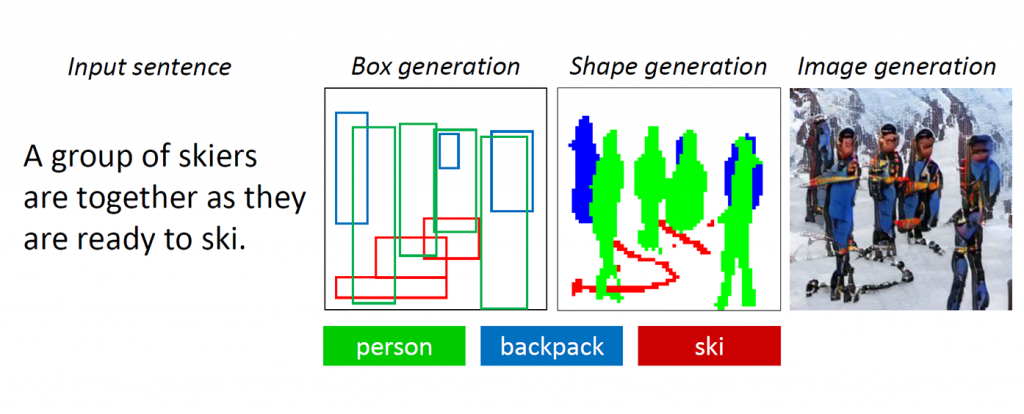
Wenn Sie gebeten würden, ein Bild von mehreren Personen in Skiausrüstung zu zeichnen, die im Schnee stehen, würden Sie wahrscheinlich mit einem Umriss von drei oder vier Personen beginnen, die in der Mitte der Leinwand positioniert sind, und dann die Skier unter ihren skizzieren Füße. Obwohl dies nicht angegeben wurde, können Sie jedem Skifahrer einen Rucksack hinzufügen, um die Erwartungen an die Sportarten der Skifahrer zu erfüllen. Schließlich würden Sie die Details sorgfältig ausfüllen und vielleicht ihre Kleidung blau und ihre Schals rosa vor einem weißen Hintergrund streichen, um diese Personen realistischer zu machen und sicherzustellen, dass ihre Umgebung der Beschreibung entspricht. Um die Szene lebendiger zu gestalten, können Sie sogar einige braune Steine skizzieren, die durch den Schnee ragen, um darauf hinzuweisen, dass sich diese Skifahrer in den Bergen befinden.
Jetzt gibt es einen Bot, der das alles kann.
Die neue KI-Technologie, die bei Microsoft Research AI entwickelt wird, kann eine Beschreibung in natürlicher Sprache verstehen, ein Layout des Bildes skizzieren, das Bild synthetisieren und dann Details basierend auf dem Layout und den einzelnen bereitgestellten Wörtern verfeinern. Mit anderen Worten, dieser Bot kann Bilder aus beschriftungsähnlichen Textbeschreibungen alltäglicher Szenen erzeugen. Dieser absichtliche Mechanismus führte zu einer signifikanten Verbesserung der erzeugten Bildqualität im Vergleich zu der früheren hochmodernen Technik zur Text-zu-Bild-Erzeugung für komplizierte alltägliche Szenen. Dies geht aus Ergebnissen von Industriestandardtests hervor, die in „ Objektgesteuerter Text- to-Image-Synthese durch kontradiktorisches Training “, das diesen Monat in Long Beach, Kalifornien, auf der IEEE-Konferenz 2019 über Computer Vision und Mustererkennung (CVPR 2019) veröffentlicht wird. Dies ist ein Kooperationsprojekt zwischen Pengchuan Zhang , Qiuyuan Huang und Jianfeng Gao von Microsoft Research AI , Lei Zhang von Microsoft, Xiaodong He von JD AI Research und Wenbo Li und Siwei Lyu von der Universität in Albany, SUNY (während Wenbo Li als arbeitete) ein Praktikant bei Microsoft Research AI).
Es gibt zwei Hauptherausforderungen, die mit dem beschreibungsbasierten Zeichenbotproblem verbunden sind. Das erste ist, dass viele Arten von Objekten in alltäglichen Szenen erscheinen können und der Bot in der Lage sein sollte, alle zu verstehen und zu zeichnen. Frühere Verfahren zur Erzeugung von Text zu Bild verwenden Bildunterschriftenpaare, die nur ein sehr grobkörniges Überwachungssignal zum Erzeugen einzelner Objekte liefern, wodurch deren Qualität bei der Objekterzeugung eingeschränkt wird. Bei dieser neuen Technologie verwenden die Forscher den COCO-Datensatz, der Beschriftungen und Segmentierungskarten für 1,5 Millionen Objektinstanzen in 80 gängigen Objektklassen enthält, sodass der Bot sowohl das Konzept als auch das Erscheinungsbild dieser Objekte lernen kann. Dieses feinkörnige überwachte Signal für die Objekterzeugung verbessert die Erzeugungsqualität für diese allgemeinen Objektklassen erheblich.
Die zweite Herausforderung besteht im Verständnis und der Erzeugung der Beziehungen zwischen mehreren Objekten in einer Szene. Es wurden große Erfolge bei der Erzeugung von Bildern erzielt, die nur ein Hauptobjekt für mehrere bestimmte Domänen enthalten, z. B. Gesichter, Vögel und gemeinsame Objekte. Das Erzeugen komplexerer Szenen mit mehreren Objekten mit semantisch bedeutsamen Beziehungen zwischen diesen Objekten bleibt jedoch eine bedeutende Herausforderung in der Text-zu-Bild-Generierungstechnologie. Dieser neue Zeichnungsbot hat gelernt, das Layout von Objekten aus Mustern des gemeinsamen Auftretens im COCO-Datensatz zu generieren, um dann ein Bild zu generieren, das vom vorgenerierten Layout abhängig ist.
Objektgesteuerte, aufmerksame Bilderzeugung
Das Herzstück des Zeichenbot von Microsoft Research AI ist eine Technologie, die als Generative Adversarial Network (GAN) bekannt ist. Das GAN besteht aus zwei Modellen für maschinelles Lernen - einem Generator, der Bilder aus Textbeschreibungen generiert, und einem Diskriminator, der Textbeschreibungen verwendet, um die Authentizität der generierten Bilder zu beurteilen. Der Generator versucht, gefälschte Bilder am Diskriminator vorbei zu bringen. Der Diskriminator hingegen will sich niemals täuschen lassen. Zusammen arbeitet der Diskriminator den Generator in Richtung Perfektion.
Der Zeichnungsbot wurde an einem Datensatz von 100.000 Bildern mit jeweils hervorstechenden Objektbeschriftungen und Segmentierungskarten sowie fünf verschiedenen Beschriftungen trainiert, sodass die Modelle einzelne Objekte und semantische Beziehungen zwischen Objekten konzipieren konnten. Das GAN lernt zum Beispiel, wie ein Hund aussehen soll, wenn Bilder mit und ohne Hundebeschreibungen verglichen werden.

Abbildung 1: Eine komplexe Szene mit mehreren Objekten und Beziehungen.
GANs funktionieren gut, wenn Bilder erzeugt werden, die nur ein hervorstechendes Objekt enthalten, z. B. ein menschliches Gesicht, Vögel oder Hunde. Die Qualität stagniert jedoch bei komplexeren Alltagsszenen, wie z. B. „Eine Frau mit Helm reitet auf einem Pferd“ (siehe Abbildung) 1.) Dies liegt daran, dass solche Szenen mehrere Objekte (Frau, Helm, Pferd) und reichhaltige semantische Beziehungen zwischen ihnen enthalten (Frau trägt Helm, Frau reitet Pferd). Der Bot muss zuerst diese Konzepte verstehen und sie mit einem aussagekräftigen Layout im Bild platzieren. Danach ist ein besser überwachtes Signal erforderlich, das die Objekterzeugung und die Layouterzeugung lehren kann, um diese Aufgabe des Sprachverständnisses und der Bilderzeugung zu erfüllen.
Wenn Menschen diese komplizierten Szenen zeichnen, entscheiden wir uns zunächst für die zu zeichnenden Hauptobjekte und erstellen ein Layout, indem wir Begrenzungsrahmen für diese Objekte auf der Leinwand platzieren. Dann konzentrieren wir uns auf jedes Objekt, indem wir wiederholt die entsprechenden Wörter überprüfen, die dieses Objekt beschreiben. Um dieses menschliche Merkmal zu erfassen, haben die Forscher ein sogenanntes objektgesteuertes aufmerksames GAN (ObjGAN) erstellt, um das menschliche Verhalten objektzentrierter Aufmerksamkeit mathematisch zu modellieren. ObjGAN zerlegt den Eingabetext in einzelne Wörter und ordnet diese Wörtern bestimmten Objekten im Bild zu.
Menschen überprüfen normalerweise zwei Aspekte, um die Zeichnung zu verfeinern: den Realismus einzelner Objekte und die Qualität von Bildfeldern. ObjGAN ahmt dieses Verhalten ebenfalls nach, indem es zwei Diskriminatoren einführt - einen objektbezogenen Diskriminator und einen patchweisen Diskriminator. Der objektbezogene Diskriminator versucht festzustellen, ob das erzeugte Objekt realistisch ist oder nicht und ob das Objekt mit der Satzbeschreibung übereinstimmt. Der Patch-weise Diskriminator versucht festzustellen, ob dieser Patch realistisch ist oder nicht und ob dieser Patch mit der Satzbeschreibung übereinstimmt.
Verwandte Arbeiten: Visualisierung von Geschichten
Hochmoderne Modelle zur Erzeugung von Text zu Bild können realistische Vogelbilder basierend auf einer Beschreibung mit einem Satz erzeugen. Die Erzeugung von Text zu Bild kann jedoch weit über die Synthese eines einzelnen Bildes auf der Grundlage eines Satzes hinausgehen. In „ StoryGAN: Ein sequentielles bedingtes GAN für die Visualisierung von Geschichten “ haben Jianfeng Gao von Microsoft Research zusammen mit Zhe Gan, Jingjing Liu und Yu Cheng von Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson und Lawrence Carin von der Duke University, Yelong Shen of Tencent AI Research und Yuexin Wu von der Carnegie Mellon University gehen noch einen Schritt weiter und schlagen eine neue Aufgabe mit dem Namen Story Visualization vor. Bei einem Absatz mit mehreren Sätzen kann eine vollständige Geschichte visualisiert werden, wobei eine Folge von Bildern erzeugt wird, eines für jeden Satz. Dies ist eine herausfordernde Aufgabe, da der Zeichenbot nicht nur ein Szenario vorstellen muss, das zur Geschichte passt, die Interaktionen zwischen verschiedenen Charakteren in der Geschichte modellieren muss, sondern auch in der Lage sein muss, die globale Konsistenz über dynamische Szenen und Charaktere hinweg aufrechtzuerhalten. Diese Herausforderung wurde durch keine einzelnen Bild- oder Videoerzeugungsmethoden angegangen.
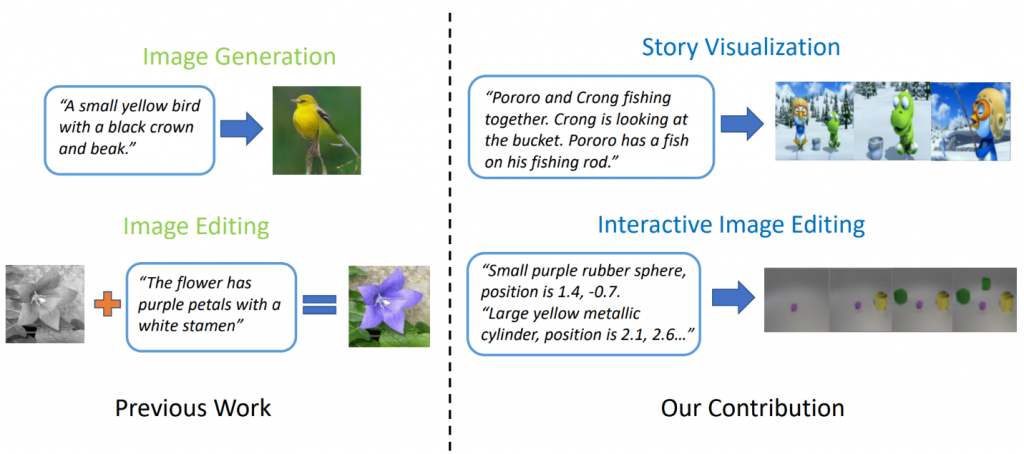
Abbildung 2: Story-Visualisierung vs. einfache Bilderzeugung.
Die Forscher entwickelten ein neues Modell zur Generierung von Story-to-Image-Sequenzen, StoryGAN, das auf dem sequentiellen bedingten GAN-Framework basiert. Dieses Modell ist insofern einzigartig, als es aus einem Deep Context Encoder besteht, der den Story-Fluss dynamisch verfolgt, und zwei Diskriminatoren auf Story- und Bildebene, um die Bildqualität und die Konsistenz der generierten Sequenzen zu verbessern. StoryGAN kann natürlich auch für die interaktive Bildbearbeitung erweitert werden, wobei ein Eingabebild basierend auf den Textanweisungen nacheinander bearbeitet werden kann. In diesem Fall dient eine Folge von Benutzeranweisungen als "Story" -Eingabe. Dementsprechend modifizierten die Forscher vorhandene Datensätze, um die CLEVR-SV- und Pororo-SV-Datensätze zu erstellen, wie in Abbildung 2 dargestellt.
Praktische Anwendungen - eine echte Geschichte
Die Technologie zur Erzeugung von Text zu Bild könnte praktische Anwendungen finden, die als eine Art Skizzenassistent für Maler und Innenarchitekten oder als Werkzeug für die sprachaktivierte Fotobearbeitung dienen. Mit mehr Rechenleistung stellen sich die Forscher die Technologie vor, mit der Animationsfilme auf der Grundlage von Drehbüchern erstellt werden. Dies erweitert die Arbeit der Animationsfilmer, indem ein Teil der manuellen Arbeit entfällt.
Die generierten Bilder sind vorerst noch weit von fotorealistisch entfernt. Einzelne Objekte weisen fast immer Fehler auf, z. B. verschwommene Gesichter und / oder Busse mit verzerrten Formen. Diese Mängel sind ein klarer Hinweis darauf, dass ein Computer, kein Mensch, die Bilder erstellt hat. Trotzdem ist die Qualität der ObjGAN-Bilder deutlich besser als die der bisher besten GAN-Bilder ihrer Klasse und dient als Meilenstein auf dem Weg zu einer generischen, menschenähnlichen Intelligenz, die die menschlichen Fähigkeiten erweitert.
Damit KIs und Menschen dieselbe Welt teilen können, muss jeder eine Möglichkeit haben, miteinander zu interagieren. Sprache und Vision sind die beiden wichtigsten Modalitäten für die Interaktion von Mensch und Maschine. Die Text-zu-Bild-Generierung ist eine wichtige Aufgabe, die die multimodale Intelligenzforschung für Sprachvision vorantreibt.
Die Forscher, die diese aufregende Arbeit geschaffen haben, freuen sich darauf, diese Ergebnisse mit den Teilnehmern des CVPR in Long Beach zu teilen und zu hören, was Sie denken. In der Zwischenzeit können Sie sich den Open-Source-Code für ObjGAN und StoryGAN auf GitHub ansehen