Trotz der Tatsache, dass die meisten IT-Unternehmen Infrastrukturlösungen basierend auf Containern und Cloud-Lösungen implementieren, ist es notwendig, die Einschränkungen dieser Technologien zu verstehen. Traditionell sind Docker, Linux Container (LXC) und Rocket (rkt) nicht wirklich isoliert, da sie in ihrer Arbeit den Kern des übergeordneten Betriebssystems gemeinsam nutzen. Ja, sie sind ressourcenschonend, aber die Gesamtzahl der geschätzten Angriffsmethoden und potenziellen Verluste durch Hacking ist immer noch groß, insbesondere im Fall einer Cloud-Umgebung mit mehreren Mandanten, in der sich Container befinden.

Die Wurzel unseres Problems liegt in der schwachen Abgrenzung von Containern in dem Moment, in dem das Host-Betriebssystem für jeden einen virtuellen Benutzerbereich erstellt. Ja, Forschung und Entwicklung wurden durchgeführt, um echte „Container“ mit einem vollwertigen Sandkasten zu schaffen. Die meisten der daraus resultierenden Lösungen führen zu einer Umstrukturierung der Grenzen zwischen Containern, um deren Isolation zu verbessern. In diesem Artikel werden vier einzigartige Projekte von IBM, Google, Amazon und OpenStack vorgestellt, die unterschiedliche Methoden verwenden, um dasselbe Ziel zu erreichen: die Schaffung einer zuverlässigen Isolation. IBM Nabla stellt Container auf Unikernel bereit, Google gVisor erstellt einen speziellen Gastkernel, Amazon Firecracker verwendet einen extrem leichten Hypervisor für Sandbox-Anwendungen und OpenStack platziert Container in einer speziellen virtuellen Maschine, die für Orchestrierungstools optimiert ist.
Überblick über die moderne Containertechnologie
Container sind eine moderne Methode zum Packen, Freigeben und Bereitstellen einer Anwendung. Im Gegensatz zu einer monolithischen Anwendung, bei der alle Funktionen in einem Programm zusammengefasst sind, sind Containeranwendungen oder Mikrodienste für eine gezielte enge Verwendung vorgesehen und auf nur eine Aufgabe spezialisiert.
Ein Container enthält alle Abhängigkeiten (z. B. Pakete, Bibliotheken und Binärdateien), die eine Anwendung benötigt, um ihre spezifische Aufgabe auszuführen. Containerisierte Anwendungen sind daher plattformunabhängig und können auf jedem Betriebssystem ausgeführt werden, unabhängig von der Version oder den installierten Paketen. Diese Bequemlichkeit erspart Entwicklern einen enormen Arbeitsaufwand bei der Anpassung verschiedener Softwareversionen für verschiedene Plattformen oder Clients. Obwohl konzeptionell nicht ganz genau, denken viele Menschen gerne an Container als „leichte virtuelle Maschinen“.
Wenn ein Container auf einem Host bereitgestellt wird, werden die Ressourcen jedes Containers, z. B. das Dateisystem, der Prozess und der Netzwerkstapel, in eine praktisch isolierte Umgebung gestellt, auf die andere Container nicht zugreifen können. Diese Architektur ermöglicht die gleichzeitige Ausführung von Hunderten und Tausenden von Containern in einem einzelnen Cluster, und jede Anwendung (oder jeder Microservice) kann dann einfach skaliert werden, indem eine große Anzahl von Instanzen repliziert wird.
In diesem Fall basiert das Containerlayout auf zwei wichtigen „Bausteinen“: dem Linux-Namespace und den Linux-Kontrollgruppen (cgroups).
Der Namespace erstellt einen praktisch isolierten Benutzerbereich und stellt der Anwendung dedizierte Systemressourcen wie Dateisystem, Netzwerkstapel, Prozess-ID und Benutzer-ID zur Verfügung. In diesem isolierten Benutzerbereich steuert die Anwendung das Stammverzeichnis des Dateisystems und kann als Stamm ausgeführt werden. Dieser abstrakte Bereich ermöglicht es jeder Anwendung, unabhängig zu arbeiten, ohne andere Anwendungen auf demselben Host zu beeinträchtigen. Derzeit sind sechs Namespaces verfügbar: Mount, Interprozesskommunikation (IPC), UNIX-Time-Sharing-System (uts), Prozess-ID (pid), Netzwerk und Benutzer. Es wird vorgeschlagen, diese Liste durch zwei zusätzliche Namespaces zu ergänzen: time und syslog, aber die Linux-Community hat sich noch nicht für die endgültigen Spezifikationen entschieden.
Cgroups bieten Begrenzung, Priorisierung, Anwendungsüberwachung und -steuerung für Hardwareressourcen. Ein Beispiel für die Hardwareressourcen, die sie steuern können, sind der Prozessor, der Speicher, das Gerät und das Netzwerk. Wenn Sie den Namespace und die cgroups kombinieren, können Sie sicher mehrere Anwendungen auf demselben Host ausführen, wobei sich jede Anwendung in einer eigenen isolierten Umgebung befindet. Dies ist die grundlegende Eigenschaft des Containers.
Der Hauptunterschied zwischen einer virtuellen Maschine (VM) und einem Container besteht darin, dass die virtuelle Maschine eine Virtualisierung auf Hardwareebene und der Container eine Virtualisierung auf Betriebssystemebene ist. Der VM-Hypervisor emuliert die Hardwareumgebung für jeden Computer, wobei die Container-Laufzeit bereits das Betriebssystem für jedes Objekt emuliert. Virtuelle Maschinen teilen sich die physische Hardware des Hosts, und Container teilen sich sowohl die Hardware als auch den Betriebssystemkern. Da Container im Allgemeinen mehr Ressourcen mit dem Host teilen, ist ihre Arbeit mit Speicher-, Speicher- und CPU-Zyklen viel effizienter als mit einer virtuellen Maschine. Der Nachteil dieses gemeinsamen Zugriffs sind jedoch die Probleme auf der Ebene der Informationssicherheit, da zwischen den Containern und dem Host zu viel Vertrauen hergestellt wird. Abbildung 1 zeigt den architektonischen Unterschied zwischen einem Container und einer virtuellen Maschine.
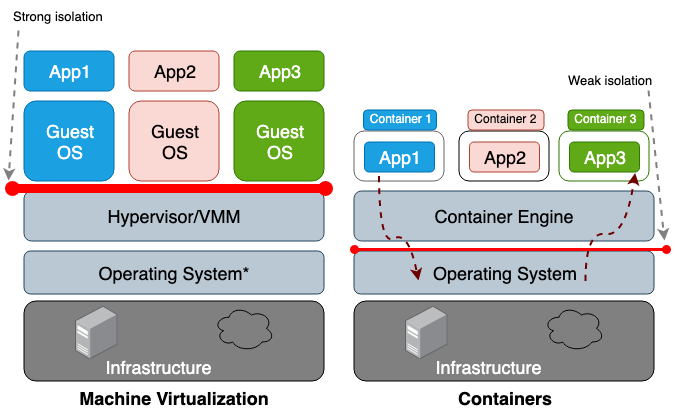
Im Allgemeinen führt die Isolierung virtualisierter Geräte zu einem viel stärkeren Sicherheitsbereich als nur die Isolierung eines Namespace. Das Risiko, dass ein Angreifer einen isolierten Prozess erfolgreich verlässt, ist viel höher als die Wahrscheinlichkeit, die virtuelle Maschine erfolgreich zu verlassen. Der Grund für das höhere Risiko, über die begrenzte Containerumgebung hinauszugehen, ist die schlechte Isolation, die durch den Namespace und die cgroups verursacht wird. Linux implementiert sie, indem jedem Prozess neue Eigenschaftsfelder zugeordnet werden. Diese Felder im Dateisystem
/proc geben dem Host-Betriebssystem an, ob ein Prozess einen anderen sehen kann oder wie viel Prozessor- / Speicherressourcen ein bestimmter Prozess verwenden kann. Wenn Sie laufende Prozesse und Threads vom übergeordneten Betriebssystem aus anzeigen (z. B. den Befehl top oder ps), sieht der Containerprozess wie jeder andere aus. In der Regel werden herkömmliche Lösungen wie LXC oder Docker nicht als vollständig isoliert betrachtet, da sie denselben Kern auf demselben Host verwenden. Daher ist es nicht verwunderlich, dass Container eine ausreichende Anzahl von Sicherheitslücken aufweisen. Beispielsweise können CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 und CVE-2019-5736 dazu führen, dass ein Angreifer Zugriff auf Daten außerhalb des Containers erhält.
Die meisten Kernel-Exploits erstellen einen Vektor für einen erfolgreichen Angriff, da sie normalerweise zu einer Eskalation von Berechtigungen führen und es einem kompromittierten Prozess ermöglichen, die Kontrolle außerhalb des beabsichtigten Namespace zu erlangen. Neben Angriffsvektoren im Zusammenhang mit Software-Schwachstellen kann auch eine falsche Konfiguration eine Rolle spielen. Beispielsweise kann das Bereitstellen von Images mit übermäßigen Berechtigungen (CAP_SYS_ADMIN, privilegierter Zugriff) oder kritischen
/var/run/docker.sock (
/var/run/docker.sock ) zu einem Leck führen. Angesichts dieser potenziell katastrophalen Folgen sollten Sie das Risiko verstehen, das Sie eingehen, wenn Sie das System in einem mandantenfähigen Bereich bereitstellen oder Container zum Speichern vertraulicher Daten verwenden.
Diese Probleme motivieren Forscher, stärkere Sicherheitsbereiche zu schaffen. Die Idee ist, einen echten Sandbox-Container zu erstellen, der so weit wie möglich vom Hauptbetriebssystem isoliert ist. Die meisten dieser Lösungen umfassen die Entwicklung einer Hybridarchitektur, die eine strikte Unterscheidung zwischen der Anwendung und der virtuellen Maschine verwendet und sich auf die Verbesserung der Effizienz von Containerlösungen konzentriert.
Zum Zeitpunkt des Schreibens gab es kein einziges Projekt, das als ausgereift genug bezeichnet werden konnte, um als Standard akzeptiert zu werden, aber in Zukunft werden Entwickler zweifellos einige dieser Konzepte als die wichtigsten akzeptieren.
Wir beginnen unsere Überprüfung mit Unikernel, dem ältesten hochspezialisierten System, das eine Anwendung mit einem minimalen Satz von Betriebssystembibliotheken in ein Image packt. Das Konzept von Unikernel selbst erwies sich als grundlegend für viele Projekte, deren Ziel es war, sichere, kompakte und optimierte Bilder zu erstellen. Danach werden wir uns mit IBM Nabla befassen, einem Projekt zum Starten von Unikernel-Anwendungen, einschließlich Containern. Darüber hinaus haben wir Google gVisor, ein Projekt zum Starten von Containern im User-Kernel-Bereich. Als nächstes werden wir zu Containerlösungen wechseln, die auf virtuellen Maschinen basieren - Amazon Firecracker und OpenStack Kata. Um diesen Beitrag zusammenzufassen, vergleichen Sie alle oben genannten Lösungen.
Unikernel
Die Entwicklung von Virtualisierungstechnologien hat es uns ermöglicht, auf Cloud Computing umzusteigen. Hypervisoren wie Xen und KVM haben den Grundstein für das gelegt, was wir heute als Amazon Web Services (AWS) und Google Cloud Platform (GCP) kennen. Und obwohl moderne Hypervisoren mit Hunderten von virtuellen Maschinen in einem einzigen Cluster arbeiten können, sind herkömmliche Allzweckbetriebssysteme nicht zu angepasst und optimiert, um in einer solchen Umgebung zu arbeiten. Das Allzweck-Betriebssystem soll in erster Linie so viele verschiedene Anwendungen wie möglich unterstützen und damit arbeiten. Daher umfassen ihre Kernel alle Arten von Treibern, Bibliotheken, Protokollen, Schedulern usw. Die meisten virtuellen Maschinen, die jetzt irgendwo in der Cloud bereitgestellt werden, werden jedoch zum Ausführen einer einzelnen Anwendung verwendet, z. B. zum Bereitstellen von DNS, eines Proxys oder einer Datenbank. Da eine solche einzelne Anwendung in ihrer Arbeit nur auf einen bestimmten und kleinen Teil des Betriebssystemkerns angewiesen ist, verschwenden alle anderen „Röcke“ einfach Systemressourcen und erhöhen aufgrund ihrer Existenz die Anzahl der Vektoren für einen potenziellen Angriff. Je größer die Codebasis ist, desto schwieriger ist es, alle Mängel zu beseitigen, und desto mehr potenzielle Schwachstellen, Fehler und andere Schwachstellen sind vorhanden. Dieses Problem ermutigt Spezialisten, hochspezialisierte Betriebssysteme mit einem Mindestmaß an Kernelfunktionalität zu entwickeln, dh Tools zur Unterstützung einer bestimmten Anwendung zu erstellen.
Zum ersten Mal wurde die Unikernel-Idee in den 90er Jahren geboren. Dann nahm er Gestalt an als spezielles Bild einer Maschine mit einem einzigen Adressraum, der direkt auf Hypervisoren arbeiten kann. Es packt die Kern- und Kernel-abhängigen Anwendungen und Funktionen in ein einziges Image. Nemesis und Exokernel sind die beiden frühesten Forschungsversionen des Unikernel-Projekts. Der Verpackungs- und Bereitstellungsprozess ist in Abbildung 2 dargestellt.
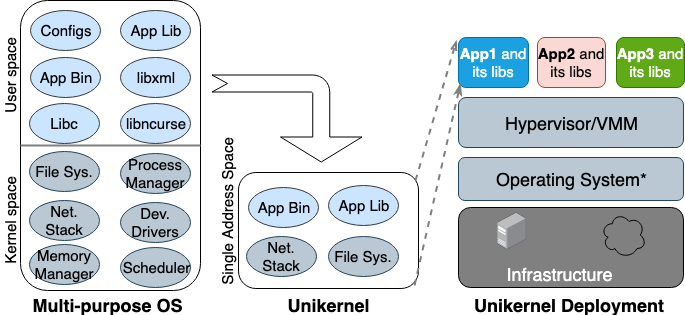 Abbildung 2. Mehrzweckbetriebssysteme, die alle Arten von Anwendungen unterstützen, sodass viele Bibliotheken und Treiber im Voraus geladen werden. Unikernels sind hochspezialisierte Betriebssysteme, die eine bestimmte Anwendung unterstützen.
Abbildung 2. Mehrzweckbetriebssysteme, die alle Arten von Anwendungen unterstützen, sodass viele Bibliotheken und Treiber im Voraus geladen werden. Unikernels sind hochspezialisierte Betriebssysteme, die eine bestimmte Anwendung unterstützen.
Unikernel unterteilt den Kernel in mehrere Bibliotheken und fügt nur die erforderlichen Komponenten in das Image ein. Wie normale virtuelle Maschinen wird Unikernel auf dem VM-Hypervisor bereitgestellt und ausgeführt. Aufgrund seiner geringen Größe kann es schnell geladen und auch schnell skaliert werden. Die wichtigsten Funktionen von Unikernel sind erhöhte Sicherheit, geringer Platzbedarf, ein hohes Maß an Optimierung und schnelles Laden. Da diese Images nur anwendungsabhängige Bibliotheken enthalten und auf die Betriebssystem-Shell nicht zugegriffen werden kann, wenn sie nicht absichtlich verbunden wurde, ist die Anzahl der Angriffsvektoren, die Angreifer auf ihnen verwenden können, minimal.
Das heißt, es ist nicht nur für Angreifer schwierig, in diesen einzigartigen Kernen Fuß zu fassen, sondern ihr Einfluss ist auch auf eine Kerninstanz beschränkt. Da die Größe von Unikernel-Images nur wenige Megabyte beträgt, werden sie in zehn Millisekunden heruntergeladen, und buchstäblich Hunderte von Instanzen können auf einem einzelnen Host ausgeführt werden. Bei Verwendung der Speicherzuweisung im selben Adressraum anstelle einer mehrstufigen Seitentabelle, wie dies bei den meisten modernen Betriebssystemen der Fall ist, haben Unikernel-Anwendungen eine geringere Speicherzugriffsverzögerung als dieselbe Anwendung, die auf einer regulären virtuellen Maschine ausgeführt wird. Da Anwendungen beim Erstellen des Images mit dem Kernel zusammenkommen, können Compiler einfach eine statische Typprüfung durchführen, um Binärdateien zu optimieren.
Unikernel.org führt eine Liste von Unikernel-Projekten. Mit all seinen Besonderheiten und Eigenschaften ist Unikernel jedoch nicht weit verbreitet. Als Docker 2016 Unikernel Systems übernahm, entschied die Community, dass das Unternehmen nun Container darin verpacken würde. Aber drei Jahre sind vergangen, und es gibt immer noch keine Anzeichen für eine Integration. Einer der Hauptgründe für diese langsame Implementierung ist, dass es noch kein ausgereiftes Tool zum Erstellen von Unikernel-Anwendungen gibt und die meisten dieser Anwendungen nur auf bestimmten Hypervisoren funktionieren können. Darüber hinaus erfordert das Portieren einer Anwendung auf Unikernel möglicherweise das manuelle Umschreiben von Code in anderen Sprachen, einschließlich des Umschreibens abhängiger Kernelbibliotheken. Es ist auch wichtig, dass das Überwachen oder Debuggen in Unikernels entweder unmöglich ist oder einen erheblichen Einfluss auf die Leistung hat.
All diese Einschränkungen hindern Entwickler daran, auf diese Technologie umzusteigen. Es ist zu beachten, dass Unikernel und Container viele ähnliche Eigenschaften haben. Sowohl das erste als auch das zweite Bild sind stark fokussierte unveränderliche Images. Dies bedeutet, dass die darin enthaltenen Komponenten nicht aktualisiert oder repariert werden können. Das heißt, Sie müssen immer ein neues Image für den Anwendungspatch erstellen. Heute ähnelt Unikernel dem Vorfahren von Docker: Damals war die Container-Laufzeit nicht verfügbar, und Entwickler mussten die grundlegenden Tools zum Erstellen einer isolierten Anwendungsumgebung (chroot, unshare und cgroups) verwenden.
Ibm nabla
Einmal schlugen Forscher von IBM das Konzept von „Unikernel als Prozess“ vor, dh die Unikernel-Anwendung, die als Prozess auf einem speziellen Hypervisor ausgeführt werden würde. Das IBM-Projekt „Nabla-Container“ stärkte den Sicherheitsbereich von Unikernel und ersetzte den universellen Hypervisor (z. B. QEMU) durch eine eigene Entwicklung namens Nabla Tender. Der Grund für diesen Ansatz ist, dass Aufrufe zwischen Unikernel und dem Hypervisor immer noch die meisten Angriffsvektoren liefern. Aus diesem Grund kann die Verwendung eines Hypervisors für Unikernel mit weniger zulässigen Systemaufrufen den Sicherheitsbereich erheblich verbessern. Nabla Tender fängt Aufrufe ab, die Unikernel an den Hypervisor weiterleitet, und übersetzt sie bereits in Systemanforderungen. Gleichzeitig blockiert die seccomp Linux-Richtlinie alle anderen Systemaufrufe, die nicht erforderlich sind, damit Tender funktioniert. Daher wird Unikernel in Verbindung mit Nabla Tender als Prozess im Benutzerbereich des Hosts ausgeführt. In Abbildung 3 wird gezeigt, wie Nabla eine dünne Schnittstelle zwischen Unikernel und dem Host erstellt.
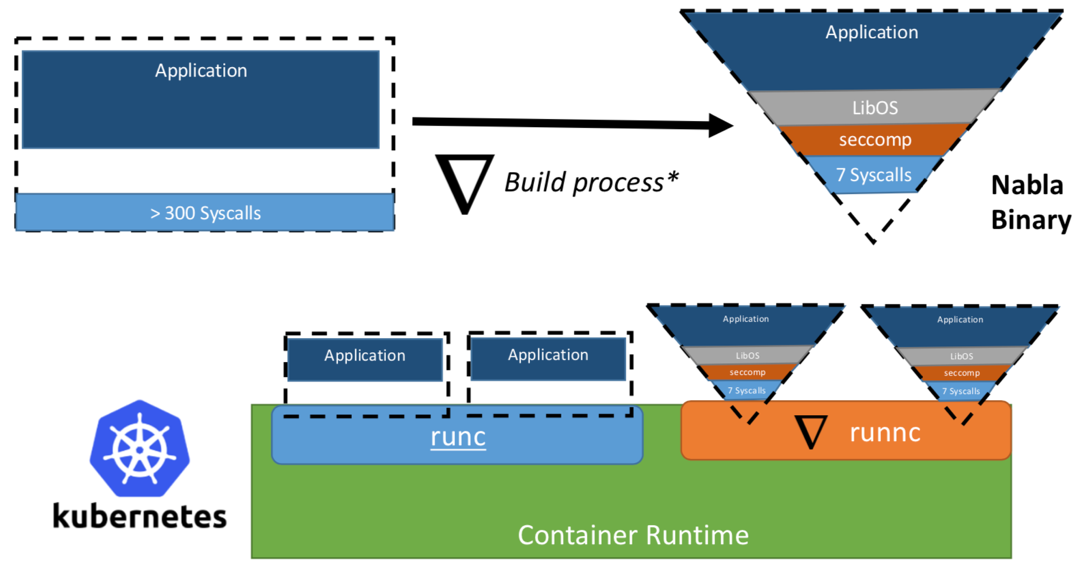 Abbildung 3. Um Nabla mit vorhandenen Container-Laufzeitplattformen zu verknüpfen, verwendet Nabla eine OCI-kompatible Umgebung, die wiederum mit Docker oder Kubernetes verbunden werden kann.
Abbildung 3. Um Nabla mit vorhandenen Container-Laufzeitplattformen zu verknüpfen, verwendet Nabla eine OCI-kompatible Umgebung, die wiederum mit Docker oder Kubernetes verbunden werden kann.Die Entwickler behaupten, dass Nabla Tender in seiner Arbeit weniger als sieben Systemaufrufe verwendet, um mit dem Host zu interagieren. Da Systemaufrufe als eine Art Brücke zwischen Prozessen im Benutzerbereich und dem Kernel des Betriebssystems dienen, ist die Anzahl der verfügbaren Vektoren für den Angriff auf den Kernel umso geringer, je weniger Systemaufrufe für uns verfügbar sind. Ein weiterer Vorteil der Ausführung von Unikernel als Prozess besteht darin, dass Sie solche Anwendungen mit einer großen Anzahl von Tools debuggen können, z. B. mit gdb.
Für die Arbeit mit Container-Orchestrierungsplattformen bietet Nabla eine dedizierte
runnc , die unter Verwendung des OCI-Standards (Open Container Initiative) implementiert wird. Letzteres definiert eine API zwischen Clients (z. B. Docker, Kubectl) und der Laufzeitumgebung (z. B. runc). Nabla wird außerdem mit einem Image-Konstruktor
runnc , den
runnc später ausführen kann. Aufgrund von Unterschieden im Dateisystem zwischen Unikernels und herkömmlichen Containern erfüllen Nabla-Images jedoch nicht die OCI-Image-Spezifikationen und daher sind Docker-Images nicht mit
runnc kompatibel. Zum Zeitpunkt des Schreibens befindet sich das Projekt noch in einem frühen Entwicklungsstadium. Es gibt andere Einschränkungen, z. B. die mangelnde Unterstützung für das Mounten / Zugreifen auf Host-Dateisysteme, das Hinzufügen mehrerer Netzwerkschnittstellen (für Kubernetes erforderlich) oder die Verwendung von Images von anderen Unikernel-Images (z. B. MirageOS).
Google gVisor
Google gVisor ist eine Sandbox-Technologie, die die Google Cloud Platform Application Engine (GCP), Cloud-Funktionen und CloudML verwendet. Irgendwann erkannte Google das Risiko, nicht vertrauenswürdige Anwendungen in der öffentlichen Cloud-Infrastruktur auszuführen, und die Ineffizienz von Sandbox-Anwendungen mit virtuellen Maschinen. Als Ergebnis wurde ein User-Space-Kernel für eine isolierte Umgebung solcher unzuverlässigen Anwendungen entwickelt. gVisor legt diese Anwendungen in der Sandbox ab, fängt alle Systemaufrufe von ihnen an den Host-Kernel ab und verarbeitet sie in der Benutzerumgebung mithilfe des gVisor Sentry-Kernels. Im Wesentlichen fungiert es als Kombination aus einem Gastkern und einem Hypervisor. Abbildung 4 zeigt die gVisor-Architektur.
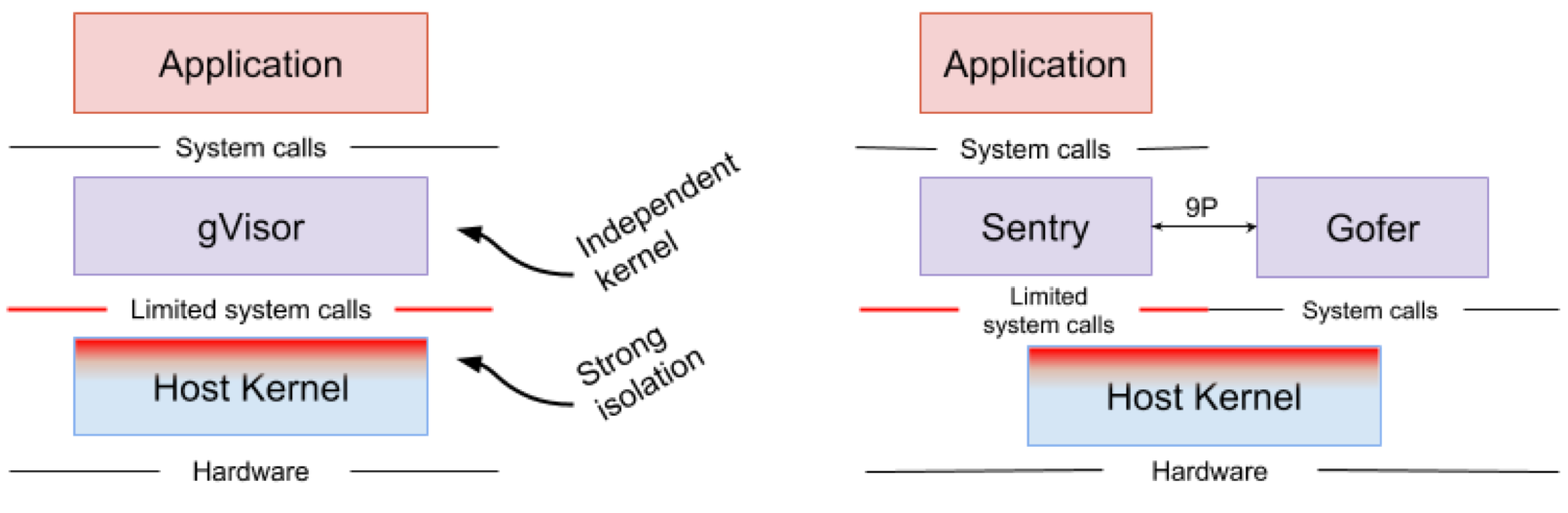 Abbildung 4. Implementierung des gVisor-Kernels // Sentry- und gVisor-Gofer-Dateisysteme verwenden eine kleine Anzahl von Systemaufrufen, um mit dem Host zu interagieren
Abbildung 4. Implementierung des gVisor-Kernels // Sentry- und gVisor-Gofer-Dateisysteme verwenden eine kleine Anzahl von Systemaufrufen, um mit dem Host zu interagierengVisor erstellt einen starken Sicherheitsbereich zwischen der Anwendung und ihrem Host. Es begrenzt die Systemaufrufe, die Anwendungen im Benutzerbereich verwenden können. Ohne sich auf Virtualisierung zu verlassen, arbeitet gVisor als Host-Prozess, der zwischen einer eigenständigen Anwendung und einem Host interagiert. Sentry unterstützt die meisten Linux-Systemaufrufe und Kernfunktionen des Kernels wie Signalübertragung, Speicherverwaltung, Netzwerkstapel und Stream-Modell. Sentry implementiert über 70% der 319 Linux-Systemaufrufe, um Sandbox-Anwendungen zu unterstützen. Sentry verwendet jedoch weniger als 20 Linux-Systemaufrufe, um mit dem Host-Kernel zu interagieren. Es ist erwähnenswert, dass gVisor und Nabla eine sehr ähnliche Strategie verfolgen: Der Schutz des Host-Betriebssystems und beide Lösungen verwenden weniger als 10% der Linux-Systemaufrufe, um mit dem Kernel zu interagieren. Sie müssen jedoch verstehen, dass gVisor einen Mehrzweckkern erstellt, und Nabla beispielsweise auf eindeutige Kernel angewiesen ist. Gleichzeitig starten beide Lösungen einen speziellen Gastkern im Benutzerbereich, um isolierte Anwendungen zu unterstützen, denen sie vertrauen.
Jemand mag sich fragen, warum gVisor einen eigenen Kernel benötigt, wenn der Linux-Kernel bereits Open Source und leicht zugänglich ist. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
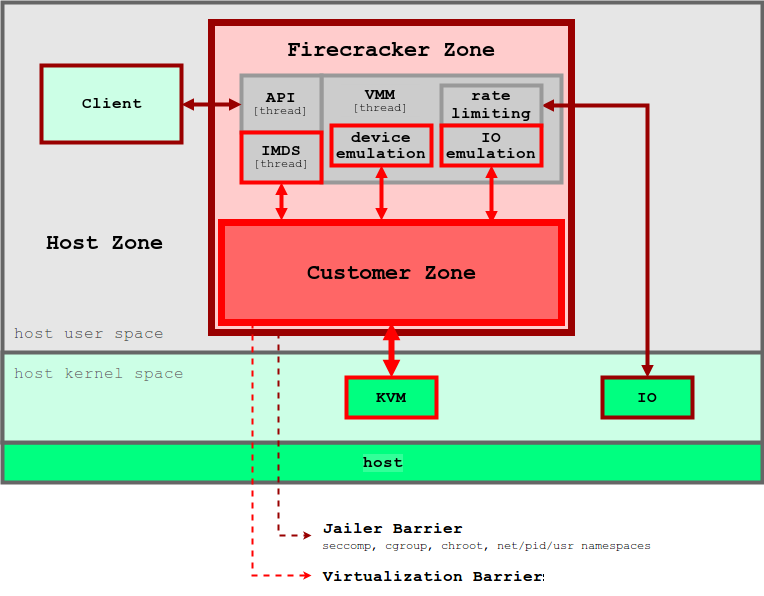 5. Firecracker
5. FirecrackerFirecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
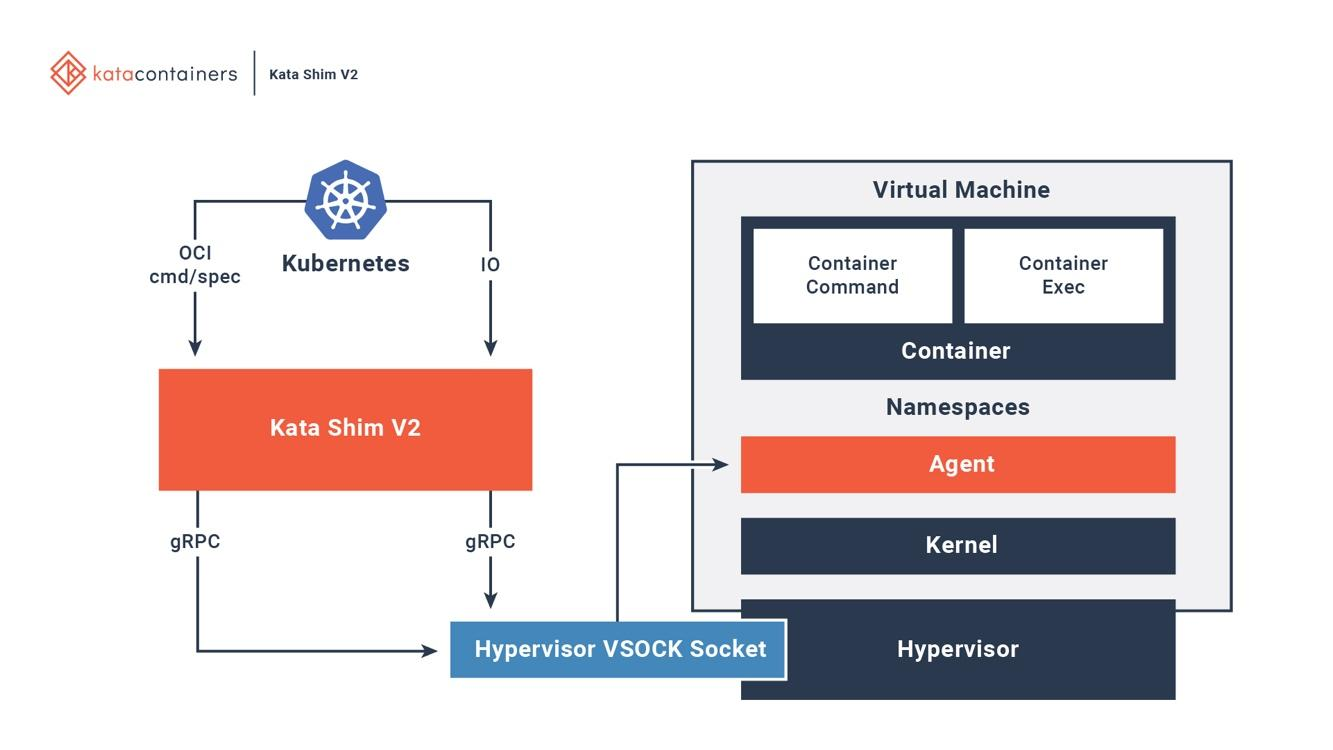 6. Kata Docker Kubernetes
6. Kata Docker KubernetesKata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Fazit
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
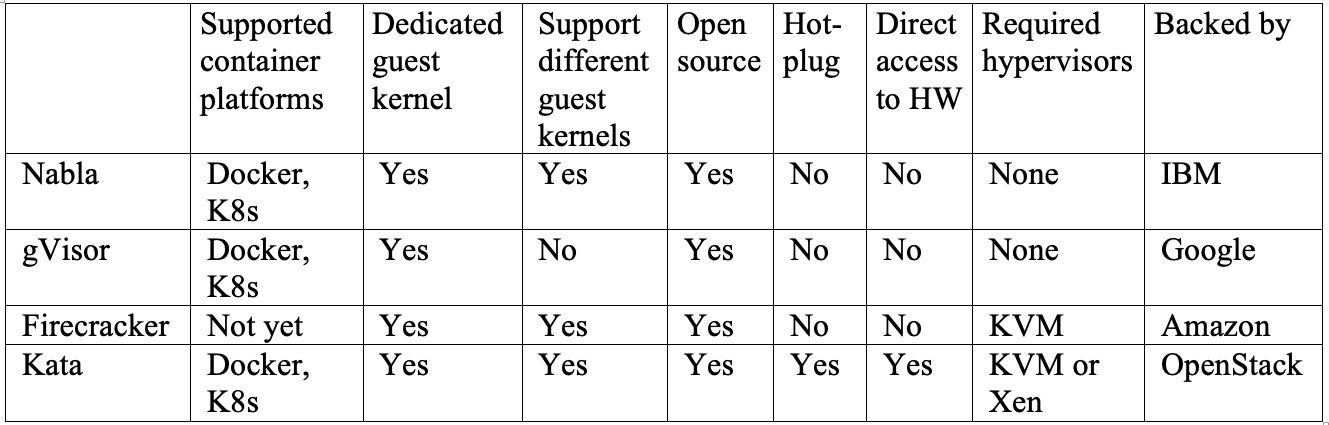 Es kann einige Zeit dauern, bis eine der Lösungen zum Standard wird, aber es ist gut, dass die meisten großen Cloud-Anbieter begonnen haben, nach Wegen zu suchen, um bestehende Probleme zu lösen.
Es kann einige Zeit dauern, bis eine der Lösungen zum Standard wird, aber es ist gut, dass die meisten großen Cloud-Anbieter begonnen haben, nach Wegen zu suchen, um bestehende Probleme zu lösen.