Hallo Habr! Mein Name ist Sasha und ich bin ein Backend-Entwickler. In meiner Freizeit lerne ich ML und habe Spaß mit hh.ru Daten.
In diesem Artikel geht es darum, wie wir den Routinezuweisungsprozess für Tester mithilfe von maschinellem Lernen automatisiert haben.
Hh.ru verfügt über einen internen Service, für den in Jira Aufgaben erstellt werden (innerhalb des Unternehmens werden sie als HHS bezeichnet), wenn jemand nicht oder falsch arbeitet. Darüber hinaus werden diese Aufgaben vom QA-Teamleiter Alexey manuell erledigt und dem Team zugewiesen, dessen Verantwortungsbereich den Fehler umfasst. Lesha weiß, dass langweilige Aufgaben von Robotern ausgeführt werden müssen. Deshalb bat er mich um Hilfe bezüglich ML.

Die folgende Grafik zeigt die Menge an HHS pro Monat. Wir wachsen und die Anzahl der Aufgaben wächst. Aufgaben werden hauptsächlich während der Arbeitszeit erstellt, einige pro Tag, und dies muss ständig abgelenkt werden.
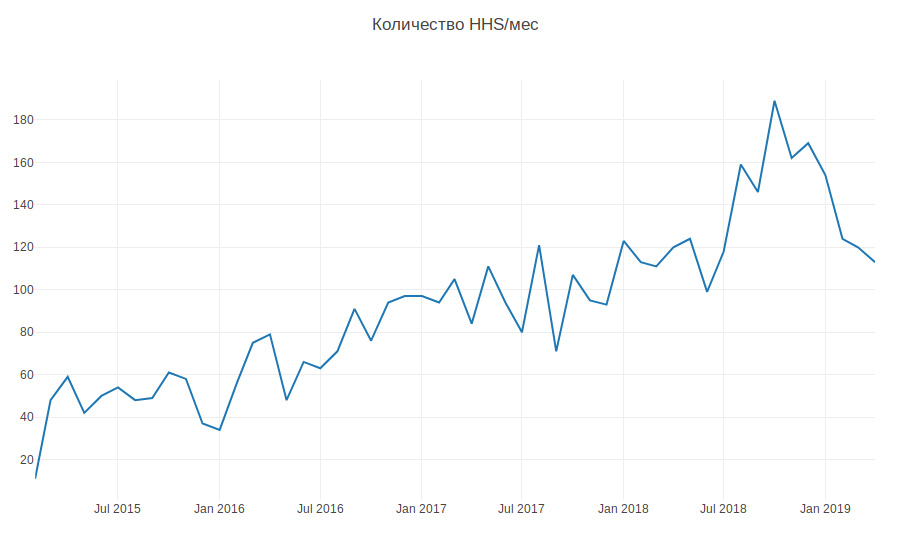
Historischen Daten zufolge muss daher gelernt werden, wie das Entwicklungsteam bestimmt wird, zu dem HHS gehört. Dies ist eine Klassifizierungsaufgabe für mehrere Klassen.
Daten
Bei maschinellen Lernaufgaben sind Qualitätsdaten das Wichtigste. Das Ergebnis der Lösung des Problems hängt von ihnen ab. Daher müssen alle maschinellen Lernaufgaben mit dem Studium der Daten beginnen. Seit Anfang 2015 haben wir ungefähr 7000 Aufgaben gesammelt, die die folgenden nützlichen Informationen enthalten:
- Zusammenfassung - Titel, Kurzbeschreibung
- Beschreibung - eine vollständige Beschreibung des Problems
- Beschriftungen - Eine Liste der Tags, die sich auf das Problem beziehen
- Reporter ist der Name des Erstellers von HHS. Diese Funktion ist nützlich, da Benutzer mit einer begrenzten Anzahl von Funktionen arbeiten.
- Erstellt - Erstellungsdatum
- Beauftragter ist die Person, der die Aufgabe zugewiesen ist. Die Zielvariable wird aus diesem Attribut generiert.
Beginnen wir mit der Zielvariablen. Erstens hat jedes Team Verantwortungsbereiche. Manchmal überschneiden sie sich, manchmal überschneidet sich ein Team in der Entwicklung mit einem anderen. Die Entscheidung basiert auf der Annahme, dass der Abtretungsempfänger, der zum Zeitpunkt des Abschlusses bei der Aufgabe blieb, für die Lösung verantwortlich ist. Aber wir müssen nicht eine bestimmte Person, sondern ein Team vorhersagen. Glücklicherweise bleiben alle Teams in Jira erhalten und können zugeordnet werden. Es gibt jedoch eine Reihe von Problemen bei der Definition eines Teams nach Personen:
- Nicht alle HHS beziehen sich auf technische Probleme, und wir sind nur an den Aufgaben interessiert, die dem Entwicklungsteam zugewiesen werden können. Daher müssen Sie Aufgaben verwerfen, bei denen der Beauftragte nicht aus der technischen Abteilung stammt
- Manchmal hören Teams auf zu existieren. Sie werden auch aus dem Trainingsset entfernt.
- Leider arbeiten die Mitarbeiter nicht für immer im Unternehmen und wechseln manchmal von Team zu Team. Glücklicherweise haben wir es geschafft, eine Geschichte von Änderungen in der Zusammensetzung aller Teams zu erhalten. Mit dem Erstellungsdatum von HHS und Beauftragten können Sie herausfinden, welches Team zu einem bestimmten Zeitpunkt mit der Aufgabe beschäftigt war.
Nach dem Herausfiltern irrelevanter Daten wurde die Trainingsstichprobe auf 4900 Aufgaben reduziert.
Schauen wir uns die Aufgabenverteilung zwischen den Teams an:
Aufgaben müssen auf 22 Teams verteilt werden.
Zeichen:
Zusammenfassung und Beschreibung sind Textfelder.
Erstens sollten sie von überschüssigen Zeichen befreit werden. Für einige Aufgaben ist es sinnvoll, in den Zeilen Zeichen zu belassen, die Informationen enthalten, z. B. + und #, um zwischen c ++ und c # zu unterscheiden. In diesem Fall habe ich mich jedoch entschieden, nur Buchstaben und Zahlen zu belassen, da habe nicht gefunden, wo andere Zeichen nützlich sein könnten.
Wörter müssen lemmatisiert werden. Lemmatisierung ist die Reduktion eines Wortes auf ein Lemma, seine normale (Vokabular-) Form. Zum Beispiel Katzen → Katze. Ich habe auch versucht, Stemming, aber mit Lemmatisierung war die Qualität etwas höher. Stamming ist der Prozess, die Basis eines Wortes zu finden. Diese Basis ist auf den Algorithmus zurückzuführen (in verschiedenen Implementierungen sind sie unterschiedlich), beispielsweise von Katzen → Katzen. Die Bedeutung des ersten und zweiten besteht darin, dieselben Wörter in verschiedenen Formen nebeneinander zu stellen. Ich habe den Python-Wrapper für
Yandex Mystem verwendet .
Außerdem sollte der Text von Stoppwörtern befreit werden, die keine Nutzlast enthalten. Zum Beispiel "war", "ich", "noch". Stoppwörter, die ich normalerweise von
NLTK nehme.
Ein anderer Ansatz, den ich bei der Arbeit mit Text versuche, ist eine zeichenbasierte Fragmentierung von Wörtern. Zum Beispiel gibt es eine "Suche". Wenn Sie es in Komponenten von 3 Zeichen aufteilen, erhalten Sie die Wörter "poi", "ois", "Klage". Dies hilft, zusätzliche Verbindungen zu erhalten. Angenommen, es gibt das Wort "Suche". Lemmatisierung führt nicht zu "Suchen" und "Suchen" in einer allgemeinen Form, aber eine Partition von 3 Zeichen hebt den gemeinsamen Teil hervor - "Anspruch".
Ich habe zwei Token gemacht. Tokenizer ist eine Methode, die Text an der Eingabe empfängt, und die Ausgabe enthält eine Liste von Token - den Komponenten des Textes. Das erste hebt lemmatisierte Wörter und Zahlen hervor. Das zweite hebt nur lemmatisierte Wörter hervor, die in 3 Zeichen unterteilt sind, d.h. Am Ausgang hat er eine Liste mit dreistelligen Token.
Tokenizer werden in
TfidfVectorizer verwendet, mit dem Textdaten (und nicht nur Daten) in eine Vektordarstellung basierend auf
tf-idf konvertiert werden . Am Eingang wird eine Liste von Zeilen eingespeist, und am Ausgang erhalten wir eine Matrix M mal N, wobei M die Anzahl der Zeilen und N die Anzahl der Vorzeichen ist. Jedes Merkmal ist ein Frequenzgang eines Wortes in einem Dokument, bei dem die Frequenz begrenzt wird, wenn das Wort in allen Dokumenten mehrmals vorkommt. Dank des Parameters ngram_range TfidfVectorizer habe ich
Bigramme und Trigramme als Attribute hinzugefügt.
Ich habe auch versucht, mit Word2vec erhaltene Worteinbettungen als zusätzliche Funktionen zu verwenden. Das Einbetten ist eine Vektordarstellung eines Wortes. Für jeden Text habe ich die Einbettungen aller seiner Wörter gemittelt. Da dies jedoch keine Erhöhung ergab, lehnte ich diese Zeichen ab.
Für Beschriftungen wurde ein
CountVectorizer verwendet. Die Zeilen mit Tags werden der Eingabe zugeführt, und am Ausgang haben wir eine Matrix, in der die Zeilen den Aufgaben und die Spalten den Tags entsprechen. Jede Zelle enthält die Anzahl der Vorkommen des Tags in der Aufgabe. In meinem Fall ist es 1 oder 0.
LabelBinarizer kam für Reporter. Es binärisiert alle Attribute. Es kann nur einen Ersteller für jede Aufgabe geben. Am Eingang zum LabelBinarizer wird eine Liste der Aufgabenersteller übermittelt, und die Ausgabe ist eine Matrix, in der die Zeilen Aufgaben sind und die Spalten den Namen der Aufgabenersteller entsprechen. Es stellt sich heraus, dass in jeder Zeile "1" in der Spalte steht, die dem Ersteller entspricht, und im Rest "0".
Bei Erstellt wird die Differenz in Tagen zwischen dem Erstellungsdatum der Aufgabe und dem aktuellen Datum berücksichtigt.
Als Ergebnis wurden die folgenden Zeichen erhalten:
- tf-idf für Zusammenfassung in Wörtern und Zahlen (4855, 4593)
- tf-idf für Zusammenfassung auf drei Zeichenpartitionen (4855, 15518)
- tf-idf für Beschreibung in Wörtern und Zahlen (4855, 33297)
- tf-idf für Beschreibung auf dreistelligen Partitionen (4855, 75359)
- Anzahl der Einträge für Labels (4855, 505)
- Binärzeichen für Reporter (4855, 205)
- Aufgabenlebensdauer (4855, 1)
Alle diese Zeichen werden zu einer großen Matrix (4855, 129478) zusammengefasst, auf der das Training durchgeführt wird.
Separat ist es wert, die Namen der Zeichen zu notieren. Weil Einige Modelle für maschinelles Lernen können Funktionen identifizieren, die den größten Einfluss auf die Klassenerkennung haben. Sie müssen diese verwenden. TfidfVectorizer, CountVectorizer und LabelBinarizer verfügen über Methoden get_feature_names, die eine Liste von Features anzeigen, deren Reihenfolge Spalten von Datenmatrizen entspricht.
Auswahl des Vorhersagemodells
Sehr oft liefert
XGBoost gute Ergebnisse. Und er begann damit. Aber ich habe eine große Anzahl von Features generiert, deren Anzahl die Größe des Trainingsmusters deutlich übersteigt. In diesem Fall ist die Wahrscheinlichkeit einer Umschulung von XGBoost hoch. Das Ergebnis ist nicht sehr gut. Hohe Dimension ist gut verdaut
LogisticRegression . Sie zeigte eine höhere Qualität.
Ich habe auch versucht, mithilfe
dieses hervorragenden Tutorials ein Modell für ein neuronales Netzwerk in Tensorflow zu erstellen, aber es stellte sich als schlechter heraus als die logistische Regression.
Auswahl von Hyperparametern
Ich habe auch mit den Hyperparametern XGBoost und Tensorflow gespielt, aber ich lasse es außerhalb des Beitrags, weil Das Ergebnis der logistischen Regression wurde nicht übertroffen. Zuletzt habe ich alle möglichen Stifte gedreht. Alle Parameter blieben daher standardmäßig, mit Ausnahme von zwei: solver = 'liblinear' und C = 3.0
Ein weiterer Parameter, der das Ergebnis beeinflussen kann, ist die Größe der Trainingsprobe. Weil Ich beschäftige mich mit historischen Daten, und im Laufe mehrerer Jahre kann sich die Geschichte ernsthaft ändern. Beispielsweise kann die Verantwortung für etwas an ein anderes Team gehen, neuere Daten können nützlicher sein und alte Daten können die Qualität sogar verringern. In diesem Zusammenhang habe ich mir Heuristiken ausgedacht - je älter die Daten sind, desto weniger sollten sie zum Modelltraining beitragen. Je nach Alter werden die Daten mit einem bestimmten Koeffizienten multipliziert, der der Funktion entnommen wird. Ich habe mehrere Funktionen generiert, um die Daten zu dämpfen, und die verwendet, die den größten Anstieg beim Testen ergab.
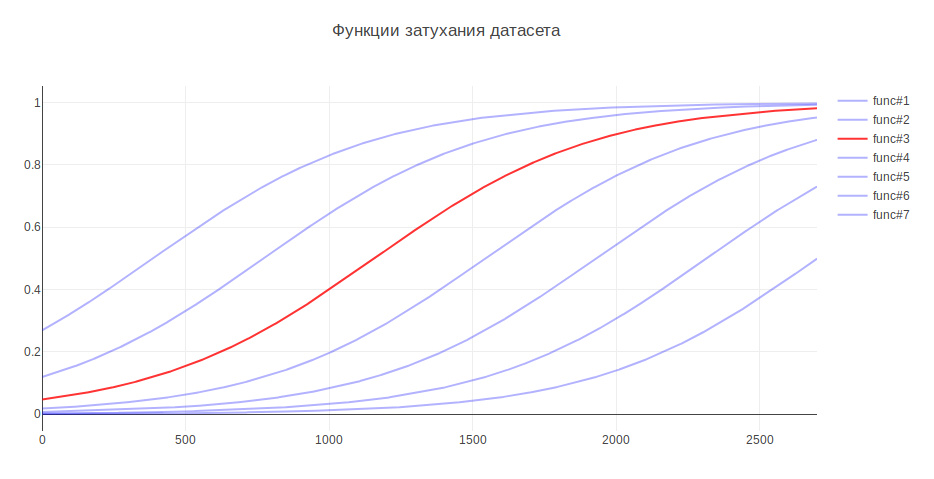
Aufgrund dessen stieg die Qualität der Klassifizierung um 3%
Qualitätsbewertung
Bei Klassifizierungsproblemen müssen wir darüber nachdenken, was für uns wichtiger ist -
Genauigkeit oder Vollständigkeit ? In meinem Fall, wenn der Algorithmus falsch ist, gibt es keinen Grund zur Sorge, wir haben sehr gute Kenntnisse zwischen den Teams und die Aufgabe wird an die Verantwortlichen oder an die Hauptaufgabe in der Qualitätssicherung übertragen. Außerdem macht der Algorithmus keine zufälligen Fehler, sondern findet einen Befehl in der Nähe des Problems. Aus Gründen der Vollständigkeit wurde daher beschlossen, 100% zu verwenden. Und für die Messung der Qualität wurde die Genauigkeitsmetrik gewählt - der Anteil der richtigen Antworten, der für das endgültige Modell 76% betrug.
Als Validierungsmechanismus habe ich zuerst die Kreuzvalidierung verwendet - wenn die Probe in N Teile unterteilt ist und die Qualität an einem Teil überprüft wird und das Training für den Rest und somit N-mal durchgeführt wird, bis jedes Teil in der Testrolle ist. Das Ergebnis wird dann gemittelt. Aber in meinem Fall passte dieser Ansatz nicht, weil Die Reihenfolge der Daten ändert sich, und wie bereits bekannt, hängt die Qualität von der Aktualität der Daten ab. Deshalb habe ich die ganze Zeit an alten studiert und wurde an frischen validiert.
Mal sehen, welche Befehle der Algorithmus am häufigsten verwirrt:

An erster Stelle stehen Marketing und Pandora. Dies ist seitdem nicht überraschend Das zweite Team ist aus dem ersten hervorgegangen und hat die Verantwortung für viele Funktionen übernommen. Wenn Sie den Rest des Teams berücksichtigen, können Sie auch die Gründe für die interne Küche des Unternehmens erkennen.
Zum Vergleich möchte ich zufällige Modelle betrachten. Wenn Sie eine verantwortliche Person zufällig zuweisen, beträgt die Qualität etwa 5%, und wenn für die häufigste Klasse - 29%.
Die wichtigsten Zeichen
LogisticRegression für jede Klasse gibt Attributkoeffizienten zurück. Je größer der Wert ist, desto größer ist der Beitrag, den dieses Attribut zu dieser Klasse geleistet hat.
Unter dem Spoiler die Ausgabe der Top-Zeichen. Präfixe geben an, woher die Zeichen kamen:
- sum - tf-idf für Zusammenfassung in Wörtern und Zahlen
- sum2 - tf-idf für Zusammenfassung bei dreistelligen Teilungen
- desc - tf-idf für Beschreibung in Wörtern und Zahlen
- desc2 - tf-idf für Beschreibung auf dreistelligen Partitionen
- lab - Feld Labels
- Repräsentant Reporter
ZeichenA-Team: sum_site (1.28), lab_responses_and_invitations (1.37), lab_failure_to the Employer (1.07), lab_makeup (1.03), sum_work (1.54), lab_hhs (1.19), lab_feedback (1.06), rep_name (1.16), sum_ window (1.13), sum_ break (1.04), rep_name_1 (1.22), lab_responses_seeker (1.0), lab_site (0.92)
API: lab_delete_account (1.12), sum_comment_resume (0.94), rep_name_2 (0.9), rep_name_3 (0.83), rep_name_4 (0.89), rep_name_5 (0.91), lab_measurements_managers (0.87), lab_comments_to_result (1.6), account_6 ), sum_view (0,91), desc_comment (1,02), rep_name_6 (0,85), desc_resume (0,86), sum_api (1,01)
Android: sum_android (1.77), lab_ios (1.66), sum_application (2.9), sum_hr_mobile (1.4), lab_android (3.55), sum_hr (1.36), lab_mobile_application (3.33), sum_mobile (1.4), rep_name_2 (1.34), sum2_ril (1.27) ), sum_android_application (1.28), sum2_pril_rilo (1.19), sum2_pril_ril (1.27), sum2_ril_log (1.19), sum2_ril_log_ (1.19)
Abrechnung: rep_name_7 (3.88), desc_account (3.23), rep_name_8 (3.15), lab_billing_wtf (2.46), rep_name_9 (4.51), rep_name_10 (2.88), sum_account (3.16), lab_billing (2.41), rep_name_11 (2.27), lab_b36 ), sum_service (2.33), lab_payment_services (1.92), sum_act (2.26), rep_name_12 (1.92), rep_name_13 (2.4)
Brandy: lab_talent Evaluation (2.17), rep_name_14 (1.87), rep_name_15 (3.36), lab_clickme (1.72), rep_name_16 (1.44), rep_name_17 (1.63), rep_name_18 (1.29), sum_page (1.24), sum_brand (1.39) lab ), sum_constructor (1.59), lab_brand der Seite (1.33), sum_description (1.23), sum_description_of the company (1.17), lab_article (1.15)
Clickme: desc_act (0,73), sum_adv_hh (0,65), sum_adv_hh_ru (0,65), sum_hh (0,77), lab_hhs (1,27), lab_bs (1,91), rep_name_19 (1,17), rep_name_20 (1,29), rep_name_21 (1,9), rep_name ), sum_advertising (0,67), sum_placing (0,65), sum_adv (0,65), sum_hh_ua (0,64), sum_click_31 (0,64)
Marketing: lab_region (0.9), lab_site_site (1.23), sum_mail (1.32), lab_managers_of Stellenangebote (0.93), sum_calender (0.93), rep_name_22 (1.33), lab_queries (1.25), rep_name_6 (1.53), lab_product_1.55 (repa1_5 ), sum_yandex (1,26), sum_distribution_vacancy (0,85), sum_distribution (0,85), sum_category (0,85), sum_error_function (0,83)
Mercury: lab_services (1.76), sum_captcha (2.02), lab_search_services (1.89), lab_lawyers (2.1), lab_authorization_worker (1.68), lab_proforientation (2.53), lab_ready_summary (2.21), rep_name_24 (1.7725_mail ), sum_user (1.57), rep_name_26 (1.43), lab_moderation_of vacancies (1.58), desc_password (1.39), rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32), sum_version_site (1.26), lab_application (1.51), lab_statistics (1.32), sum_mobile_version_site (1.25), lab_mobile_version (5.1), sum_version (1.41), rep_name_28 (1.24), lab_string (1.04.1 ), lab_jtb (1.07), rep_name_16 (1.12), rep_name_29 (1.05), sum_site (0.95), rep_name_30 (0.92)
TMS: rep_name_31 (1.39), lab_talantix (4.28), rep_name_32 (1.55), rep_name_33 (2.59), sum_valuation_talantix (0.74), lab_search (0.57), lab_search (0.63), rep_name_34 (0.64), lab_port (0.56) ), lab_tms (0,74), sum_hh Antwort (0,57), lab_mailing (0,64), sum_talantix (0,6), sum2_po (0,56)
Talantix: sum_system (0,86), rep_name_16 (1,37), sum_talantix (1,16), lab_mail (0,94), lab_xor (0,8), lab_talantix (3,19), rep_name_35 (1,07), rep_name_18 (1,33), lab_personal_data (0,79) ), sum_talantics (0,89), sum_proceed (0,78), lab_mail (0,77), sum_response_stop_view (0,73), rep_name_6 (0,72)
WebServices: sum_vacancy (1.36), desc_pattern (1.32), sum_archive (1.3), lab_patterns (1.39), sum_number_phone (1.44), rep_name_36 (1.28), lab_lawyers (2.1), lab_invitation (1.27), lab_invitation (2) ), lab_selected_summages (1.2), lab_key_keys (1.22), sum_find (1.18), sum_phone (1.16), sum_folder (1.17)
iOS: sum_application (1.41), desc_application (1.13), lab_andriod (1.73), rep_name_37 (1.05), lab_mobile_application (1.88), lab_ios (4.55), rep_name_6 (1.41), rep_name_38 (1.35), sum_mobile_application ), sum_mobile (0,98), rep_name_39 (0,74), sum_resum_hide (0,88), rep_name_40 (0,81), lab_Duplication von Stellenangeboten (0,76)
Architektur: sum_statistics_response (1.1), rep_name_41 (1.4), lab_graphics_views_and_responses_ Stellenangebote (1.04), lab_creation_of Stellenangebote (1.16), lab_quotas (1.0), sum_special Angebot (1.02), rep_name_42 (1.33) 1.01_01_01 ), rep_name_43 (1.09), sum_dependent (0.83), sum_statistics (0.83), lab_responses_worker (0.76), sum_500ka (0.74)
Gehaltsbank: lab_500 (1.18), lab_authorization (0.79), sum_500 (1.04), rep_name_44 (0.85), sum_500_site (1.03), lab_site (1.54), lab_visibility_resume (1.54), lab_price list (1.26), lab_setting_visibility_7_resume (resume sum_error (0,79), lab_delivered_orders (1,33), rep_name_43 (0,74), sum_ie_11 (0,69), sum_500_error (0,66), sum2_site_ite (0,65)
Mobile Produkte: lab_mobile_application (1.69), lab_backs (1.65), sum_hr_mobile (0.81), lab_applicant (0.88), lab_employer (0.84), sum_mobile (0.81), rep_name_45 (1.2), desc_d0 (0.87), rep_name_46 (1.rr), sum_h 0,79), sum_incorrect_search_work (0,61), desc_application (0,71), rep_name_47 (0,69), rep_name_28 (0,61), sum_work_search (0,59)
Pandora: sum_receive (2.68), desc_receive (1.72), lab_sms (1.59), sum_ letter (2.75), sum_notification_response (1.38), sum_password (1.52), lab_recover_password (1.52), lab_mail_mail (1.31, mail, mailbox (1.91) ), lab_mail (1,72), lab_mail (3,37), desc_mail (1,69), desc_mail (1,47), rep_name_6 (1,32)
Peppers: lab_saving_summary (1.43), sum_summing (2.02), sum_oron (1.57), sum_oron_vacancy (1.66), desc_resum (1.19), lab_summing (1.39), sum_code (1.2), lab_applicant (1.34), sum_index (1.47), sum_index ), lab_creation_summary (1.28), rep_name_45 (1.82), sum_civilness (1.47), sum_save_summum (1.18), lab_invital_index (1.13)
Suche-1: sum2_poi_is_search (1.86), sum_loop (3.59), lab_questions_o_search (3.86), sum2_poi (1.86), desc_overs (2.49), lab_observing_summary (2.2), lab_observer (2.32), lab_loop (4.3oopropo_1) (1.62), sum_synonym (1.71), sum_sample (1.62), sum2_isk (1.58), sum2_is_isk (1.57), lab_auto-update_sum (1.57)
Suche-2: rep_name_48 (1.13), desc_d1 (1.1), lab_premium_in_search (1.02), lab_views_of Stellenangebote (1.4), sum_search (1.4), desc_d0 (1.2), lab_show_contacts (1.17), rep_name_49 (1.12950, lab13 (1.05), lab_search_of Stellenangebote (1.62), lab_responses_and_invitations (1.61), sum_response (1.09), lab_selected_results (1.37), lab_filter_of_responses (1.08)
Superprodukte: lab_contact_information (1.78), desc_address (1.46), rep_name_46 (1.84), sum_address (1.74), lab_selected_resumes (1.45), lab_reviews_worker (1.29), sum_right_shot (1.29), sum_right_range (1.29) ), sum_error_position (1.33), rep_name_42 (1.32), sum_quota (1.14), desc_address_office (1.14), rep_name_51 (1.09)
Die Schilder spiegeln ungefähr wider, was die Teams tun.
Modellnutzung
Darauf aufbauend ist der Aufbau des Modells abgeschlossen und es ist möglich, ein Programm auf dessen Basis zu erstellen.
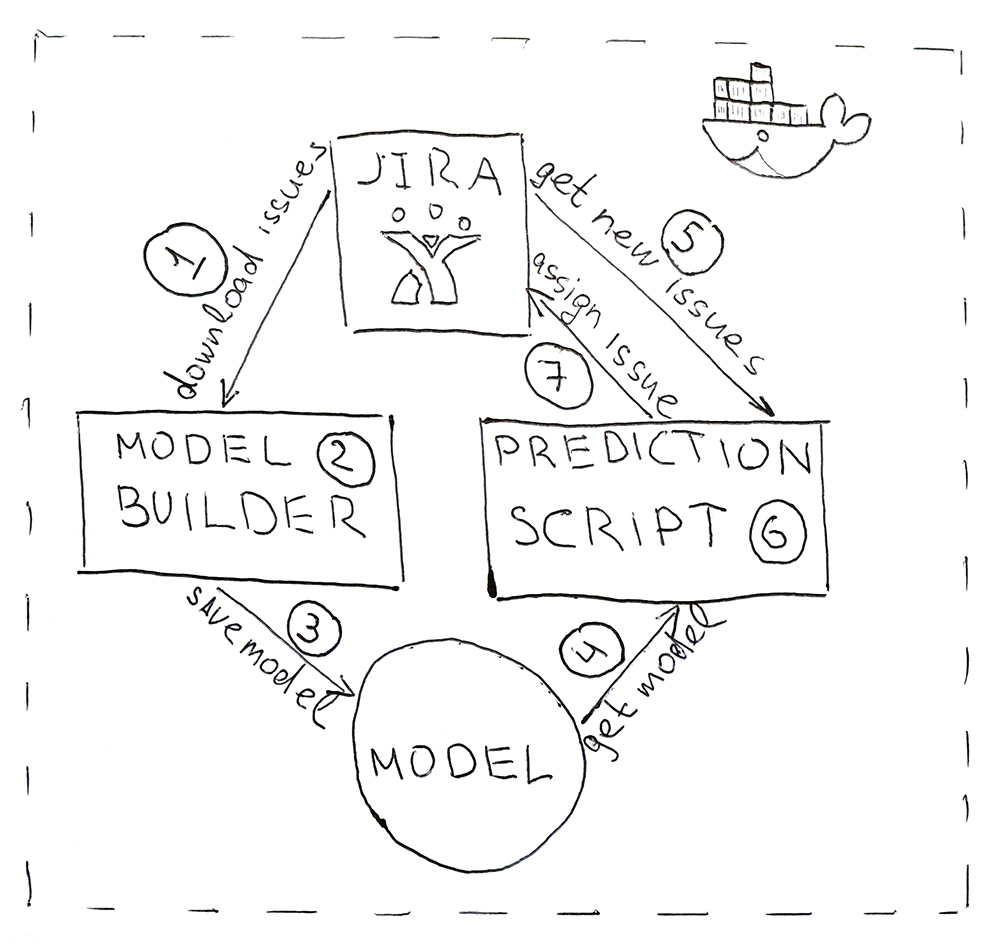
Das Programm besteht aus zwei Python-Skripten. Der erste erstellt ein Modell und der zweite macht Vorhersagen.
- Jira bietet eine API, über die Sie bereits abgeschlossene Aufgaben (HHS) herunterladen können. Einmal am Tag wird das Skript gestartet und heruntergeladen.
- Heruntergeladene Daten werden in Tags konvertiert. Zunächst werden die Daten für Training und Test geschlagen und zur Validierung an das ML-Modell übermittelt, um sicherzustellen, dass die Qualität nicht von Anfang an abnimmt. Und dann wird das Modell zum zweiten Mal auf alle Daten trainiert. Der gesamte Vorgang dauert ca. 10 Minuten.
- Das trainierte Modell wird auf der Festplatte gespeichert. Ich habe das Dill- Dienstprogramm verwendet, um Objekte zu serialisieren. Neben dem Modell selbst müssen auch alle Objekte gespeichert werden, die zum Abrufen der Merkmale verwendet wurden. Dies dient dazu, Schilder für die neue HHS an derselben Stelle zu platzieren.
- Mit demselben Dill wird das Modell zur Vorhersage in das Skript geladen, das alle 5 Minuten ausgeführt wird.
- Gehen Sie zu Jira für die neue HHS.
- Wir erhalten die Zeichen und geben sie an das Modell weiter, das für jede HHS den Klassennamen - den Namen des Teams - zurückgibt.
- Wir finden die für das Team verantwortliche Person und weisen ihm über die Jira-API eine Aufgabe zu. Es kann ein Tester sein, wenn das Team keinen Tester hat, dann ist es ein Teamleiter.
Um die Bereitstellung des Programms zu vereinfachen und dieselben Bibliotheksversionen wie während der Entwicklung zu verwenden, werden Skripts in einen Docker-Container gepackt.
Infolgedessen haben wir den Routineprozess automatisiert. Die Genauigkeit von 76% ist nicht zu groß, aber in diesem Fall sind die Fehler nicht kritisch. Alle Aufgaben finden ihre Ausführenden, und vor allem müssen Sie jetzt nicht mehr mehrmals am Tag abgelenkt werden, um die Essenz der Aufgaben zu verstehen und nach verantwortlichen Aufgaben zu suchen. Alles funktioniert automatisch! Hurra!