
Der Artikel ist eher technisch als geschäftlich, aber wir werden auch einige Schlussfolgerungen aus geschäftlicher Sicht ziehen. Besonderes Augenmerk wird auf den automatischen Vergleich von Waren aus verschiedenen Quellen gelegt.
Die Arbeit des Online-Shops besteht aus einer relativ großen Anzahl von Komponenten. Und egal, was der Plan ist, um jetzt Gewinn zu machen, zu wachsen und nach Investoren zu suchen oder zum Beispiel verwandte Bereiche zu entwickeln, müssen Sie zumindest diese Fragen schließen:
- Arbeiten Sie mit Lieferanten. Um etwas Unnötiges zu verkaufen, müssen Sie zuerst etwas Unnötiges kaufen.
- Verzeichnisverwaltung. Jemand hat eine enge Spezialisierung, während jemand Hunderttausende verschiedener Waren verkauft.
- Einzelhandelspreismanagement. Hier müssen Sie die Preise der Lieferanten und die Preise der Wettbewerber sowie erschwingliche Finanzinstrumente berücksichtigen.
- Arbeite mit dem Lager. Grundsätzlich ist es möglich, kein eigenes Lager zu haben, sondern die Waren aus den Lagern der Partner zu entnehmen, aber auf die eine oder andere Weise stellt sich die Frage.
- Marketing. Hier ist die Website mit Inhalten, Platzierung auf Websites, Werbung (online und offline), Werbeaktionen und vielem mehr gefüllt.
- Empfang und Bearbeitung von Bestellungen. Call Center, Warenkorb auf der Website, Bestellungen über Instant Messenger, Bestellungen über Plattformen und Marktplätze.
- Lieferung.
- Buchhaltung und andere interne Systeme.
Das Geschäft, über das wir sprechen werden, hat keine enge Spezialisierung, bietet aber eine Menge von Kosmetik bis hin zu Minitraktoren. Ich werde Ihnen erzählen, wie wir mit Lieferanten zusammenarbeiten, Wettbewerber überwachen, Katalogverwaltung und Preisgestaltung (Groß- und Einzelhandel) und mit Großhandelskunden zusammenarbeiten. Ein kleiner Touch zum Thema Lager.
Um einige der technischen Lösungen besser zu verstehen, ist es nicht überflüssig, dies zu wissen
Irgendwann beschlossen wir, dass technologische Dinge, wenn möglich, nicht für uns selbst, sondern universell erledigt werden sollten. Und vielleicht wird es nach mehreren Versuchen herauskommen, ein neues Geschäft aufzubauen. Es stellt sich unter bestimmten Bedingungen als Startup innerhalb des Unternehmens heraus.
Wir erwägen daher ein separates, mehr oder weniger universelles System, in das der Rest der Unternehmensinfrastruktur integriert ist.
Was ist das Problem der Zusammenarbeit mit Lieferanten?
Und es gibt tatsächlich viele von ihnen. Nur um etwas zu geben:
- Es gibt viele Lieferanten an sich. Wir haben ungefähr 400. Jeder muss sich etwas Zeit nehmen.
- Es gibt keine einzige Möglichkeit, Angebote von Lieferanten zu erhalten. Jemand sendet pünktlich an die Mail, jemand auf Anfrage, jemand lädt auf Datei-Hosting hoch, jemand platziert auf der Site. Es gibt viele Möglichkeiten, die Datei über Skype zu senden.
- Es gibt kein einzelnes Datenformat. Ich habe sogar ein Bild zu diesem Thema gezeichnet (es ist niedriger, Tabellen symbolisieren verschiedene Formate).
- Es gibt das Konzept der Mindesteinzelhandels- und Mindestgroßhandelspreise, die eingehalten werden müssen, um weiterhin mit dem Lieferanten zusammenarbeiten zu können. Oft werden sie in ihrem eigenen Format bereitgestellt.
- Die Nomenklatur jedes Lieferanten ist unterschiedlich. Infolgedessen wird dasselbe Produkt unterschiedlich genannt, und es gibt keinen eindeutigen Schlüssel, mit dem sie leicht verglichen werden können. Deshalb vergleichen wir es schwierig.
- Das System der Bestellung beim Lieferanten ist nicht automatisiert. Wir bestellen von jemandem über Skype, von jemandem in Ihrem Konto bis zu jemandem, dem wir jeden Abend eine Exel-Datei mit einer Liste von Bestellungen senden.

Wir haben gelernt, mit diesen Problemen umzugehen. Zusätzlich zu letzterem wird an letzterem gearbeitet. Nun wird es technische Details geben und dann die folgende Liste betrachten.
Daten sammeln
Wie es war
Lieferantendateien wurden manuell aus verschiedenen Quellen gesammelt und vorbereitet. Die Vorbereitung umfasste das Umbenennen gemäß einer bestimmten Vorlage und das Bearbeiten von Inhalten. Je nach Datei mussten nicht standardmäßige Waren, nicht auf Lager befindliche Waren, Spalten umbenannt oder Währungen umgerechnet, Daten von verschiedenen Registerkarten auf einer gesammelt werden.
Wie hat
Zunächst lernten wir, Post zu überprüfen und Briefe mit Anhängen von dort abzuholen. Dann automatisierten sie die Arbeit mit direkten Links und Links zu Yandex- und Google-Laufwerken. Dies löste das Problem, Angebote von ungefähr 75% unserer Lieferanten zu erhalten. Wir haben auch festgestellt, dass Angebote über diese Kanäle häufiger aktualisiert werden, sodass der tatsächliche Prozentsatz der Automatisierung höher ist. Wir bekommen immer noch einige Preise für Boten.
Zweitens verarbeiten wir Dateien nicht mehr manuell. Zu diesem Zweck haben wir Lieferantenprofile eingegeben, in denen Sie angeben können, welche Spalte und Registerkarte verwendet werden soll, wie Währung und Verfügbarkeit, Lieferzeit und Arbeitsplan des Lieferanten ermittelt werden sollen.
Es stellte sich flexibel heraus. Natürlich haben wir beim ersten Mal nicht alles berücksichtigt, aber jetzt gibt es genug Flexibilität, um die Verarbeitung aller 400 Anbieter zu konfigurieren, da jeder unterschiedliche Dateiformate hat.
In Bezug auf Dateiformate verstehen wir xls, xlsx, csv, xml (yml). In unserem Fall war das genug.
Sie fanden auch heraus, wie Datensätze gefiltert werden. Wir haben eine Liste mit Stoppwörtern erstellt, und wenn das Angebot des Lieferanten diese enthält, verarbeiten wir sie nicht. Technische Details sind wie folgt: Auf einer kleinen Liste können Sie und noch besser "frontal", auf großen Listen schneller Bloom Filter. Wir haben mit ihm experimentiert und alles so gelassen, wie es ist, weil der Gewinn auf der Liste um eine Größenordnung größer ist als bei uns.
Ein weiterer wichtiger Punkt ist der Arbeitsplan des Lieferanten. Unsere Lieferanten arbeiten nach unterschiedlichen Zeitplänen, außerdem befinden sie sich in verschiedenen Ländern, an denen die Wochenenden nicht zusammenfallen. Die Lieferzeit wird normalerweise als Zahl oder als Zahlenbereich in Werktagen angegeben. Wenn wir die Einzel- und Großhandelspreise bilden, müssen wir irgendwie den Zeitpunkt bewerten, zu dem wir die Waren an den Kunden liefern können. Zu diesem Zweck haben wir konfigurierbare Kalender erstellt. In den Einstellungen jedes Anbieters können Sie angeben, auf welchem Kalender er funktioniert.
Ich musste je nach Kategorie und Hersteller eine Konfiguration der Rabatte und Margen vornehmen. Es kommt vor, dass der Lieferant eine gemeinsame Datei für alle Partner hat, aber es gibt Rabattvereinbarungen mit einigen Partnern. Dank dessen war es weiterhin möglich, bei Bedarf Mehrwertsteuer zu addieren oder zu subtrahieren.
Die Konfiguration der Rabatt- und Aufschlagregeln führt uns übrigens zum nächsten Thema. Schließlich müssen Sie vor der Verwendung herausfinden, um welche Art von Produkt es sich handelt.
So funktioniert Mapping
Ein kleines Beispiel dafür, wie dasselbe Produkt von verschiedenen Lieferanten aufgerufen werden kann, um zu verstehen, mit was Sie arbeiten müssen:
Monitor LG LCD 22MP48D-P
21,5 "LG 22MP48D-P Schwarz (16: 9, 1920 x 1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Computerperipheriegeräte - Monitore LG 22MP48D-P
bis zu 22 "inklusive LG Monitor LG 22MP48D-P (21,5", schwarz, IPS-LED 5 ms 16: 9 DVI matt 250 cd 1920 x 1080 D-Sub FHD) 22MP48D-P
Monitore LG 22 "LG 22MP48D-P Hochglanzschwarz (IPS, LED, 1920 x 1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100 M: 1, + DVI) Monitor
LCD-Monitore LG LCD-Monitor 22 "IPS 22MP48D-P LG 22MP48D-P
LG Monitor 21,5 "LG 22MP48D-P gl.Black IPS, 1920 x 1080, 5 ms, 250 cd / m2, 1000: 1 (Mega-DCR), D-Sub, DVI-D (HDCP), Vesa 22MP48D-P.ARUZ
LG Monitor LG 22MP48D-P Schwarz 22MP48D-P.ARUZ
Monitor LG 22MP48D-P 22MP48D-P
Monitore LG 22MP48D-P Hochglanzschwarz 22MP48D-P
Monitor 21,5 "LG Flatron 22MP48D-P schwarz (IPS, 1920 x 1080, 16: 9, 178/178, 250 cd / m2, 1000: 1, 5 ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Monitor 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21,5 "22MP48D-P IPS-LED, 1920 x 1080, 5 ms, 250 cd / m2, 5 ml: 1, 178 ° / 178 °, D-Sub, DVI, Neigung, VESA, glänzendes Schwarz 22MP48D-P
LG 21,5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Monitor 21.5`` LG 22MP48D-P Schwarz
LG MONITOR 21,5 "LG 22MP48D-P glänzend schwarz (IPS, LED, 1920 x 1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100 M: 1, + DVI) 22MP48D-P
LG LCD-Monitor 21,5 '' [16: 9] 1920 x 1080 (FHD) IPS, nicht GLAR, 250 cd / m2, H178 ° / V178 °, 1000: 1, 16,7 M Farbe, 5 ms, VGA, DVI, Neigung, 2 Jahre, Schwarz OK 22MP48D -P
LCD LG 21,5 "22MP48D-P schwarz {IPS LED 1920 x 1080 5 ms 16: 9 250 cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22 "LCD 22MP48D 22MP48D-P
21,5 "16x9 LG Monitor LG 21,5" 22MP48D-P schwarz IPS LED 5ms 16: 9 DVI matt 250cd 1920x1080 D-Sub FHD 2,7 kg 22MP48D-P.ARUZ
Monitor 21,5 "LG 22MP48D-P [Schwarz]; 5 ms; 1920 x 1080, DVI, IPS
Wie es war
Der Vergleich umfasste 1C (kostenpflichtiges Modul eines Drittanbieters). In Bezug auf Bequemlichkeit / Geschwindigkeit / Genauigkeit ermöglichte ein solches System die Führung eines Katalogs mit 60.000 Produkten, die auf dieser Ebene von 6 Personen verfügbar waren. Das heißt, jeden Tag veraltet und aus den Angeboten der Lieferanten verschwunden, wurden so viele passende Waren wie neue erstellt. Sehr ungefähr - 0,5% der Kataloggröße, d.h. 300 Produkte.
Wie es wurde: eine allgemeine Beschreibung des Ansatzes
Etwas höher gab ich ein Beispiel dafür, was wir zusammenbringen müssen. Als ich mich mit dem Thema Matching befasste, war ich ein wenig überrascht, dass ElasticSearch für die Matching-Aufgabe beliebt ist. Meiner Meinung nach weist es konzeptionelle Einschränkungen auf. Für unseren Technologie-Stack verwenden wir MS SQL Server zur Datenspeicherung. Der Vergleich funktioniert jedoch in unserer eigenen Infrastruktur. Da viele Daten vorhanden sind und wir sie schnell verarbeiten müssen, verwenden wir Datenstrukturen, die für eine bestimmte Aufgabe optimiert sind, und versuchen, nicht ohne Bedarf auf die Festplatte oder Datenbank zuzugreifen und andere langsame Systeme.
Offensichtlich kann das Vergleichsproblem auf viele Arten gelöst werden, und offensichtlich liefert keine von ihnen absolute Genauigkeit. Daher besteht die Hauptidee darin, diese Methoden zu kombinieren, sie nach Genauigkeit und Geschwindigkeit zu ordnen und sie unter Berücksichtigung der Geschwindigkeit in absteigender Reihenfolge der Genauigkeit anzuwenden.
Der Ausführungsplan für jeden unserer Algorithmen (mit Vorbehalt zu entarteten Fällen) kann kurz durch die folgende allgemeine Reihenfolge dargestellt werden:
Tokenisierung Wir brechen die Quelllinie in etwas Bedeutendes, unabhängiges. Es kann einmal und weiter in allen Algorithmen verwendet werden.
Normalisierung von Token. In guter Weise müssen Sie die Wörter der natürlichen Sprache auf die allgemeine Zahl und Deklination und Bezeichner wie „ABC15MX“ (dies ist, wenn überhaupt, kyrillisch) bringen, um sie in Latein umzuwandeln. Und bringen Sie alles in das gleiche Register.
Token-Kategorisierung. Ich versuche zu verstehen, was jeder Teil bedeutet. Sie können beispielsweise eine Kategorie, einen Hersteller, eine Farbe usw. auswählen.
Suchen Sie nach dem besten Kandidaten für ein Match.
Eine Schätzung der Wahrscheinlichkeit, dass die ursprüngliche Linie und der beste Kandidat dasselbe Produkt anzeigen.
Die ersten beiden Punkte gelten für alle derzeit verfügbaren Algorithmen, und dann beginnen die Improvisationen.
Tokenisierung Hier haben wir genau das getan, wir teilen die Linie in Teile nach Sonderzeichen wie Leerzeichen, Schrägstrich und so weiter. Der Zeichensatz im Laufe der Zeit stellte sich als signifikant heraus, aber wir haben im Algorithmus selbst nichts Kompliziertes verwendet.
Dann müssen wir die Token normalisieren. Konvertieren Sie sie in Kleinbuchstaben. Anstatt alles zum Nominativ zu führen, schneiden wir einfach die Enden ab. Wir haben auch ein kleines Wörterbuch und übersetzen unsere Token ins Englische. Unter anderem erspart uns die Übersetzung Synonyme, ähnlich wie russische Wörter auf die gleiche Weise ins Englische übersetzt werden. Wo wir nicht übersetzen konnten, ändern wir die buchstabierten kyrillischen Zeichen in das lateinische Alphabet. (Es ist überhaupt nicht überflüssig, wie sich herausstellte. Selbst wenn Sie keinen schmutzigen Trick erwarten, zum Beispiel in der Zeile "Samsung U43NU7100U", kann das kyrillische E durchaus mithalten.)

Token-Kategorisierung. Wir können die Kategorie, Hersteller, Modell, Artikel, EAN, Farbe hervorheben. Wir haben ein Verzeichnis, in dem die Daten strukturiert sind. Wir haben Daten zu Wettbewerbern, die uns Handelsplattformen zur Verfügung stellen. Wenn möglich, strukturieren wir die Daten bei der Verarbeitung. Wir können Fehler oder Tippfehler korrigieren, z. B. den Hersteller oder die Farbe, die in allen unseren Quellen nur einmal vorkommen, ohne den Hersteller bzw. die Farbe zu berücksichtigen. Als Ergebnis haben wir ein großes Wörterbuch mit möglichen Herstellern, Modellen, Artikeln, Farben und Token-Kategorisierung ist nur eine Wörterbuchsuche nach O (1). Theoretisch können Sie eine offene Liste von Kategorien und eine Art intelligenten Klassifizierungsalgorithmus haben, aber unser grundlegender Ansatz funktioniert gut, und die Kategorisierung ist kein Engpass.
Es ist zu beachten, dass der Lieferant manchmal bereits strukturierte Daten bereitstellt, z. B. der Artikel sich in einer separaten Zelle in der Tabelle befindet oder der Lieferant beim Großhandel einen Rabatt auf den Einzelhandel gewährt und die Einzelhandelspreise im yml (xml) -Format erhältlich sind. Dann speichern wir die Datenstruktur und unterteilen die Token heuristisch nur aus unstrukturierten Daten in Kategorien.
Und nun darüber, welche Algorithmen und in welcher Reihenfolge wir verwenden.
Genaue und fast exakte Übereinstimmungen
Der einfachste Fall. Die Linien wurden in Token unterteilt, sie führten sie zu einer Form. Dann haben sie eine Hash-Funktion entwickelt, die nicht auf die Reihenfolge der Token reagiert. Darüber hinaus können wir durch Matching per Hash alle Daten im Speicher behalten und uns 16 Megabyte pro Wörterbuch mit einer Million Schlüsseln leisten. In der Praxis schnitt der Algorithmus besser ab als einfache Zeichenfolgenvergleiche.
Was das Hashing betrifft, bietet sich die Verwendung von "exklusiv oder" und eine Funktion wie diese an:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
Das Interessanteste in dieser Phase ist, einen Hash einer einzelnen Zeile zu erhalten. In der Praxis stellte sich heraus, dass 32 Bit klein sind und viele Kollisionen erhalten werden. Außerdem können Sie nicht nur den Quellcode der Funktion aus dem Framework entnehmen und den Typ des Rückgabewerts ändern. Es gibt weniger Kollisionen für einzelne Zeilen, aber nach dem "exklusiven oder" treten sie immer noch auf. Deshalb haben wir unseren eigenen geschrieben. Tatsächlich haben sie die Funktion einfach aus dem Nichtlinearitäts-Framework aus den Eingabedaten hinzugefügt. Es war definitiv besser, mit der neuen Funktion mit einer Kollision haben wir uns nur einmal auf unseren Millionen von Datensätzen getroffen, aufgezeichnet und auf bessere Zeiten verschoben.
Daher suchen wir nach Übereinstimmungen, ohne die Wortreihenfolge und ihre Form zu berücksichtigen. Eine solche Suche funktioniert für O (1).
Leider selten, aber es kommt auch vor: "ABC 42 Typ 16" und "ABC 16 Typ 42", und das sind zwei verschiedene Produkte. Wir haben auch gelernt, mit solchen Dingen umzugehen, aber dazu später mehr.
Passende vom Menschen bestätigte Produkte
Wir haben Produkte, die manuell abgeglichen werden (meistens handelt es sich um Produkte, die automatisch abgeglichen werden, aber manuell überprüft wurden). Tatsächlich machen wir in diesem Fall dasselbe, nur dass wir jetzt ein Wörterbuch mit übereinstimmenden Hashes hinzugefügt haben, dessen Suche die zeitliche Komplexität des Algorithmus nicht verändert hat.
Manuell übereinstimmende Zeilen liegen einfach in der Datenbank, nur für den Fall, dass Sie mit solchen Rohdaten den Hashing-Algorithmus in Zukunft ändern, alles neu berechnen und nichts verlieren können.
Attributzuordnung
Die ersten beiden Algorithmen sind schnell und genau, aber nicht genug. Als nächstes wenden wir den Attributabgleich an.
Zuvor haben wir die Daten bereits in Form von normalisierten Token dargestellt und sogar in Kategorien sortiert. In diesem Kapitel rufe ich Token-Kategorienattribute auf.
Das zuverlässigste Attribut ist EAN (https://ru.wikipedia.org/wiki/European_Article_Number). EAN-Übereinstimmungen geben Ihnen fast 100% Garantie, dass es sich um dasselbe Produkt handelt. Eine EAN-Nichtübereinstimmung sagt jedoch nichts aus, da ein Produkt unterschiedliche EANs haben kann. Alles wäre in Ordnung, aber in unseren Daten ist die EAN selten, daher ihr Einfluss auf den Vergleich auf der Fehlerstufe.
Der Artikel ist weniger zuverlässig. Etwas Seltsames kommt oft direkt aus den strukturierten Daten des Lieferanten, aber in diesem Stadium verwenden wir es auf jeden Fall.
Wie in der letzten Phase verwenden wir hier Wörterbücher (Suche nach O (1)), und der Hash von (Hersteller + Modell + Artikel) wird als Schlüssel verwendet. Mit Hashing können Sie alle Vorgänge im Speicher ausführen. In diesem Fall berücksichtigen wir auch die Farbe, wenn sie übereinstimmt oder nicht existiert, dann glauben wir, dass die Ware zusammenfiel.
Suche nach der besten Übereinstimmung
Die vorherigen Schritte waren einfach, schnell und ziemlich zuverlässig, decken jedoch leider weniger als die Hälfte der Vergleiche ab.
Bei der Suche nach der besten Übereinstimmung gibt es eine einfache Idee: Das Zusammentreffen seltener Token hat ein großes Gewicht, das Zusammentreffen häufiger Token ist gering. Token, die Zahlen enthalten, haben einen höheren Wert als Buchstaben-Token. Token, die in derselben Reihenfolge übereinstimmen, werden höher bewertet als Token, die neu angeordnet wurden. Lange Spiele sind besser als kurze.
Jetzt bleibt eine schnelle Datenstruktur zu entwickeln, die all dies gleichzeitig berücksichtigen kann und in den Speicher eines Verzeichnisses mit einigen Millionen Datensätzen passt.
Wir hatten die Idee, unseren Katalog in Form eines Wörterbuchs von Wörterbüchern zu präsentieren. Auf der ersten Ebene wird der Schlüssel ein Hash des Herstellers sein (die Daten im Katalog sind strukturiert, wir kennen den Hersteller), der Wert ist das Wörterbuch. Nun die zweite Ebene. Der Schlüssel auf der zweiten Ebene ist der Hash vom Token. Der Wert ist die Liste der ID-Elemente aus dem Katalog, in dem dieses Token vorkommt. In diesem Fall verwenden wir Kombinationen von Token in der Reihenfolge, in der sie in unserem Katalog erscheinen. Wir entscheiden, was als Kombination verwendet werden soll und was nicht. Abhängig von der Anzahl der Token, ihrer Länge usw. ist dies ein Kompromiss zwischen Geschwindigkeit, Genauigkeit und dem erforderlichen Speicher. In der Abbildung habe ich diese Struktur ohne Hashes und ohne Normalisierung vereinfacht.
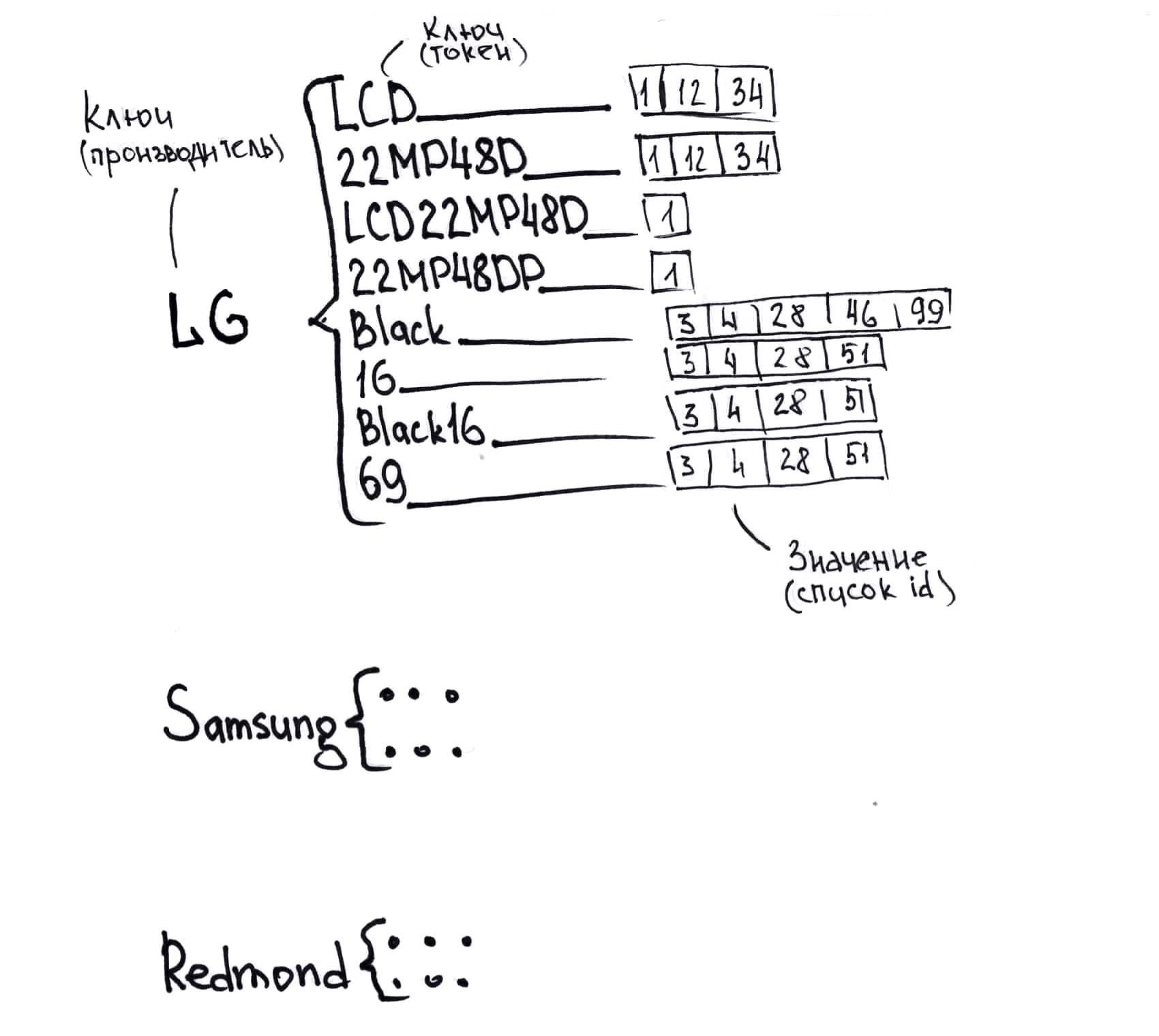
Wenn durchschnittlich 20 Token für jedes Produkt verwendet werden, wird in unseren Listen, die die Werte des beigefügten Wörterbuchs enthalten, durchschnittlich 20 Mal eine Verknüpfung zum Produkt hergestellt. Es gibt nicht mehr als 20 Mal andere Token als Waren im Katalog. Sie können ungefähr den für einen Katalog mit einer Million Datensätzen erforderlichen Speicher berechnen: 20 Millionen Schlüssel, jeweils 4 Byte, 20 Millionen Produkt-ID, jeweils 4 Byte, Overhead für die Organisation von Wörterbüchern und Listen (die Reihenfolge ist dieselbe, jedoch aufgrund der Größe von Listen und Wörterbüchern wir wissen es nicht im Voraus, sondern nehmen unterwegs zu, multiplizieren mit zwei). Insgesamt - 480 Megabyte. In Wirklichkeit stellte sich heraus, dass es ein bisschen mehr Token für Waren gab, und wir benötigen bis zu 800 Megabyte pro Katalog in einer Million Waren. Was akzeptabel ist, die Funktionen des modernen Eisens ermöglichen es Ihnen, mehr als hundert Verzeichnisse dieser Größe gleichzeitig im Speicher zu speichern.
Zurück zum Algorithmus. Mit einer Zeichenfolge, die wir abgleichen müssen, können wir den Hersteller bestimmen (wir haben einen Kategorisierungsalgorithmus) und dann Token mit demselben Algorithmus wie für Waren aus dem Katalog abrufen. Hier meine ich, einschließlich Kombinationen von Token.
Dann ist alles relativ einfach. Für jedes Token können wir schnell alle Produkte finden, in denen es gefunden wurde, das Gewicht jeder Übereinstimmung schätzen, alles berücksichtigen, worüber wir zuvor gesprochen haben - Länge, Häufigkeit, Vorhandensein von Zahlen oder Sonderzeichen - und die „Ähnlichkeit“ aller gefundenen Kandidaten bewerten. In der Realität gibt es auch hier Optimierungen. Wir berücksichtigen nicht alle Kandidaten. Zuerst erstellen wir eine kleine Liste von Übereinstimmungen von Token mit großem Gewicht, und wir wenden keine Übereinstimmungen von Token mit geringem Gewicht auf alle Produkte an, sondern nur auf diese Liste.
Wir wählen die beste Übereinstimmung aus, betrachten die Übereinstimmung der Token, die sich als kategorisiert herausstellten, und berücksichtigen die Vergleichsbewertung. Ferner haben wir zwei Schwellenwerte P1 und P2, P1 <P2. Wenn sich herausstellt, dass die Bewertung den Schwellenwert P2 überschreitet - eine Beteiligung des Menschen ist nicht erforderlich, geschieht alles automatisch. Wenn zwischen zwei Werten - wir bieten an, den Vergleich manuell zu sehen, bevor er nicht an der Preisgestaltung teilnimmt. Wenn weniger als P1 - höchstwahrscheinlich ist ein solches Produkt nicht im Katalog enthalten, geben wir nichts zurück.
Zurück zu den Zeilen "ABC 42 Type 16" und "ABC 16 Type 42". Die Lösung ist überraschend einfach: Wenn mehrere Produkte dieselben Hashes haben, stimmen wir sie nicht mit Hash überein. Und der letzte Algorithmus berücksichtigt die Reihenfolge der Token. Theoretisch können solche Zeilen in der Preisliste des Lieferanten mit nichts Beliebigem abgeglichen werden, wenn die Nummern 16 und 42 überhaupt nicht vorkommen. Tatsächlich sind wir auf ein solches Bedürfnis nicht gestoßen.
Geschwindigkeit und Genauigkeit
Nun zur Geschwindigkeit von allem. Die für die lineare Erstellung der Wörterbücher erforderliche Zeit hängt von der Größe des Katalogs ab. Die direkt zum Vergleich benötigte Zeit hängt linear von der Anzahl der zu vergleichenden Waren ab. Alle an der Suche beteiligten Datenstrukturen werden nach der Erstellung nicht geändert. Dies gibt uns die Möglichkeit, Multithreading in der Matching-Phase zu verwenden. Die Vorbereitungsarbeiten für den Katalog mit einer Million Datensätzen dauern etwa 40 bis 80 Sekunden. Der Vergleich funktioniert mit einer Geschwindigkeit von 20-40.000 Datensätzen pro Sekunde und hängt nicht von der Größe des Verzeichnisses ab. Dann müssen Sie jedoch die Ergebnisse speichern. Der gewählte Ansatz ist im Allgemeinen für große Volumes von Vorteil, aber eine Datei mit einem Dutzend Datensätzen ist unverhältnismäßig lang. Daher verwenden wir den Cache und zählen unsere Suchstrukturen alle 15 Minuten neu.
Zwar müssen die zu vergleichenden Daten irgendwo gelesen werden (meistens handelt es sich um eine Excel-Datei), und die passenden Sätze müssen irgendwo gespeichert werden, und dies braucht auch Zeit. Die Gesamtzahl beträgt also 2-4 Tausend Datensätze pro Sekunde.
Um die Genauigkeit zu bewerten, haben wir eine Testsuite von ca. 20.000 manuell verifizierten Vergleichen verschiedener Lieferanten aus verschiedenen Kategorien erstellt. Nach jeder Änderung wurde der Algorithmus anhand dieser Daten getestet. Die Ergebnisse sind wie folgt:
- Die Waren befinden sich im Katalog und wurden korrekt verglichen - 84%
- Das Produkt befindet sich im Katalog, wurde jedoch nicht abgeglichen. Ein manueller Abgleich ist erforderlich - 16%
- Die Waren befinden sich im Katalog und wurden falsch verglichen - 0,2%
- Das Produkt befindet sich nicht im Katalog und wurde vom Programm korrekt identifiziert - 98,5%
- Das Produkt ist nicht im Katalog enthalten, aber das Programm hat es mit einem der Produkte abgeglichen - 1,5%
In 80% der Fälle, in denen das Produkt übereinstimmte, ist keine manuelle Bestätigung erforderlich (wir bestätigen den Vergleich automatisch). Unter diesen automatisch bestätigten Angeboten sind 0,1% der Fehler.
Übrigens, 0,1% der Fehler sind viel, wie sich herausstellt. Bei einer Million übereinstimmender Datensätze sind dies tausend falsch übereinstimmende Datensätze. Und das ist eine Menge, weil Käufer genau solche Aufzeichnungen am besten finden. Nun, wie man keinen Traktor für den Preis der Scheinwerfer von diesem Traktor bestellt. Diese tausend Fehler stehen jedoch zu Beginn der Arbeit an einer Million Vorschlägen, sie wurden schrittweise korrigiert. Die Quarantäne für verdächtige Preise, die dieses Problem schließt, erschien später, in den ersten Monaten, in denen wir ohne sie gearbeitet haben.
Es gibt eine andere Kategorie von Fehlern, die nicht mit dem Vergleich zusammenhängt: Dies sind die falschen Preise unserer Lieferanten. Dies ist teilweise der Grund, warum wir den Preis im Vergleich nicht berücksichtigen. Wir haben beschlossen, dass wir, da wir zusätzliche Informationen in Form eines Preises haben, versuchen werden, nicht nur unsere eigenen Fehler, sondern auch die anderer zu ermitteln.
Suche nach den falschen Preisen
Dies ist der Teil, an dem wir aktiv experimentieren. Die Basisversion ist, und es erlaubt Ihnen nicht, das Telefon zum Preis eines Gehäuses zu verkaufen, aber ich habe das Gefühl, dass es besser ist.
Für jedes Produkt finden wir die Grenzen akzeptabler Lieferantenpreise. Je nachdem, welche Daten verfügbar sind, berücksichtigen wir die Preise der Lieferanten für dieses Produkt, die Preise der Wettbewerber, die Preise der Lieferanten der Waren dieses Herstellers in dieser Kategorie. Die Preise, die nicht innerhalb der Grenzen liegen, werden unter Quarantäne gestellt und in allen unseren Algorithmen ignoriert. Manuell können Sie einen so verdächtigen Preis als normal markieren. Dann merken wir uns dies für dieses Produkt und geben die Grenzen akzeptabler Preise an.
Der direkte Algorithmus zur Berechnung der maximal und minimal akzeptablen Preise ändert sich ständig. Wir suchen nach einem Kompromiss zwischen der Anzahl der falsch positiven und der Anzahl der erkannten falschen Preise.
Wir verwenden Medianwerte in den Berechnungen (Durchschnittswerte ergeben das schlechteste Ergebnis) und analysieren die Verteilungsform noch nicht. Die Analyse der Verteilungsform ist genau der Ort, an dem der Algorithmus meines Erachtens verbessert werden kann.
Arbeiten Sie mit der Datenbank
Aus all dem können wir schließen, dass wir die Daten zu Lieferanten und Wettbewerbern häufig und auf vielfältige Weise aktualisieren und die Arbeit mit der Datenbank zu einem Engpass werden kann. Grundsätzlich haben wir zunächst darauf hingewiesen und versucht, maximale Leistung zu erzielen. Wenn Sie mit einer großen Anzahl von Datensätzen arbeiten, gehen wir wie folgt vor:
- Wir löschen Indizes aus der Tabelle, mit der wir arbeiten
- Deaktivieren Sie die Volltextindizierung für diese Tabelle
- Löschen Sie alle Datensätze mit einer bestimmten Bedingung (z. B. alle Angebote bestimmter Lieferanten, die wir gerade bearbeiten).
- Fügen Sie neue Datensätze mit BULK COPY ein
- Indizes neu erstellen
- Aktivieren Sie die Volltextindizierung
Massenkopien arbeiten mit einer Geschwindigkeit von 10-40.000 Datensätzen pro Sekunde, weshalb eine so große Verbreitung noch abzuwarten ist, aber so akzeptabel ist.
Das Löschen von Datensätzen dauert ungefähr genauso lange wie das Einfügen. Es ist noch einige Zeit erforderlich, um die Indizes neu zu erstellen.
Übrigens haben wir für jedes Verzeichnis eine eigene Datenbank. Wir erstellen sie im laufenden Betrieb. Und jetzt erkläre ich Ihnen, warum wir mehr als einen Katalog haben.
Was ist das Problem der Katalogisierung
Und es gibt auch viele von ihnen. Jetzt werden wir auflisten:
- Der Katalog enthält rund 400.000 Produkte aus ganz unterschiedlichen Kategorien. Es ist unmöglich, jede der Kategorien professionell zu verstehen.
- Sie müssen einem bestimmten Stil folgen, die allgemeinen Regeln für den Namen des Katalogs befolgen, Unterkategorien benennen usw. Daher versuchen wir, eine kohärente und logische Verzeichnisstruktur zu erreichen.
- Sie können dasselbe Produkt mehrmals erstellen, und dies ist ein Problem. Ohne ein Tool, das ähnliche Namen analysiert, werden ständig Duplikate erstellt.
- Es ist sinnvoll, die Waren, die Lieferanten auf Lager haben, in den Katalog aufzunehmen. In diesem Fall benötigen Sie Prioritäten für Produktkategorien.
- Wir brauchen mehrere Verzeichnisse. Einer von uns, wir führen ihn selbst durch, der andere - der Aggregatorkatalog, wir aktualisieren ihn per API. Die Bedeutung des zweiten Katalogs besteht darin, dass die Aggregatorplattform nur mit ihrem eigenen Katalog arbeitet und dementsprechend Angebote in ihrer Nomenklatur akzeptiert. Dies ist ein weiterer Ort, an dem sich herausstellte, dass Sie einen Vergleich benötigen.
Wir hielten es für logisch und richtig, ein Verzeichnis an derselben Stelle zu führen, an der Vergleiche durchgeführt werden. So können wir den Benutzern, die das Verzeichnis verwalten, mitteilen, was der Lieferant hat, jedoch nicht im Verzeichnis.
Wie führen wir einen Katalog?
Es wird sich um den Katalog ohne detaillierte Merkmale handeln, die Merkmale sind eine separate große Geschichte, ein anderes Mal darüber.
Als grundlegende Eigenschaften haben wir Folgendes gewählt:
- Produzent
- Kategorie
- das Modell
- Artikelnummer
- Farbe
- Ean
Zuerst haben wir eine API erstellt, um den Katalog von einer externen Quelle zu beziehen, und dann haben wir daran gearbeitet, Datensätze bequem zu erstellen, zu bearbeiten und zu löschen.
Wie die Suche funktioniert
Die Bequemlichkeit der Verwaltung eines Katalogs besteht vor allem darin, dass ein Produkt schnell in einem Katalog oder im Angebot eines Lieferanten gefunden werden kann und es Nuancen gibt. Beispielsweise müssen Sie in der Lage sein, nach der Zeile "LG 21.5" 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P "für" 2MP48 "zu suchen.
Die sofort einsatzbereite SQL Server-Volltextsuche ist nicht geeignet, da sie nicht weiß, wie sie ausgeführt werden soll, und die Suche mit LIKE '% 2MP48%' ist zu langsam.
Unsere Lösung ist ziemlich Standard, wir verwenden N-Gramm. Genauer gesagt, dann Trigramme. Und bereits durch Trigramme erstellen wir einen Volltextindex und führen eine Volltextsuche durch. Ich bin mir nicht sicher, ob wir den Speicherplatz in diesem Fall sehr rational nutzen, aber in Bezug auf die Geschwindigkeit wurde diese Lösung je nach Anforderung von 50 bis 500 Millisekunden, manchmal bis zu einer Sekunde bei einem Array von drei Millionen Datensätzen, entwickelt.
Lassen Sie mich erklären, dass die Zeile "LG 21.5" 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P in die Zeile "lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad" konvertiert wird adv dvi vi2 i22 ”, das in einem separaten Feld gespeichert wird, das am Volltextindex teilnimmt.
Übrigens sind Trigramme für uns immer noch nützlich.
Erstellen Sie ein neues Produkt
Die Produkte im Katalog werden größtenteils auf Vorschlag des Lieferanten erstellt. Das heißt, wir haben bereits Informationen darüber, dass der Anbieter „LG LCD Monitor 21,5 '' [16: 9] 1920 x 1080 (FHD) IPS, nicht GLARE, 250 cd / m2, H178 ° / V178 °, 1000: 1, 16,7 m Farbe, anbietet. 5 ms, VGA, DVI, Tilt, 2Y, Schwarz OK 22MP48D-P ”zu einem Preis von 120 USD, und er hat 5 bis 10 Einheiten auf Lager.
Bei der Erstellung eines Produkts müssen wir zunächst sicherstellen, dass ein solches Produkt noch nicht im Katalog erstellt wurde. Wir lösen dieses Problem in vier Schritten.
Erstens, wenn wir ein Produkt im Katalog haben, ist es sehr wahrscheinlich, dass der Vorschlag des Lieferanten automatisch auf dieses Produkt abgestimmt wird.
Zweitens führen wir, bevor wir dem Benutzer das Formular zum Erstellen eines neuen Produkts zeigen, eine Suche nach Trigrammen durch und zeigen die relevantesten Ergebnisse an. (Technisch erfolgt dies mit CONTAINSTABLE).
Drittens werden wir beim Ausfüllen der Felder für ein neues Produkt ähnliche vorhandene Produkte anzeigen. Dies löst zwei Probleme: Es hilft, Duplikate zu vermeiden und den Stil in den Namen beizubehalten. Ähnliche Produkte können als Modell verwendet werden.
Und viertens, erinnern Sie sich, wir haben die Zeilen in Token aufgeteilt, sie normalisiert und Hashes gezählt? Wir werden das Gleiche tun und einfach keine Waren mit den gleichen Hashes erstellen lassen.
In dieser Phase versuchen wir, dem Benutzer zu helfen. Anhand der Zeile in der Preisliste werden wir versuchen, den Hersteller, die Kategorie, den Artikel, die EAN und die Farbe der Waren zu bestimmen. Zuerst durch Token (wir können sie in Kategorien einteilen), dann, wenn es nicht funktioniert, finden wir das ähnlichste Produkt durch Trigramme. Und wenn es ähnlich genug ist, geben Sie den Hersteller und die Kategorie ein.
Die Produktbearbeitung funktioniert fast gleich, nur dass nicht alles anwendbar ist.
Wie wir unsere Preise festlegen
Die Aufgabe besteht darin, ein Gleichgewicht zwischen Menge und Umsatzspanne aufrechtzuerhalten - um einen maximalen Gewinn zu erzielen. Bei allen anderen Aspekten der Geschäftstätigkeit geht es ebenfalls darum, aber genau das, was in der Preisphase geschieht, hat den größten Einfluss.
Zumindest benötigen wir Informationen zu Angeboten von Lieferanten und Wettbewerbern. Es lohnt sich auch, die Mindestein- und Großhandelspreise und Lieferkosten sowie Finanzinstrumente - Kredite und Raten - zu berücksichtigen.
Wir sammeln Mitbewerberpreise
Zunächst haben wir viele Profile unserer eigenen Preise. Es gibt ein Profil für den Einzelhandel, es gibt mehrere für Großhandelskunden. Alle von ihnen werden in unserem System erstellt und konfiguriert.
Dementsprechend sind die Wettbewerber für jedes Profil unterschiedlich. Im Einzelhandel - andere Einzelhandelsgeschäfte, im Großhandel - dieselben Lieferanten.
Bei den Lieferanten ist alles klar, aber für den Einzelhandel sammeln wir Wettbewerberdaten auf verschiedene Weise. Erstens liefern einige Aggregatoren Informationen zu allen Preisen für alle Waren, die sich auf der Website befinden. In unserer eigenen Nomenklatur können wir aber Produkte abgleichen, so dass es automatisch funktioniert. Und das ist vorerst fast genug. Zweitens haben wir Konkurrenten Parser. Da sie noch nicht automatisiert sind und in Form von Konsolenanwendungen vorliegen (die manchmal abstürzen), verwenden wir sie selten.
Passen Sie Ihr Profil an
Im Profil haben wir die Möglichkeit, je nach Warenpreis des Lieferanten, der Kategorie, des Herstellers, des Lieferanten unterschiedliche Margenbereiche zu konfigurieren.
Es ist weiterhin möglich anzugeben, mit welchen Lieferanten in welcher Kategorie oder welchem Hersteller wir arbeiten und mit welchen - nicht mit welchen Wettbewerbern wir berücksichtigen.Dann richten wir Finanzinstrumente ein, geben an, welche Raten verfügbar sind und wie viel die Bank für sich selbst nehmen wird.Und bereits innerhalb der Margengrenzen bilden wir unsere eigenen Preise, um in erster Linie das gleiche Gleichgewicht zu halten und in zweiter Linie den Verkauf unserer Lagerwaren zu verbessern. Dies ist auf den Punkt gebracht, aber in der Tat nehme ich nicht an, in einfachen Worten zu erklären, was dort passiert.Ich kann Ihnen sagen, was nicht passiert. Leider wissen wir noch nicht, wie wir die Nachfrage prognostizieren und die Kosten für die Lagerung von Waren in einem Lager berücksichtigen sollen.Integration in Systeme von Drittanbietern
Ein wichtiger Teil aus geschäftlicher Sicht, aber aus technischer Sicht uninteressant. Kurz gesagt, ich kann sagen, dass wir Daten an Systeme von Drittanbietern senden können (einschließlich inkrementeller Systeme, dh wir verstehen, was sich seit dem letzten Austausch geändert hat) und Mailinglisten erstellen können.Die Newsletter sind anpassbar, daher liefern wir (und nicht nur das) unsere Angebote an Großhandelskunden.Eine andere Möglichkeit, mit Großhandelskunden zusammenzuarbeiten, ist das B2B-Portal. Es befindet sich noch in der aktiven Entwicklung und wird in einem Monat buchstäblich funktionieren.Konten, Änderungsprotokollierung
Eine weitere aus technischer Sicht uninteressante Frage. Jeder Benutzer hat ein Konto.Kurz gesagt, kann Folgendes gesagt werden: Wenn ORM verwendet wird, verfügt es über einen integrierten Änderungsverfolgungsmechanismus. Wenn Sie sich darauf einlassen (und in unserem Fall ist es EF Core und es gibt dort sogar eine API), können Sie sich in fast zwei Zeilen anmelden.Für den Änderungsverlauf haben wir eine Benutzeroberfläche erstellt. Jetzt können Sie nachverfolgen, wer was in den Systemeinstellungen geändert hat, wer bestimmte Produkte bearbeitet oder verglichen hat usw.Den Protokollen zufolge können Statistiken berücksichtigt werden, was wir auch tun. Wir wissen, wer wie viele Produkte erstellt oder bearbeitet hat, wie viele Vergleiche manuell bestätigt wurden und wie viele abgelehnt wurden. Sie können jede Änderung sehen.Ein wenig über die allgemeine Struktur des Systems
Wir haben eine Datenbank für Konten und katalogunabhängige Dinge, eine Datenbank für Protokolle und eine Datenbank für jedes Verzeichnis. Dies erleichtert Verzeichnisabfragen, die Datenanalyse ist einfacher und der Code ist verständlicher.Das Protokollierungssystem ist übrigens selbst geschrieben. Wir müssen wirklich Protokolle gruppieren, die sich auf eine Anforderung oder eine schwere Aufgabe beziehen. Außerdem benötigen wir grundlegende Funktionen, um sie zu analysieren. Bei schlüsselfertigen Lösungen stellte sich heraus, dass dies schwierig ist, und dies ist eine weitere Abhängigkeit, die unterstützt werden muss.Die Weboberfläche wird unter ASP.NET Core und Bootstrap erstellt, und der Windows-Dienst führt umfangreiche Vorgänge aus.Ein weiteres Merkmal, von dem das Projekt meiner Meinung nach profitiert hat, sind verschiedene Modelle zum Lesen und Schreiben von Daten. Wir haben kein vollwertiges CQRS implementiert, aber wir haben eines der Konzepte von dort übernommen. Wir schreiben über die Repositorys in die Datenbank, aber die Objekte, die für die Aufzeichnung verwendet werden, verlassen niemals die Methoden zum Aktualisieren / Erstellen / Löschen. Die Massenaktualisierung erfolgt über BULK COPY. Zum Lesen wurden ein separates Modell und eine separate Ebene für den Datenzugriff erstellt, sodass wir nur das lesen, was wir zu einem bestimmten Zeitpunkt benötigen. Es stellte sich heraus, dass Sie ORM verwenden können, während Sie schwere Abfragen vermeiden, zu unsicheren Zeiten (wie beim verzögerten Laden) auf die Datenbank zugreifen und N + 1-Probleme haben. Außerdem verwenden wir das Modell zum Lesen als DTO.Von den Hauptabhängigkeiten haben wir ASP.NET Core, mehrere Nuget-Pakete von Drittanbietern und MS SQL Server. Obwohl dies möglich ist, versuchen wir, uns nicht auf viele Systeme von Drittanbietern zu verlassen. Um das Projekt vollständig lokal bereitzustellen, installieren Sie einfach SQL Server, holen Sie sich den Quellcode aus dem Versionskontrollsystem und erstellen Sie das Projekt. Die erforderlichen Datenbanken werden automatisch erstellt, es wird jedoch nichts anderes benötigt. Möglicherweise müssen Sie eine oder zwei Zeilen in der Konfiguration ändern.Was nicht
Wir haben noch kein Projektwissenssystem erstellt. Wir möchten Wikis und Tipps an Ort und Stelle machen. Sie haben keine einfache intuitive Benutzeroberfläche erstellt, die nicht schlecht, aber für eine unvorbereitete Person etwas verwirrt ist. CI / CD bisher nur in den Plänen.Hat die detaillierten Eigenschaften der Ware nicht behandelt. Wir planen auch, aber es gibt noch keine bestimmte Frist.
Geschäftsübersicht
Vom Beginn der aktiven Entwicklung bis zum Start in der Produktion arbeiteten zwei Personen 7 Monate an dem Projekt. Zu Beginn hatten wir in unserer Freizeit einen Prototyp. Die schwierigste Integration wurde in bestehende Systeme gegeben.In den drei Monaten, in denen wir in Produktion sind, ist die Anzahl der für Großhandelskunden verfügbaren Waren von 70.000 auf 230.000 gestiegen, die Anzahl der Waren auf der Baustelle von 60.000 auf 140.000. Die Website ist immer zu spät, da sie Funktionen, Bilder und Produktbeschreibungen benötigt. Wir entladen 106.000 Angebote auf den Aggregator anstatt 40.000 vor drei Monaten. Die Anzahl der Personen, die mit dem Katalog arbeiten, hat sich nicht geändert.Wir arbeiten mit 425 Lieferanten zusammen, diese Zahl hat sich in drei Monaten fast verdoppelt. Wir verfolgen die Preise von mehr als tausend Wettbewerbern. Nun, während wir es verfolgen - wir haben ein System zum Parsen, aber in den meisten Fällen nehmen wir vorgefertigte Daten von denen, die sie regelmäßig bereitstellen.Leider kann ich Ihnen nichts über Verkäufe erzählen, ich selbst habe keine zuverlässigen Daten. Die Nachfrage ist saisonabhängig und es ist unmöglich, den Monat direkt mit dem Vormonat zu vergleichen. Und in einem Jahr ist zu viel passiert, um den Einfluss unseres Systems von allen Faktoren hervorzuheben. Sehr, sehr bedingt, plus oder minus einen Kilometer, Katalogwachstum, flexiblere und wettbewerbsfähigere Preise und das damit verbundene Umsatzwachstum haben sich bereits für die Entwicklung und Implementierung bezahlt gemacht.Ein weiteres Ergebnis: Wir haben ein Projekt erhalten, das im Wesentlichen nicht mit der Infrastruktur eines bestimmten Geschäfts zusammenhängt, und Sie können daraus einen öffentlichen Dienst machen. Es wurde von Anfang an konzipiert und dieser Plan hat fast funktioniert. Leider ist die Boxed-Lösung fehlgeschlagen. Um ein Projekt als Service anzubieten, bei dem Sie sich registrieren können, aktivieren Sie das Kontrollkästchen "Ich stimme zu" und das "wie es ist" funktioniert, ohne sich an den Kunden anzupassen. Sie müssen die Benutzeroberfläche neu gestalten, Flexibilität hinzufügen und ein Wiki erstellen. Und um die Infrastruktur einfach skalierbar zu machen und einen einzelnen Fehlerpunkt zu beseitigen. Jetzt haben wir nur noch regelmäßige Backups, um die Zuverlässigkeit zu gewährleisten. Als Unternehmenslösung sind wir meiner Meinung nach bereit, geschäftliche Probleme zu lösen. Kleinunternehmen ist es, ein Unternehmen zu finden.Übrigens haben wir bereits einen Drittanbieter mit den grundlegendsten Funktionen gewonnen. Die Jungs brauchten ein Werkzeug zum Vergleichen von Waren, und die mit der aktiven Entwicklung verbundenen Unannehmlichkeiten erschreckten sie nicht.