
Definieren wir zunächst das Konzept der „Warteschlange“.
Berücksichtigen Sie den Warteschlangentyp
„FIFO“ (first in, first out). Wenn Sie den Wert von
Wikipedia übernehmen - "Dies ist ein abstrakter Datentyp mit der Disziplin des Zugriffs auf Elemente." Kurz gesagt bedeutet dies, dass wir keine Daten in zufälliger Reihenfolge abrufen können, sondern nur das aufnehmen, was zuerst kam.
Als nächstes müssen Sie entscheiden, warum sie überhaupt benötigt werden?
1. Für zurückgestellte Operationen. Ein klassisches Beispiel ist die Bildverarbeitung. Zum Beispiel hat ein Benutzer ein Bild auf die Site hochgeladen, die wir verarbeiten müssen. Dieser Vorgang nimmt viel Zeit in Anspruch. Der Benutzer möchte nicht so lange warten. Daher laden wir das Bild und übertragen es in die Warteschlange. Und es wird verarbeitet, wenn ein „Arbeiter“ es bekommt.
2. Für den Umgang mit Spitzenlasten. Zum Beispiel gibt es einen Teil des Systems, der manchmal viel Verkehr verursacht und keine sofortige Antwort erfordert. Optional können Sie Berichte erstellen. Diese Aufgabe in die Warteschlange stellen - wir bieten die Möglichkeit, sie mit einer einheitlichen Belastung des Systems zu bewältigen.
3. Skalierbarkeit. Und wahrscheinlich der wichtigste Grund, die Warteschlange macht es möglich
skalieren. Dies bedeutet, dass Sie mehrere Dienste für die parallele Verarbeitung aufrufen können, was die Produktivität erheblich erhöht.
Schauen wir uns nun die Probleme an, mit denen wir konfrontiert werden, wenn wir die Warteschlange selbst erstellen:
1. Paralleler Zugriff. Nur ein Handler kann eine Nachricht aus einer Warteschlange entgegennehmen. Das heißt, wenn zwei Dienste gleichzeitig nach Nachrichten fragen, muss jeder von ihnen einen eindeutigen Satz von Nachrichten zurückgeben. Andernfalls stellt sich heraus, dass eine Nachricht zweimal verarbeitet wird. Was könnte voll sein.
2. Der Mechanismus der Deduplizierung. Der Dienst sollte über ein System verfügen, das die Warteschlange vor Duplikaten schützt. Es kann vorkommen, dass ein und derselbe Datensatz zweimal zufällig an die Warteschlange gesendet wird. Infolgedessen werden wir dasselbe zweimal verarbeiten. Welches ist wieder voll.
3. Fehlerbehandlungsmechanismus. Angenommen, unser Service hat drei Nachrichten aus der Warteschlange genommen. Zwei davon verarbeitete er erfolgreich, indem er Entfernungsanforderungen aus der Warteschlange sendete. Und der dritte konnte er nicht verarbeiten und starb. Eine Nachricht, die sich im Verarbeitungsstatus befindet, ist für andere Dienste nicht verfügbar. Und es sollte nicht für immer im Verarbeitungsstatus bleiben. Eine solche Nachricht sollte durch eine Logik an einen anderen Handler übergeben werden. Ein Beispiel für die Implementierung dieser Logik wird in Kürze anhand von AWS SQS (Simple Queue Service) betrachtet.
Amazon Web Services - Einfacher Warteschlangendienst
Schauen wir uns nun an, wie SQS diese Probleme löst und was es kann.
1. Paralleler Zugriff. In der Warteschlange können Sie den Parameter
Visibility Timeout festlegen. Es bestimmt, wie lange die Verarbeitung einer Nachricht so lange wie möglich dauern kann. Standardmäßig sind es
30 Sekunden. Wenn ein Dienst eine Nachricht aufnimmt, wird sie 30 Sekunden lang in den Status
"In Flight" versetzt . Wenn während dieser Zeit kein Befehl zum Entfernen dieser Nachricht aus der Warteschlange vorhanden war, kehrt sie zum Anfang zurück und der nächste Dienst kann sie erneut zur Verarbeitung empfangen.
Kleine Shemka-Arbeit.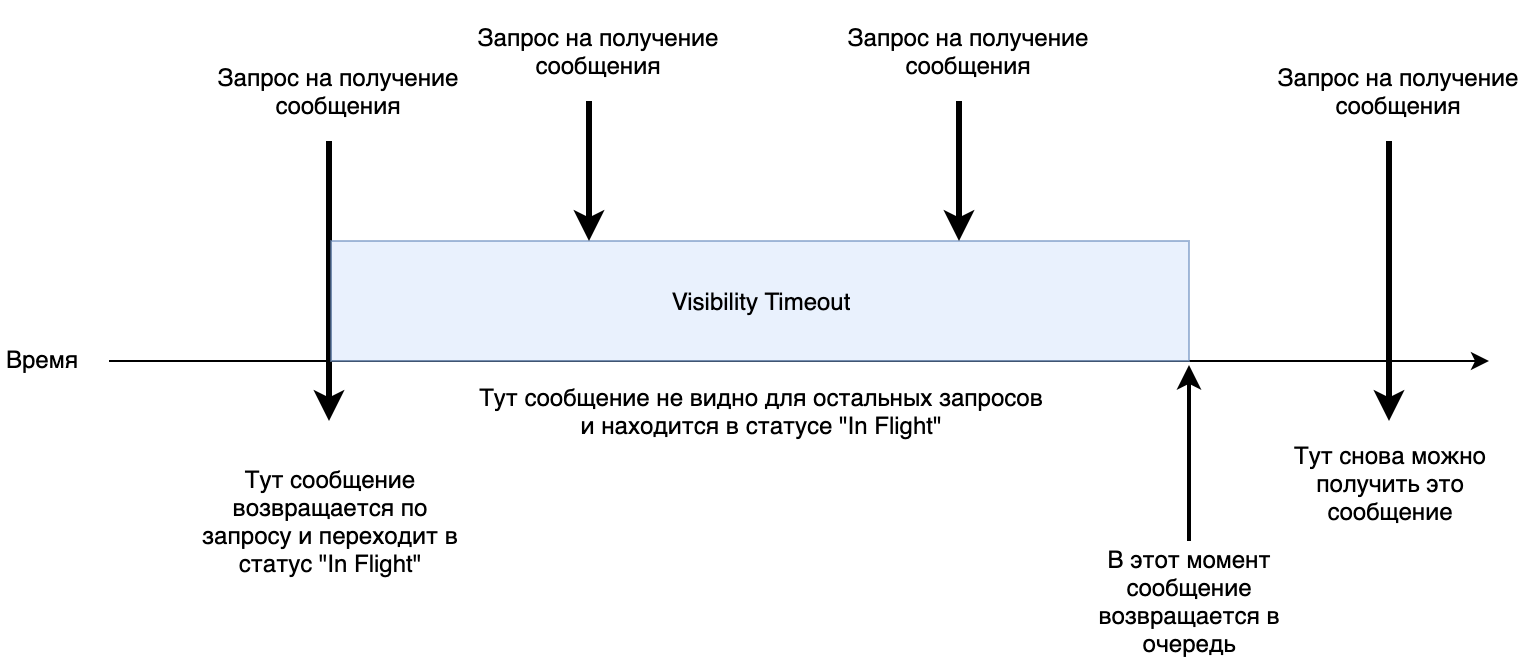
Hinweis: Seien Sie vorsichtig. In einigen Fällen sendet SQS möglicherweise eine doppelte Nachricht (Punkt "Mindestens einmalige Zustellung"). Daher sollte Ihr Dienst für die Verarbeitung idempotent sein .
2. Fehlerbehandlungsmechanismus. In SQS können Sie die zweite Runde für "tote" Nachrichten konfigurieren (Dead Letter Queue). Das heißt, diejenigen, die unseren Service nicht verarbeiten konnten, werden an eine separate Warteschlange gesendet, über die Sie nach eigenem Ermessen verfügen können. Sie können auch festlegen, nach welcher Anzahl erfolgloser Versuche die Nachricht in die Warteschlange "tot" gestellt wird. Ein fehlgeschlagener Versuch ist das Ablaufen des "Sichtbarkeitszeitlimits". Das heißt, wenn während dieser Zeit keine Löschanforderung gesendet wurde, wird eine solche Nachricht als unverarbeitet betrachtet und kehrt in die Hauptwarteschlange zurück oder geht zu den "Toten".
3. Deduplizierung von Nachrichten. SQS hat auch ein doppeltes Schutzsystem. Jede Nachricht hat eine
"Deduplizierungs-ID" . SQS stellt keine Nachricht in die Warteschlange
wiederholte "Deduplizierungs-ID" für 5 Minuten. Sie müssen in jeder Nachricht eine "Deduplizierungs-ID" angeben oder die inhaltsbasierte ID-Generierung aktivieren. Dies bedeutet, dass ein auf der Grundlage Ihres Inhalts generierter Hash in die "Deduplizierungs-ID" gelangt. Der Parameter
"Inhaltsbasierte Deduplizierung". Weitere Informationen zur DeduplizierungHinweis: Seien Sie vorsichtig, wenn Sie innerhalb von 5 Minuten zwei identische Nachrichten senden und die Option "Inhaltsbasierte Deduplizierung" aktiviert ist. SQS fügt der Warteschlange keine zweite Nachricht hinzu.
Hinweis: Seien Sie beispielsweise vorsichtig, wenn auf dem Gerät keine Verbindung besteht und es keine Antwort erhält und nach 5 Minuten eine zweite Anforderung sendet, wird ein Duplikat erstellt.
4. Lange Umfrage. Lange Umfrage . SQS unterstützt diese Art der Verbindung mit einer maximalen Zeitüberschreitung von 20 Sekunden. Was ermöglicht es uns, Verkehr und "Ruckeln" des Dienstes zu sparen.
5. Metriken. Amazon bietet auch detaillierte Warteschlangenmetriken. Wie die Anzahl der empfangenen / gesendeten / gelöschten Nachrichten, die Größe dieser Nachrichten in KB usw. Sie können SQS auch mit dem CloudWatch-Protokolldienst verbinden. Dort kann man noch mehr sehen. Dort können Sie auch die sogenannten
„Alarme“ konfigurieren und Aktionen für beliebige Ereignisse konfigurieren.
Weitere Informationen zum Herstellen einer Verbindung zu SQS. Und
CloudWatch-Dokumentation
Schauen wir uns nun die Einstellungen für die Warteschlange an:
Die wichtigsten:
Standard-Sichtbarkeitszeitlimit - Die Anzahl der Sekunden / Minuten / Stunden, für die die Nachricht nach dem Empfang für den Empfang nicht sichtbar ist. Die maximale Bearbeitungszeit beträgt 12 Stunden.
Aufbewahrungszeitraum für Nachrichten
- Die Anzahl der Sekunden / Minuten / Stunden / Tage. Dies bedeutet, wie lange unverarbeitete Nachrichten in der Warteschlange gespeichert werden. Maximal 14 Tage.
Maximale Nachrichtengröße - Maximale Nachrichtengröße in KB. Der Wert liegt zwischen 1 KB und 256 KB.
Zustellungsverzögerung - Sie können die Verzögerungszeit für die Zustellung einer Nachricht an die Warteschlange festlegen. Von 0 Sekunden bis 15 Minuten (Nachrichten befinden sich zwar in der Warteschlange, sind jedoch für den Empfang nicht sichtbar).
Wartezeit für Nachrichten empfangen - Zeit, wie lange die Verbindung hält, falls wir "Lange Abfrage" verwenden, um neue Nachrichten zu empfangen.
Inhaltsbasierte Deduplizierung - Wenn
das Flag auf true gesetzt ist, wird jeder Nachricht eine „Deduplizierungs-ID“ in Form eines aus dem Inhalt generierten SHA-256-Hash hinzugefügt.
Einstellungen für die tote Warteschlange
Redrive-Richtlinie verwenden - Wenn
ein Flag gesetzt ist, werden Nachrichten nach mehreren Versuchen umgeleitet.
Dead Letter Queue - Der Name der "toten" Warteschlange, an die Rohnachrichten gesendet werden.
Maximaler Empfang - Die Anzahl der erfolglosen Verarbeitungsversuche, nach denen die Nachricht an die "tote" Warteschlange gesendet wird
Hinweis: Beachten Sie auch, dass wir alle Hauptparameter zusammen mit jeder Nachricht separat senden können. Beispielsweise kann jede einzelne Nachricht ein eigenes Sichtbarkeitszeitlimit oder eine eigene Zustellungsverzögerung haben.
Nun ein wenig zu den Nachrichten selbst und ihren Eigenschaften:
Eine Nachricht hat mehrere Parameter:
1. Nachrichtentext - beliebiger Text
2. Die Nachrichtengruppen-ID ist so etwas wie ein Tag, ein Kanal, der für alle Nachrichten erforderlich ist. Es wird garantiert, dass jede solche Gruppe im FIFO-Modus verarbeitet wird.
3. Message Deduplication Id - Zeichenfolge zum Identifizieren von Duplikaten. Wenn der Modus "Inhaltsbasierte Deduplizierung" eingestellt ist, ist der Parameter optional.
Es gibt auch Nachrichtenattribute
Attribute bestehen aus einem Namen, einem Typ und einem Wert.
1. Name - Zeichenfolge
2. Typ - Es gibt verschiedene Typen: Zeichenfolge, Zahl, Binär. Der Typ wird einfach als Zeichenfolge geliefert, und es ist möglich, dem Typ ein Postfix hinzuzufügen. In diesem Fall wird der Typ mit diesem Postfix durch den Punkt geliefert, z. B. string.example_postfix
3. Wert - Zeichenfolge
Hinweis: Bitte beachten Sie, dass die maximale Anzahl von Attributen 10 Details beträgt
PS: Dieser Artikel enthält eine kurze Beschreibung der Warteschlange sowie einige Informationen zu den Funktionen und Mechanismen von SQS. Der folgende Artikel widmet sich
AWS Lambda und anschließend deren praktischem Austausch.