Über Artikel
Dieser Beitrag ist eine kurze Notiz für Programmierer, die mehr darüber erfahren möchten, wie die GPU mit Verzweigungen umgeht. Sie können es als Einführung in dieses Thema betrachten. Ich empfehle, mit [
1 ], [
2 ] und [
8 ] zu beginnen, um eine Vorstellung davon zu bekommen, wie das GPU-Ausführungsmodell allgemein aussieht, da wir nur ein separates Detail betrachten werden. Für neugierige Leser gibt es alle Links am Ende des Beitrags. Wenn Sie Fehler finden, kontaktieren Sie mich.
Inhalt
- Über Artikel
- Inhalt
- Wortschatz
- Wie unterscheidet sich der GPU-Kern vom CPU-Kern?
- Was ist Konsistenz / Diskrepanz?
- Beispiele für die Verarbeitung von Ausführungsmasken
- Fiktive ISA
- AMD GCN ISA
- AVX512
- Wie gehe ich mit der Diskrepanz um?
- Referenzen
Wortschatz
- GPU - Grafikprozessor, GPU
- Flynns Klassifikation
- SIMD - Einzelbefehl mehrere Daten, Einzelbefehlsstrom, Mehrfachdatenstrom
- SIMT - Einzelbefehl mehrere Threads, Einzelbefehl Stream, mehrere Threads
- Wave (SIM) - Ein Stream, der im SIMD-Modus ausgeführt wird
- Linie (Spur) - ein separater Datenstrom im SIMD-Modell
- SMT - Simultanes Multithreading, gleichzeitiges Multithreading (Intel Hyper-Threading) [ 2 ]
- Mehrere Threads teilen sich die zentralen Computerressourcen
- IMT - Interleaved Multithreading, abwechselndes Multithreading [ 2 ]
- Mehrere Threads teilen sich die gesamten Computerressourcen des Kernels, aber nur einen
- BB - Basic Block, ein Basic Block - eine lineare Folge von Anweisungen mit einem einzigen Sprung am Ende
- ILP - Parallelität auf Befehlsebene, Parallelität auf Befehlsebene [ 3 ]
- ISA - Instruction Set Architecture, Befehlssatzarchitektur
In meinem Beitrag werde ich mich an diese erfundene Klassifikation halten. Es ähnelt in etwa der Organisation einer modernen GPU.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
Andere Namen:
- Der Kern kann CU, SM, EU heißen
- Eine Welle kann als Wellenfront, Hardware-Thread (HW-Thread), Warp oder Kontext bezeichnet werden
- Eine Zeile kann als Programm-Thread (SW-Thread) bezeichnet werden.
Wie unterscheidet sich der GPU-Kern vom CPU-Kern?
Jede aktuelle Generation von GPU-Kernen ist weniger leistungsfähig als Zentralprozessoren: einfaches ILP / Multi-Issue [
6 ] und Prefetch [
5 ], keine Prognose oder Vorhersage von Übergängen / Rückgaben. All dies, zusammen mit winzigen Caches, macht einen ziemlich großen Bereich auf dem Chip frei, der mit vielen Kernen gefüllt ist. Speicherlade- / Speichermechanismen sind in der Lage, die Kanalbreite um eine Größenordnung größer zu bewältigen (dies gilt nicht für integrierte / mobile GPUs) als herkömmliche CPUs, aber Sie müssen dies mit hohen Latenzen bezahlen. Um die Latenz zu verbergen, verwendet die GPU SMT [
2 ]. Während eine Welle inaktiv ist, verwenden andere die freien Computerressourcen des Kernels. Normalerweise hängt die Anzahl der von einem Kern verarbeiteten Wellen von den verwendeten Registern ab und wird dynamisch durch Zuweisen einer festen Registerdatei bestimmt [
8 ]. Die Planung für die Ausführung von Anweisungen ist hybride - dynamisch-statisch [
6 ] [
11 4.4]. Im SIMD-Modus ausgeführte SMT-Kernel erzielen hohe FLOPS-Werte (Floating-Point-Operationen pro Sekunde, Flops, Anzahl der Gleitkomma-Operationen pro Sekunde).
 Legendendiagramm. Schwarz - inaktiv, weiß - aktiv, grau - aus, blau - inaktiv, rot - ausstehendAbbildung 1. 4: 2-Ausführungsverlauf
Legendendiagramm. Schwarz - inaktiv, weiß - aktiv, grau - aus, blau - inaktiv, rot - ausstehendAbbildung 1. 4: 2-AusführungsverlaufDas Bild zeigt den Verlauf der Ausführungsmaske, wobei die x-Achse die Zeit von links nach rechts und die y-Achse die Kennung der Linie von oben nach unten zeigt. Wenn Sie dies immer noch nicht verstehen, kehren Sie nach dem Lesen der folgenden Abschnitte zur Zeichnung zurück.
Dies ist ein Beispiel dafür, wie der GPU-Kernausführungsverlauf in einer fiktiven Konfiguration aussehen kann: Vier Wellen teilen sich einen Sampler und zwei ALUs. Der Wellenplaner gibt in jedem Zyklus zwei Anweisungen aus zwei Wellen aus. Wenn eine Welle beim Ausführen eines Speicherzugriffs oder einer langen ALU-Operation inaktiv ist, wechselt der Scheduler zu einem anderen Wellenpaar, wodurch die ALU ständig zu fast 100% belegt ist.
Abbildung 2. 4: 1-AusführungsverlaufEin Beispiel mit der gleichen Last, aber dieses Mal wird in jedem Zyklus des Befehls nur eine Welle ausgegeben. Beachten Sie, dass die zweite ALU hungert.
Abbildung 3. Ausführungsverlauf 4: 4Dieses Mal werden in jedem Zyklus vier Anweisungen ausgegeben. Beachten Sie, dass es zu viele Anfragen an ALU gibt, sodass fast immer zwei Wellen warten (tatsächlich ist dies ein Fehler des Planungsalgorithmus).
Update Weitere Informationen zu den Schwierigkeiten bei der Planung der Ausführung von Anweisungen finden Sie unter [
12 ].
In der realen Welt haben GPUs unterschiedliche Kernkonfigurationen: Einige können bis zu 40 Wellen pro Kern und 4 ALUs haben, andere haben 7 feste Wellen und 2 ALUs. All dies hängt von vielen Faktoren ab und wird dank des sorgfältigen Prozesses der Architektursimulation bestimmt.
Darüber hinaus können echte SIMD-ALUs eine geringere Breite als die von ihnen bedienten Wellen haben, und dann dauert es mehrere Zyklen, um einen ausgegebenen Befehl zu verarbeiten. Der Faktor wird als Länge "Glockenspiel" bezeichnet [
3 ].
Was ist Konsistenz / Diskrepanz?
Schauen wir uns das folgende Code-Snippet an:
Beispiel 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
Hier sehen wir einen Befehlsstrom, in dem der Ausführungspfad von der Kennung der ausgeführten Zeile abhängt. Offensichtlich haben unterschiedliche Linien unterschiedliche Bedeutungen. Was wird passieren? Es gibt verschiedene Ansätze zur Lösung dieses Problems [
4 ], aber am Ende tun sie alle dasselbe. Ein solcher Ansatz ist die Ausführungsmaske, die ich behandeln werde. Dieser Ansatz wurde in den Nvidia-GPUs vor Volta und in den AMD GCN-GPUs verwendet. Der Hauptpunkt der Ausführungsmaske ist, dass wir für jede Zeile in der Welle ein Bit speichern. Wenn das entsprechende Zeilenausführungsbit 0 ist, werden keine Register für den nächsten ausgegebenen Befehl beeinflusst. Tatsächlich sollte die Zeile nicht den Einfluss des gesamten ausgeführten Befehls spüren, da ihr Ausführungsbit 0 ist. Dies funktioniert wie folgt: Die Welle bewegt sich in der Tiefensuchreihenfolge entlang des Kontrollflussgraphen und speichert den Verlauf der ausgewählten Übergänge, bis die Bits gesetzt sind. Ich denke, es ist besser, es mit einem Beispiel zu zeigen.
Angenommen, wir haben Wellen mit einer Breite von 8. So sieht die Ausführungsmaske für das Codefragment aus:
Beispiel 1. Verlauf der Ausführungsmaske
Betrachten Sie nun komplexere Beispiele:
Beispiel 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
Beispiel 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
Möglicherweise stellen Sie fest, dass eine Historie erforderlich ist. Bei Verwendung des Ausführungsmaskenansatzes verwenden Geräte normalerweise eine Art Stapel. Der naive Ansatz besteht darin, einen Stapel von Tupeln (exec_mask, address) zu speichern und Konvergenzbefehle hinzuzufügen, die die Maske aus dem Stapel extrahieren und den Befehlszeiger für die Welle ändern. In diesem Fall verfügt die Welle über genügend Informationen, um das gesamte CFG für jede Zeile zu umgehen.
In Bezug auf die Leistung sind aufgrund all dieser Datenspeicherung nur ein paar Schleifen erforderlich, um einen Kontrollflussbefehl zu verarbeiten. Und vergessen Sie nicht, dass der Stapel eine begrenzte Tiefe hat.
Update. Dank
@craigkolb habe ich einen Artikel [
13 ] gelesen, in dem darauf
hingewiesen wird, dass die AMD GCN-Fork / Join-Anweisungen zuerst einen Pfad aus weniger Threads auswählen [
11 4.6], wodurch garantiert wird, dass die Maskenstapeltiefe gleich log2 ist.
Update. Offensichtlich ist es fast immer möglich, alles in einen Shader / eine Struktur-CFG in einen Shader einzubetten und daher den gesamten Verlauf der Ausführungsmasken in Registern zu speichern und statisch umgehende / konvergierende CFGs zu planen [
15 ]. Nachdem ich mir das LLVM-Backend für AMDGPU angesehen hatte, fand ich keine Hinweise auf eine Stapelverarbeitung, die ständig vom Compiler ausgegeben wurde.
Hardware-Unterstützung für Laufzeitmasken
Schauen Sie sich nun diese Kontrollflussdiagramme von Wikipedia an:
Abbildung 4. Einige Arten von KontrollflussdiagrammenWas ist der Mindestsatz an Anweisungen zur Maskensteuerung, die wir benötigen, um alle Fälle zu behandeln? So sieht es in meiner künstlichen ISA mit impliziter Parallelisierung, expliziter Maskensteuerung und vollständig dynamischer Synchronisation von Datenkonflikten aus:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
Schauen wir uns Fall d) an.
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
Ich bin kein Spezialist für die Analyse von Kontrollflüssen oder das Entwerfen von ISA, daher bin ich mir sicher, dass es einen Fall gibt, den meine künstliche ISA nicht verarbeiten kann, aber dies ist nicht wichtig, da eine strukturierte CFG für alle ausreichen sollte.
Update. Weitere Informationen zur GCN-Unterstützung für Anweisungen zum Kontrollfluss finden Sie hier: [
11 ] Kapitel 4 und zur LLVM-Implementierung hier: [
15 ].
Fazit:
- Divergenz - der resultierende Unterschied in den Pfaden, die von verschiedenen Linien derselben Welle gewählt werden
- Konsistenz - keine Diskrepanz.
Beispiele für die Verarbeitung von Ausführungsmasken
Fiktive ISA
Ich habe die vorherigen Codefragmente in meinem künstlichen ISA kompiliert und sie auf einem Simulator in SIMD32 ausgeführt. Sehen Sie, wie es mit der Ausführungsmaske umgeht.
Update. Beachten Sie, dass ein künstlicher Simulator immer den wahren Pfad wählt, und dies ist nicht der beste Weg.
Beispiel 1
 Abbildung 5. Die Geschichte von Beispiel 1
Abbildung 5. Die Geschichte von Beispiel 1Haben Sie einen schwarzen Bereich bemerkt? Diesmal verschwendet. Einige Zeilen warten darauf, dass andere die Iteration abschließen.
Beispiel 2
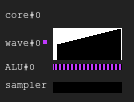 Abbildung 6. Verlauf von Beispiel 2
Abbildung 6. Verlauf von Beispiel 2Beispiel 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 Abbildung 7. Verlauf von Beispiel 3
Abbildung 7. Verlauf von Beispiel 3AMD GCN ISA
Update. GCN verwendet auch die explizite Maskenverarbeitung. Weitere Informationen hierzu finden Sie hier: [
11 4.x]. Ich habe mich entschlossen, einige Beispiele aus ihrer ISA zu zeigen, dank
Shader-Spielplatz ist dies einfach zu tun. Vielleicht finde ich eines Tages einen Simulator und schaffe es, Diagramme zu bekommen.
Denken Sie daran, dass der Compiler intelligent ist, damit Sie andere Ergebnisse erzielen können. Ich habe versucht, den Compiler so auszutricksen, dass er meine Zweige nicht optimiert, indem ich dort Zeigerschleifen platziere und dann den Assembler-Code bereinige. Ich bin kein GCN-Spezialist, daher werden möglicherweise einige wichtige
nop übersprungen.
Beachten Sie auch, dass die Anweisungen S_CBRANCH_I / G_FORK und S_CBRANCH_JOIN in diesen Fragmenten nicht verwendet werden, da sie einfach sind und vom Compiler nicht unterstützt werden. Daher war es leider nicht möglich, den Maskenstapel zu berücksichtigen. Wenn Sie wissen, wie der Compiler die Stapelverarbeitung ausgibt, sagen Sie es mir bitte.
Update. Schauen Sie sich diesen
@ SiNGUL4RiTY-Vortrag über die Implementierung eines vektorisierten Kontrollflusses im von AMD verwendeten LLVM-Backend an.
Beispiel 1
Beispiel 2
Beispiel 3
AVX512
Update. @tom_forsyth hat mich darauf hingewiesen, dass die AVX512-Erweiterung auch über eine explizite Maskenverarbeitung verfügt. Hier einige Beispiele. Weitere Details hierzu finden Sie in [
14 ], 15.x und 15.6.1. Es ist nicht gerade eine GPU, aber es hat immer noch eine echte SIMD16 mit 32 Bit. Code-Snippets wurden mit ISPC (–target = avx512knl-i32x16)
godbolt erstellt und sind stark überarbeitet, sodass sie möglicherweise nicht 100% wahr sind.
Beispiel 1
Beispiel 2
Beispiel 3
Wie gehe ich mit der Diskrepanz um?
Ich habe versucht, ein einfaches, aber vollständiges Beispiel dafür zu erstellen, wie Ineffizienz durch das Kombinieren divergierender Linien entsteht.
Stellen Sie sich einen einfachen Code vor:
uint thread_id = get_thread_id()
Erstellen wir 256 Threads und messen ihre Ausführungszeit:
Abbildung 8. Dauer divergierender FädenDie x-Achse ist die Kennung des Programmstroms, die y-Achse sind die Taktzyklen; Verschiedene Spalten zeigen, wie viel Zeit beim Gruppieren von Flüssen mit unterschiedlichen Wellenlängen im Vergleich zur Ausführung mit einem Thread verschwendet wird.
Die Wellenlaufzeit entspricht der maximalen Laufzeit unter den darin enthaltenen Zeilen. Sie können sehen, dass die Leistung bereits mit SIMD8 dramatisch abnimmt, und eine weitere Erweiterung macht es nur ein wenig schlechter.
Abbildung 9. Laufzeit konsistenter ThreadsIn dieser Abbildung sind dieselben Spalten dargestellt, diesmal wird die Anzahl der Iterationen jedoch nach Stream-IDs sortiert, dh Streams mit einer ähnlichen Anzahl von Iterationen werden an eine Welle übertragen.
In diesem Beispiel wird die Ausführung möglicherweise um etwa die Hälfte beschleunigt.
Natürlich ist das Beispiel zu einfach, aber ich hoffe, Sie verstehen den Punkt: Die Diskrepanz bei der Ausführung ergibt sich aus der Diskrepanz der Daten, daher müssen CFGs einfach und die Daten konsistent sein.
Wenn Sie beispielsweise einen Raytracer schreiben, können Sie davon profitieren, die Strahlen mit derselben Richtung und Position zu gruppieren, da sie höchstwahrscheinlich dieselben Knoten in der BVH durchlaufen. Weitere Informationen finden Sie in [
10 ] und anderen verwandten Artikeln.
Erwähnenswert ist auch, dass es Techniken zum Umgang mit Diskrepanzen auf Hardwareebene gibt, z. B. Dynamic Warp Formation [
7 ] und vorausgesagte Ausführung für kleine Zweige.
Referenzen
[1]
Eine Reise durch die Grafik-Pipeline[2]
Kayvon Fatahalian: PARALLEL COMPUTING[3]
Computerarchitektur Ein quantitativer Ansatz[4]
Stapellose SIMT-Rekonvergenz zu geringen Kosten[5]
Analyse der GPU-Speicherhierarchie durch Mikrobenchmarking[6]
Analyse der NVIDIA Volta GPU-Architektur über Microbenchmarking[7]
Dynamische Warp-Bildung und -Planung für einen effizienten GPU-Kontrollfluss[8]
Maurizio Cerrato: GPU-Architekturen[9]
Spielzeug-GPU-Simulator[10]
Verringerung der Verzweigungsdivergenz in GPU-Programmen[11]
"Vega" -Anweisungssatzarchitektur[12]
Joshua Barczak: Simulation der Shader-Ausführung für GCN[13]
Tangentenvektor: Ein Exkurs zur Divergenz[14]
Intel 64- und IA-32-ArchitekturenSoftware-Entwicklerhandbuch[15]
Vektorisierung des divergenten Kontrollflusses für SIMD-Anwendungen