Die Geschichte der Bildoptimierung für Java-Anwendungen begann mit dem Spring-Blog-Artikel Spring Boot in a Container . Es wurden verschiedene Aspekte beim Erstellen von Docker-Images für Spring-Boot-Anwendungen erörtert, einschließlich eines so interessanten Problems wie der Reduzierung der Größe von Images. Für unsere Teams war dies aus mehreren Gründen relevant, daher haben wir beschlossen, diese Lösung auf unsere Anwendungen anzuwenden.
Wie so oft hat sich nicht alles beim ersten Mal gelöst, es gab Nuancen bei Projekten mit mehreren Modulen und den Versuch, all dies auf dem CI-System voranzutreiben. In diesem Artikel finden Sie eine Lösung für diese Probleme.
Ziel der Optimierung ist es, den Unterschied zwischen den resultierenden Bildern von Baugruppe zu Baugruppe zu verringern. Dies führt zu einem guten Ergebnis bei der kontinuierlichen Lieferung. Wenn Sie also die Größe des Bilds als solches minimieren möchten, können Sie auf andere Artikel auf dem Hub verweisen
Wenn Sie nicht erklären müssen, warum Sie etwas mit einer Multimeter-Startanwendung tun sollten, bevor Sie sie in das Image einfügen, können Sie sofort mit der Beschreibung des Optimierungsansatzes fortfahren . Wenn Sie den Artikel aus dem Frühjahrsblog kennengelernt haben, können Sie mit der Lösung der gefundenen Probleme fortfahren.
Warum ist das alles oder die Kehrseite des fetten Glases?
Standardmäßig ist das von Spring Boot erzeugte JAR eine ausführbare JAR-Datei, die den Anwendungscode und alle seine Abhängigkeiten enthält.
Der Vorteil dieses Ansatzes liegt auf der Hand: Es ist praktisch, mit einer Datei zu arbeiten. Sie enthält alles, was Sie zum Ausführen von java -jar <myapp>.jar benötigen. Dockerfile ist trivial und nicht von Interesse.
Der Nachteil ist ineffiziente Speicherung. In einer klassischen Boot-Anwendung spricht das Verhältnis von Code und Bibliotheken eindeutig nicht für unseren Code. Eine leere Anwendung mit einem Webpart und Bibliotheken für die Arbeit mit der Datenbank, die über start.spring.io generiert werden kann, benötigt beispielsweise 20 MB, von denen 98% Bibliotheken sind. Und dieses Verhältnis ändert sich während des Entwicklungsprozesses nicht wesentlich.
Wir erfassen die Anwendung jedoch mehrmals, jedoch regelmäßig auf dem CI-Server, und stellen sie dann in einer Reihe von Umgebungen bereit. Somit wachsen 10 Baugruppen bei 200 MB und 100 bei 2 GB, von denen Änderungen nur sehr wenig benötigen.
Es kann argumentiert werden, dass dies für die aktuellen Speicherkosten lächerliche Zahlen sind und Sie keine Zeit mit solchen Optimierungen verschwenden können, aber alles hängt von der Größe der Organisation und der Anzahl der Anwendungen ab, deren Bilder gespeichert werden müssen. Die Bereitstellungsbedingungen können auch stark motivieren: Wenn sich die Registrierung und der Server in der Nähe befinden, ist selbst ein Unterschied von 100 MB nicht sehr auffällig. In verteilten Systemen kann dies jedoch viel wichtiger sein, insbesondere wenn Sie in bestimmten Ländern wie China mit seiner Firewall und instabilen Kanälen bereitstellen müssen nach außen.
Wenn die Gründe herausgefunden sind, ist es Zeit zu optimieren.
Wir optimieren die Montage oder Was kann man dem Frühlingsblog entnehmen?
Der Artikel bietet eine vernünftige Lösung: Anstelle einer einzelnen Ebene, die mit dem COPY my-jar.jar app.jar generiert wird, müssen mehrere Ebenen erstellt werden.
Eine Ebene enthält Bibliotheken, die zweite ist unser eigener Code. Dazu müssen Sie die JAR-Datei entpacken und den Inhalt auf verschiedene Bildebenen kopieren.
Das Skript zum Vorbereiten der JAR-Datei sieht folgendermaßen aus:
Eine Docker-Datei mit einem mehrstufigen Build könnte folgendermaßen aussehen
FROM openjdk:8-jdk-alpine as build WORKDIR /wd COPY prepare_for_docker.sh /usr/local/bin/prepare_for_docker COPY target/demo.jar /wd/app.jar RUN prepare_for_docker /wd/app.jar FROM openjdk:8-jdk-alpine COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib COPY --from=build /wd/docker-dist/META-INF /app/META-INF COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]
In der ersten Phase kopieren wir alles, was wir brauchen, führen unser Skript aus, um die JAR-Datei zu entpacken, und in der zweiten Phase legen wir separate Bibliotheken und unseren Code separat in Ebenen an.
Es ist einfach, die Funktionsfähigkeit sicherzustellen:
- Zum ersten Mal sammeln
- Nehmen Sie Änderungen an unserem Code vor.
- Wir starten
docker build erneut und sehen die geschätzten Zeilen Using cache beim Kopieren des gesamten lib-Verzeichnisses
... Step 5/10 : RUN prepare_for_docker app.jar ---> Running in c8e422491eb2 Removing intermediate container c8e422491eb2 ---> c7dcec4ae18a Step 6/10 : FROM openjdk:8-jdk-alpine ---> a3562aa0b991 Step 7/10 : COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib ---> Using cache ---> 01b600d7e350 Step 8/10 : COPY --from=build /wd/docker-dist/META-INF /app/META-INF ---> Using cache ---> 5c0c03a3c8f1 Step 9/10 : COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ---> 5ffed6ee5696 Step 10/10 : ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"] ---> Running in 99957250fe5d Removing intermediate container 99957250fe5d ---> 6735799d9f32 Successfully built 6735799d9f32 Successfully tagged boot2-sample:latest
Eine naheliegende Möglichkeit, diesen Ansatz zu verbessern, besteht darin, ein kleines Basisimage mit einem Skript zu erstellen, um es nicht von Projekt zu Projekt zu ziehen. Dadurch wird die erste Schicht prägnanter.
FROM zeldigas/java-layered-builder as build COPY target/demo.jar app.jar RUN prepare_for_docker app.jar
Wir stellen die Lösung fertig
Wie bereits am Anfang des Artikels erwähnt, funktioniert die Lösung, aber während der Operation wurden einige Probleme gefunden, die später besprochen werden.
Nicht alle Dateien in lib gleichermaßen bibliothekarisch
Wenn Ihr Projekt aus mehreren Modulen besteht (zumindest gibt es Modul A, von dem Modul B abhängt, das als Federfettglas zusammengebaut ist) und eine Originallösung darauf anwendet, werden Sie feststellen, dass kein Layer-Caching auftritt. Was ist schief gelaufen?
Die Sache ist in zusätzlichen Modulen: Sie sind Quellen für ständige Änderungen für die Ebene, auch wenn Sie keine Änderungen am Modulcode vornehmen. Dies liegt an der Besonderheit, Maven-JAR-Dateien zu erstellen (bei Gradle ist die Situation etwas besser, aber nicht sicher). Die Aufgabe, reproduzierbare Artefakte zu erhalten, ist nicht das Thema dieses Artikels (obwohl dies natürlich interessant und erreichbar ist), daher werden wir zu einer ziemlich einfachen Lösung übergehen.
Wir verteilen den Inhalt von lib nach dem Entpacken in 2 Verzeichnisse und trennen die Projektmodule von anderen Bibliotheken. Lassen Sie uns das Skript zum Auspacken des fetten Glases fertigstellen:
Infolgedessen begann das Skript, die Übertragung zusätzlicher Parameter zu unterstützen (siehe 1 und 2). Wenn zusätzliche Argumente (3) übergeben werden, wird jedes von ihnen als Präfix für den Namen der Datei betrachtet, die wir (4) in ein separates Verzeichnis verschieben.
Dockerfile-Beispiel für ein Szenario mit einem zusätzlichen. shared-module und Version 1.0-SNAPSHOT
FROM openjdk:8-jdk-alpine as build COPY target/demo.jar /wd/app.jar RUN prepare_for_docker /wd/app.jar shared-module-1.0 FROM openjdk:8-jdk-alpine COPY --from=build /wd/docker-dist/BOOT-INF/lib /app/lib COPY --from=build /wd/docker-dist/app-lib /app/lib COPY --from=build /wd/docker-dist/META-INF /app/META-INF COPY --from=build /wd/docker-dist/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","com.example.demo.DemoApplication"]
Auf dem CI-Server ausführen
Nachdem wir alles lokal getestet und mit dem Ergebnis zufrieden waren, begannen wir mit der Ausführung auf dem CI-Server und stellten anhand der Build-Protokolle fest, dass kein Wunder eingetreten war oder die Ergebnisse nicht konstant waren: In einigen Fällen wurde das Caching durchgeführt und das nächste Mal waren alle Ebenen neu.
Infolgedessen wurde der Schuldige entdeckt - der Docker-Cache bzw. dessen Abwesenheit bei verschiedenen Agenten (unsere Baugruppe ist nicht an einen bestimmten Agenten des CI-Systems gebunden). Wie sich herausstellte, werden Ebenen mit einer anderen Prüfsumme aus demselben Dateisatz abgerufen, wenn sich keine geeigneten Ebenen im Docker-Cache befinden. Sie können dies lokal überprüfen, indem Sie den Build mit der Option --no-cache ausführen oder --no-cache zweites Mal erstellen, indem Sie zuerst das Image und alle Zwischenebenen löschen. Als Ergebnis erhalten Sie eine völlig andere Prüfsummenebene, die alle vorherigen Bemühungen negiert.

Es gibt verschiedene Möglichkeiten, um das Problem zu lösen:
- Wenn Ihr CI-System dies sofort unterstützt (z. B. hat Circle CI im Plan-Teil eine integrierte Unterstützung für den gemeinsam genutzten Cache während Assemblys).
- Mischen eines Abschnitts mit einem Docker-Cache zwischen Agenten
- Nutzen Sie den integrierten Cache-Management-Docker (
--cache-from )
Wir sind den dritten Weg gegangen, da es in unserem Fall der einfachste war. Mit dieser Option können Sie dem Docker-Daemon mitteilen, welche Images berücksichtigt werden sollen, und versuchen, sie während der Assembly für das Caching zu verwenden. Sie können so viele Bilder angeben, wie Sie für erforderlich halten. Hauptsache, sie befinden sich im Dateisystem. Wenn das angegebene Image nicht vorhanden ist, wird es einfach ignoriert, sodass Sie es vor dem Erstellen ziehen müssen.
So sieht die Container-Baugruppe mit diesem Ansatz aus:
set -e version=...
Wir versuchen, Ebenen nur aus dem neuesten Image wiederzuverwenden, was oft genug ist, aber niemand stört sich daran, komplexere Logik aufzuwickeln und einige Versionen zurückzuverfolgen oder sich auf die ID von vcs-Commits zu verlassen.
Wir passen diesen Ansatz an die Funktionen Ihres CI an und erhalten eine zuverlässige Wiederverwendung von Ebenen mit Bibliotheken.
Insgesamt
Die Lösung zeigt gute Ergebnisse, insbesondere bei Projekten mit einem aktiven Entwicklungsstadium und einer optimierten CD-Pipeline. Die folgende Grafik zeigt das Ergebnis der Anwendung der Optimierung auf eine der Anwendungen. Es ist deutlich zu sehen, dass sich das lineare Wachstum ab der 70. Baugruppe zu krampfhaft verändert hat (Fehler in den 60er Jahren hängen genau mit den Debugging-Arbeiten an Build-Agenten zusammen). Emissionen nach sind mit der Aktualisierung des Basisimages (hoch) und der Bibliotheken (niedriger) verbunden.
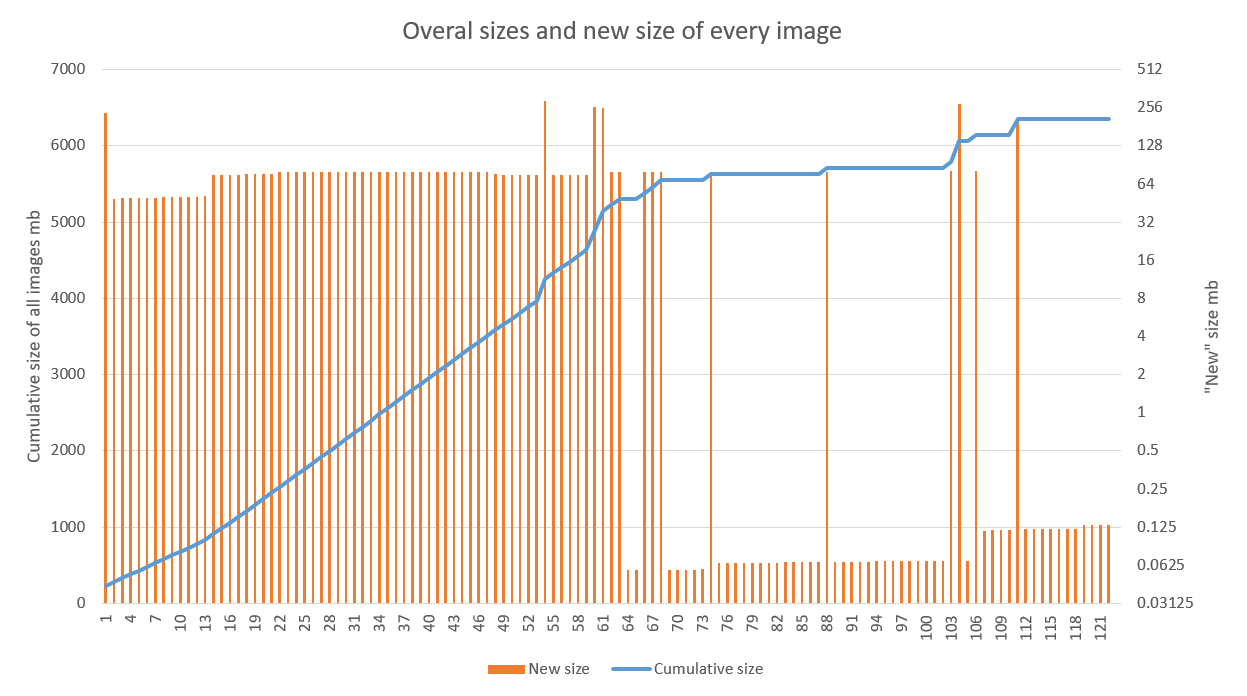
Die Speicheroptimierung ist in unserem Fall ein angenehmer, aber eher sekundärer Bonus. Viel erfreulicher ist die Beschleunigung der Bereitstellung der neuen Version gegenüber der alten in mehreren Regionen.
Es sollte beachtet werden, dass diese Technik durchaus mit anderen Ansätzen kompatibel ist, die darauf abzielen, die Größe eines einzelnen Bildes zu reduzieren (alpine und andere leichte Grundbilder, benutzerdefinierte Laufzeit für die Anwendung). Die Hauptsache ist, die allgemeinen Regeln für das Zusammenstellen des Bildes in Bezug auf das Caching zu befolgen und sicherzustellen, dass das Ergebnis reproduzierbar ist.