Ziele und Anforderungen zum Testen von "1C Accounting"
Der Hauptzweck des Tests besteht darin, das Verhalten des 1C-Systems auf zwei verschiedenen DBMS unter anderen identischen Bedingungen zu vergleichen. Das heißt, Die Konfiguration der 1C-Datenbanken und die anfängliche Datenpopulation sollten bei jedem Test gleich sein.
Die wichtigsten Parameter, die während des Tests erhalten werden sollten:
- Die Ausführungszeit jedes Tests (von der Entwicklungsabteilung 1C entfernt)
- Die Belastung der DBMS- und Serverumgebung während des Tests wird von DBMS-Administratoren sowie von Systemadministratoren in der Serverumgebung entfernt
Das Testen des 1C-Systems sollte unter Berücksichtigung der Client-Server-Architektur durchgeführt werden. Daher ist es erforderlich, einen Benutzer oder mehrere Benutzer im System zu emulieren, um die Eingabe von Informationen in die Schnittstelle zu erarbeiten und diese Informationen in der Datenbank zu speichern. Gleichzeitig ist es erforderlich, dass eine große Menge periodischer Informationen über einen großen Zeitraum veröffentlicht wird, um Summen in den Akkumulationsregistern zu erstellen.
Zur Durchführung von Tests wurde ein Algorithmus in Form eines Skripts zum Testen von Skripten für die Konfiguration von 1C Accounting 3.0 entwickelt, bei dem die serielle Eingabe von Testdaten in das 1C-System durchgeführt wird. Mit dem Skript können Sie verschiedene Einstellungen für die durchgeführten Aktionen und die Menge der Testdaten festlegen. Detaillierte Beschreibung unten.
Beschreibung der Einstellungen und Eigenschaften der getesteten Umgebungen
Wir bei Fortis haben beschlossen, die Ergebnisse zu überprüfen, einschließlich des bekannten
Gilev-Tests .
Wir wurden auch aufgefordert, Tests durchzuführen, einschließlich einiger Veröffentlichungen zu den Ergebnissen von Leistungsänderungen während des Übergangs von MS SQL Server zu PostgreSQL. Wie zum Beispiel:
1C Battle: PostgreSQL 9.10 gegen MS SQL 2016 .
Hier ist also die Infrastruktur zum Testen:
Die Server für MS SQL und PostgreSQL waren virtuell und wurden abwechselnd für den gewünschten Test ausgeführt. 1C stand auf einem separaten Server.
DetailsHypervisor-Spezifikation:Modell: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 bei 2,40 GHz (2 Sockel * 16 CPU HT = 32 CPU)
RAM: 212 GB
Betriebssystem: VMWare ESXi 6.5
PowerProfile: Leistung
Hypervisor Disk Subsystem:Controller: Adaptec 6805, Cache-Größe: 512 MB
Volumen: RAID 10, 5,7 TB
Streifengröße: 1024 KB
Schreib-Cache: Ein
Lese-Cache: Aus
Räder: 6 Stk. HGST HUS726T6TAL,
Sektorgröße: 512 Bytes
Cache schreiben: ein
PostgreSQL wurde wie folgt konfiguriert:- postgresql.conf:
Die Grundeinstellungen wurden mit dem Taschenrechner vorgenommen - pgconfigurator.cybertec.at . Die Parameter vast_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost wurden basierend auf Informationen geändert, die aus den am Ende der Veröffentlichung genannten Quellen stammen. Der Wert des Parameters temp_buffers wurde erhöht, basierend auf dem Vorschlag, dass 1C temporäre Tabellen aktiv verwendet:
listen_addresses = '*' max_connections = 1000
- Kernel, Betriebssystemparameter:
Die Einstellungen werden im Profildateiformat für den optimierten Dämon festgelegt:
[sysctl]
- Dateisystem:
Alle Inhalte der Datei postgresql.conf:
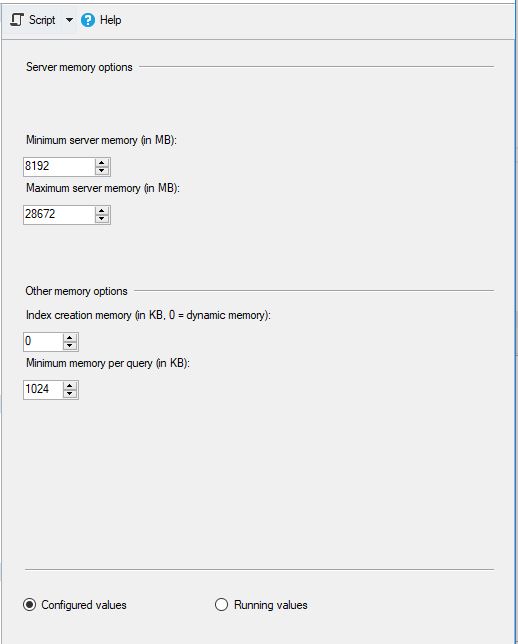
MS SQL wurde wie folgt konfiguriert: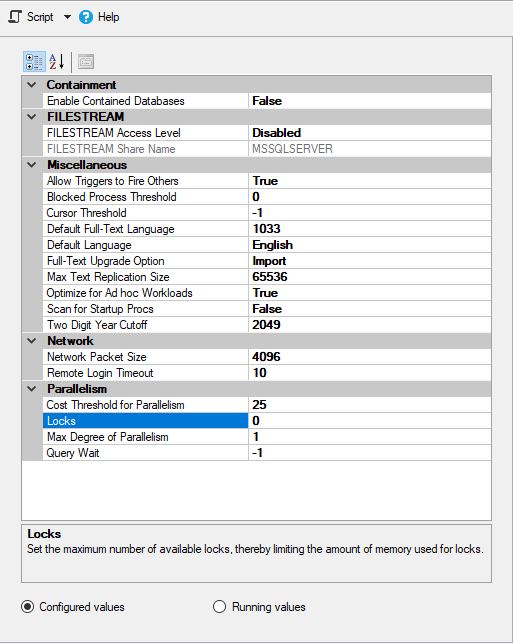
und
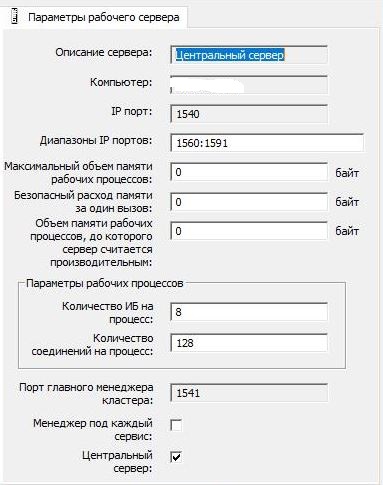
Die Einstellungen des 1C-Clusters wurden standardmäßig beibehalten:

und
Auf den Servern befand sich kein Antivirenprogramm, und es wurde nichts von Drittanbietern installiert.
Für MS SQL wurde tempdb auf ein separates logisches Laufwerk verschoben. Die Datendateien und Transaktionsprotokolldateien für die Datenbanken befanden sich jedoch auf demselben logischen Laufwerk (dh die Datendateien und Transaktionsprotokolle wurden nicht in separate logische Laufwerke aufgeteilt).
Das Indizieren von Laufwerken in Windows, in dem sich MS SQL Server befand, wurde auf allen logischen Laufwerken deaktiviert (wie es in den meisten Fällen in prodovskih-Umgebungen üblich ist).
Beschreibung des Hauptalgorithmus des Skripts für automatisierte TestsDer geschätzte Haupttestzeitraum beträgt 1 Jahr. In diesem Zeitraum werden für jeden Tag Dokumente und Referenzinformationen gemäß den angegebenen Parametern erstellt.
An jedem Ausführungstag werden Eingabe- und Ausgabeinformationsblöcke gestartet:
- Block 1 "_" - "Empfang von Waren und Dienstleistungen"
- Das Kontrahentenverzeichnis wird geöffnet
- Ein neues Element des Verzeichnisses "Auftragnehmer" wird mit Blick auf "Lieferant" erstellt.
- Ein neues Element des Verzeichnisses "Verträge" wird mit der Ansicht "Mit Lieferant" für eine neue Gegenpartei erstellt
- Das Verzeichnis "Nomenklatur" wird geöffnet
- Eine Reihe von Elementen des Verzeichnisses "Nomenklatur" wird mit dem Typ "Produkt" erstellt.
- Eine Reihe von Elementen des Verzeichnisses "Nomenklatur" wird mit dem Typ "Service" erstellt.
- Eine Liste von Dokumenten "Quittungen von Waren und Dienstleistungen"
- Es wird ein neues Dokument „Wareneingang für Waren und Dienstleistungen“ erstellt, in dem die tabellarischen Teile „Waren“ und „Dienstleistungen“ mit den erstellten Datensätzen gefüllt sind
- Der Bericht „Account Card 41“ wird für den aktuellen Monat erstellt (wenn das Intervall für die zusätzliche Bildung angegeben ist).
- Block 2 "_" - "Verkauf von Waren und Dienstleistungen"
- Das Kontrahentenverzeichnis wird geöffnet
- Mit der Ansicht "Käufer" wird ein neues Element des Verzeichnisses "Gegenparteien" erstellt
- Ein neues Element des Verzeichnisses "Verträge" wird mit der Ansicht "Mit Käufer" für eine neue Gegenpartei erstellt
- Eine Liste der Dokumente „Verkauf von Waren und Dienstleistungen“ wird geöffnet.
- Es wird ein neues Dokument „Verkauf von Waren und Dienstleistungen“ erstellt, in dem die tabellarischen Teile „Waren“ und „Dienstleistungen“ gemäß den angegebenen Parametern aus zuvor erstellten Daten ausgefüllt werden
- Der Bericht „Account Card 41“ wird für den aktuellen Monat erstellt (wenn das Intervall für die zusätzliche Bildung angegeben ist).
- Der Bericht „Account Card 41“ für den aktuellen Monat wird generiert
Am Ende jedes Monats, in dem die Erstellung von Dokumenten durchgeführt wurde, werden Eingabe- und Ausgabeblöcke von Informationen ausgeführt:
- Der Bericht „Account Card 41“ wird vom Jahresanfang bis zum Monatsende erstellt
- Der Bericht „Umsatzbilanz“ wird vom Jahresanfang bis zum Monatsende erstellt
- Das Regulierungsverfahren „Monatsende“ wird durchgeführt
Das Ergebnis der Ausführung gibt Auskunft über die Testzeit in Stunden, Minuten, Sekunden und Millisekunden.
Hauptmerkmale des Testskripts:- Möglichkeit zum Deaktivieren / Aktivieren einzelner Einheiten
- Möglichkeit, die Gesamtzahl der Dokumente für jeden der Blöcke anzugeben
- Möglichkeit, die Anzahl der Dokumente für jeden Block pro Tag anzugeben
- Möglichkeit, die Menge der Waren und Dienstleistungen in Dokumenten anzugeben
- Möglichkeit, Listen mit quantitativen und Preisindikatoren für die Aufzeichnung festzulegen. Dient zum Erstellen verschiedener Wertesätze in Dokumenten
Der grundlegende Testplan für jede der Datenbanken:- "Der erste Test." , « »
- — 20 . 1 . : 50 «», 50 «», 100 «», 50 «» + «», 50 «» + «», 2 « ». 1 1
- « ». ,
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:- , :
- « » « »
- 1 "*.dt"
- « »
Ergebnisse
Und jetzt die interessantesten Ergebnisse auf dem MS SQL Server DBMS:Details:
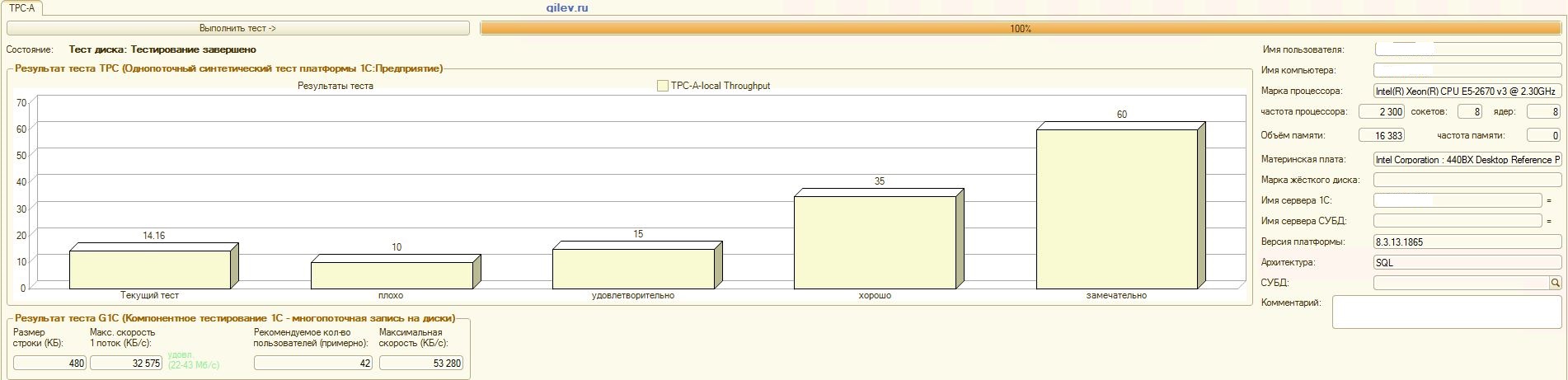
:
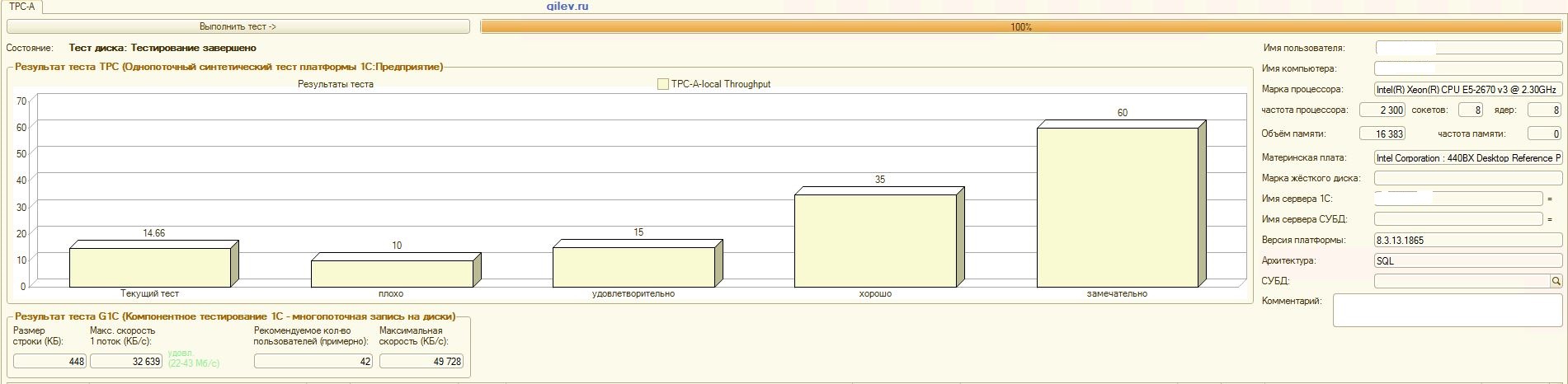
:

PostgreSQL,
, , , :
:
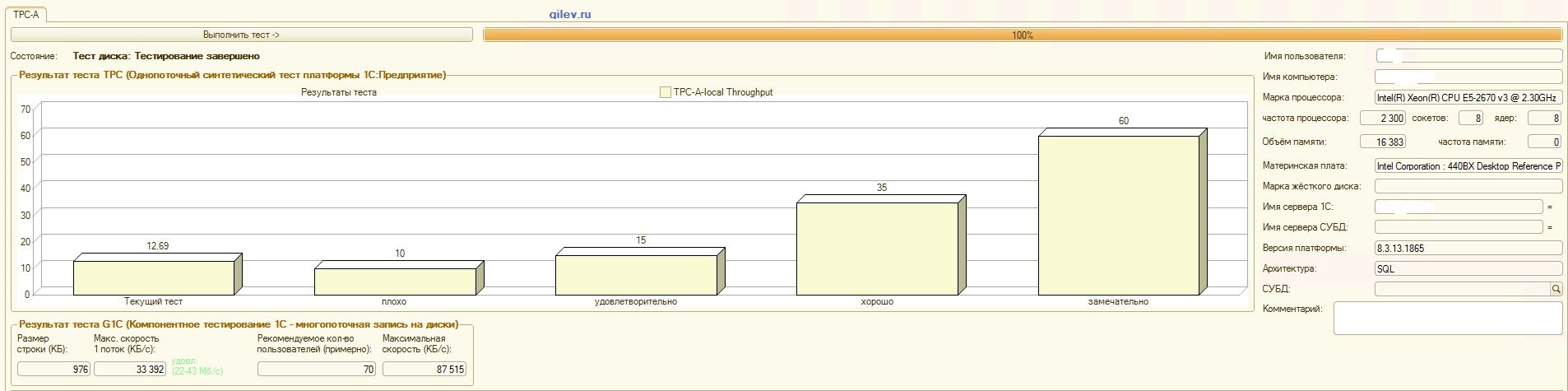
:
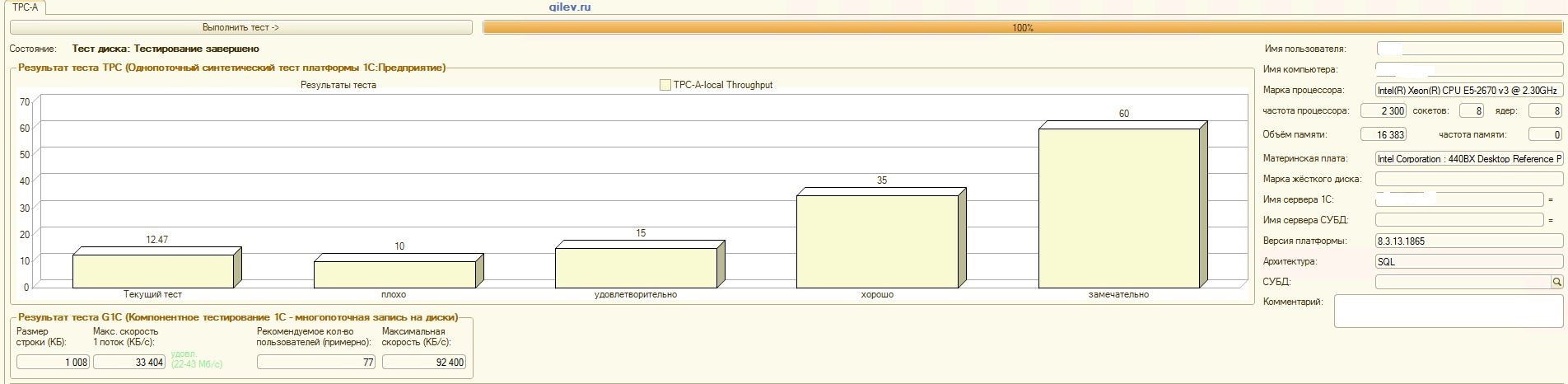
:

Gilev-Test:Wie aus den Ergebnissen hervorgeht, verlor PostgreSQL im allgemeinen synthetischen Test durchschnittlich 14,82% der durchschnittlichen Leistung von MS SQL-DBMS . Nach den letzten beiden Indikatoren zeigte PostgreSQL jedoch ein signifikant besseres Ergebnis als MS SQL.Spezialisierte Tests für 1C Accounting:Wie aus den Ergebnissen hervorgeht, funktioniert 1C Accounting mit MS SQL und PostgreSQL mit den oben angegebenen Einstellungen ungefähr gleich .In beiden Fällen funktionierte das DBMS stabil.Natürlich müssen Sie möglicherweise sowohl vom DBMS als auch vom Betriebssystem und vom Dateisystem eine subtilere Optimierung vornehmen. Alles wurde während der Ausstrahlung von Veröffentlichungen erledigt, die besagten, dass die Produktivität beim Wechsel von MS SQL zu PostgreSQL erheblich oder in etwa gleich hoch sein würde. Darüber hinaus wurden bei diesen Tests eine Reihe von Maßnahmen ergriffen, um das Betriebssystem und das Dateisystem für CentOS selbst zu optimieren, die oben beschrieben wurden.Es ist erwähnenswert, dass der Gilev-Test für PostgreSQL viele Male ausgeführt wurde - die besten Ergebnisse werden erzielt. Der Gilev-Test wurde dreimal unter MS SQL ausgeführt, sodass keine Optimierung unter MS SQL durchgeführt wurde. Alle nachfolgenden Versuche waren, den Elefanten zu den MS SQL-Metriken zu bringen.Nachdem der optimale Unterschied im Gilev-Synthesetest zwischen MS SQL und PostgreSQL erreicht worden war, wurden spezielle Tests für das oben beschriebene 1C-Rechnungswesen durchgeführt.Die allgemeine Schlussfolgerung lautet, dass 1C Accounting trotz der erheblichen Leistungseinbußen beim Gilev-Synthesetest von PostgreSQL DBMS in Bezug auf MS SQL mit den oben angegebenen Einstellungen sowohl auf MS SQL DBMS als auch auf PostgreSQL DBMS installiert werden kann .Bemerkungen
Es sollte sofort beachtet werden, dass diese Analyse nur durchgeführt wurde, um die 1C-Leistung in verschiedenen DBMS zu vergleichen.Diese Analyse und Schlussfolgerung sind nur für 1C Accounting unter den oben beschriebenen Bedingungen und Softwareversionen korrekt. Basierend auf der erhaltenen Analyse ist es unmöglich, genau zu schließen, was mit anderen Einstellungen und Softwareversionen sowie mit einer anderen 1C-Konfiguration passieren wird.Das Gilev-Testergebnis legt jedoch nahe, dass bei allen Konfigurationen von 1C Version 8.3 und höher bei korrekten Einstellungen der maximale Leistungsabfall für PostgreSQL-DBMS im Vergleich zu MS SQL-DBMS wahrscheinlich nicht mehr als 15% beträgt. Es ist auch zu berücksichtigen, dass detaillierte Tests für einen genauen Vergleich viel Zeit und Ressourcen erfordern. Auf dieser Grundlage können wir eine wahrscheinlichere Annahme machen, dass1C Version 8.3 und höher kann mit einem maximalen Leistungsverlust von bis zu 15% von MS SQL auf PostgreSQL migriert werden . Es gab keine objektiven Hindernisse für den Übergang, bis diese 15% möglicherweise nicht auftreten, und im Falle ihrer Manifestation reicht es aus, bei Bedarf nur ein wenig leistungsstärkere Ausrüstung zu kaufen.Es ist auch wichtig zu beachten, dass die getesteten Datenbanken klein waren, d. H. Deutlich weniger als 100 GB Datengröße, und die maximale Anzahl gleichzeitig laufender Threads 4 betrug. Dies bedeutet, dass für große Datenbanken, deren Größe signifikant größer als 100 GB ist (z. B. etwa 1 TB). sowie für Datenbanken mit intensiven Zugriffen (Dutzende und Hunderte von gleichzeitig aktiven Flüssen) können diese Ergebnisse falsch sein.Für eine objektivere Analyse wird es in Zukunft hilfreich sein, den veröffentlichten MS SQL Server 2019 Developer und PostgreSQL 12 zu vergleichen, die auf demselben CentOS-Betriebssystem installiert sind, sowie wenn MS SQL auf der neuesten Version von Windows Server OS installiert ist. Jetzt bringt niemand PostgreSQL unter Windows, sodass der Leistungsabfall von PostgreSQL-DBMS sehr bedeutend sein wird.Natürlich spricht der Gilev-Test allgemein über die Leistung und nicht nur für 1C. Im Moment ist es jedoch noch zu früh zu sagen, dass das MS SQL DBMS immer deutlich besser sein wird als das PostgreSQL DBMS, da es nicht genügend Fakten gibt. Um diese Aussage zu bestätigen oder zu widerlegen, müssen Sie eine Reihe anderer Tests durchführen. Für .NET müssen Sie beispielsweise sowohl atomare Aktionen als auch komplexe Tests schreiben, diese wiederholt und unter verschiedenen Bedingungen ausführen, die Ausführungszeit festlegen und den Durchschnittswert ermitteln. Vergleichen Sie dann diese Werte. Dies wird eine objektive Analyse sein.Im Moment sind wir nicht bereit, eine solche Analyse durchzuführen, aber in Zukunft ist es durchaus möglich, sie durchzuführen. Dann werden wir detaillierter beschreiben, unter welchen Operationen PostgreSQL besser als MS SQL ist und wie viel in Prozent und wo MS SQL besser als PostgreSQL ist und wie viel in Prozent.Außerdem wurden in unserem Test keine Optimierungsmethoden für MS SQL angewendet, die hier beschrieben werden . Vielleicht hat dieser Artikel nur vergessen, die Windows-Datenträgerindizierung zu deaktivieren.Beim Vergleich zweier DBMS sollte ein weiterer wichtiger Punkt beachtet werden: PostgreSQL DBMS ist kostenlos und offen, während MS SQL DBMS bezahlt wird und den Quellcode geschlossen hat.Jetzt auf Kosten des Gilev-Tests. Außerhalb der Tests wurden Spuren für den synthetischen Test (den ersten Test) und für alle anderen Tests entfernt. Der erste Test fragt hauptsächlich sowohl atomare Operationen (Einfügen, Aktualisieren, Löschen und Lesen) als auch komplexe (mit Bezug auf mehrere Tabellen sowie das Erstellen, Ändern und Löschen von Tabellen in der Datenbank) mit unterschiedlichen Mengen an Verarbeitungsdaten ab. Daher kann der Gilev-Synthesetest als recht objektiv angesehen werden, um die durchschnittliche einheitliche Leistung zweier Umgebungen (einschließlich DBMS) relativ zueinander zu vergleichen. Die absoluten Werte selbst sagen nichts aus, aber ihr Verhältnis zweier verschiedener Medien ist durchaus objektiv.Auf Kosten anderer Gilev-Tests. Die Ablaufverfolgung zeigt, dass die maximale Anzahl von Threads 7 betrug, die Schlussfolgerung zur Anzahl der Benutzer jedoch mehr als 50. Auf Anfrage ist auch nicht ganz klar, wie andere Indikatoren berechnet werden. Daher sind die übrigen Tests nicht objektiv und äußerst unterschiedlich und ungefähr. Nur spezielle Tests, die nicht nur die Besonderheiten des Systems selbst, sondern auch die Arbeit der Benutzer selbst berücksichtigen, liefern genauere Werte.Danksagung
- führte 1C-Setup durch und startete Gilev-Tests und leistete auch einen wesentlichen Beitrag zur Erstellung dieser Veröffentlichung:
- Roman Buts - Teamleiter 1C
- Alexander Gryaznov - 1C Programmierer
- Fortis-Kollegen, die einen wesentlichen Beitrag zur Optimierung der Optimierung für CentOS, PostgreSQL usw. geleistet haben, aber inkognito bleiben wollten
Besonderer Dank geht auch an uaggster und BP1988 für einige Ratschläge zu MS SQL und Windows.Nachwort
Auch eine merkwürdige Analyse wurde in diesem Artikel durchgeführt .Und welche Ergebnisse hatten Sie und wie haben Sie getestet?Quellen