Guten Tag, Chabravchane. Ich arbeite bei Veeam Software und bin einer der Entwickler unserer Linux-Backup-Lösung. Durch die Besetzung bin ich zufällig auf BTRFS gestoßen. In jüngerer Zeit ist es vom Status „noch nicht geeignet“ zum Status „stabil“ übergegangen. Und während die ersten Benutzer im Netzwerk Problembereiche und Stabilitätsprobleme diskutierten, stießen wir bei Veeam mit einem Zauberstab darauf und versuchten, es zu sichern. Es stellte sich, gelinde gesagt, nicht sehr viel heraus - es ist zu unterschiedlich, nicht wie herkömmliche Dateisysteme. Ich musste viele Aspekte studieren und viele Rechen sammeln, bevor wir lernten, damit zu arbeiten. Während des Lernprozesses hat es BTRFS geschafft, mich sowohl auf gute als auch auf weniger gute Weise zu beeindrucken. Ich bin sicher, sie wird keinen IT-Spezialisten aus der Linux-Welt gleichgültig lassen: Einige werden spucken, andere werden loben.
Wenn Sie von diesem Dateisystem gehört haben, aber nicht wissen, warum es ist, sich für Details interessieren oder suchen, wo Sie es kennenlernen können, lade ich Sie zu cat ein.
Einführung
BTRFS (B-Tree Filesystem) - Dateisystem für Unix-ähnliche Betriebssysteme, basierend auf der Copy-on-Write-Technik (CoW), das eine einfache Skalierung des Dateisystems, ein hohes Maß an Datenzuverlässigkeit und -sicherheit, Konfigurationsflexibilität und einfache Verwaltung bei gleichzeitiger Wartung bietet zur gleichen Zeit hohe Geschwindigkeit. Zumindest sagt das die
Haupt-Wiki-Seite .
Um die Formalitäten zu erfüllen, listen wir die Hauptmerkmale von btrfs auf:
- Maximale Dateigröße 2 ^ 64 Bytes
- Dynamische Inode-Tabelle
- Datendeduplizierung
- Effektive Dateispeicherung in sehr kleinen und sehr großen Größen
- Subwolums und Snapshots erstellen
- Subvolumenquoten
- Prüfsummen für Daten und Metadaten
- Die Möglichkeit, mehrere Laufwerke in einem einzigen Dateisystem zu kombinieren
- Erstellen einer RAID-Konfiguration auf Dateisystemebene
- Datenkomprimierung
- Defragmentierungsdaten im laufenden Betrieb
Ich möchte Sie sofort warnen, dass sich BTRFS aktiv entwickelt und einige Punkte von Version zu Version unterschiedlich sein können. Über den Link
https://btrfs.wiki.kernel.org/index.php/Changelog können Sie herausfinden, wann welche Funktionen hinzugefügt, geändert oder behoben wurden.
Ja, BTRFS ist ein junges und modernes Dateisystem, das eine Vielzahl von Aufgaben löst, jedoch nicht ohne Nachteile:
- Die aktive Entwicklung führt zu einer Änderung aller wichtigen Punkte, auf die sich Drittanbieter bei der Arbeit verlassen können.
- Trotz der Zusicherungen der Entwickler hinsichtlich der Stabilität von BTRFS treten bei Benutzern regelmäßig Probleme auf, die möglicherweise zu Datenverlust führen. In der Regel „schweben“ sie in der Natur, weshalb sie noch nicht untersucht und korrigiert wurden.
- Hohe Anfälligkeit für Fragmentierung.
- Spärliche und manchmal veraltete Dokumentation.
Eine ganze Seite ist den Problemen des Dateisystems in verschiedenen Versionen der Kernel gewidmet -
https://btrfs.wiki.kernel.org/index.php/Gotchas . Ich rate Ihnen dringend, dort nachzuschauen - es stellt sich als sehr interessant und nicht offensichtlich heraus.
BTRFS-Struktur
Das vereinfachte BTRFS-Gerät kann in folgende Ebenen unterteilt werden:

Blockgeräte befinden sich auf der untersten Ebene und stellen einen oder mehrere separate physische Adressräume dar (dasselbe „physische“ wie die Blockgeräte selbst, dies sind jedoch bereits Details). Durch spezielle Strukturen werden die zugewiesenen physischen Speicherblöcke zu einem einzigen virtuellen Adressraum zusammengefasst.
Metadatenstrukturen und Blöcke mit Benutzerdaten (Extents) werden bereits auf logischer Ebene angesprochen. Infolgedessen können sich Daten, die sich sequentiell auf einer logischen Ebene befinden, physisch auf verschiedenen Blockgeräten befinden.
Metadatenstrukturen können in Ebenen unterteilt werden. Natürlich werde ich sie nicht klassifizieren - es gibt viele von ihnen, und solche Details auf niedriger Ebene sind das Thema eines separaten Artikels. Hier ist es wichtig, dass sich einige Strukturen in der Hierarchie als höher als andere herausstellen, und ganz oben wird es eine Struktur geben, die ein Subvolumen ist.
Subvolume ist eine Art Einstiegspunkt oder vielmehr die Stammelemente des Dateisystems. Sie bilden eine separate Ebene der Datendarstellung, die die Arbeit der unteren Ebenen zusammenfasst und Benutzerdaten in der üblichen Form darstellt: Verzeichnisse und Dateien. Darüber hinaus sind Subwölfe ein Schlüsselelement des CoW-Mechanismus in BTRFS. Dieselben Dateien in zwei Subvolumes können sich als derselbe Datensatz auf den unteren Ebenen herausstellen.
Die letzte Schicht ist die Datenschicht. Wie der Benutzer sie sieht. Dies sind Dateien und Verzeichnisse, die sich im Subvolume befinden.
Aber genug Theorie. Es ist Zeit, weiter zu üben!
Btrfs-Progs
Dies ist ein Standardsatz von Dienstprogrammen zum Verwalten von BTRFS. Abhängig vom Distributionspaket kann das Paket mit diesen Dienstprogrammen im Repository unterschiedliche Namen haben:
btrfsprogs ,
btrfs-progs ,
btrfs-tools usw. Wenn Ihr Repository nichts Ähnliches hatte, können Sie es jederzeit manuell kompilieren. Die Quellen sind nicht weit entfernt -
https://github.com/kdave/btrfs-progs .
Die wichtigsten Dienstprogramme in diesem Paket sind
btrfs und
mkfs.btrfs . Ab dem zweiten, denke ich, ist alles sehr klar - es ist notwendig, BTRFS auf einem Blockgerät zu erstellen. Erstens ist
btrfs das Hauptdienstprogramm, mit dem Sie den Rest erledigen können. Eine Art "Schweizer Messer".
In diesem Artikel habe ich Version v4.15.1 verwendet. Das Dienstprogramm entwickelt sich sehr aktiv und es gibt spürbare Unterschiede von Version zu Version. Wenn Sie also nicht über den erforderlichen Befehl verfügten, überprüfen Sie die Version des Dienstprogramms
btrfs. Möglicherweise ist sie bereits veraltet.
Wahrscheinlich befinden sich auch die Dienstprogramme
btrfsck und
btrfstune im Paket.
- Die erste dient dazu, das Dateisystem auf Fehler und nachfolgende Korrekturen zu überprüfen. Ich empfehle jedoch nicht, es zu verwenden. Es befindet sich im veralteten Status und seine Funktionalität wurde in den Befehl btrfs check verschoben.
- Mit der zweiten Option können Sie einige nützliche Vorgänge für btrfs ausführen, z. B. die eindeutige Kennung des Dateisystems (FS UUID) ändern oder bestimmte Funktionen des Dateisystems aktivieren.
Zusätzlich zu den oben aufgeführten Dienstprogrammen enthält das Paket mehrere weitere Dienstprogramme, die jedoch hauptsächlich zum Debuggen von btrfs benötigt werden und in diesem Artikel nicht hilfreich sind.
Formatieren einer Festplatte in BTRFS
In der Praxis ist alles einfacher. Beginnen wir mit einem Laufwerk.
Das Formatieren einer einzelnen Festplatte in btrfs erfolgt mit dem üblichen Befehl:
mkfs.btrfs /dev/sdc -L single_drive
Als Antwort gibt das Dienstprogramm die Parameter des erstellten Dateisystems an die Konsole aus:
btrfs-progs v4.15.1 See http://btrfs.wiki.kernel.org for more information. Label: single_drive UUID: 59307d69-6d2f-4d2e-aae2-a5189ad3c256 Node size: 16384 Sector size: 4096 Filesystem size: 1.00GiB Block group profiles: Data: single 8.00MiB Metadata: DUP 51.19MiB System: DUP 8.00MiB SSD detected: no Incompat features: extref, skinny-metadata Number of devices: 1 Devices: ID SIZE PATH 1 1.00GiB /dev/sdc
Lassen Sie uns die dargestellten Parameter durchgehen.
Wenn Sie ein Blockgerät markieren, wendet btrfs standardmäßig eine Duplizierung auf Metadaten und Systemdaten an, und Benutzerdaten verbleiben in einer einzigen Kopie auf dem Datenträger. Wenn Sie btrfs auf mehreren Datenträgern gleichzeitig erstellen, wird das Profil "RAID0" standardmäßig auf Benutzerdaten und "RAID1" auf Metadaten angewendet.
Diese Gruppe von Parametern wird mit zwei Schlüsseln gesteuert:
-d für Daten und
-m für Metadaten und Systemdaten.
Aber es gibt eine Nuance ... Bei SSDs ist das anders. Tatsache ist, dass wenn wir ein SSD-Laufwerk (oder ein Flash-Laufwerk) markieren würden, das Dateisystem standardmäßig keine Metadaten duplizieren würde. SSDs können die Datendeduplizierung verlängern, um die Lebensdauer von Speicherelementen zu verlängern. Das heißt, Mit zwei logischen Kopien der Daten wird tatsächlich nur eine auf dem Medium aufgezeichnet. Wenn ein Speichersegment ausfällt, werden daher „beide Kopien“ der Daten beschädigt. Durch zweimaliges Schreiben von Daten wird die SSD-Ressource außerdem einfach schneller verbraucht.
Um den Medientyp zu bestimmen, überprüft btrfs den Inhalt der Datei
/ sys / block / DEV / queue / rotational , wobei "DEV" der Name des zu überprüfenden Blockgeräts ist.
Selbstverständlich kann auch bei einer SSD das Speicherprofil erzwungen werden.
Um eine btrfs-Instanz auf mehreren Geräten zu erstellen, geben Sie diese einfach mit einem Leerzeichen an:
sudo mkfs.btrfs /dev/sdc /dev/sdd -L double_drive
oder mit Profilen:
sudo mkfs.btrfs /dev/sdc /dev/sdd -d raid1 -m raid1 -L raid1_drive
Es ist zu beachten, dass die Medien nicht dieselbe Größe haben müssen, auch wenn die vollständige Spiegelung verwendet wird. Sobald jedoch nicht genügend Speicherplatz auf dem kleinsten Laufwerk vorhanden ist, um Speicher zuzuweisen, zeigt das Dateisystem eine Meldung an, dass kein freier Speicherplatz vorhanden ist, obwohl physisch möglicherweise noch freier Speicherplatz auf anderen Medien vorhanden ist.
Montage
Der erste Mount von frisch erstellten btrfs unterscheidet sich nicht von anderen Dateisystemen:
mount /dev/sdc /mnt
Befindet sich das Dateisystem auf mehreren Festplatten, reicht es zum Mounten aus, eine davon anzugeben.
Im Allgemeinen umfasst das Mounten von btrfs immer das Mounten eines oder mehrerer seiner Subvolumes. Wenn der Befehl mount nicht angegeben ist, welches Subvolume gemountet werden soll, liest btrfs aus dem speziellen Datensatz die ID des Subvolumes, das standardmäßig gemountet werden muss. Dieser Eintrag kann später mit dem Befehl
btrfs set-default geändert werden. Wenn Sie ihn jedoch zum ersten Mal auf btrfs bereitstellen, gibt es nur ein Subvolume - das Root-Volume. Es ist standardmäßig für die Montage angegeben.
Die Root-Unterwelt auf btrfs ist immer vorhanden. Es wird zusammen mit dem Dateisystem angezeigt und kann in Zukunft nicht mehr geändert werden.
Es gibt zwei Möglichkeiten, ein anderes als das Standard-Subvolume bereitzustellen:
Geben Sie den Pfad vom Root-Subvolume btrfs an:
mount -o subvol=/path/to/subvol /dev/sdc /mnt
Geben Sie entweder die Subvolume-ID an:
mount -o subvolid=257 /dev/sdc /mnt
Wie bereits erwähnt, wird eines der btrfs-Subvolumes standardmäßig als gemountet angegeben. Finden Sie heraus, welches möglich ist, indem Sie Folgendes tun:
btrfs subvolume get-default /path/to/any/subvolume
Um den Standard-Submount zu installieren, können Sie den folgenden Befehl verwenden:
btrfs subvolume set-default 258 /path/to/any/subvolume
Der Pfad zum Subvolume wird in diesem Fall nur benötigt, um die spezifische btrfs-Instanz anzugeben, für die der Befehl gilt. Dies muss übrigens keine Unterwelt sein, der Pfad zu einem Verzeichnis ist ebenfalls geeignet.
Der Befehl
mount akzeptiert eine Vielzahl von Optionen zum Steuern der Funktionen von btrfs: Defragmentierung, Cache-Leeren, Komprimierung, Cow, Protokollierung, Balance, SSD-Unterstützung und viele andere für btrfs spezifische Dinge. Ich werde sie im Rahmen dieses Artikels nicht berücksichtigen, weil Sie werden für die Feinabstimmung des Dateisystems benötigt, und in den allermeisten Fällen können Sie auf sie verzichten.
Subvolumen ist
Ein Subvolume ist ein Schlüsselelement von btrfs, das verschiedene Funktionen ausführt:
- Speicherung von Benutzerdaten und anderem Teilvolumen,
- Bereitstellung des Zugriffs auf Daten (Montage),
- CoW-Mechanismus
- Schnappschüsse erstellen.
In erster Näherung ist das Subvolumen ein normales Verzeichnis. Sie können sie umbenennen / verschieben, ihren Inhalt anzeigen, Dateien darin platzieren und ändern. Es sind keine speziellen Dienstprogramme erforderlich.
Das Erstellen und Löschen eines Subvolumes erfolgt auf gemounteten btrfs mit speziellen Befehlen:
btrfs subvolume create /mnt/subvolume_name btrfs subvolume delete /mnt/subvolume_name
Ich stelle fest, dass, wenn Sie versuchen, das Subvolume mit dem Dateimanager oder dem Dienstprogramm
rm zu entfernen, der Vorgang mit einem Fehler endet, der
nicht zulässig ist (der Vorgang ist nicht zulässig).
UPD: Ab Kernel Version 4.18.0 können Sub-Volleys mit dem Dienstprogramm
rm oder den Dateimanager-Tools gelöscht werden. Anscheinend war es ein Fehler, keine Funktion. Vielen Dank an Prototik
Habravchanin für die Klarstellung.
Nach dem Erstellen eines Subvolumes können Sie dessen Eigenschaften sehen:
btrfs subvolume show /mnt/subvolume_name Name: subx UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Parent UUID: - Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 268 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Lassen Sie uns die Haupteigenschaften des Subwolumes durchgehen:
- Name - Der Name des Subvolumes
- UUID ist eine universelle eindeutige Kennung, die hauptsächlich dazu dient, Subwoofer-Snapshot-Beziehungen zu bestimmen.
- Übergeordnete UUID - Kennung des Subvolume-Vorfahren, von dem der aktuelle abgeleitet ist.
- Empfangene UUID - Kennung des Subvolume-Vorfahren, der über btrfs send gesendet wurde.
- Subvolume ID - eine eindeutige Kennung für die Platzierung im B-Baum,
- Generierung - Transaktionsnummer bei der letzten Aktualisierung der Subvolume-Metadaten,
- Gen bei der Erstellung - Transaktionsnummer zum Zeitpunkt der Erstellung des Subvolumes,
- Übergeordnete ID - Kennung des Subvolumens, in das das aktuelle eingebettet ist.
- Die ID der obersten Ebene entspricht genau der ID der Eltern.
- Flags - Flags (tatsächlich ist nur 1 Flag schreibgeschützt ),
- Schnappschüsse - Eine Liste von Schnappschüssen aus diesem Subvolume.
Das Subvolume hat einen weiteren Parameter - dies ist sein Pfad vom Stammelement btrfs. Der Pfad wird angezeigt, wenn das Subvolume aufgelistet wird:
btrfs subvolume list /path/to/any/btrfs/mountpoint
Aber hier ist alles einfach und klar - es macht nicht einmal Sinn, die Ausgabe des Befehls zu bringen.
Wie bei den Befehlen
get-default und
set-default können Sie hier den Pfad zu einem beliebigen Subvolume angeben. Das Ergebnis ändert sich nicht. Dieser Pfad wird verwendet, um das Root-Subbolum btrfs zu finden. Danach wird der gesamte Subwolum-Baum gelesen.
Wenn Sie versuchen, das Subvolume beispielsweise mit dem Dienstprogramm
cp zu kopieren, ist der Kopiervorgang erfolgreich. Infolgedessen wird jedoch nicht das Subvolume erstellt, sondern das übliche Verzeichnis. Btrfs bietet jedoch ein viel flexibleres Werkzeug zum Erstellen solcher Kopien - Schnappschüsse.
Schnappschuss ist
Snapshot ist auch eine Unterwelt mit erweiterten Eigenschaften.
Ihr Hauptunterschied besteht darin, dass der Schnappschuss Aufzeichnungen darüber enthält, aus welchem Subwolum er hergestellt wurde. Dies sind die Felder
Parent UUID und
Received UUID . Im Subwoofer sind diese Felder ebenfalls vorhanden, sie sind jedoch immer leer. Tatsächlich sind ein Schnappschuss und ein Subvolumen ein und dasselbe.
Beim Erstellen können Sie den Snapshot mit der
-r für Änderungen blockieren.
btrfs subvolume snapshot -r /path/to/subvol /path/to/snapshot
In diesem Fall bleiben die Dateien garantiert in dem Zustand, in dem sie sich zum Zeitpunkt der Erstellung des Snapshots befanden.
Das schreibgeschützte Flag kann auch manuell gesteuert werden. Dies funktioniert für jedes Subvolume:
btrfs property get /path/to/subvol ro btrfs property set /path/to/subvol ro true
Wenn wir uns nun die Eigenschaften des Snapshots ansehen, sehen wir das ausgefüllte
übergeordnete UUID- Feld:
btrfs subvolume show /path/to/snapshot Name: subx UUID: d08612d8-596a-11e9-8647-d663bd873d93 Parent UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 269 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Ein wichtiges Merkmal der Snapshot-Operation ist, dass sie nicht rekursiv ist. Anstelle eines verschachtelten Subvolumes werden im Snapshot leere Verzeichnisse erstellt.
Wenden wir uns dem folgenden Beispiel zu.
Im Dateisystem befindet sich ein Subwoofer „sub0“, in dem sich ein Subwoofer
subA und ein Verzeichnis
dirB befinden . In jedem von ihnen befinden sich
fileA bzw.
fileB .
Schnappschuss entfernen:
btrfs subvolume snapshot sub0 snap0
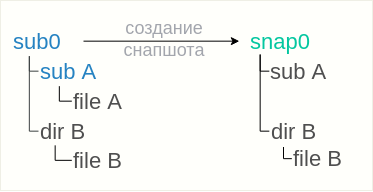
Der
erstellte Snapshot
Snap0 erbt alle Dateien und Verzeichnisse des übergeordneten Snapshots. Der SubA-
Subwoofer wird jedoch nicht im Snapshot angezeigt. Stattdessen wird im Snapshot nur ein leeres Verzeichnis angezeigt, d. H. Der Inhalt des SubA-
Subvolumes wird nicht vererbt.
Einerseits ist dies gut - wir entfernen den Schnappschuss aus einem bestimmten Subvolume, und alle verschachtelten sind für uns nicht von Interesse. Wenn andererseits ein rekursiver Snapshot erforderlich ist, hat btrfs keine Lösung für dieses Problem. Wir müssen nach Arbeitsrunden suchen.
Die erste Problemumgehung basiert auf der Tatsache, dass der Snapshot ohne schreibgeschütztes Flag entfernt wurde, sodass Sie die Situation ganz einfach beheben können:
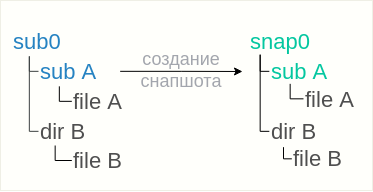
Wenn der Schnappschuss mit dem schreibgeschützten Flag entfernt wurde, funktioniert die obige Option nicht, da In
snap0 können Sie weder das Verzeichnis löschen noch einen Snapshot platzieren. Es gibt nur eine Option: Platzieren Sie Schnappschüsse in der Nähe des Snap0-
Subwoofers :
btrfs subvolume snapshot sub0/subA snapA
und mounten
Sie dann
snapA in
snap0 snapshot, das Verzeichnis dafür ist bereits vorhanden:
mount -o subvol=snapA snap0/subA
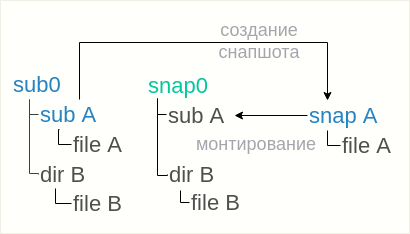
In jedem Fall ist es wichtig zu verstehen, dass rekursive Schnappschüsse alle zu unterschiedlichen Zeiten in unterschiedlichen Vorgängen aufgenommen werden. Es kann nicht von einer atomaren Entfernung eines Schnappschusses aus mehreren Subvolumina gesprochen werden.
Beim Schreiben kopieren
Ein bisschen über Subvolume und CoW-Ansatz. Stellen Sie sich vor, ein Subvolume befindet sich im Dateisystem und eine Datei befindet sich darin (im Idealfall - die Datei ist nicht fragmentiert). Als nächstes wird ein Schnappschuss vom Subwolly entfernt.

Im Dateisystem wird ein neues Subvolume (Snapshot) mit genau demselben Inhalt wie das ursprüngliche Subvolume angezeigt. Das Erstellen eines Schnappschusses erfolgt fast augenblicklich - die Daten der Datei selbst werden nicht kopiert. Stattdessen werden zusätzliche Metadaten erstellt und ein Snapshot zusammen mit dem übergeordneten Subvolume wird zum Eigentümer der Datei. Tatsächlich gab es nur eine Datei auf der Festplatte, aber jetzt gehört sie sowohl zum Subvolume als auch zum Snapshot.
Wenn Sie jetzt die Datei im Subvolume ändern, wirken sich die Änderungen nicht auf die Datei im Snapshot aus. Wenn beim Erstellen des Snapshots das schreibgeschützte Flag nicht gesetzt wurde, kann auch die Datei im Snapshot geändert werden.
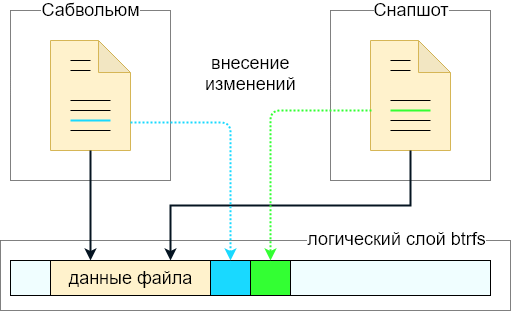
Technisch gesehen werden beim Ändern einer Datei nur diese Änderungen aufgezeichnet. Die Quelldatei wird also auf der Festplatte gespeichert, plus ein Delta, das die Originaldatei von der geänderten unterscheidet. Wenn Sie eines der Subvolumes löschen (mit dem zweiten meine ich einen Snapshot), werden überschüssige Daten, die von niemandem mehr verwendet werden, von der Festplatte gelöscht, und nur die aktuelle Version der Datei verbleibt auf der Festplatte (aus Sicht des verbleibenden Subvolumes).
Ein kurzer Hinweis : Nach dem Entfernen verschwindet der Subwoofer sofort aus den Augen des Benutzers und das Dienstprogramm gibt die Steuerung an das Terminal zurück. Die Daten auf der Festplatte werden jedoch für einige Zeit durch den Hintergrundprozess bereinigt. Das heißt, im Gegensatz zum Entfernen eines regulären Verzeichnisses muss nicht auf den tatsächlichen Abschluss des Löschvorgangs gewartet werden. Wenn Sie mit diesem Prozess synchronisieren und warten müssen, bis er abgeschlossen ist, können Sie beim Aufruf von
delete den Schalter
--commit-after angeben. Der Befehl
btrfs subvolume list ,
der mit der
Option -d aufgerufen wird , zeigt eine Liste der Subvolumes an, die vom Benutzer gelöscht wurden und gerade von der Festplatte gelöscht werden.
Darüber hinaus können Sie mit btrfs Dateien im Dateisystem klonen, ohne auf Snapshots zurückgreifen zu müssen. Dies erfolgt durch regelmäßiges Kopieren mit der
--reflink :
cp -ax --reflink=always /original/file /copied/file
Der Schlüssel
reflink=always teilt dem Dateisystem mit, dass beim Kopieren der CoW-Mechanismus verwendet werden soll. Nach dem Kopieren können Dateien unabhängig voneinander geändert werden, sodass wir das gleiche Verhalten wie nach dem Erstellen eines Snapshots erhalten. Warum brauchen wir dann Subbolen?
Subtolums auf btrfs spielen die Rolle eines übergeordneten Steuerungswerkzeugs für ganze Datensätze: Erstens ist es die atomare Schnappschussentfernung aus allen Daten eines Subvolumens (im Fall von --reflink-Atomizität nur auf Dateiebene), und zweitens ist es möglich zu sehen, von wem es geerbt wird oder schnell den Datensatz auf eine frühere Version usw. zurücksetzen.
Somit bietet btrfs die Möglichkeit, Dateizustände zu gewünschten Zeitpunkten zu erfassen, wobei Subvolume als übergeordnetes Mittel zur Verwaltung dieser Zustände verwendet wird.
Subvolume Recovery
In den Weiten stellt sich oft die Frage: "Ich habe einen Subwoofer, ich habe einen Schnappschuss, wie man einen Rückwärtsgang macht?" Dieser Ansatz gilt nicht für btrfs, weil Es gibt keine Möglichkeit, "den Subwolly zurückzurollen". Stattdessen bietet btrfs eine Strategie an, um den Subwolly durch seinen Snapshot zu ersetzen. In der Tat, warum etwas zurücksetzen, wenn der Schnappschuss selbst dieses Objekt ist, das wir mit Zurücksetzen erhalten möchten.
Stellen Sie sich dieses Szenario vor: Auf btrfs gibt es ein Subvolume, in dem sich die Dateien einer Datenbank befinden (also oder andere wichtige Daten). Snapshots werden regelmäßig aus diesem Subvolume entfernt, und irgendwann müssen die Daten zurückgesetzt werden. In diesem Fall entfernen wir einfach das Subwolum und verwenden stattdessen den daraus entnommenen Snapshot. Wenn wir diese Daten nicht ebenfalls verderben möchten, entfernen wir einen weiteren Snapshot aus dem Snapshot. Wenn die ursprüngliche Unterwelt nicht gemountet und als normales Verzeichnis verwendet wurde, muss sie entweder gelöscht oder verschoben / umbenannt werden, und an ihrer Stelle sollte ein Snapshot platziert werden.
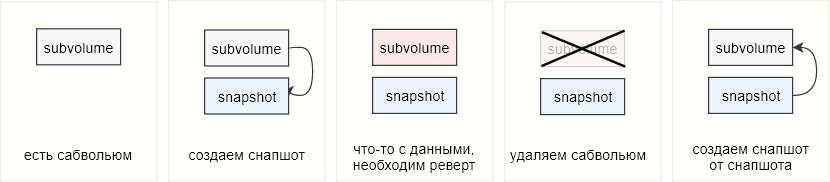
In der Konsole könnte es ungefähr so aussehen:
Wenn das Subvolume über den Mount-Punkt bereitgestellt und verwendet wurde, reicht es aus, das Subvolume zu entfernen und an seiner Stelle einen Snapshot bereitzustellen.

Der Vollständigkeit halber werde ich es noch einmal versuchen und etwas anders. Das Subvolumen, in dem Änderungen auftreten, ist der
Hauptzweig .
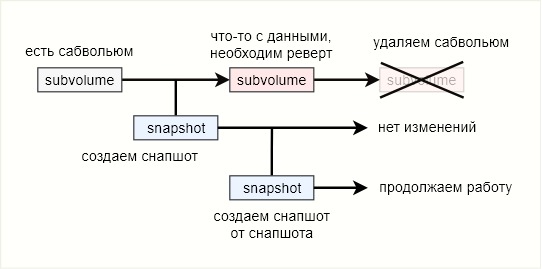
Beim Erstellen eines Snapshots wird der Status der Dateien auf der Festplatte festgelegt. Von nun an ist ein Schnappschuss ein Brunch der Hauptniederlassung. Alle weiteren Änderungen an
main wirken sich in keiner Weise auf den Schnappschuss aus. Rollback auf Snapshot bedeutet, die Verwendung des
Hauptzweigs zu beenden und vollständig auf Brunch umzuschalten. Der
Hauptzweig kann als unnötig gelöscht werden. Somit ist btrfs praktisch ein Versionskontrollsystem, jedoch ohne die Möglichkeit, Zweige wieder zusammenzuführen.
Dateisystembaum
Einer der nicht offensichtlichen Punkte bei der Verwendung von btrfs ist die Aufteilung der Systemdaten in Subvolumes. Natürlich gibt es keinen „richtigen“ Ansatz für dieses Problem. Es gibt jedoch drei Möglichkeiten, die Struktur des Subvolumens zu organisieren: eine flache Struktur, verschachtelt und gemischt.
Eine flache Struktur bedeutet, dass das Subvolumen in einer flachen Liste im Root-Subvolumen platziert wird. Sie können beispielsweise das Stammverzeichnis des Dateisystems (nennen wir es
Stammverzeichnis ), das Benutzerverzeichnis
home , das Verzeichnis mit der Site
/ var / www und die Datenbank, die sich beispielsweise in
/ var / database befindet, als separate Subvolumes auswählen.
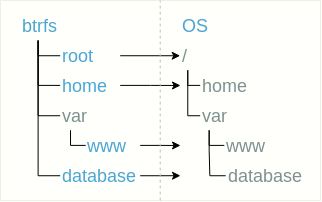
Der Einfachheit halber kann ein Teilvolumen in Verzeichnissen abgelegt werden, wie beispielsweise im Fall des Teilvolumens
var / www .
Bei diesem Ansatz muss das gesamte Subvolumen bereitgestellt werden. Das
Root- Sub muss einen Mount-Punkt / haben und darin die Verzeichnisse
home und
var enthalten .
Nach der Montage Wurzel in dem / home muss sabvolyum installiert werden zu Hause und im Verzeichnis / var / www und / var / databas ein e - sabvolyumy var / www und Datenbank ist.Somit kann der Baum von btrfs-subvolume willkürlich im virtuellen Dateisystem des Betriebssystems angezeigt werden, und dafür gibt es bereits genug.Vorteile:- Der Benutzer sieht nur das gemountete Subvolumen.
- Es ist einfach, den Subwoofer auszutauschen (einen abmontieren, den anderen montieren).
- leicht zu entfernender Subwoofer.
Nachteile:
- Es ist leicht zu verwechseln, wo es installiert werden soll.
- Für jedes Subvolume sollte ein Eintrag in fstab vorhanden sein. Wenn Snapshots „Rollbacks“ enthalten, müssen auch die entsprechenden Einträge in fstab aktualisiert werden.
Die verschachtelte Struktur des Subvolumes schlägt eine einfache Verwendung des Subvolumes anstelle einiger Verzeichnisse vor.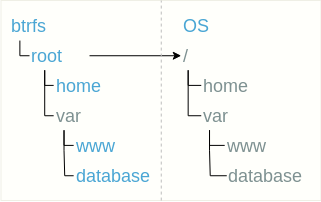 In diesem Fall muss zusätzlich zum Root-Subvolume nichts mehr gemountet werden.Vorteile:
In diesem Fall muss zusätzlich zum Root-Subvolume nichts mehr gemountet werden.Vorteile:- Alle Subvolumina sind sichtbar, die Struktur ist leicht wahrzunehmen,
- Sie müssen nichts erneut mounten, alles ist wie bei einem "normalen" Dateisystem.
Nachteile:
- Alle Subvolumes sind sichtbar, vielleicht möchten sich einige vor dem Benutzer verstecken.
- Es ist schwierig, das Subwolum zu entfernen / zu ersetzen (der Grund dafür sind verschachtelte Subwölfe).
Nun, der dritte Ansatz ist gemischt. Es beinhaltet eine Kombination der ersten beiden, um die Vorteile beider zu maximieren. Es ist jedoch möglich, dass dieser spezielle Ansatz zu einer komplexen, schwer zu ändernden, verwirrten Struktur mit einer großen Anzahl von Einträgen in fstab führt. Es hängt alles von der Nüchternheit des Systemadministrators ab.
Festplatte hinzufügen / entfernen, ausgleichen
btrfs bietet eine hervorragende Funktionalität - die Möglichkeit, Hot-Block-Geräte direkt während des Betriebs des Dateisystems hinzuzufügen: btrfs device add /path/to/device /path/to/btrfs
Oder löschen: btrfs device remove /path/to/device /path/to/btrfs
Übrigens können Sie in einem Add / Delete-Aufruf mehrere Festplatten angeben.Der angegebene Pfad ist wiederum der Pfad zu einem beliebigen Subvolume des BTRFS, auf das der Befehl angewendet wird.Lassen Sie uns überprüfen, wie viele und welche Blockgeräte von btrfs gesteuert werden: btrfs filesystem show /path/to/btrfs Label: none uuid: 52961dda-df84-4e2d-9727-e93e7738df81 Total devices 2 FS bytes used 192.00KiB devid 1 size 20.00GiB used 132.00MiB path /dev/sdc devid 2 size 50.00GiB used 0.00B path /dev/sdd
0,00B im verwendeten Feld gibt an , dass die hinzugefügte Festplatte leer ist. Um es mit Daten gemäß dem Aufzeichnungsprofil zu füllen, müssen Sie Folgendes ausgleichen: btrfs balance start /path/to/btrfs
Der Befehl balance verteilt Daten auf Datenträgern entsprechend dem ausgewählten Aufzeichnungsprofil neu. Im Fall von RAID1 führt der Saldo beispielsweise zum Klonen von Daten vom Originalgerät, im Fall von RAID0 zu einer gleichmäßigeren Verteilung von Daten auf zwei Festplatten usw.Infolge des Gleichgewichts werden die Daten auf der Platte dichter geschrieben, wenn zuvor Hohlräume auf der Platte vorhanden waren, d. H. Defragmentierung wird sich herausstellen. Es ist jedoch wichtig zu verstehen, dass dies nicht genau „diese“ Defragmentierung ist. In diesem Fall betrachtet der Befehl balance nicht den logischen Inhalt, sondern arbeitet nur mit Datenblöcken. Sie achtet nicht darauf, dass eine Datei auf der Festplatte verteilt ist. Stattdessen überträgt balance Datenblöcke von einem Ort zum anderen. Das heißt,
Eine zum Ausgleich fragmentierte Datei bleibt danach fragmentiert. Aber!
Die Fragmentierung auf der Ebene der Datenblöcke nimmt immer noch ab, und dies kann verwendet werden.Um Verwirrung zu vermeiden, sagen wir Folgendes: Die Balance- Operation reduziert die Fragmentierung auf der Ebene der Datenblöcke, hat jedoch keinen Einfluss auf die Dateifragmentierung.Der Befehl balance bietet auch die Möglichkeit, das Aufnahmeprofil zu ändern. Beispielsweise wurde das DUP-Profil auf der Festplatte verwendet, und nach dem Hinzufügen der Festplatte wurde beschlossen, RAID1 vollständig zu erstellen. Verwenden Sie dazu den Filter convert: btrfs balance start -dconvert=raid1 -mconvert=raid1 /path/to/btrfs
Mit den Optionen -dconvertund werden -mconvertneue Datensatzprofile für Daten bzw. Metadaten festgelegt. Es gibt auch die Option -sconvert, mit der das Systemdatenschreibprofil geändert werden kann. Sie müssen jedoch auch den Schalter -f (--force) hinzufügen, um den Vorgang zu erzwingen.Im Allgemeinen besteht der Hauptzweck von Filtern darin, die Regeln für den Ausgleichsvorgang festzulegen: Welche Blöcke müssen verarbeitet und welche nicht berührt werden. So können Sie beispielsweise nur Blöcke betreffen, die mit einem bestimmten Aufzeichnungsprofil (Filterprofile) aufgezeichnet wurden, oder Blöcke, die über einem bestimmten Prozentsatz belegt sind (Verwendungsfilter), oder nur Gruppen von Blöcken, die sich auf eine bestimmte Festplatte beziehen (Devid-Filter) usw. Sie können übrigens noch kombiniert werden. Im Allgemeinen sind die Funktionen von Filtern sehr umfangreich und hauptsächlich für die Durchführung eines selektiven Datenausgleichs erforderlich.Fragmentierung
Leider ist btrfs aufgrund seiner Architektur äußerst anfällig für Phänomene wie Fragmentierung. Tatsache ist, dass Daten immer an einen neuen Speicherort auf der Festplatte geschrieben werden. Selbst wenn Sie die Datei lesen, nichts mit den Daten tun und sie in dieselbe Datei zurückschreiben, werden die Daten in einen neuen Bereich auf der Festplatte verschoben. Das gleiche passiert, wenn Sie die Daten in der Datei nur teilweise aktualisieren - die Änderungen werden in einen neuen Bereich auf der Festplatte geschrieben. Daher werden häufige Fragmentdateien sehr stark geändert, wodurch die "Streuung" von Fragmenten im Allgemeinen über mehrere Festplatten erhöht wird. Dies führt zu einer erhöhten Belastung der CPU und einem unnötigen Speicherverbrauch. Am fragmentiertesten sind Datenbanken und Images von virtuellen Maschinen.Sie können die Dateifragmentierung mit dem Dienstprogramm filefrag auswerten (nicht in btrfs-progs enthalten). filefrag /path/to/your/file
Es zeigt die Anzahl der zum Speichern der Datei verwendeten Speicherbereiche. Einfach ausgedrückt: Je weniger Extents beteiligt sind, desto weniger fragmentiert ist die Datei.Es gibt zwei Methoden, um die Fragmentierung von btrfs zu bekämpfen: die Defragmentierung und die Flagge nocow.Die Defragmentierung kann auf eine einzelne Datei oder auf ein Subvolume / Verzeichnis angewendet werden, auch rekursiv. Der Befehl lautet wie folgt: btrfs filesystem defragment /path/to/file/or/dir
Ich muss sagen, dass dieses Team nicht immer zu den erwarteten Ergebnissen führt. Kleine, leicht fragmentierte Dateien (10 - 20 Bereiche) nach der Defragmentierung können in noch mehr Teile aufgeteilt werden. Darüber hinaus unterbricht die Defragmentierung von btrfs in einigen Versionen des Kernels die Deduplizierung von Dateien und macht sie zu echten physischen Kopien. Das heißt,
Schnappschüsse auf physischer Ebene werden zu vollständigen Kopien.Die zweite Möglichkeit, die Fragmentierung zu bekämpfen, besteht in einem Dateiattribut nocow. chattr +C /path/to/file
Das Attribut nocowkann nur auf eine neue oder leere Datei gesetzt werden. Der Mechanismus zum Kopieren beim Schreiben wird deaktiviert , sodass btrfs beim Aktualisieren des Inhalts einer Datei immer mit einem festen Festplattenbereich arbeitet und Daten über vorhandene (auf physischer Ebene) schreibt. Von den Minuspunkten von nocow wird auch die Überprüfung der Prüfsumme für diese Datei deaktiviert. Mit anderen Worten, keine Kuh - keine Prüfsumme.Stellen Sie das Attribut natürlich manuell einnocowJede Datei ist eine undankbare Aufgabe. Wenn dieses Flag des Verzeichnisses / Subvolumes gesetzt ist, erben alle darin erstellten neuen Dateien das Flag automatisch. Gleiches gilt für die erstellten verschachtelten Verzeichnisse. Wenn zu dem Zeitpunkt, als das Attribut aktiviert wurde, sich bereits Daten im Verzeichnis befanden, hat dies keine Auswirkungen auf sie. Das Attribut nocowkann nur auf eine neue oder leere Datei festgelegt werden.Eine andere Möglichkeit, das Flag automatisch zu setzen, nocowbesteht darin, das Dateisystem mit der folgenden Option bereitzustellen nodatacow: mount -o subvol=path/to/subvol,nodatacow /dev/sdXX /path/to/mountpoint
Diese Option bewirkt, dass die Option automatisch eine Verbindung herstellt nodatasum, sodass für neu erstellte Dateien keine Prüfsummen berechnet werden.Wie üblich gibt es eine Nuance: Sie können nicht nur einen Subwoofer mit einer Option montieren nocow. Entweder hat jedes Subvolumen eine Option nocowoder keine. Alles wird vom ersten gemounteten Subvolume entschieden: Wenn eine Option angegeben wurde nodatacow, werden alle nachfolgenden Mounts automatisch mit dieser Option ausgeführt.Ein nicht offensichtlicher Moment tritt auf, wenn Sie eine Datei mit einem Flag versehen nocowund den Snapshot aus dem Subvolume entfernen, in dem sich diese Datei befindet. In diesem Fall ignoriert btrfs das Flag, nocowwenn mehr als ein Subvolumen auf den aktualisierten Datenblock verweist. Daher trotz der Flaggenocow(Die Datei erbt sie übrigens auch im Snapshot.) Änderungen an den Dateien werden in einen neuen Bereich auf der Festplatte verschoben, und die Datei wird erneut fragmentiert. Wenn der Datenblock in der Datei mehrmals aktualisiert wird, fällt er beim ersten Mal in einen neuen Bereich auf der Festplatte, und bei nachfolgenden Einträgen wird er in diesem neuen Bereich "an Ort und Stelle" aktualisiert.Tricks und Misserfolge
Wenn Sie btrfs-progs verwenden, können Sie den vollständigen Namen des Befehls weglassen: btrfs sub cre = btrfs subvolume create
Es reicht nur das Zusammentreffen der ersten Zeichen, die den Befehl eindeutig bestimmen: su = subvolume, fi = filesystem, ba = balance, de = device;
Ich denke, das Prinzip ist klar.Leider kann btrfs keinen Snapshot des Verzeichnisses erstellen, aber es gibt eine Problemumgehung:Sie nocowkönnen das Attribut nicht auf eine vorhandene Datendatei festlegen. Sie können jedoch den folgenden Weg gehen:Wenn btrfs nicht mehr genügend Speicherplatz hat, kann selbst das Löschen einer Datei den Fehler "Kein Speicherplatz mehr auf dem Gerät" verursachen . Für die Lösung wird empfohlen, ein temporäres Laufwerk mit einer Größe von vorzugsweise mindestens 1 GB an btrfs anzuschließen. Bereinigen Sie dann die Daten. Entfernen Sie dann das temporäre Laufwerk.Die Balance- Operation , die ohne Angabe von Schreibprofilen aufgerufen wird, ändert sie implizit von dup in raid1 . Was übrigens auf der Gotchas- Seite steht . Dies geschieht nach dem Hinzufügen der Festplatte zu btrfs, das das Dup- Schreibprofil verwendet . Denken Sie daran, dass beim Formatieren eines einzelnen Laufwerks in btrfs das Standard- Dup- Profil für Metadaten und Systemdaten verwendet wird.Vielleicht das wichtigste
Vermeiden Sie das Erstellen von Klonen von Blockgeräten auf niedriger Ebene mit btrfs. Als „intelligentes“ Dateisystem liest btrfs bei einigen Vorgängen (meistens beim Mounten) die Systemdaten auf Blockgeräten erneut, um alle Teile des Dateisystems zu finden. Wenn im Suchvorgang zwei Blockgeräte mit denselben UUIDs gefunden werden, akzeptiert btrfs diese als Teil derselben Instanz. Wenn sich jedoch herausstellt, dass diese beiden Geräte das Original und sein Klon sind, weiß der Treiber nach dem Mounten allein, wie das Dateisystem funktioniert, aber es ist klar, dass dies nicht zu etwas Gutem führen wird. Im schlimmsten Fall führt dies zu einer irreversiblen Datenbeschädigung.Wenn Sie Festplatten wirklich auf einfache Weise mit btrfs klonen möchten, müssen Sie äußerst vorsichtig sein. Im Allgemeinen sollte ein Klon für den Betriebssystemkern nicht als Blockgerät sichtbar sein, solange das Original im System vorhanden ist, und umgekehrt. Unter dieser Bedingung können Sie die UUID des Klons ändern (gut oder das Original, hier optional). Das mit dem Paket btrfs-progs gelieferte Dienstprogramm btrfstune hilft dabei : btrfstune -u /path/to/device
Und noch einmal: btrfstune ist ein „intelligentes“ Dienstprogramm, das die UUID nicht nur auf der Festplatte, sondern im gesamten Dateisystem ändert. Dies bedeutet, dass sie beim Aufruf alle Blockgeräte liest, um die UUID auf allen Geräten zu ersetzen, die sich auf das Dateisystem beziehen.Anstelle einer Schlussfolgerung
Wenn Sie in diesem Moment nichts verstehen, ist dies normal. Btrfs ist nicht trivial und erliegt möglicherweise nicht sofort. Jedes Mal, wenn es mir so vorkam, als würde ich sie jetzt verstehen, warf sie eine Überraschung und ließ sie bestehende Dinge überdenken. Ich kann nicht sagen, dass ich im Moment alles verstanden habe - beim Schreiben habe ich etwas Neues gefunden, obwohl ich bereits aufgrund meiner Erfahrung geschrieben habe.Ich würde den Prozess des Mastering von btrfs mit dem Übergang von einem prozeduralen Programmierstil zu einem objektorientierten vergleichen. Der erste Eindruck ist "Wow, wie großartig", aber dann schreiben Sie beharrlich weiterhin prozeduralen Code, der in Klassen eingeschlossen ist.In dem Artikel habe ich versucht, kein Wasser zu gießen - um alles über den Fall zu schreiben. Trotzdem stellte sich heraus, dass es ziemlich umfangreich war. Aber bei weitem nicht alles war zu sagen - man kann immer noch über btrfs schreiben und schreiben. Dieser Artikel ist nur die Spitze des Eisbergs. Der Anfang besteht darin, seine Philosophie zu verstehen und sie zu nutzen. Und jetzt ist es Zeit zu enden.Vielen Dank für das Lesen bis zum Ende. Ich hoffe nicht müde. Schreiben Sie in die Kommentare, was Sie sonst noch wissen möchten.Machen Sie Backups, meine Herren. Und lassen Sie sie nie nützlich sein.