In dem Artikel werde ich Ihnen erzählen, wie wir das Problem der PostgreSQL-Fehlertoleranz angegangen sind, warum dies für uns wichtig geworden ist und was am Ende passiert ist.
Wir haben einen hoch ausgelasteten Service: 2,5 Millionen Benutzer weltweit, mehr als 50.000 aktive Benutzer pro Tag. Die Server befinden sich in Amazone in einer Region Irlands: Es sind ständig mehr als 100 verschiedene Server in Betrieb, von denen fast 50 über Datenbanken verfügen.
Das gesamte Backend ist eine große monolithische Stateful-Java-Anwendung, die eine konstante Websocket-Verbindung zum Client aufrechterhält. Bei gleichzeitiger Arbeit mehrerer Benutzer auf einer Karte sehen alle die Änderungen in Echtzeit, da wir jede Änderung in der Datenbank aufzeichnen. Wir haben ungefähr 10.000 Anfragen pro Sekunde an unsere Datenbanken. Bei Spitzenlast in Redis schreiben wir mit 80-100.000 Abfragen pro Sekunde.

Warum wir von Redis zu PostgreSQL gewechselt sind
Zunächst arbeitete unser Service mit Redis zusammen, einem Schlüsselwert-Repository, in dem alle Daten im RAM des Servers gespeichert sind.
Vorteile von Redis:
- Hohe Rücklaufquote, as alles ist im Speicher gespeichert;
- Bequeme Sicherung und Replikation.
Nachteile Redis für uns:
- Es gibt keine echten Transaktionen. Wir haben versucht, sie auf der Ebene unserer Anwendung zu simulieren. Leider funktionierte dies nicht immer gut und erforderte das Schreiben von sehr komplexem Code.
- Die Datenmenge ist durch die Speichermenge begrenzt. Mit zunehmender Datenmenge wächst der Speicher, und am Ende werden wir auf die Merkmale der ausgewählten Instanz stoßen, für die in AWS der Dienst angehalten werden muss, um den Instanztyp zu ändern.
- Es ist notwendig, ständig eine niedrige Latenz aufrechtzuerhalten, da Wir haben sehr viele Anfragen. Der optimale Verzögerungspegel für uns beträgt 17-20 ms. Auf der Ebene von 30-40 ms erhalten wir lange Antworten auf die Anforderungen unserer Anwendung und die Verschlechterung des Dienstes. Leider geschah dies bei uns im September 2018, als eine der Redis-Instanzen aus irgendeinem Grund eine zweimal höhere Latenz als gewöhnlich erhielt. Um das Problem zu lösen, haben wir den Service mitten am Tag wegen außerplanmäßiger Wartung eingestellt und die problematische Redis-Instanz ersetzt.
- Es ist leicht, Dateninkonsistenzen zu erhalten, selbst bei geringfügigen Fehlern im Code, und dann viel Zeit damit zu verbringen, Code zu schreiben, um diese Daten zu korrigieren.
Wir haben die Nachteile berücksichtigt und festgestellt, dass wir zu etwas Bequemerem übergehen müssen, mit normalen Transaktionen und weniger Abhängigkeit von der Latenz. Durchführung einer Studie, Analyse vieler Optionen und Auswahl von PostgreSQL.
Wir sind seit 1,5 Jahren in eine neue Datenbank umgezogen und haben nur einen kleinen Teil der Daten übertragen. Jetzt arbeiten wir gleichzeitig mit Redis und PostgreSQL. Weitere Informationen zu den Phasen des Verschiebens und Wechselns von Daten zwischen Datenbanken finden Sie in einem
Artikel meines Kollegen .
Als wir gerade mit dem Umzug begannen, arbeitete unsere Anwendung direkt mit der Datenbank und wandte sich an den Redis- und PostgreSQL-Assistenten. Der PostgreSQL-Cluster bestand aus einem Master- und einem asynchronen Replikatreplikat. So sah das Datenbankoperationsschema aus:
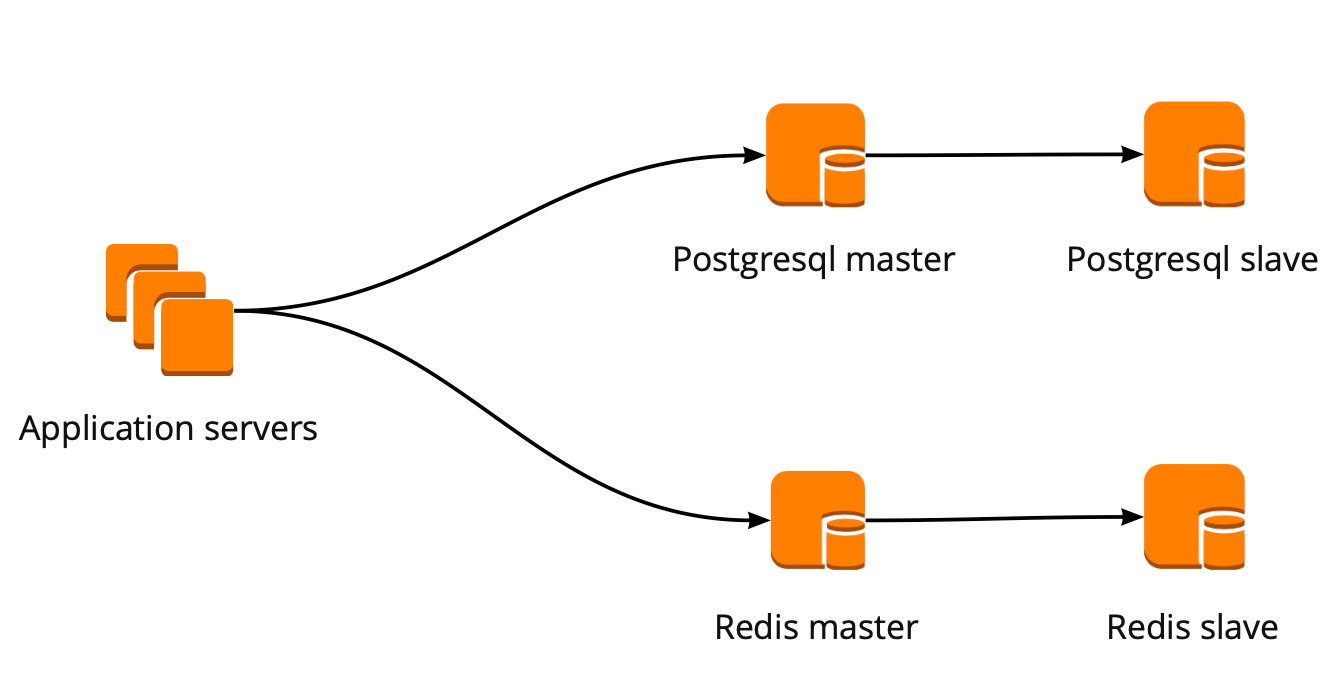
PgBouncer-Bereitstellung
Während wir umzogen, entwickelte sich auch das Produkt: Die Anzahl der Benutzer und die Anzahl der Server, die mit PostgreSQL arbeiteten, nahmen zu, und wir begannen, Verbindungen zu verpassen. PostgreSQL erstellt für jede Verbindung einen eigenen Prozess und verbraucht Ressourcen. Sie können die Anzahl der Verbindungen bis zu einem bestimmten Punkt erhöhen, andernfalls besteht die Möglichkeit, dass der Datenbankbetrieb nicht optimal ist. Die ideale Option in dieser Situation wäre die Wahl eines Verbindungsmanagers, der vor der Basis steht.
Wir hatten zwei Optionen für den Verbindungsmanager: Pgpool und PgBouncer. Der erste unterstützt jedoch nicht den Transaktionsmodus für die Arbeit mit der Datenbank. Daher haben wir uns für PgBouncer entschieden.
Wir haben das folgende Arbeitsschema eingerichtet: Unsere Anwendung greift auf einen PgBouncer zu, gefolgt von Masters PostgreSQL, und hinter jedem Master ein Replikat mit asynchroner Replikation.

Gleichzeitig konnten wir nicht die gesamte Datenmenge in PostgreSQL speichern, und die Geschwindigkeit der Arbeit mit der Datenbank war für uns wichtig. Daher haben wir begonnen, PostgreSQL auf Anwendungsebene zu sharden. Das oben beschriebene Schema ist hierfür relativ praktisch: Wenn Sie einen neuen PostgreSQL-Shard hinzufügen, reicht es aus, die PgBouncer-Konfiguration zu aktualisieren, und die Anwendung kann sofort mit dem neuen Shard arbeiten.
PgBouncer-Fehlertoleranz
Dieses Schema funktionierte, bis die einzige PgBouncer-Instanz starb. Wir befinden uns in AWS, wo alle Instanzen auf Hardware ausgeführt werden, die regelmäßig ausfällt. In solchen Fällen wechselt die Instanz einfach auf die neue Hardware und funktioniert wieder. Dies geschah mit PgBouncer, war jedoch nicht mehr verfügbar. Das Ergebnis dieses Herbstes war die Unzugänglichkeit unseres Dienstes für 25 Minuten. AWS empfiehlt die Verwendung von Redundanz auf der Benutzerseite für solche Situationen, die zu diesem Zeitpunkt bei uns nicht implementiert wurden.
Danach haben wir ernsthaft über die Fehlertoleranz von PgBouncer- und PostgreSQL-Clustern nachgedacht, da eine ähnliche Situation bei jeder Instanz in unserem AWS-Konto erneut auftreten kann.
Wir haben das PgBouncer-Fehlertoleranzschema wie folgt erstellt: Alle Anwendungsserver greifen auf den Network Load Balancer zu, hinter dem sich zwei PgBouncer befinden. Jeder PgBouncer betrachtet den gleichen Master-PostgreSQL jedes Shards. Wenn die AWS-Instanz erneut abstürzt, wird der gesamte Datenverkehr über einen anderen PgBouncer umgeleitet. Fehlertoleranz Network Load Balancer bietet AWS.
Mit diesem Schema können Sie problemlos neue PgBouncer-Server hinzufügen.

Erstellen eines PostgreSQL-Failoverclusters
Bei der Lösung dieses Problems haben wir verschiedene Optionen berücksichtigt: selbst geschriebenes Failover, repmgr, AWS RDS, Patroni.
Selbstgeschriebene Skripte
Sie können die Arbeit des Masters überwachen und im Falle eines Sturzes das Replikat zum Master hochstufen und die Konfiguration von PgBouncer aktualisieren.
Die Vorteile dieses Ansatzes sind maximale Einfachheit, da Sie selbst Skripte schreiben und genau verstehen, wie sie funktionieren.
Nachteile:
- Der Master stirbt möglicherweise nicht, stattdessen kann ein Netzwerkfehler auftreten. Ohne dies zu wissen, wird das Replikat an den Master weitergeleitet, und der alte Master arbeitet weiter. Infolgedessen erhalten wir zwei Server als Master und wissen nicht, welcher von ihnen die neuesten tatsächlichen Daten enthält. Diese Situation wird auch als Split-Brain bezeichnet.
- Wir hatten keine Nachbildung. In unserer Konfiguration werden der Master und ein Replikat nach dem Umschalten des Replikats auf den Master verschoben, und wir haben keine Replikate mehr. Daher müssen wir manuell ein neues Replikat hinzufügen.
- Wir benötigen eine zusätzliche Überwachung des Failover-Vorgangs, während wir 12 PostgreSQL-Shards haben, was bedeutet, dass wir 12 Cluster überwachen müssen. Wenn Sie die Anzahl der Shards erhöhen, müssen Sie immer noch daran denken, das Failover zu aktualisieren.
Selbst geschriebenes Failover sieht sehr kompliziert aus und erfordert nicht triviale Unterstützung. Mit einem einzelnen PostgreSQL-Cluster ist dies die einfachste Option, die jedoch nicht skaliert werden kann und daher für uns nicht geeignet ist.
Repmgr
Replication Manager für PostgreSQL-Cluster, der den Betrieb eines PostgreSQL-Clusters verwalten kann. Gleichzeitig gibt es kein automatisches Failover "out of the box", sodass Sie für die Arbeit Ihren eigenen "Wrapper" auf die fertige Lösung schreiben müssen. Daher kann alles noch komplizierter werden als bei selbst geschriebenen Skripten. Deshalb haben wir Repmgr nicht einmal ausprobiert.
AWS RDS
Es unterstützt alles, was Sie für uns benötigen, kann sichern und unterstützt einen Verbindungspool. Es verfügt über eine automatische Umschaltung: Beim Tod des Masters wird das Replikat zum neuen Master, und AWS ändert den DNS-Datensatz in den neuen Master, während sich die Replikate in verschiedenen AZs befinden können.
Zu den Nachteilen gehört das Fehlen subtiler Einstellungen. Als Beispiel für die Feinabstimmung: In unseren Fällen gibt es Einschränkungen für TCP-Verbindungen, die in RDS leider nicht möglich sind:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
Darüber hinaus ist der AWS RDS-Preis fast doppelt so hoch wie der reguläre Instanzpreis, was der Hauptgrund für die Ablehnung dieser Entscheidung war.
Patroni
Dies ist eine Python-Vorlage zum Verwalten von PostgreSQL mit guter Dokumentation, automatischem Failover und Github-Quellcode.
Vorteile von Patroni:
- Jeder Konfigurationsparameter ist gezeichnet, es ist klar, wie es funktioniert;
- Das automatische Failover funktioniert sofort.
- Es ist in Python geschrieben, und da wir selbst viel in Python schreiben, wird es für uns einfacher sein, mit Problemen umzugehen und möglicherweise sogar bei der Entwicklung des Projekts zu helfen.
- Es steuert PostgreSQL vollständig, ermöglicht es Ihnen, die Konfiguration auf allen Knoten des Clusters gleichzeitig zu ändern. Wenn ein Neustart des Clusters erforderlich ist, um die neue Konfiguration anzuwenden, kann dies mithilfe von Patroni erneut durchgeführt werden.
Nachteile:
- Aus der Dokumentation geht nicht hervor, wie mit PgBouncer gearbeitet werden soll. Obwohl es schwierig ist, es als Minus zu bezeichnen, besteht die Aufgabe von Patroni darin, PostgreSQL zu verwalten, und wie die Verbindungen zu Patroni verlaufen, ist unser Problem.
- Es gibt nur wenige Beispiele für die Implementierung von Patroni in großen Mengen, während es viele Beispiele für die Implementierung von Grund auf gibt.
Um einen Failover-Cluster zu erstellen, haben wir Patroni ausgewählt.
Patroni-Implementierungsprozess
Vor Patroni hatten wir 12 PostgreSQL-Shards in der Konfiguration, einen Master und ein Replikat mit asynchroner Replikation. Anwendungsserver haben über den Network Load Balancer auf die Datenbanken zugegriffen, hinter dem zwei Instanzen mit PgBouncer standen, und alle PostgreSQL-Server waren dahinter.
Um Patroni zu implementieren, mussten wir ein verteiltes Cluster-Konfigurations-Repository auswählen. Patroni arbeitet mit verteilten Konfigurationsspeichersystemen wie etcd, Zookeeper, Consul. Wir haben nur einen vollwertigen Consul-Cluster auf dem Produkt, der in Verbindung mit Vault funktioniert, und wir verwenden ihn nicht mehr. Ein guter Grund, Consul für den vorgesehenen Zweck zu verwenden.
Wie Patroni mit dem Konsul zusammenarbeitet
Wir haben einen Consul-Cluster, der aus drei Knoten besteht, und einen Patroni-Cluster, der aus einem Leader und einem Replikat besteht (in Patroni wird ein Master als Cluster-Leader und Slaves als Replicas bezeichnet). Jede Instanz eines Patroni-Clusters sendet ständig Informationen zum Clusterstatus an Consul. Daher können Sie vom Konsul aus immer die aktuelle Konfiguration des Patroni-Clusters herausfinden und herausfinden, wer derzeit der Anführer ist.

Um Patroni mit Consul zu verbinden, reicht es aus, die offizielle Dokumentation zu lesen, in der angegeben ist, dass Sie den Host im http- oder https-Format angeben müssen, je nachdem, wie wir mit Consul arbeiten, und optional das Verbindungsschema:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
Es sieht einfach aus, aber hier beginnen Fallstricke. Mit Consul arbeiten wir an einer sicheren Verbindung über https und unsere Verbindungskonfiguration sieht folgendermaßen aus:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Das geht aber nicht Zu Beginn kann Patroni keine Verbindung zu Consul herstellen, da es trotzdem versucht, http zu folgen.
Der Quellcode für Patroni half bei der Lösung des Problems. Gut, dass es in Python geschrieben ist. Es stellt sich heraus, dass der Host-Parameter überhaupt nicht analysiert wird und das Protokoll im Schema angegeben werden muss. Hier ist der Arbeitskonfigurationsblock für die Zusammenarbeit mit Consul:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Konsul-Vorlage
Daher haben wir Speicher für eine Konfiguration ausgewählt. Jetzt müssen Sie verstehen, wie PgBouncer seine Konfiguration ändert, wenn Sie den Leader im Patroni-Cluster ändern. Die Dokumentation beantwortet diese Frage nicht, weil Dort wird die Arbeit mit PgBouncer grundsätzlich nicht beschrieben.
Auf der Suche nach einer Lösung haben wir einen Artikel gefunden (ich erinnere mich leider nicht an den Namen), in dem geschrieben wurde, dass die Consul-Vorlage bei der Verbindung von PgBouncer und Patroni sehr hilfreich war. Dies veranlasste uns, die Arbeit der Konsul-Vorlage zu studieren.
Es stellte sich heraus, dass die Consul-Vorlage die Konfiguration des PostgreSQL-Clusters in Consul ständig überwacht. Wenn sich der Leader ändert, aktualisiert er die PgBouncer-Konfiguration und sendet einen Befehl zum Neustart.
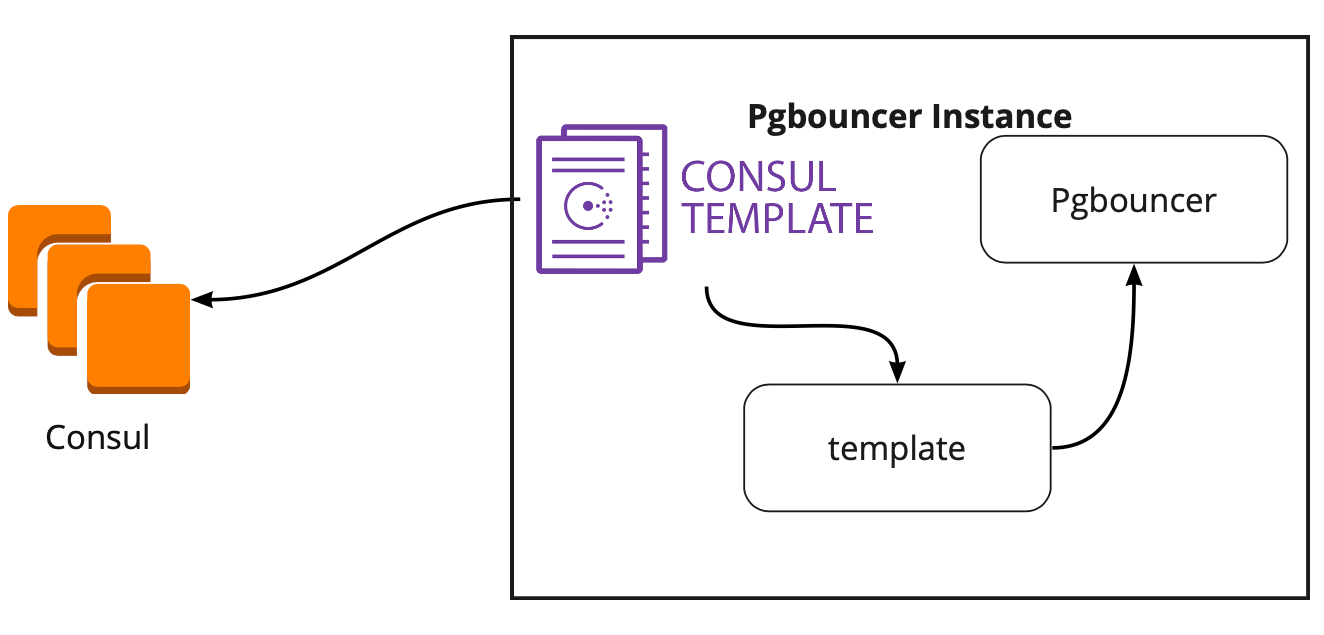
Das große Plus der Vorlage ist, dass sie als Code gespeichert wird. Wenn Sie also einen neuen Shard hinzufügen, reicht es aus, ein neues Commit durchzuführen und die Vorlage im automatischen Modus zu aktualisieren, wobei das Prinzip der Infrastruktur als Code unterstützt wird.
Neue Architektur mit Patroni
Als Ergebnis haben wir dieses Arbeitsschema erhalten:

Alle Anwendungsserver greifen auf den Balancer zu → zwei PgBouncer-Instanzen befinden sich dahinter → Auf jeder Instanz wird eine ulonsul-Vorlage gestartet, die den Status jedes Patroni-Clusters überwacht und die Relevanz der PgBouncer-Konfiguration überwacht, die Anforderungen an den aktuellen Leiter jedes Clusters sendet.
Manuelle Prüfung
Vor dem Start des Programms haben wir diese Schaltung in einer kleinen Testumgebung gestartet und die Funktion der automatischen Umschaltung überprüft. Sie öffneten das Brett, bewegten den Aufkleber und "töteten" in diesem Moment den Anführer des Clusters. Deaktivieren Sie in AWS die Instanz einfach über die Konsole.

Der Aufkleber kehrte innerhalb von 10 bis 20 Sekunden zurück und begann sich wieder normal zu bewegen. Dies bedeutet, dass der Patroni-Cluster ordnungsgemäß funktioniert hat: Er hat den Anführer geändert, die Informationen an Consul gesendet, und die Consul-Vorlage hat diese Informationen sofort erfasst, die PgBouncer-Konfiguration ersetzt und den Befehl zum erneuten Laden gesendet.
Wie kann man unter hoher Last überleben und minimale Ausfallzeiten einhalten?
Alles funktioniert super! Es stellen sich aber neue Fragen: Wie funktioniert es unter hoher Last? Wie kann man schnell und sicher alles in die Produktion rollen?
Die Testumgebung, in der wir Lasttests durchführen, hilft uns bei der Beantwortung der ersten Frage. Es ist völlig identisch mit der Produktion in der Architektur und hat Testdaten generiert, deren Volumen ungefähr dem der Produktion entspricht. Wir beschließen, nur einen der PostgreSQL-Assistenten während des Tests zu "töten" und zu sehen, was passiert. Zuvor ist es jedoch wichtig, das automatische Rollen zu überprüfen, da wir in dieser Umgebung mehrere PostgreSQL-Shards haben, sodass wir vor dem Verkauf hervorragende Tests der Konfigurationsskripte erhalten.
Beide Aufgaben sehen ehrgeizig aus, aber wir haben PostgreSQL 9.6. Vielleicht werden wir sofort auf 11.2 upgraden?
Wir beschließen, dies in zwei Schritten zu tun: zuerst ein Upgrade auf 11.2, dann Patroni.
PostgreSQL-Update
Um die Version von PostgreSQL schnell zu aktualisieren, müssen Sie die Option
-k verwenden , mit der ein fester Link auf der Festplatte erstellt wird und Ihre Daten nicht kopiert werden müssen. Bei einer Basis von 300-400 GB dauert das Update 1 Sekunde.
Wir haben viele Shards, daher muss das Update automatisch durchgeführt werden. Zu diesem Zweck haben wir ein Ansible-Playbook geschrieben, das den gesamten Aktualisierungsprozess für uns ausführt:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
Hierbei ist zu beachten, dass vor dem Starten des Upgrades das
Programm mit dem Parameter
--check ausgeführt werden muss, um die Möglichkeit eines Upgrades zu
gewährleisten . Unser Skript ersetzt auch das Upgrade durch Konfigurationen. Das Skript, das wir in 30 Sekunden fertiggestellt haben, ist ein hervorragendes Ergebnis.
Starten Sie Patroni
Um das zweite Problem zu lösen, schauen Sie sich einfach die Konfiguration von Patroni an. Im offiziellen Repository gibt es eine Beispielkonfiguration mit initdb, die für die Initialisierung einer neuen Datenbank beim ersten Start von Patroni verantwortlich ist. Da wir jedoch eine vorgefertigte Datenbank haben, haben wir diesen Abschnitt gerade aus der Konfiguration gelöscht.
Als wir Patroni auf einem vorgefertigten PostgreSQL-Cluster installierten und ausführten, hatten wir ein neues Problem: Beide Server wurden als Leader gestartet. Patroni weiß nichts über den frühen Status des Clusters und versucht, beide Server als zwei separate Cluster mit demselben Namen zu starten. Löschen Sie das Datenverzeichnis auf dem Slave, um dieses Problem zu beheben:
rm -rf /var/lib/postgresql/
Dies darf nur am Sklaven erfolgen!Wenn Sie ein sauberes Replikat verbinden, erstellt Patroni einen Basebackup-Leader, stellt das Replikat wieder her und holt den aktuellen Status durch Wal-Logs ein.
Eine weitere Schwierigkeit besteht darin, dass alle PostgreSQL-Cluster standardmäßig als main bezeichnet werden. Wenn jeder Cluster nichts über den anderen weiß, ist dies normal. Wenn Sie jedoch Patroni verwenden möchten, müssen alle Cluster einen eindeutigen Namen haben. Die Lösung besteht darin, den Clusternamen in der PostgreSQL-Konfiguration zu ändern.
Belastungstest
Wir haben einen Test gestartet, der die Arbeit der Benutzer auf den Boards simuliert. Als die Last unseren durchschnittlichen Tageswert erreichte, wiederholten wir genau denselben Test und schalteten eine Instanz mit dem Leiter PostgreSQL aus. Das automatische Failover funktionierte wie erwartet: Patroni wechselte den Leader, Consul-template aktualisierte die Konfiguration von PgBouncer und schickte den Befehl zum Neuladen. Laut unseren Grafiken in Grafana war klar, dass es Verzögerungen von 20 bis 30 Sekunden und eine kleine Anzahl von Fehlern von Servern im Zusammenhang mit der Verbindung zur Datenbank gibt. Dies ist eine normale Situation. Solche Werte gelten für unser Failover und sind definitiv besser als die Ausfallzeit des Dienstes.
Patronis Produktion
Als Ergebnis haben wir folgenden Plan erhalten:
- Stellen Sie die Consul-Vorlage auf dem PgBouncer-Server bereit und starten Sie sie.
- PostgreSQL-Updates auf Version 11.2;
- Änderung des Clusternamens;
- Starten eines Patroni-Clusters.
Gleichzeitig können Sie mit unserem Schema fast jederzeit das erste Element erstellen. Wir können abwechselnd jeden PgBouncer von der Arbeit entfernen und eine Bereitstellung darauf ausführen und die Konsul-Vorlage starten. Also haben wir es getan.
Für ein schnelles Rollen haben wir Ansible verwendet, da wir bereits das gesamte Playbook in einer Testumgebung überprüft haben und die Ausführungszeit des vollständigen Skripts für jeden Shard zwischen 1,5 und 2 Minuten betrug. Wir könnten alles abwechselnd für jeden Shard ausrollen, ohne unseren Service zu beenden, aber wir müssten jedes PostgreSQL für ein paar Minuten ausschalten. In diesem Fall könnten Benutzer, deren Daten sich auf diesem Shard befinden, zu diesem Zeitpunkt nicht vollständig arbeiten, was für uns nicht akzeptabel ist.
Der Ausweg aus dieser Situation war die geplante Wartung, die alle 3 Monate stattfindet. Dies ist ein Fenster für geplante Arbeiten, wenn wir unseren Dienst vollständig deaktivieren und Datenbankinstanzen aktualisieren. Es blieb noch eine Woche bis zum nächsten Fenster, und wir beschlossen, nur zu warten und uns weiter vorzubereiten. Während des Wartens haben wir zusätzlich sichergestellt: Für jeden PostgreSQL-Shard haben wir im Falle eines Fehlers ein Ersatzreplikat erstellt, um die neuesten Daten zu speichern, und für jeden Shard eine neue Instanz hinzugefügt, die ein neues Replikat im Patroni-Cluster werden sollte, um keinen Befehl zum Löschen von Daten auszuführen . All dies trug dazu bei, das Fehlerrisiko zu minimieren.

Wir haben unseren Dienst neu gestartet, alles hat so funktioniert, wie es sollte, die Benutzer haben weiter gearbeitet, aber in den Diagrammen haben wir eine ungewöhnlich hohe Belastung des Consul-Servers festgestellt.
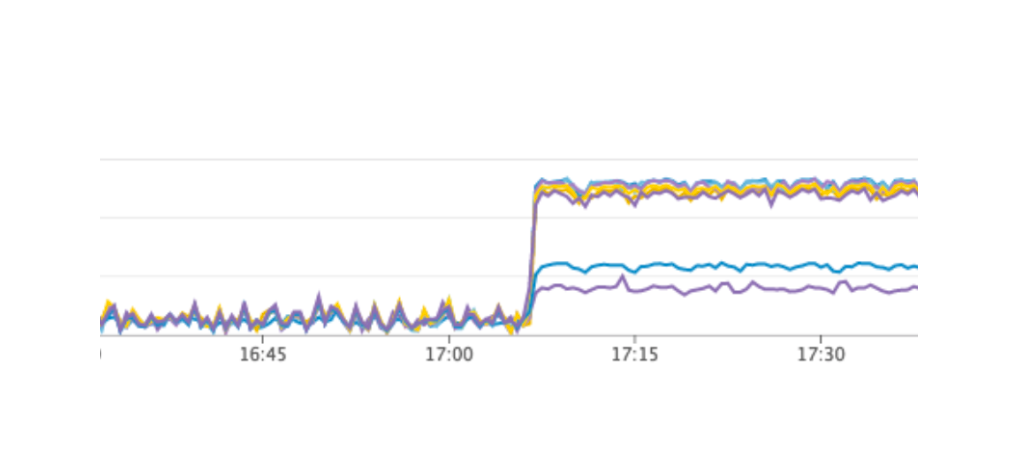
Warum haben wir es in der Testumgebung nicht gesehen? Dieses Problem zeigt sehr gut, dass es notwendig ist, das Prinzip der Infrastruktur als Code zu befolgen und die gesamte Infrastruktur zu verfeinern, beginnend mit Testumgebungen und endend mit der Produktion. Ansonsten ist es sehr einfach, das Problem zu bekommen, das wir haben. Was ist passiert? Consul erschien zuerst in der Produktion und dann in Testumgebungen. Infolgedessen war die Version von Consul in Testumgebungen höher als in der Produktion. Nur in einer der Versionen wurde ein CPU-Leck bei der Arbeit mit consul-template behoben. Deshalb haben wir gerade Consul aktualisiert und damit das Problem gelöst.
Starten Sie den Patroni-Cluster neu
Wir haben jedoch ein neues Problem, das uns nicht einmal bewusst war. Beim Aktualisieren von Consul entfernen wir einfach den Consul-Knoten mit dem Befehl consul verlassen aus dem Cluster. → Patroni stellt eine Verbindung zu einem anderen Consul-Server her. → Alles funktioniert. Als wir jedoch die letzte Instanz des Consul-Clusters erreichten und den Consul-Leave-Befehl an ihn sendeten, wurden alle Patroni-Cluster einfach neu gestartet, und in den Protokollen wurde der folgende Fehler angezeigt:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
Der Patroni-Cluster konnte keine Informationen zu seinem Cluster abrufen und wurde neu gestartet.
Um eine Lösung zu finden, haben wir die Autoren von Patroni über ein Problem mit Github kontaktiert. Sie schlugen Verbesserungen an unseren Konfigurationsdateien vor:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
Wir konnten das Problem in einer Testumgebung wiederholen und diese Parameter dort testen, aber leider funktionierten sie nicht.
Das Problem ist noch ungelöst. Wir planen, die folgenden Lösungen auszuprobieren:
- Verwenden Sie Consul-Agent für jede Instanz des Patroni-Clusters.
- Beheben Sie das Problem im Code.
Wir wissen, wo der Fehler aufgetreten ist: Das Problem verwendet wahrscheinlich das Standardzeitlimit, das nicht durch die Konfigurationsdatei überschrieben wird. Wenn der letzte Consul-Server aus dem Cluster entfernt wird, friert der gesamte Consul-Cluster länger als eine Sekunde ein. Aus diesem Grund kann Patroni den Status des Clusters nicht abrufen und startet den gesamten Cluster vollständig neu.
Zum Glück sind keine Fehler mehr aufgetreten.
Ergebnisse der Verwendung von Patroni
Nach dem erfolgreichen Start von Patroni haben wir in jedem Cluster ein zusätzliches Replikat hinzugefügt. Jetzt gibt es in jedem Cluster den Anschein eines Quorums: ein Anführer und zwei Repliken - um sich beim Wechsel gegen den Fall des Split-Brain zu versichern.
Patroni arbeitet seit mehr als drei Monaten in der Produktion. In dieser Zeit hat er es bereits geschafft, uns zu helfen. Vor kurzem starb der Leiter eines der Cluster in AWS, das automatische Failover funktionierte und die Benutzer arbeiteten weiter. Patroni erledigte seine Hauptaufgabe.
Eine kleine Zusammenfassung der Verwendung von Patroni:- Bequemlichkeit der Änderung einer Konfiguration. Es reicht aus, die Konfiguration auf einer Instanz zu ändern, und sie wird über den gesamten Cluster gezogen. Wenn ein Neustart erforderlich ist, um die neue Konfiguration anzuwenden, meldet Patroni dies. Patroni kann den gesamten Cluster mit einem einzigen Befehl neu starten, was ebenfalls sehr praktisch ist.
- Das automatische Failover funktioniert und hat es bereits geschafft, uns zu helfen.
- PostgreSQL-Update ohne Ausfallzeiten der Anwendung. Sie müssen zuerst die Replikate auf die neue Version aktualisieren, dann den Leader im Patroni-Cluster ändern und den alten Leader aktualisieren. In diesem Fall erfolgt das erforderliche Testen des automatischen Failovers.