(erster Teil hier: https://habr.com/en/post/456446/ )
Ceph
Einführung
Da das Netzwerk eines der Schlüsselelemente von Ceph ist und in unserem Unternehmen ein wenig spezifisch ist, werden wir Ihnen zunächst ein wenig darüber erzählen.
Es wird viel weniger Beschreibungen von Ceph selbst geben, hauptsächlich eine Netzwerkinfrastruktur. Es werden nur Ceph-Server und einige Funktionen von Proxmox-Virtualisierungsservern beschrieben.
Also: Die Netzwerktopologie selbst ist als Leaf-Spine aufgebaut. Die klassische dreistufige Architektur ist ein Netzwerk, in dem Core (Core-Router), Aggregation (Aggregation-Router) und direkt mit Access- Clients (Access-Router) verbunden sind:
Drei-Ebenen-Schema
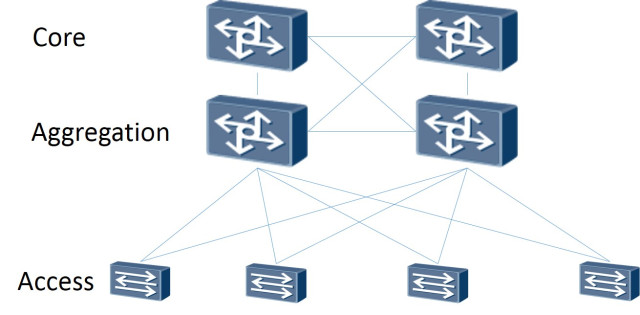
Die Leaf-Spine-Topologie besteht aus zwei Ebenen: Spine (grob gesagt der Hauptrouter) und Leaf (Zweige).
Zwei-Ebenen-Schema

Das gesamte interne und externe Routing basiert auf BGP. Das Hauptsystem für Zugriffskontrolle, Ansagen und mehr ist XCloud.
Server für die Kanalreservierung (und auch für deren Erweiterung) sind mit zwei L3-Switches verbunden (die meisten Server sind mit Leaf-Switches verbunden, einige Server mit erhöhter Netzwerklast sind jedoch direkt mit dem Spine des Switch verbunden) und geben über BGP ihre Unicast-Adresse bekannt. sowie eine Anycast-Adresse für den Dienst, wenn mehrere Server den Dienstverkehr bedienen und der ECMP-Ausgleich für sie ausreicht. Eine separate Funktion dieses Schemas, mit der wir Adressen sparen konnten, aber auch Ingenieure mit der IPv6-Welt vertraut machen mussten, war die Verwendung des nicht nummerierten BGP-Standards basierend auf RFC 5549. Für einige Zeit wurde Quagga für Server in BGP in diesem Schema für Server und regelmäßig verwendet Es gab Probleme mit dem Verlust von Festen und Konnektivität. Nach dem Wechsel zu FRRouting (dessen aktive Mitwirkende unsere Anbieter von Netzwerkgeräten sind: Cumulus und XCloudNetworks) haben wir solche Probleme nicht mehr beobachtet.
Der Einfachheit halber nennen wir dieses gesamte allgemeine Schema eine "Fabrik".
Suche nach einem Weg
Konfigurationsoptionen für das Clusternetzwerk:
1) Zweites Netzwerk auf BGP
2) Das zweite Netzwerk auf zwei separaten gestapelten Switches mit LACP
3) Zweites Netzwerk auf zwei separaten isolierten Switches mit OSPF
Tests
Die Tests wurden in zwei Arten durchgeführt:
a) Netzwerk mit den Dienstprogrammen iperf, qperf, nuttcp
b) interne Tests Ceph Ceph-Gobench, Rados Bench, erstellt rbd und getestet auf ihnen mit dd in einem oder mehreren Threads, mit fio
Alle Tests wurden auf Testmaschinen mit SAS-Festplatten durchgeführt. Die Zahlen zur rbd-Leistung wurden nicht sehr genau betrachtet, sondern nur zum Vergleich herangezogen. Interessiert an Änderungen je nach Art der Verbindung.
Erste Option
Netzwerkkarten werden an das werkseitig konfigurierte BGP angeschlossen.
Die Verwendung dieses Schemas für das interne Netzwerk wurde nicht als die beste Wahl angesehen:
Erstens die überschüssige Anzahl von Zwischenelementen in Form von Schaltern, die eine zusätzliche Latenzzeit ergeben (dies war der Hauptgrund).
Zweitens verwendeten sie zunächst, um die Statik über s3 zu übertragen, eine Anycast-Adresse, die auf mehreren Computern mit Radosgateway ausgelöst wurde. Dies führte dazu, dass der Verkehr von Front-End-Maschinen zu RGW nicht gleichmäßig verteilt wurde, sondern auf dem kürzesten Weg weitergeleitet wurde - das heißt, Front-End-Nginx wandte sich immer an denselben Knoten mit RGW, der mit dem mit ihm geteilten Blatt verbunden war (dies war natürlich der Fall) nicht das Hauptargument - wir haben uns einfach später von Anycast-Adressen geweigert, statisch zurückzugeben). Aus Gründen der Reinheit des Experiments beschlossen sie jedoch, Tests mit einem solchen Schema durchzuführen, um Daten zum Vergleich zu erhalten.
Wir hatten Angst, Tests für die gesamte Bandbreite durchzuführen, da die Fabrik von Prod-Servern genutzt wird. Wenn wir die Verbindungen zwischen Blatt und Wirbelsäule blockieren, würde dies einen Teil des Umsatzes beeinträchtigen.
Tatsächlich war dies ein weiterer Grund, ein solches System abzulehnen.
Iperf-Tests mit einer BW-Grenze von 3 Gbit / s von 1, 10 und 100 Streams wurden zum Vergleich mit anderen Schemata verwendet.
Tests zeigten die folgenden Ergebnisse:
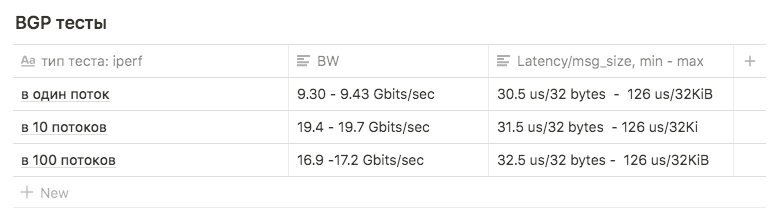
in 1 Stream ungefähr 9,30 - 9,43 Gbit / s (in diesem Fall steigt die Anzahl der erneuten Übertragungen stark auf 39148 ). Die Zahl, die nahe am Maximum einer Schnittstelle liegt, legt nahe, dass eine der beiden verwendet wird. Die Anzahl der erneuten Übertragungen beträgt ungefähr 500-600.
10 Streams mit 9,63 Gbit / s pro Schnittstelle, während die Anzahl der erneuten Übertragungen auf durchschnittlich 17045 anstieg.
In 100 Threads war das Ergebnis schlechter als in 10 , während die Anzahl der erneuten Übertragungen geringer ist: Der Durchschnittswert beträgt 3354
Zweite Option
Lacp
Es gab zwei Juniper EX4500-Schalter. Sie sammelten sie auf dem Stapel, verbanden den Server mit den ersten Links zu einem Switch, den zweiten zum zweiten.
Der anfängliche Verbindungsaufbau war wie folgt:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
Die iperf- und qperf-Tests zeigten Bw bis zu 16 Gbit / s. Wir haben uns entschieden, verschiedene Mod-Typen zu vergleichen:
rr, balance-xor und 802.3ad. Wir haben auch verschiedene Arten von Hashing Layer2 + 3 und Layer3 + 4 verglichen (in der Hoffnung, einen Vorteil beim Hash-Computing zu erzielen).
Wir haben auch die Ergebnisse für verschiedene sysctl-Werte der Variablen net.ipv4.fib_multipath_hash_policy verglichen (nun, wir haben ein wenig mit net.ipv4.tcp_congestion_control gespielt , obwohl es nichts mit Bonding zu tun hat. Es gibt einen guten ValdikSS-Artikel zu dieser Variablen)).
Bei allen Tests gelang es jedoch nicht, den Schwellenwert von 18 Gbit / s zu überschreiten (diese Zahl wurde mit balance-xor und 802.3ad erreicht , es gab keinen großen Unterschied zwischen den Testergebnissen), und dieser Wert wurde "im Sprung" durch Bursts erreicht.
Dritte Option
OSPF
Um diese Option zu konfigurieren, wurde LACP von den Switches entfernt (das Stapeln wurde beibehalten, aber nur für die Verwaltung verwendet). Auf jedem Switch haben wir ein separates VLAN für eine Gruppe von Ports gesammelt (mit Blick auf die Zukunft, dass sowohl QA- als auch PROD-Server in denselben Switches stecken bleiben).
Konfigurierte zwei flache private Netzwerke für jedes VLAN (eine Schnittstelle pro Switch). Zu diesen Adressen kommt die Ankündigung einer weiteren Adresse aus dem dritten privaten Netzwerk, dem Clusternetzwerk für CEPH.
Da das öffentliche Netzwerk (über das wir SSH verwenden) mit BGP funktioniert, haben wir frr verwendet, um OSPF zu konfigurieren, das sich bereits auf dem System befindet.
10.10.10.0/24 und 20.20.20.0/24 - zwei flache Netzwerke an den Switches
172.16.1.0/24 - Netzwerk zur Ankündigung
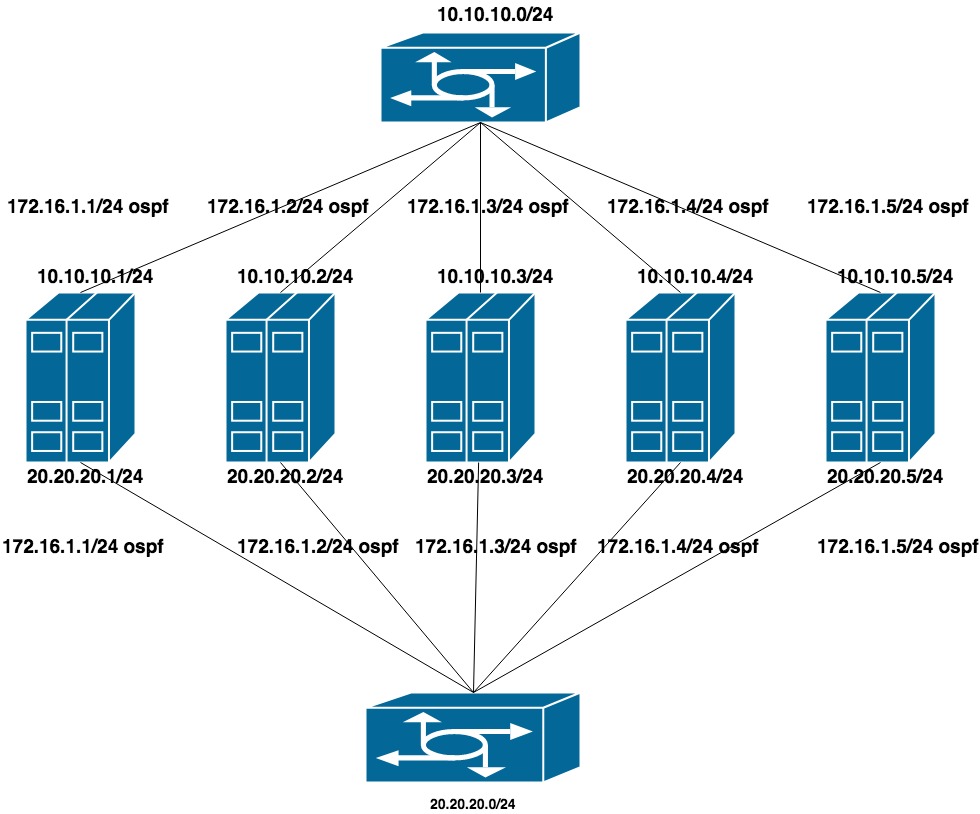
Maschineneinrichtung:
Schnittstellen ens1f0 ens1f1 betrachten ein privates Netzwerk
Schnittstellen ens4f0 ens4f1 betrachten das öffentliche Netzwerk
Die Netzwerkkonfiguration auf dem Computer sieht folgendermaßen aus:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
Frr-Konfigurationen sehen folgendermaßen aus:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
Bei diesen Einstellungen testen das Netzwerk iperf, qperf usw. zeigten eine maximale Auslastung beider Kanäle bei 19,8 Gbit / s, während die Latenz auf 20 us abfiel
Bgp-Router-ID- Feld : Wird verwendet, um den Knoten bei der Verarbeitung von Routing-Informationen und beim Erstellen von Routen zu identifizieren. Wenn in der Konfiguration nicht angegeben, wird eine der Host-IP-Adressen ausgewählt. Verschiedene Hersteller von Hardware und Software haben möglicherweise unterschiedliche Algorithmen. In unserem Fall hat FRR die größte Loopback-IP-Adresse verwendet. Dies führte zu zwei Problemen:
1) Wenn wir versucht haben, eine andere Adresse (z. B. privat aus dem Netzwerk 172.16.0.0) als die aktuelle Adresse aufzuhängen, führte dies zu einer Änderung der Router-ID und dementsprechend zu einer Neuinstallation der aktuellen Sitzungen. Dies bedeutet eine kurze Pause und einen Verlust der Netzwerkkonnektivität.
2) Wenn wir versucht haben, eine von mehreren Computern gemeinsam genutzte Anycast-Adresse aufzulegen, die als Router-ID ausgewählt wurde , wurden zwei Knoten mit derselben Router-ID im Netzwerk angezeigt .
Teil 2
Nach dem Testen der Qualitätssicherung haben wir begonnen, den Kampf gegen Ceph zu verbessern.
NETZWERK
Wechsel von einem Netzwerk zu zwei
Der Cluster-Netzwerkparameter ist einer der Parameter, die nicht im laufenden Betrieb geändert werden können, indem das OSD über ceph tell osd angegeben wird. * Injectargs. Das Ändern in der Konfiguration und das Neustarten des gesamten Clusters ist eine tolerierbare Lösung, aber ich wollte wirklich nicht einmal eine kleine Ausfallzeit haben. Es ist auch unmöglich, ein OSD mit einem neuen Netzwerkparameter neu zu starten - irgendwann hätten wir zwei Halbcluster gehabt - alte OSDs im alten Netzwerk, neue im neuen. Glücklicherweise ist der Cluster-Netzwerkparameter (und übrigens auch public_network) eine Liste, dh Sie können mehrere Werte angeben. Wir haben uns entschlossen, schrittweise umzuziehen - fügen Sie zuerst ein neues Netzwerk zu den Konfigurationen hinzu und entfernen Sie dann das alte. Ceph geht die Liste der Netzwerke nacheinander durch - OSD beginnt zuerst mit dem zuerst aufgelisteten Netzwerk zu arbeiten.
Die Schwierigkeit bestand darin, dass das erste Netzwerk über bgp funktionierte und mit einem Switch verbunden war, und das zweite - mit ospf und mit anderen, die nicht physisch mit dem ersten verbunden waren. Zum Zeitpunkt des Übergangs war ein vorübergehender Netzwerkzugriff zwischen den beiden Netzwerken erforderlich. Die Besonderheit beim Einrichten unserer Factory war, dass ACLs nicht im Netzwerk konfiguriert werden können, wenn sie nicht in der Liste der angekündigten ACLs enthalten sind (in diesem Fall handelt es sich um „externe“ ACLs, und ACLs können nur extern erstellt werden. Sie wurden auf Spanien erstellt, sind jedoch nicht angekommen auf Blättern).
Die Lösung war eine Krücke, kompliziert, aber es funktionierte: das interne Netzwerk über bgp gleichzeitig mit ospf zu bewerben.
Die Übergangssequenz ist wie folgt:
1) Konfigurieren Sie das Clusternetzwerk für ceph in zwei Netzwerken: über bgp und über ospf
In frr configs war es nicht notwendig, irgendetwas zu ändern, eine Zeile
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
Es schränkt uns nicht in den angekündigten Adressen ein, die Adresse für das interne Netzwerk selbst wird auf der Loopback-Schnittstelle angehoben, es hat gereicht, den Empfang der Ansage dieser Adresse auf den Routern zu konfigurieren.
2) Fügen Sie der ceph.conf- Konfiguration ein neues Netzwerk hinzu
cluster network = 172.16.1.0/24, 55.66.77.88/27
Starten Sie das OSD nacheinander neu, bis alle Benutzer zum Netzwerk 172.16.1.0/24 wechseln.
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3) Dann entfernen wir das überschüssige Netzwerk aus der Konfiguration
cluster network = 172.16.1.0/24
und wiederholen Sie den Vorgang.
Das ist alles, wir sind reibungslos in ein neues Netzwerk umgezogen.
Referenzen:
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench