Die Wahl eines Ortes für eine neue Niederlassung ist eine verantwortungsvolle Entscheidung. Fehler können insbesondere in kapitalintensiven Branchen teuer sein. Meistens werden solche Entscheidungen von Managementexperten getroffen: basierend auf Kenntnissen der Stadt, der Branche und früheren Erfahrungen.
In diesem Artikel werde ich darüber sprechen, wie Analytics bei solchen Entscheidungen helfen kann. So sammeln Sie Informationen über die Bevölkerung, Immobilienpreise und machen interaktive Visualisierungen. Hängt die Anzahl der Kunden von der Entfernung zur Filiale, dem Baujahr des Hauses und dem Wert der Immobilie ab?
Stadtbevölkerung genau zu Hause

Code zum Erstellen einer Karte Um die Bevölkerung des Hauses zu beurteilen, haben wir die Daten
der Reform des Wohnungsbaus und der kommunalen Dienstleistungen verwendet . Auf diesem Portal erhalten Sie Informationen zu jedem Haus: Baujahr, Wohnbereich, Anzahl der Wohnräume. Die Bevölkerungsschätzung jedes Hauses basierte auf der Anzahl der Wohnungen und der gesamten Wohnfläche: durchschnittlich etwa 3 Personen pro Wohnung mit geringfügigen Unterschieden für einige Häuser und Stadtbezirke.
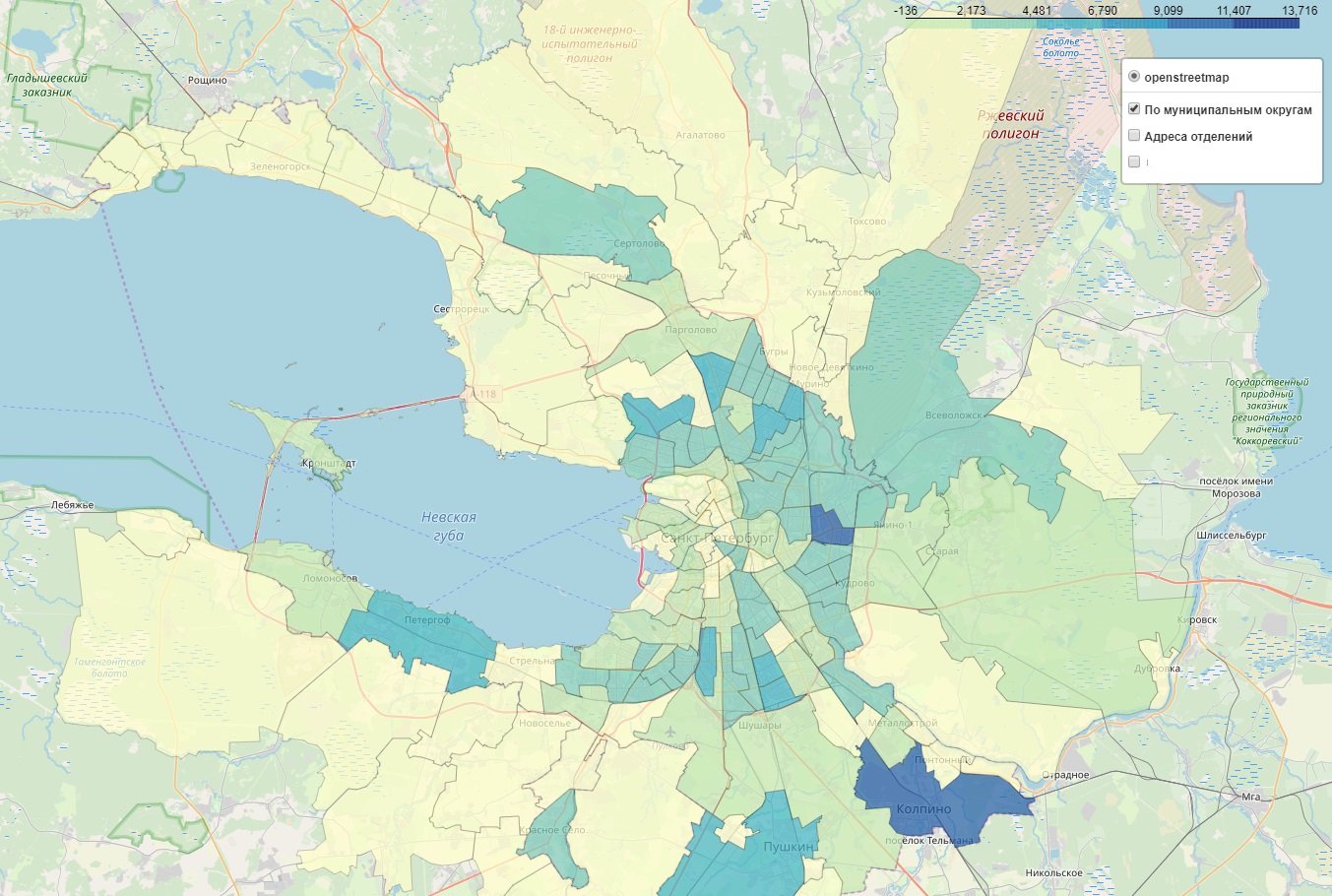
Oben ist eine Wärmekarte mit Bevölkerungsdichte in St. Petersburg. Unsere Karte für den internen Gebrauch enthält auch eine separate Schicht mit der Kundendichte. Es ist bequemer, nach weißen Flecken zu suchen - Orten mit geringer Abdeckung.
Kundenadressen
Aufgrund der Besonderheiten des Geschäfts hatten wir Adressen für fast alle Kunden in unserer Datenbank. Es war nur erforderlich, die geografischen Koordinaten für jede Adresse zu finden: Geokodierung oder Geokodierung. Um die Koordinaten zu erhalten, habe ich das Geocoder-Paket für Python verwendet. Die folgenden Probleme traten während der Geokodierung auf:
- Einige Adressen sind falsch, z. B. ist der Fall oder der Brief verwirrt. In dieser Situation kann die Geokodierung den Kunden in einen Kindergarten oder ein Bürogebäude „bringen“. In solchen Fällen musste ich einen Prozess schreiben, bei dem die Koordinaten innerhalb von 200 m zum nächsten Wohngebäude geändert wurden.
- Punkte mit einer ungewöhnlich hohen Anzahl von Kunden: Stadtzentrum, mitten in einer großen Straße, mitten im Bezirk. Solche Koordinaten wurden mit einer falsch ausgefüllten Adresse erhalten und konnten das Gesamtbild verzerren. Daher wurden sie vor der Modellierung gelöscht
Als Ergebnis haben wir für 93% der Kunden die genauen Koordinaten des Hauses erhalten. Jetzt können Sie eine solche Karte erstellen:
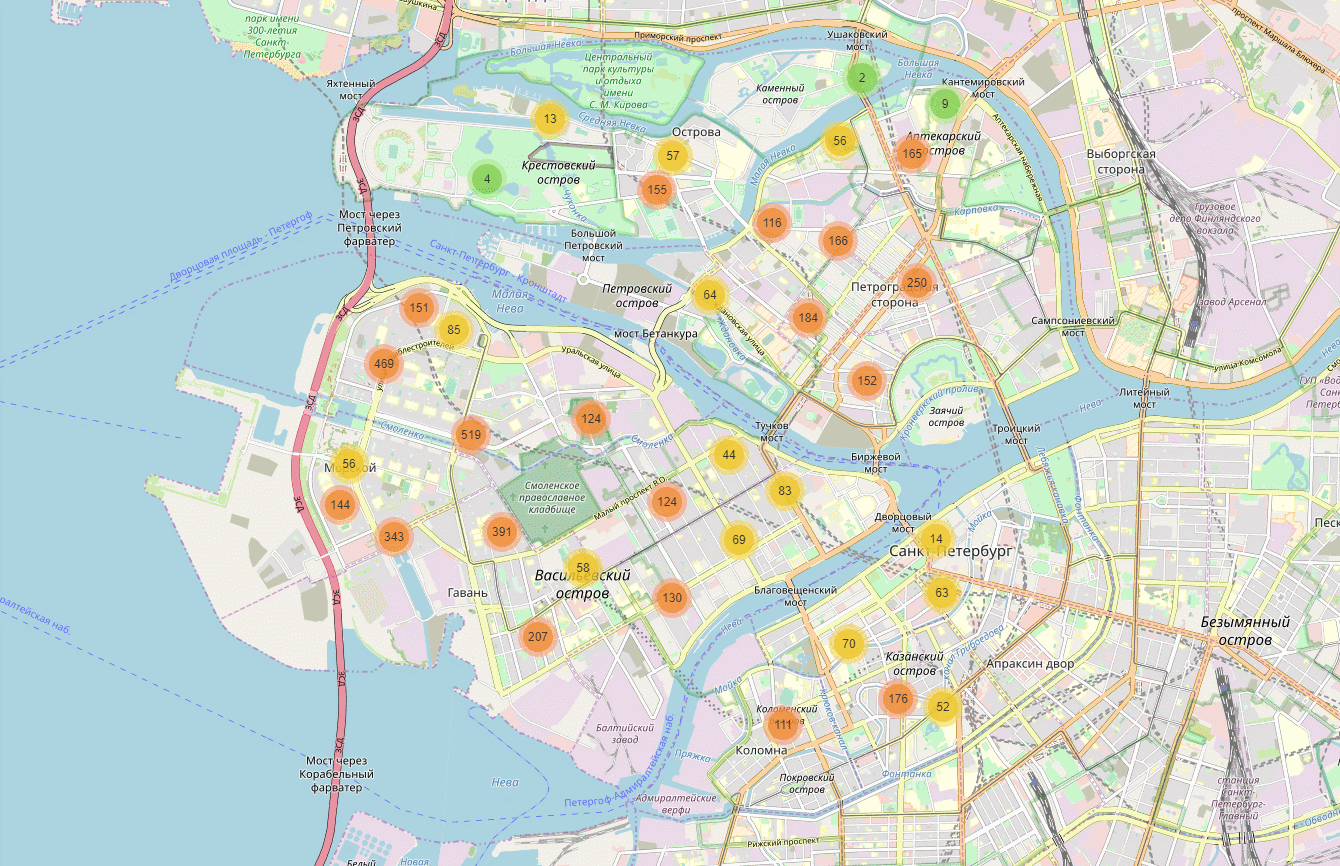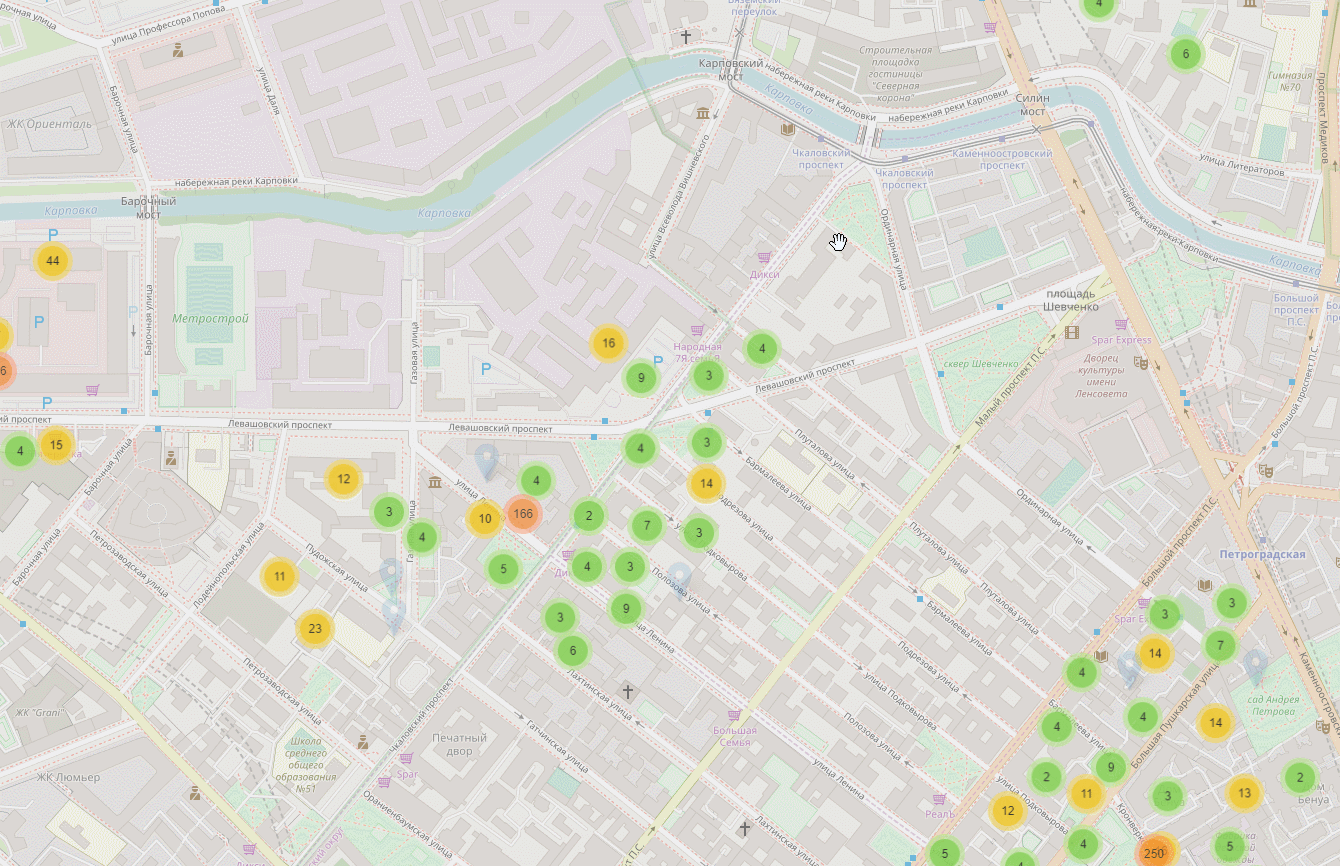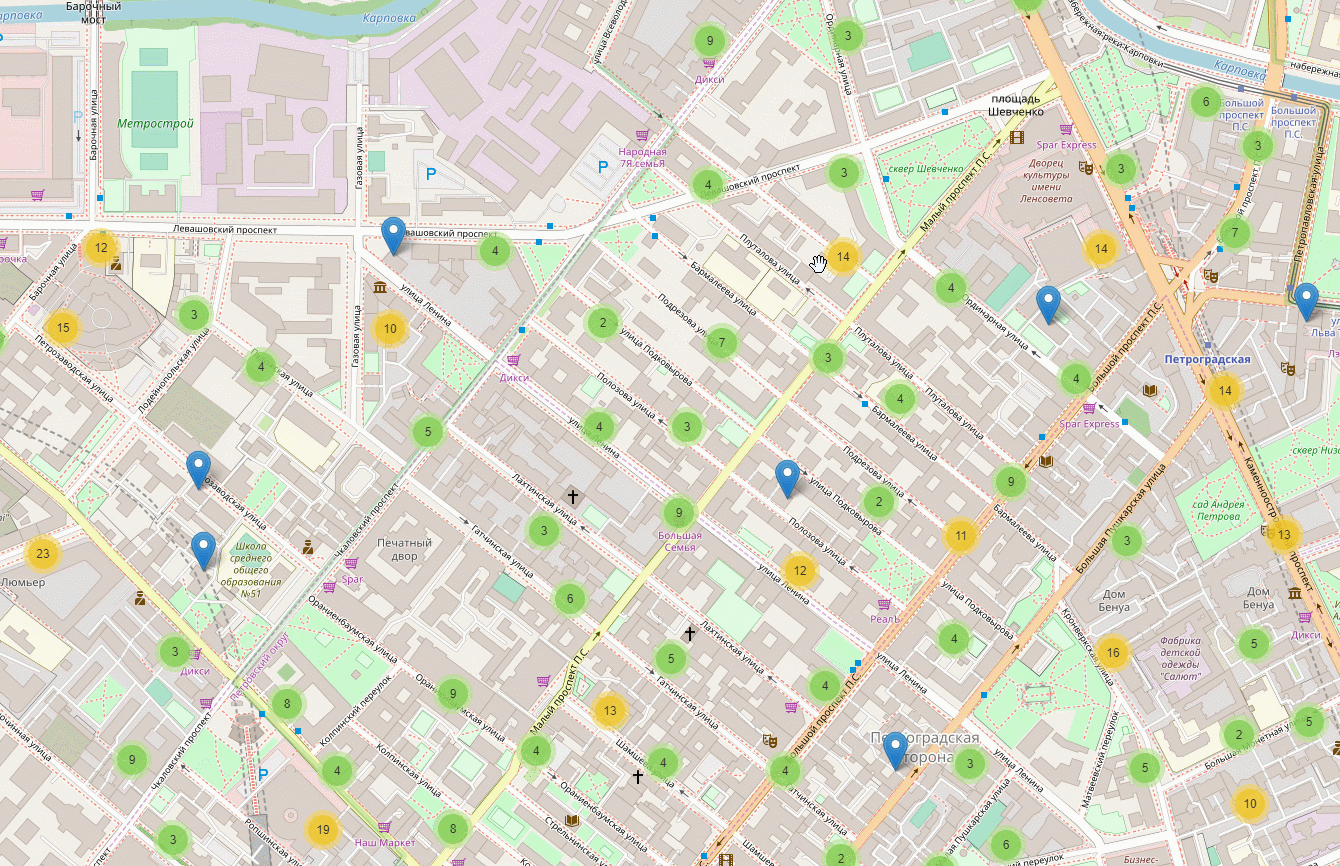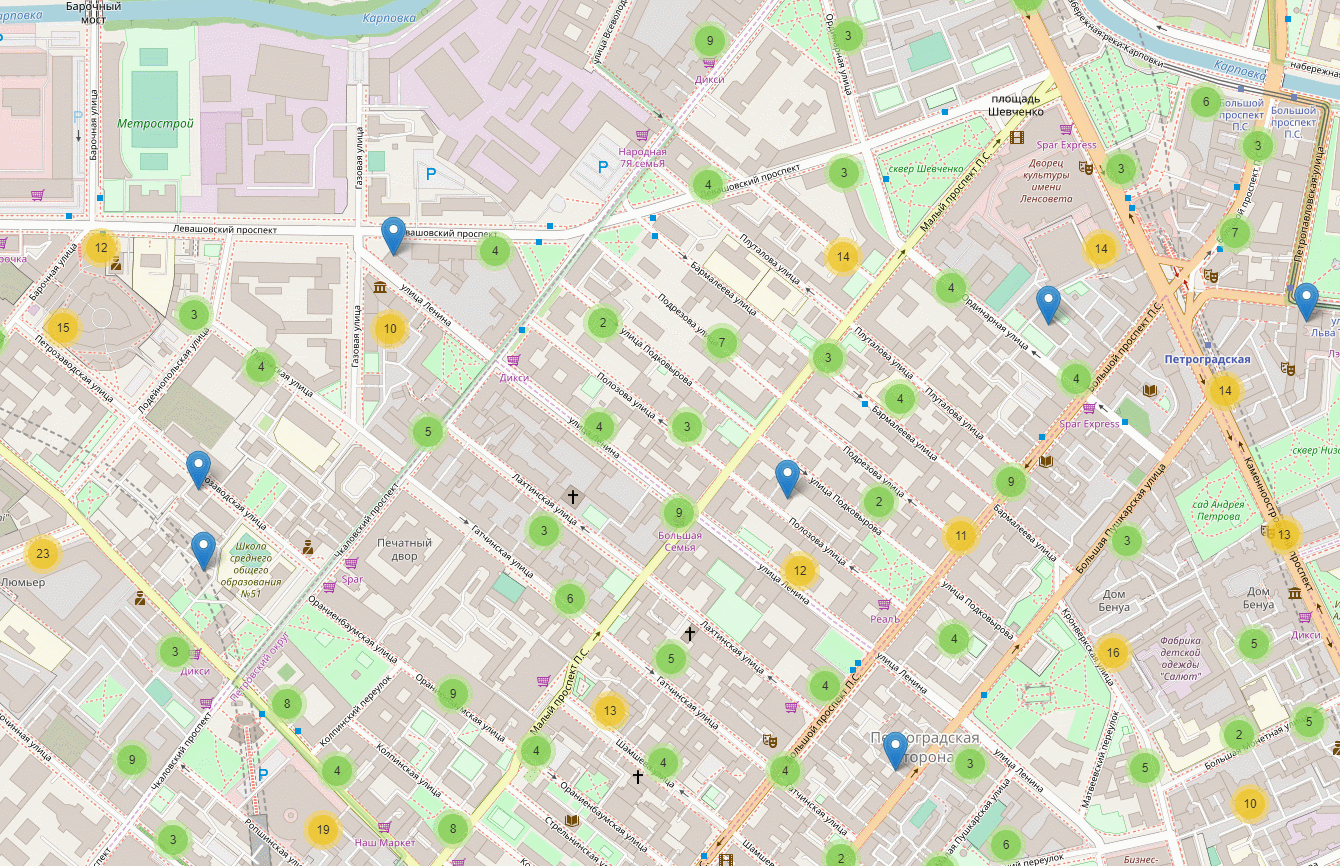 Auf der Karte sind zufällige Daten für einen Teil von St. Petersburg aufgezeichnet.
Auf der Karte sind zufällige Daten für einen Teil von St. Petersburg aufgezeichnet.Code zum Erstellen einer Karte import pandas as pd import folium from folium.plugins import MarkerCluster
Eine solche Karte erwies sich als praktisches Werkzeug zum Testen von Hypothesen. Zum Beispiel hatte das Unternehmen die Hypothese, dass es in einigen Haustypen (sowjetische Massengebäude: Schiffe, Serie 504, Chruschtschow usw.) keine Kunden geben würde. Es stellte sich heraus, dass dies nicht ganz stimmt. Ja, der Anteil der Kunden aus der Bevölkerung in solchen Häusern ist gering. Sie müssen jedoch berücksichtigt werden, da es in der Stadt viele solcher Häuser gibt, die bis zu 20% des Kundenstroms ausmachen.
Grenzen von Stadtteilen
Sie können die Bevölkerungs- und Kundendaten aus dem vorherigen Abschnitt nach Gemeindebezirken neu anordnen und zuordnen. Wenn Sie Infofenster und benutzerdefinierte Farben hinzufügen, wird dies sehr informativ. Es gibt bereits einen ausgezeichneten
Artikel über den Hub, in dem die Schritte zeigen, wie solche Karten erstellt werden.

Eigenschaftswert
Die Ermittlung der Immobilienpreise hat sich als entmutigende Aufgabe erwiesen. In der ersten Phase konnten wir ab Anfang 2018 alle Anzeigen für den Verkauf von Immobilien erhalten - das sind etwa 700.000 Datensätze.
Für jedes Haus wurden die Kosten pro Quadratmeter als Median der Anzeigen berechnet. Für 20% der Häuser ohne Werbung haben wir die Kosten für Quadratmeter geschätzt. m. mit dem Modell. Der Hauptfaktor ist der Preis pro Quadratmeter. m 15 nächstgelegene Häuser. Gleichzeitig erhielten Häuser mit ähnlichen Merkmalen mehr Gewicht: Baujahr, Anzahl der Einwohner, Art des Projekts. Der durchschnittliche Fehler des Modells im Testsatz betrug 9,5%, was für unsere Studie durchaus akzeptabel ist. Vor allem, wenn man bedenkt, dass selbst in einem Haus die Kosten für Quadratmeter. m. kann stark variieren: Boden, Reparatur, Fläche und andere Faktoren.
Entfernung von zu Hause zum Zweig
Die Grafik für 4 Abteilungen zeigt die Abhängigkeit des Kundenanteils im Haus von der Entfernung zur Abteilung. In einigen Branchen gibt es starke Sprünge, was auf den Einfluss anderer Faktoren (Alter des Hauses, Immobilienpreis) hindeutet.

Alter zu Hause
Interessant ist die Beziehung zwischen dem Baujahr des Hauses und dem Anteil der Kunden.

Zur weiteren Modellierung wurde das Alter des Hauses in 5 sinnvolle Kategorien unterteilt:
Preis pro Quadratmeter m
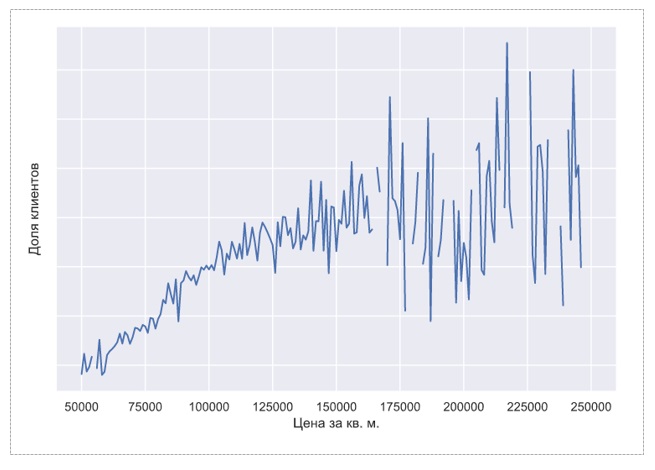
Der Preis korreliert mit dem Kundenanteil. Die Beziehung ist jedoch schwächer als zwischen dem Anteil der Kunden und dem Alter des Hauses. Vielleicht liegt der Grund darin, dass das Alter des Hauses mit dem Alter der Bewohner korreliert. Und das Alter einer Person hat großen Einfluss auf die Häufigkeit von Anfragen nach medizinischen Leistungen.
Modellbeschreibung
Anschließend entwickelte sich aus dieser Analyse ein vollwertiges Modell, bei dem die Koordinaten am Eingang angegeben werden und die Anzahl der Besuche neuer Kunden am Ausgang ermittelt wird. Der Artikel erwies sich als umfangreich, daher werde ich kurz auf das Modell eingehen.
Zur leichteren Interpretation der Ergebnisse wurde die lineare Regression als Modell gewählt. Die Zielvariable ist der Anteil der Kunden im Haus, Faktoren: der Logarithmus der Entfernung zum nächsten Büro, die Wohnkosten, das Baujahr des Hauses. Alle drei Faktoren erwiesen sich als signifikant und gingen in das Modell ein.
Durch Einsetzen neuer Koordinaten in ein solches Modell (dh Ändern des Abstandsfaktors zum nächsten Zweig) erhalten wir am Ausgang eine neue Anzahl von Clients für das gesamte Netzwerk. Wenn wir von dieser Zahl die Anzahl der Kunden abziehen, die zuvor waren, erhalten wir einen Nettoeffekt.
Eine solche Erklärung des Problems ist insofern zweckmäßig, als neue Standorte unter Berücksichtigung des Standorts der aktuellen Niederlassungen ausgewählt werden. Das heißt, es ist nicht erforderlich, den Kannibalisierungsfaktor zwischen verschiedenen Abteilungen zusätzlich zu berücksichtigen.
Die Suche nach optimalen Punkten für die gesamte Stadt wurde durch eine einfache Aufzählung der Koordinaten alle 500 m durchgeführt. Um den Effekt der Öffnung mehrerer Zweige zu berechnen, wurden die Punkte nacheinander festgelegt.
Ergebnisse
Es ist uns gelungen, die Wandkarte zu ersetzen, auf der wir die Grenzen der Stadtteile manuell gemalt und auf praktischen interaktiven Karten etwas gelesen haben. Befreien Sie Mitarbeiter davon, Tausende von Adressen manuell zu korrigieren und mit Gemeindebezirken abzugleichen. Bereichern Sie die Daten und gehen Sie von der Ebene des Stadtbezirks zu jedem Haus.
Es stellte sich heraus, dass mehrere sehr vielversprechende und nicht offensichtliche Orte für die Platzierung identifiziert wurden. Erstellen Sie ein Modell, das verschiedene Punkte automatisch und unparteiisch vergleicht.
Interessante Ergebnisse wurden erzielt, wenn die Geschäftsbereiche in „geo-abhängig“ und „geo-unabhängig“ unterteilt wurden. Ersteres sollte Teil neuer Niederlassungen sein, letzteres kann im Rahmen aktueller Standorte entwickelt werden.
(nicht im Artikel vorgestellt) .