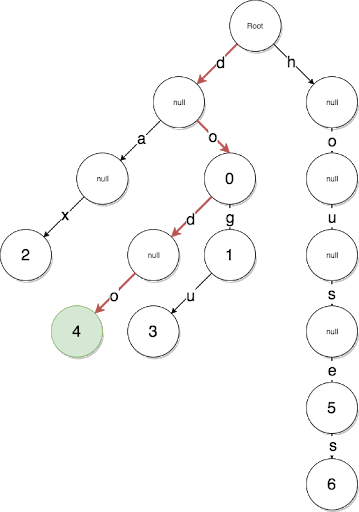
Gelegenheitsumsetzung
buildNode(childNodes, key = '', level = 0) { let node = {key} this.iterations++ if (childNodes.length == 1) { let nodeKey = level == 0 ? childNodes[0].key : childNodes[0].key.slice(level - 1) node.key = nodeKey let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(nodeKey)), childNodes[0].hash]) node.hash = ethUtil.sha3(nodeHashes) return node } let leftChilds = [] let rightChilds = [] childNodes.forEach((node) => { if (node.key[level] == '1') { rightChilds.push(node) } else { leftChilds.push(node) } }) if (leftChilds.length && rightChilds.length) { node.leftChild = this.buildNode(leftChilds, '0', level + 1) node.rightChild = this.buildNode(rightChilds, '1', level + 1) let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(node.key)), node.leftChild.hash, node.rightChild.hash]) node.hash = ethUtil.sha3(nodeHashes) } else if (leftChilds.length && !rightChilds.length) { node = this.buildNode(leftChilds, key + '0', level + 1) } else if (!leftChilds.length && rightChilds.length) { node = this.buildNode(rightChilds, key + '1', level + 1) } else if (!leftChilds.length && !rightChilds.length) { throw new Error('invalid tree') } return node }
Das heißt, wir gehen rekursiv durch und erstellen getrennte linke und rechte untergeordnete Teilbäume. Gleichzeitig ist das Erstellen des Schlüssels wie ein Pfad in diesem Baum!
Diese Lösung ist noch trivialer und arbeitet schneller, während sie ziemlich optimiert ist! Tatsächlich kann der Patricia-Baum weiter optimiert werden, indem neue Knotentypen eingeführt werden - Erweiterungsknoten, Verzweigungsknoten usw., wie im Ethereum-Protokoll, aber diese Implementierung erfüllt alle unsere Bedingungen - wir haben eine schnelle und speicheroptimierte Datenstruktur.
Durch die Implementierung dieser Datenstrukturen ermöglichte Opporty die Skalierung von Plasma Cash, da es möglich ist, den Verlauf des Tokens zu überprüfen und die Nichteinbeziehung des Tokens in den Baum zu ermöglichen! Auf diese Weise können Sie die Validierung von Blöcken und der untergeordneten Plasmakette selbst erheblich beschleunigen.
Nützliche Links:
- Weißbuchplasma
- Git Hub
- Anwendungsfälle und Architekturbeschreibung
- Lightning-Netzwerkpapier