
Vor einiger Zeit haben wir Agentless Monitoring und Alarme dafür durchgeführt. Dies ist ein Analogon zu CloudWatch in AWS mit einer kompatiblen API. Jetzt arbeiten wir an Balancern und automatischer Skalierung. Obwohl wir einen solchen Service nicht anbieten, bieten wir unseren Kunden an, dies selbst zu tun, indem wir unsere Überwachung und Tags (AWS Resource Tagging API) als einfache Serviceerkennung als Datenquelle verwenden. Wir werden in diesem Beitrag zeigen, wie das geht.
Ein Beispiel für eine minimale Infrastruktur eines einfachen Webdienstes: DNS -> 2 Balancer -> 2 Backend. Diese Infrastruktur kann als das Minimum angesehen werden, das für einen fehlertoleranten Betrieb und eine fehlertolerante Wartung erforderlich ist. Aus diesem Grund werden wir diese Infrastruktur nicht noch mehr „komprimieren“, sodass beispielsweise nur ein Backend übrig bleibt. Aber ich möchte die Anzahl der Backend-Server erhöhen und auf zwei reduzieren. Dies wird unsere Aufgabe sein. Alle Beispiele sind im Repository verfügbar.
Basisinfrastruktur
Wir werden uns nicht im Detail mit der Konfiguration der oben genannten Infrastruktur befassen, sondern nur zeigen, wie sie erstellt wird. Wir bevorzugen die Bereitstellung der Infrastruktur mit Terraform. Es hilft, schnell alles zu erstellen, was Sie benötigen (VPC, Subnetz, Sicherheitsgruppe, VMs) und diesen Vorgang immer wieder zu wiederholen.
Skript zum Erhöhen der Basisinfrastruktur:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
Alle in dieser Konfiguration beschriebenen Entitäten sollten anscheinend vom Durchschnittsbenutzer moderner Clouds verstanden werden. Für unsere Cloud und für eine bestimmte Aufgabe spezifische Variablen werden in eine separate Datei verschoben - terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
Starten Sie Terraform:
Terraform anwenden yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
Überwachungssetup
Die oben gestarteten VMs werden automatisch von unserer Cloud überwacht. Diese Überwachungsdaten werden die Informationsquelle für die zukünftige automatische Skalierung sein. Wenn wir uns auf bestimmte Metriken stützen, können wir die Leistung erhöhen oder verringern.
Durch die Überwachung in unserer Cloud können Sie Alarme unter verschiedenen Bedingungen für verschiedene Metriken konfigurieren. Es ist sehr bequem. Wir müssen die Metriken in keinem Intervall analysieren und eine Entscheidung treffen - dies erfolgt durch Cloud-Überwachung. In diesem Beispiel werden Alarme für CPU-Metriken verwendet. In unserer Überwachung können sie jedoch auch für folgende Metriken konfiguriert werden: Netzwerkauslastung (Geschwindigkeit / pps), Festplattenauslastung (Geschwindigkeit / iops).
Cloudwatch Put-Metric-Alarm export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
Beschreibung einiger Parameter, die möglicherweise unverständlich sind:
--profile - aws-cli-Einstellungsprofil, beschrieben in ~ / .aws / config. In der Regel werden unterschiedliche Zugriffsschlüssel in unterschiedlichen Profilen festgelegt.
--dimensions - Der Parameter bestimmt, für welche Ressource der Alarm im obigen Beispiel erstellt wird - für die Instanz mit dem Bezeichner aus der Variablen $ instance_id.
--namespace - Namespace, aus dem die Überwachungsmetrik ausgewählt wird.
--metric-name - Der Name der Überwachungsmetrik.
--statistic - Der Name der Metrikwertaggregationsmethode.
--period - Zeitintervall zwischen Überwachungswerterfassungsereignissen.
- Bewertungszeiträume - Die Anzahl der Intervalle, die zum Auslösen eines Alarms erforderlich sind.
--threshold - metrischer Schwellenwert zur Beurteilung des Alarmzustands.
--comparison-operator - Eine Methode, mit der der Wert einer Metrik relativ zu einem Schwellenwert bewertet wird.
Im obigen Beispiel werden zwei Alarme für jede Backend-Instanz erstellt. Scaling-low- <Instanz-ID> wechselt in den Alarmzustand, wenn die CPU 3 Minuten lang weniger als 15% lädt. Scaling-high- <Instanz-ID> wechselt in den Alarmzustand, wenn die CPU 3 Minuten lang mehr als 80% lädt.
Tag-Anpassung
Nach dem Einrichten der Überwachung stehen wir vor der folgenden Aufgabe: der Ermittlung von Instanzen und ihren Namen (Serviceerkennung). Wir müssen irgendwie verstehen, wie viele Backend-Instanzen wir jetzt gestartet haben, und wir müssen auch deren Namen kennen. In einer Welt außerhalb der Cloud eignen sich beispielsweise Konsul und Konsulvorlage gut zum Generieren einer Balancer-Konfiguration. Aber es gibt Tags in unserer Cloud. Tags helfen uns, Ressourcen zu kategorisieren. Indem wir Informationen für ein bestimmtes Tag (Beschreibungs-Tags) anfordern, können wir verstehen, wie viele Instanzen wir derzeit im Pool haben und welche ID sie haben. Standardmäßig wird eine eindeutige Instanz-ID als Hostname verwendet. Dank des internen DNS in der VPC werden diese IDs / Hostnamen in die internen IP-Instanzen aufgelöst.
Wir setzen Tags für Backend-Instanzen und Balancer:
ec2 create-tags export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
Wo:
--resources - Eine Liste der Ressourcenkennungen, auf die Tags gesetzt werden.
--tags ist eine Liste von Schlüssel-Wert-Paaren.
Ein Beispiel für Beschreibungs-Tags finden Sie in der CROC Cloud- Dokumentation .
Setup für die automatische Skalierung
Jetzt, da die Cloud überwacht und wir wissen, wie man mit Tags arbeitet, können wir nur den Status der konfigurierten Alarme auf deren Auslösung abfragen. Hier benötigen wir eine Entität, die sich mit der regelmäßigen Überwachung und dem Starten von Aufgaben zum Erstellen / Löschen von Instanzen befasst. Hier können verschiedene Automatisierungswerkzeuge angewendet werden. Wir werden AWX verwenden. AWX ist eine Open-Source-Version des kommerziellen Ansible Tower , einem Produkt zur zentralen Verwaltung der Ansible-Infrastruktur. Die Hauptaufgabe besteht darin, unser ansibles Spielbuch regelmäßig zu starten.
Ein Beispiel für eine AWX-Bereitstellung finden Sie auf der Wiki- Seite im offiziellen Repository. Die AWX-Konfiguration wird auch in der Ansible Tower-Dokumentation beschrieben. Damit AWX benutzerdefinierte Playbooks ausführen kann, müssen Sie es konfigurieren, indem Sie die folgenden Entitäten erstellen:
- Drei Arten von Berechtigungen:
- AWS-Anmeldeinformationen - zum Autorisieren von Vorgängen im Zusammenhang mit der CROC Cloud.
- Anmeldeinformationen des Computers - SSH-Schlüssel für den Zugriff auf neu erstellte Instanzen.
- SCM-Anmeldeinformationen - zur Autorisierung im Versionskontrollsystem. - Project ist eine Entität, die das Git-Repository aus dem Playbook entfernt.
- Skripte - dynamisches Inventarskript für ansible.
- Inventar ist eine Entität, die das dynamische Inventarskript aufruft, bevor das Playbook gestartet wird.
- Vorlage - Die Konfiguration eines bestimmten Playbook-Aufrufs besteht aus einer Reihe von Anmeldeinformationen, Inventar und Playbook aus Project.
- Workflow - eine Folge von Aufrufen von Playbooks.
Der automatische Skalierungsprozess kann in zwei Teile unterteilt werden:
- scale_up - Erstellt eine Instanz, wenn mindestens ein hoher Alarm ausgelöst wird.
- scale_down - Beendigung einer Instanz, wenn ein niedriger Alarm für sie funktioniert hat.
Im Rahmen des Teils scale_up benötigen Sie:
- Fragen Sie den Cloud-Überwachungsdienst nach dem Vorhandensein hoher Alarme im Status "Alarm" ab.
- Stoppen Sie scale_up vorzeitig, wenn sich alle hohen Alarme im Status "OK" befinden.
- Erstellen Sie eine neue Instanz mit den erforderlichen Attributen (Tag, Subnetz, Sicherheitsgruppe usw.).
- Erstellen Sie hohe und niedrige Alarme für eine laufende Instanz.
- Konfigurieren Sie unsere Anwendung in einer neuen Instanz (in unserem Fall ist es nur Nginx mit einer Testseite).
- Aktualisieren Sie die Haproxy-Konfiguration und laden Sie sie neu, damit die Anforderungen an die neue Instanz gesendet werden.
create-instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
In create-instance.yaml geschieht Folgendes: Erstellen einer Instanz mit den richtigen Parametern, Kennzeichnen dieser Instanz und Erstellen der erforderlichen Alarme. Das Nginx-Installations- und Konfigurationsskript wird auch über Benutzerdaten übergeben. Benutzerdaten werden vom Cloud-Init-Dienst verarbeitet, der eine flexible Konfiguration der Instanz während des Startvorgangs ermöglicht, ohne auf andere Automatisierungstools zurückgreifen zu müssen.
In update-lb.yaml wird die Datei /etc/haproxy/haproxy.cfg auf der Haproxy-Instanz neu erstellt und der Haproxy-Dienst neu geladen:
update-lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
Wobei haproxy.cfg.j2 die Vorlage für die Konfigurationsdatei des Haproxy-Dienstes ist:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
Da die Option httpchk im Backend-Abschnitt der Haproxy-Konfiguration definiert ist, fragt der Haproxy-Dienst unabhängig den Status von Backend-Instanzen ab und gleicht den Datenverkehr nur zwischen früheren Integritätsprüfungen aus.
Im scale_down-Teil benötigen Sie:
- Status niedrig Alarm prüfen;
- Beenden Sie das Spiel vorzeitig, wenn im Status "Alarm" keine niedrigen Alarme vorliegen.
- Beenden Sie alle Instanzen, für die ein niedriger Alarm in der Alarmklasse liegt.
- die Beendigung des letzten Instanzpaares verbieten, auch wenn sich ihre Alarme im Alarmzustand befinden;
- Entfernen Sie die Instanzen, die wir aus der Load Balancer-Konfiguration entfernt haben.
destroy-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
In destroy-instance.yaml werden die Alarme gelöscht, die Instanz und ihr Tag werden beendet und die Bedingungen, die das Beenden der letzten Instanzen verbieten, werden überprüft.
Wir löschen Tags explizit nach dem Löschen von Instanzen, da nach dem Löschen einer Instanz die damit verbundenen Tags verschoben gelöscht werden und für eine weitere Minute verfügbar sind.
AWX
Aufgaben, Vorlagen festlegen
Mit den folgenden Aufgaben werden die erforderlichen Entitäten in AWX erstellt:
awx-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
Das vorherige Snippet erstellt eine Vorlage für jedes der verwendeten Ansible-Playbooks. Jede Vorlage konfiguriert den Start eines Playbooks mit einer Reihe definierter Anmeldeinformationen und Inventar.
Das Erstellen einer Pipe für Aufrufe von Playbooks ermöglicht die Workflow-Vorlage. Das Einrichten des Workflows für die automatische Skalierung wird nachfolgend dargestellt:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
Die vorherige Vorlage zeigt das Workflow-Diagramm, d.h. Reihenfolge der Vorlagenausführung. In diesem Workflow wird jeder nächste Schritt (success_nodes) nur ausgeführt, wenn der vorherige erfolgreich abgeschlossen wurde. Eine grafische Darstellung des Workflows ist in der Abbildung dargestellt:
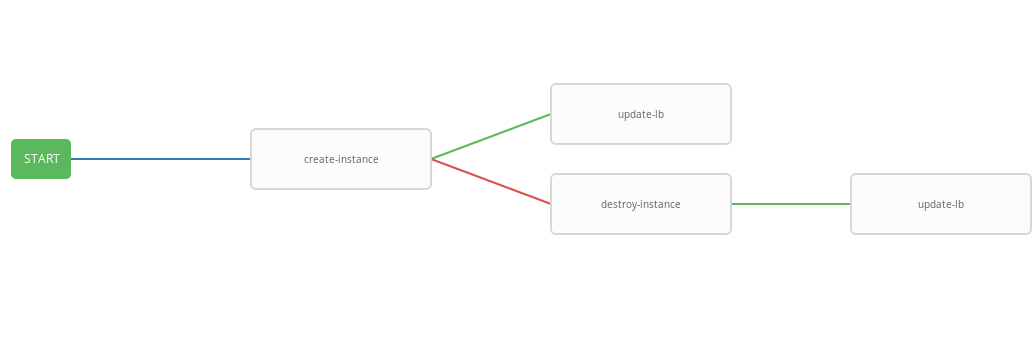
Als Ergebnis wurde ein verallgemeinerter Workflow erstellt, der das Playbook "create-instace" ausführt und je nach Ausführungsstatus die Playbooks "destroy-instance" und / oder "update-lb" ausführt. Der integrierte Workflow kann bequem nach einem bestimmten Zeitplan ausgeführt werden. Der automatische Skalierungsprozess startet alle drei Minuten und startet und beendet Instanzen je nach Alarmstatus.
Arbeitstests
Überprüfen Sie nun den Betrieb des konfigurierten Systems. Installieren Sie zunächst das Dienstprogramm wrk für das http-Benchmarking.
wrk installieren ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
Wir werden die Cloud-Überwachung verwenden, um die Verwendung von Instanzressourcen während des Ladens zu überwachen:
Überwachung function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
Das vorherige Skript erfasst alle 60 Sekunden einmalig den Durchschnittswert der CPUUtilization-Metrik für die letzte Minute und fragt den Status von Alarmen für Backend-Instanzen ab.
Jetzt können Sie wrk ausführen und die Auslastung der Ressourcen der Backend-Instanzen unter Last überprüfen:
wrk laufen ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
Der letzte Befehl startet den Benchmark für 500 Sekunden, verwendet 12 Threads und öffnet 100 http-Verbindungen.
Im Laufe der Zeit sollte das Überwachungsskript zeigen, dass während des Benchmarks der statistische Wert der CPUUtilization-Metrik steigt, bis er 300% erreicht. 180 Sekunden nach dem Start des Benchmarks sollte das StateValue-Flag in den Alarmstatus wechseln. Alle zwei Minuten wird der automatische Skalierungsworkflow gestartet. Standardmäßig ist die parallele Ausführung desselben Workflows verboten. Das heißt, alle zwei Minuten wird eine Aufgabe zum Ausführen eines Workflows zur Warteschlange hinzugefügt und erst nach Abschluss der vorherigen Aufgabe gestartet. Während der Arbeit von wrk werden daher die Ressourcen ständig erhöht, bis die hohen Alarme aller Backend-Instanzen in den OK-Zustand versetzt werden. Nach Abschluss beendet der Workflow wrk scale_down alle bis auf zwei Backend-Instanzen.
Beispielausgabe eines Überwachungsskripts:
Überwachungsergebnisse # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
Auch in der CROC Cloud können Sie die im Überwachungsbeitrag verwendeten Diagramme auf der Instanzseite auf der entsprechenden Registerkarte anzeigen.
Das Anzeigen von Alarmen ist auf der Überwachungsseite auf der Registerkarte Alarme verfügbar.
Fazit
Die automatische Skalierung ist ein recht beliebtes Szenario, befindet sich jedoch leider noch nicht in unserer Cloud (aber nur für den Moment). Wir haben jedoch viele leistungsstarke APIs, um ähnliche und viele andere Aufgaben zu erledigen. Dabei werden beliebte, fast standardmäßige Tools wie Terraform, ansible, aws-cli und andere verwendet.