
Die moderne Entwicklergemeinschaft ist heute mehr denn je Mode und Trends ausgesetzt, und dies gilt insbesondere für die Welt der Front-End-Entwicklung. Unsere Rahmenbedingungen und neuen Praktiken sind der Hauptwert, und die meisten Lebensläufe, offenen Stellen und Konferenzprogramme bestehen darin, sie aufzulisten. Und obwohl die Entwicklung von Ideen und Werkzeugen an sich nicht negativ ist, vergaßen wir aufgrund des ständigen Wunsches der Entwickler, schwer fassbaren Trends zu folgen, die Bedeutung des allgemeinen theoretischen Wissens über die Anwendungsarchitektur.
Die Prävalenz des Optimierungswerts gegenüber dem Wissen über Theorie und Best Practices hat dazu geführt, dass die meisten neuen Projekte heutzutage einen äußerst geringen Wartungsaufwand aufweisen, was für Entwickler (die konstant hohe Komplexität beim Studieren und Ändern des Codes) und für Kunden (niedrige Raten und) erhebliche Unannehmlichkeiten mit sich bringt hohe Entwicklungskosten).
Um die aktuelle Situation zumindest irgendwie zu beeinflussen, möchte ich Ihnen heute sagen, was eine gute Architektur ist, wie sie auf Webschnittstellen anwendbar ist und vor allem, wie sie sich im Laufe der Zeit entwickelt.
NB : Als Beispiele im Artikel werden nur die Frameworks verwendet, mit denen sich der Autor direkt befasst hat, und React and Redux wird hier besondere Aufmerksamkeit geschenkt. Trotzdem sind viele der hier beschriebenen Ideen und Prinzipien allgemeiner Natur und können mehr oder weniger erfolgreich auf andere Schnittstellenentwicklungstechnologien projiziert werden.Architektur für Dummies
Lassen Sie uns zunächst den Begriff selbst behandeln. Mit einfachen Worten, die Architektur eines Systems ist die Definition seiner Komponenten und das Schema der Interaktion zwischen ihnen. Dies ist eine Art konzeptionelle Grundlage, auf der später die Implementierung aufgebaut wird.
Die Aufgabe der Architektur besteht darin, die externen Anforderungen an das entworfene System zu erfüllen. Diese Anforderungen variieren von Projekt zu Projekt und können sehr spezifisch sein. Im Allgemeinen sollen sie jedoch die Modifizierungs- und Erweiterungsprozesse für entwickelte Lösungen erleichtern.
Die Qualität der Architektur wird normalerweise in den folgenden Eigenschaften ausgedrückt:
-
Begleitfähigkeit : Die bereits erwähnte Veranlagung des Systems zum Studieren und Ändern (die Schwierigkeit, Fehler zu erkennen und zu korrigieren, die Funktionalität zu erweitern, die Lösung an eine andere Umgebung oder Bedingungen anzupassen).
-
Austauschbarkeit : Die Fähigkeit, die Implementierung eines beliebigen Elements des Systems zu ändern, ohne andere Elemente zu beeinflussen
-
Testbarkeit : die Fähigkeit, den korrekten Betrieb des Elements zu überprüfen (die Fähigkeit, das Element zu steuern und seinen Zustand zu beobachten)
-
Portabilität : Die Fähigkeit, ein Element in anderen Systemen wiederzuverwenden
- Benutzerfreundlichkeit: Der allgemeine Komfort des Systems beim Betrieb durch den Endbenutzer
Separat wird auch eines der Schlüsselprinzipien für den Aufbau einer Qualitätsarchitektur erwähnt: das Prinzip der
Trennung von Anliegen . Es besteht darin, dass jedes Element des Systems ausschließlich für eine einzelne Aufgabe verantwortlich sein sollte (im Übrigen auf den Anwendungscode angewendet: siehe
Prinzip der Einzelverantwortung ).
Nachdem wir nun eine Vorstellung vom Konzept der Architektur haben, wollen wir sehen, welche architektonischen Entwurfsmuster uns im Kontext von Schnittstellen bieten können.
Die drei wichtigsten Wörter
Eines der bekanntesten Muster der Schnittstellenentwicklung ist MVC (Model-View-Controller), dessen Schlüsselkonzept darin besteht, die Schnittstellenlogik in drei separate Teile zu unterteilen:
1.
Modell - ist für den Empfang, die Speicherung und die Verarbeitung von Daten verantwortlich
2.
Ansicht - verantwortlich für die Datenvisualisierung
3.
Controller - steuert Modell und Ansicht
Dieses Muster enthält auch eine Beschreibung des Interaktionsschemas zwischen ihnen, aber hier werden diese Informationen weggelassen, da der Öffentlichkeit nach einer bestimmten Zeit eine verbesserte Modifikation dieses Musters namens MVP (Model-View-Presenter) präsentiert wurde, die dieses ursprüngliche Schema darstellt Interaktion stark vereinfacht:
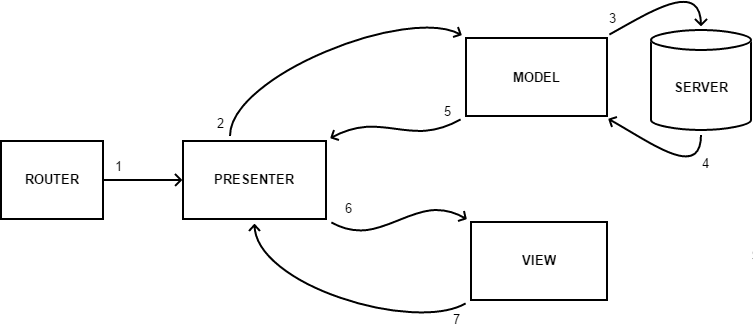
Da es sich speziell um Webschnittstellen handelt, haben wir ein weiteres ziemlich wichtiges Element verwendet, das normalerweise mit der Implementierung dieser Muster einhergeht - einen Router. Seine Aufgabe ist es, die URL zu lesen und die damit verbundenen Moderatoren anzurufen.
Das obige Schema funktioniert wie folgt:
1. Der Router liest die URL und ruft den zugehörigen Presenter auf
2-5. Der Präsentator wendet sich an Model und erhält die erforderlichen Daten daraus.
6. Presenter überträgt Daten vom Modell in die Ansicht, wodurch die Visualisierung implementiert wird.
7. Während der Benutzerinteraktion mit der Benutzeroberfläche benachrichtigt View Presenter darüber, wodurch wir zum zweiten Punkt zurückkehren
Wie die Praxis gezeigt hat, sind MVC und MVP keine ideale und universelle Architektur, aber sie tun dennoch eine sehr wichtige Sache - sie weisen auf drei Hauptverantwortungsbereiche hin, ohne die keine Schnittstelle in der einen oder anderen Form implementiert werden kann.
NB: Im Großen und Ganzen bedeuten die Konzepte von Controller und Presenter dasselbe, und der Unterschied in ihrem Namen ist nur erforderlich, um die genannten Muster zu unterscheiden, die sich nur in der Implementierung der Kommunikation unterscheiden .MVC- und Server-Rendering
Trotz der Tatsache, dass MVC ein Muster für die Implementierung eines Clients ist, findet es seine Anwendung auch auf dem Server. Darüber hinaus ist es im Kontext des Servers am einfachsten, die Funktionsprinzipien zu demonstrieren.
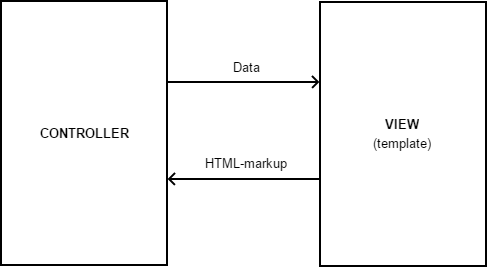
In Fällen, in denen es sich um klassische Informationsseiten handelt, bei denen die Aufgabe des Webservers darin besteht, HTML-Seiten für den Benutzer zu generieren, können wir mit MVC auch eine recht präzise Anwendungsarchitektur organisieren:
- Der Router liest die Daten aus der empfangenen HTTP-Anfrage
(GET / Benutzerprofil / 1) und ruft den zugehörigen Controller
(UsersController.getProfilePage (1)) auf.- Der Controller ruft das Modell auf, um die erforderlichen Informationen aus der Datenbank
abzurufen (UsersModel.get (1)).- Der Controller übergibt die empfangenen Daten an View
(View.render ('Benutzer / Profil', Benutzer)) und empfängt von ihm ein HTML-Markup, das sie an den Client zurückgibt
In diesem Fall wird View normalerweise wie folgt implementiert:
const templates = { 'users/profile': ` <div class="user-profile"> <h2>{{ name}}</h2> <p>E-mail: {{ email }}</p> <p> Projects: {{#each projects}} <a href="/projects/{{id}}">{{name}}</a> {{/each}} </p> <a href=/user-profile/1/edit>Edit</a> </div> ` }; class View { render(templateName, data) { const htmlMarkup = TemplateEngine.render(templates[templateName], data); return htmlMarkup; } }
NB: Der obige Code wurde absichtlich als Beispiel vereinfacht. In realen Projekten werden Vorlagen in separaten Dateien herausgenommen und durchlaufen vor der Verwendung die Kompilierungsphase (siehe Handlebars.compile () oder _.template () ).Hier werden die sogenannten Template-Engines verwendet, die uns Werkzeuge zur bequemen Beschreibung von Textvorlagen und Mechanismen zum Ersetzen realer Daten in diesen zur Verfügung stellen.
Ein solcher Ansatz zur Implementierung von View zeigt nicht nur eine ideale Aufgabentrennung, sondern bietet auch ein hohes Maß an Testbarkeit: Um die Richtigkeit der Anzeige zu überprüfen, reicht es aus, die Referenzlinie mit der Linie zu vergleichen, die wir von der Template-Engine erhalten haben.
Mit MVC erhalten wir somit eine nahezu perfekte Architektur, bei der jedes seiner Elemente einen ganz bestimmten Zweck, minimale Konnektivität sowie ein hohes Maß an Testbarkeit und Portabilität aufweist.
Der Ansatz zur Generierung von HTML-Markups mithilfe von Server-Tools wurde aufgrund der geringen UX allmählich durch SPA ersetzt.
Backbone und MVP
Eines der ersten Frameworks, das die Anzeigelogik vollständig auf den Client brachte, war
Backbone.js . Die Implementierung von Router, Presenter und Model ist ziemlich Standard, aber die neue Implementierung von View verdient unsere Aufmerksamkeit:

const UserProfile = Backbone.View.extend({ tagName: 'div', className: 'user-profile', events: { 'click .button.edit': 'openEditDialog', }, openEditDialog: function(event) {
Offensichtlich ist die Implementierung des Mappings viel komplizierter geworden - das Abhören von Ereignissen aus dem Modell und dem DOM sowie die Logik ihrer Verarbeitung wurden zur elementaren Standardisierung hinzugefügt. Um Änderungen in der Benutzeroberfläche anzuzeigen, ist es außerdem äußerst wünschenswert, View nicht vollständig neu zu rendern, sondern feinere Arbeiten mit bestimmten DOM-Elementen (normalerweise unter Verwendung von jQuery) durchzuführen, für die viel zusätzlicher Code geschrieben werden musste.
Aufgrund der allgemeinen Komplikation der View-Implementierung wurde das Testen komplizierter. Da wir jetzt direkt mit dem DOM-Baum arbeiten, müssen wir zum Testen zusätzliche Tools verwenden, die die Browserumgebung bereitstellen oder emulieren.
Und die Probleme mit der neuen View-Implementierung endeten nicht dort:
Darüber hinaus ist es ziemlich schwierig, ineinander verschachtelte Ansichten zu verwenden. Im Laufe der Zeit wurde dieses Problem mithilfe von
Regionen in
Marionette.js behoben.
Zuvor mussten Entwickler jedoch ihre eigenen Tricks erfinden, um dieses recht einfache und häufig auftretende Problem zu lösen.
Und der letzte. Die auf diese Weise entworfenen Schnittstellen waren für nicht synchronisierte Daten prädisponiert. Da alle Modelle auf der Ebene verschiedener Präsentatoren isoliert existierten, wurden sie beim Ändern von Daten in einem Teil der Schnittstelle normalerweise nicht in einem anderen aktualisiert.
Trotz dieser Probleme erwies sich dieser Ansatz als mehr als praktikabel, und die zuvor erwähnte Entwicklung von Backbone in Form von
Marionette kann weiterhin erfolgreich zur Entwicklung von SPA eingesetzt werden.
Reagieren und ungültig machen
Es ist kaum zu glauben, aber zum Zeitpunkt der ersten Veröffentlichung sorgte
React.js in der Entwicklergemeinde für große Skepsis. Diese Skepsis war so groß, dass lange Zeit folgender Text auf der offiziellen Website veröffentlicht wurde:
Gib es fünf Minuten
Reagieren fordert eine Menge konventioneller Weisheit heraus, und auf den ersten Blick mögen einige der Ideen verrückt erscheinen.
Und dies trotz der Tatsache, dass React im Gegensatz zu den meisten Mitbewerbern und Vorgängern kein vollwertiges Framework war und nur eine kleine Bibliothek, um die Anzeige von Daten im DOM zu erleichtern:
React ist eine JavaScript-Bibliothek zum Erstellen von Benutzeroberflächen über Facebook und Instagram. Viele Leute denken an React als das V in MVC.
Das Hauptkonzept, das React uns bietet, ist das Konzept einer Komponente, die uns tatsächlich eine neue Möglichkeit bietet, View zu implementieren:
class User extends React.Component { handleEdit() {
Die Reaktion war unglaublich angenehm zu bedienen. Zu seinen unbestreitbaren Vorteilen gehörten bis heute:
1)
Erklärung und Reaktivität . Das DOM muss beim Ändern der angezeigten Daten nicht mehr manuell aktualisiert werden.
2)
Die Zusammensetzung der Komponenten . Das Erstellen und Erkunden des Ansichtsbaums ist zu einer völlig elementaren Aktion geworden.
Leider hat React eine Reihe von Problemen. Eines der wichtigsten ist die Tatsache, dass React kein vollwertiges Framework ist und uns daher weder eine Anwendungsarchitektur noch vollwertige Tools für dessen Implementierung bietet.
Warum ist dies in Fehler geschrieben? Ja, da React jetzt die beliebteste Lösung für die Entwicklung von Webanwendungen ist (
Proof , ein
weiterer Proof und ein weiterer Proof ), ist es ein Einstiegspunkt für neue Front-End-Entwickler, bietet aber gleichzeitig keine an oder bewirbt keine Architektur, noch irgendwelche Ansätze und Best Practices zum Erstellen vollständiger Anwendungen. Darüber hinaus erfindet und fördert er seine eigenen Ansätze wie
HOC oder
Hooks , die außerhalb des React-Ökosystems nicht verwendet werden. Infolgedessen löst jede React-Anwendung typische Probleme auf ihre eigene Weise und führt dies normalerweise nicht auf die korrekteste Weise aus.
Dieses Problem kann mithilfe eines der häufigsten Fehler von React-Entwicklern demonstriert werden, der im Missbrauch von Komponenten besteht:
Wenn das einzige Werkzeug, das Sie haben, ein Hammer ist, sieht alles wie ein Nagel aus.
Mit ihrer Hilfe lösen Entwickler eine völlig undenkbare Reihe von Aufgaben, die weit über den Rahmen der Datenvisualisierung hinausgehen. Tatsächlich implementieren sie mit Hilfe von Komponenten absolut alles - von
Medienabfragen von CSS bis zum
Routing .
Reagieren und reduzieren
Die Wiederherstellung der Ordnung in der Struktur von React-Anwendungen wurde durch das Erscheinen und die Popularisierung von
Redux erheblich erleichtert. Wenn React eine Ansicht von MVP ist, hat uns Redux eine recht praktische Variante des Modells angeboten.
Die Hauptidee von Redux ist die Übertragung von Daten und die Logik der Arbeit mit ihnen in einem einzigen zentralen Data Warehouse - dem sogenannten Store. Dieser Ansatz löst das Problem der Datenverdoppelung und -desynchronisierung, über das wir etwas früher gesprochen haben, vollständig und bietet auch viele andere Annehmlichkeiten, zu denen unter anderem die einfache Untersuchung des aktuellen Status der Daten in der Anwendung gehört.
Ein weiteres ebenso wichtiges Merkmal ist die Art der Kommunikation zwischen dem Store und anderen Teilen der Anwendung. Anstatt direkt auf den Store oder seine Daten zuzugreifen, wird uns angeboten, die sogenannten Aktionen (einfache Objekte, die das Ereignis oder den Befehl beschreiben) zu verwenden, die eine schwache
lose Kopplung zwischen dem Store und der Ereignisquelle bieten und dadurch den Grad der Projektwartbarkeit erheblich erhöhen. Auf diese Weise zwingt Redux Entwickler nicht nur dazu, korrektere Architekturansätze zu verwenden, sondern ermöglicht es Ihnen auch, verschiedene Vorteile der
Ereignisbeschaffung zu nutzen. Jetzt können wir im Debugging-Prozess den Verlauf von Aktionen in der Anwendung, ihre Auswirkungen auf die Daten und bei Bedarf alle diese Informationen exportieren Dies ist auch äußerst nützlich bei der Analyse von Produktionsfehlern.
Das allgemeine Schema der Anwendung unter Verwendung von React / Redux kann wie folgt dargestellt werden:
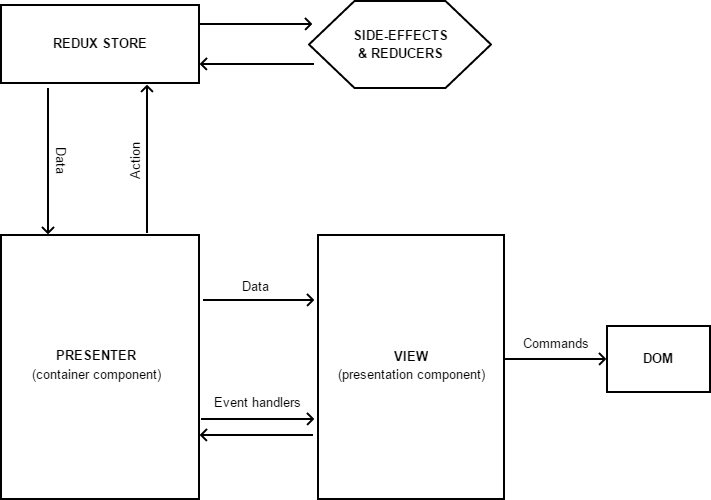
Reaktionskomponenten sind weiterhin für die Anzeige von Daten verantwortlich. Im Idealfall sollten diese Komponenten sauber und funktionsfähig sein. Falls erforderlich, können sie jedoch einen lokalen Status und eine zugehörige Logik aufweisen (z. B. um das Ausblenden / Anzeigen eines bestimmten Elements oder die grundlegende Vorverarbeitung einer Benutzeraktion zu implementieren).
Wenn ein Benutzer eine Aktion in der Schnittstelle ausführt, ruft die Komponente einfach die entsprechende Handlerfunktion auf, die sie von außen zusammen mit den anzuzeigenden Daten empfängt.
Sogenannte Containerkomponenten fungieren für uns als Presenter - sie üben die Kontrolle über die Anzeigekomponenten und deren Interaktion mit den Daten aus. Sie werden mithilfe der
Verbindungsfunktion erstellt , die die Funktionalität der an sie übergebenen Komponente erweitert, ein Abonnement zum Ändern von Daten im Store hinzufügt und es uns ermöglicht, zu bestimmen, welche Daten- und Ereignishandler an diese übergeben werden sollen.
Und wenn mit den Daten hier alles klar ist (wir ordnen einfach Daten aus dem Speicher den erwarteten „Requisiten“ zu), möchte ich näher auf die Ereignishandler eingehen - sie senden nicht nur Aktionen an den Store, sondern enthalten möglicherweise zusätzliche Logik für die Verarbeitung des Ereignisses - Schließen Sie beispielsweise Verzweigungen ein, führen Sie automatische Weiterleitungen durch und führen Sie alle anderen für den Präsentator spezifischen Arbeiten aus.
Ein weiterer wichtiger Punkt in Bezug auf Containerkomponenten: Aufgrund der Tatsache, dass sie über das HOC erstellt werden, beschreiben Entwickler häufig Anzeigekomponenten und Containerkomponenten innerhalb eines einzelnen Moduls und exportieren nur den Container. Dies ist nicht der richtige Ansatz, da die Anzeigekomponente zum Testen und Wiederverwenden vollständig vom Container getrennt und vorzugsweise in einer separaten Datei entfernt werden sollte.
Nun, das Letzte, was wir noch nicht in Betracht gezogen haben, ist der Store. Es dient uns als eine ziemlich spezifische Implementierung des Modells und besteht aus mehreren Komponenten: State (ein Objekt, das alle unsere Daten enthält), Middleware (eine Reihe von Funktionen, die alle empfangenen Aktionen vorverarbeiten), Reducer (eine Funktion, die Daten im State ändert) und einige oder ein Handler für Nebenwirkungen, der für die Ausführung asynchroner Vorgänge (Zugriff auf externe Systeme usw.) verantwortlich ist.
Das häufigste Problem hierbei ist die Form unseres Staates. Formal legt Redux uns keine Einschränkungen auf und gibt keine Empfehlungen, wie dieses Objekt aussehen soll. Entwickler können absolut alle Daten darin speichern (einschließlich des
Status von Formularen und
Informationen vom Router ). Diese Daten können von beliebigem Typ sein (es ist
nicht verboten , auch Funktionen und Instanzen von Objekten zu speichern) und haben eine beliebige Verschachtelungsebene. Tatsächlich führt dies wiederum dazu, dass wir von Projekt zu Projekt einen völlig anderen Ansatz für die Verwendung von State verfolgen, was wiederum einige Verwirrung stiftet.
Zunächst sind wir uns einig, dass wir nicht unbedingt alle Anwendungsdaten im Status halten müssen - dies wird in
der Dokumentation deutlich
angegeben . Obwohl das Speichern eines Teils der Daten im Status von Komponenten bestimmte Unannehmlichkeiten beim Navigieren durch den Verlauf von Aktionen während des Debug-Prozesses verursacht (der interne Status von Komponenten bleibt immer unverändert), führt die Übertragung dieser Daten in den Status zu noch größeren Schwierigkeiten - dies erhöht die Größe erheblich und erfordert die Erstellung von noch mehr Aktionen und Reduzierungen.
Beim Speichern anderer lokaler Daten in State handelt es sich normalerweise um eine allgemeine Schnittstellenkonfiguration, bei der es sich um eine Reihe von Schlüssel-Wert-Paaren handelt. In diesem Fall können wir leicht mit einem einfachen Objekt und einem Reduzierer dafür arbeiten.
Und wenn es um das Speichern von Daten aus externen Quellen geht, dann ist es aufgrund der Tatsache, dass es sich bei der Entwicklung von Schnittstellen in den allermeisten Fällen um klassische CRUD handelt, sinnvoll, State als RDBMS zu behandeln: Schlüssel sind der Name Ressource und dahinter befinden sich Arrays geladener Objekte (
ohne Verschachtelung ) und optionale Informationen (z. B. die Gesamtzahl der Datensätze auf dem Server, um eine Paginierung zu erstellen). Die allgemeine Form dieser Daten sollte so einheitlich wie möglich sein. Auf diese Weise können wir die Erstellung von Reduzierungen für jeden Ressourcentyp vereinfachen:
const getModelReducer = modelName => (models = [], action) => { const isModelAction = modelActionTypes.includes(action.type); if (isModelAction && action.modelName === modelName) { switch (action.type) { case 'ADD_MODELS': return collection.add(action.models, models); case 'CHANGE_MODEL': return collection.change(action.model, models); case 'REMOVE_MODEL': return collection.remove(action.model, models); case 'RESET_STATE': return []; } } return models; };
Ein weiterer Punkt, den ich im Zusammenhang mit der Verwendung von Redux diskutieren möchte, ist die Implementierung von Nebenwirkungen.
Vergessen Sie zunächst vollständig
Redux Thunk - die Umwandlung der von ihm vorgeschlagenen Aktionen in Funktionen mit Nebenwirkungen, obwohl es sich um eine funktionierende Lösung handelt, die jedoch die Grundkonzepte unserer Architektur vermischt und ihre Vorteile auf nichts reduziert.
Redux Saga bietet uns einen viel korrekteren Ansatz für die Implementierung von Nebenwirkungen, obwohl es einige Fragen bezüglich der technischen Implementierung gibt.
Weiter - versuchen Sie, Ihre Nebenwirkungen, die auf den Server zugreifen, so weit wie möglich zu vereinheitlichen. Wie die Statusform und Reduzierungen können wir fast immer die Logik implementieren, Anforderungen an den Server mit einem einzigen Handler zu erstellen. Im Fall der RESTful-API kann dies beispielsweise durch Abhören verallgemeinerter Aktionen wie:
{ type: 'CREATE_MODEL', payload: { model: 'reviews', attributes: { title: '...', text: '...' } } }
... und die gleichen verallgemeinerten HTTP-Anforderungen für sie erstellen:
POST /api/reviews { title: '...', text: '...' }
Wenn Sie alle oben genannten Tipps bewusst befolgen, erhalten Sie, wenn nicht sogar eine ideale Architektur, diese zumindest in der Nähe.
Glänzende Zukunft
Die moderne Entwicklung von Webschnittstellen hat wirklich einen bedeutenden Schritt nach vorne gemacht, und jetzt leben wir in einer Zeit, in der ein wesentlicher Teil der Hauptprobleme bereits auf die eine oder andere Weise gelöst wurde. Dies bedeutet jedoch keineswegs, dass in Zukunft keine neuen Revolutionen stattfinden werden.
Wenn Sie versuchen, in die Zukunft zu schauen, werden wir höchstwahrscheinlich Folgendes sehen:
1. Komponentenansatz ohne JSXDas Konzept der Komponenten hat sich als äußerst erfolgreich erwiesen, und wir werden höchstwahrscheinlich eine noch stärkere Popularisierung sehen. Aber JSX selbst kann und muss sterben. Ja, es ist wirklich sehr praktisch zu verwenden, aber es ist weder ein allgemein akzeptierter Standard noch ein gültiger JS-Code. Bibliotheken zur Implementierung von Schnittstellen, egal wie gut sie sind, sollten keine neuen Standards erfinden, die dann in jedem möglichen Entwicklungs-Toolkit immer wieder implementiert werden müssen.
2. Behälter ohne Redux angebenDie von Redux vorgeschlagene Verwendung eines zentralen Data Warehouse war ebenfalls eine äußerst erfolgreiche Lösung und sollte in Zukunft zu einer Art Standard bei der Entwicklung von Schnittstellen werden. Die interne Architektur und Implementierung kann jedoch bestimmten Änderungen und Vereinfachungen unterliegen.
3. Verbesserung der Austauschbarkeit von BibliothekenIch glaube, dass die Front-End-Entwicklergemeinde im Laufe der Zeit die Vorteile der Maximierung der Austauschbarkeit von Bibliotheken erkennen und sich nicht mehr in ihren kleinen Ökosystemen einschließen wird. Alle Komponenten von Anwendungen - Router, Statuscontainer usw. - sollten äußerst universell sein, und ihr Austausch sollte kein Massen-Refactoring oder Umschreiben der Anwendung von Grund auf erfordern.
Warum das alles?
Wenn wir versuchen, die oben dargestellten Informationen zu verallgemeinern und auf eine einfachere und kürzere Form zu reduzieren, erhalten wir einige ziemlich allgemeine Punkte:
- Für eine erfolgreiche Anwendungsentwicklung reichen Kenntnisse der Sprache und des Frameworks nicht aus. Allgemeine theoretische Aspekte sollten beachtet werden: Anwendungsarchitektur, Best Practices und Entwurfsmuster.
"Die einzige Konstante ist Veränderung." Die Ansätze für Bodenbearbeitung und Entwicklung werden sich weiter ändern, daher müssen große und langlebige Projekte der Architektur angemessene Aufmerksamkeit widmen. Ohne sie wird die Einführung neuer Werkzeuge und Praktiken äußerst schwierig sein.
Und das ist wahrscheinlich alles für mich. Vielen Dank an alle, die die Kraft gefunden haben, den Artikel bis zum Ende zu lesen. Wenn Sie Fragen oder Kommentare haben, lade ich Sie ein, Kommentare abzugeben.