Was ist wichtig für ein Entwicklungsteam, das gerade mit dem Aufbau eines maschinellen Lernsystems beginnt? Architektur, Komponenten, Testfunktionen mithilfe von Integrations- und Komponententests erstellen einen Prototyp und erzielen die ersten Ergebnisse. Und weiter zur Bewertung des Arbeitseinsatzes, zur Planung der Entwicklung und Umsetzung.
Dieser Artikel konzentriert sich auf den Prototyp. Was einige Zeit nach dem Gespräch mit dem Produktmanager erstellt wurde: Warum „berühren“ wir nicht das maschinelle Lernen? Insbesondere NLP und Stimmungsanalyse?
"Warum nicht?" Ich antwortete. Trotzdem mache ich seit mehr als 15 Jahren Backend-Entwicklung. Ich arbeite gerne mit Daten und löse Leistungsprobleme. Aber ich musste immer noch herausfinden, „wie tief das Kaninchenloch ist“.
Komponenten auswählen
Um die Komponenten, die die Logik unseres ML-Kernels implementieren, irgendwie zu skizzieren, werfen wir einen Blick auf ein einfaches Beispiel für die Implementierung der Stimmungsanalyse, eine der vielen auf GitHub verfügbaren.
Ein Beispiel für eine Stimmungsanalyse in Pythonimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
Das Parsen solcher Beispiele ist eine separate Herausforderung für den Entwickler.
Nur 45 Codezeilen und 4 (vier, Karl!) Logische Blöcke gleichzeitig:
- Herunterladen von Daten für das Modelltraining (Zeilen 25-26)
- Hochgeladene Daten vorbereiten - Feature-Extraktion (Zeilen 31-34)
- Modell erstellen und trainieren (Zeilen 36-39)
- Testen eines trainierten Modells und Ausgeben von Ergebnissen (Zeilen 41-45)
Jeder dieser Punkte verdient einen eigenen Artikel. Und es erfordert sicherlich die Registrierung in einem separaten Modul. Zumindest für die Bedürfnisse von Unit-Tests.
Unabhängig davon lohnt es sich, die Komponenten der Datenaufbereitung und des Modelltrainings hervorzuheben.
In jede der Möglichkeiten, das Modell präziser zu machen, werden Hunderte von Stunden wissenschaftlicher und technischer Arbeit investiert.
Glücklicherweise gibt es eine vorgefertigte Lösung, um schnell mit NLP beginnen zu können - die
NLTK- und
TextBlob-Bibliotheken . Der zweite ist ein Wrapper über NLTK, der die Aufgabe übernimmt - das Extrahieren von Features aus dem Trainingssatz und das Trainieren des Modells bei der ersten Klassifizierungsanforderung.
Bevor Sie das Modell trainieren, müssen Sie jedoch Daten dafür vorbereiten.
Daten vorbereiten
Daten herunterladen
Wenn wir über den Prototyp sprechen, ist das Laden von Daten aus einer CSV / TSV-Datei elementar. Sie rufen einfach die Funktion
read_csv aus der Pandas-Bibliothek auf:
import pandas as pd data = pd.read_csv(data_path, delimiter)
Es werden jedoch keine Daten zur Verwendung im Modell bereit sein.
Erstens, wenn wir das CSV-Format ein wenig ignorieren, ist es leicht zu erwarten, dass jede Quelle Daten mit ihren eigenen Eigenschaften liefert, und daher benötigen wir eine Art quellenabhängige Datenaufbereitung. Selbst für den einfachsten Fall einer CSV-Datei müssen wir das Trennzeichen kennen, um sie nur zu analysieren.
Außerdem sollten Sie bestimmen, welche Einträge positiv und welche negativ sind. Diese Informationen werden natürlich in der Anmerkung zu den Datensätzen angegeben, die wir verwenden möchten. Tatsache ist jedoch, dass in einem Fall das Vorzeichen von pos / neg 0 oder 1 ist, im anderen Fall ein logisches Wahr / Falsch, im dritten Fall nur eine pos / neg-Zeichenfolge und in einigen Fällen ein Tupel von ganzen Zahlen von 0 bis 5 Letzteres ist für den Fall der Klassifizierung mehrerer Klassen relevant, aber wer hat gesagt, dass ein solcher Datensatz nicht für die binäre Klassifizierung verwendet werden kann? Sie müssen nur die Grenze zwischen positiven und negativen Werten angemessen identifizieren.
Ich möchte das Modell an verschiedenen Datensätzen testen, und es ist erforderlich, dass das Modell nach dem Training das Ergebnis in einem einzigen Format zurückgibt. Und dafür sollten seine heterogenen Daten in eine einzige Form gebracht werden.
Es gibt also drei Funktionen, die wir beim Laden der Daten benötigen:
- Die Verbindung zur Datenquelle erfolgt für CSV. In unserem Fall ist sie in der Funktion read_csv implementiert.
- Unterstützung für Formatfunktionen;
- Vorläufige Datenaufbereitung.
So sieht es im Code aus.
import numpy as np
Es wurde die Klasse
CsvSentimentDataLoader erstellt, der im Konstruktor der Pfad zu csv, das Trennzeichen, die Namen des Textes und die Klassifizierungsattribute sowie eine Liste von Werten übergeben werden, die den positiven Wert des Textes angeben.
Das Laden selbst erfolgt in der Methode
load_data .
Wir unterteilen die Daten in Test- und Trainingssätze
Ok, wir haben die Daten hochgeladen, aber wir müssen sie noch in die Trainings- und Testsätze aufteilen.
Dies erfolgt mit der Funktion
train_test_split aus der
sklearn- Bibliothek. Diese Funktion kann viele Parameter als Eingabe verwenden und bestimmen, wie genau dieser Datensatz in Zug und Test unterteilt wird. Diese Parameter wirken sich erheblich auf die resultierenden Trainings- und Testsätze aus, und es wird für uns wahrscheinlich zweckmäßig sein, eine Klasse (nennen wir sie SimpleDataSplitter) zu erstellen, die diese Parameter verwaltet und den Aufruf dieser Funktion aggregiert.
from sklearn.model_selection import train_test_split
Jetzt enthält diese Klasse die einfachste Implementierung, die, wenn sie geteilt wird, nur einen Parameter berücksichtigt - den Prozentsatz der Datensätze, die als Testsatz verwendet werden sollten.
Datensätze
Um das Modell zu trainieren, habe ich frei verfügbare Datensätze im CSV-Format verwendet:
Und um es noch bequemer zu machen, habe ich für jeden Datensatz eine Klasse erstellt, die Daten aus der entsprechenden CSV-Datei lädt und in Trainings- und Testsätze aufteilt.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
Ja, beim Laden von Daten stellte sich im ursprünglichen Beispiel heraus, dass etwas mehr als 5 Codezeilen vorhanden waren.
Jetzt ist es jetzt möglich, neue Datensätze zu erstellen, indem Datenquellen und Algorithmen zur Vorbereitung von Trainingssätzen miteinander in Einklang gebracht werden.
Darüber hinaus sind einzelne Komponenten für Unit-Tests wesentlich bequemer.
Wir trainieren das Modell
Das Modell lernt schon seit einiger Zeit. Dies muss einmalig zu Beginn der Anwendung erfolgen.
Zu diesem Zweck wurde ein kleiner Wrapper erstellt, mit dem Sie Daten herunterladen und vorbereiten sowie das Modell zum Zeitpunkt der Anwendungsinitialisierung trainieren können.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
Zuerst erhalten wir Trainings- und Testdaten, dann extrahieren wir Merkmale und schließlich trainieren wir den Klassifikator und überprüfen die Genauigkeit des Testsatzes.
Testen
Bei der Initialisierung erhalten wir ein Protokoll, anhand dessen beurteilt wird, dass die Daten heruntergeladen und das Modell erfolgreich trainiert wurden. Und mit sehr guter (für den Anfang) Genauigkeit trainiert - 0,8878.
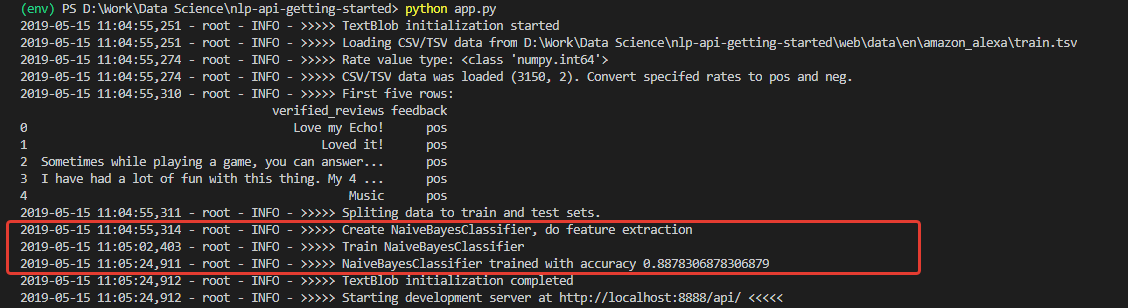
Nachdem ich solche Zahlen erhalten hatte, war ich sehr begeistert. Aber meine Freude ließ leider nicht lange auf sich warten. Das an diesem Set trainierte Modell ist ein undurchdringlicher Optimist und kann im Prinzip negative Kommentare nicht erkennen.
Der Grund dafür liegt in den Trainingssatzdaten. Die Anzahl der positiven Bewertungen im Set liegt bei über 90%. Dementsprechend fallen negative Bewertungen mit einer Modellgenauigkeit von etwa 88% einfach in die erwarteten 12% der falschen Klassifizierungen.
Mit anderen Worten, mit einem solchen Trainingssatz ist es einfach unmöglich, das Modell zu trainieren, um negative Kommentare zu erkennen.
Um dies wirklich sicherzustellen, habe ich einen Komponententest durchgeführt, bei dem die Klassifizierung für 100 positive und 100 negative Phrasen aus einem anderen Datensatz getrennt ausgeführt wird. Zum Testen habe ich den Datensatz mit den
Sentiment Labeled Sentences der University of California verwendet.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
Der Algorithmus zum Testen der Klassifizierung positiver Werte lautet wie folgt:
- Testdaten herunterladen;
- Nimm 100 Beiträge mit dem Tag 'pos'
- Wir führen jeden von ihnen durch das Modell und zählen die Anzahl der korrekten Ergebnisse
- Zeigen Sie das Endergebnis in der Konsole an.
Ebenso werden negative Kommentare gezählt.
Wie erwartet wurden alle negativen Kommentare als positiv bewertet.
Und wenn Sie das Modell anhand des zum Testen verwendeten Datensatzes trainieren -
Sentiment Labeled ? Dort beträgt die Verteilung der negativen und positiven Kommentare genau 50 bis 50.
Ändern Sie den Code und testen Sie, führen Sie Etwas schon. Die tatsächliche Genauigkeit von 200 Einträgen aus einem Satz von Drittanbietern beträgt 76%, während die Genauigkeit der Klassifizierung negativer Kommentare 79% beträgt.
Natürlich reichen 76% für einen Prototyp, aber nicht genug für die Produktion. Dies bedeutet, dass zusätzliche Maßnahmen erforderlich sind, um die Genauigkeit des Algorithmus zu verbessern. Dies ist jedoch ein Thema für einen anderen Bericht.
Zusammenfassung
Erstens haben wir eine Anwendung mit einem Dutzend Klassen und mehr als 200 Codezeilen erhalten, was etwas mehr als das ursprüngliche Beispiel von 30 Zeilen ist. Und Sie sollten ehrlich sein - dies sind nur Hinweise auf die Struktur, die erste Klärung der Grenzen der zukünftigen Anwendung. Prototyp.
Und dieser Prototyp ermöglichte es zu erkennen, wie weit der Abstand zwischen den Ansätzen zum Code aus Sicht der Spezialisten für maschinelles Lernen und aus Sicht der Entwickler traditioneller Anwendungen ist. Und dies ist meiner Meinung nach die Hauptschwierigkeit für Entwickler, die sich für maschinelles Lernen entscheiden.
Das nächste, was Anfänger in Erstaunen versetzen kann - die Daten sind nicht weniger wichtig als das ausgewählte Modell. Dies wurde deutlich gezeigt.
Darüber hinaus besteht immer die Möglichkeit, dass sich ein Modell, das auf einige Daten trainiert wurde, auf anderen Daten nur unzureichend zeigt oder dass sich seine Genauigkeit irgendwann verschlechtert.
Dementsprechend sind Metriken erforderlich, um den Status des Modells, Flexibilität bei der Arbeit mit Daten und technische Fähigkeiten zur Anpassung des Lernens im laufenden Betrieb zu überwachen. Usw.
All dies sollte bei der Gestaltung der Architektur und der Gebäudeentwicklungsprozesse berücksichtigt werden.
Im Allgemeinen war das "Kaninchenloch" nicht nur sehr tief, sondern auch äußerst geschickt verlegt. Umso interessanter ist es für mich als Entwickler, dieses Thema in Zukunft zu studieren.