Viele, die mit Spark ML gearbeitet haben, wissen, dass einige der Dinge, die sie dort getan haben, "nicht ganz erfolgreich" sind.
oder gar nicht gemacht. Die Position der Spark-Entwickler ist, dass SparkML die Basisplattform ist und alle Erweiterungen separate Pakete sein müssen. Dies ist jedoch nicht immer praktisch, da Data Scientist und Analysten mit vertrauten Tools (Jupter, Zeppelin) arbeiten möchten, bei denen das meiste benötigt wird. Sie möchten keine 500-Megabyte-JAR-Dateien mit Maven-Assembly sammeln oder Abhängigkeiten in ihre Hände herunterladen und zu den Spark-Startparametern hinzufügen. Eine genauere Arbeit mit Build-Systemen für JVM-Projekte erfordert möglicherweise viele zusätzliche Anstrengungen von Analysten und DataScientists, die an Jupyter / Zeppelin gewöhnt sind. Es ist eindeutig eine schlechte Idee, DevOps und Clusteradministratoren zu bitten, eine Reihe von Paketen auf Rechenknoten zu platzieren. Jeder, der selbst Erweiterungen für SparkML geschrieben hat, weiß, wie viele versteckte Schwierigkeiten es mit wichtigen Klassen und Methoden gibt (die aus irgendeinem Grund privat sind [ml]), Einschränkungen bei den Arten der gespeicherten Parameter usw.
Und mit der MMLSpark-Bibliothek scheint das Leben jetzt etwas einfacher zu sein, und der Schwellenwert für den Einstieg in skalierbares maschinelles Lernen mit SparkML und Scala ist etwas niedriger.
Einführung
Aufgrund einer Reihe von Schwierigkeiten sowie einer geringen Anzahl vorgefertigter Methoden und Lösungen in SparkML schreiben viele Unternehmen ihre Erweiterungen für Spark. Ein Beispiel ist PravdaML , das bei Odnoklassniki entwickelt wird und nach einer schnellen Einschätzung der Inhalte von GitHub sehr vielversprechend aussieht. Leider sind die meisten dieser Lösungen entweder geschlossen oder offen, aber sie können nicht über Maven / sbt und die API-Dokumentation installiert werden, was die Arbeit mit ihnen sehr schwierig macht.
Heute schauen wir uns die MMLSpark- Bibliothek an.
Wir werden wie üblich das Beispiel der Aufgabe betrachten, Passagiere der Titanic zu klassifizieren. Ziel ist es, möglichst viele Funktionen der MMLSpark-Bibliothek anzuzeigen, nicht Schalte SOTA auf ImageNet aus zeige cooles maschinelles Lernen. Also wird die Titanic reichen.

Die Bibliothek selbst verfügt über eine native API für Scala ( Dokumentation ), eine Python-API ( Dokumentation ) und wird nach einigen Stellen im GitHub-Repository bald eine API für R haben.
Es gibt gute Beispiel-Laptops im GitHub-Projekt (PySpark + Jupyter) , aber wir werden den anderen Weg gehen. Wie Dmitry Bugaychenko schrieb , haben Sie bei der Entwicklung für Spark allen Grund, Scala dafür zu verwenden. Darüber hinaus können Sie mit Scala Ihren eigenen Transformer und Estimator viel effizienter und flexibler definieren, um sie in die SparkML-Pipeline einzubetten, aber wie langsam numpy funktioniert / pandas Code in UDF (auf ausführbare Dateien von der JVM aufgerufen) wurde bereits viel geschrieben.
Installationsbeschreibung
Der gesamte Laptop ist hier verfügbar. Für die Arbeit mit der Titanic reicht das lokal auf einem Laptop mit Standardeinstellungen ausgeführte Zeppelin Docker-Image für die Augen aus. Docker finden Sie hier . Die MMLSpark-Bibliothek befindet sich nicht in Maven Central, sondern in Spark-Paketen. Um sie zu Zeppelin hinzuzufügen, müssen Sie den folgenden Block am Anfang des Laptops ausführen:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
Es ist erwähnenswert, dass die Bibliothek eine hervorragende Abwärtskompatibilität aufweist: Im Gegensatz zum XGBoost4j-spark, für den mindestens Spark 2.3+ erforderlich ist, wurde dieses Element in Spark 2.2.1 integriert, das mit dem Zeppelin Docker-Image geliefert wurde, und es gab keine Schwierigkeiten Ich habe es nicht bemerkt.
Hinweis: Der größte Teil der MMLSpark-Bibliothek ist der Inferenz von Gittern in einem Cluster gewidmet, für die CNTK vorhanden ist (das laut Dokumentation vorgefertigte cntk-Modelle lesen sollte) und einem riesigen OpenCV-Block. Wir werden uns auf alltäglichere Aufgaben konzentrieren und versuchen, den Fall zu „simulieren“, wenn wir riesige Arrays tabellarischer Daten haben, die in HDFS in Form von CSV, Tabellen oder in einem anderen Format vorliegen. Wir müssen sie also vorverarbeiten und ein Modell erstellen, während diese Daten nicht in den Speicher einer Maschine passen. Daher führen wir alle Aktionen im Cluster aus.
Lesen und Intelligenzanalyse
Im Allgemeinen ist Spark + Zeppelin überhaupt nicht schlecht und kann die EDA-Aufgabe bewältigen, aber wir werden versuchen, ihre Fähigkeiten zu erweitern. Zuerst importieren wir die Klassen, die wir brauchen:
- Alles von spark.sql.types, um ein Schema zu deklarieren und die Daten korrekt zu lesen
- Alles von spark.sql.functions, um auf Spalten zuzugreifen und integrierte Funktionen zu verwenden
- com.microsoft.ml.spark.SummarizeData , das als Analogon zu pandas.DataFrame.describe bezeichnet werden kann
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
Wir lesen unsere Datei:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
Und jetzt schauen wir uns die Daten selbst sowie ihre Größe an:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
Hinweis: Es ist wirklich nicht erforderlich, createOrReplaceTempView zu verwenden, wenn Sie nur .show (5) schreiben können. Aber show hat ein Problem: Wenn die Daten "breit" sind, "schwebt" die Textdarstellung der Platte, und es wird überhaupt nichts klar.
Holen Sie sich die Größe unserer Daten: Train shape is: 891 x 12
Und jetzt können wir uns in der SQL-Zelle die ersten 5 Zeilen ansehen:
%sql select * from trainHead
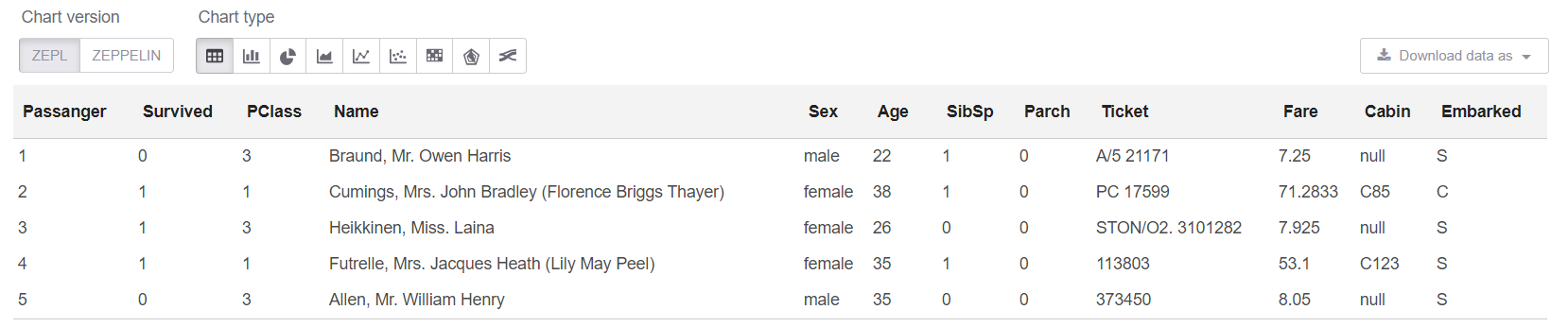
Nun, sehen wir uns die Zusammenfassung auf unserem Tisch an:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
Die SummarizeData-Klasse bietet gegenüber dem einfachen Dataset.describe mehrere Vorteile, da Sie die Anzahl fehlender und eindeutiger Werte zählen und die Genauigkeit der Berechnung von Quantilen festlegen können. Dies kann für wirklich große Datenmengen von entscheidender Bedeutung sein.

Einige persönliche GedankenIm Allgemeinen schien es mir persönlich, dass Odnoklassniki in PravdaML eine bessere Implementierung des SummarizeData-Analogons hatte. Microsoft ist den einfachen Weg org.apache.spark.sql.functions und verwendet org.apache.spark.sql.functions . Es ist nur so, dass alles bequem in einer einzigen Klasse zusammengefasst ist. Für Odnoklassniki wird dies über den VectorStatCollector implementiert, der beim Aufrufen etwas komplexeren Code erfordert (Sie müssen zuerst alle Features in einen Vektor VectorAssembler ) und möglicherweise zusätzliche Operationen erfordert (z. B. weigert sich VectorAssembler normalerweise, VectorAssembler zu DecimalType ). Aufgrund meiner Erfahrungen mit Spark gehe ich jedoch davon aus, dass SummarizeData aus MMLSpark mit Fehlern wie StackOverflow in org.apache.spark.sql.catalyst wenn wirklich viele Spalten vorhanden sind und das Berechnungsdiagramm zum Zeitpunkt des Starts nicht klein ist ( Obwohl speziell für solche Fans von "Extrem" in Spark 2.4 die Möglichkeit hinzugefügt wurde, den Catalyst Graph Optimizer zu reduzieren. Nun, es scheint, dass mit einer wirklich großen Anzahl von Spalten die Version von Microsoft langsamer sein wird. Dies muss aber natürlich separat geprüft werden.
Datenbereinigung
In der Titanic ist alles wie gewohnt - in einer Reihe von Zeichenfolgenspalten fehlen Werte. Und eine Art Überhöhung in den Daten (es scheint, dass diese bestimmte Version der Daten nicht sehr spezifisch ist) - 25 Zeilen von den fehlenden Werten entfernt. Beheben Sie zunächst Folgendes:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
String-Datenverarbeitung
Soweit ich mich erinnere, waren die Attribute, die aus den Feldern Name und Cabin stammen, die besten, die in der Titanic hervorgebracht wurden. Sie können sie viel liefern, aber wir beschränken uns auf einige wenige, um keine Beispiele für fast denselben Code zu nennen.
Normalerweise ist es zweckmäßig, für solche Dinge reguläre Ausdrücke zu verwenden.
Aber wir wollen in diesem Fall:
- alles wurde verteilt, die Daten wurden am selben Ort verarbeitet wie sie waren;
- Alles wurde als SpakrML Transformer- oder Spark ML Estimator-Klassen konzipiert, damit es später in Pipeline zusammengestellt werden kann.
Hinweis: Die Pipeline garantiert uns erstens, dass wir immer die gleichen Transformationen sowohl auf den Zug als auch auf den Test anwenden, und ermöglicht es uns, den Fehler des "Blicks in die Zukunft" bei der Kreuzvalidierung zu erkennen. Darüber hinaus erhalten wir einfache Funktionen zum Speichern, Laden und Vorhersagen mithilfe unserer Pipeline.
SparkML hat eine „fast universelle“ Klasse für solche Aufgaben - SQLTranformer , aber das Schreiben in SQL ist eindeutig schlechter als das Schreiben in Scala, schon allein deshalb, weil es möglich ist, Syntax oder typische Fehler beim Kompilieren und Hervorheben der Syntax in Idea zu erkennen. Und hier hilft uns MMLSpark, wo ein wirklich universeller UDFTransformer implementiert wird :
import com.microsoft.ml.spark.UDFTransformer
Zunächst werden wir unsere Transformationsfunktion erstellen, die bis zum Limit sehr einfach ist. Unser Ziel ist es nun, den Prozess der Erstellung von UDFTransformer aufzuzeigen. Im Prinzip kann jeder anhand solcher einfachen Beispiele jeder Komplexitätsebene Logik hinzufügen.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(Sie können sofort sehen, wie bequem Scala ist, mit fehlenden Werten zu arbeiten, die übrigens nicht nur null , sondern auch Double.NaN , aber es gibt so ein Witz so selten wie Auslassungen in BooleanType Variablen usw.)
UserDefinedFunction nun unsere UserDefinedFunction und erstellen UserDefinedFunction sofort einen darauf basierenden Transformer :
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
Hinweis: In einem Zeppelin-Laptop ist alles gleich, aber wenn alles später im Produktionscode zusammenkommt, ist es wichtig, dass sich alle UDFs in Klassen oder Objekten befinden, die extends Serializable . Die offensichtliche Sache, die Sie manchmal vergessen und dann für eine lange Zeit vertiefen können, ist, was falsch ist, wenn Sie die langen Stapelspuren von Spark-Fehlern lesen.
Jetzt haben wir noch das Cabin . Schauen wir es uns genauer an:

Wir sehen, dass viele Werte fehlen, Buchstaben, Zahlen, verschiedene Kombinationen usw. Nehmen wir die Anzahl der Kabinen (wenn mehr als eine) sowie die Anzahl - sie haben wahrscheinlich eine Art Logik, zum Beispiel, wenn die Nummerierung von einem Ende des Schiffes stammt, hatten die Kabinen am Bug weniger Chancen. Wir werden auch Funktionen erstellen und dann auf diesen UDFTransformer basieren:
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
Beginnen wir nun mit den fehlenden Werten, nämlich dem Alter. Lassen Sie uns zunächst die Visualisierungsfunktionen von Zeppelin nutzen:
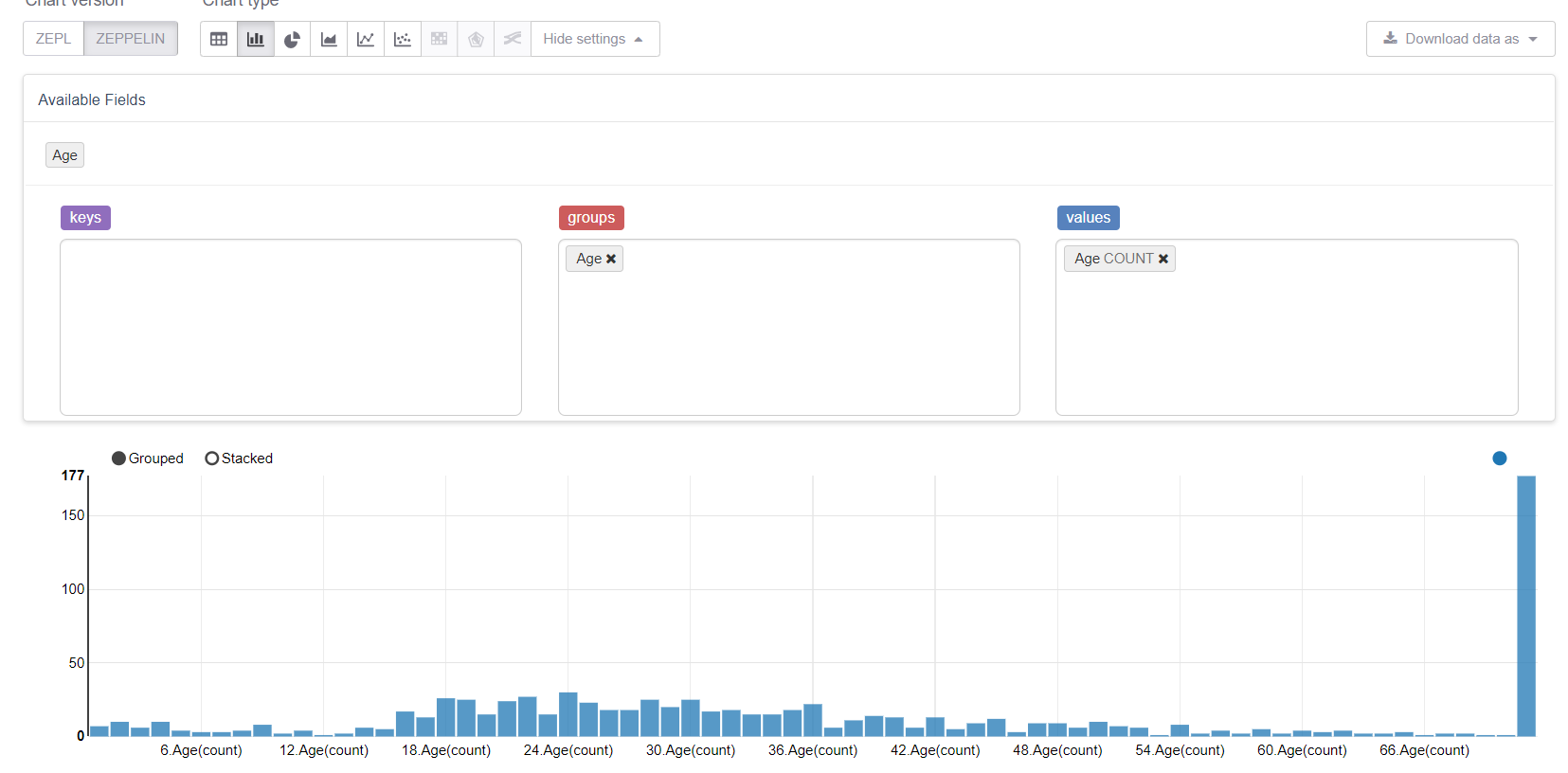
Und sehen Sie, wie fehlende Werte alles verderben. Es wäre logisch, sie durch eine Mitte (oder einen Median) zu ersetzen, aber unser Ziel ist es, alle Funktionen der MMLSpark-Bibliothek zu berücksichtigen. Daher werden wir unseren eigenen Estimator schreiben, der die Gruppen- / Durchschnittswerte der Trainingsstichprobe berücksichtigt und durch die entsprechenden Lücken ersetzt.
Wir werden brauchen:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
Achten wir auf ConstructorWritable , das das Leben erheblich vereinfacht. Wenn unser Model ein "trainiertes" Modell ist, das von der Methode fit(), wird und das vollständig vom Konstruktor bestimmt wird (und dies ist wahrscheinlich in 99% der Fälle der Fall), können wir die Serialisierung überhaupt nicht mit unseren Händen schreiben. Dies vereinfacht und beschleunigt die Entwicklung erheblich, beseitigt Fehler und senkt auch die Einstiegsschwelle für DataScientist und Analysten, die normalerweise keine professionellen Programmierer sind.
Definieren Sie unsere Estimator Klasse. In der Tat ist das Wichtigste hier die fit , der Rest sind technische Punkte:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
Hinweis: Ich habe defaultCopy nicht verwendet, da ich beim Aufruf aus irgendeinem Grund geschworen habe, keinen Konstruktor zu haben. \ <Init> (java.lang.String), obwohl dies anscheinend nicht hätte passieren dürfen. In jedem Fall ist die Implementierung der copy einfach.
Jetzt müssen Sie Model implementieren - eine Klasse, die das trainierte Modell beschreibt und die transform implementiert. Wir werden es basierend auf der in org.apache.spark.sql.functions coalesce Funktion org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
Das letzte Objekt, das wir deklarieren müssen, ist ein Reader , den wir mithilfe der MMLSpark ConstructorReadable- Klasse implementieren:
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
Pipeline-Erstellung
In Pipeline möchte ich sowohl die üblichen SparkML-Klassen als auch die unglaublich praktische Sache von MMLSpark - MultiColumnAdapter zeigen , mit der Sie SparkML-Transformatoren auf viele Spalten gleichzeitig anwenden können (als Referenz nehmen beispielsweise StringIndexer und OneHotEncoder genau eine Spalte zur Eingabe, wodurch sie umgedreht werden Anzeige bei Schmerzen):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
Zunächst erklären wir, welche Spalten wir haben:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
Erstellen Sie nun einen String-Encoder:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
Hinweis: Im Gegensatz zu Scikit-Learn in SparkML arbeitet StringIndexer nach dem Prinzip des Frequenzcodierers und kann verwendet werden, um eine Ordnungsbeziehung anzugeben (d. H. Kategorie 0 <Kategorie 1, und dies ist sinnvoll). Dieser Ansatz eignet sich häufig gut für entscheidende Bäume.
Imputer unseren Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
Und VectorAssembler , da SparkML-Klassifizierer mit VectorType komfortabler arbeiten:
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
Jetzt werden wir die mit MMLSpark - LightGBM gelieferte Gradientenverstärkung verwenden, die zusammen mit XGBoost und CatBoost in den "Big Three" der besten Implementierungen dieses Algorithmus enthalten ist. Es funktioniert um ein Vielfaches schneller, besser und stabiler als die GBM-Implementierung von SparkML (auch wenn der JVM-Port noch in der aktiven Entwicklung ist):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
Hinweis: LightGBM unterstützt das Arbeiten mit kategorialen Variablen (fast wie Catboost). Daher haben wir im Voraus angegeben, wo sich die Kategorieattribute in unserem Vektor befinden, und er selbst wird herausfinden, was mit ihnen zu tun ist und wie sie zu codieren sind.
Weitere Informationen zu LightGBM-Funktionen für Spark- Auf Knoten, auf denen RadHat LightGBM ausgeführt wird, stürzt jede Version außer der neuesten ab, da ihm die
glibc Version nicht gefällt . Dies wurde kürzlich behoben. Bei der Installation über Maven ruft MMLSpark bei der Installation über Maven die vorletzte Version von LightGBM ab, sodass Sie die Abhängigkeit der neuesten Version von RadHat mit Ihren Händen hinzufügen müssen. - LightGBM erstellt in seiner Arbeit einen Socket auf dem Treiber für die Kommunikation mit Führungskräften, und zwar unter Verwendung des
new java.net.ServerSocket(0) . Daher wird ein zufälliger Port von den kurzlebigen Ports des Betriebssystems verwendet. Wenn sich der Bereich der kurzlebigen Ports von dem Bereich der von der Firewall geöffneten Ports unterscheidet, dann kann viel brennen Sie können einen interessanten Effekt erzielen, wenn LightGBM manchmal funktioniert (wenn ich einen guten Port gewählt habe) und manchmal nicht. Und dort wird es Fehler wie ConnectionTimeOut , die beispielsweise auch auf die Option hinweisen, wenn GC an Führungskräften hängt oder so etwas. Wiederholen Sie meine Fehler im Allgemeinen nicht.
Nun, endlich erklären Sie unsere Pipeline:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
Schulung
Wir werden unser Trainingsset in einen Zug und einen Test aufteilen und unsere Pipeline überprüfen. Hier ist es nur möglich, den Komfort der Pipeline zu bewerten, da sie völlig unabhängig von der Partition ist und uns garantiert, dass wir dieselben Transformationen zum Trainieren und Testen anwenden und alle Transformationsparameter im Zug „gelernt“ werden:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
Zur bequemen Berechnung von Metriken verwenden wir eine andere Klasse aus MMLSpark - ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
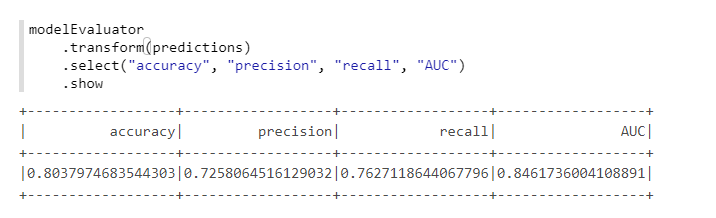
Nicht schlecht, da wir die Standardeinstellungen nicht geändert haben.
Auswahl von Hyperparametern
Um Hyperparameter in MMLSpark auszuwählen, gibt es eine separate coole Sache, TuneHyperparameters , die eine zufällige Suche im Raster implementiert. Leider wird Pipeline noch nicht unterstützt, sodass wir den üblichen SparkML CrossValidator :
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
Leider habe ich keinen bequemen Weg gefunden, wie Sie die Ergebnisse zusammen mit den Parametern sehen können, mit denen sie erhalten wurden. Daher ist es notwendig, "monströse" Designs zu verwenden:
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
Was uns so etwas gibt:
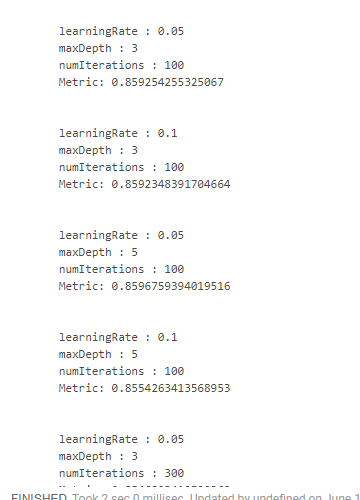
Wir haben das beste Ergebnis erzielt, indem wir die Lerngeschwindigkeit verringert und die Tiefe der Bäume erhöht haben. Auf dieser Basis wäre es möglich, den Suchraum anzupassen und ein noch optimaleres Ergebnis zu erzielen, aber wir haben einfach kein solches Ziel.
Fazit
Während MMLSpark Version 0.17 hat und immer noch separate Fehler enthält. Von allen Spark-Erweiterungen, die ich gesehen habe, verfügt MMLSpark meiner Meinung nach über die umfassendste Dokumentation und den verständlichsten Installations- und Implementierungsprozess. Microsoft hat es noch nicht wirklich beworben, es gab nur einen Bericht über die Databricks , aber dort ging es mehr um DeepLearning und nicht um solche routinemäßigen Dinge, über die ich geschrieben habe.
Persönlich hat diese Bibliothek bei unseren Aufgaben sehr geholfen, sodass ich ein wenig weniger durch den Dschungel der Spark-Quellen kommen und nicht mit Reflect auf private [ml] -Methoden zugreifen konnte, und ein Kollege fand die Bibliothek fast zufällig. Gleichzeitig wird aufgrund der Tatsache, dass sich die Bibliothek in der aktiven Entwicklung befindet, die Quelldateistruktur voller Brei etwas verwirrend. Nun, da es keine speziellen Beispiele oder andere Dokumentationen gibt (außer für nacktes Scaladoc), mussten wir zuerst ständig in den Quellcode kriechen.
Daher hoffe ich wirklich, dass dieses Mini-Tutorial (trotz all seiner Offensichtlichkeit und Einfachheit) für jemanden nützlich ist und dabei hilft, viel Zeit und Mühe zu sparen!