In diesem Artikel werde ich darüber sprechen, wie sich das Projekt, in dem ich arbeite, von einem großen Monolithen in eine Reihe von Mikrodiensten verwandelt hat.
Das Projekt begann seine Geschichte vor langer Zeit, Anfang 2000. Die ersten Versionen wurden in Visual Basic 6 geschrieben. Im Laufe der Zeit wurde klar, dass die zukünftige Entwicklung dieser Sprache schwer zu unterstützen sein würde, da die IDE und die Sprache selbst schlecht entwickelt sind. In den späten 2000er Jahren wurde beschlossen, auf ein vielversprechenderes C # umzusteigen. Die neue Version wurde parallel zur Verfeinerung der alten Version geschrieben, nach und nach befand sich immer mehr Code in .NET. Das Backend in C # konzentrierte sich zunächst auf die Dienstarchitektur. Während der Entwicklung wurden jedoch gemeinsam genutzte Bibliotheken mit Logik verwendet und Dienste in einem einzigen Prozess gestartet. Es stellte sich heraus, dass die Anwendung, die wir "Service-Monolith" nannten.
Einer der wenigen Vorteile dieses Bundles war die Fähigkeit der Dienste, sich gegenseitig über eine externe API aufzurufen. Es gab offensichtliche Voraussetzungen für den Übergang zu einem korrekteren Service und in Zukunft zu einer Microservice-Architektur.
Wir haben unsere Zersetzungsarbeiten um 2015 begonnen. Wir haben noch keinen idealen Zustand erreicht - es gibt Teile eines großen Projekts, die schwer als Monolithen zu bezeichnen sind, aber sie sehen auch nicht wie Mikrodienste aus. Die Fortschritte sind jedoch erheblich.
Ich werde im Artikel über ihn sprechen.
Inhalt
Architektur und Probleme der bestehenden Lösung
Anfänglich sah die Architektur wie folgt aus: Die Benutzeroberfläche ist eine separate Anwendung, der monolithische Teil ist in Visual Basic 6 geschrieben, die Anwendung in .NET war eine Reihe verwandter Dienste, die mit einer ziemlich großen Datenbank arbeiten.
Nachteile der vorherigen LösungSingle Point of FailureWir hatten einen einzigen Fehlerpunkt: Die .NET-Anwendung wurde in einem Prozess ausgeführt. Wenn eines der Module abstürzte, schlug die gesamte Anwendung fehl und Sie mussten sie neu starten. Da wir eine große Anzahl von Prozessen für verschiedene Benutzer automatisieren, konnten einige aufgrund eines Fehlers in einem von ihnen für einige Zeit nicht funktionieren. Und mit einem Softwarefehler hat auch die Redundanz nicht geholfen.
Die Aufstellung der VerbesserungenDieser Fehler ist eher organisatorisch. Unsere Anwendung hat viele Kunden, und alle möchten sie so schnell wie möglich fertigstellen. Bisher war dies nicht parallel möglich, und alle Kunden standen in einer Schlange. Dieser Prozess wirkte sich negativ auf das Geschäft aus, da sie nachweisen mussten, dass ihre Aufgabe wertvoll war. Und das Entwicklungsteam hat Zeit damit verbracht, diese Aufstellung zu organisieren. Dies nahm viel Zeit und Mühe in Anspruch, und das Produkt konnte sich daher nicht so schnell ändern, wie es von ihm gewesen wäre.
Unangemessener Einsatz von RessourcenWenn Sie Services in einem einzigen Prozess platzieren, haben wir die Konfiguration immer vollständig von Server zu Server kopiert. Wir wollten die am meisten ausgelasteten Dienste separat platzieren, um keine Ressourcen zu verschwenden und eine flexiblere Verwaltung unseres Bereitstellungsschemas zu erhalten.
Es ist schwer, moderne Technologie einzuführenEin Problem, das allen Entwicklern bekannt ist: Es besteht der Wunsch, moderne Technologien in das Projekt einzuführen, aber es gibt keine Möglichkeit. Bei einer großen monolithischen Lösung wird jede Aktualisierung der aktuellen Bibliothek, ganz zu schweigen vom Übergang zu einer neuen, zu einer eher nicht trivialen Aufgabe. Es dauert lange, um dem Teamleiter zu beweisen, dass es mehr Boni als verbrauchte Nerven bringt.
Schwierigkeiten beim Ausgeben von ÄnderungenDies war das schwerwiegendste Problem - wir haben alle zwei Monate Veröffentlichungen veröffentlicht.
Jede Veröffentlichung wurde trotz Tests und der Bemühungen der Entwickler zu einer echten Katastrophe für die Bank. Das Geschäft verstand, dass zu Beginn der Woche einige der Funktionen für ihn nicht funktionieren würden. Und die Entwickler haben verstanden, dass sie auf eine Woche mit schwerwiegenden Zwischenfällen warten.
Jeder hatte den Wunsch, die Situation zu ändern.
Microservice-Erwartungen
Lieferung der Komponenten nach Verfügbarkeit. Lieferung von Komponenten, sobald diese verfügbar sind, aufgrund der Zersetzung der Lösung und der Trennung verschiedener Prozesse.
Kleine Food-Teams. Dies ist wichtig, da ein großes Team, das an einem alten Monolithen arbeitet, schwierig zu verwalten war. Ein solches Team war gezwungen, nach einem strengen Prozess zu arbeiten, aber ich wollte mehr Kreativität und Unabhängigkeit. Nur kleine Teams konnten es sich leisten.
Isolierung von Diensten in getrennten Prozessen. Im Idealfall wollte ich in Containern isolieren, aber eine große Anzahl von in .NET Framework geschriebenen Diensten wird nur unter Windows ausgeführt. Jetzt gibt es Dienste in .NET Core, aber bisher gibt es nur wenige.
Flexibilität bei der Bereitstellung. Ich möchte Dienste nach Bedarf kombinieren und nicht nach den Anforderungen des Codes.
Einsatz neuer Technologien. Dies ist für jeden Programmierer interessant.
Übergangsprobleme
Wenn es einfach wäre, einen Monolithen in Microservices zu zerlegen, müssten Sie natürlich nicht auf Konferenzen darüber sprechen und Artikel schreiben. In diesem Prozess gibt es viele Fallstricke, ich werde die wichtigsten beschreiben, die uns gestört haben.
Das erste Problem ist typisch für die meisten Monolithen: die Kohärenz der Geschäftslogik. Wenn wir einen Monolithen schreiben, möchten wir unsere Klassen wiederverwenden, um keinen zusätzlichen Code zu schreiben. Beim Wechsel zu Microservices wird dies zu einem Problem: Der gesamte Code ist eng miteinander verbunden, und es ist schwierig, Dienste zu trennen.
Zu Beginn der Arbeiten verfügte das Repository über mehr als 500 Projekte und mehr als 700.000 Codezeilen. Dies ist eine ziemlich große Lösung und das
zweite Problem . Es war nicht möglich, es einfach in Microservices zu unterteilen.
Das dritte Problem ist der Mangel an notwendiger Infrastruktur. Tatsächlich waren wir daran beteiligt, den Quellcode manuell auf die Server zu kopieren.
So wechseln Sie von Monolith zu Microservices
Microservice-ZuordnungZunächst stellten wir sofort fest, dass die Trennung von Mikrodiensten ein iterativer Prozess ist. Wir waren immer verpflichtet, die Entwicklung von Geschäftsaufgaben parallel durchzuführen. Wie wir dies technisch durchführen werden, ist bereits unser Problem. Deshalb haben wir uns auf den iterativen Prozess vorbereitet. Es funktioniert nicht anders, wenn Sie eine große Anwendung haben, und es ist nicht bereit, von Anfang an neu geschrieben zu werden.
Mit welchen Methoden isolieren wir Microservices?
Die erste Möglichkeit besteht darin, vorhandene Module als Dienste zu portieren. In dieser Hinsicht hatten wir Glück: Es gab bereits formalisierte Dienste, die am WCF-Protokoll arbeiteten. Sie wurden in separaten Baugruppen veröffentlicht. Wir haben sie separat verschoben und jeder Baugruppe einen kleinen Launcher hinzugefügt. Es wurde mit der wunderbaren Topshelf-Bibliothek geschrieben, mit der Sie die Anwendung sowohl als Dienst als auch als Konsole ausführen können. Dies ist praktisch für das Debuggen, da in der Lösung keine zusätzlichen Projekte erforderlich sind.
Services wurden gemäß der Geschäftslogik verbunden, da sie gemeinsame Assemblys verwendeten und mit einer gemeinsamen Datenbank arbeiteten. Es war schwierig, sie als Microservices in ihrer reinen Form zu bezeichnen. Trotzdem könnten wir diese Dienstleistungen separat in verschiedenen Prozessen ausgeben. Dies ermöglichte es bereits, ihren gegenseitigen Einfluss zu verringern und das Problem der parallelen Entwicklung und eines einzelnen Fehlerpunkts zu verringern.
Das Erstellen mit einem Host ist nur eine Codezeile in der Program-Klasse. Wir haben Topshelf in einer Helferklasse versteckt.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
Der zweite Weg, um Microservices zu isolieren: Erstellen Sie sie, um neue Probleme zu lösen. Wenn der Monolith nicht gleichzeitig wächst, ist dies bereits hervorragend, was bedeutet, dass wir uns in die richtige Richtung bewegen. Um neue Probleme zu lösen, haben wir versucht, separate Dienste bereitzustellen. Wenn es eine solche Gelegenheit gab, haben wir mehr „kanonische“ Dienste erstellt, die ihr Datenmodell vollständig steuern, eine separate Datenbank.
Wir haben wie viele andere mit Authentifizierungs- und Autorisierungsdiensten begonnen. Sie sind perfekt dafür. Sie sind unabhängig, haben in der Regel ein separates Datenmodell. Sie selbst interagieren nicht mit dem Monolithen, nur er wendet sich an sie, um einige Probleme zu lösen. Bei diesen Diensten können Sie mit dem Übergang zu einer neuen Architektur beginnen, die Infrastruktur auf ihnen debuggen, einige Ansätze im Zusammenhang mit Netzwerkbibliotheken ausprobieren usw. In unserer Organisation gibt es keine Teams, die keinen Authentifizierungsdienst durchführen könnten.
Der dritte Weg, die von uns verwendeten
Mikrodienste zu isolieren , ist für uns ein wenig spezifisch. Dadurch wird die Geschäftslogik aus der UI-Ebene herausgezogen. Wir haben die Hauptanwendung für die Desktop-Benutzeroberfläche, die wie das Backend in C # geschrieben ist. Entwickler machten regelmäßig Fehler und führten die UI-Teile der Logik aus, die im Backend hätten vorhanden sein und wiederverwendet werden sollen.
Wenn Sie sich ein reales Beispiel aus dem Code des UI-Teils ansehen, können Sie sehen, dass der größte Teil dieser Lösung echte Geschäftslogik enthält, die in anderen Prozessen nützlich ist, nicht nur zum Erstellen eines UI-Formulars.
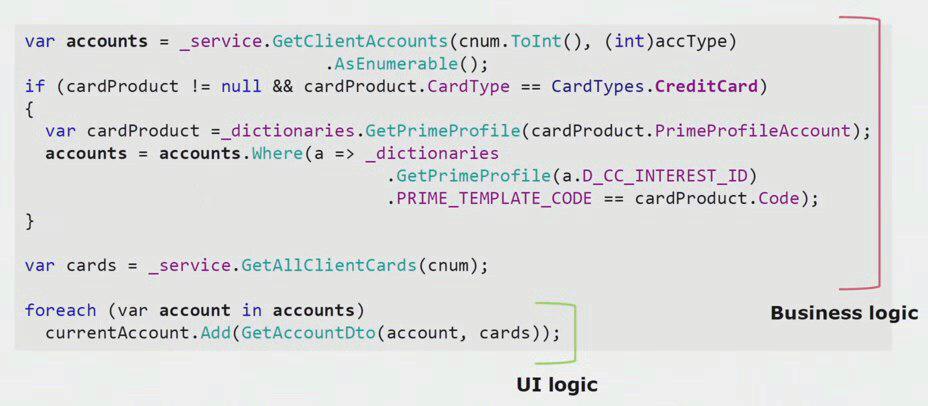
Die eigentliche UI-Logik besteht nur aus den letzten paar Zeilen. Wir haben es auf den Server übertragen, damit wir es wiederverwenden können, wodurch die Benutzeroberfläche reduziert und die richtige Architektur erreicht wird.
Die vierte, wichtigste Methode zur Isolierung von Mikrodiensten , mit der Sie den Monolithen reduzieren können, ist das Entfernen vorhandener Dienste bei der Verarbeitung. Wenn wir vorhandene Module so wie sie sind herausnehmen, ist das Ergebnis für Entwickler nicht immer angenehm, und der Geschäftsprozess ab dem Zeitpunkt der Erstellung der Funktionalität kann veraltet sein. Dank Refactoring können wir einen neuen Geschäftsprozess unterstützen, da sich die Geschäftsanforderungen ständig ändern. Wir können den Quellcode verbessern, bekannte Fehler beseitigen und ein besseres Datenmodell erstellen. Es gibt viele Vorteile.
Die Abteilung Verarbeitungsdienstleistungen ist untrennbar mit dem Konzept eines begrenzten Kontexts verbunden. Dies ist ein Konzept aus dem themenorientierten Design. Dies bedeutet einen Domänenmodellabschnitt, in dem alle Begriffe einer einzelnen Sprache eindeutig definiert sind. Betrachten Sie als Beispiel den Kontext von Versicherungen und Rechnungen. Wir haben eine monolithische Anwendung, und es ist notwendig, mit dem Konto in der Versicherung zu arbeiten. Wir erwarten, dass der Entwickler die vorhandene "Account" -Klasse in einer anderen Assembly findet, einen Link von der "Insurance" -Klasse herstellt und einen Arbeitscode erhält. Das DRY-Prinzip wird eingehalten, die Aufgabe durch die Verwendung von vorhandenem Code wird schneller erledigt.
Infolgedessen stellt sich heraus, dass die Kontexte von Konten und Versicherungen miteinander verbunden sind. Wenn neue Anforderungen auftreten, wird diese Verbindung die Entwicklung beeinträchtigen und die Komplexität einer bereits komplexen Geschäftslogik erhöhen. Um dieses Problem zu lösen, müssen Sie die Grenzen zwischen den Kontexten im Code finden und deren Verstöße entfernen. Im Zusammenhang mit Versicherungen ist es beispielsweise durchaus möglich, dass die 20-stellige Kontonummer der Zentralbank und das Datum der Kontoeröffnung ausreichen.
Um diese begrenzten Kontexte voneinander zu trennen und mit dem Extrahieren von Mikrodiensten aus einer monolithischen Lösung zu beginnen, haben wir einen Ansatz verwendet, z. B. das Erstellen externer APIs innerhalb der Anwendung. Wenn wir wussten, dass ein Modul zu einem Microservice werden sollte, der sich im Rahmen des Prozesses irgendwie ändert, haben wir sofort die Logik, die zu einem anderen begrenzten Kontext gehört, durch externe Aufrufe aufgerufen. Zum Beispiel über REST oder WCF.
Wir haben uns entschieden, Code, der verteilte Transaktionen erfordert, nicht zu vermeiden. In unserem Fall stellte sich heraus, dass es recht einfach war, diese Regel einzuhalten. Wir haben solche Situationen immer noch nicht erlebt, in denen hart verteilte Transaktionen wirklich benötigt werden - die endgültige Konsistenz zwischen den Modulen ist völlig ausreichend.
Betrachten Sie ein bestimmtes Beispiel. Wir haben das Konzept eines Orchesterförderers, der die Essenz der "Anwendung" verarbeitet. Er erstellt abwechselnd einen Kunden, ein Konto und eine Bankkarte. Wenn der Client und das Konto erfolgreich erstellt wurden und die Erstellung der Karte fehlgeschlagen ist, wechselt die Anwendung nicht in den Status "erfolgreich" und bleibt im Status "Karte nicht erstellt". In Zukunft wird die Hintergrundaktivität es aufnehmen und beenden. Das System befindet sich seit einiger Zeit in einem Zustand der Inkonsistenz, aber dies passt insgesamt zu uns.
Wenn dennoch eine Situation auftritt, in der ein Teil der Daten konsistent gespeichert werden muss, werden wir höchstwahrscheinlich den Service erweitern, um dies in einem Prozess zu verarbeiten.
Betrachten wir ein Beispiel für die Zuweisung von Mikroservices. Wie kann es relativ sicher in die Produktion gebracht werden? In diesem Beispiel haben wir einen separaten Teil des Systems - das Gehaltsservice-Modul, einen der Abschnitte des Codes, aus denen wir einen Microservice erstellen möchten.
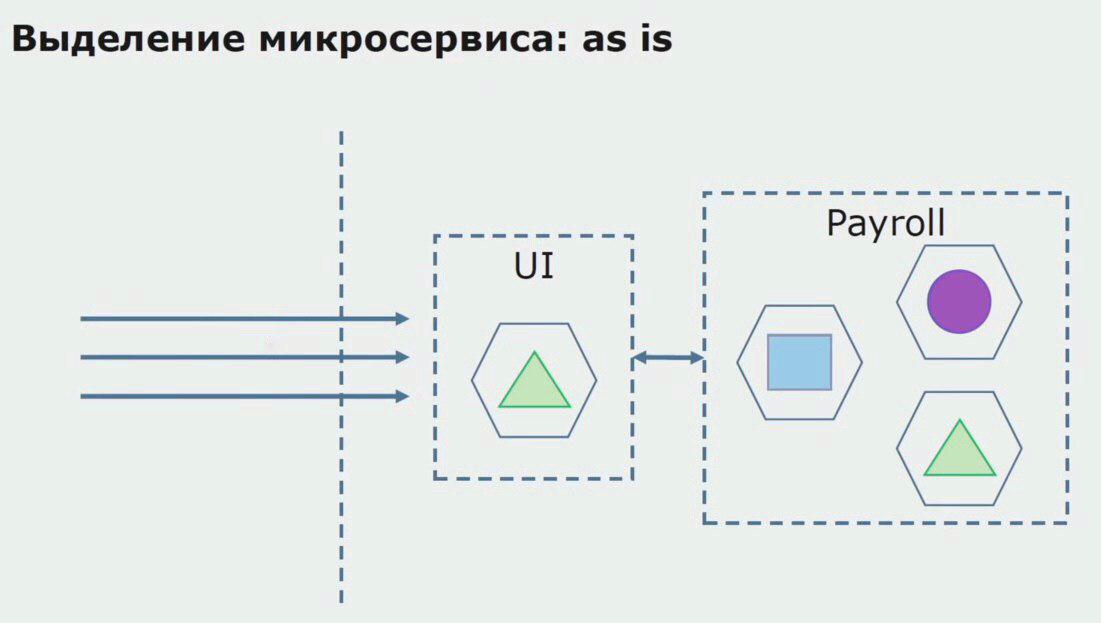
Zunächst erstellen wir einen Microservice, indem wir den Code neu schreiben. Wir verbessern einige Punkte, die nicht zu uns passen. Wir realisieren neue Geschäftsanforderungen vom Kunden. Wir erweitern das Bundle zwischen der Benutzeroberfläche und dem Gateway-API-Backend, das die Anrufweiterleitung ermöglicht.
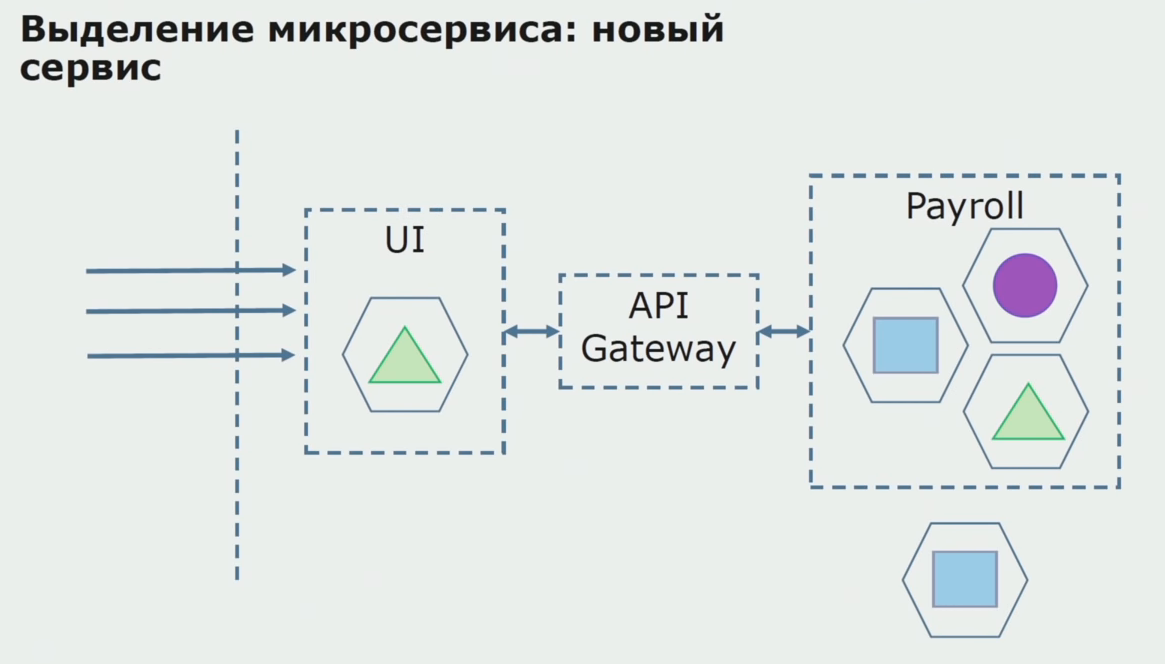
Als nächstes geben wir diese Konfiguration in Betrieb, jedoch im Status des Piloten. Die meisten unserer Benutzer arbeiten immer noch mit alten Geschäftsprozessen. Für neue Benutzer entwickeln wir eine neue Version einer monolithischen Anwendung, die dieser Prozess nicht mehr enthält. Tatsächlich haben wir eine Reihe von Monolithen und Mikroservices, die in Form eines Piloten arbeiten.
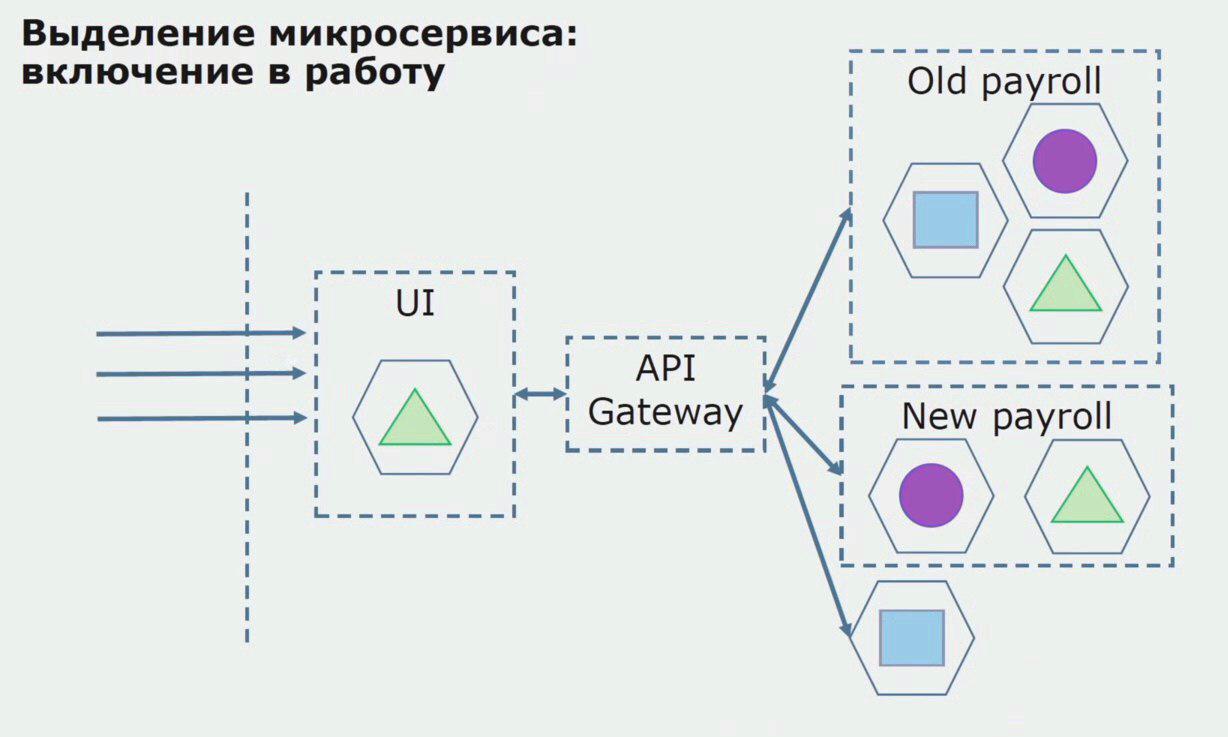
Mit einem erfolgreichen Piloten verstehen wir, dass die neue Konfiguration wirklich funktionsfähig ist. Wir können den alten Monolithen aus der Gleichung entfernen und die neue Konfiguration anstelle der alten Lösung belassen.
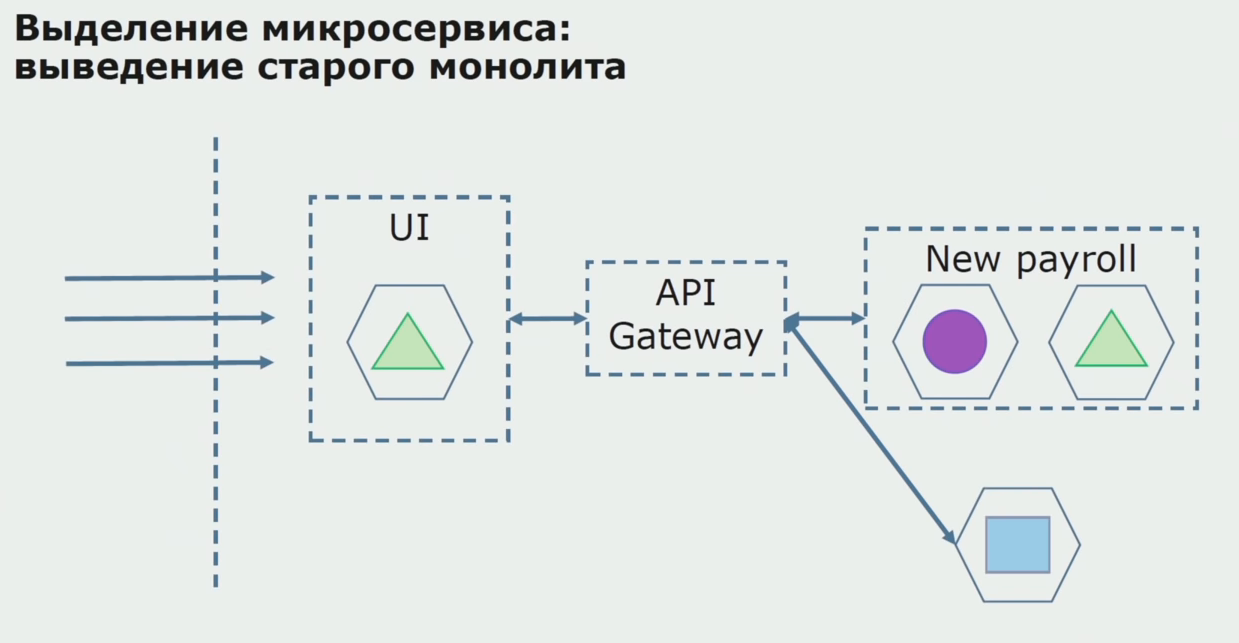
Insgesamt verwenden wir fast alle vorhandenen Methoden zum Aufteilen des Quellcodes eines Monolithen. All dies ermöglicht es uns, die Größe von Teilen der Anwendung zu reduzieren und sie in neue Bibliotheken zu übertragen, wodurch ein besserer Quellcode entsteht.
Arbeiten Sie mit einer DB
Die Datenbank kann schlechter unterteilt werden als der Quellcode, da sie nicht nur das aktuelle Schema, sondern auch die gesammelten historischen Daten enthält.
Unsere Datenbank hatte wie viele andere einen weiteren wichtigen Nachteil - ihre enorme Größe. Diese Datenbank wurde in Übereinstimmung mit der komplizierten Geschäftslogik des Monolithen entworfen, und es haben sich Verknüpfungen zwischen Tabellen verschiedener begrenzter Kontexte angesammelt.
In unserem Fall trat bei vielen großen Projekten ein Problem auf, um alle Probleme zu lösen (eine große Datenbank, viele Beziehungen, manchmal unverständliche Grenzen zwischen Tabellen): die Verwendung der gemeinsam genutzten Datenbankvorlage. Daten wurden aus Tabellen durch Ansicht, durch Replikation entnommen und an andere Systeme gesendet, auf denen diese Replikation benötigt wird. Infolgedessen konnten wir die Tabellen nicht in einem separaten Schema herausnehmen, da sie aktiv verwendet wurden.
Die Trennung hilft uns, in begrenzte Kontexte im Code aufzubrechen. Es gibt uns normalerweise eine ziemlich gute Vorstellung davon, wie wir Daten auf Datenbankebene aufteilen. Wir verstehen, welche Tabellen sich auf einen begrenzten Kontext beziehen und welche sich auf einen anderen beziehen.
Wir haben zwei globale Methoden zum Partitionieren der Datenbank angewendet: Partitionieren vorhandener Tabellen und Partitionieren mit Verarbeitung.
Die Trennung vorhandener Tabellen ist eine Methode, die sich gut eignet, wenn die Datenstruktur von hoher Qualität ist, die Geschäftsanforderungen erfüllt und für alle geeignet ist. In diesem Fall können wir vorhandene Tabellen in einem separaten Schema auswählen.
Eine Verarbeitungsabteilung ist erforderlich, wenn sich das Geschäftsmodell stark geändert hat und die Tabellen uns nicht mehr vollständig zufrieden stellen.
Separate vorhandene Tabellen. Wir müssen bestimmen, was wir trennen werden. Ohne dieses Wissen wird nichts daraus, und hier hilft uns die Trennung begrenzter Kontexte im Code. Wenn es möglich ist, die Grenzen von Kontexten im Quellcode zu verstehen, wird in der Regel klar, welche Tabellen zur Trennung in die Liste aufgenommen werden sollen.
Stellen Sie sich vor, wir haben eine Lösung, bei der zwei Monolithmodule mit einer Datenbank interagieren. Wir müssen sicherstellen, dass nur ein Modul mit dem Teil der getrennten Tabellen interagiert und das andere über die API mit ihm interagiert. Für den Anfang reicht es aus, dass nur ein Eintrag über die API erfolgt. Dies ist eine notwendige Bedingung, damit wir über die Unabhängigkeit von Mikrodiensten sprechen können. Das Lesen von Links kann so lange bestehen bleiben, bis ein großes Problem vorliegt.

Im nächsten Schritt können wir bereits einen Codeabschnitt auswählen, der mit abnehmbaren Tabellen mit oder ohne Verarbeitung in einem separaten Microservice funktioniert, und ihn in einem separaten Prozesscontainer ausführen. Dies ist ein separater Dienst mit Kommunikation mit der Monolith-Datenbank und den Tabellen, die nicht direkt damit zusammenhängen. Der Monolith interagiert immer noch mit dem abnehmbaren Teil zum Lesen.

Später werden wir diese Verbindung entfernen, dh das Lesen der Daten der monolithischen Anwendung aus den getrennten Tabellen wird ebenfalls an die API übertragen.
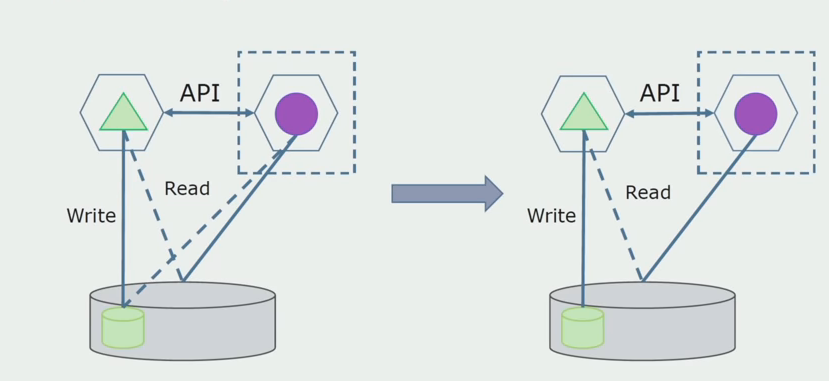
Als nächstes wählen wir aus der allgemeinen Datenbank die Tabellen aus, mit denen nur der neue Microservice arbeitet. Wir können Tabellen in einem separaten Schema oder sogar in einer separaten physischen Datenbank platzieren. Es gab eine Verbindung zum Lesen zwischen dem Microservice und der Monolith-Datenbank, aber es gibt keinen Grund zur Sorge, in dieser Konfiguration kann sie lange leben.
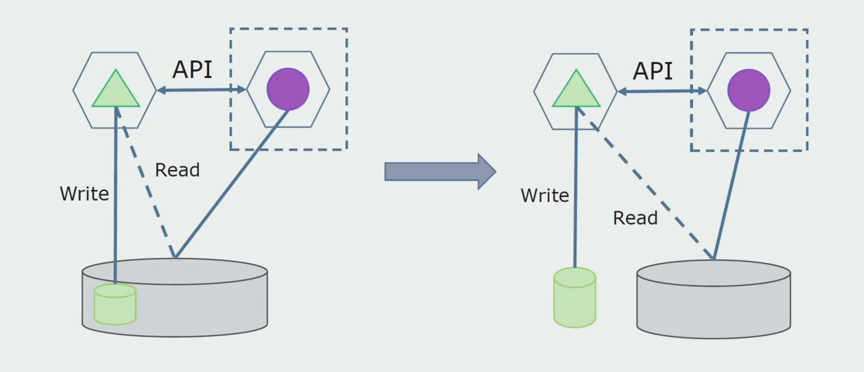
Der letzte Schritt besteht darin, alle Verbindungen vollständig zu entfernen. In diesem Fall müssen wir möglicherweise Daten aus der Hauptdatenbank migrieren. Manchmal möchten wir einige Daten oder Verzeichnisse, die von externen Systemen repliziert wurden, in mehreren Datenbanken wiederverwenden. Wir treffen uns regelmäßig.
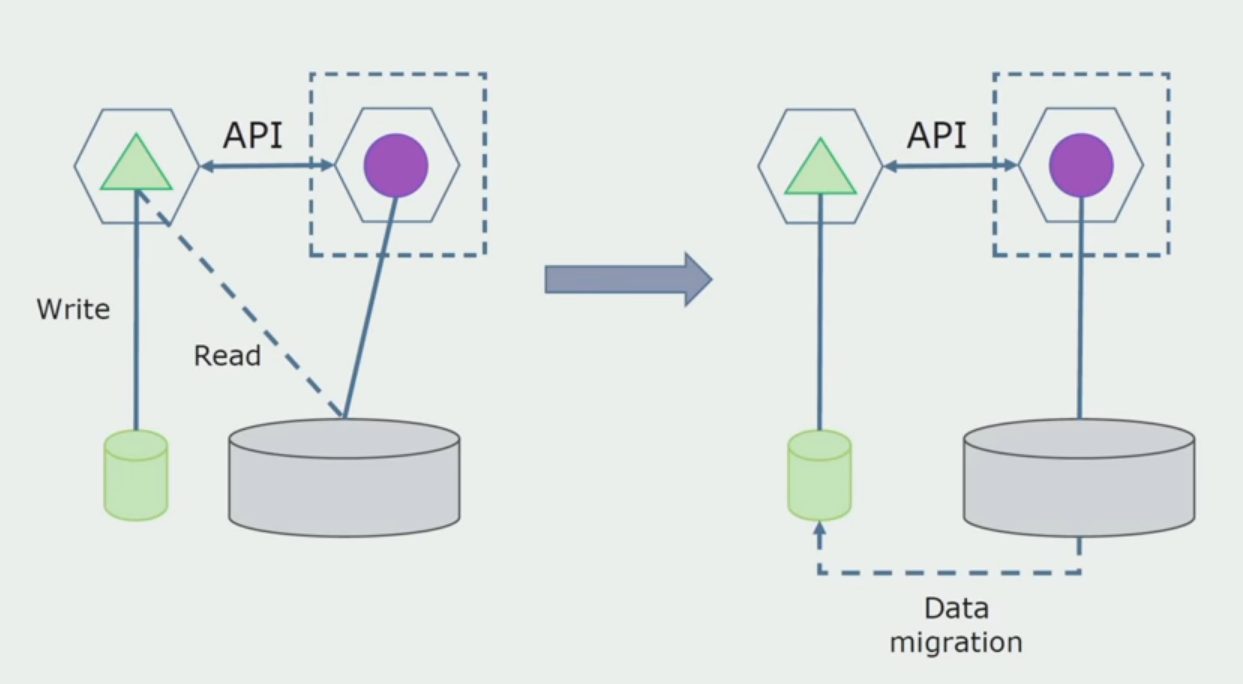 Verarbeitungsabteilung.
Verarbeitungsabteilung. Diese Methode ist der ersten sehr ähnlich und geht nur in umgekehrter Reihenfolge vor. Wir haben sofort eine neue Datenbank und einen neuen Mikroservice, der über die API mit dem Monolithen interagiert. Gleichzeitig bleibt jedoch eine Reihe von Datenbanktabellen übrig, die wir in Zukunft löschen möchten. Wir werden es nicht mehr brauchen, in dem neuen Modell haben wir es ersetzt.
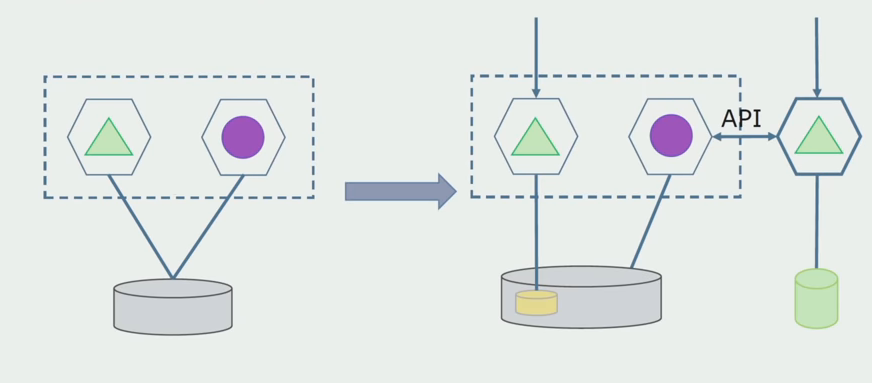
Damit dieses Schema funktioniert, benötigen wir höchstwahrscheinlich eine Übergangszeit.
Es gibt zwei mögliche Ansätze.
Erstens : Wir duplizieren alle Daten in den neuen und alten Datenbanken. In diesem Fall haben wir Datenredundanz, es kann Probleme mit der Synchronisation geben. Aber dann können wir zwei verschiedene Kunden nehmen. Einer wird mit der neuen Version arbeiten, der andere mit der alten.
Zweitens : Wir teilen Daten nach bestimmten Geschäftsmerkmalen. In unserem System waren beispielsweise 5 Produkte in der alten Datenbank gespeichert. Als sechste haben wir im Rahmen einer neuen Geschäftsaufgabe eine neue Datenbank erstellt. Wir benötigen jedoch die Gateway-API, die diese Daten synchronisiert und dem Client zeigt, wohin und was er nehmen soll.
Beide Ansätze funktionieren, je nach Situation wählen.
Nachdem wir sichergestellt haben, dass alles funktioniert, kann der Teil des Monolithen, der mit den alten Datenbankstrukturen funktioniert, deaktiviert werden.
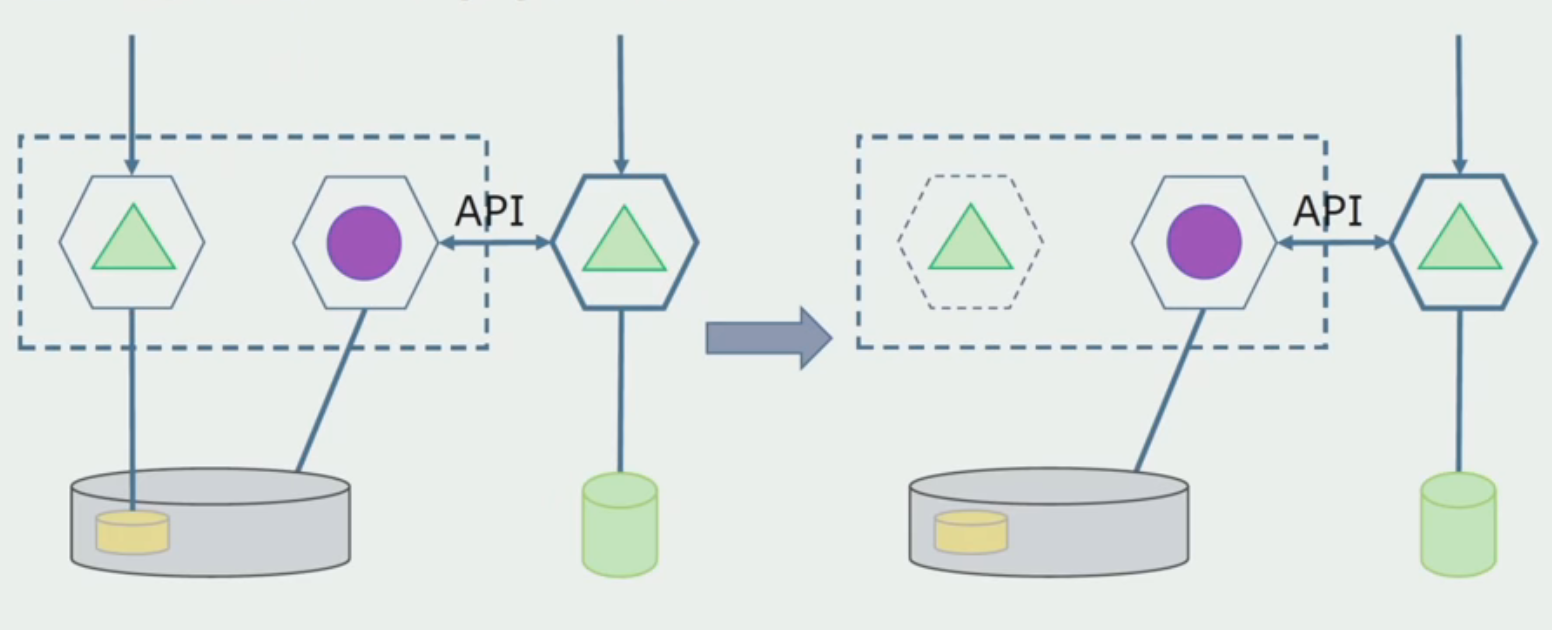
Der letzte Schritt besteht darin, die alten Datenstrukturen zu entfernen.

Zusammenfassend können wir sagen, dass wir Probleme mit der Datenbank haben: Es ist schwierig, damit zu arbeiten, verglichen mit dem Quellcode, es ist schwieriger zu trennen, aber dies kann und sollte getan werden. Wir haben einige Möglichkeiten gefunden, die dies ziemlich sicher ermöglichen, aber es ist einfacher, einen Fehler mit den Daten als mit dem Quellcode zu machen.
Arbeiten mit Quellcode
So sah das Quellcodediagramm aus, als wir mit der Analyse eines monolithischen Projekts begannen.

Es kann bedingt in drei Schichten unterteilt werden. Dies ist eine Schicht aus gestarteten Modulen, Plugins, Diensten und einzelnen Aktivitäten. Tatsächlich waren dies die Eintrittspunkte innerhalb der monolithischen Lösung. Alle von ihnen waren fest mit einer gemeinsamen Schicht verbunden. Es hatte Geschäftslogik, die zwischen Diensten geteilt wurde, und viele Verbindungen. Jeder Dienst und jedes Plugin verwendete je nach Größe und Gewissen der Entwickler bis zu 10 oder mehr gängige Assemblys.
Wir hatten Glück, wir hatten Infrastrukturbibliotheken, die separat genutzt werden konnten.
Manchmal trat eine Situation auf, in der einige der allgemeinen Objekte nicht zu dieser Schicht gehörten, sondern Infrastrukturbibliotheken waren. Dies wurde durch Umbenennen entschieden.
Am meisten besorgt über begrenzte Kontexte. Früher mischten sich 3-4 Kontexte in einer gemeinsamen Assembly und verwendeten sich gegenseitig innerhalb derselben Geschäftsfunktionen. Es war notwendig zu verstehen, wo und an welchen Grenzen dies unterteilt werden kann und was als nächstes mit der Zuordnung dieser Trennung in Quellcode-Assemblys zu tun ist.
Wir haben mehrere Regeln für den Codetrennungsprozess formuliert.
Erstens : Wir wollten keine Geschäftslogik mehr zwischen Diensten, Aktivitäten und Plugins teilen. Sie wollten die Geschäftslogik im Rahmen von Microservices unabhängig machen. Andererseits werden Microservices im Idealfall als Dienste wahrgenommen, die völlig unabhängig existieren. Ich glaube, dass dieser Ansatz etwas verschwenderisch ist und schwer zu erreichen ist, da beispielsweise Dienste in C # auf jeden Fall durch eine Standardbibliothek verbunden werden. Unser System ist in C # geschrieben, andere Technologien wurden noch nicht verwendet. Aus diesem Grund haben wir beschlossen, dass wir es uns leisten können, gemeinsame technische Baugruppen zu verwenden. Die Hauptsache ist, dass sie keine Fragmente der Geschäftslogik haben. Wenn Sie einen praktischen Wrapper über dem von Ihnen verwendeten ORM haben, ist das Kopieren von Service zu Service sehr teuer.
Unser Team ist ein Fan von themenorientiertem Design, daher ist die „Zwiebelarchitektur“ perfekt für uns. Die Basis unserer Services war keine Datenzugriffsschicht, sondern eine Assembly mit Domänenlogik, die nur Geschäftslogik enthält und keine Infrastrukturverbindungen aufweist. Gleichzeitig können wir die Domänenassembly unabhängig ändern, um die mit den Frameworks verbundenen Probleme zu lösen.
Zu diesem Zeitpunkt stießen wir auf das erste ernsthafte Problem. Der Dienst sollte sich auf eine Domänenassembly beziehen, wir wollten die Logik unabhängig machen, und hier hat uns das DRY-Prinzip stark gestört. Um Doppelarbeit zu vermeiden, wollten die Entwickler Klassen aus benachbarten Assemblys wiederverwenden. Infolgedessen begannen die Domänen wieder miteinander zu kommunizieren. Wir haben die Ergebnisse analysiert und festgestellt, dass das Problem möglicherweise auch im Bereich des Quellcode-Speichergeräts liegt. Wir hatten ein großes Repository, in dem alle Quellcodes lagen. Die Lösung für das gesamte Projekt war auf einer lokalen Maschine sehr schwierig zu montieren. Aus diesem Grund wurden separate kleine Lösungen für die Teile des Projekts erstellt, und niemand verbot, ihnen eine gemeinsame oder Domänen-Assembly hinzuzufügen und sie wiederzuverwenden. Das einzige Tool, das uns dies nicht erlaubte, war der Überprüfungscode. Aber manchmal stürzte er auch ab.
Dann begannen wir, zu einem Modell mit separaten Repositorys zu wechseln. Die Geschäftslogik fließt nicht mehr von Service zu Service, Domänen sind wirklich unabhängig geworden. Begrenzte Kontexte werden klarer unterstützt. Wie verwenden wir Infrastrukturbibliotheken wieder? Wir haben sie einem separaten Repository zugewiesen und sie dann in die Nuget-Pakete gestellt, die wir in Artifactory abgelegt haben. Bei jeder Änderung erfolgt die Zusammenstellung und Veröffentlichung automatisch.
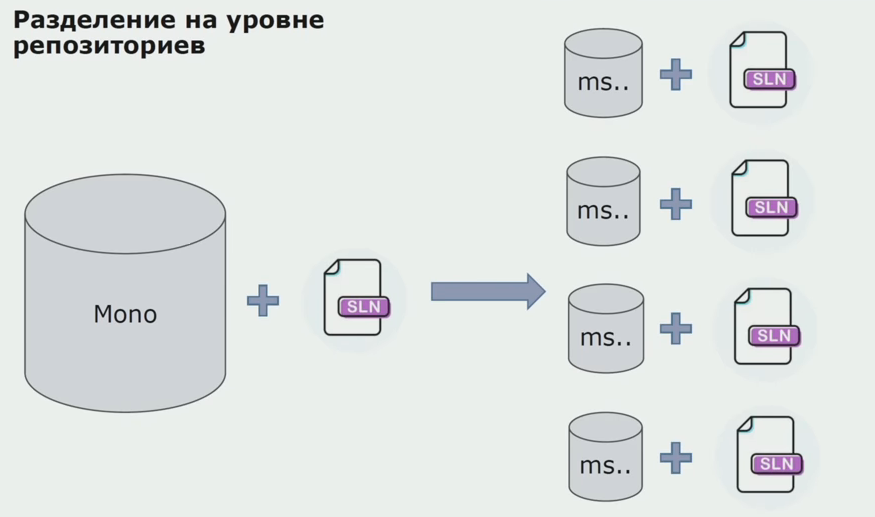
Unsere Dienstleistungen bezogen sich auf interne Infrastrukturpakete genauso wie auf externe. Wir laden externe Bibliotheken von Nuget herunter. Um mit Artifactory zu arbeiten, wo wir diese Pakete abgelegt haben, haben wir zwei Paketmanager verwendet. In kleinen Repositories haben wir auch Nuget verwendet. In Repositorys mit mehreren Diensten haben wir Paket verwendet, das mehr Versionskonsistenz zwischen Modulen bietet.
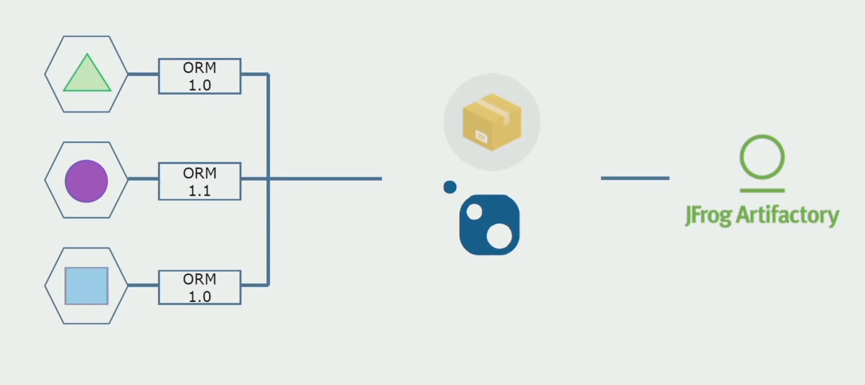
Durch die Arbeit am Quellcode, die geringfügige Änderung der Architektur und die gemeinsame Nutzung von Repositorys machen wir unsere Dienste unabhängiger.
Infrastrukturprobleme
Die meisten Nachteile der Umstellung auf Microservices hängen mit der Infrastruktur zusammen. Sie benötigen eine automatisierte Bereitstellung, Sie benötigen neue Bibliotheken für die Infrastruktur.
Manuelle Installation in UmgebungenZunächst haben wir die Lösung manuell in der Umgebung installiert. Um diesen Prozess zu automatisieren, haben wir eine CI / CD-Pipeline erstellt. Wir haben uns für den kontinuierlichen Lieferprozess entschieden, da eine kontinuierliche Bereitstellung für uns aus Sicht der Geschäftsprozesse noch nicht akzeptabel ist. Daher erfolgt das Senden an den Betrieb über die Schaltfläche und zum Testen - automatisch.
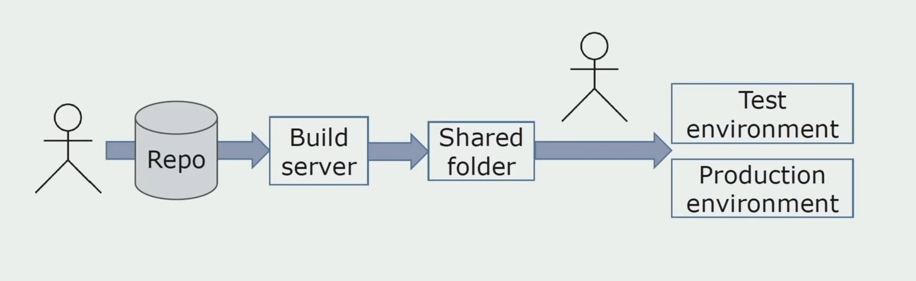
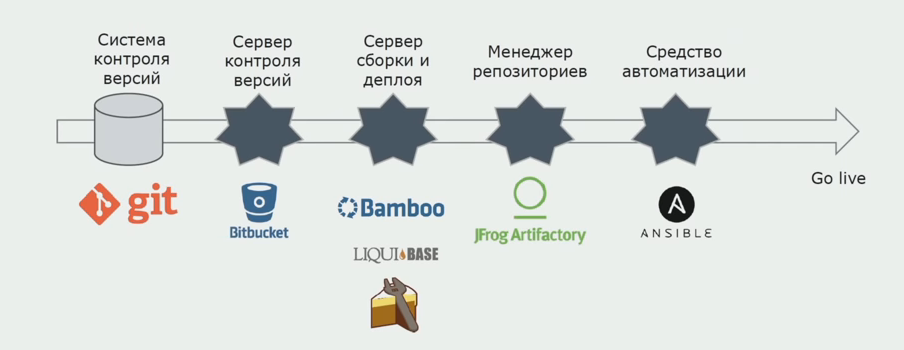
Wir verwenden Atlassian, Bitbucket zum Speichern des Quellcodes und Bamboo zum Zusammenstellen. Wir schreiben gerne Assembly-Skripte in Cake, weil es das gleiche C # ist. Vorgefertigte Pakete kommen zu Artifactory, und Ansible gelangt automatisch zu den Testservern, wonach sie sofort getestet werden können.
Separate Protokollierung
Zu einer Zeit war eine der Ideen des Monolithen die Bereitstellung einer gemeinsamen Protokollierung. Wir mussten auch verstehen, was mit den einzelnen Protokollen auf den Datenträgern zu tun ist. Protokolle werden in Textdateien an uns geschrieben. Wir haben uns für den Standard-ELK-Stack entschieden. Wir haben nicht über Anbieter direkt an die ELK geschrieben, sondern beschlossen, die Textprotokolle fertigzustellen und die darin enthaltene Ablaufverfolgungs-ID als Kennung aufzuschreiben und den Dienstnamen hinzuzufügen, damit diese Protokolle dann analysiert werden können.

Mit Filebeat haben wir die Möglichkeit, unsere Protokolle von Servern zu sammeln und sie dann zu konvertieren. Mit Kibana können Sie Anforderungen in der Benutzeroberfläche erstellen und beobachten, wie der Anruf zwischen den Diensten verlaufen ist. Die Trace-ID hilft dabei sehr.
Testen und Debuggen von verwandten Diensten
Anfangs haben wir nicht vollständig verstanden, wie entwickelte Dienste zu debuggen sind. Mit dem Monolithen war alles einfach, wir haben ihn auf dem lokalen Computer ausgeführt. Zuerst haben sie versucht, dasselbe mit Microservices zu tun, aber manchmal müssen Sie mehrere andere ausführen, um einen Microservice vollständig zu starten, was unpraktisch ist. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
Zusammenfassung
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.