Hallo! Mein Name ist Vitaliy Kostousov, ich arbeite im Global Tech Heroes-Team und heute werde ich Ihnen über den Support berichten - eine der wichtigsten Komponenten eines jeden Dienstes. Sie können eine großartige Anwendung mit coolen Bildern und manchmal ausreichend scherzhaften Chat-Bots erstellen. Sie können offen entleeren und den Kunden zunächst einen kostengünstigen Service anbieten. Sie können eine wunderbare SMM-Box mieten, für die Sie sich nicht schämen und die in den 90er Jahren nicht so oft gewechselt werden muss wie ein Buchhalter.
Aber all dies kann gut stolpern, wenn keine vernünftige Unterstützung für Ihren Service vorhanden ist. Und Unterstützung im globalen Sinne - von der Lösung von Benutzerproblemen bis zur Sicherstellung der Funktionalität von Software und Hardware. Nun, im Ernst, wie lange werden die Leute die Anwendung verwenden, die seit ein paar Wochen dumm ist, aber die Entwickler haben immer noch nicht normal auf Probleme reagiert, der Support-Service ist mit Roboterantworten abgemeldet und können Sie im Call Center kostenlos klassische Musik hören?

Da wir alles arrangiert haben, was wir in unserer Arbeit verwenden, um Probleme zu erkennen und zu lösen, wie viele von uns und alles andere unter dem Schnitt sind.
Jetzt arbeiten wir in drei Ländern: Russland, Großbritannien und Israel. Wir haben Hunderttausende aktive Benutzer, allein Firmenkunden mehr als 20.000. Unsere Anwendungen werden täglich täglich angefordert. Und es gibt Fahrer und Anfragen von ihnen. Und auch interne Systeme und Überwachung. All dies sollte funktionieren und gut funktionieren. Zu diesem Zweck verfügen wir über ein globales technisches Support-Team namens „Tech Heroes“ - Forschungs- und Entwicklungsteams, Eskalationsbetreiber und -ingenieure sowie Global Incident Manager. Und dem begegnen sie in ihrer Arbeit.
Team und Benutzer
Machen Sie sofort eine Reservierung, dass die Endbenutzer unseres Teams nicht nur Kunden und Fahrer sind, die Vorrang haben (sowohl private als auch geschäftliche), sondern auch Marketing, Support-Services und unsere internen Abteilungen. Natürlich schreiben sie zur Unterstützung entweder über die Anwendung oder in sozialen Netzwerken. Wenn das Problem technischer Natur ist, geht die Aufgabe in SalesForce sofort an uns. Sie können nicht nur über die Anwendung und die Qualität ihrer Arbeit als Ganzes oder über einige Funktionen im Besonderen schreiben, sondern auch über die Leistung der internen Dienste des Unternehmens. Es gibt mehr als 1000 Gett-Mitarbeiter, die Fragen zur Arbeitssoftware und zur Prozessorganisation stellen.
Unser Team besteht aus 8 Personen, die in drei Ländern verteilt sind - Israel, Großbritannien und Russland. Ein Spezialist aus Russland arbeitet remote. Zu seinen Aufgaben gehört die Arbeit mit betrieblichen Prozessen: Überwachung und Änderung unserer Hauptdienste. Die verbleibenden sieben beschäftigen sich mit betrieblichen und vielen anderen Problemen: Tests, Fehler, Spezifikationen, schnelle Lösung von Anrufen von betrieblichen Spezialisten und Managern sowie Überwachung aller unserer Datenbanken, Dienste und Mikrodienste. Dieses Team verarbeitet alle Tickets aus dem Land, in dem sie ankommen. Zum größten Teil müssen Sie mit lokalen Problemen arbeiten, aber es kommt vor, dass es einen schwerwiegenden Fehler in der Arbeit globaler Dienste gibt, dann geht die Arbeit in den globalen Modus.
Sie müssen auch berücksichtigen, dass wir weltweit viele B2B-Kunden haben - das System verfügt über sehr flexible Einstellungen und die Möglichkeit der Geschäftsintegration mit den Diensten des Unternehmens. Das heißt, es gibt viel mehr Klassen von Autos, als private Nutzer des Dienstes sehen. Es ist wichtig zu verstehen, dass all dies sowohl den Betrieb von Diensten als auch die Anzahl der Transaktionsvorgänge beeinflusst. Das B2B-Segment kann ein persönliches Konto auf der Website des Unternehmens verwenden.
Software
Es gibt verschiedene Systeme für die Arbeit mit Tickets auf dem Markt, die sich bereits als nützlich erwiesen haben: LiveAgent, ZenDesk, ZohoDesk und andere. Sie können nach Belieben wählen, Sie können aus Gewohnheit, Sie können - ausgehend von der Art von Software, mit der Ihre Kollegen arbeiten, um nicht eine Reihe von Schichten und Krücken zu blockieren (die auch unterstützt und fertiggestellt werden müssen). Daher arbeiten wir für SalesForce, da es von den Hauptgeschäftsbereichen des Unternehmens (Vertrieb und Support) verwendet wird. Auf diese Weise können Sie den Status jedes Falls von der Seite seines Erstellers aus verfolgen. Es gibt eine automatische Priorisierung von Fällen basierend auf den Berufungsthemen. SalesForce ist ebenfalls in Jira integriert. Wenn eine Aufgabe erstellt oder ein Fehler in die Entwicklung eingeführt wird, wird der Status auch in diesem Fall angezeigt. So erreichen wir eine transparente Kommunikation zwischen Support und Entwicklung.
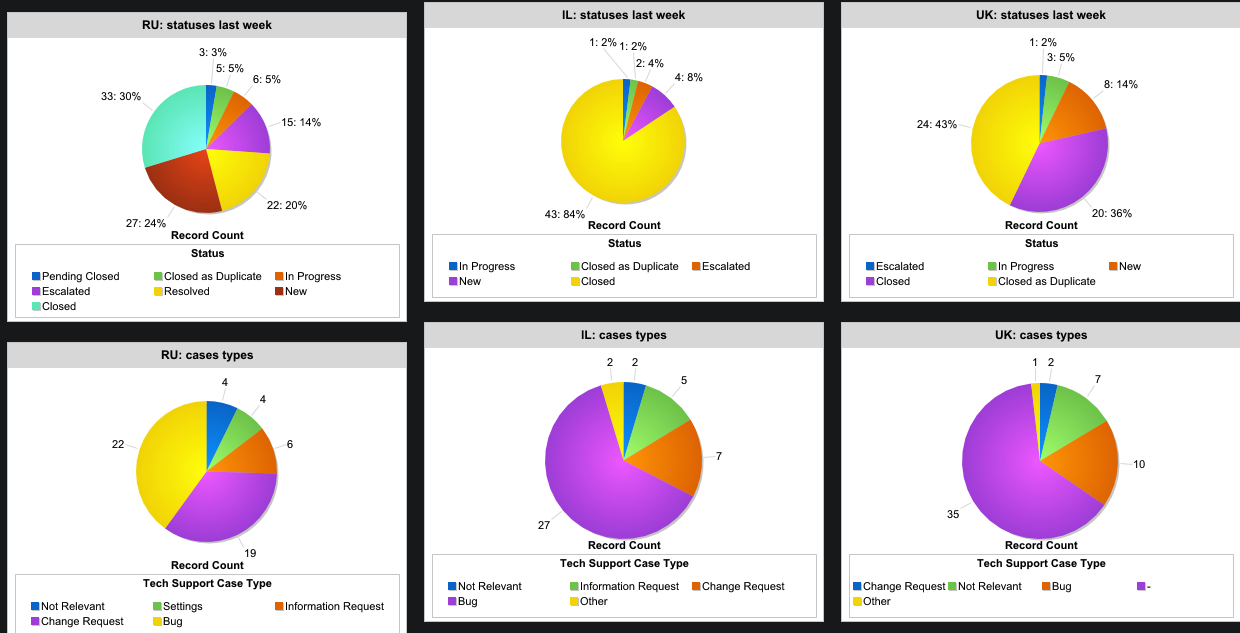 SalesForce, anklickbar
SalesForce, anklickbarEin spezielles Anwendungssystem ermöglicht es Ihnen, die SLA für jedes bei uns ankommende Ticket zu verfolgen.
Tickets und Anfragen
Insbesondere beschäftigt sich unser Team mit der Arbeit der Anwendung selbst (sowohl für Fahrer als auch für Passagiere), mit Microservices, mit denen Betriebsspezialisten zusammenarbeiten, sowie mit Tests und Überwachung. Darüber hinaus werden immer neue Berichte und Überwachungen angefordert, die für Kollegen aus anderen Abteilungen hilfreich sein können. Gleichzeitig ist eine gewisse Überwachung ausschließlich für unser Team vorgesehen, wenn sie sich ausschließlich auf die technischen Parameter der Dienste und Datenbanken bezieht. Ein Teil der Überwachung sendet Benachrichtigungen an uns, das verantwortliche Team und den Support. Wenn das Problem beispielsweise mit der Treiberanwendung zusammenhängt, reagiert der Support viel schneller und benachrichtigt die Treiber bei Bedarf. Somit wird der Zeitpunkt der Information auf einige Minuten reduziert.
Überwachung
Wir haben viel Überwachung. Sobald einer von ihnen funktioniert, unabhängig davon, ob es sich um Newrelic (Systemdienste aktiv), Grafik (Überwachung bestimmter Szenarien) oder Datadog (Infrastruktur-Verfügbarkeit) handelt, erhalten wir sofort eine Benachrichtigung in Slack und erhalten einen Anruf (dank Pagerduty). Und für einen bestimmten Zeitraum wird eine Person ernannt. Da dies automatisch geschieht, ist es wahrscheinlich, dass diese bestimmte Person derzeit nicht verfügbar ist oder einfach nicht geantwortet hat. Der Anruf wird dann weiter entlang der Kette weitergeleitet.
Wenn die Warnungen ausgelöst werden, überprüfen wir die Leistung der Systeme erneut und ermitteln die Ursache des Fehlers (oder der erhöhten Last oder einer großen Anzahl von Ereignissen oder Anrufen, die hier fliegen werden). Wenn wir verstehen, dass dies ein Problem ist und gelöst werden muss, senden wir einen Brief an spezielle Vertriebsgruppen für Betriebsspezialisten.
Deshalb sind wir immer online.
Incident Management
Wenn Ihr Unternehmen Dienstleistungen erbringt, ist das Incident Management nirgendwo. Wir arbeiten nach diesem Schema:
- Rechtzeitige Erkennung von Problemen.
- Benachrichtigung über das Problem der verantwortlichen Personen.
- Stakeholder-Benachrichtigung auf allen Ebenen. Das heißt, wir sprechen über das Problem für Unternehmen, damit jeder dort genau versteht, wie sich solche Probleme auf Unternehmen und Gewinne auswirken.
- Wahrung maximaler Transparenz der Arbeit.
- Obligatorische Ursachenanalyse. Immerhin hat es den Ursprung des Problems, und das nächste kann verhindert werden. Dies ist schneller und nützlicher als eine erneute Lösung in der zweiten Runde.
Ziel ist es, Probleme im Nullstadium kennenzulernen. Zu diesem Zeitpunkt haben Sie das Problem als Mitarbeiter entdeckt, der die Arbeitskapazität bereitstellt. Nicht, wenn der Kunde Sie über sie informiert hat. Daher verwenden wir aktiv das APM-Toolkit (Application Performance Monitoring). Ich werde sie noch einmal aussprechen.
NewRelic- Überwachung aller unserer Microservices und Gateways
- 50x, 4xx Fehler
- Redis apdex
- DBs Apdex
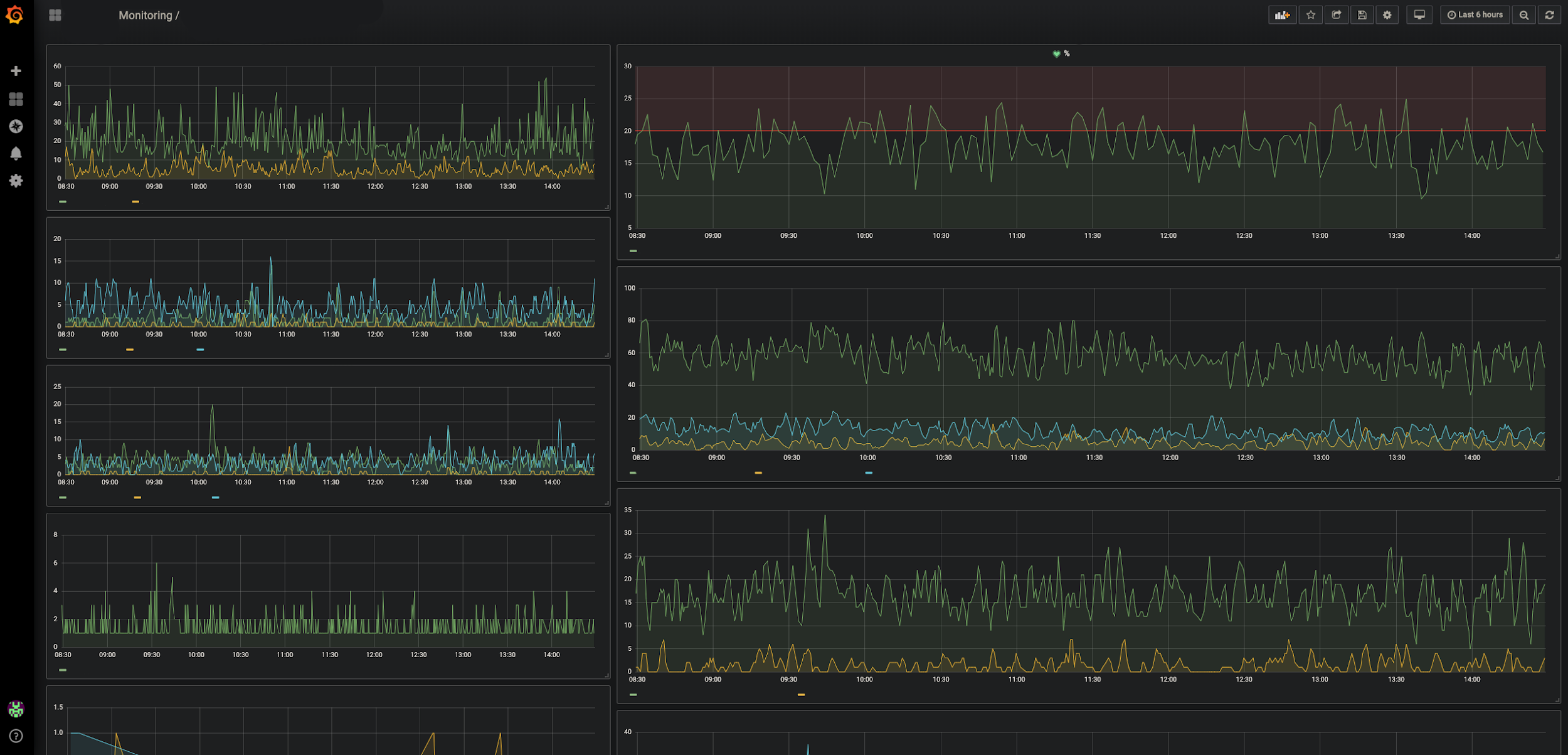
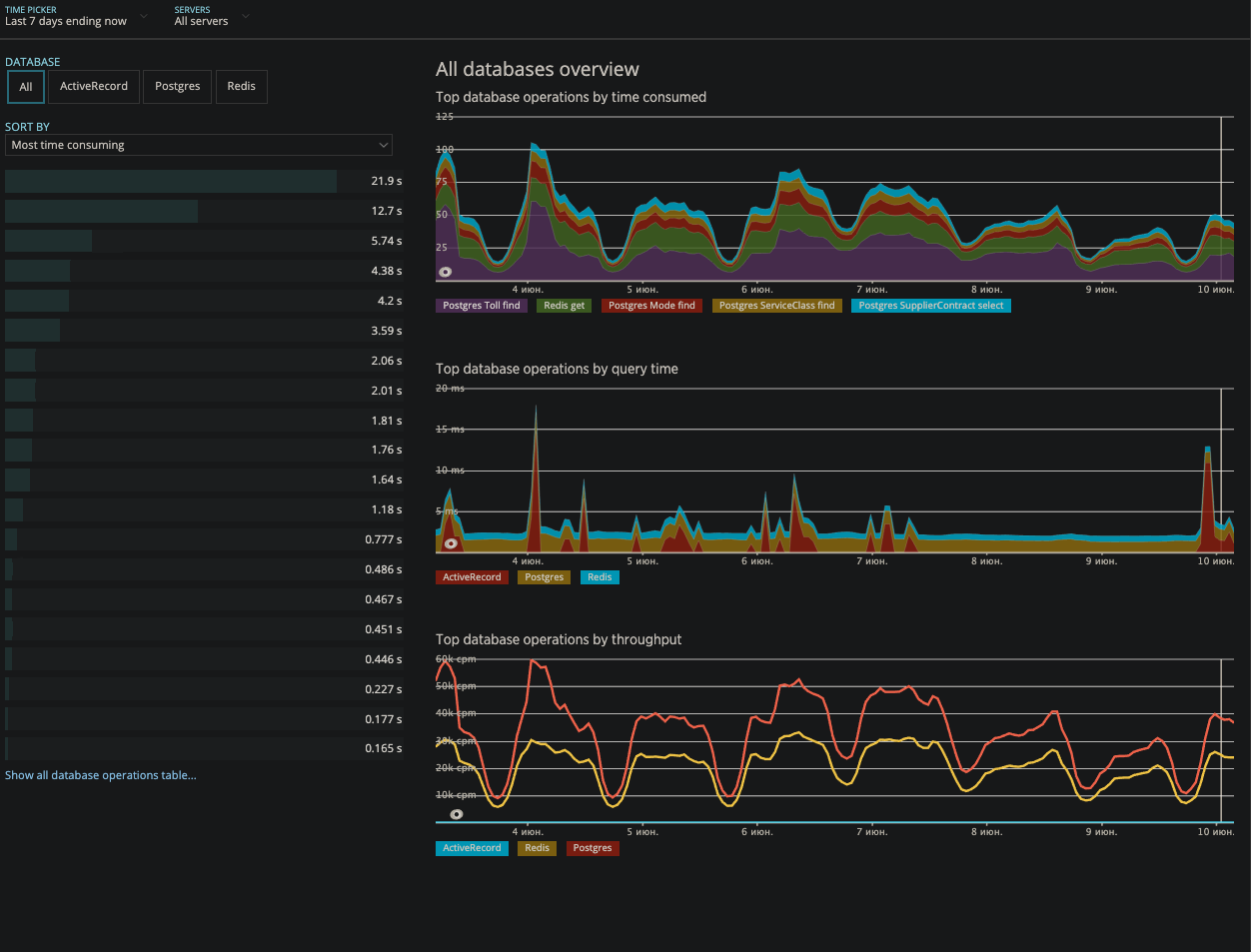 NewRelic, anklickbarGrafana
NewRelic, anklickbarGrafana Ereignisüberwachung (macht deutlich, was genau nicht mehr funktioniert oder welches Verhalten sich vom Normalen unterscheidet).
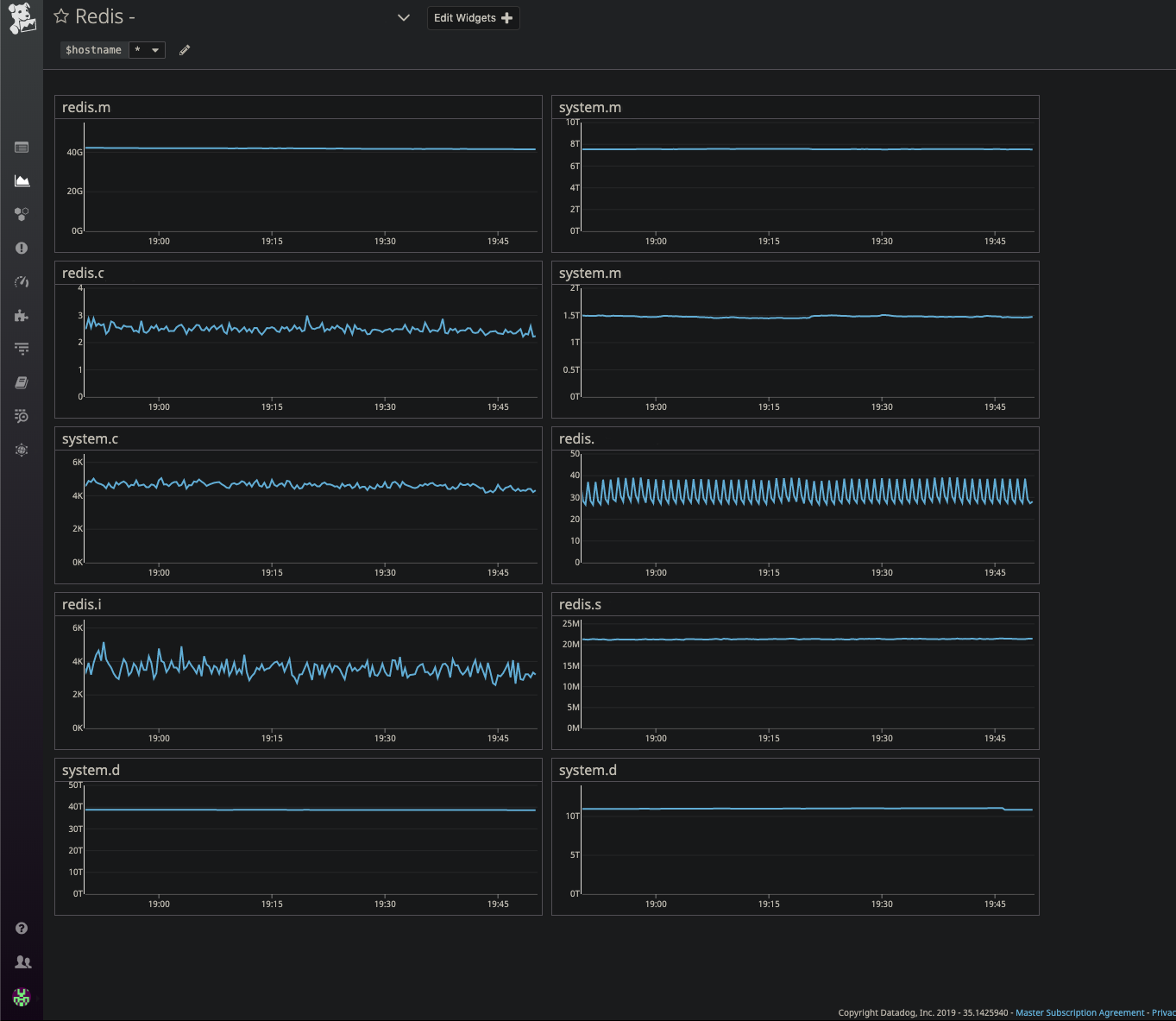
 Grafana, anklickbarDataDog
Grafana, anklickbarDataDog . Überwachung der Hardwarekomponenten unseres Systems (Datenbanken, Load Balancer).
 DataDog, anklickbarDruckluftbremse
DataDog, anklickbarDruckluftbremse Code-Ausnahmen für Apps / Microservices (es gibt eine Liste von Ausnahmen, z. B. beim Ausführen von Code oder Abfragen in der Datenbank, wenn etwas schief geht und es auf der Liste steht - wir verfolgen es).
Kibana - Überwachung von Microservice- / Anwendungsprotokollen (Treiber / Client).
Und damit alles nicht nur zur Erkennung, sondern auch zur rechtzeitigen Benachrichtigung (sofort, je schneller -
desto besser) funktioniert, ist all dies mit einer Reihe von Benachrichtigungskanälen verbunden, von Slack und
PagerDuty bis hin zu guten alten E-Mail-Benachrichtigungen. Daher wird das gesamte Team sofort über eventuelle Anomalien informiert. Warnungen können an verschiedene Kanäle gesendet werden. Die für den Betrieb von Anwendungen wichtige Überwachung sendet immer Warnungen an das technische Supportteam und selektiv an die Kanäle der Entwicklungsteams, die für eine bestimmte Funktion / einen bestimmten Dienst verantwortlich sind. All dies hilft, die Reaktionszeit zu optimieren.
Im nächsten Schritt traten Schwierigkeiten auf, als Sie nach dem Auffinden eines Problems die für den Service verantwortliche Person schnell benachrichtigen mussten. Und dies ist nicht so einfach, wenn es viele Prozesse und Microservices gibt, was bedeutet, dass es keine weniger verantwortlichen gibt. Und der Alarm kann spät in der Nacht eintreffen, wenn Sie etwas wollen, aber Sie klären einfach nicht, wer für was verantwortlich ist.
Aus diesem Grund haben wir ein praktisches Verzeichnis erstellt, in dem alle Service-Eigentümer (im Allgemeinen im gesamten Unternehmen) aufgelistet sind. Wie die Praxis gezeigt hat, hat uns dies allein geholfen, die Zeit für die Lösung jedes Vorfalls um etwa 20% zu verkürzen.
Das beste Rezept für eine anhaltende Katastrophe in diesem Fall ist, den Vorfall ohne eine verantwortliche Person zu verlassen.
Es gibt eine spezielle Person, Global Incident Manager, die als Drehscheibe für schwerwiegende Vorfälle fungiert. Er ist an der Überwachung und Änderung der Basissysteme beteiligt, um Fehler zu beseitigen, die zu den Knochen des Unternehmens führen können, und ist gegenüber den obersten Mitarbeitern des Unternehmens verantwortlich und liefert ihnen detaillierte Berichte über die Analyse der Grundursachen.
Kurz gesagt, der Incident Management-Prozess selbst sieht folgendermaßen aus:
- Wir ermitteln die Ursachen des Vorfalls.
- Wir finden die verantwortliche Person.
- Wir koordinieren die Bemühungen mit ihm, um das Problem so schnell wie möglich zu beheben.
- Wir treffen alle notwendigen Entscheidungen während des Vorfalls.
- Wir informieren das Unternehmen darüber, bringen ihnen alle Probleme.
- Wenn sich der Staub verteilt hat, starten wir die Ursachenanalyse, RCA (Root Cause Analysis).
Wir erstellen Vorfallberichte in Jira, es gibt ein entsprechendes Modul,
Vorfälle , wir haben dort eine Reihe zusätzlicher Felder hinzugefügt.
Es gibt nur drei Stufen der RCA.
1. Anfänglicher CinchDies ist die Beschreibung der Ursache des Problems auf oberster Ebene (unabhängig davon, ob es sich um ein Problem mit der Datenbank, der Infrastruktur oder dem Code handelt). Dieser Bericht wird von dem Support-Mitarbeiter erstellt, der den Vorfall verwaltet hat. Der Bericht muss innerhalb von 24 Stunden nach Abschluss des Vorfalls ausgefüllt werden.
2. F & E-RCADer wichtigste Teil des Prozesses muss innerhalb von 48 Stunden nach Abschluss des Vorfalls abgeschlossen sein. Es gibt bereits eine vollständige technische Analyse der Grundursache - warum es passiert ist, warum es nicht entdeckt wurde (Tester übersehen oder es gibt keine angemessene Überwachung), besteht die Möglichkeit, dass es erneut passiert und was zu tun ist, um zu verhindern, dass es erneut auftritt.
3. AktionenBasierend auf dem zweiten Absatz werden die entsprechenden Unteraufgaben gebildet, der Vorfall bleibt offen, bis die letzte dieser Unteraufgaben geschlossen wird. Niemand möchte, dass diese Aufgabe lange Zeit ein Kanban benötigt, daher motiviert dies, alles schneller zu lösen.
So arbeiten wir bei Gett mit Vorfällen.
Zahlen und Technologien
Wir arbeiten natürlich rund um die Uhr mit einem SLA von 99,99%. Der Hauptstapel, den wir auf GoLang / Ruby haben, bietet die notwendige Geschwindigkeit für die Verarbeitung komplexer Algorithmen. Insgesamt gibt es mehr als 150 Microservices, und alle sind auch auf GoLang und Ruby verfügbar. Wir verwenden MySQL, Postgres und Presto als Datenbanken. Wir haben Speicher auf AWS.
Die größte Belastung für unsere Dienstleistungen ist die Neujahrsfeiertage und die vorangegangenen zwei Wochen. Der Zustand der Wettbewerber wirkt sich beispielsweise auch darauf aus, dass einer von ihnen die Anwendung eingestellt hat, was bedeutet, dass unsere Maschinen häufiger aufgerufen werden.
Es gibt auch Spitzen in der internen Arbeit, die sich auf Endbenutzer auswirken. Zum Beispiel, wenn wir die Datenbank aktualisieren oder technische Arbeiten auf der Seite von Lieferanten und Lieferanten ausführen oder neue Services für die Produktion bereitstellen (nicht freitags, ja) oder Funktionen in Auftrag geben, die eine große Anzahl von Benutzern oder Transaktionen sofort betreffen.
Wir sind auch Menschen, und manchmal kommt es vor, dass falsche Einstellungen oder manuelle Eingriffe zu Betriebsfehlern führen. Deshalb haben wir einen Plan für diesen Fall entwickelt:

Nein, das nicht. Hier:
- Wir prüfen Daten in Diensten, Protokollen und Audits.
- Wir testen und führen Update-Vorgänge auf Scrum durch.
- Wir bereiten eine Aufgabe für das Team vor und überwachen die Ausführung der Aufgabe in der Produktion.
Wenn Sie an Details interessiert sind, können Sie in den Kommentaren Fragen stellen. Wir werden diese entweder hier oder in einem separaten ausführlichen Beitrag beantworten.