Toloka ist die größte Quelle für maschinell markierte Daten für maschinelle Lernaufgaben. Jeden Tag produzieren in Tolok Zehntausende von Künstlern mehr als 5 Millionen Bewertungen. Für alle Forschungen und Experimente im Zusammenhang mit maschinellem Lernen werden große Mengen an Qualitätsdaten benötigt. Aus diesem Grund veröffentlichen wir offene Datensätze für die akademische Forschung in verschiedenen Fachgebieten.
Heute werden wir Links zu den ersten öffentlichen Datensätzen teilen und darüber sprechen, wie sie zusammengestellt wurden. Wir zeigen Ihnen auch, wo Sie den Namen unserer Plattform betonen können.
Eine interessante Tatsache: Je komplexer die Technologie der künstlichen Intelligenz ist, desto mehr braucht sie menschliche Hilfe. Menschen kategorisieren Bilder, um Computer Vision zu trainieren. Menschen bewerten die Relevanz von Seiten für Suchanfragen. Menschen wandeln Sprache in Text um, sodass der Sprachassistent das Verstehen und Sprechen lernt. Die Maschine benötigt menschliche Bewertungen, damit sie ohne Menschen weiter und besser als Menschen funktioniert.
Bisher haben viele Unternehmen solche Bewertungen ausschließlich mit Hilfe speziell geschulter Mitarbeiter - Gutachter - gesammelt. Im Laufe der Zeit gab es jedoch zu viele Aufgaben im Bereich des maschinellen Lernens, und zum größten Teil erforderten die Aufgaben selbst keine besonderen Kenntnisse und Erfahrungen mehr. Es gab also eine Nachfrage nach der Hilfe der "Menge" (Menge). Aber nicht jeder kann alleine eine große Anzahl zufälliger Darsteller finden und mit ihnen arbeiten. Crowdsourcing-Plattformen lösen dieses Problem.
Yandex.Toloka (so richtig ausgesprochen, mit Schwerpunkt auf der letzten Silbe) ist eine der größten Crowdsourcing-Plattformen der Welt. Wir haben mehr als 4 Millionen registrierte Benutzer. Mehr als 500 Projekte sammeln mit unserer Hilfe täglich Bewertungen. Angenehme Tatsache: In diesem Jahr erwähnten alle sechs Redner verschiedener Unternehmen Toloka im Bereich Datenkennzeichnung auf der Data Fest-Konferenz als Quelle für Aufschläge für ihre Projekte.
Es wurde viel über die Verwendung von Toloka im Geschäftsleben gesagt. Heute werden wir über unseren anderen Bereich sprechen, den wir für nicht weniger nützlich halten.
Forschung in Tolok
Crowdsourcing und im Allgemeinen die Aufgabe, menschliche Markups in Massen zu sammeln, entsprechen in etwa der industriellen Anwendung des maschinellen Lernens. Dies ist ein Bereich, für den alle Technologieunternehmen viel Geld ausgeben. Gleichzeitig war sie aus irgendeinem Grund in Bezug auf die Forschung stark unterinvestiert: Im Gegensatz zu anderen Bereichen der ML gab es relativ wenige ernsthafte Studien und Artikel zur Arbeit mit Menschenmengen.
Das möchten wir ändern. Unser Team sieht in Toloka nicht nur ein Werkzeug zur Lösung angewandter Probleme, sondern auch eine Plattform für wissenschaftliche Forschung in verschiedenen Themenbereichen.
Toloka Öffentliche Datensätze
Wir wollen die wissenschaftliche Gemeinschaft unterstützen und Forscher für die Toloka gewinnen. Deshalb beginnen wir, Datensätze für nichtkommerzielle, akademische Zwecke zu veröffentlichen. Sie können für Forscher aus verschiedenen Richtungen von Interesse sein: Hier finden Sie Chat-Bots und Daten zum Testen von Modellen zur Aggregation von Urteilen von Tolkern, zur Sprachforschung und für Aufgaben des Computer-Sehens. Reden wir über sie:
Toloka Persona Chat RusEin Datensatz von 10.000 Dialogen wird Forschern von Dialogsystemen helfen, Ansätze für das Training von Chat-Bots zu erarbeiten. Wir haben es zusammen mit
iPavlov vorbereitet, einem Projekt des Labors für neuronale Systeme und tiefes Lernen am MIPT, das auf dem Gebiet der künstlichen Intelligenz im Gespräch forscht und
DeepPavlov entwickelt, eine offene Bibliothek zur Erstellung interaktiver Assistenten. Der Persona Chat Rus-Datensatz enthält Profile, die die Persönlichkeit einer Person beschreiben, sowie Dialoge zwischen Studienteilnehmern.
Wie Daten gesammelt wurdenIn der ersten Phase haben wir mithilfe von Toloka-Benutzern Profile gesammelt, die Informationen über eine Person, ihre Hobbys, ihren Beruf, ihre Familie und ihre Lebensereignisse enthalten, und diejenigen ausgewählt, die für Dialoge geeignet sind.
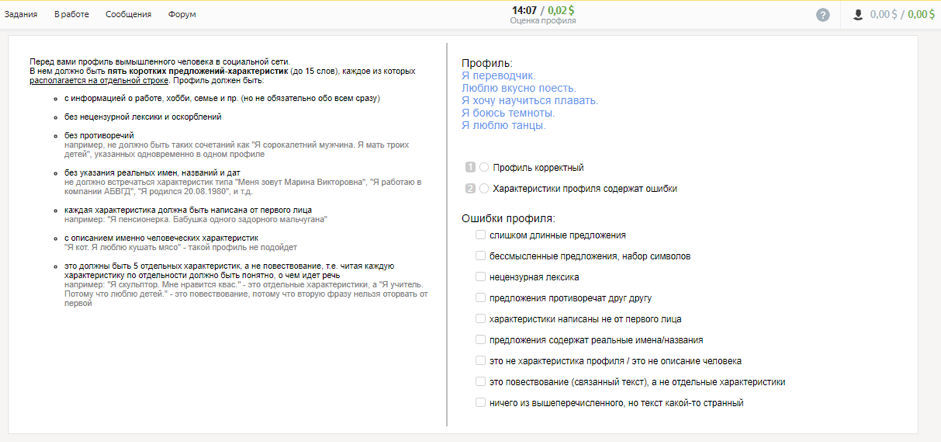
In der zweiten Phase haben wir die Teilnehmer eingeladen, die Rolle der in einem dieser Profile beschriebenen Person zu spielen und im Messenger miteinander zu kommunizieren. Der Zweck des Dialogs ist es, mehr über den Gesprächspartner zu erfahren und über sich selbst zu erzählen. Die resultierenden Dialoge wurden von anderen Darstellern überprüft.

Relevanz der Toloka-Aggregation 2Mit Dataset können Sie Qualitätskontrollmethoden im Crowdsourcing untersuchen. Es enthält fast eine halbe Million anonymer Bewertungen von Darstellern, die 2016 im Rahmen des Projekts „Relevanz (2 Abstufungen)“ gesammelt wurden. Hier finden Sie sowohl anonymisierte Bewertungen von Tolokern als auch Referenzbewertungen, mit deren Hilfe die Qualität der Antworten gemessen werden kann. Die Untersuchung dieser Daten ermöglicht es uns zu verfolgen, wie sich die Meinungen der ausübenden Künstler auf die Qualität der endgültigen Bewertung auswirken, welche Methoden zur Aggregation der Ergebnisse besser anzuwenden sind und wie viele Meinungen gesammelt werden müssen, um eine verlässliche Antwort zu erhalten.
Wie Daten gesammelt wurdenDem Auftragnehmer wurden eine Anfrage und die Region des Benutzers, der sie festgelegt hat, ein Screenshot des Dokuments und ein Link dazu, die Möglichkeit zur Verwendung von Suchmaschinen und Antwortoptionen angeboten: „Relevant“, „Nicht relevant“, „Nicht angezeigt“.
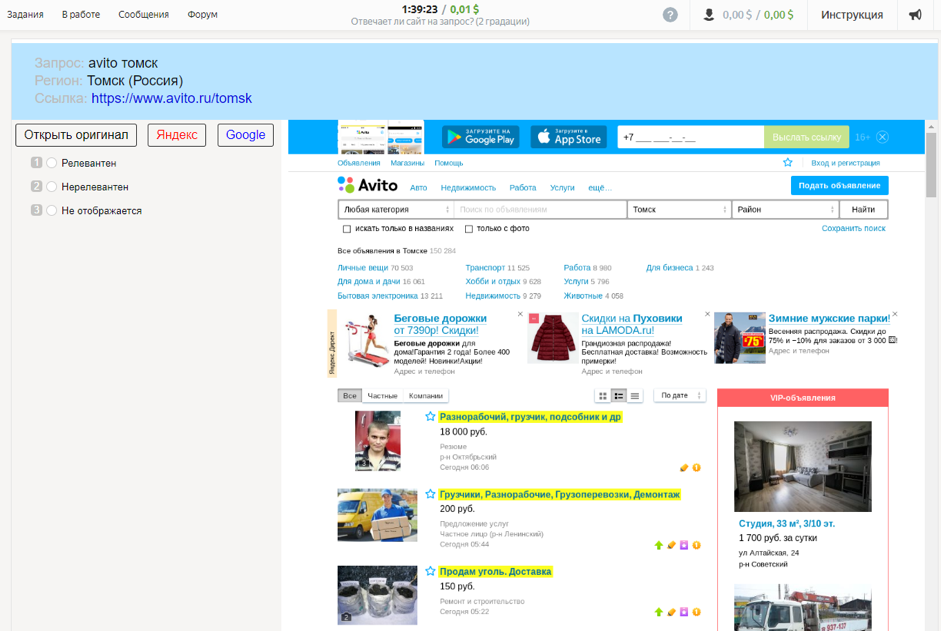
Toloka-Aggregationsrelevanz 5Dieser Datensatz ist derselbe wie der vorherige, nur Schätzungen wurden hier nicht auf einer binären, sondern auf einer Fünf-Punkte-Skala im Projekt „Relevanz (5 Abstufungen)“ gesammelt. Der Datensatz enthält mehr als eine Million Bewertungen.
Wie Daten gesammelt wurdenDie Bewertung von Dokumenten für fünf Klassen ist komplexer und erfordert mehr Qualifikationen. Dem Auftragnehmer wurden die Anfrage und die Region des Benutzers, der sie festgelegt hat, ein Screenshot des Dokuments und ein Link dazu, Schaltflächen für die Verwendung von Suchmaschinen und fünf Antwortoptionen angeboten: "Vital", "Nützlich", "Relevant +", "Relevant -", "Irrelevant".

Der Hauptindikator für die Qualität ist die Genauigkeit der aggregierten Antworten, die auf der Grundlage von Kontrollaufgaben (Goldensets) geschätzt werden. Einige Aufgaben im Datensatz haben nicht eine, sondern mehrere richtige Antworten. Jede dieser Antworten wird als richtig angesehen. Genauigkeit der wichtigsten Aggregationsmethoden:
● Die Mehrheitsmeinung beträgt 89,92%.
● Dawid-Skene - 90,72%.
● GLAD - 90,16%.
Lexikalische Beziehungen aus der Weisheit der Menge (LRWC)Der Datensatz enthält die Meinungen von Muttersprachlern der russischen Sprache zur Beziehung zwischen Gattung und Art zwischen Wörtern: die Verbindung zwischen dem Allgemeinen (Hyperonym) und dem Privaten (Hyponym). Gesammelt vom Forscher Dmitry Ustalov im Jahr 2017.
Wie Daten gesammelt wurdenFür die Studie wurden 300 der in modernen russischen Substantiven am häufigsten verwendeten verwendet. Unter Verwendung von Thesauri (RuTez, RuWordNet) und automatisierten Methoden zur Bildung von Hyperonymen (Watset, Hyperstar) wurden 10.600 Gattungsartenpaare (vom Typ "Kätzchen" - "Säugetier") erhalten. Die Teilnehmer der Studie mussten die Frage beantworten: „Stimmt es, dass ein Kätzchen eine Säugetierart ist?“ Um die Frage richtig zu formulieren, wurden Hyperonyme mit einem morphologischen Analysator und einem Pymorphie2-Generator in den Genitiv eingefügt.
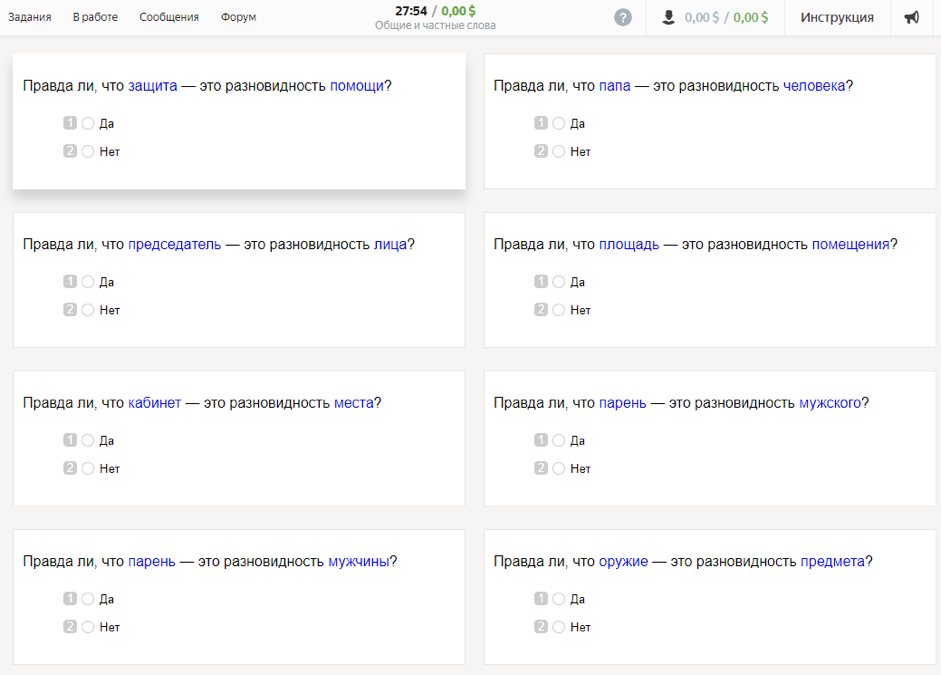
Jedes Paar wurde von sieben russischsprachigen Künstlern über 20 Jahren ausgezeichnet. Nach den Ergebnissen, die nach Aggregation aller Schätzungen erhalten wurden, erhielten 4576 Wortpaare positive und 6024 negative Antworten. Interessanterweise waren sich die Studienteilnehmer bei der Auswahl einer negativen Antwort eher einig als einer positiven.
Vom Menschen kommentierte sinnesdisambiguierte Wortkontexte für RussischDer Datensatz enthält 2562 kontextbezogene Bedeutungen von 20 Wörtern, die die größte Vielfalt semantischer Bedeutungen darstellen. Die Studie wurde 2017 von Dmitry Ustalov durchgeführt.
Wie Daten gesammelt wurdenDen Studienteilnehmern wurde das Wort und ein Beispiel für seine Verwendung in der Sprache gezeigt. Es war notwendig, die Bedeutung des Wortes im Kontext der Äußerung zu bestimmen und eine der Antwortoptionen zu wählen.

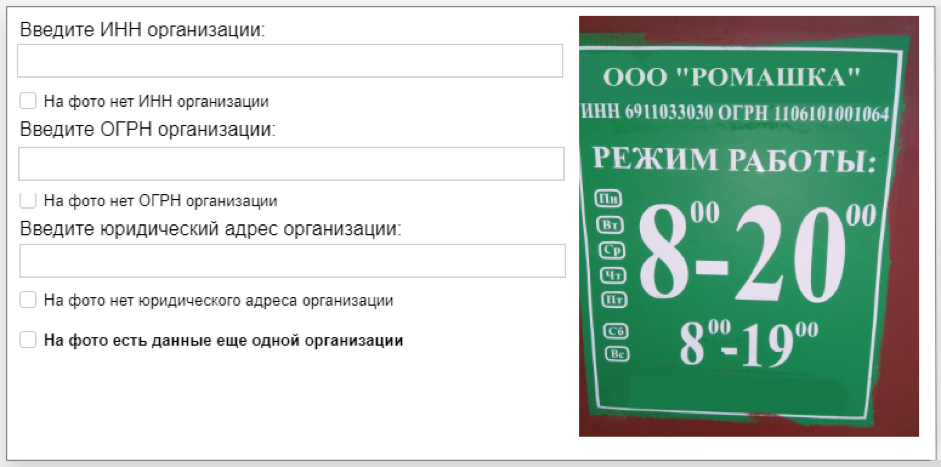
Toloka Business ID ErkennungFür diesen Datensatz haben wir 10.000 Fotos von Informationstafeln von Organisationen und eine Textdatei mit Nummern (TIN und PSRN) erstellt, die auf der Tafel angegeben sind. Nachdem das Computer-Vision-Modell aus diesen Daten gelernt hat, kann es die Zahlenfolge im Bild erkennen. Der Datensatz wird vom Yandex.Directory-Dienst bereitgestellt.
Wie Daten gesammelt wurdenZuerst haben wir die Aufgabe in der mobilen Anwendung Toloka gestartet: Die Darsteller wurden eingeladen, zu der auf der Karte angegebenen Adresse zu kommen, die Organisation zu finden und ein Foto des Informationsschilds zu machen. Diese und andere Feldaufgaben helfen dabei, aktuelle Informationen in Yandex.Directory zu verwalten.
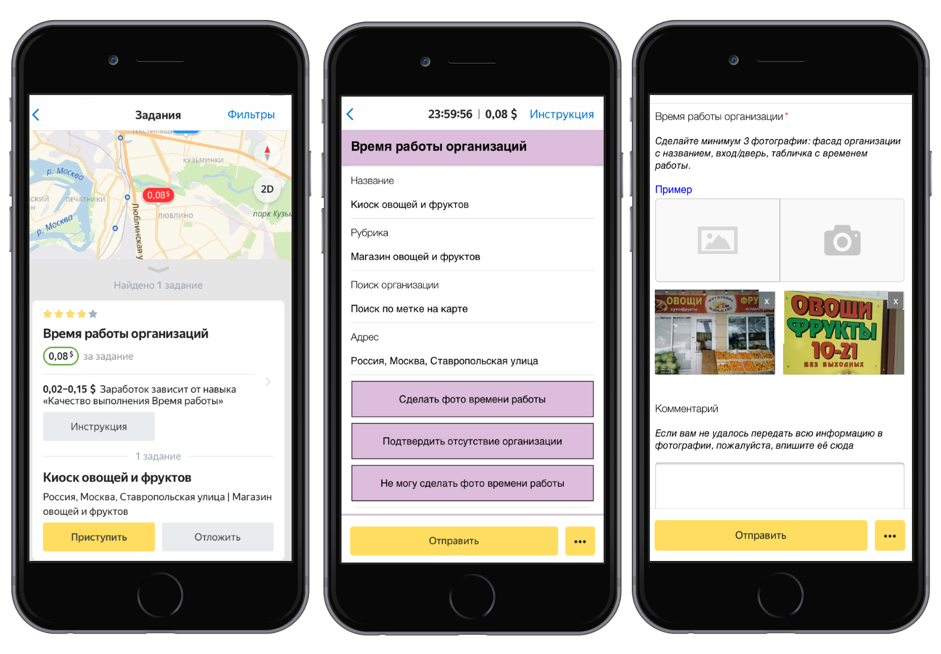
Dann wurde die Qualität der erledigten Aufgaben von anderen Darstellern überprüft. Wir haben die Fotos mit TIN und PSRN zur Entschlüsselung geschickt. Tolokers druckte diese Zahlen aus Fotos nach, woraufhin wir die Ergebnisse verarbeiteten und einen Datensatz bildeten.
Toloka AggregationsmerkmaleDer Datensatz enthält ungefähr 60.000 Bewertungen in 1000 Aufgaben mit den richtigen Antworten für fast alle Aufgaben. Künstler klassifizierten Websites entsprechend der Verfügbarkeit von Inhalten für Erwachsene in fünf Kategorien. Zusätzlich zu jeder Aufgabe sind 52 reelle Indikatoren beigefügt, anhand derer die Kategorie vorhergesagt werden kann.
Sie können Datensätze über den folgenden Link auswählen und herunterladen:
https://toloka.yandex.ru/datasets/ . Wir haben nicht vor, darauf einzugehen, und fordern die Forscher auf, auf Crowdsourcing zu achten und über ihre Projekte zu sprechen.