Gruß, Chabrowiten! Die Übersetzung des folgenden Artikels wurde speziell für Studenten des
Kubernetes-basierten Infrastructure Platform- Kurses erstellt, der morgen mit dem Unterricht beginnen wird. Fangen wir an.

Autoskalierung in Kubernetes
Mit der automatischen Skalierung können Sie die Arbeitslast je nach Ressourcennutzung automatisch erhöhen und verringern.
Die automatische Skalierung von Kubernetes hat zwei Dimensionen:
- Cluster Autoscaler, der für die Skalierung der Knoten verantwortlich ist;
- Horizontal Pod Autoscaler (HPA), der automatisch die Anzahl der Herde in einem Bereitstellungs- oder Replikatsatz skaliert.
Die automatische Skalierung von Clustern kann in Verbindung mit der automatischen Skalierung von horizontalen Herden verwendet werden, um die Rechenressourcen und den Grad der Systemgleichzeitigkeit, die zur Einhaltung von Service Level Agreements (SLAs) erforderlich sind, dynamisch zu steuern.
Die automatische Skalierung von Clustern hängt stark von den Funktionen des Cloud-Infrastrukturanbieters ab, der den Cluster hostet, und HPA kann unabhängig vom IaaS / PaaS-Anbieter betrieben werden.
HPA-Entwicklung
Die automatische Skalierung des horizontalen Herdes hat seit der Einführung von Kubernetes v1.1 wesentliche Änderungen erfahren. Die erste Version von HPA skalierte Herde basierend auf dem gemessenen CPU-Verbrauch und später basierend auf der Speichernutzung. Kubernetes 1.6 führte eine neue API namens Custom Metrics ein, die HPA-Zugriff auf benutzerdefinierte Metriken ermöglichte. Kubernetes 1.7 hat eine Aggregationsebene hinzugefügt, mit der Anwendungen von Drittanbietern die Kubernetes-API durch Registrierung als API-Add-Ons erweitern können.
Dank der API für benutzerdefinierte Metriken und der Aggregationsebene können Überwachungssysteme wie Prometheus dem HPA-Controller anwendungsspezifische Metriken bereitstellen.
Die automatische Skalierung des horizontalen Herdes wird als Regelkreis implementiert, der regelmäßig die Ressourcenmetrik-API (Ressourcenmetrik-API) nach Schlüsselmetriken wie CPU- und Speichernutzung und die Benutzerdefinierte Metrik-API (Benutzerdefinierte Metrik-API) nach bestimmten Anwendungsmetriken abfragt.
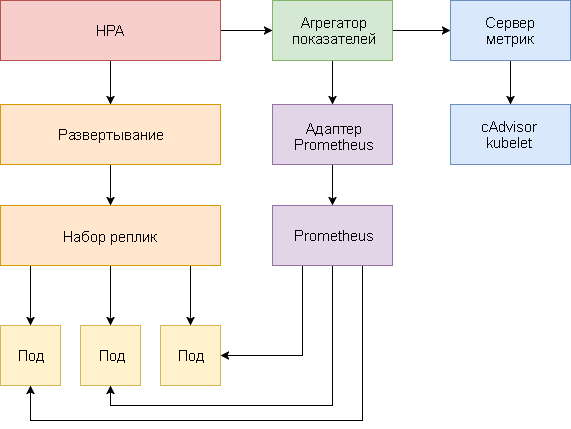
Im Folgenden finden Sie eine schrittweise Anleitung zum Konfigurieren von HPA v2 für Kubernetes 1.9 und höher.
- Installieren Sie das Metrics Server-Add-In, das wichtige Metriken bereitstellt.
- Starten Sie eine Demo-Anwendung, um zu sehen, wie die automatische Skalierung des Herdes basierend auf der CPU- und Speicherauslastung funktioniert.
- Stellen Sie den Prometheus- und den benutzerdefinierten API-Server bereit. Registrieren Sie einen benutzerdefinierten API-Server auf Aggregationsebene.
- Konfigurieren Sie HPA mithilfe von benutzerdefinierten Metriken, die von der Demoanwendung bereitgestellt werden.
Bevor Sie beginnen, müssen Sie Go Version 1.8 (oder höher) installieren und das
k8s-prom-hpa-Repository in
GOPATH :
cd $GOPATH git clone https:
1. Einrichten des Metrikservers
Der Kubernetes
Metric Server ist der Cluster-Aggregator für Ressourcenauslastungsdaten
innerhalb des Clusters, der
Heapster ersetzt. Der
kubernetes.summary_api sammelt Informationen zur CPU- und Speichernutzung für Knoten und Herde von
kubernetes.summary_api . Die Zusammenfassungs-API ist eine speichereffiziente API zum Übertragen von Kubelet / cAdvisor-Datenmetriken an einen Server.
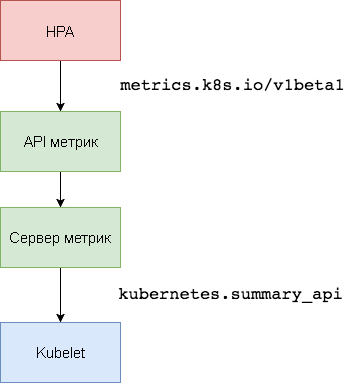
In der ersten Version von HPA wurde ein Heapster-Aggregator benötigt, um die CPU und den Speicher abzurufen. In HPA v2 und Kubernetes 1.8 ist nur ein
horizontal-pod-autoscaler-use-rest-clients aktivierten
horizontal-pod-autoscaler-use-rest-clients erforderlich. Diese Option ist in Kubernetes 1.9 standardmäßig aktiviert. GKE 1.9 wird mit einem vorinstallierten Metrikserver geliefert.
Erweitern Sie den
kube-system Namespace des
kube-system :
kubectl create -f ./metrics-server
Nach 1 Minute beginnt der
metric-server mit der Übertragung von Daten über die Nutzung der CPU und des Speichers durch Knoten und Pods.
Knotenmetriken anzeigen:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
Herzfrequenzindikatoren anzeigen:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. Automatische Skalierung basierend auf CPU- und Speicherauslastung
Zum Testen der horizontalen automatischen Skalierung (HPA) von Herden können Sie eine kleine Golang-basierte Webanwendung verwenden.
Erweitern Sie
podinfo im
default Namespace:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo über den NodePort-Dienst unter
http://<K8S_PUBLIC_IP>:31198 .
Geben Sie einen HPA an, der mindestens zwei Replikate bereitstellt, und skalieren Sie ihn auf zehn Replikate, wenn die durchschnittliche CPU-Auslastung 80% überschreitet oder der Speicherverbrauch über 200 MiB liegt:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
HPA erstellen:
kubectl create -f ./podinfo/podinfo-hpa.yaml
Nach einigen Sekunden kontaktiert der HPA-Controller den Metrikserver und erhält Informationen zur CPU- und Speichernutzung:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
Führen Sie einen Auslastungstest mit rakyll / hey durch, um die CPU-Auslastung zu erhöhen:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
Sie können HPA-Ereignisse wie folgt überwachen:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Entfernen Sie podinfo vorübergehend (Sie müssen es in einem der nächsten Schritte dieses Handbuchs erneut bereitstellen).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. Benutzerdefiniertes Metrics Server-Setup
Für die Skalierung basierend auf benutzerdefinierten Metriken werden zwei Komponenten benötigt. Die erste - die
Prometheus- Zeitreihendatenbank - sammelt Anwendungsmetriken und speichert sie. Die zweite Komponente, der
k8s-prometheus-Adapter , ergänzt die benutzerdefinierten Metriken-API-Kubernetes mit vom Builder bereitgestellten Metriken.
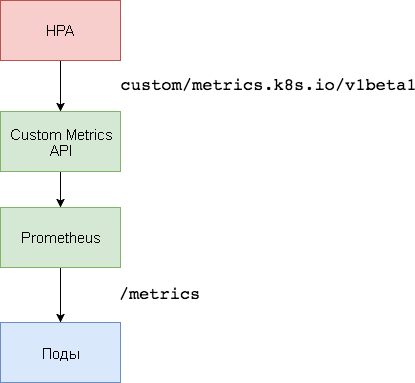
Ein dedizierter Namespace wird verwendet, um Prometheus und den Adapter bereitzustellen.
Erstellen Sie einen
monitoring Namespace:
kubectl create -f ./namespaces.yaml
Erweitern Sie Prometheus v2 im
monitoring Namespace:
kubectl create -f ./prometheus
Generieren Sie die für den Prometheus-Adapter erforderlichen TLS-Zertifikate:
make certs
Stellen Sie den Prometheus-Adapter für die API für benutzerdefinierte Metriken bereit:
kubectl create -f ./custom-metrics-api
Holen Sie sich eine Liste der von Prometheus bereitgestellten speziellen Metriken:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
Extrahieren Sie dann die Dateisystem-Nutzungsdaten für alle Pods im
monitoring Namespace:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. Automatische Skalierung basierend auf benutzerdefinierten Metriken
Erstellen Sie den NodePort-
podinfo Dienst und stellen Sie ihn im
default Namespace
podinfo :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Die
podinfo Anwendung
podinfo die spezielle Metrik
http_requests_total . Der Prometheus-Adapter entfernt das Suffix
_total und markiert diese Metrik als Zähler.
Rufen Sie die Gesamtzahl der Abfragen pro Sekunde über die API für benutzerdefinierte Metriken ab:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
Der Buchstabe
m bedeutet
901m , so dass beispielsweise 901
901m 901 Millisekunden sind.
Erstellen Sie eine HPA, die die Podinfo-Bereitstellung erweitert, wenn die Anzahl der Anforderungen 10 Anforderungen pro Sekunde überschreitet:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
Erweitern Sie HPA
podinfo im
default Namespace:
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
Nach einigen Sekunden erhält der HPA den Wert
http_requests von der Metrik-API:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
Wenden Sie die Last für den Podinfo-Dienst mit 25 Anforderungen pro Sekunde an:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
Nach einigen Minuten beginnt der HPA mit der Skalierung der Bereitstellung:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Bei der aktuellen Anzahl von Anforderungen pro Sekunde erreicht die Bereitstellung niemals maximal 10 Pods. Drei Replikate reichen aus, um sicherzustellen, dass die Anzahl der Anforderungen pro Sekunde für jeden Pod weniger als 10 beträgt.
Nach Abschluss der Auslastungstests reduziert HPA die Bereitstellungsskala auf die anfängliche Anzahl von Replikaten:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Möglicherweise haben Sie bemerkt, dass der automatische Skalierer nicht sofort auf Änderungen der Metriken reagiert. Standardmäßig werden sie alle 30 Sekunden synchronisiert. Darüber hinaus erfolgt die Skalierung nur, wenn die Arbeitslast in den letzten 3 bis 5 Minuten nicht erhöht oder verringert wurde. Dies hilft, widersprüchliche Entscheidungen zu vermeiden, und lässt Zeit, um den Auto-Scaler des Clusters zu verbinden.
Fazit
Nicht alle Systeme können die SLA-Konformität nur auf der Grundlage der CPU- oder Speicherauslastung (oder beider) erzwingen. Die meisten Webserver und mobilen Server zur Verarbeitung von Verkehrsspitzen benötigen eine automatische Skalierung basierend auf der Anzahl der Anforderungen pro Sekunde.
Für ETL-Anwendungen (aus dem Eng. Extract Transform Load - „Extrahieren, Transformieren, Laden“) kann die automatische Skalierung beispielsweise ausgelöst werden, wenn die angegebene Schwellenlänge der Jobwarteschlange überschritten wird.
In allen Fällen können Sie durch Instrumentieren von Anwendungen mit Prometheus und Hervorheben der erforderlichen Indikatoren für die automatische Skalierung die Anwendungen optimieren, um die Verarbeitung von Verkehrsspitzen zu verbessern und eine hohe Verfügbarkeit der Infrastruktur sicherzustellen.
Ideen, Fragen, Kommentare? Nehmen Sie an der Diskussion bei
Slack teil !
Hier ist so ein Material. Wir warten auf Ihre Kommentare und sehen uns auf dem
Kurs !