Das TensorFlow-Ökosystem enthält eine Reihe von Compilern und Optimierern, die auf verschiedenen Ebenen des Software- und Hardware-Stacks arbeiten. Für diejenigen, die Tensorflow täglich verwenden, kann dieser mehrstufige Stapel schwer verständliche Fehler sowohl bei der Kompilierung als auch bei der Laufzeit verursachen, die mit der Verwendung verschiedener Arten von Hardware (GPU, TPU, mobile Plattformen usw.) verbunden sind.
Diese Komponenten, beginnend mit dem Tensorflow-Diagramm, können in Form eines solchen Diagramms dargestellt werden:
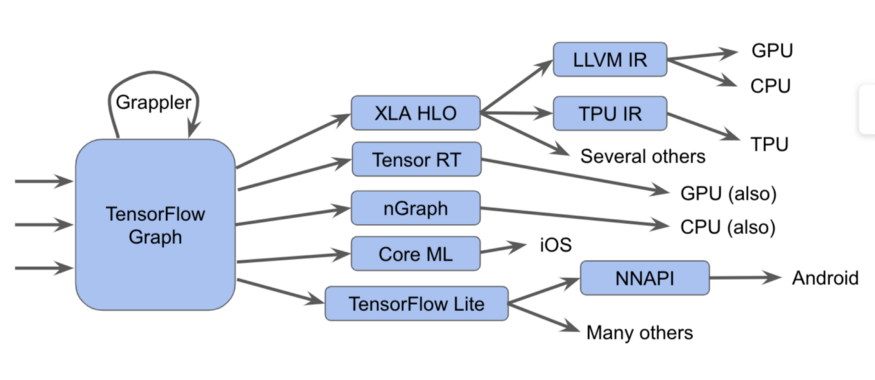 Es ist tatsächlich schwieriger
Es ist tatsächlich schwierigerIn diesem Diagramm sehen wir, dass Tensorflow-Diagramme auf verschiedene Arten ausgeführt werden können.
eine NotizIn TensorFlow 2.0 können Diagramme implizit sein, die gierige Ausführung kann Vorgänge einzeln, in Gruppen oder in einem vollständigen Diagramm ausführen. Diese Diagramme oder Fragmente des Diagramms müssen optimiert und ausgeführt werden.
Zum Beispiel:
- Wir senden die Grafiken an den Tensorflow-Executor, der spezialisierte handgeschriebene Kernel aufruft
- Konvertieren Sie sie in XLA HLO (XLA High-Level Optimizer-Darstellung) - eine allgemeine Darstellung des XLA-Optimierers, der wiederum den LLVM- Compiler für die CPU oder GPU aufrufen oder XLA für TPU weiterhin verwenden oder kombinieren kann.
- Wir konvertieren sie in TensorRT , nGraph oder ein anderes Format für einen speziellen Befehlssatz, der in Hardware implementiert ist.
- Wir konvertieren sie in das TensorFlow Lite- Format, führen sie in der TensorFlow Lite-Laufzeit aus oder konvertieren sie in Code, um sie auf der GPU oder dem DSP über die Android Neural Networks API (NNAPI) oder dergleichen auszuführen.
Es gibt auch komplexere Methoden, einschließlich vieler Optimierungsdurchläufe auf jeder Ebene, wie beispielsweise im Grappler-Framework, das die Operationen in TensorFlow optimiert.
Obwohl diese verschiedenen Implementierungen von Compilern und Zwischendarstellungen die Leistung verbessern, stellt ihre Vielfalt für Endbenutzer ein Problem dar, z. B. verwirrende Fehlermeldungen beim Koppeln dieser Subsysteme. Außerdem müssen die Entwickler neuer Software- und Hardware-Stacks die Optimierungs- und Konvertierungspassagen für jeden neuen Fall anpassen.
Aufgrund all dessen freuen wir uns, MLIR, eine mehrstufige Zwischenvertretung, bekannt zu geben. Dies ist ein Zwischenansichtsformat und Kompilierungsbibliotheken zur Verwendung zwischen einer Modellansicht und einem Compiler auf niedriger Ebene, der hardwareabhängigen Code generiert. Mit der Einführung von MLIR möchten wir neuen Forschungsergebnissen bei der Entwicklung der Optimierung von Compilern und der Implementierung von Compilern auf der Basis industrieller Qualitätskomponenten Platz machen.
Wir erwarten, dass MLIR für viele Gruppen von Interesse ist, darunter:
- Compilerforscher sowie Praktiker, die die Leistung und den Speicherverbrauch von Modellen für maschinelles Lernen optimieren möchten;
- Hardwarehersteller, die nach einer Möglichkeit suchen, ihre Hardware mit Tensorflow zu kombinieren, z. B. TPUs, mobile Neuroprozessoren in Smartphones und andere benutzerdefinierte ASICs;
- Personen, die den Programmiersprachen die Vorteile der Optimierung von Compilern und Hardwarebeschleunigern bieten möchten;
Was ist MLIR?
MLIR ist im Wesentlichen eine flexible Infrastruktur für moderne Optimierungscompiler. Dies bedeutet, dass es aus einer IR-Spezifikation (Intermediate Representation) und einer Reihe von Werkzeugen zum Transformieren dieser Darstellung besteht. Wenn wir über Compiler sprechen, wird der Übergang von einer übergeordneten Ansicht zu einer untergeordneten Ansicht als Verringern bezeichnet, und wir werden diesen Begriff in Zukunft verwenden.
MLIR wurde unter dem Einfluss von LLVM gebaut und leiht sich schamlos viele gute Ideen daraus. Es verfügt über ein flexibles Typsystem und dient zur Darstellung, Analyse und Transformation von Graphen, wobei viele Abstraktionsebenen in einer Kompilierungsebene kombiniert werden. Diese Abstraktionen umfassen Tensorflow-Operationen, verschachtelte polyedrische Schleifenbereiche, LLVM-Anweisungen sowie Festpunktoperationen und -typen.
Dialekte von MLIR
Um die verschiedenen Software- und Hardwareziele zu trennen, hat MLIR „Dialekte“, darunter:
- TensorFlow IR, das alles enthält, was in TensorFlow-Diagrammen getan werden kann
- XLA HLO IR, entwickelt, um alle Vorteile des XLA-Compilers zu nutzen, dessen Ausgabe wir nicht nur Code für TPU erhalten können.
- Ein experimenteller Affinitätsdialekt, der speziell für polyedrische Darstellungen und Optimierungen entwickelt wurde
- LLVM IR, 1: 1, das mit der nativen LLVM-Ansicht übereinstimmt, sodass MLIR mithilfe von LLVM Code für die GPU und die CPU generieren kann.
- TensorFlow Lite wurde entwickelt, um Code für mobile Plattformen zu generieren
Jeder Dialekt enthält eine Reihe spezifischer Operationen, bei denen Invarianten verwendet werden, z. B.: "Es handelt sich um einen binären Operator, dessen Eingabe und Ausgabe vom gleichen Typ sind."
Erweiterungen MLIR
MLIR verfügt nicht über eine feste und integrierte Liste globaler intrinsischer Operationen. Dialekte können vollständig benutzerdefinierte Typen definieren, und so kann MLIR Dinge wie das LLVM-IR-Typsystem (mit erstklassigen Aggregaten), Domänensprachenabstraktionen wie quantisierte Typen, die für ML-optimierte Beschleuniger wichtig sind, und in Zukunft auch modellieren. sogar ein Swift- oder Clang-System.
Wenn Sie diesem System einen neuen Low-Level-Compiler hinzufügen möchten, können Sie einen neuen Dialekt erstellen und vom Dialekt des TensorFlow-Diagramms zu Ihrem Dialekt absteigen. Dies vereinfacht den Pfad für Hardwareentwickler und Compilerentwickler. Sie können den Dialekt auf verschiedene Ebenen desselben Modells ausrichten. Optimierer auf hoher Ebene sind für bestimmte Teile der IR verantwortlich.
Für Compiler-Forscher und Framework-Entwickler können Sie mit MLIR Transformationen auf jeder Ebene erstellen. Sie können Ihre eigenen Operationen und Abstraktionen im IR definieren und so Ihre Anwendungsaufgaben besser modellieren. Somit ist MLIR mehr als eine reine Compiler-Infrastruktur, die LLVM ist.
Obwohl MLIR als Compiler für ML arbeitet, ermöglicht es auch den Einsatz von Technologien für maschinelles Lernen! Dies ist sehr wichtig für Ingenieure, die numerische Bibliotheken entwickeln, und kann nicht die gesamte Vielfalt der ML-Modelle und -Hardware unterstützen. Die Flexibilität von MLIR erleichtert das Erforschen von Strategien für den Code-Abstieg beim Wechsel zwischen Abstraktionsebenen.
Was weiter
Wir haben ein
GitHub-Repository geöffnet und laden alle Interessierten ein (siehe unseren Leitfaden!). Wir werden in den kommenden Monaten etwas mehr als diese Toolbox veröffentlichen - die Dialektspezifikationen TensorFlow und TF Lite. Wir können Ihnen mehr erzählen, um mehr zu erfahren, sehen Sie sich die
Präsentation von Chris Luttner und unsere
README auf Github an .
Wenn Sie über alle Aspekte von MLIR auf dem Laufenden bleiben möchten, nehmen Sie an unserer
neuen Mailingliste teil , die sich in Kürze auf Ankündigungen zukünftiger Versionen unseres Projekts konzentrieren wird. Bleib bei uns!