Wir nehmen den Zentralprozessor als das „Gehirn“ eines Computers wahr, aber was bedeutet das wirklich? Was genau passiert in den Milliarden von Transistoren, die einen Computer zum Laufen bringen? In unserer neuen Miniserie mit vier Artikeln werden wir den Prozess der Erstellung der Architektur von Computergeräten betrachten und über die Prinzipien ihrer Funktionsweise sprechen.
In dieser Reihe werden wir über Computerarchitektur, Design von Prozessorkarten, VLSI (Very-Large-Scale-Integration), Chipherstellung und zukünftige Trends auf dem Gebiet der Computertechnologie sprechen. Wenn Sie die Details der Prozessoren verstehen möchten, ist es besser, die Studie mit dieser Artikelserie zu beginnen.
Wir beginnen mit einer sehr allgemeinen Erklärung, was der Prozessor tut und wie sich die Bausteine zu einer funktionierenden Struktur verbinden. Insbesondere werden Prozessorkerne, Speicherhierarchie, Verzweigungsvorhersage und mehr berücksichtigt. Zunächst müssen wir einfach definieren, was die CPU tut. Die einfachste Erklärung: Der Prozessor folgt einer Reihe von Anweisungen, um eine bestimmte Operation für viele eingehende Daten auszuführen. Beispielsweise kann ein Wert aus dem Speicher gelesen, dann zu einem anderen Wert hinzugefügt und das Ergebnis schließlich unter einer anderen Adresse im Speicher gespeichert werden. Es kann etwas komplizierter sein, zum Beispiel die Division zweier Zahlen, wenn das Ergebnis der vorherigen Berechnung größer als Null ist.
Programme wie ein Betriebssystem oder ein Spiel sind selbst Befehlsfolgen, die die CPU ausführen muss. Diese Anweisungen werden aus dem Speicher geladen und nacheinander in einem einfachen Prozessor ausgeführt, bis das Programm beendet wird. Softwareentwickler schreiben Programme in Hochsprachen wie C ++ oder Python, aber der Prozessor kann sie nicht verstehen. Er versteht nur Einsen und Nullen, daher müssen wir den Code in diesem Format irgendwie darstellen.
Programme werden zu einer Reihe von Anweisungen auf niedriger Ebene kompiliert, die als
Assemblersprache bezeichnet werden und Teil der Befehlssatzarchitektur (ISA) sind. Dies ist eine Reihe von Anweisungen, die die CPU verstehen und ausführen muss. Einige der häufigsten ISAs sind x86, MIPS, ARM, RISC-V und PowerPC. Ebenso wie sich die Syntax zum Schreiben einer Funktion in C ++ von der Funktion unterscheidet, die dieselbe Aktion in Python ausführt, hat jede ISA ihre eigene Syntax.
Diese ISAs können in zwei Hauptkategorien unterteilt werden: feste und variable Länge. ISA RISC-V verwendet Befehle mit fester Länge, was bedeutet, dass eine vorbestimmte Anzahl von Bits in jedem Befehl bestimmt, welcher Typ der Befehl ist. In x86 ist alles anders, es werden Anweisungen variabler Länge verwendet. In x86 können Anweisungen auf unterschiedliche Weise mit unterschiedlicher Anzahl von Bits für verschiedene Teile codiert werden. Aufgrund dieser Komplexität ist der Befehlsdecoder auf dem x86-Prozessor normalerweise der komplexeste Teil des gesamten Geräts.
Befehle mit fester Länge bieten aufgrund einer konstanten Struktur eine einfache Dekodierung, begrenzen jedoch die Gesamtzahl der Befehle, die von ISA unterstützt werden können. Während die gängigen Versionen der RISC-V-Architektur ungefähr 100 Anweisungen enthalten und alle Open Source sind, ist die x86-Architektur proprietär und niemand weiß, wie viele Anweisungen darin enthalten sind. Es wird allgemein angenommen, dass es mehrere tausend x86-Anweisungen gibt, aber niemand veröffentlicht die genaue Anzahl. Trotz der Unterschiede zwischen ISAs haben alle die gleiche Grundfunktionalität.
Ein Beispiel für einige RISC-V-Anweisungen. Der Opcode rechts ist 7 Bit lang und bestimmt die Art des Befehls. Zusätzlich enthält jeder Befehl Bits, die die verwendeten Register und die ausgeführten Funktionen definieren. Assembler-Anweisungen werden also in Binärcode unterteilt, damit der Prozessor ihn versteht.Jetzt können wir den Computer einschalten und mit der Ausführung von Programmen beginnen. Die Ausführung des Befehls besteht aus mehreren grundlegenden Teilen, die in viele Stufen des Prozessors unterteilt sind.
Die erste Stufe ist die Übertragung von Anweisungen vom Speicher zum Prozessor, um die Ausführung zu starten. Im zweiten Schritt wird der Befehl decodiert, damit die CPU verstehen kann, um welchen Befehlstyp es sich handelt. Es gibt viele Typen, einschließlich arithmetischer Anweisungen, Verzweigungsanweisungen und Speicheranweisungen. Nachdem die CPU herausgefunden hat, welche Art von Befehl sie ausführt, werden die Operanden für den Befehl aus dem Speicher oder den internen CPU-Registern entnommen. Wenn Sie die Nummer A und die Nummer B hinzufügen möchten, können Sie diese erst hinzufügen, wenn Sie die Werte von A und B kennen. Die meisten modernen Prozessoren sind 64-Bit-Prozessoren, dh die Größe jedes Datenwerts beträgt 64 Bit.
64 Bit ist die Breite des Prozessorregisters, des Datenkanals und / oder der Speicheradresse. Für normale Benutzer bedeutet dies, wie viele Informationen ein Computer gleichzeitig verarbeiten kann. Dies lässt sich am besten im Vergleich zu einem jüngeren Architekturverwandten - einem 32-Bit-Prozessor - verstehen. Die 64-Bit-Architektur kann doppelt so viele Informationsbits gleichzeitig verarbeiten (64 Bit gegenüber 32 Bit).Nachdem der Prozessor die Operanden für den Befehl empfangen hat, überträgt er sie an die Ausführungsstufe, wo die Operation an den eingehenden Daten ausgeführt wird. Dies kann das Hinzufügen von Zahlen, das Ausführen logischer Manipulationen mit Zahlen oder das einfache Übergeben von Zahlen sein, ohne diese zu ändern. Nach der Berechnung des Ergebnisses kann ein Speicherzugriff erforderlich sein, um es zu speichern, oder der Prozessor kann den Wert einfach in einem seiner internen Register speichern. Nach dem Speichern des Ergebnisses aktualisiert die CPU den Status der verschiedenen Elemente und fährt mit dem nächsten Befehl fort.
Diese Erklärung ist natürlich stark vereinfacht, und die meisten modernen Prozessoren unterteilen diese verschiedenen Stufen in 20 oder noch mehr kleine Stufen, um die Effizienz zu steigern. Dies bedeutet, dass der Prozessor zwar mit mehreren Befehlen in jedem Zyklus beginnt und endet, es jedoch 20 oder mehr Zyklen dauern kann, um einen Befehl von Anfang bis Ende auszuführen. Ein solches Modell wird normalerweise als Pipeline ("Pipeline", normalerweise ins Russische übersetzt als "Förderer") bezeichnet, da es einige Zeit dauert, die Pipeline mit Flüssigkeit zu füllen und ihren Durchgang abzuschließen, aber nach dem Befüllen ist die Durchflussrate (Datenausgabe) konstant.
Ein Beispiel für einen 4-stufigen Förderer. Mehrfarbige Rechtecke kennzeichnen voneinander unabhängige Anweisungen.Der gesamte Zyklus, den die Anweisung durchläuft, ist ein sehr sorgfältig koordinierter Prozess, aber nicht alle Anweisungen können gleichzeitig ausgeführt werden. Zum Beispiel ist das Hinzufügen sehr schnell und das Teilen oder Laden aus dem Speicher kann Tausende von Zyklen dauern. Anstatt den gesamten Prozessor bis zum Abschluss eines langsamen Befehls anzuhalten, führen die meisten modernen Prozessoren diese mit einer Änderung der Reihenfolge aus. Das heißt, sie bestimmen, welche der Anweisungen im Moment am vorteilhaftesten auszuführen ist, und puffern andere Anweisungen, die noch nicht bereit sind. Wenn der aktuelle Befehl noch nicht fertig ist, kann der Prozessor im Code vorwärts springen, um zu sehen, ob etwas anderes bereit ist.
Moderne Prozessoren führen nicht nur eine Abfolge von Änderungen aus, sondern verwenden auch eine Technologie, die als
superskalare Architektur bezeichnet wird . Dies bedeutet, dass der Prozessor zu jeder Zeit gleichzeitig viele Anweisungen in jeder Phase der Pipeline ausführt. Er kann auch erwarten, dass Hunderte weitere mit ihrer Ausführung beginnen. Um mehrere Anweisungen gleichzeitig in den Prozessoren ausführen zu können, gibt es mehrere Kopien jeder Stufe der Pipeline. Wenn der Prozessor feststellt, dass zwei Befehle zur Ausführung bereit sind und keine Abhängigkeit zwischen ihnen besteht, wartet er nicht, bis sie separat ausgeführt werden, sondern führt sie gleichzeitig aus. Eine beliebte Implementierung dieser Architektur heißt Simultaneous Multithreading (SMT) und wird auch als Hyper-Threading bezeichnet. Intel- und AMD-Prozessoren unterstützen jetzt doppelseitiges SMT, während IBM Chips entwickelt hat, die bis zu acht SMTs unterstützen.
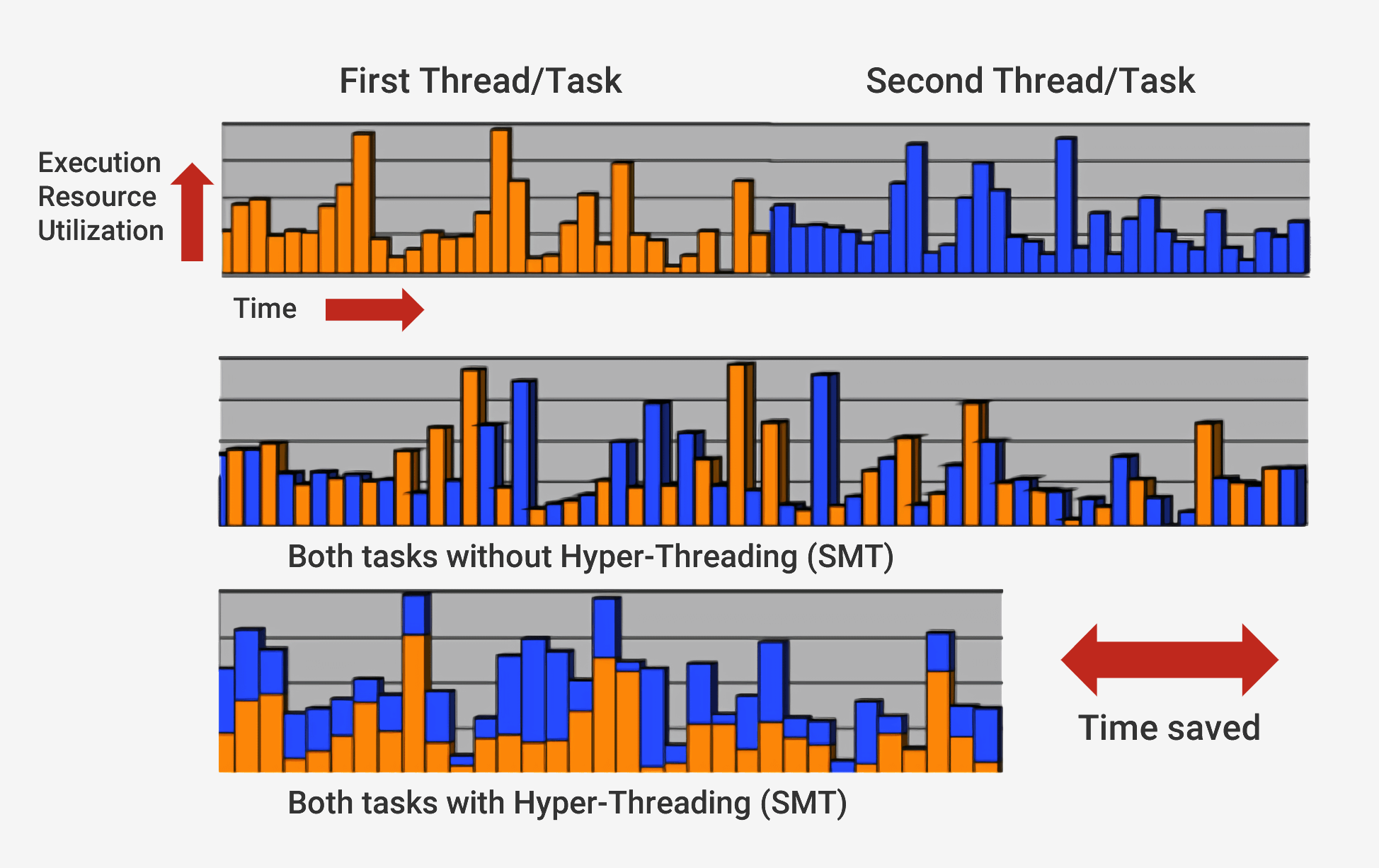
Um diese sorgfältig koordinierte Ausführung abzuschließen, verfügt der Prozessor neben dem Basiskern über viele zusätzliche Elemente. Der Prozessor verfügt über Hunderte von separaten Modulen, von denen jedes eine bestimmte Funktion hat. Wir werden jedoch nur die Grundlagen berücksichtigen. Die wichtigsten und profitabelsten sind Caches und der Prädiktor für Übergänge. Es gibt andere zusätzliche Strukturen, die wir nicht berücksichtigen werden: Neuanordnen von Puffern, Registrieren von Umbenennungstabellen und Sicherungsstationen.
Die Notwendigkeit von Caches kann manchmal verwirrend sein, da sie Daten wie RAM oder SSD speichern. Caches unterscheiden sich jedoch in Latenz und Zugriffsgeschwindigkeit. Obwohl der RAM-Speicher extrem schnell ist, ist er um Größenordnungen langsamer als die CPU benötigt. Möglicherweise sind Hunderte von Zyklen erforderlich, um auf die Übertragung von RAM-Daten zu reagieren, und der Prozessor hat zu diesem Zeitpunkt nichts zu tun. Und wenn sich keine Daten im RAM befinden, kann es Zehntausende von Zyklen dauern, um von der SSD auf diese zuzugreifen. Ohne Caches würden Prozessoren ständig anhalten.
Prozessoren haben normalerweise drei Cache-Ebenen, aus denen die sogenannte
Speicherhierarchie besteht . Der L1-Cache ist der kleinste und schnellste, L2 befindet sich in der Mitte und L3 ist der größte und langsamste aller Caches. Über den Caches in der Hierarchie befinden sich kleine Register, in denen der einzige Datenwert während der Berechnungen gespeichert wird. In der Größenordnung sind diese Register die schnellsten Speichergeräte im System. Wenn der Compiler ein übergeordnetes Programm in Assemblersprache konvertiert, bestimmt er, wie diese Register am besten verwendet werden können.
Wenn die CPU Daten aus dem Speicher anfordert, prüft sie zunächst, ob diese Daten bereits im L1-Cache gespeichert sind. Wenn ja, können Sie in nur wenigen Zyklen darauf zugreifen. Wenn sie nicht vorhanden sind, überprüft der Prozessor L2 und dann den L3-Cache. Caches werden so implementiert, dass sie im Allgemeinen für den Kernel transparent sind. Der Kernel fordert einfach Daten an der angegebenen Speicheradresse an, und die Ebene in der Hierarchie, auf der er existiert, antwortet darauf. Beim Übergang zu nachfolgenden Ebenen in der Speicherhierarchie nehmen Größe und Verzögerungen normalerweise um Größenordnungen zu. Wenn die CPU am Ende keine Daten in einem der Caches findet, greift sie auf den Hauptspeicher (RAM) zu.
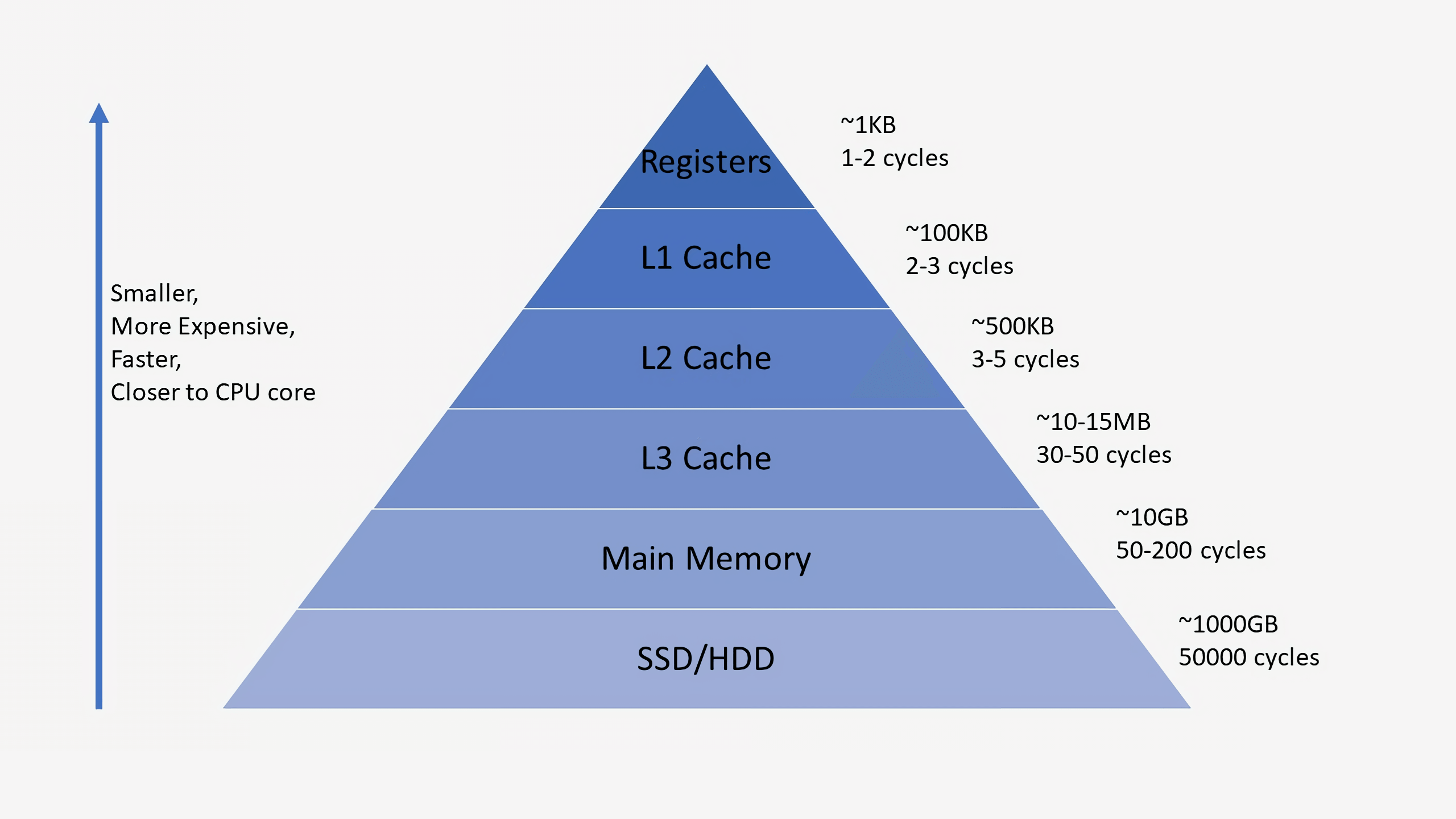
In einem normalen Prozessor verfügt jeder Kern über zwei L1-Caches: einen für Daten und einen für Anweisungen. L1-Caches haben normalerweise eine Gesamtkapazität von etwa 100 Kilobyte und die Größe variiert stark in Abhängigkeit von der Chip- und Prozessorgeneration. Darüber hinaus verfügt normalerweise jeder Kern über einen eigenen L2-Cache, obwohl dies in einigen Architekturen zwei Kernen gemeinsam sein kann. L2-Caches sind normalerweise mehrere hundert Kilobyte groß. Schließlich gibt es einen einzigen L3-Cache, der allen Kernen gemeinsam ist und eine Größe in der Größenordnung von zehn Megabyte aufweist.
Wenn der Prozessor den Code ausführt, werden die am häufigsten verwendeten Anweisungen und Datenwerte zwischengespeichert. Dies beschleunigt die Ausführung erheblich, da der Prozessor nicht ständig in den Hauptspeicher gehen muss, um die erforderlichen Daten zu erhalten. Im zweiten und dritten Teil der Serie werden wir mehr darüber sprechen, wie diese Speichersysteme implementiert sind.
Einer der wichtigsten Bausteine eines modernen Prozessors ist neben Caches ein genauer
Übergangsprädiktor . Übergangsanweisungen (Verzweigungsbefehle) ähneln den if-Konstrukten für den Prozessor. Ein Befehlssatz wird ausgeführt, wenn die Bedingung wahr ist, und der andere, wenn sie falsch ist. Zum Beispiel müssen wir zwei Zahlen vergleichen, und wenn sie gleich sind, führen Sie eine Funktion aus, und wenn sie nicht gleich sind, führen Sie eine andere aus. Diese Verzweigungsanweisungen sind sehr häufig und können etwa 20% aller Anweisungen in einem Programm ausmachen.
Auf den ersten Blick scheint es, dass diese Verzweigungsanweisungen keine Probleme verursachen sollten, aber ihre ordnungsgemäße Ausführung kann für den Prozessor sehr schwierig sein. Zu jedem Zeitpunkt kann der Prozessor dabei sein, zehn oder zwanzig Befehle gleichzeitig auszuführen, daher ist es sehr wichtig zu wissen,
welche Befehle ausgeführt werden sollen. Es kann 5 Zyklen dauern, um festzustellen, ob der aktuelle Befehl ein Übergang ist, und weitere 10 Zyklen, um festzustellen, ob die Bedingung erfüllt ist. Zu diesem Zeitpunkt kann der Prozessor bereits Dutzende zusätzlicher Anweisungen ausführen, ohne zu wissen, ob diese Anweisungen wirklich für die Ausführung geeignet sind.
Um dieses Problem zu umgehen, verwenden alle modernen Hochleistungsprozessoren eine Technik namens Spekulation. Dies bedeutet, dass der Prozessor Verzweigungsbefehle verfolgt und sich fragt, ob die bedingte Verzweigung ausgeführt wird oder nicht. Wenn die Vorhersage korrekt ist, hat der Prozessor bereits begonnen, die folgenden Anweisungen auszuführen, und dies führt zu einer Leistungssteigerung. Wenn die Vorhersage falsch ist, stoppt der Prozessor die Ausführung, löscht alle falschen Anweisungen, die er ausgeführt hat, und startet erneut am richtigen Punkt.
Solche Verzweigungsprädiktoren sind einige der einfachsten Arten des maschinellen Lernens, da der Prädiktor das Verhalten von Verzweigungen während der Ausführung untersucht. Wenn er zu oft falsch vorhersagt, beginnt er, das richtige Verhalten zu lernen. Jahrzehntelange Forschungen zu Übergangsvorhersagetechniken haben in modernen Prozessoren zu einer Vorhersagegenauigkeit von mehr als 90% geführt.
Die Antizipation führt zwar zu einer enormen Leistungssteigerung, da der Prozessor bereits fertige Anweisungen ausführen kann, anstatt in der Warteschlange auf die Ausführung zu warten, sondern auch Sicherheitslücken schafft. Der berühmte Spectre-Angriff nutzt Fehler aus, um Übergänge vorherzusagen und zu antizipieren. Der Angreifer verwendet speziell ausgewählten Code, um den Prozessor zu zwingen, den Code proaktiv auszuführen, was zu einem Verlust von Werten aus dem Speicher führt. Um Datenlecks zu vermeiden, mussten bestimmte Aspekte der Antizipation überarbeitet werden, was zu einem leichten Leistungsabfall führte.
In den letzten Jahrzehnten hat die in modernen Prozessoren verwendete Architektur einen langen Weg zurückgelegt. Innovation und die Entwicklung einer durchdachten Struktur haben zu einer höheren Produktivität und einem optimaleren Einsatz von Hardware geführt. Die Entwickler der Zentralprozessoren bewahren die Geheimnisse ihrer Technologien jedoch sorgfältig auf, sodass wir nicht genau herausfinden können, was in ihnen geschieht. Die Grundprinzipien der Prozessoren sind jedoch für alle Architekturen und Modelle standardisiert. Intel kann seine geheimen Zutaten hinzufügen, um den Anteil der Cache-Treffer zu erhöhen, und AMD kann einen verbesserten Übergangsprädiktor hinzufügen, aber die Prozessoren beider Unternehmen führen dieselbe Aufgabe aus.
In diesem ersten Blick und Rückblick haben wir die Grundlagen der Funktionsweise von Prozessoren behandelt. Im nächsten Teil erfahren Sie, wie Sie die Komponenten der Prozessoren entwickeln, über Logikelemente, Taktfrequenzen, Energieverwaltung, Schaltkreise und vieles mehr sprechen.
Empfohlene Lektüre