ClickHouse-Benutzer wissen, dass der Hauptvorteil in der hohen Geschwindigkeit der Verarbeitung von analytischen Abfragen liegt. Aber wie können wir solche Aussagen machen? Dies sollte durch vertrauenswürdige Leistungstests unterstützt werden. Wir werden heute darüber sprechen.
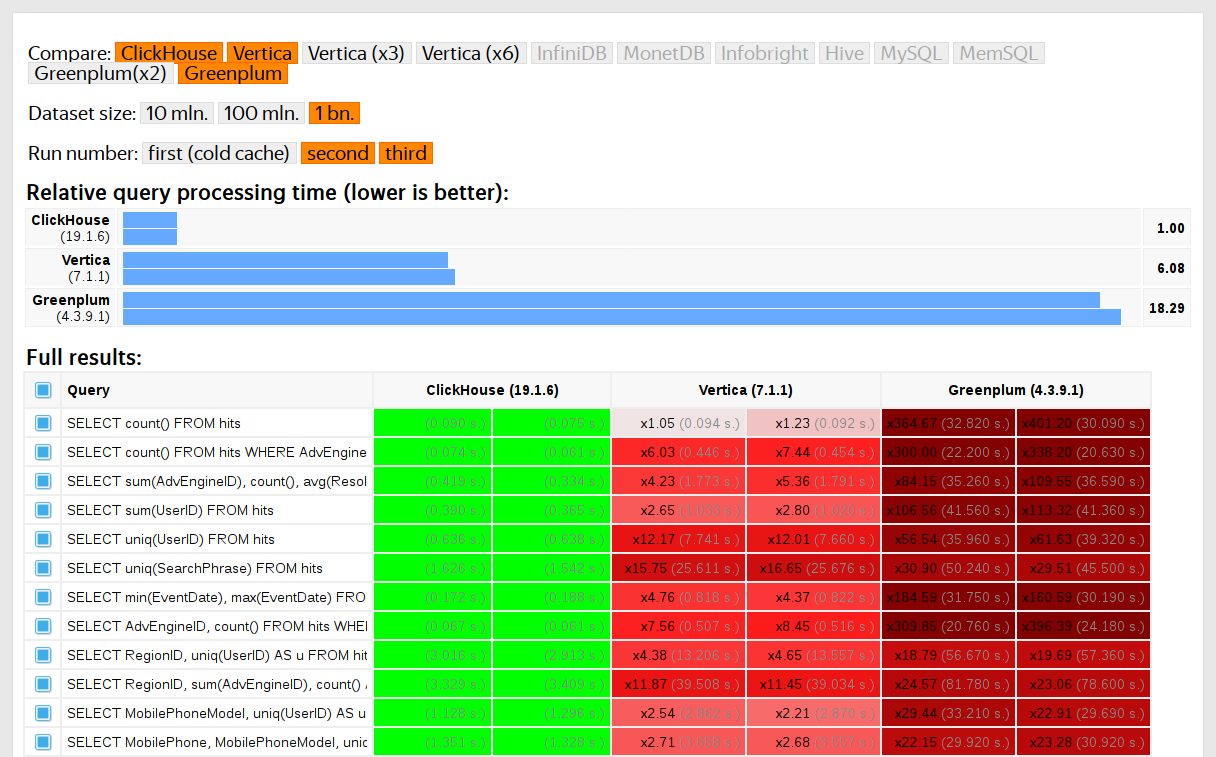
Wir haben 2013 mit der Durchführung solcher Tests begonnen, lange bevor das Produkt in Open Source verfügbar wurde. Nach wie vor waren wir am meisten an der Geschwindigkeit des Yandex.Metrica-Datendienstes interessiert. Wir haben bereits seit Januar 2009 Daten in ClickHouse gespeichert. Ein Teil der Daten wurde seit 2012 in die Datenbank geschrieben, und ein Teil wurde aus
OLAPServer und Metrage konvertiert - Datenstrukturen, die zuvor in Yandex.Metrica verwendet wurden. Daher haben wir für die Tests die erste verfügbare Teilmenge von 1 Milliarde Seitenaufrufdaten verwendet. Es gab noch keine Abfragen in Metric, und wir haben Abfragen erstellt, die für uns selbst am interessantesten sind (alle Arten von Filterung, Aggregation und Sortierung).
ClickHouse wurde im Vergleich zu ähnlichen Systemen wie Vertica und MonetDB getestet. Um ehrlich zu sein, wurde es von einem Mitarbeiter durchgeführt, der zuvor kein ClickHouse-Entwickler gewesen war, und bestimmte Fälle im Code wurden erst optimiert, als die Ergebnisse erhalten wurden. Ebenso haben wir einen Datensatz für Funktionstests erhalten.
Nachdem ClickHouse 2016 Open Source beigetreten war, gab es weitere Fragen zu den Tests.
Nachteile von Tests mit proprietären Daten
Leistungstests:
- Sie sind von außen nicht reproduzierbar, da für ihren Start geschlossene Daten erforderlich sind, die nicht veröffentlicht werden können. Aus dem gleichen Grund stehen einige Funktionstests externen Benutzern nicht zur Verfügung.
- Nicht entwickeln. Es besteht die Notwendigkeit einer signifikanten Erweiterung ihres Satzes, so dass es möglich ist, Änderungen der Geschwindigkeit einzelner Teile des Systems auf isolierte Weise zu überprüfen.
- Sie werden nicht ordnungsgemäß für Poolanforderungen ausgeführt. Externe Entwickler können ihren Code nicht auf Leistungsregressionen überprüfen.
Sie können diese Probleme lösen - alte Tests wegwerfen und neue basierend auf offenen Daten erstellen. Unter den offenen Daten können Sie
Daten zu Flügen in die USA ,
Taxifahrten in New York oder vorgefertigte Benchmarks TPC-H, TPC-DS und
Star Schema Benchmark verwenden . Die Unannehmlichkeit besteht darin, dass diese Daten weit von Yandex.Metrica-Daten entfernt sind und ich Testanforderungen speichern möchte.
Es ist wichtig, echte Daten zu verwenden.
Sie müssen die Leistung des Dienstes nur an realen Daten aus der Produktion testen. Schauen wir uns einige Beispiele an.
Beispiel 1Angenommen, Sie füllen eine Datenbank mit gleichmäßig verteilten Pseudozufallszahlen. In diesem Fall funktioniert die Datenkomprimierung nicht. Die Datenkomprimierung ist jedoch eine wichtige Eigenschaft für analytische DBMS. Die Auswahl des richtigen Komprimierungsalgorithmus und der richtigen Integration in das System ist eine nicht triviale Aufgabe, bei der es keine richtige Lösung gibt, da die Datenkomprimierung einen Kompromiss zwischen der Komprimierungs- und Dekomprimierungsgeschwindigkeit und dem potenziellen Komprimierungsverhältnis erfordert. Systeme, die nicht wissen, wie man Daten komprimiert, verlieren garantiert. Wenn wir jedoch gleichmäßig verteilte Pseudozufallszahlen für Tests verwenden, wird dieser Faktor nicht berücksichtigt und alle anderen Ergebnisse werden verzerrt.
Schlussfolgerung: Die Testdaten sollten ein realistisches Komprimierungsverhältnis aufweisen.
Über die Optimierung von Datenkomprimierungsalgorithmen in ClickHouse habe ich in einem
früheren Beitrag gesprochen .
Beispiel 2Lassen Sie uns an der Geschwindigkeit der SQL-Abfrage interessiert sein:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Dies ist eine typische Anfrage für Yandex.Metrica. Was ist wichtig für seine Geschwindigkeit?
- Wie wird GROUP BY durchgeführt ?
- Welche Datenstruktur wird zur Berechnung der Aggregatfunktion uniq verwendet?
- Wie viele verschiedene RegionIDs sind und wie viel RAM jeder Status der Uniq-Funktion benötigt.
Es ist aber auch sehr wichtig, dass die Datenmenge für verschiedene Regionen ungleich verteilt ist. (Wahrscheinlich wird es nach einem Potenzgesetz verteilt. Ich habe ein Diagramm in der Log-Log-Skala erstellt, bin mir aber nicht sicher.) Und wenn ja, ist es für uns wichtig, dass die Zustände des Uniq-Aggregats mit einer kleinen Anzahl von Werten wenig Speicher benötigen. Wenn es viele verschiedene Aggregationsschlüssel gibt, wird die Anzahl in Byteeinheiten angegeben. Wie erhalte ich die generierten Daten mit all diesen Eigenschaften? Natürlich ist es besser, echte Daten zu verwenden.
Viele DBMS implementieren die HyperLogLog-Datenstruktur für die ungefähre Berechnung von COUNT (DISTINCT), aber alle funktionieren relativ schlecht, da diese Datenstruktur eine feste Speichermenge verwendet. Und ClickHouse verfügt über eine Funktion, die je nach Größe des Sets eine
Kombination aus drei verschiedenen Datenstrukturen verwendet .
Schlussfolgerung: Die Testdaten sollten die Eigenschaften der Werteverteilung in den Daten darstellen - Kardinalität (Anzahl der Werte in den Spalten) und gegenseitige Kardinalität mehrerer verschiedener Spalten.
Beispiel 3Lassen Sie uns die Leistung nicht des analytischen ClickHouse-DBMS testen, sondern von etwas Einfacherem, beispielsweise Hash-Tabellen. Für Hash-Tabellen ist die Auswahl der richtigen Hash-Funktion sehr wichtig. Für std :: unordered_map ist dies etwas weniger wichtig, da es sich um eine kettenbasierte Hash-Tabelle handelt und eine Primzahl als Größe des Arrays verwendet wird. In der Standardbibliotheksimplementierung in gcc und clang wird eine triviale Hash-Funktion als Standard-Hash-Funktion für numerische Typen verwendet. Aber std :: unordered_map ist nicht die beste Wahl, wenn wir maximale Geschwindigkeit erreichen wollen. Bei Verwendung von Hash-Tabellen mit offener Adressierung wird die richtige Auswahl der Hash-Funktion zu einem entscheidenden Faktor, und wir können die triviale Hash-Funktion nicht verwenden.
Es ist einfach, Leistungstests für Hash-Tabellen für zufällige Daten zu finden, ohne die verwendeten Hash-Funktionen zu berücksichtigen. Es ist auch leicht, Hash-Funktionstests zu finden, wobei der Schwerpunkt auf der Rechengeschwindigkeit und einigen Qualitätskriterien liegt, jedoch isoliert von den verwendeten Datenstrukturen. Tatsache ist jedoch, dass Hash-Tabellen und HyperLogLog unterschiedliche Qualitätskriterien für Hash-Funktionen erfordern.
Weitere
Informationen hierzu finden Sie im Bericht
„Wie Hash-Tabellen in ClickHouse angeordnet sind“ . Es ist etwas veraltet, da
Schweizer Tische nicht berücksichtigt
werden .
Herausforderung
Wir möchten, dass die Daten für Leistungstests für die Struktur dieselben wie für Yandex.Metrica-Daten sind, für die alle für Benchmarks wichtigen Eigenschaften gespeichert sind, damit in diesen Daten jedoch keine Spuren von echten Website-Besuchern zurückbleiben. Das heißt, die Daten sollten anonymisiert und Folgendes gespeichert werden:
- Kompressionsverhältnisse
- Kardinalität (Anzahl verschiedener Werte),
- gegenseitige Kardinalitäten mehrerer verschiedener Spalten,
- Eigenschaften probabilistischer Verteilungen, mit denen Daten modelliert werden können (wenn wir beispielsweise glauben, dass Regionen nach einem Potenzgesetz verteilt sind, sollte der Exponent - der Verteilungsparameter - für künstliche Daten ungefähr der gleiche sein wie für real).
Und was wird benötigt, damit die Daten ein ähnliches Komprimierungsverhältnis haben? Wenn beispielsweise LZ4 verwendet wird, sollten die Teilzeichenfolgen in den Binärdaten in ungefähr denselben Abständen wiederholt werden und die Wiederholungen sollten ungefähr dieselbe Länge haben. Für ZSTD wird eine Byte-Entropie-Übereinstimmung hinzugefügt.
Das maximale Ziel: ein Tool für externe Personen verfügbar zu machen, mit dem jeder seinen Datensatz für die Veröffentlichung anonymisieren kann. Damit wir die Leistung von Daten anderer Personen debuggen und testen, ähnlich wie Daten aus der Produktion. Und ich möchte, dass es interessant ist, die generierten Daten zu sehen.
Dies ist eine informelle Erklärung des Problems. Es würde jedoch niemand eine formelle Erklärung abgeben.
Versuche zu lösen
Die Bedeutung dieser Aufgabe sollte für uns nicht übertrieben werden. Tatsächlich war es nie in den Plänen und niemand würde es tun. Ich gab einfach die Hoffnung nicht auf, dass sich etwas einfallen lassen würde, und plötzlich hätte ich gute Laune und viele Dinge, die auf später verschoben werden könnten.
Explizite probabilistische Modelle
Die erste Idee besteht darin, eine Familie von Wahrscheinlichkeitsverteilungen auszuwählen, die sie für jede Spalte der Tabelle modelliert. Wählen Sie dann basierend auf den Statistiken der Daten die Modellanpassungsparameter aus und generieren Sie neue Daten unter Verwendung der ausgewählten Verteilung. Sie können einen Pseudozufallszahlengenerator mit einem vordefinierten Startwert verwenden, um ein reproduzierbares Ergebnis zu erhalten.
Für Textfelder können Sie Markov-Ketten verwenden - ein verständliches Modell, für das Sie eine effektive Implementierung durchführen können.
Es stimmt, einige Tricks sind erforderlich:
- Wir wollen die Kontinuität von Zeitreihen erhalten - was bedeutet, dass für einige Datentypen nicht der Wert selbst modelliert werden muss, sondern der Unterschied zwischen den benachbarten.
- Um die bedingte Kardinalität von Spalten zu simulieren (z. B. dass es normalerweise nur wenige IP-Adressen pro Besucher-ID gibt), müssen Sie auch die Abhängigkeiten zwischen den Spalten explizit aufschreiben (um beispielsweise eine IP-Adresse zu generieren, wird ein Hash aus der Besucher-ID verwendet, aber auch einige andere pseudozufällige Daten werden hinzugefügt).
- Es ist unklar, wie die Abhängigkeit auszudrücken ist, dass ein Besucher ungefähr zur gleichen Zeit häufig URLs mit übereinstimmenden Domains besucht.
All dies wird in Form eines Programms dargestellt, in dem alle Distributionen und Abhängigkeiten fest codiert sind - das sogenannte „C ++ - Skript“. Markov-Modelle werden jedoch immer noch aus der Summe der Statistiken berechnet, die mit Rauschen geglättet und aufgeraut werden. Ich habe angefangen, dieses Skript zu schreiben, aber aus irgendeinem Grund wurde es plötzlich unerträglich langweilig, nachdem ich das Modell explizit für zehn Spalten geschrieben hatte. Und in der Treffertabelle von Yandex.Metrica gab es 2012 mehr als 100 Spalten.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Diese Herangehensweise an die Aufgabe war ein Fehlschlag. Wenn ich mich fleißiger an sie gewandt hätte, wäre das Drehbuch sicher geschrieben worden.
Vorteile:
- ideologische Einfachheit.
Nachteile:
- die Komplexität der Implementierung,
- Die implementierte Lösung ist nur für einen Datentyp geeignet.
Und ich möchte eine allgemeinere Lösung - damit sie nicht nur auf Yandex.Metrica-Daten angewendet werden kann, sondern auch andere Daten verschleiert.
Hier sind jedoch Verbesserungen möglich. Sie können Modelle nicht manuell auswählen, sondern einen Katalog von Modellen implementieren und die besten unter ihnen auswählen (beste Anpassung + eine Art Regularisierung). Oder Sie können Markov-Modelle für alle Arten von Feldern verwenden, nicht nur für Text. Abhängigkeiten zwischen Daten können auch automatisch verstanden werden. Dazu müssen Sie die
relativen Entropien (relative Informationsmenge) zwischen den Spalten oder einfacher die relativen Kardinalitäten (etwa „wie viele verschiedene A-Werte im Durchschnitt für einen festen Wert von B“) für jedes Spaltenpaar berechnen. Dadurch wird beispielsweise deutlich, dass URLDomain vollständig von der URL abhängig ist und nicht umgekehrt.
Aber ich habe diese Idee auch abgelehnt, weil es zu viele Optionen für das gibt, was berücksichtigt werden muss, und das Schreiben wird lange dauern.
Neuronale Netze
Ich habe bereits gesagt, wie wichtig diese Aufgabe für uns ist. Niemand dachte daran, sich in die Umsetzung einzuschleichen. Glücklicherweise arbeitete Kollege Ivan Puzyrevsky dann als Lehrer an der HSE und entwickelte gleichzeitig den YT-Kern. Er fragte mich, ob ich interessante Aufgaben hätte, die den Studenten als Diplomthema angeboten werden könnten. Ich bot ihm dieses an und er versicherte mir, dass es geeignet sei. Also gab ich diese Aufgabe einem guten Menschen „von der Straße“ - Sharif Anvardinov (die NDA ist für die Arbeit mit Daten unterschrieben).
Er erzählte ihm von all seinen Ideen, aber vor allem erklärte er, dass das Problem auf jede Weise gelöst werden kann. Eine gute Option wäre es, die Ansätze zu verwenden, die ich überhaupt nicht verstehe: Erstellen Sie beispielsweise einen Textdatendump mit LSTM. Es sah ermutigend aus, dank des
Artikels Die unvernünftige Wirksamkeit wiederkehrender neuronaler Netze , der mir dann aufgefallen ist.
Das erste Merkmal der Aufgabe ist, dass Sie strukturierte Daten generieren müssen, nicht nur Text. Es war nicht offensichtlich, ob ein wiederkehrendes neuronales Netzwerk Daten mit der gewünschten Struktur erzeugen könnte. Es gibt zwei Möglichkeiten, dies zu lösen. Das erste besteht darin, separate Modelle zur Erzeugung der Struktur und für den „Füllstoff“ zu verwenden: Das neuronale Netzwerk sollte nur Werte erzeugen. Diese Option wurde jedoch auf später verschoben, danach jedoch nie mehr. Die zweite Möglichkeit besteht darin, einfach einen TSV-Speicherauszug als Text zu generieren. Die Praxis hat gezeigt, dass im Text ein Teil der Zeilen nicht der Struktur entspricht, diese Zeilen jedoch beim Laden weggeworfen werden können.
Das zweite Merkmal - ein wiederkehrendes neuronales Netzwerk erzeugt eine Folge von Daten, und die Abhängigkeiten in den Daten können nur in der Reihenfolge dieser Folge folgen. In unseren Daten ist die Reihenfolge der Spalten möglicherweise in Bezug auf die Abhängigkeiten zwischen ihnen umgekehrt. Wir haben mit dieser Funktion nichts gemacht.
Gegen Sommer erschien das erste funktionierende Python-Skript, das Daten generierte. Auf den ersten Blick ist die Datenqualität anständig:
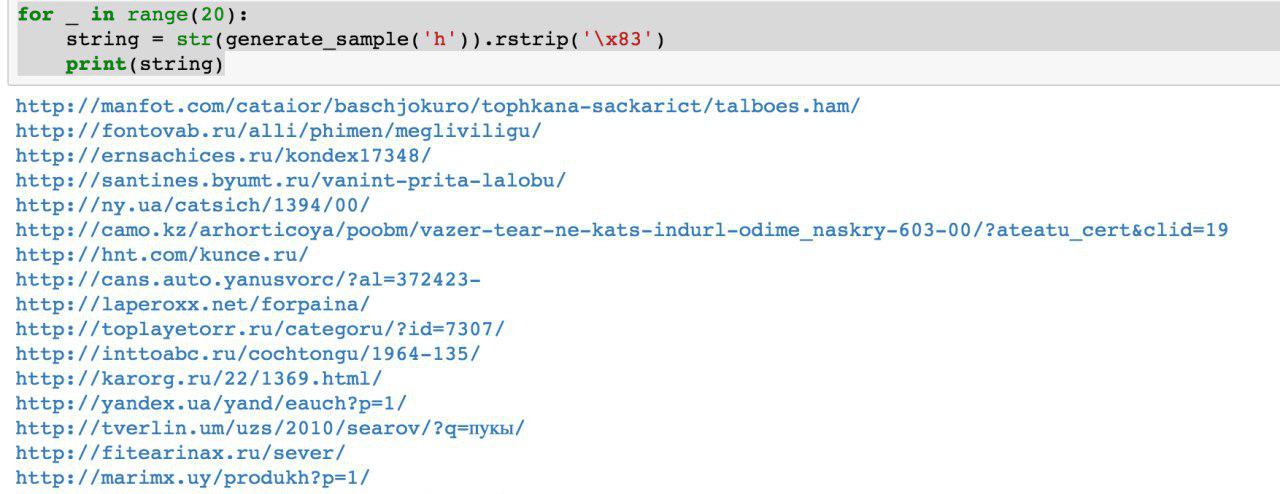
Zwar wurden Schwierigkeiten aufgedeckt:
- Die Größe des Modells beträgt etwa ein Gigabyte. Und wir haben versucht, ein Modell für Daten zu erstellen, deren Größe in der Größenordnung von mehreren Gigabyte liegt (für den Anfang). Die Tatsache, dass das resultierende Modell so groß ist, wirft Bedenken auf: Plötzlich wird es möglich sein, echte Daten daraus zu erhalten, auf denen es trainiert wurde. Höchstwahrscheinlich nicht. Aber ich verstehe maschinelles Lernen und neuronale Netze nicht und habe den Python-Code von dieser Person nicht gelesen. Wie kann ich also sicher sein? Dann gab es Artikel darüber, wie man neuronale Netze komprimiert, ohne an Qualität zu verlieren, aber dies blieb ohne Implementierung. Einerseits sieht dies nicht nach einem Problem aus - Sie können die Veröffentlichung des Modells ablehnen und nur die generierten Daten veröffentlichen. Andererseits können im Fall einer Umschulung die erzeugten Daten einen Teil der Quelldaten enthalten.
- Auf einem einzelnen Computer mit einer CPU beträgt die Datengenerierungsrate ungefähr 100 Zeilen pro Sekunde. Wir hatten die Aufgabe, mindestens eine Milliarde Zeilen zu generieren. Die Berechnung ergab, dass dies vor der Verteidigung des Diploms nicht möglich war. Die Verwendung anderer Hardware ist nicht praktikabel, da ich das Ziel hatte, das Datengenerierungstool für eine breite Verwendung verfügbar zu machen.
Sharif versuchte, die Datenqualität durch Vergleichen von Statistiken zu untersuchen. Zum Beispiel habe ich die Häufigkeit berechnet, mit der verschiedene Symbole in der Quelle und in den generierten Daten erscheinen. Das Ergebnis war atemberaubend - die häufigsten Zeichen sind Ð und Ñ.
Keine Sorge - er hat sein Diplom perfekt verteidigt, danach haben wir diese Arbeit sicher vergessen.
Komprimierte Datenmutation
Angenommen, die Problemstellung wird auf einen Punkt reduziert: Sie müssen Daten generieren, für die die Komprimierungsverhältnisse genau den Originaldaten entsprechen, während die Daten mit genau derselben Geschwindigkeit dekomprimiert werden müssen. Wie kann man das machen? Bytes komprimierter Daten müssen direkt bearbeitet werden! Dann ändert sich die Größe der komprimierten Daten nicht, aber die Daten selbst ändern sich. Ja, und alles wird schnell funktionieren. Als diese Idee auftauchte, wollte ich sie sofort umsetzen, obwohl sie ein anderes Problem als das ursprüngliche löst. Es passiert immer.
Wie bearbeite ich eine komprimierte Datei direkt? Angenommen, wir interessieren uns nur für LZ4. Mit LZ4 komprimierte Daten bestehen aus zwei Arten von Anweisungen:
- Literale: Kopieren Sie die nächsten N Bytes unverändert.
- Übereinstimmung (Übereinstimmung, die minimale Wiederholungslänge beträgt 4): Wiederholen Sie N Bytes, die sich in der Datei in einem Abstand von M befanden.
Ausgangsdaten:
Hello world Hello .
Komprimierte Daten (bedingt):
literals 12 "Hello world " match 5 12 .
Lassen Sie in der komprimierten Datei die Übereinstimmung unverändert, und in Literalen ändern wir die Bytewerte. Als Ergebnis erhalten wir nach der Dekomprimierung eine Datei, in der alle sich wiederholenden Sequenzen mit mindestens 4 Längen ebenfalls wiederholt und in denselben Abständen wiederholt werden, aber gleichzeitig aus einem anderen Satz von Bytes bestehen (bildlich gesprochen wurde kein einziges Byte aus der Originaldatei in der modifizierten Datei entnommen )
Aber wie kann man Bytes ändern? Dies ist nicht offensichtlich, da Daten neben Spaltentypen auch eine eigene interne implizite Struktur haben, die wir beibehalten möchten. Beispielsweise wird Text häufig in UTF-8-Codierung gespeichert - und wir möchten auch in den generierten Daten gültiges UTF-8. Ich habe eine einfache Heuristik erstellt, um mehrere Bedingungen zu erfüllen:
- Null-Bytes und ASCII-Steuerzeichen wurden unverändert gespeichert.
- einige Interpunktion blieb bestehen,
- ASCII wurde in ASCII übersetzt, und im Übrigen wurde das höchstwertige Bit gespeichert (oder Sie können explizit ein if-Set für verschiedene UTF-8-Längen schreiben). Unter einer Klasse von Bytes wird ein neuer Wert gleichmäßig zufällig ausgewählt;
- und auch um Fragmente von
https:// und ähnlichem zu speichern, sonst sieht alles zu albern aus.
Die Besonderheit dieses Ansatzes besteht darin, dass die Anfangsdaten selbst als Modell für die Daten dienen, was bedeutet, dass das Modell nicht veröffentlicht werden kann. Damit können Sie die Datenmenge nicht mehr als das Original generieren. Zum Vergleich war es in früheren Ansätzen möglich, ein Modell zu erstellen und auf seiner Basis eine unbegrenzte Datenmenge zu generieren.
Beispiel für URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
Das Ergebnis hat mich gefreut - es war interessant, die Daten zu betrachten. Trotzdem stimmte etwas nicht. Die URLs sind immer noch strukturiert, aber an einigen Stellen war es zu einfach, Yandex oder Avito zu erraten. Es wurde eine Heuristik erstellt, die manchmal einige Bytes an einigen Stellen neu anordnet.
Andere Überlegungen machten sich Sorgen. Beispielsweise können vertrauliche Informationen in einer Spalte vom Typ FixedString in binärer Form dargestellt werden und bestehen aus irgendeinem Grund aus ASCII-Steuerzeichen und Interpunktion, die ich speichern wollte. Und ich berücksichtige keine Datentypen.
Ein weiteres Problem: Wenn Daten vom Typ "Länge, Wert" in einer Spalte gespeichert sind (so werden Spalten vom Typ String gespeichert), wie kann dann sichergestellt werden, dass die Länge nach der Mutation korrekt bleibt? Als ich versuchte, das Problem zu beheben, wurde die Aufgabe sofort uninteressant.
Zufällige Permutationen
Das Problem ist jedoch nicht gelöst. Wir haben mehrere Experimente durchgeführt und es wurde nur noch schlimmer. Es bleibt nur nichts zu tun und zufällige Seiten im Internet zu lesen, da die Stimmung schon verdorben ist. Glücklicherweise wurde auf einer dieser Seiten
der Algorithmus zum Rendern der Todesszene des Protagonisten im Spiel Wolfenstein 3D
analysiert .

Schöne Animation - der Bildschirm füllt sich mit Blut. Der Artikel erklärt, dass dies tatsächlich eine pseudozufällige Permutation ist. Zufällige Permutation - eine zufällig ausgewählte Eins-zu-Eins-Transformation einer Menge. Das heißt, die Anzeige der gesamten Menge, in der die Ergebnisse für verschiedene Argumente nicht wiederholt werden. Mit anderen Worten, dies ist eine Möglichkeit, alle Elemente einer Menge in zufälliger Reihenfolge zu durchlaufen. Es ist ein solcher Prozess, der im Bild gezeigt wird - wir übermalen jedes Pixel, das zufällig aus allen ausgewählt wurde, ohne Wiederholung. Wenn wir bei jedem Schritt nur ein zufälliges Pixel auswählen würden, würden wir lange brauchen, um das letzte zu übermalen.
Das Spiel verwendet einen sehr einfachen Algorithmus für die pseudozufällige Permutation -
LFSR (Linear Feedback Shift Register). Wie Pseudozufallszahlengeneratoren können zufällige Permutationen bzw. deren Familien, die durch den Schlüssel parametrisiert werden, kryptografisch stark sein - genau das benötigen wir, um die Daten zu konvertieren. Obwohl es möglicherweise nicht offensichtliche Details gibt. Beispielsweise kann eine kryptografisch starke Verschlüsselung von N Bytes zu N Bytes mit einem voreingestellten Schlüssel und einem Initialisierungsvektor anscheinend als pseudozufällige Permutation vieler N-Byte-Zeichenfolgen verwendet werden. In der Tat ist eine solche Transformation eins zu eins und sieht zufällig aus. Wenn wir jedoch für alle unsere Daten dieselbe Transformation verwenden, kann das Ergebnis einer Analyse unterzogen werden, da der gleiche Initialisierungsvektor und die gleichen Schlüsselwerte mehrmals verwendet werden. Dies ähnelt dem Blockcode-Verschlüsselungsmodus des
elektronischen Codebuchs .
Wie kann man eine pseudozufällige Permutation erhalten? Sie können einfache Eins-zu-Eins-Transformationen durchführen und daraus eine ziemlich komplexe Funktion zusammenstellen, die zufällig aussieht. Lassen Sie mich Ihnen ein Beispiel für einige meiner bevorzugten Eins-zu-Eins-Transformationen geben:
- Multiplikation mit einer ungeraden Zahl (z. B. einer großen Primzahl) in der Zweierkomplementarithmetik;
- xor-shift:
x ^= x >> N , - CRC-N, wobei N die Anzahl der Bits des Arguments ist.
So wird beispielsweise aus drei Multiplikationen und zwei Xor-Shift-Operationen der
Murmhash- Finalizer
zusammengesetzt . Diese Operation ist eine pseudozufällige Permutation. Aber nur für den Fall, ich stelle fest, dass Hash-Funktionen, auch N Bits in N Bits, nicht gegenseitig eindeutig sein müssen.
Oder hier ist ein weiteres interessantes
Beispiel aus der Elementarzahlentheorie von Jeff Preshing.
Wie können wir pseudozufällige Permutationen für unsere Aufgabe verwenden? Sie können damit alle numerischen Felder konvertieren. Dann ist es möglich, alle Kardinalitäten und gegenseitigen Kardinalitäten aller Feldkombinationen beizubehalten. Das heißt, COUNT (DISTINCT) gibt den gleichen Wert wie vor der Konvertierung und mit jedem GROUP BY zurück.
Es ist anzumerken, dass die Wahrung aller Kardinalitäten der Aussage über das Problem der Datenanonymisierung leicht widerspricht. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . Usw. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
Ergebnis
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .