In diesem Artikel werden die Vorteile der Protokollierung erläutert. Ich werde über Protokolle auf PSR erzählen. Ich werde einige persönliche Empfehlungen zur Arbeit mit der Ebene, der Nachricht und dem Kontext des protokollierten Ereignisses hinzufügen. Es wird ein Beispiel gegeben, wie die Protokollierung und Überwachung mithilfe von ELK in einer in Laravel geschriebenen und in mehreren Fällen über Docker gestarteten Anwendung organisiert wird. Ich werde eine wichtige Regel des Warnsystems unterzeichnen. Ich werde ein Beispiel für ein Skript geben, das den gesamten Überwachungsstapel mit einem Befehl auslöst.
Die Vorteile der Protokollierung
Eine gut organisierte Protokollierung ermöglicht mindestens Folgendes:
- Zu wissen, dass etwas nicht wie beabsichtigt läuft (es gibt Fehler)
- Kennen Sie die Details des Fehlers, anhand derer Sie feststellen können, bei wem und wo der Fehler aufgetreten ist, und verhindern Sie eine Wiederholung
- Wisse, dass alles wie vorgesehen läuft (access.log, debug-, info-level)
Die Protokollierung selbst sagt Ihnen dies alles nicht, aber mithilfe der Protokolle können Sie die Details von Ereignissen unabhängig herausfinden oder ein Überwachungssystem für Protokolle konfigurieren, das Probleme melden kann. Wenn die Nachrichten in den Protokollen von einer ausreichenden Menge an Kontext begleitet werden, vereinfacht dies das Debuggen erheblich, da mehr Daten über die Situation verfügbar sind, in der das Ereignis aufgetreten ist.
Was zu schreiben und was zu schreiben
Ein Teil der PHP-Community hat Empfehlungen für einige Code-Schreibaufgaben entwickelt. Eine solche Empfehlung ist das PSR-3 Logger Interface . Es beschreibt nur, was Sie protokollieren müssen. Zu diesem Psr\Log\LoggerInterface des Pakets "psr / log" entwickelt. Wenn Sie es verwenden, müssen Sie die drei Komponenten des Ereignisses kennen:
- Level - Ereignisbedeutung
- Nachricht - Text, der das Ereignis beschreibt
- Kontext - Eine Reihe zusätzlicher Informationen zum Ereignis
PSR-3-Ereignisebenen
Die Ebenen stammen aus RFC 5424 - The Syslog Protocol. Ihre ungefähre Beschreibung lautet wie folgt:
- Debug - Details zum Debuggen
- info - Interessante Ereignisse
- Hinweis - Wesentliche Ereignisse, aber keine Fehler
- Warnung - Ausnahmefälle, aber keine Fehler
- Fehler - Ausführungsfehler, die keinen vorübergehenden Eingriff erfordern
- kritisch - Kritische Bedingungen (Systemkomponente ist nicht verfügbar, unerwartete Ausnahme)
- alert - Aktion erfordert sofortiges Eingreifen
- Notfall - Das System funktioniert nicht
Es gibt eine Beschreibung, die jedoch nicht immer leicht zu befolgen ist, da es schwierig ist, die Bedeutung bestimmter Ereignisse zu bestimmen. Im Kontext einer einzelnen Anforderung war es beispielsweise nicht möglich, auf die verbundene Ressource zuzugreifen. Bei der Aufzeichnung dieses Ereignisses wissen wir nicht, ob eine solche Anforderung fehlgeschlagen ist oder nur ein Benutzer fehlschlägt. Es hängt davon ab, ob ein sofortiges Eingreifen erforderlich ist oder ob dies ein seltener Fall ist, es kann warten oder sogar ignoriert werden. Solche Probleme werden im Rahmen der Überwachung von Protokollen gelöst. Sie müssen jedoch noch das Niveau bestimmen. Daher können die Protokollierungsstufen im Team vereinbart werden. Ein Beispiel:
- Notfall ist die Ebene für externe Systeme, die Ihr System überprüfen und sicherstellen können, dass es vollständig nicht funktioniert oder die Eigendiagnose nicht funktioniert.
- alert - Das System selbst kann seinen Status beispielsweise mit einer geplanten Aufgabe diagnostizieren und als Ergebnis ein Ereignis mit dieser Ebene aufzeichnen. Dies können Überprüfungen verbundener Ressourcen oder etwas Bestimmtes sein, z. B. ein Saldo auf dem Konto einer verwendeten externen Ressource.
- kritisch - ein Ereignis, bei dem ein Fehler eine Systemkomponente ergibt, die sehr wichtig ist und immer funktionieren sollte. Es hängt schon sehr davon ab, was das System macht. Geeignet für Ereignisse, die wichtig sind, um schnell herauszufinden, auch wenn es nur einmal passiert ist.
- Fehler - Es ist ein Ereignis aufgetreten, über das Sie bei baldiger Wiederholung Bericht erstatten müssen. Fehler beim Abschließen der Aktion, die ausgeführt werden muss, aber diese Aktion fällt nicht unter die Beschreibung von kritisch. Beispielsweise war es nicht möglich, das Profilbild eines Benutzers auf seine Anfrage hin zu speichern, aber das System ist kein Profilbilddienst, sondern ein Chat-System.
- Warnung - Ereignisse, für deren sofortige Benachrichtigung Sie über einen bestimmten Zeitraum eine erhebliche Anzahl von Ereignissen wählen müssen. Fehler beim Ausführen einer Aktion, deren Fehler nichts Ernstes bricht. Dies sind immer noch Fehler, deren Korrektur jedoch auf den Arbeitsplan warten kann. Beispielsweise konnte der Avatar des Benutzers nicht gespeichert werden, und das System war ein Online-Shop. Eine Benachrichtigung über sie ist (mit hoher Häufigkeit) erforderlich, um über plötzliche Anomalien informiert zu werden, da sie Symptome schwerwiegenderer Probleme sein können.
- Hinweis - Dies sind Ereignisse, die vom System bereitgestellte Abweichungen melden, die Teil der normalen Funktionsweise des Systems sind. Zum Beispiel hat der Benutzer am Eingang das falsche Passwort angegeben, der Benutzer hat den zweiten Vornamen nicht eingegeben, aber es ist nicht erforderlich, der Benutzer hat die Bestellung für 0 Rubel gekauft, dies wird jedoch in seltenen Fällen für Sie bereitgestellt. Eine Benachrichtigung mit hoher Frequenz ist ebenfalls erforderlich, da ein starker Anstieg der Anzahl der Abweichungen auf einen Fehler zurückzuführen sein kann, der dringend behoben werden muss.
- Info - Ereignisse, deren Auftreten die normale Funktionsweise des Systems meldet. Beispielsweise hat sich ein Benutzer registriert, ein Benutzer hat ein Produkt gekauft, ein Benutzer hat ein Feedback hinterlassen. Die Benachrichtigung für solche Ereignisse muss in umgekehrter Weise konfiguriert werden: Wenn über einen bestimmten Zeitraum nicht genügend solche Ereignisse aufgetreten sind, müssen Sie benachrichtigt werden, da deren Verringerung auf einen Fehler zurückzuführen sein kann.
- Debug - Ereignisse zum Debuggen eines Prozesses auf dem System. Wenn Sie dem Kontext des Ereignisses genügend Daten hinzufügen, können Sie das Problem diagnostizieren oder daraus schließen, dass der Prozess im System ordnungsgemäß funktioniert. Beispielsweise hat ein Benutzer eine Produktseite geöffnet und eine Liste mit Empfehlungen erhalten. Erhöht die Anzahl der gesendeten Ereignisse erheblich, sodass die Protokollierung solcher Ereignisse nach einer Weile entfernt werden kann. Infolgedessen ist die Anzahl solcher Ereignisse im normalen Betrieb variabel, und die Überwachung auf Benachrichtigung darüber kann weggelassen werden.
Ereignismeldung
Nach PSR-3 muss eine Nachricht entweder eine Zeichenfolge oder ein Objekt mit der Methode __toString() . Darüber hinaus kann die Nachrichtenzeile gemäß PSR-3 Platzhalter der Form ”User {username} created” , die durch Werte aus dem Kontextarray ersetzt werden können. Wenn Sie Elasticsearch und Kibana für die Überwachung verwenden, empfehle ich, keine Platzhalter zu verwenden, sondern feste Zeilen zu schreiben, da dies das Filtern von Ereignissen vereinfacht und der Kontext immer vorhanden ist. Darüber hinaus schlage ich vor, auf zusätzliche Anforderungen für die Nachricht zu achten:
- Der Text sollte kurz, aber aussagekräftig sein. Dies wird in Warnungen und in den Listen der aufgetretenen Ereignisse angezeigt.
- Der Text ist besser, um für verschiedene Teile des Programms eindeutig zu sein. Auf diese Weise können Sie anhand der Warnung, ohne in den Kontext zu schauen, nachvollziehen, in welchem Teil das Ereignis aufgetreten ist.
Ereigniskontext
Der Ereigniskontext für PSR-3 ist ein Array (möglicherweise verschachtelt) von Variablenwerten, z. B. Entitäts-IDs. Der Kontext kann leer gelassen werden, wenn die Nachricht über das Ereignis klar ist. getMessage() Sie eine Ausnahme protokollieren, sollten Sie die gesamte Ausnahme übergeben, nicht nur getMessage() . Bei Verwendung von Monolog über NormalizerFormatter werden nützliche Daten automatisch aus der Ausnahme extrahiert und dem Ereigniskontext hinzugefügt, einschließlich der Stapelverfolgung. Das heißt, Sie brauchen stattdessen
[ 'exception' => $exception->getMessage(), ]
zu verwenden
[ 'exception' => $exception, ]
In Laravel können Sie automatisch Daten für Ereignisse in Ereignisse eingeben. Dies kann über den globalen Protokollkontext (nur für erfolglose Ausnahmen oder über report() ) oder über LogFormatter (für alle Ereignisse) erfolgen. Normalerweise werden Informationen mit der ID des aktuellen Benutzers, der Anforderungs-URI, der IP, der Anforderungs-UUID und dergleichen hinzugefügt.
Denken Sie bei der Verwendung von Elasticsearch als Protokoll-Repository daran, dass feste Datentypen verwendet werden. Wenn Sie also customer_id im Kontext einer Nummer übergeben haben und versuchen, ein Ereignis mit einem anderen Typ zu speichern, z. B. einer Zeichenfolge (uuid), wird eine solche Nachricht nicht geschrieben. Typen im Index werden beim ersten Empfang des Werts festgelegt. Wenn jeden Tag Indizes erstellt werden, wird der neue Typ erst am nächsten Tag aufgezeichnet. Aber selbst dies wird nicht alle Probleme lösen, da für Kibana die Typen gemischt werden und einige der mit dem Typ verbundenen Operationen erst verfügbar sind, wenn gemischte Indizes vorhanden sind.
Um dieses Problem zu vermeiden, empfehle ich Ihnen, die folgenden Regeln zu befolgen:
- Verwenden Sie keine zu generischen Schlüsselnamen, die unterschiedlichen Typs sein können
- Führen Sie eine explizite Umwandlung in einen Werttyp durch, wenn Sie sich über den Typ nicht sicher sind
Beispiel: stattdessen
[ 'response' => $response->all(), 'customer_id' => $id, 'value' => $someValue, ]
zu verwenden
[ 'smsc_response_data' => json_encode($response->all()), 'customer_id' => (string) $customer_id, 'smsc_request_some_value' => (string) $someValue, ]
Aufruf eines Loggers aus dem Code
Um ein Ereignis schnell im Protokoll aufzuzeichnen, können Sie verschiedene Optionen auswählen. Betrachten wir einige davon.
- Deklarieren Sie das globale Funktionsprotokoll
log() und rufen Sie es aus verschiedenen Teilen des Programms auf. Dieser Ansatz hat viele Nachteile. In Klassen, in denen wir auf diese Funktion zugreifen, wird beispielsweise eine implizite Abhängigkeit gebildet. Dies sollte vermieden werden. Darüber hinaus ist ein solcher Logger schwer zu konfigurieren, wenn das System mehrere verschiedene haben muss. Ein weiterer Nachteil, wenn wir über die Arbeit mit Laravel sprechen, ist, dass wir die vom Framework bereitgestellten Funktionen nicht verwenden, um dieses Problem zu lösen. - Verwenden Sie Laravel Fassade \ Log. Bei diesem Ansatz hängen die Teile des Systems, die auf diese Fassade zugreifen, vom Rahmen ab. In Teilen des Systems, die wir nicht aus dem Framework entfernen werden, ist eine solche Lösung durchaus geeignet. Schreiben Sie beispielsweise von einigen Instanzen eines Konsolenbefehls, einer Hintergrundaufgabe oder eines Controllers. Oder wenn es bereits eine komplizierte Struktur von Diensten gibt und das Einwerfen einer Instanz eines Loggers in diese nicht so einfach ist.
- Lösen Sie die Logger-Abhängigkeit über die Helfer des Frameworks
app() und resolve() . Der Ansatz hat die gleichen Nachteile wie die Verwendung der Fassade, Sie müssen jedoch etwas mehr Code schreiben. - Geben Sie die Abhängigkeit vom Logger im Konstruktor der Klasse an, die dieser Logger verwenden wird. Gleichzeitig sollte dasselbe
LoggerInterface als Typ angegeben werden, um DIP zu erfüllen. Dank Autowiring-Frameworks werden Abhängigkeiten bei der Implementierung ihrer deklarierten Abstraktionen automatisch aufgelöst. In Laravel können einige Abhängigkeitsklassen in einer separaten Methode angegeben werden, anstatt im Konstruktor der gesamten Klasse angegeben zu werden.
Wo im Code, um den Logger aufzurufen
Bei der Organisation des Codes im Projekt kann sich die Frage stellen, in welcher Klasse ich in das Protokoll schreiben soll. Sollte es ein Service sein? Oder sollte dies dort erfolgen, wo der Dienst aufgerufen wird: Controller, Hintergrundaufgabe, Konsolenbefehl? Oder sollte jede Ausnahme entscheiden, was mit ihrer report (Laravel) in das Protokoll geschrieben werden soll? Es gibt keine einfache Antwort auf alle Fragen gleichzeitig.
Betrachten Sie die von Laravel gegebene Gelegenheit , die Aufgabe der Protokollierung selbst an die Ausnahmeklasse zu delegieren. Eine Ausnahme kann nicht wissen, wie wichtig es für das System ist, die Ebene eines Ereignisses zu bestimmen. Darüber hinaus hat eine Ausnahme keinen Zugriff auf den Kontext, es sei denn, sie wird beim Aufruf dieser Ausnahme speziell hinzugefügt. Um die render für eine Ausnahme aufzurufen, dürfen Sie entweder die Ausnahme nicht abfangen (der globale ErrorHandler wird verwendet) oder den globalen Helfer report() abfangen und verwenden. Mit dieser Methode können wir den PSR-3-Logger nicht jedes Mal aufrufen, wenn wir diese Ausnahme abfangen können. Aber ich denke nicht, dass es sich lohnt, der Ausnahme eine solche Verantwortung zu übertragen.
Es scheint, dass wir uns immer nur bei Diensten anmelden können. In der Tat können Sie in einigen Diensten die Protokollierung durchführen. Betrachten Sie jedoch einen Service, der nicht vom Projekt abhängt, und planen Sie im Allgemeinen, ihn in einem separaten Paket zusammenzufassen. Dann weiß dieser Dienst nicht, wie wichtig er für das Projekt ist, und kann daher den Protokollierungsgrad nicht bestimmen. Zum Beispiel ein Integrationsdienst mit einem bestimmten SMS-Gateway. Wenn wir einen Netzwerkfehler erhalten, bedeutet dies nicht, dass er ziemlich schwerwiegend ist. Möglicherweise verfügt das System über einen Integrationsdienst mit einem anderen SMS-Gateway, über den ein zweiter Sendeversuch ausgeführt wird. Dann kann der Fehler des ersten als Warnung und der Fehler des zweiten als Fehler gemeldet werden. Erst jetzt sollten alle diese Integrationen von einem anderen Dienst aufgerufen werden, der sich genau anmeldet. Es stellt sich heraus, dass der Fehler in einem Dienst liegt und wir uns in einem anderen anmelden. Aber manchmal haben wir keinen Service-Wrapper über einem anderen Service - wir rufen ihn direkt vom Controller aus auf. In diesem Fall halte ich es für zulässig, in das Protokoll in der Steuerung zu schreiben, anstatt einen Service-Dekorateur für die Protokollierung zu schreiben.
Ein Beispiel für die Verwendung von Abhängigkeit und das Übergeben von Kontext:
<?php namespace App\Console\Commands; use App\Services\ExampleService; use Illuminate\Console\Command; use Psr\Log\LoggerInterface; class Example extends Command { protected $signature = 'example'; public function handle(ExampleService $service, LoggerInterface $logger) { try { $service->example(); } catch (\Exception $exception) { $logger->critical('Example error', [ 'exception' => $exception, ]); } } }
Wo man schreibt
Betrachten Sie die folgenden Optionen.
- Gemäß der 12-Faktor-Anwendung und einigen anderen Empfehlungen müssen Sie in stdout, stderr der Anwendungslaufzeit schreiben. Dazu können Sie im Konfigurationslogger
php://stdout * angeben. - Ignorieren Sie den 12-Faktor-Docker und schreiben Sie in Dateien. Mit Laravel (Monolog) können Sie sogar die Protokollrotation konfigurieren. Weitere Nachrichten aus Dateien können mit Filebeat gesammelt und zur Analyse an Logstash gesendet werden.
- Senden Sie Protokolle von der Anwendung direkt weiter, z. B. über UDP, um die Leistung zu steigern.
- Lösungen kombinieren. Schreiben Sie in Dateien, die mit Filebeat gesammelt und an Logstash gesendet werden. Schreiben Sie in den Container stderr, um die
docker logs und Protokolle bequem aus der Container-Orchestrierungsumgebung erfassen zu können. In diesem Fall können Sie einige Kanäle nur lokal schreiben, andere über das Netzwerk senden.
* In php-fpm 7.2 erhalten wir beim Schreiben von Protokollen in stdout "WARNUNG: [pool www] Kind X hat in stdout gesagt ...", und lange Nachrichten werden abgeschnitten. Eine Lösung für dieses Problem ist hier . In php-fpm 7.3 gibt es kein solches Problem.
Optionen für das Aufnahmeformat:
- Vom Menschen lesbar (Zeilenumbrüche, Einrückungen usw.)
- Maschinenlesbar (normalerweise json)
- Beide Formate gleichzeitig: maschinenlesbar in stdout für weiteres Routing, lesbar bei plötzlichen Routingproblemen und schnellem Debugging
Bei jeder der Optionen wird davon ausgegangen, dass die Protokolle weitergeleitet werden. Zumindest werden sie aus folgenden Gründen an ein einzelnes Verarbeitungssystem (Speicher) von Protokollen gesendet:
- Langzeitspeicherung und Archivierung
- Große Trends
- Flexibles Ereignisbenachrichtigungssystem
Docker kann einen Protokollmanager angeben. Der Standardwert ist json-file , dh der Docker fügt die Ausgabe des Containers zur json-file auf dem Host hinzu. Wenn wir einen Protokollmanager auswählen, der Datensätze irgendwo über das Netzwerk sendet, können wir den docker logs nicht mehr verwenden. Wenn stdout / stderr des Containers als einziger Ort zum Aufzeichnen von Anwendungsprotokollen ausgewählt wurde, ist es bei Netzwerkproblemen oder Problemen mit einem einzelnen Repository möglicherweise nicht möglich, Einträge für das Debuggen schnell zu extrahieren.
Wir können json-file docker und Filebeat verwenden. Wir erhalten sowohl lokale Protokolle als auch weiteres Routing. Es ist erwähnenswert, dass hier ein weiteres Merkmal des Dockers ist. Wenn Sie ein Ereignis aufzeichnen, das länger als 16 KB ist, bricht der Docker den Datensatz mit dem Symbol \n , was viele Protokollsammler verwirrt. Hier gibt es ein Problem . Das Problem des Dockers konnte nicht gelöst werden, so dass es von den Sammlern gelöst wurde. In einigen Versionen unterstützt Filebeat dieses Docker-Verhalten und kombiniert Ereignisse korrekt.
Welche Kombination aller Möglichkeiten von Zielen und Aufnahmeformaten können Sie für Ihr Projekt selbst auswählen?
Verwenden von Filebeat + ELK + Elastalert
Kurz gesagt kann die Rolle jedes Dienstes wie folgt beschrieben werden:
- Filebeat - sammelt Ereignisse aus Dateien und sendet sie
- Logstash - analysiert Ereignisse und sendet
- Elasticsearch - speichert strukturierte Ereignisse
- Kibana - zeigt Ereignisse an (Grafiken, Aggregationen usw.)
- Elastalert - Sendet Warnungen basierend auf Anforderungen
Zusätzlich können Sie: zabbix, metricbeat, grafana und mehr.
Nun mehr zu jedem.
Filebeat
Sie können als separater Dienst auf dem Host ausgeführt werden. Sie können einen separaten Docker-Container verwenden. Um mit dem Ereignisstrom von Docker zu arbeiten, wird der /var/lib/docker/containers/*/*.log . Filebeat bietet eine Vielzahl von Optionen, mit denen Sie das Verhalten in verschiedenen Situationen festlegen können (die Datei wird umbenannt, die Datei wird gelöscht und dergleichen). Filebeat selbst kann json innerhalb des Ereignisses analysieren, aber nicht json kann auch in Ereignisse geraten, was zu einem Fehler führt. Die gesamte Ereignisverarbeitung erfolgt am besten an einem Ort.
Fragmentkonfiguration für Filebeat 6 filebeat.inputs: - type: docker containers: ids: - "*" processors: - add_docker_metadata: ~
Logstash
Kann Ereignisse aus vielen Quellen akzeptieren, aber hier betrachten wir Filebeat.
In jedem Ereignis gibt es neben dem Ereignis selbst von stdout / stderr Metadaten (Host, Container usw.). Es gibt viele integrierte Verarbeitungsfilter: Analysieren in regelmäßigen Abständen, Analysieren von JSON, Ändern, Hinzufügen, Löschen von Feldern usw. Geeignet zum Parsen von Anwendungsprotokollen und nginx access.log in einem beliebigen Format. Kann Daten in verschiedene Repositorys übertragen, aber hier betrachten wir Elasticsearch.
Konfigurationsfragment des Logstash-Filters if [status] { date { match => ["timestamp_nginx_access", "dd/MMM/yyyy:HH:mm:ss Z"] target => "timestamp_nginx" remove_field => ["timestamp_nginx_access"] } mutate { convert => { "bytes_sent" => "integer" "body_bytes_sent" => "integer" "request_length" => "integer" "request_time" => "float" "upstream_response_time" => "float" "upstream_connect_time" => "float" "upstream_header_time" => "float" "status" => "integer" "upstream_status" => "integer" } remove_field => [ "message" ] rename => { "@timestamp" => "event_timestamp" "timestamp_nginx" => "@timestamp" } } }
Elasticsearch
Elasticsearch ist ein sehr leistungsfähiges Tool für eine Vielzahl von Aufgaben, kann jedoch zur Überwachung von Protokollen nur mit einem bestimmten Minimum verwendet werden.
Gespeicherte Ereignisse sind ein Dokument, Dokumente werden in Indizes gespeichert.
Jeder Index ist ein Schema, in dem für jedes Feld des Dokuments ein Typ definiert ist. Sie können ein Ereignis nicht im Index speichern, wenn mindestens ein Feld den falschen Typ hat.
Mit verschiedenen Typen können Sie verschiedene Vorgänge für eine Gruppe von Dokumenten ausführen (für Zahlen - Summe, Min, Max, Durchschnitt usw., für Zeichenfolgen - Fuzzy-Suche usw.).
Für Protokolle empfiehlt das Management normalerweise die Verwendung von Tagesindizes - jeden Tag einen neuen Index.
Die Gewährleistung eines stabilen Betriebs von Elasticsearch mit zunehmendem Datenvolumen ist eine Aufgabe, die tiefere Kenntnisse über dieses Tool erfordert. Eine schnelle Lösung für das Stabilitätsproblem besteht jedoch darin, veraltete Daten automatisch zu löschen. Zu diesem Zweck empfehle ich, die Ereignisebenen in logstash auf verschiedene Indizes aufzuteilen. Dadurch können seltene, aber wichtigere Ereignisse länger gespeichert werden.
Logstash-Ausgabekonfigurations-Snippet output { if [fields][log_type] == "app_log" { if [level] in ["DEBUG", "INFO", "NOTICE"] { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-debug-%{+YYYY.MM.dd}" } } else { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-error-%{+YYYY.MM.dd}" } } } }
Um veraltete Indizes automatisch zu entfernen, empfehle ich die Verwendung eines Programms von Elastic Curator . Der Start des Programms wird dem Cron-Zeitplan hinzugefügt. Die Konfiguration selbst kann in einer separaten Datei gespeichert werden.
Ein Fragment der Konfiguration zum Entfernen veralteter Indizes action: delete_indices description: logstash-app-log-error options: ignore_empty_list: True filters: - filtertype: pattern kind: prefix value: logstash-app-log-error- - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: months unit_count: 6
, Filebeat Logstash, . Elasticsearch -- , , .
Kibana
Kibana . -, Elasticsearch. .
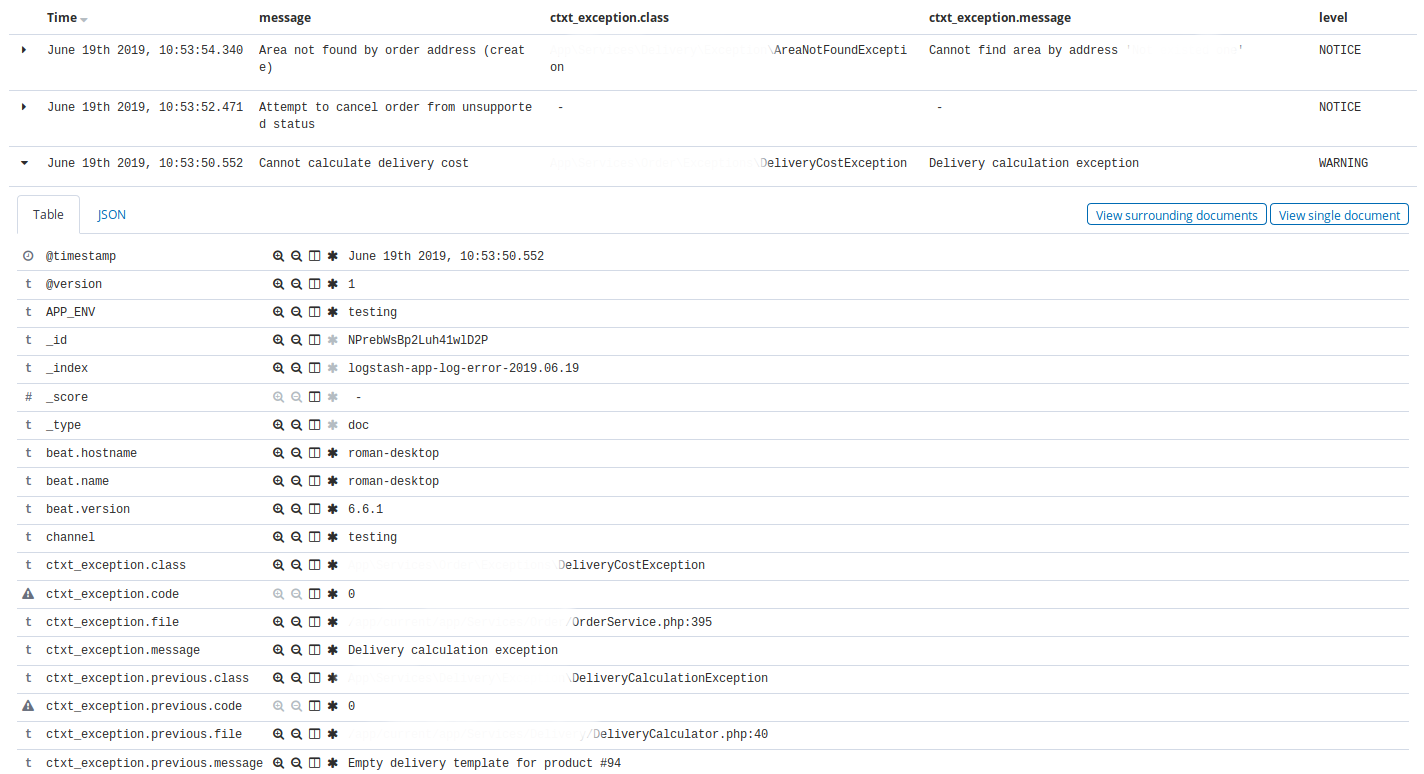
Kibana — Discovery . , Discovery app warning , time, message, exception class, host, client_id.
, Discovery nginx, 404 time, message, request, status.
Kibana , : , , . , ( ).
Elastalert
Elastalert Elasticsearch . , . , .
, (), .
:
- ALERT, EMERGENCY. — 10
- CRITICAL. — 30
- , N X M
- 10 INFO 3
- nginx 200, 201, 304 75% , 50
name: Blacklist ALERT, EMERGENCY type: blacklist index: logstash-app-* compare_key: "level" blacklist: - "ALERT" - "EMERGENCY" realert: minutes: 5 alert: - "slack"
— . , , . Kibana.
, , http- 75% , , , , . - , , , .
, , , , Kibana, .
5 . , , , , , .
, . .
Kibana . .
docker-. , , staging- production-, .
, Elastalert, . Elastalert ,
envsubst < /opt/elastalert/config.dist.yaml > /opt/elastalert/config.yaml entrypoint- , .
, , , .
Makefile build: docker build -t some-registry/elasticsearch elasticsearch docker build -t some-registry/logstash logstash docker build -t some-registry/kibana kibana docker build -t some-registry/nginx nginx docker build -t some-registry/curator curator docker build -t some-registry/elastalert elastalert push: docker push some-registry/elasticsearch docker push some-registry/logstash docker push some-registry/kibana docker push some-registry/nginx docker push some-registry/curator docker push some-registry/elastalert pull: docker pull some-registry/elasticsearch docker pull some-registry/logstash docker pull some-registry/kibana docker pull some-registry/nginx docker pull some-registry/curator docker pull some-registry/elastalert prepare: docker network create -d bridge elk-network || echo "ok" stop: docker rm -f kibana || true docker rm -f logstash || true docker rm -f elasticsearch || true docker rm -f nginx || true docker rm -f elastalert || true run-logstash: docker rm -f logstash || echo "ok" docker run -d --restart=always --network=elk-network --name=logstash -p 127.0.0.1:5001:5001 -e "LS_JAVA_OPTS=-Xms256m -Xmx256m" -e "ES_HOST=elasticsearch:9200" some-registry/logstash run-kibana: docker rm -f kibana || echo "ok" docker run -d --restart=always --network=elk-network --name=kibana -p 127.0.0.1:5601:5601 --mount source=elk-kibana,target=/usr/share/kibana/optimize some-registry/kibana run-elasticsearch: docker rm -f elasticsearch || echo "ok" docker run -d --restart=always --network=elk-network --name=elasticsearch -e "ES_JAVA_OPTS=-Xms1g -Xmx1g" --mount source=elk-esdata,target=/usr/share/elasticsearch/data some-registry/elasticsearch run-nginx: docker rm -f nginx || echo "ok" docker run -d --restart=always --network=elk-network --name=nginx -p 80:80 -v /root/elk/.htpasswd:/etc/nginx/.htpasswd some-registry/nginx run-elastalert: docker rm -f elastalert || echo "ok" docker run -d --restart=always --network=elk-network --name=elastalert --env-file=./elastalert/.env some-registry/elastalert run: prepare run-elasticsearch run-kibana run-logstash run-elastalert delete-old-indices: docker run --rm --network=elk-network -e "ES_HOST=elasticsearch:9200" some-registry/curator curator --config /curator/curator.yml /curator/actions.yml
:
- 80 nginx, basic auth Kibana
- Logstash . ssh-
- nginx
- , docker-
- , .env- nginx-
- *_JAVA_OPTS , 4GB RAM ( ES).
, xpack-.
docker-compose. , , Dockerfile-, Filebeat, Logstash, , , , , VCS.
. . , ( Laravel scheduler), , 5 . ALERT. , . , , .
Fazit
, , , . . , - . . , , .