Mit nginx zum Ausgleich des HTTP-Verkehrs auf L7-Ebene kann eine Clientanforderung an den nächsten Anwendungsserver gesendet werden, wenn das Ziel keine positive Antwort zurückgibt. Ein Test des Mechanismus der passiven Überprüfung des Integritätsstatus des Anwendungsservers ergab die Mehrdeutigkeit der Dokumentation und die Spezifität der Algorithmen zum Ausschließen des Servers aus dem Pool der Produktionsserver.
Zusammenfassung des Ausgleichs des HTTP-Verkehrs
Es gibt verschiedene Möglichkeiten, den HTTP-Verkehr auszugleichen. Auf der Ebene des OSI-Modells
gibt es Ausgleichstechnologien auf Netzwerk-, Transport- und Anwendungsebene. Abhängig von der Größe der Anwendung
können Kombinationen verwendet werden .
Die Technologie des Verkehrsausgleichs wirkt sich positiv auf die Anwendung und deren Wartung aus. Hier sind einige davon. Horizontale Skalierung der Anwendung, bei der die
Last auf mehrere Knoten verteilt wird . Geplante Außerbetriebnahme des Anwendungsservers durch Entfernen des Flusses von Clientanforderungen. Implementierung der A / B-Teststrategie für die geänderte Anwendungsfunktionalität. Verbesserung der Anwendungsfehlertoleranz durch
Senden von Anforderungen an gut funktionierende Anwendungsserver .
Die letzte Funktion ist in zwei Modi implementiert. Im passiven Modus wertet der Balancer im Clientverkehr die Antworten des Zielanwendungsservers aus und schließt sie unter bestimmten Bedingungen aus dem Pool der Produktionsserver aus. Im aktiven Modus sendet der Balancer regelmäßig unabhängig voneinander Anforderungen an den Anwendungsserver an einem bestimmten URI und beschließt, diese für bestimmte Anzeichen einer Antwort aus dem Pool der Produktionsserver auszuschließen. Anschließend gibt der Balancer unter bestimmten Bedingungen den Anwendungsserver an den Pool der Produktionsserver zurück.
Passive Überprüfung des Anwendungsservers und dessen Ausschluss aus dem Pool der Produktionsserver
Schauen wir uns die Prüfung des passiven Anwendungsservers in der Freeware-Edition von nginx / 1.17.0 genauer an. Anwendungsserver werden nacheinander vom Round Robin-Algorithmus ausgewählt, ihre Gewichte sind gleich.
Das dreistufige Diagramm zeigt einen Zeitabschnitt, der mit dem Senden einer Clientanforderung an den Anwendungsserver Nr. 2 beginnt. Ein heller Indikator kennzeichnet die Anforderungen / Antworten zwischen dem Client und dem Balancer. Dunkler Indikator - Anfragen / Antworten zwischen Nginx und Anwendungsservern.
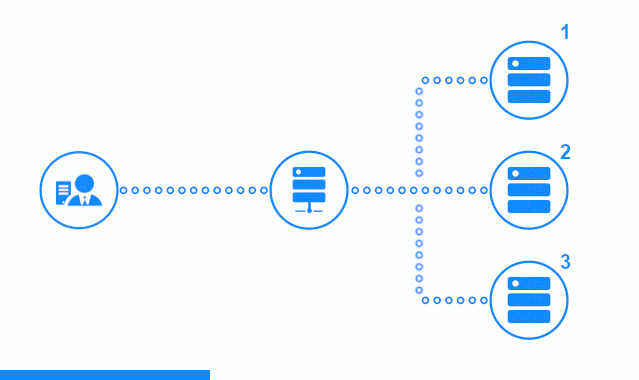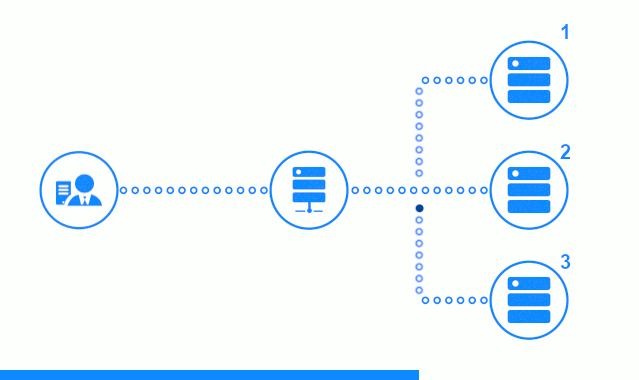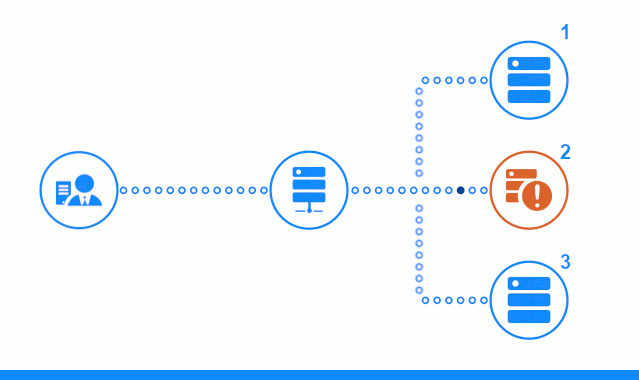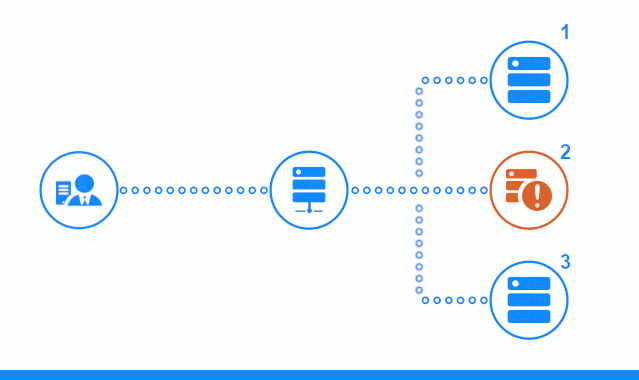
Der dritte Schritt des Diagramms zeigt, wie der Balancer die Anforderung des Clients an den nächsten Anwendungsserver umleitet, falls der Zielserver eine Fehlerantwort gegeben hat oder überhaupt nicht geantwortet hat.
Die Liste der HTTP- und TCP-Fehler, bei denen der Server den folgenden Server verwendet, ist in der Anweisung
proxy_next_upstream angegeben.
Standardmäßig leitet nginx nur
Anforderungen mit idempotenten HTTP-Methoden an den nächsten Anwendungsserver weiter.
Was bekommt der Kunde? Einerseits erhöht die Möglichkeit, eine Anforderung an den nächsten Anwendungsserver umzuleiten, die Wahrscheinlichkeit, dem Client eine zufriedenstellende Antwort zu geben, wenn der Zielserver ausfällt. Andererseits ist es offensichtlich, dass ein sequentieller Aufruf zuerst an den Zielserver und dann an den nächsten die Gesamtantwortzeit für den Client erhöht.
Am Ende wird
die Antwort des Anwendungsservers an den Client zurückgegeben
, wo der Zähler für zulässige Versuche proxy_next_upstream_tries endet .
Wenn Sie die Umleitungsfunktion zum nächsten Arbeitsserver verwenden, müssen Sie zusätzlich die Zeitüberschreitungen auf dem Balancer- und dem Anwendungsserver harmonisieren. Die Obergrenze der Zeit für eine Reiseanforderung zwischen Anwendungsservern und dem Balancer ist das Client-Timeout oder die vom Unternehmen angegebene Wartezeit. Bei der Berechnung von Zeitüberschreitungen muss auch die Marge für Netzwerkereignisse (Verzögerungen / Verluste während der Paketzustellung) berücksichtigt werden. Wenn der Client die Sitzung jedes Mal durch eine Zeitüberschreitung beendet, während der Balancer eine garantierte Antwort erhält, ist die gute Absicht, die Anwendung zuverlässig zu machen, zwecklos.

Die passive Integritätsprüfung von Anwendungsservern wird beispielsweise durch Anweisungen mit den folgenden Optionen für ihre Werte gesteuert:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
Ab dem 2. Juli
2019 wurde in der Dokumentation
festgelegt, dass der Parameter
max_fails die Anzahl der erfolglosen Versuche festlegt, mit dem Server zu arbeiten, die innerhalb der durch den Parameter
fail_timeout angegebenen Zeit
erfolgen sollen .
Der Parameter
fail_timeout legt die Zeit fest, in der die angegebene Anzahl erfolgloser Versuche, mit dem Server zu arbeiten, erfolgen muss, damit der Server als nicht verfügbar betrachtet wird. und die Zeit, in der der Server als nicht verfügbar betrachtet wird.
In dem angegebenen Beispiel, das Teil der Konfigurationsdatei ist, ist der Balancer so konfiguriert, dass innerhalb von 100 Sekunden 5 fehlgeschlagene Anrufe abgefangen werden.
Zurückgeben des Anwendungsservers an den Produktionsserverpool
Wie aus der Dokumentation hervorgeht, kann der Balancer nach
fail_timeout den Server nicht als nicht funktionsfähig betrachten. Leider wird in der Dokumentation nicht explizit festgelegt, wie die Serverleistung bewertet wird.
Ohne ein Experiment kann man nur annehmen, dass der Mechanismus zum Überprüfen des Zustands dem zuvor beschriebenen ähnlich ist.
Erwartungen und Realität
In der dargestellten Konfiguration wird vom Balancer das folgende Verhalten erwartet:
- Bis der Balancer den Anwendungsserver Nr. 2 aus dem Pool der Produktionsserver ausschließt, werden Clientanforderungen an ihn gesendet.
- Anforderungen, die mit einem Fehler von 500 vom Anwendungsserver Nr. 2 zurückgegeben wurden, werden an den nächsten Anwendungsserver weitergeleitet, und der Client erhält positive Antworten.
- Sobald der Balancer innerhalb von 100 Sekunden 5 Antworten mit Code 500 erhält, wird der Anwendungsserver Nr. 2 aus dem Pool der Produktionsserver ausgeschlossen. Alle Anforderungen nach einem 100-Sekunden-Fenster werden ohne zusätzliche Zeit sofort an die verbleibenden funktionierenden Anwendungsserver gesendet.
- Nach 100 Sekunden muss der Balancer die Leistung des Anwendungsservers bewerten und an den Pool der Produktionsserver zurückgeben.
Nach Durchführung von Sachversuchen wurde nach Angaben der Balancer-Magazine festgestellt, dass Aussage Nr. 3 nicht funktioniert. Der Balancer schließt einen
inaktiven Server aus, sobald die Bedingung für den Parameter
max_fails erfüllt ist . Somit wird ein ausgefallener Server vom Dienst ausgeschlossen, ohne auf den Ablauf von 100 Sekunden zu warten. Der Parameter
fail_timeout spielt nur die Rolle der Obergrenze der
Fehlerakkumulationszeit .
Als Teil der Behauptung Nr. 4 stellt sich heraus, dass nginx die Funktionalität einer Anwendung, die zuvor von der Serverwartung ausgeschlossen war, mit nur einer Anforderung überprüft. Und wenn der Server immer noch mit einem Fehler antwortet,
schlägt die nächste Prüfung nach
fail_timeout fehl .
Was fehlt?
- Der in nginx / 1.17.0 implementierte Algorithmus ist möglicherweise nicht die fairste Methode, um die Leistung des Servers zu überprüfen, bevor er an den funktionierenden Serverpool zurückgegeben wird. Zumindest wird gemäß der aktuellen Dokumentation nicht 1 Anforderung erwartet, sondern der in max_fails angegebene Betrag .
- Der Statusprüfungsalgorithmus berücksichtigt nicht die Geschwindigkeit von Anforderungen. Je größer es ist, desto stärker verschiebt sich das Spektrum bei erfolglosen Versuchen nach links, und der Anwendungsserver verlässt den Arbeitsserverpool zu schnell. Ich nehme an, dass dies sich nachteilig auf Anwendungen auswirken kann, die es sich erlauben, Fehler „kurzzeitig“ zu erzeugen. Zum Beispiel beim Sammeln von Müll.

Ich wollte Sie fragen, ob der Algorithmus zur Überprüfung des Serverzustands, der die Geschwindigkeit fehlgeschlagener Versuche misst, einen praktischen Nutzen bringt.