Jedes Überwachungssystem ist mit drei Arten von Leistungsproblemen konfrontiert.
Erstens sollte ein gutes Überwachungssystem Daten von außen sehr schnell empfangen, verarbeiten und aufzeichnen. Das Konto geht in Mikrosekunden. Auf den ersten Blick mag dies nicht offensichtlich erscheinen, aber wenn das System groß genug wird, werden alle diese Sekundenbruchteile zusammengefasst, was zu deutlich spürbaren Verzögerungen führt.

Die zweite Aufgabe besteht darin, einen bequemen Zugriff auf große Arrays zuvor gesammelter Metriken (mit anderen Worten auf historische Daten) bereitzustellen. Historische Daten werden in einer Vielzahl von Kontexten verwendet. Beispielsweise werden Berichte und Diagramme daraus generiert, aggregierte Prüfungen werden darauf aufgebaut, Trigger hängen von ihnen ab. Wenn der Zugriff auf den Verlauf verzögert wird, wirkt sich dies sofort auf die Geschwindigkeit des gesamten Systems aus.
Drittens nehmen historische Daten viel Platz ein. Selbst relativ bescheidene Überwachungskonfigurationen erhalten sehr schnell eine solide Geschichte. Da jedoch kaum jemand den Ladeverlauf des fünf Jahre alten Prozessors zur Hand haben möchte, sollte das Überwachungssystem in der Lage sein, den Verlauf nicht nur gut aufzuzeichnen, sondern auch gut zu löschen (in Zabbix wird dieser Vorgang als „Housekeeping“ bezeichnet). Das Löschen alter Daten muss nicht so effizient sein wie das Sammeln und Analysieren neuer Daten. Schwere Löschvorgänge beanspruchen jedoch wertvolle DBMS-Ressourcen und können kritischere Vorgänge verlangsamen.
Die ersten beiden Probleme werden durch Caching gelöst. Zabbix unterstützt mehrere spezialisierte Caches, um das Lesen und Schreiben von Daten zu beschleunigen. Die DBMS-Mechanismen selbst sind hier nicht geeignet, weil Selbst der fortschrittlichste Allzweck-Caching-Algorithmus weiß nicht, welche Datenstrukturen zu einem bestimmten Zeitpunkt einen sofortigen Zugriff erfordern.
Überwachungs- und Zeitreihendaten
Alles ist in Ordnung, solange sich die Daten im Speicher des Zabbix-Servers befinden. Der Speicher ist jedoch nicht unendlich und irgendwann müssen die Daten in die Datenbank geschrieben (oder gelesen) werden. Und wenn die Datenbankleistung ernsthaft hinter der Geschwindigkeit der Erfassung von Metriken zurückbleibt, helfen selbst die fortschrittlichsten speziellen Caching-Algorithmen lange Zeit nicht weiter.
Das dritte Problem betrifft auch die Datenbankleistung. Um dies zu lösen, müssen Sie eine zuverlässige Löschstrategie auswählen, die andere Datenbankvorgänge nicht beeinträchtigt. Standardmäßig löscht Zabbix historische Daten in Stapeln von mehreren tausend Datensätzen pro Stunde. Sie können längere Verwaltungsperioden oder größere Paketgrößen konfigurieren, wenn die Geschwindigkeit der Datenerfassung und der Platz in der Datenbank dies zulassen. Bei einer sehr großen Anzahl von Metriken und / oder einer hohen Häufigkeit ihrer Erfassung kann die ordnungsgemäße Einrichtung der Verwaltung eine entmutigende Aufgabe sein, da ein Zeitplan für das Löschen von Daten möglicherweise nicht mit dem Tempo der Aufzeichnung neuer Metriken Schritt hält.
Zusammenfassend lässt sich sagen, dass das Überwachungssystem Leistungsprobleme in drei Richtungen löst: Sammeln neuer Daten und Schreiben in die Datenbank mithilfe von SQL INSERT-Abfragen, Zugreifen auf Daten mithilfe von SELECT-Abfragen und Löschen von Daten mithilfe von DELETE. Mal sehen, wie eine typische SQL-Abfrage ausgeführt wird:
- Das DBMS analysiert die Abfrage und überprüft sie auf Syntaxfehler. Wenn die Anforderung syntaktisch korrekt ist, erstellt die Engine einen Syntaxbaum zur weiteren Verarbeitung.
- Der Abfrageplaner analysiert den Syntaxbaum und berechnet die verschiedenen Wege (Pfade) zur Ausführung der Anforderung.
- Der Scheduler berechnet den günstigsten Weg. Dabei werden viele Dinge berücksichtigt - wie groß sind die Tabellen, müssen die Ergebnisse sortiert werden, gibt es Indizes für die Abfrage usw.
- Wenn der optimale Pfad gefunden wurde, führt die Engine die Abfrage aus, indem sie auf die gewünschten Datenblöcke zugreift (mithilfe von Indizes oder sequentiellem Scannen), die Sortier- und Filterkriterien anwendet, das Ergebnis sammelt und an den Client zurückgibt.
- Zum Einfügen, Ändern und Löschen von Abfragen muss die Engine auch die Indizes für die entsprechenden Tabellen aktualisieren. Bei großen Tabellen kann dieser Vorgang länger dauern als das Arbeiten mit den Daten selbst.
- Höchstwahrscheinlich aktualisiert das DBMS auch die internen Statistiken zur Datennutzung für nachfolgende Aufrufe des Abfrageplaners.
Im Allgemeinen gibt es viel Arbeit. Die meisten DBMS bieten eine Vielzahl von Einstellungen für die Abfrageoptimierung, konzentrieren sich jedoch normalerweise auf einige durchschnittliche Workflows, in denen das Einfügen und Löschen von Datensätzen ungefähr mit der gleichen Häufigkeit wie die Änderung erfolgt.
Wie oben erwähnt, sind für Überwachungssysteme die typischsten Vorgänge das Hinzufügen und periodische Löschen im Stapelmodus. Das Ändern zuvor hinzugefügter Daten erfolgt fast nie, und der Zugriff auf die Daten erfordert die Verwendung aggregierter Funktionen. Außerdem werden die Werte der hinzugefügten Metriken normalerweise nach Zeit geordnet. Solche Daten werden üblicherweise als
Zeitreihen bezeichnet :
Zeitreihen sind eine Reihe von Datenpunkten, die in einer temporären Reihenfolge indiziert (oder aufgelistet oder graffiti) sind.
Aus Sicht der Datenbank haben Zeitreihen die folgenden Eigenschaften:
- Zeitreihen können als Folge von zeitlich geordneten Blöcken auf einer Festplatte gespeichert werden.
- Zeitreihentabellen können mithilfe einer Zeitspalte indiziert werden.
- Die meisten SQL SELECT-Abfragen verwenden WHERE-, GROUP BY- oder ORDER BY-Klauseln in einer Zeitangabespalte.
- In der Regel haben Zeitreihendaten ein „Ablaufdatum“, nach dem sie gelöscht werden können.
Offensichtlich sind herkömmliche SQL-Datenbanken nicht zum Speichern solcher Daten geeignet, da Allzweckoptimierungen diese Eigenschaften nicht berücksichtigen. Daher sind in den letzten Jahren einige neue, zeitorientierte DBMS aufgetaucht, wie beispielsweise InfluxDB. Alle gängigen DBMS für Zeitreihen haben jedoch einen wesentlichen Nachteil: das Fehlen einer vollständigen SQL-Unterstützung. Darüber hinaus sind die meisten von ihnen nicht einmal CRUD (Erstellen, Lesen, Aktualisieren, Löschen).
Kann Zabbix diese DBMS auf irgendeine Weise verwenden? Einer der möglichen Ansätze besteht darin, historische Daten zur Speicherung in eine externe Datenbank zu übertragen, die auf Zeitreihen spezialisiert ist. Da die Zabbix-Architektur externe Backends zum Speichern historischer Daten unterstützt (z. B. unterstützt Zabbix Elasticsearch), erscheint diese Option auf den ersten Blick sehr sinnvoll. Wenn wir jedoch ein oder mehrere DBMS für Zeitreihen als externe Server unterstützen würden, müssten Benutzer mit folgenden Punkten rechnen:
- Ein weiteres System, das untersucht, konfiguriert und gewartet werden muss. Ein weiterer Ort, um Einstellungen, Speicherplatz, Speicherrichtlinien, Leistung usw. zu verfolgen.
- Reduzierung der Fehlertoleranz des Überwachungssystems, z In der Kette der zugehörigen Komponenten wird ein neues Glied angezeigt.
Für einige Benutzer überwiegen die Vorteile eines dedizierten dedizierten Speichers für historische Daten möglicherweise die Unannehmlichkeiten, sich um ein anderes System sorgen zu müssen. Für viele ist dies jedoch eine unnötige Komplikation. Es ist auch zu beachten, dass die Komplexität der universellen Schicht für die Arbeit mit Zabbix-Datenbanken deutlich zunehmen wird, da die meisten dieser spezialisierten Lösungen über eigene APIs verfügen. Und im Idealfall ziehen wir es vor, neue Funktionen zu erstellen, anstatt gegen andere APIs zu kämpfen.
Es stellt sich die Frage, ob es eine Möglichkeit gibt, das DBMS für Zeitreihen zu nutzen, ohne jedoch die Flexibilität und die Vorteile von SQL zu verlieren. Natürlich gibt es keine universelle Antwort, aber eine bestimmte Lösung kam der Antwort sehr nahe -
TimescaleDB .
Was ist TimescaleDB?
TimescaleDB (TSDB) ist eine PostgreSQL-Erweiterung, die die Arbeit mit Zeitreihen in einer regulären PostgreSQL (PG) -Datenbank optimiert. Obwohl es, wie oben erwähnt, keinen Mangel an gut skalierbaren Zeitreihenlösungen auf dem Markt gibt, ist ein einzigartiges Merkmal von TimescaleDB die Fähigkeit, gut mit Zeitreihen zu arbeiten, ohne die Kompatibilität und die Vorteile traditioneller relationaler CRUD-Datenbanken zu beeinträchtigen. In der Praxis bedeutet dies, dass wir das Beste aus beiden Welten bekommen. Die Datenbank weiß, welche Tabellen als Zeitreihen betrachtet werden sollten (und wendet alle erforderlichen Optimierungen an), aber Sie können mit ihnen auf die gleiche Weise wie mit regulären Tabellen arbeiten. Darüber hinaus müssen Anwendungen nicht wissen, dass die Daten von TSDB gesteuert werden!
Um eine Tabelle als Zeitreihentabelle zu markieren (in TSDB wird dies als Hypertabelle bezeichnet), rufen Sie einfach die TSDB-Prozedur create_ hypertable () auf. Unter der Haube unterteilt TSDB diese Tabelle unter bestimmten Bedingungen in sogenannte Fragmente (der englische Begriff ist Chunk). Fragmente können als automatisch gesteuerte Abschnitte einer Tabelle dargestellt werden. Jedes Fragment hat einen entsprechenden Zeitbereich. Für jedes Fragment legt die TSDB außerdem spezielle Indizes fest, sodass die Arbeit mit einem Datenbereich den Zugriff auf andere nicht beeinträchtigt.
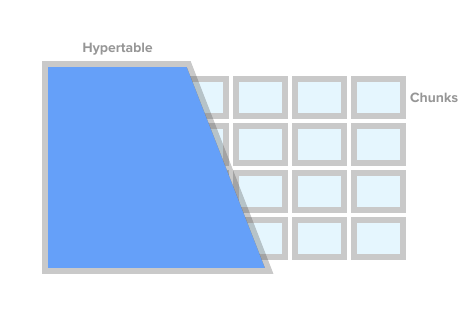 Hypertabellenbild von timescaledb.com
Hypertabellenbild von timescaledb.comWenn die Anwendung einen neuen Wert für die Zeitreihe hinzufügt, leitet die Erweiterung diesen Wert an das gewünschte Fragment weiter. Wenn der Bereich für die Zeit des neuen Werts nicht definiert ist, erstellt TSDB ein neues Fragment, weist ihm den gewünschten Bereich zu und fügt dort den Wert ein. Wenn eine Anwendung Daten von einer Hypertabelle anfordert, prüft die Erweiterung vor dem Ausführen der Anforderung, welche Fragmente dieser Anforderung zugeordnet sind.
Das ist aber noch nicht alles. TSDB ergänzt das robuste und bewährte PostgreSQL-Ökosystem mit einer Vielzahl von Leistungs- und Skalierbarkeitsänderungen. Dazu gehören das schnelle Hinzufügen neuer Datensätze, schnelle Zeitabfragen und praktisch kostenlose Stapellöschungen.
Wie bereits erwähnt, sollte eine gute Überwachungslösung eine große Menge historischer Daten effektiv löschen, um die Größe der Datenbank zu steuern und die Aufbewahrungsrichtlinien einzuhalten (d. H. Daten nicht länger als erforderlich zu speichern). Mit TSDB können wir die gewünschte Story einfach löschen, indem wir bestimmte Fragmente aus der Hypertabelle löschen. In diesem Fall muss die Anwendung keine Fragmente nach Namen oder anderen Links verfolgen. TSDB löscht alle erforderlichen Fragmente gemäß der angegebenen Zeitbedingung.
TimescaleDB- und PostgreSQL-Partitionierung
Auf den ersten Blick scheint TSDB ein guter Wrapper für die Standardpartitionierung von PG-Tabellen zu sein (
deklarative Partitionierung , wie sie in PG10 offiziell genannt wird). Zum Speichern historischer Daten können Sie die Standardpartitionierung PG10 verwenden. Wenn Sie genau hinschauen, sind die Fragmente der TSDB und des PG10-Abschnitts alles andere als identische Konzepte.
Das Einrichten der Partitionierung in PG erfordert zunächst ein tieferes Verständnis der Details, die die Anwendung selbst oder das DBMS auf gute Weise ausführen sollten. Zunächst müssen Sie Ihre Abschnittshierarchie planen und entscheiden, ob verschachtelte Partitionen verwendet werden sollen. Zweitens müssen Sie ein Abschnittsbenennungsschema erstellen und es irgendwie in die Skripte zum Erstellen des Schemas übertragen. Höchstwahrscheinlich enthält das Benennungsschema Datum und / oder Uhrzeit, und solche Namen müssen irgendwie automatisiert werden.
Als nächstes müssen Sie darüber nachdenken, wie abgelaufene Daten gelöscht werden. In der TSDB können Sie einfach den Befehl drop_chunks () aufrufen, der die Fragmente festlegt, die für einen bestimmten Zeitraum gelöscht werden sollen. Wenn Sie in PG10 einen bestimmten Wertebereich aus Standard-PG-Abschnitten entfernen müssen, müssen Sie die Liste der Abschnittsnamen für diesen Bereich selbst berechnen. Wenn das ausgewählte Partitionierungsschema verschachtelte Abschnitte umfasst, erschwert dies das Löschen weiter.
Ein weiteres Problem, das angegangen werden muss, ist die Vorgehensweise bei Daten, die über die aktuellen Zeitbereiche hinausgehen. Beispielsweise können Daten aus einer Zukunft stammen, für die noch keine Abschnitte erstellt wurden. Oder aus der Vergangenheit für bereits gelöschte Abschnitte. Standardmäßig funktioniert das Hinzufügen eines solchen Datensatzes in PG10 nicht und wir verlieren einfach die Daten. In PG11 können Sie einen Standardabschnitt für solche Daten definieren, der das Problem jedoch nur vorübergehend maskiert und nicht löst.
Natürlich können alle oben genannten Probleme auf die eine oder andere Weise gelöst werden. Sie können die Basis mit Triggern, Cron-Jabs aufhängen und großzügig mit Skripten bestreuen. Es wird hässlich, aber funktional sein. Es besteht kein Zweifel, dass PG-Abschnitte besser sind als riesige monolithische Tabellen, aber was definitiv nicht durch Skripte und Trigger gelöst wird, sind Zeitreihenverbesserungen, die PG nicht hat.
Das heißt, Im Vergleich zu PG-Abschnitten zeichnen sich die TSDB-Hypertabellen nicht nur dadurch aus, dass sie die Nerven der DB-Administratoren schonen, sondern auch den Zugriff auf Daten optimieren und neue hinzufügen. Beispielsweise sind Fragmente in TSDB immer ein eindimensionales Array. Dies vereinfacht die Fragmentverwaltung und beschleunigt Einfügungen und Auswahlen. Um neue Daten hinzuzufügen, verwendet TSDB einen eigenen Routing-Algorithmus im gewünschten Fragment, der im Gegensatz zum Standard-PG nicht alle Abschnitte sofort öffnet. Bei einer großen Anzahl von Abschnitten kann der Leistungsunterschied erheblich variieren. Technische Details zum Unterschied zwischen Standardpartitionierung in PG und TSDB finden Sie in
diesem Artikel .
Zabbix und TimescaleDB
Von allen Optionen scheint TimescaleDB die sicherste Wahl für Zabbix und seine Benutzer zu sein:
- TSDB ist als PostgreSQL-Erweiterung und nicht als eigenständiges System konzipiert. Daher sind keine zusätzliche Hardware, virtuelle Maschinen oder andere Änderungen in der Infrastruktur erforderlich. Benutzer können ihre ausgewählten Tools weiterhin für PostgreSQL verwenden.
- Mit TSDB können Sie fast den gesamten Code für die Arbeit mit der Datenbank in Zabbix unverändert speichern.
- TSDB verbessert die Leistung von History Syncer und Housekeeper erheblich.
- Niedrige Eintrittsschwelle - Die Grundkonzepte der TSDB sind einfach und unkompliziert.
- Die einfache Installation und Konfiguration sowohl der Erweiterung selbst als auch von Zabbix hilft Benutzern kleiner und mittlerer Systeme erheblich.
Mal sehen, was getan werden muss, um TSDB mit einem frisch installierten Zabbix zu starten. Nach der Installation von Zabbix und dem Ausführen von PostgreSQL-Datenbankerstellungsskripten müssen Sie TSDB herunterladen und auf der gewünschten Plattform installieren. Siehe Installationsanweisungen
hier . Nach der Installation der Erweiterung müssen Sie sie für die Zabbix-Basis aktivieren und dann das mit Zabbix gelieferte Skript timecaledb.sql ausführen. Es befindet sich entweder in der Datenbank / postgresql / timecaledb.sql, wenn die Installation aus dem Quellcode stammt, oder in /usr/share/zabbix/database/timecaledb.sql.gz, wenn die Installation aus Paketen stammt. Das ist alles! Jetzt können Sie den Zabbix-Server starten und er funktioniert mit TSDB.
Das Skript timescaledb.sql ist trivial. Er konvertiert lediglich die regulären Zabbix-Verlaufstabellen in TSDB-Hypertabellen und ändert die Standardeinstellungen. Legt die Parameter Artikelverlaufszeitraum überschreiben und Artikeltrendzeitraum überschreiben fest. Jetzt (Version 4.2) arbeiten die folgenden Zabbix-Tabellen unter TSDB-Kontrolle: history, history_uint, history_str, history_log, history_text, Trends und Trends_uint. Das gleiche Skript kann zum Migrieren dieser Tabellen verwendet werden (beachten Sie, dass der Parameter migrate_data auf true festgelegt ist). Es muss berücksichtigt werden, dass die Datenmigration ein sehr langer Prozess ist und mehrere Stunden dauern kann.
Der Parameter chunk_time_interval => 86400 erfordert möglicherweise auch Änderungen, bevor timecaledb.sql ausgeführt wird. Chunk_time_interval ist das Intervall, das die Zeit begrenzt, in der Werte in dieses Fragment fallen. Wenn Sie beispielsweise das Intervall chunk_time_interval auf 3 Stunden festlegen, werden die Daten für den gesamten Tag auf 8 Fragmente verteilt, wobei das erste Fragment Nr. 1 die ersten 3 Stunden (0: 00-2: 59), das zweite Fragment Nr. 2 die zweiten 3 Stunden ( 3: 00-5: 59) usw. Das letzte Fragment Nr. 8 enthält Werte mit einer Zeit von 21: 00-23: 59. 86400 Sekunden (1 Tag) ist der durchschnittliche Standardwert, aber Benutzer geladener Systeme möchten ihn möglicherweise reduzieren.
Um den Speicherbedarf grob abzuschätzen, ist es wichtig zu verstehen, wie viel Platz ein Durchschnitt pro Stück einnehmen kann. Das allgemeine Prinzip ist, dass das System über genügend Speicher verfügen muss, um mindestens ein Fragment aus jeder Hypertabelle anzuordnen. In diesem Fall sollte die Summe der Fragmentgrößen natürlich nicht nur mit einem Rand in den Speicher passen, sondern auch kleiner sein als der Wert des Parameters shared_buffers aus postgresql.conf. Weitere Informationen zu diesem Thema finden Sie in der TimescaleDB-Dokumentation.
Wenn Sie beispielsweise über ein System verfügen, das hauptsächlich ganzzahlige Metriken erfasst, und die Tabelle history_uint in 2-Stunden-Fragmente aufteilen und den Rest der Tabellen in eintägige Fragmente aufteilen möchten, müssen Sie diese Zeile in timecaledb.sql ändern:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
Nachdem sich eine bestimmte Menge historischer Daten angesammelt hat, können Sie die Fragmentgrößen für die Tabelle history_uint überprüfen, indem Sie chunk_relation_size () aufrufen:
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
Dieser Aufruf kann wiederholt werden, um die Fragmentgrößen für alle Hypertabellen zu ermitteln. Wenn beispielsweise festgestellt wurde, dass die Fragmentgröße von history_uint 13 MB beträgt, die Fragmente für andere Verlaufstabellen beispielsweise 20 MB und für Trendtabellen 10 MB, beträgt der Gesamtspeicherbedarf 13 + 4 x 20 + 2 x 10 = 113 MB. Wir müssen auch Speicherplatz von shared_buffers lassen, um andere Daten zu speichern, beispielsweise 20%. Dann muss der Wert von shared_buffers auf 113 MB / 0,8 = ~ 140 MB gesetzt werden.
Für eine feinere Abstimmung von TSDB wurde kürzlich das Dienstprogramm timescaledb-tune veröffentlicht. Es analysiert postgresql.conf, korreliert es mit der Systemkonfiguration (Speicher und Prozessor) und gibt dann Empfehlungen zum Einstellen von Speicherparametern, Parametern für die Parallelverarbeitung, WAL. Das Dienstprogramm ändert die Datei postgresql.conf. Sie können sie jedoch mit dem Parameter -dry-run ausführen und die vorgeschlagenen Änderungen überprüfen.
Wir werden uns mit den Zabbix-Parametern befassen. Artikelverlaufszeitraum überschreiben und Artikeltrendzeitraum überschreiben (verfügbar unter Administration -> Allgemein -> Haushalt). Sie werden benötigt, um historische Daten als ganze Fragmente von TSDB-Hypertabellen und nicht als Datensätze zu löschen.
Tatsache ist, dass Sie mit Zabbix den Reinigungszeitraum für jedes Datenelement (Metrik) einzeln festlegen können. Diese Flexibilität wird jedoch erreicht, indem die Liste der Elemente gescannt und einzelne Perioden in jeder Iteration der Haushaltsführung berechnet werden. Wenn das System individuelle Verwaltungsperioden für einzelne Elemente hat, kann das System offensichtlich nicht für alle Metriken zusammen einen einzigen Grenzwert haben, und Zabbix kann nicht den richtigen Befehl zum Löschen der erforderlichen Fragmente geben. Durch Deaktivieren des Überschreibungsverlaufs für Metriken verliert Zabbix die Möglichkeit, den Verlauf durch Aufrufen der drop_chunks () -Prozedur für history_ * -Tabellen schnell zu löschen. Wenn Sie also Override-Trends deaktivieren, verlieren Sie dieselbe Funktion für Trends_ * -Tabellen.
Mit anderen Worten, um das neue Housekeeping-System optimal nutzen zu können, müssen Sie beide Optionen global gestalten. In diesem Fall liest der Reinigungsprozess die Einstellungen der Datenelemente überhaupt nicht.
Leistung mit TimescaleDB
Es ist Zeit zu prüfen, ob all das in der Praxis wirklich funktioniert. Unser Prüfstand ist Zabbix 4.2rc1 mit PostgreSQL 10.7 und TimescaleDB 1.2.1 für Debian 9. Die Testmaschine ist ein 10-Kern-Intel Xeon mit 16 GB RAM und 60 GB Speicherplatz auf der SSD. Nach heutigen Maßstäben ist dies eine sehr bescheidene Konfiguration, aber unser Ziel ist es herauszufinden, wie effektiv TSDB im wirklichen Leben ist. In Konfigurationen mit unbegrenztem Budget können Sie einfach 128-256 GB RAM einfügen und den größten Teil (wenn nicht den gesamten) der Datenbank in den Speicher stellen.
Unsere Testkonfiguration besteht aus 32 aktiven Zabbix-Agenten, die Daten direkt an den Zabbix-Server übertragen. Jeder Agent bedient 10.000 Artikel. Der historische Zabbix-Cache ist auf 256 MB und das PG für gemeinsam genutzte Puffer auf 2 GB festgelegt. Diese Konfiguration bietet eine ausreichende Auslastung der Datenbank, verursacht jedoch gleichzeitig keine große Auslastung der Zabbix-Serverprozesse. Um die Anzahl der beweglichen Teile zwischen den Datenquellen und der Datenbank zu verringern, haben wir Zabbix Proxy nicht verwendet.
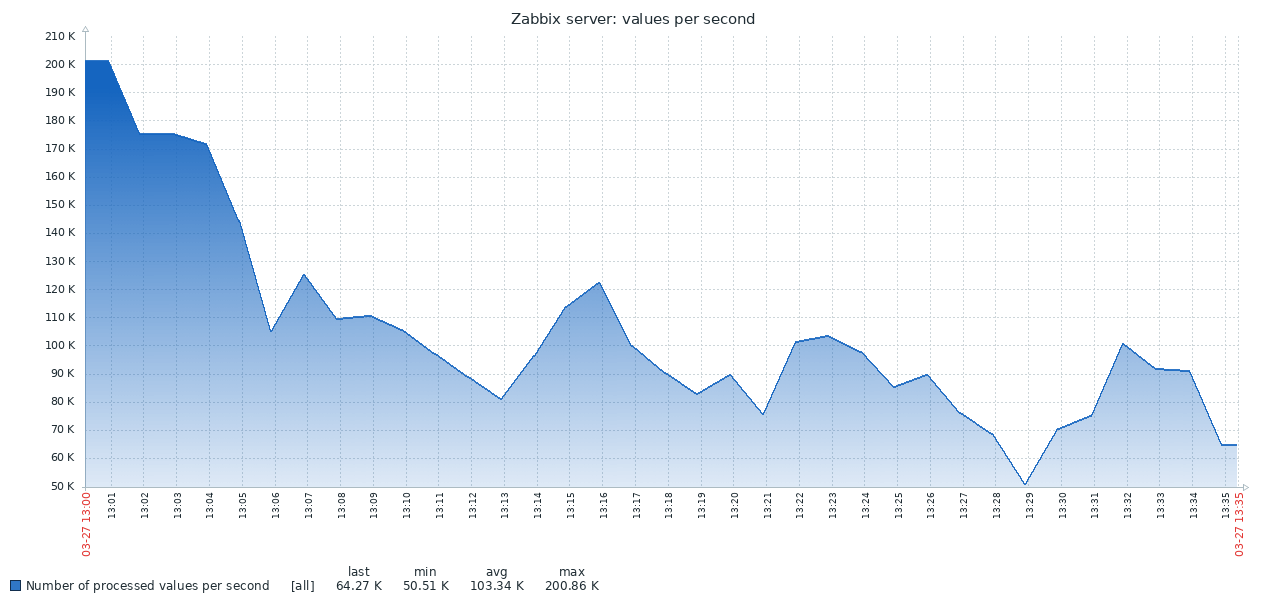
Hier ist das erste Ergebnis des Standard-PG-Systems:
Das Ergebnis der TSDB ist völlig anders:

Die folgende Grafik kombiniert beide Ergebnisse. Die Arbeit beginnt mit ziemlich hohen NVPS-Werten in 170-200K, weil Es dauert einige Zeit, bis der Verlaufscache gefüllt ist, bevor die Synchronisierung mit der Datenbank beginnt.
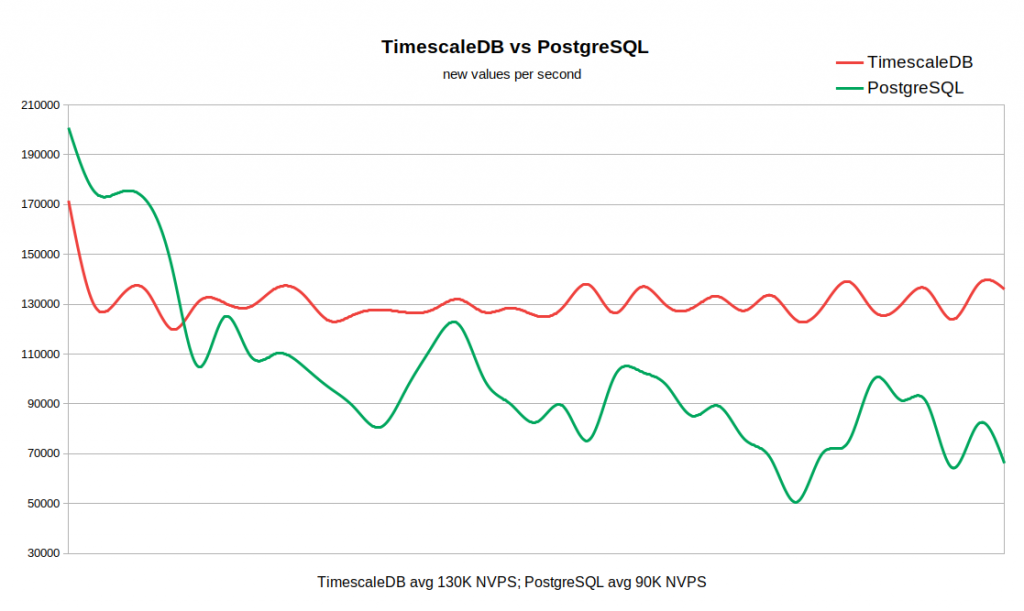
Wenn die Verlaufstabelle leer ist, ist die Schreibgeschwindigkeit in TSDB mit der Schreibgeschwindigkeit in PG vergleichbar, und dies sogar mit einem kleinen Rand davon. Sobald die Anzahl der Datensätze in der Geschichte 50-60 Millionen erreicht, sinkt der Durchsatz von PG auf 110.000 NVPS. Was jedoch unangenehmer ist, er ändert sich weiterhin umgekehrt mit der Anzahl der in der historischen Tabelle gesammelten Datensätze. Gleichzeitig behält TSDB während des gesamten Tests eine stabile Geschwindigkeit von 130 KB NVPS von 0 bis 300 Millionen Datensätzen bei.
Insgesamt ist in unserem Beispiel der Unterschied in der durchschnittlichen Leistung ziemlich signifikant (130 K gegenüber 90 K ohne Berücksichtigung des anfänglichen Peaks). Es ist auch ersichtlich, dass die Insertionsrate in Standard-PG über einen weiten Bereich variiert. Wenn für einen Workflow das Speichern von Dutzenden oder Hunderten von Millionen Datensätzen in der Historie erforderlich ist, jedoch keine Ressourcen für sehr aggressive Caching-Strategien vorhanden sind, ist TSDB ein starker Kandidat für das Ersetzen des Standard-PG.
Der Vorteil von TSDB ist für dieses relativ bescheidene System bereits offensichtlich, aber höchstwahrscheinlich wird der Unterschied bei großen Arrays historischer Daten noch deutlicher. Andererseits ist dieser Test keineswegs eine Verallgemeinerung aller möglichen Szenarien der Arbeit mit Zabbix. Natürlich gibt es viele Faktoren, die die Ergebnisse beeinflussen, wie z. B. Hardwarekonfigurationen, Betriebssystemeinstellungen, Zabbix-Servereinstellungen und zusätzliche Auslastung durch andere im Hintergrund ausgeführte Dienste. Das heißt, Ihr Kilometerstand kann variieren.
Fazit
TimescaleDB ist eine vielversprechende Technologie. Es wurde bereits erfolgreich in ernsthaften Produktionsumgebungen betrieben. TSDB funktioniert gut mit Zabbix und bietet erhebliche Vorteile gegenüber der Standard-PostgreSQL-Datenbank.
Hat TSDB irgendwelche Mängel oder Gründe, die Verwendung zu verschieben? Aus technischer Sicht sehen wir keine Argumente dagegen. Es sollte jedoch berücksichtigt werden, dass die Technologie noch neu ist, mit einem instabilen Veröffentlichungszyklus und einer unklaren Strategie für die Entwicklung von Funktionen. Insbesondere werden alle ein oder zwei Monate neue Versionen mit wesentlichen Änderungen veröffentlicht. Einige Funktionen können entfernt werden, wie dies beispielsweise beim adaptiven Chunking der Fall ist. Als weiterer Unsicherheitsfaktor ist die Lizenzpolitik zu erwähnen. Es ist sehr verwirrend, da es drei Lizenzierungsstufen gibt. Der TSDB-Kernel wird unter der Apache-Lizenz erstellt, einige Funktionen werden unter ihrer eigenen Timescale-Lizenz veröffentlicht, es gibt jedoch auch eine geschlossene Version von Enterprise.
Wenn Sie Zabbix mit PostgreSQL verwenden, gibt es keinen Grund, TimescaleDB zumindest nicht auszuprobieren. Vielleicht wird Sie dieses Ding angenehm überraschen :) Denken Sie daran, dass die Unterstützung für TimescaleDB in Zabbix noch experimentell ist - vorerst sammeln wir Nutzerkritiken und sammeln Erfahrungen.