Heute möchten wir über eine so nützliche Funktion von Yandex.Cloud wie unterbrochene virtuelle Maschinen sprechen. Dies ist eine spezielle Option, die Sie beim Erstellen einer virtuellen Maschine auswählen können, um Computerressourcen zu einem reduzierten Preis zu verwenden. Was ist das Besondere an unterbrechbaren virtuellen Maschinen, warum sind sie billiger als normale und in welchen Fällen ist es ratsam, sie zu verwenden?

Die Kapazitäten von Yandex.Cloud und genauer gesagt des
Yandex Compute Cloud- Infrastrukturdienstes sind deutlich höher als die von Benutzern verwendeten. Standardmäßig wird davon ausgegangen, dass Benutzer beliebig skalieren können. Zumindest aus diesen Gründen übersteigen die verfügbaren Ressourcen der Cloud-Plattform ohne Berücksichtigung anderer Aspekte die aktuelle Nachfrage erheblich. Bei diesen freien Kapazitäten entstehen unterbrochene virtuelle Maschinen.
Hauptbeschränkungen
Kurz gesagt kann die Art der unterbrochenen virtuellen Maschinen wie folgt beschrieben werden: Der Dienst bietet an, seine kostenlosen Computerressourcen zu einem niedrigeren Preis zu nutzen, vorausgesetzt, diese Ressourcen können jederzeit abgerufen werden.
Im Allgemeinen funktionieren unterbrochene virtuelle Maschinen wie normale virtuelle Maschinen, weisen jedoch eine Reihe von Einschränkungen auf:
- Sie sind nicht durch ein Service Level Agreement (SLA) abgedeckt.
- Die Fähigkeit zum Erstellen und Ausführen ist nicht garantiert.
- Sie können jederzeit zum Anhalten gezwungen werden. Die Wahrscheinlichkeit eines Stopps ist gering, aber ungleich Null. Sie kann sich im Laufe der Zeit ändern und in verschiedenen Yandex.Cloud-Verfügbarkeitszonen variieren.
- Eine unterbrochene virtuelle Maschine kann nicht normalisiert werden, sondern eine reguläre unterbrochene. Das entsprechende Flag wird einmal gesetzt und ändert sich nicht.
- Die Maschine wird sicher in einem Zeitraum von nicht mehr als 24 Stunden angehalten.
In der Praxis funktionieren unterbrochene virtuelle Maschinen in den allermeisten Fällen alle 24 Stunden, die in den Servicebedingungen vorgesehen sind. Ein erzwungener Stopp tritt in der Regel nur auf, wenn in kurzer Zeit eine große Anzahl gewöhnlicher virtueller Maschinen in einer bestimmten Verfügbarkeitszone erstellt wird: Ein neuer Benutzer mit schwerwiegenden Anforderungen wird angezeigt oder aktuelle Benutzer werden massiv skaliert.
Gleichzeitig kann die gestoppte virtuelle Maschine erneut gestartet werden: Alle Daten auf den Festplatten werden sowohl beim automatischen als auch beim manuellen Herunterfahren gespeichert.
Anwendungsfälle
Einschränkungen für unterbrochene virtuelle Maschinen werfen eine logische Frage auf: Wie werden sie angewendet, wenn Ressourcen jederzeit widerrufen werden können? Zur Erklärung hier einige mögliche Anwendungsfälle.
Stapelverarbeitung
Die Stapelverarbeitung umfasst die parallele Ausführung einer großen Anzahl ressourcenintensiver Aufgaben. Dies kann die Konvertierung von Dateiformaten, Bildverarbeitung und -erkennung sowie
ETL-Operationen sein . Unter dem Strich gibt es in der Stapelverarbeitung eine Jobwarteschlange und eine ganze Reihe von Arbeitsprozessen (Executoren), die Jobs aus der Warteschlange empfangen. Wenn ein einzelner Executor, der auf einem unterbrochenen Computer ausgeführt wird, stoppt, wird die Aufgabe einfach an den nächsten Executor übertragen. Mit anderen Worten, das Stoppen einer oder sogar mehrerer virtueller Maschinen hat keine wesentlichen negativen Auswirkungen auf den Prozess und das Ergebnis der Verarbeitung.

Bei der Stapelverarbeitung von Daten geht es um die Verwendung von Dutzenden von virtuellen Maschinen. Die Verwendung von intermittierenden Maschinen bietet sehr spürbare Einsparungen. Einer der Hauptverbraucher produktiver diskontinuierlicher virtueller Maschinen mit 32 Kernen ist Seismotech, ein langjähriger Yandex.Cloud-Client. Seismotek verarbeitet seismische Daten, die für die Erkundung von Gas- und Ölfeldern erforderlich sind. Bei der seismischen Erkundung wird mit großen Informationsmengen gearbeitet. Die Daten werden stapelweise verarbeitet. Das Unternehmen verwendet gleichzeitig mehr als 60 unterbrochene Maschinen: insgesamt bis zu 2000 vCPU und 4000 GB RAM.
Projekte auf Hadoop
Mit Hadoop werden verteilte Programme entwickelt und ausgeführt, die auf Clustern von Hunderten und Tausenden von kostengünstigen Knoten ausgeführt werden. Die von Hadoop bereitgestellten Mechanismen für die Dateireplikation und den automatischen Neustart von Aufgaben auf ausgefallenen Knoten gewährleisten die Stabilität eines verteilten Systems gegenüber Ausfällen einzelner Computer. Aus diesem Grund kann bei Verwendung von Hadoop zumindest ein Teil der Knoten problemlos für unterbrochene virtuelle Maschinen bereitgestellt werden. Wenn sie vorzeitig beendet werden, werden Aufgaben an andere Knoten gesendet.
Web Services-Failover
Die kontinuierliche Verfügbarkeit des Webdienstes kann mithilfe eines Clusters sichergestellt werden. Ein Cluster besteht aus zwei oder mehr Servern. Eine seiner Aufgaben bei der Anwendung auf Webdienste besteht darin, einen stabilen Betrieb zum Zeitpunkt von Spitzenlasten sicherzustellen. Typische Beispiele: Online-Shopping-Sites oder Sport-Sites, bei denen das Verkehrswachstum an bestimmte Daten gebunden ist. Für Geschäfte können dies traditionelle Feiertage oder Rabatte sein, und für sportbezogene Websites können dies Veranstaltungstage sein, an denen Live-Übertragungen, Rezensionen und Fotoberichte veröffentlicht werden. In solchen Momenten kann das Verkehrsaufkommen erheblich zunehmen.
Der Cluster muss den Zustrom von Besuchern bewältigen, indem er den Verkehr auf verschiedene Knoten verteilt. Für einen Zeitraum mit starkem, aber kurzlebigem Lastwachstum kann Fehlertoleranz durch Hinzufügen von Servern auf nicht mehr verfügbaren virtuellen Maschinen bereitgestellt werden. Diese Option ist kostengünstig und macht ihre Arbeit gut. Es ist wichtig, eine Bedingung zu beachten: Ein solcher Cluster muss hybride sein, dh normale virtuelle Maschinen enthalten. In diesem Fall führt selbst das unwahrscheinliche Anhalten unterbrochener Maschinen nicht zu einem Servicefehler.
Projekte bei Kubernetes
Kubernetes automatisiert die Bereitstellung, Skalierung und Verwaltung von Containeranwendungen auf einer großen Anzahl von Knoten. Eine der Hauptentitäten, die als Baustein von Kubernetes bezeichnet werden kann, befindet sich unter (pod). Pod ermöglicht den Start eines oder mehrerer Container auf einem Knoten. Ein Knoten für jeden Herd wird vom Kubernetes-Scheduler ausgewählt und zugewiesen. Wenn ein separater Knoten mit einem laufenden Herd ausfällt, überträgt der Scheduler ihn automatisch an einen Knoten, der im normalen Modus arbeitet. Dieses Schema zur Aufrechterhaltung des Zustands legt nahe, dass ein Teil der Knoten in diskontinuierlichen virtuellen Maschinen gehostet werden kann.
Kontinuierliche Integrationstests
Die Praxis der kontinuierlichen Integration basiert auf der häufigen Montage und Erprobung des Projekts. In diesem Fall werden hauptsächlich automatisierte Tests verwendet. Schematisch sieht es so aus: Eine Testumgebung wird auf einer virtuellen Maschine erstellt, der letzte Build der Anwendung wird auf diese hochgeladen, automatisierte Tests werden durchgeführt, die Testergebnisse werden hochgeladen, die virtuelle Maschine wird gelöscht. Das Testen dauert in der Regel mehrere zehn Minuten, seltener mehrere Stunden.
Traditionell sind die Schwachstellen der kontinuierlichen Integration erhebliche Kosten für die Unterstützung des Integrationsprozesses selbst und der hohe Bedarf an Computerressourcen. Unter diesem Gesichtspunkt und unter Berücksichtigung des Zeitrahmens automatisierter Tests scheinen eingestellte virtuelle Maschinen für eine kontinuierliche Integration mehr als geeignet zu sein. Sie sind viel billiger und die Wahrscheinlichkeit, dass ein Auto zum Zeitpunkt des Tests sofort anhält, ist verschwindend gering. Selbst wenn das Auto noch angehalten wird, ist der Schaden aus Sicht des Unternehmens minimal.
Verwendung in Verbindung mit anderen Yandex.Cloud-Diensten
Mit dem Yandex Instance Groups-Dienst können Sie den Status einer ganzen Gruppe unterbrochener virtueller Maschinen automatisch überwachen. Er kann unabhängig voneinander virtuelle Maschinen mit den angegebenen Merkmalen erstellen, die erforderliche Anzahl von Maschinen in der Gruppe verwalten und unterbrochene Instanzen neu starten, wenn sie anhalten. Es spielt keine Rolle, ob seit dem Start ein erzwungener Stopp stattgefunden hat oder 24 Stunden vergangen sind. Nur eines ist wichtig: Ein Neustart wird durchgeführt, wenn Ressourcen verfügbar sind. Yandex Instance Groups vereinfacht die Arbeit mit unterbrochenen virtuellen Maschinen, kann jedoch nicht garantieren, dass in einer bestimmten Verfügbarkeitszone notwendigerweise freie Kapazitäten vorhanden sind.
Wirtschaftsleistung
Wie bereits erwähnt, können unterbrechbare virtuelle Maschinen die Kosten für die Verwendung von Computerressourcen senken. In Yandex haben wir vor einigen Jahren begonnen, an einer ähnlichen Funktion zu arbeiten. Um Computeraufgaben in garantierte ausführbare und unterbrechbare Aufgaben zu unterteilen, waren erhebliche Investitionen erforderlich. Aber es war nicht umsonst: Am Ende haben wir die nützliche Auslastung der Serverinfrastruktur von 30-40% auf 70-80% erhöht.

Jetzt stehen allen Yandex.Cloud-Benutzern auf Knopfdruck ähnliche Funktionen zur Verfügung. Ein einfaches Beispiel: Wenn Sie die Hälfte der verwendeten virtuellen Maschinen mit hundertprozentiger Kernellast in das Interrupt-Format übertragen, können Sie bis zu 35-40% des Budgets einsparen.
Zu reduzierten Kosten stehen CPU- und RAM-Ressourcen zur Verfügung. Speicherplatz und IP-Adressen werden zu regulären Preisen bezahlt. Dies zeigt eine einfache Berechnung für die Cascade Lake-Plattform.
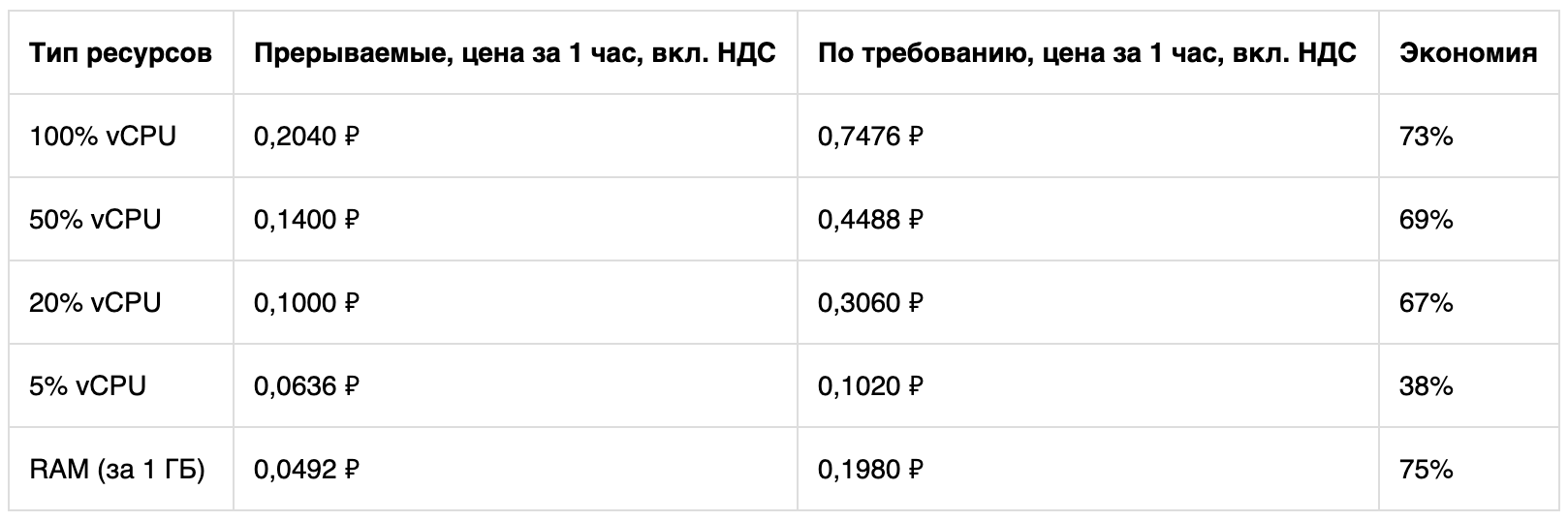
Wenn Sie möchten, können Sie die Kosten für die Verwendung virtueller Maschinen in verschiedenen Modi mithilfe eines
Taschenrechners vergleichen .
Wir hoffen, dass wir ein wenig Klarheit schaffen und einige nützliche Beispiele nennen konnten. In diesen Fällen können Sie unterbrechbare virtuelle Maschinen verwenden, um die Kosten für Computerressourcen zu senken, ohne die Qualität bei der Ausführung von Aufgaben zu verlieren.
Weitere Veröffentlichungen zu Cloud on Habré