Unter dem Strich darüber, welchen Ansatz Huawei bei der Organisation des direkten Remote-Speicherzugriffs mithilfe der AI Fabric-Technologie bietet und wie er sich von InfiniBand und reinem Ethernet-basierten RDMA unterscheidet.
Distributed Computing wird in einer Vielzahl von Branchen eingesetzt. Dies sind wissenschaftliche Forschung und technische Entwicklungen wie Gesichtserkennungs- oder Autopilot-Erkennungswerkzeuge und Industrie. Im Allgemeinen findet die Datenanalyse immer mehr Anwendungen, und wir können mit Zuversicht sagen, dass sie in naher Zukunft nicht an Popularität verlieren wird. Tatsächlich erleben wir jetzt einen Übergang von der Ära des Cloud Computing, in der die wichtigsten Faktoren Anwendungen und die Geschwindigkeit der Bereitstellung von Diensten waren, zur Ära der Datenmonetarisierung, auch durch die Verwendung von Algorithmen für künstliche Intelligenz. Laut unseren internen Daten (
GIV- Bericht
2025: Entfaltung des Branchenentwurfs einer intelligenten Welt ) werden bis 2025 86% der Unternehmen KI für ihre Arbeit verwenden. Viele von ihnen betrachten diesen Bereich als das Hauptinstrument für die Modernisierung von Aktivitäten und möglicherweise als das grundlegende Instrument für zukünftige Geschäftsentscheidungen. Dies bedeutet, dass jedes dieser Unternehmen eine Art Verarbeitung von Rohdaten benötigt - höchstwahrscheinlich über verteilte Cluster.
Die Entwicklung der Architektur
Mit der wachsenden Popularität des verteilten Rechnens nimmt das zwischen einzelnen Rechenzentrumsmaschinen ausgetauschte Verkehrsaufkommen zu. Bei der Diskussion über Netzwerke wird traditionell die Aufmerksamkeit auf das Wachstum des Datenverkehrs zwischen dem Rechenzentrum und den Endbenutzern im Internet gerichtet, und es wächst wirklich. Die Zunahme des horizontalen Verkehrs in verteilten Systemen geht jedoch weit über alles hinaus, was Benutzer generieren. Laut Facebook verdoppelt sich der Verkehr zwischen ihren internen Systemen in weniger als einem Jahr.

Bei Versuchen, mit diesem Datenverkehr umzugehen, können Sie die Cluster vergrößern, dies ist jedoch nicht endlos möglich. Um das Wachstum der Rechenlast in den Clustern vorherzusagen, ist es daher erforderlich, die Verarbeitungseffizienz zu erhöhen - zunächst, um Engpässe in diesen verteilten Netzwerken zu finden und zu beseitigen.
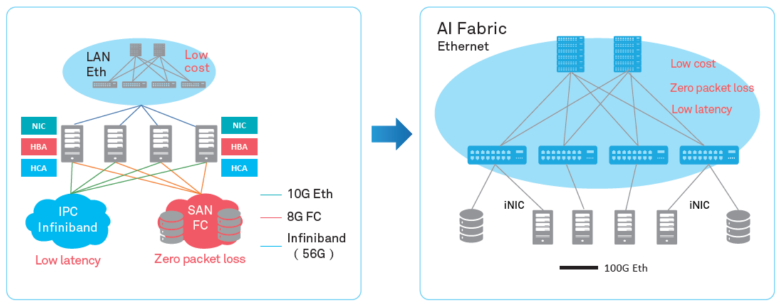
Wenn früher die Ressourcen jedes dieser Systeme separat das „schwache Glied“ verteilter Systeme waren, während sich ständig weiterentwickelnde Datenübertragungsnetze sogar die Anforderungen übertrafen, ist heute die Netzwerkkommunikation die Hauptursache für das Problem. Der bekannte TCP / IP-Protokollstapel und die Baumtopologie entsprechen nicht mehr den zugewiesenen Aufgaben. Daher verlassen immer mehr Rechenzentren das zentralisierte und wechseln zu einer neuen CLOS-Architektur, die eine größere Bandbreite und eine bessere Cluster-Skalierbarkeit bietet, wie dies beispielsweise Facebook vor einigen Jahren getan hat.

Gleichzeitig ist es notwendig, den Prozess auf einer anderen Ebene zu optimieren - auf der Ebene der Interaktion zweier getrennter Systeme. In diesem Artikel möchten wir darüber sprechen, welche Optimierungstools das Huawei Ai Fabric-Rechenzentrum bietet. Dies ist unsere proprietäre Technologie, die den Datenaustausch zwischen Knoten beschleunigt.
Netzwerkänderungen
Der wichtigste „Trick“ von Huawei Ai Fabric besteht darin, den Overhead beim Übertragen von Datenpaketen zwischen Systemen innerhalb des Clusters durch Implementierung von RDMA (Remote Direct Memory Access) zu reduzieren - direkter Zugriff auf den Speicher von Systemen im Cluster.
RDMA - eine Möglichkeit, Übertragungsverzögerungen zu reduzieren
RDMA ist keine neue Idee. Die Technologie ermöglicht den direkten Datenaustausch zwischen Speicher und Netzwerkschnittstelle, reduziert die Latenz und verhindert unnötiges Kopieren von Daten in Puffer. Seine Wurzeln reichen bis in die 1990er Jahre von Compaq, Intel und Microsoft zurück.
Es gibt drei Arten von Verzögerungen bei der Übertragung eines Pakets von einem System zu einem anderen:
- aufgrund der Prozessorverarbeitung, die beispielsweise zum Puffern von Daten im Betriebssystem und zum Berechnen von Prüfsummen erforderlich ist;
- aufgrund von Bussen und Datenübertragungskanälen (es ist technisch unmöglich, die Bandbreite signifikant zu erhöhen);
- aufgrund von Netzwerkgeräten.

Um die Verluste in dieser Kette bereits in den neunziger Jahren zu verringern, wurde vorgeschlagen, den direkten Zugriff auf den Speicher interagierender Systeme zu verwenden - ein abstraktes Modell der Architektur virtueller Schnittstellen. Die Hauptidee besteht darin, dass Anwendungen, die auf zwei interagierenden Systemen ausgeführt werden, ihren lokalen Speicher vollständig ausfüllen und eine P2P-Verbindung für die Datenübertragung herstellen, ohne das Betriebssystem zu beeinträchtigen. Auf diese Weise können Paketübertragungsverzögerungen erheblich reduziert werden. Da das VIA-Modell nicht implizierte, dass die übertragenen Daten in Zwischenpuffern abgelegt wurden, wurden außerdem die für den Kopiervorgang erforderlichen Ressourcen eingespart.

In Bezug auf das abstrakte Modell hat VIA RDMA als Technologie weitere Schritte zur optimalen Ressourcennutzung unternommen. Insbesondere wartet es nicht darauf, dass der Puffer gefüllt wird, um eine Verbindung herzustellen, und ermöglicht Verbindungen zu mehreren Computern gleichzeitig. Aufgrund dessen kann die Technologie Übertragungsverzögerungen von bis zu 1 ms reduzieren und so die Belastung des Prozessors verringern.
InfiniBand vs Ethernet
Die beiden wichtigsten RDMA-Implementierungen auf dem Markt - das proprietäre InfiniBand-Transportprotokoll und das „reine“ Ethernet-basierte RDMA - sind leider nicht ohne Nachteile.
Das InfiniBand-Transportprotokoll verfügt über einen integrierten Mechanismus zur Steuerung der Paketzustellung (Schutz vor Datenverlust), wird jedoch von bestimmten Geräten unterstützt und ist nicht mit Ethernet kompatibel. Tatsächlich schließt die Verwendung dieses Protokolls das Rechenzentrum bei einem Ausrüstungslieferanten, der bestimmte Risiken birgt und Schwierigkeiten beim Service verspricht (da InfiniBand einen geringen Marktanteil hat, wird es nicht so einfach sein, Spezialisten zu finden). Natürlich können Sie bei der Implementierung des Protokolls keine vorhandenen IP-Netzwerkgeräte verwenden.
RDMA über Ethernet ermöglicht die Verwendung vorhandener Geräte im Netzwerk und unterstützt Ethernet-Netzwerke, wodurch es einfacher wird, Service-Spezialisten zu finden. Im Vergleich zu Infiniband reduziert dies die Betriebskosten der Infrastruktur erheblich und vereinfacht deren Bereitstellung.
Der einzige schwerwiegende Nachteil, der die weit verbreitete Einführung von RDMA über Ethernet verhinderte, ist der fehlende Schutz vor Paketverlust, der die Bandbreite des gesamten Netzwerks begrenzt. Mechanismen von Drittanbietern müssen verwendet werden, um Paketverluste zu reduzieren oder eine Überlastung des Netzwerks zu verhindern. Wir sind genau diesen Weg gegangen und haben unsere eigenen intelligenten Algorithmen angeboten, um die Nachteile von RDMA gegenüber Ethernet auszugleichen und gleichzeitig die Vorteile des neuen Tools Huawei Ai Fabric beizubehalten.
Huawei AI Fabric - sein Weg
AI Fabric implementiert RDMA über Ethernet, ergänzt durch einen eigenen intelligenten Algorithmus zur Verwaltung von Netzwerküberlastungen, der keinen Paketverlust, hohe Netzwerkbandbreite und geringe Übertragungsverzögerung für RDMA-Streams bietet.
Huawei Ai Fabric basiert auf offenen Standards und unterstützt eine Reihe verschiedener Geräte, wodurch der Implementierungsprozess optimiert wird. Einige zusätzliche Tools - Add-Ons gegenüber offenen Standards, mit denen die Effizienz des Datenaustauschs gesteigert werden kann, die wir in späteren Veröffentlichungen diskutieren werden - sind jedoch nur für Geräte verfügbar, die von Huawei hergestellt werden. Die Switches der CloudEngine-Serie, die die Lösung unterstützen, verfügen über einen integrierten Chip, der die Verkehrseigenschaften analysiert und die Netzwerkparameter dynamisch anpasst, wodurch der Switch-Puffer effizienter genutzt werden kann. Die gesammelten Merkmale werden auch verwendet, um zukünftige Verkehrsmuster vorherzusagen.
Für wen ist das nützlich?
Mit Huawei Ai Fabric können Sie auf zwei Ebenen Gewinne erzielen.
Einerseits ermöglicht die Lösung die Optimierung der Rechenzentrumsarchitektur - Reduzierung der Anzahl der Knoten (aufgrund einer optimaleren Ressourcennutzung) und Schaffung einer konvergierten Umgebung ohne die herkömmliche Trennung in separate Subnetze, deren Wartung in Teilen schwierig und teuer ist. Mit dem Tool müssen Sie nicht für jeden Diensttyp im Domänencontroller separate Subnetze auswählen (mit eigenen Netzwerkanforderungen). Sie können eine einzelne Umgebung erstellen, die alle Dienste bereitstellt.

Auf der anderen Seite können Sie mit AI Fabric die Geschwindigkeit des verteilten Rechnens erhöhen, insbesondere dort, wo Sie häufig auf den Speicher von Remote-Systemen zugreifen müssen. Zum Beispiel impliziert die Einführung von KI in jedem Bereich eine Lernphase des Algorithmus, die Millionen von Operationen umfassen kann, so dass der Verzögerungsgewinn bei jeder solchen Operation zu einer ernsthaften Beschleunigung des Prozesses führt.
Die Einführung eines speziellen Tools wie Huawei Ai Fabric macht sich in einem Rechenzentrum mit sechs oder mehr Switches bemerkbar. Je größer das Rechenzentrum ist, desto höher ist jedoch der Gewinn. Aufgrund der optimalen Ressourcennutzung bietet ein Cluster in der gleichen Größenordnung mit Ai Fabric eine höhere Leistung. Beispielsweise kann ein Cluster mit 384 Knoten die Leistung eines „regulären“ Clusters mit 512 Knoten erreichen. Darüber hinaus unterliegt die Lösung keinen Einschränkungen hinsichtlich der Anzahl der physischen Switches innerhalb der Infrastruktur. Es kann Zehntausende geben (wenn Sie vergessen, dass Projekte normalerweise auf die Größe der Verwaltungsdomäne beschränkt sind).