In der
vorherigen Version habe ich das Framework für die Netzwerkautomatisierung beschrieben. Nach Einschätzung einiger Leute hat bereits diese erste Herangehensweise an das Problem bereits einige Fragen in die Regale gestellt. Und das freut mich sehr, denn unser Ziel im Zyklus ist es nicht, das Ansible mit Python-Skripten abzudecken, sondern ein System aufzubauen.
Der gleiche Rahmen legt die Reihenfolge fest, in der wir uns mit der Frage befassen.
Und die Netzwerkvirtualisierung, der dieses Problem gewidmet ist, passt nicht wirklich in das ADSM-Thema, in dem wir die Automatisierung analysieren.
Aber schauen wir es uns aus einem anderen Blickwinkel an.
Schon lange nutzen viele Dienste ein Netzwerk. Bei einem Netzbetreiber handelt es sich beispielsweise um 2G, 3G, LTE, Breitband und B2B. Im Fall von DC: Konnektivität für verschiedene Clients, Internet, Blockspeicher, Objektspeicher.
Und alle Dienste müssen voneinander isoliert sein. Es erschienen also Overlay-Netzwerke.
Und alle Dienste möchten nicht darauf warten, dass eine Person sie manuell konfiguriert. So erschienen Orchestratoren und SDN.
Der erste Ansatz zur systematischen Automatisierung des Netzwerks oder vielmehr von Teilen davon wurde lange Zeit verfolgt und an vielen Stellen implementiert: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Hier beschäftigen wir uns heute mit ihm.

Inhalt
- Gründe
- Terminologie
- Unterlage - Physikalisches Netzwerk
- Overlay - virtuelles Netzwerk
- Überlagerung mit ToR
- Überlagerung vom Host
- Fallstudie Wolframgewebe
- Kommunikation innerhalb einer physischen Maschine
- Kommunikation zwischen VMs auf verschiedenen physischen Computern
- Gehe nach außen
- FAQ
- Fazit
- Nützliche Links
Gründe
Und da wir darüber gesprochen haben, sollten die Voraussetzungen für die Netzwerkvirtualisierung erwähnt werden. Tatsächlich hat dieser Prozess gestern nicht begonnen.
Sie haben wahrscheinlich mehr als einmal gehört, dass das Netzwerk immer der inerteste Teil eines Systems war. Und das ist in jeder Hinsicht wahr. Ein Netzwerk ist die Basis, auf der alles basiert, und es ist ziemlich schwierig, Änderungen daran vorzunehmen - Dienste tolerieren es nicht, wenn das Netzwerk liegt. Die Außerbetriebnahme eines einzelnen Knotens kann häufig die meisten Anwendungen summieren und viele Clients betreffen. Dies ist teilweise der Grund, warum das Netzwerkteam Änderungen widerstehen kann - denn jetzt funktioniert es irgendwie (
wir wissen vielleicht nicht einmal wie ), aber hier müssen wir etwas Neues konfigurieren, und es ist nicht bekannt, wie sich dies auf das Netzwerk auswirkt.
Um nicht darauf zu warten, dass Netzwerkanbieter VLANs weiterleiten und keine Dienste auf jedem Netzwerkknoten registrieren, haben sich die Benutzer für Overlays entschieden - überlagerte Netzwerke - von denen es eine große Vielfalt gibt: GRE, IPinIP, MPLS, MPLS L2 / L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE usw.
Ihre Anziehungskraft liegt in zwei einfachen Dingen:
- Es werden nur Endknoten konfiguriert - Sie müssen keine Transitknoten berühren. Dies beschleunigt den Prozess erheblich und ermöglicht es Ihnen manchmal sogar, die Netzwerkinfrastrukturabteilung von der Einführung neuer Dienste auszuschließen.
- Die Last ist tief in den Headern versteckt - Transitknoten müssen nichts darüber wissen, über die Adressierung auf Hosts, Routen des auferlegten Netzwerks. Dies bedeutet, dass Sie weniger Informationen in den Tabellen speichern müssen. Nehmen Sie also ein einfacheres / billigeres Gerät.
In dieser nicht ganz vollständigen Ausgabe habe ich nicht vor, alle möglichen Technologien zu analysieren, sondern den Rahmen für den Betrieb von Overlay-Netzwerken in DCs zu beschreiben.
Die gesamte Serie beschreibt ein Rechenzentrum, das aus Reihen ähnlicher Racks besteht, in denen dieselbe Serverausrüstung installiert ist.
Auf diesem Gerät werden virtuelle Maschinen / Container / Serverless ausgeführt, die Dienste implementieren.

Terminologie
In der Schleife werde ich den
Server als Programm bezeichnen, das die Serverseite der Client-Server-Kommunikation implementiert.
Physische Maschinen in Racks werden
nicht als Server bezeichnet.
Die physische Maschine ist ein x86-Rack-Computer. Am häufigsten verwenden wir den Begriff
Host . Also werden wir es "
Maschine " oder
Host nennen .
Ein Hypervisor ist eine Anwendung, die auf einem physischen Computer ausgeführt wird und die physischen Ressourcen emuliert, auf denen virtuelle Maschinen ausgeführt werden. Manchmal wird in der Literatur und im Netzwerk das Wort "Hypervisor" als Synonym für "Host" verwendet.
Eine virtuelle Maschine ist ein Betriebssystem, das auf einer physischen Maschine über einem Hypervisor ausgeführt wird. Für uns ist es im Rahmen dieses Zyklus nicht so wichtig, ob es sich tatsächlich um eine virtuelle Maschine oder nur um einen Container handelt. Wir werden es "
VM " nennen
Mandant ist ein umfassendes Konzept, das ich in diesem Artikel als separaten Service oder separaten Client definieren werde.
Mandantenfähigkeit oder Mandantenfähigkeit - die Verwendung derselben Anwendung durch verschiedene Clients / Dienste. Gleichzeitig wird durch die Architektur der Anwendung und nicht durch separat ausgeführte Instanzen eine Isolierung der Clients voneinander erreicht.
ToR - Top of the Rack-Switch - Ein am Rack montierter Switch, an den alle physischen Maschinen angeschlossen sind.
Zusätzlich zur ToR-Topologie praktizieren verschiedene Anbieter End of Row (EoR) oder Middle of Row (obwohl letzteres eine abweisende Seltenheit ist und ich die Abkürzungen MoR nicht gesehen habe).
Underlay-Netzwerk oder zugrunde liegendes Netzwerk oder Underlay - physische Netzwerkinfrastruktur: Switches, Router, Kabel.
Overlay-Netzwerk oder Overlay-Netzwerk oder Overlay - ein virtuelles Netzwerk von Tunneln, das über einem physischen Netzwerk ausgeführt wird.
L3-Factory oder IP-Factory ist eine enorme Erfindung der Menschheit, die es Interviews ermöglicht, STP nicht zu wiederholen und TRILL nicht zu lernen. Ein Konzept, bei dem das gesamte Netzwerk bis zur Zugriffsebene ausschließlich L3 ist, ohne VLANs und entsprechend große gestreckte Broadcast-Domänen. Woher kommt das Wort "Fabrik" im nächsten Teil?
SDN - Software Defined Network. Braucht kaum eine Einführung. Ein Ansatz zur Netzwerkverwaltung, wenn Änderungen am Netzwerk nicht von einer Person, sondern von einem Programm durchgeführt werden. Normalerweise bedeutet dies, dass die Steuerebene über die Endnetzwerkgeräte hinaus zur Steuerung verschoben wird.
NFV - Network Function Virtualization - Virtualisierung von Netzwerkgeräten, bei der davon ausgegangen wird, dass ein Teil der Netzwerkfunktionen in Form von virtuellen Maschinen oder Containern gestartet werden kann, um die Implementierung neuer Dienste zu beschleunigen, die Verkettung von Diensten zu organisieren und die horizontale Skalierbarkeit zu vereinfachen.
VNF - Virtuelle Netzwerkfunktion. Spezifisches virtuelles Gerät: Router, Switch, Firewall, NAT, IPS / IDS usw.
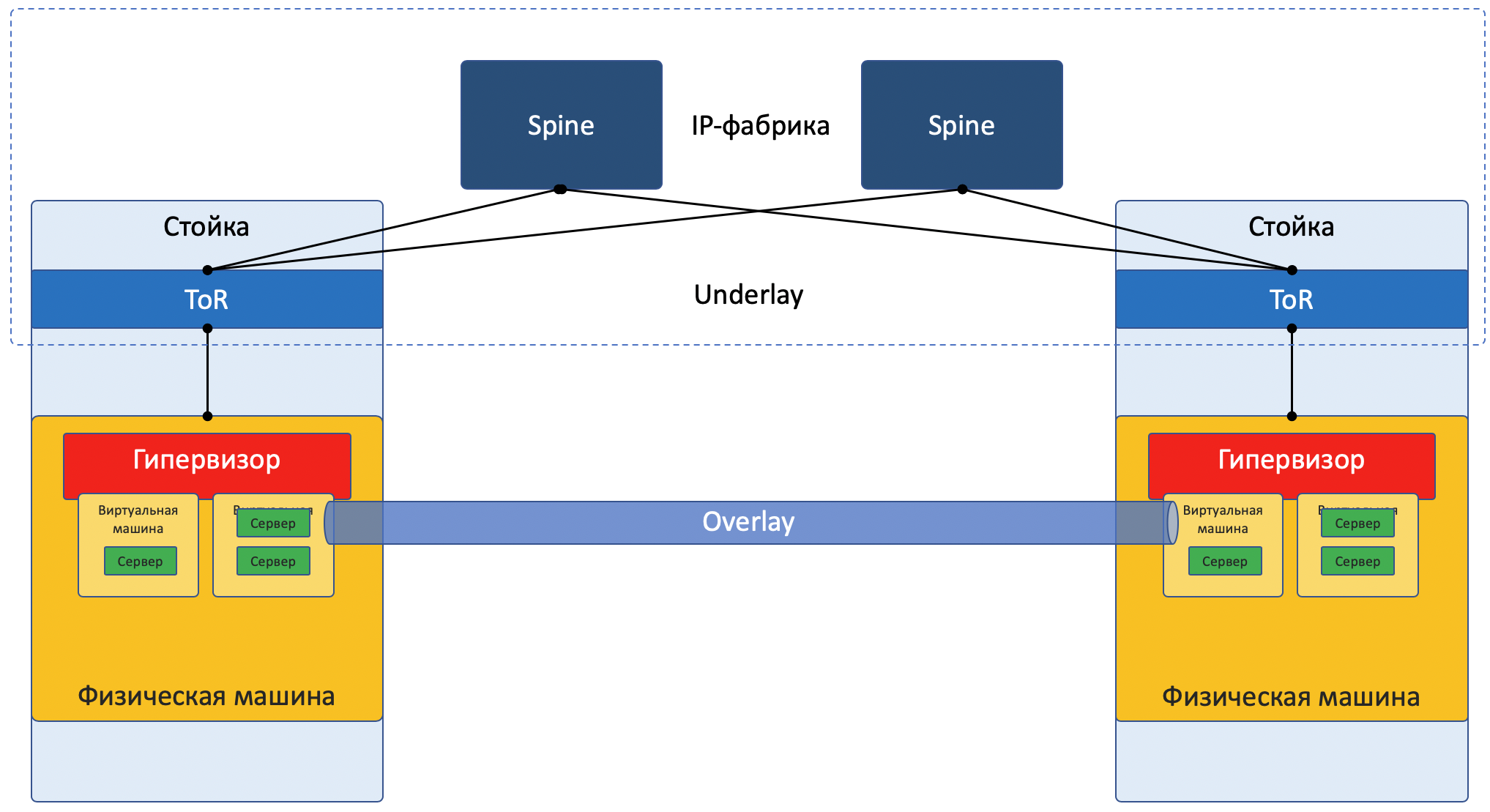
Ich vereinfache jetzt absichtlich die Beschreibung auf eine bestimmte Implementierung, um den Leser nicht viel zu verwirren. Für eine gründlichere Lektüre senden Sie es an den Abschnitt Links . Darüber hinaus verspricht Roma Gorge, der diesen Artikel wegen Ungenauigkeiten kritisiert, ein separates Problem zu Server- und Netzwerkvirtualisierungstechnologien zu schreiben, das sich eingehender und detaillierter mit Details befasst.
Die meisten Netzwerke können heute klar in zwei Teile unterteilt werden:
Unterlage - ein physisches Netzwerk mit einer stabilen Konfiguration.
Überlagerung - Abstraktion über Unterlage, um Mieter zu isolieren.
Dies gilt sowohl für den Fall von DC (den wir in diesem Artikel analysieren werden) als auch für ISP (den wir nicht analysieren werden, da er bereits in
SDSM enthalten war ). Bei Unternehmensnetzwerken ist die Situation natürlich etwas anders.
Netzwerkfokus Bild:

Unterlage
Unterlage ist ein physisches Netzwerk: Hardware-Switches und Kabel. Geräte in der Unterlage wissen, wie sie zu physischen Maschinen gelangen.
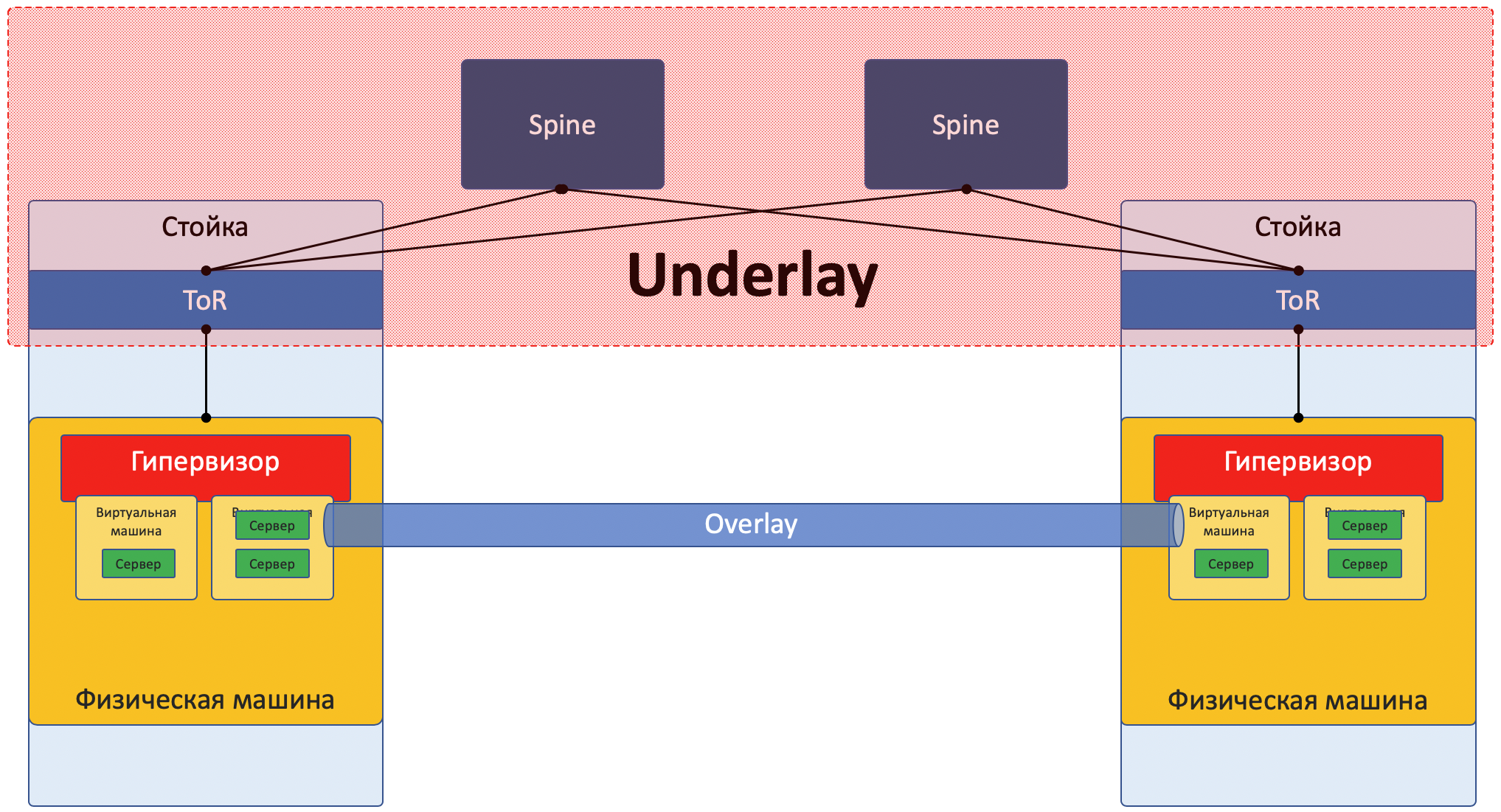
Es basiert auf Standardprotokollen und -technologien. Nicht zuletzt, weil die Hardwaregeräte immer noch mit proprietärer Software arbeiten, die weder die Chipprogrammierung noch die Implementierung ihrer Protokolle ermöglicht, sind Kompatibilität mit anderen Anbietern und Standardisierung erforderlich.
Aber jemand wie Google kann es sich leisten, eigene Switches zu entwickeln und die allgemein akzeptierten Protokolle aufzugeben. LAN_DC ist jedoch nicht Google.
Die Unterlage wird relativ selten geändert, da ihre Aufgabe die grundlegende IP-Konnektivität zwischen physischen Maschinen ist. Underlay weiß nichts über darauf laufende Services, Clients, Mandanten - es muss nur ein Paket von einem Computer auf einen anderen geliefert werden.
Die Unterlage kann folgendermaßen aussehen:
- IPv4 + OSPF
- IPv6 + ISIS + BGP + L3VPN
- L2 + TRILL
- L2 + STP
Das Underlay-Netzwerk wird auf klassische Weise konfiguriert: CLI / GUI / NETCONF.
Manuell Skripte, proprietäre Dienstprogramme.
Im Detail wird der nächste Artikel der Reihe der Unterlage gewidmet sein.
Überlagerung
Overlay - Ein virtuelles Tunnelnetzwerk, das sich über Underlay erstreckt und es den VMs eines Clients ermöglicht, miteinander zu kommunizieren und gleichzeitig von anderen Clients isoliert zu sein.
Clientdaten werden in beliebigen Tunnel-Headern zur Übertragung über ein gemeinsam genutztes Netzwerk gekapselt.

So können die VMs eines Clients (eines Dienstes) über Overlay miteinander kommunizieren, ohne zu wissen, was das Paket tatsächlich enthält.
Die Überlagerung kann beispielsweise dieselbe sein wie oben erwähnt:
- GRE-Tunnel
- VXLAN
- EVPN
- L3VPN
- GENF
Ein Overlay-Netzwerk wird normalerweise über eine zentrale Steuerung konfiguriert und verwaltet. Daraus werden die Konfiguration, die Steuerebene und die Datenebene an Geräte geliefert, die den Clientverkehr weiterleiten und kapseln.
Im Folgenden werden wir dies anhand von Beispielen analysieren.
Ja, das ist reines SDN.Es gibt zwei grundlegend unterschiedliche Ansätze zum Organisieren eines Overlay-Netzwerks:
- Überlagerung mit ToR
- Überlagerung vom Host
Überlagerung mit ToR
Die Überlagerung kann bei einem am Rack montierten Zugriffsschalter (ToR) beginnen, wie dies beispielsweise bei einer VXLAN-Factory der Fall ist.
Dies ist ein bewährter Mechanismus in ISP-Netzwerken, den alle Anbieter von Netzwerkgeräten unterstützen.
In diesem Fall muss der ToR-Switch jedoch jeweils unterschiedliche Dienste gemeinsam nutzen können, und der Netzwerkadministrator muss in gewissem Umfang mit den Administratoren virtueller Maschinen zusammenarbeiten und Änderungen (wenn auch automatisch) an der Gerätekonfiguration vornehmen.
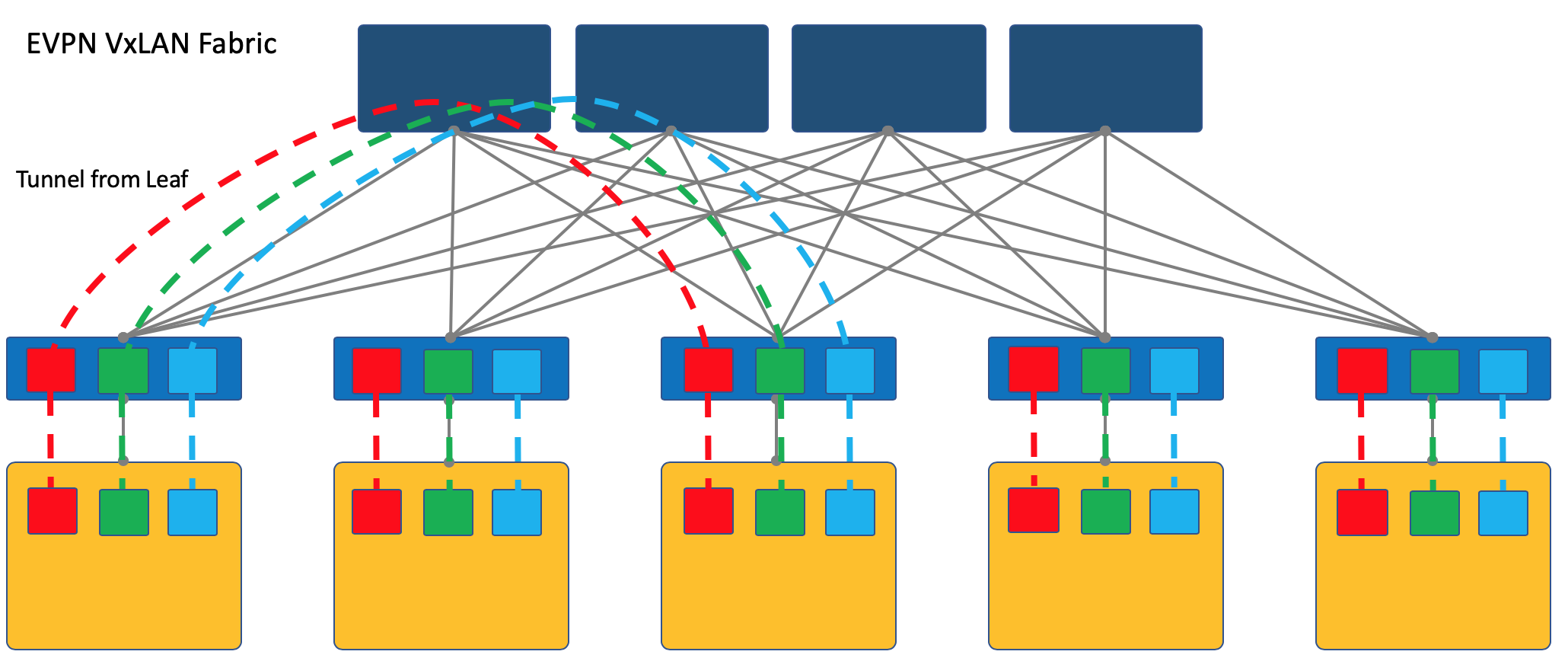
Hier verweise ich den Leser auf einen Artikel über
VxLAN im Hub unseres alten Freundes
@bormoglotx .
In dieser
Präsentation mit ENOG werden Ansätze zum Aufbau eines DC-Netzwerks mit einer EVPN VXLAN-Factory ausführlich beschrieben.
Und für ein vollständigeres Eintauchen in die Realität können Sie das Buch
A Modern, Open and Scalable Fabric: VXLAN EVPN lesen .
Ich stelle fest, dass VXLAN nur eine Kapselungsmethode ist und die Tunnelbeendigung nicht auf ToR, sondern auf dem Host erfolgen kann, wie dies beispielsweise bei OpenStack der Fall ist.
Die VXLAN-Factory, in der Overlay auf ToR beginnt, ist jedoch eines der etablierten Overlay-Netzwerkdesigns.
Überlagerung vom Host
Ein anderer Ansatz besteht darin, Tunnel auf den Endhosts zu starten und zu beenden.
In diesem Fall bleibt das Netzwerk (Underlay) so einfach und statisch wie möglich.
Und der Host selbst führt alle erforderlichen Kapselungen durch.
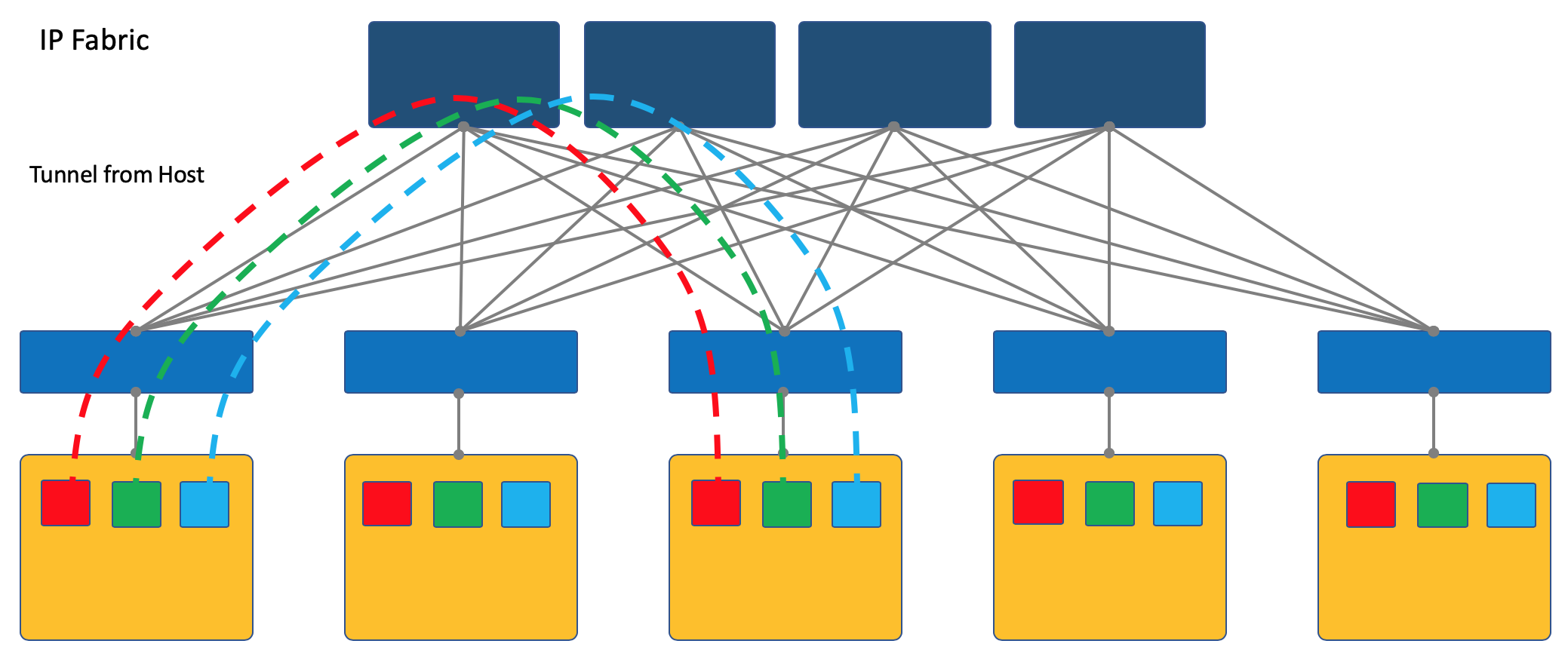
Dazu müssen Sie sicherlich eine spezielle Anwendung auf den Hosts ausführen, aber es lohnt sich.
Erstens ist das Ausführen eines Clients auf einem Linux-Computer einfacher oder, sagen wir, allgemein möglich, während Sie sich auf dem Switch befinden, müssen Sie sich höchstwahrscheinlich vorerst an proprietäre SDN-Lösungen wenden, was die Idee eines Multi-Anbieters zunichte macht.
Zweitens kann der ToR-Schalter in diesem Fall sowohl aus Sicht der Steuerebene als auch der Datenebene so einfach wie möglich belassen werden. In der Tat - dann muss er nicht mit dem SDN-Controller kommunizieren und die Netzwerke / ARPs aller verbundenen Clients speichern - kennt er auch nur die IP-Adresse der physischen Maschine, was die Switching- / Routing-Tabellen erheblich vereinfacht.
In der ADSM-Serie wähle ich den Overlay-Ansatz vom Host aus - dann sprechen wir nur darüber und werden nicht zur VXLAN-Factory zurückkehren.
Der einfachste Weg, um die Beispiele zu betrachten. Als Testperson nehmen wir die OpenSource SDN OpenContrail-Plattform, die jetzt als
Tungsten Fabric bekannt ist .
Am Ende des Artikels werde ich einige Gedanken zur Analogie mit OpenFlow und OpenvSwitch machen.
Fallstudie Wolframgewebe
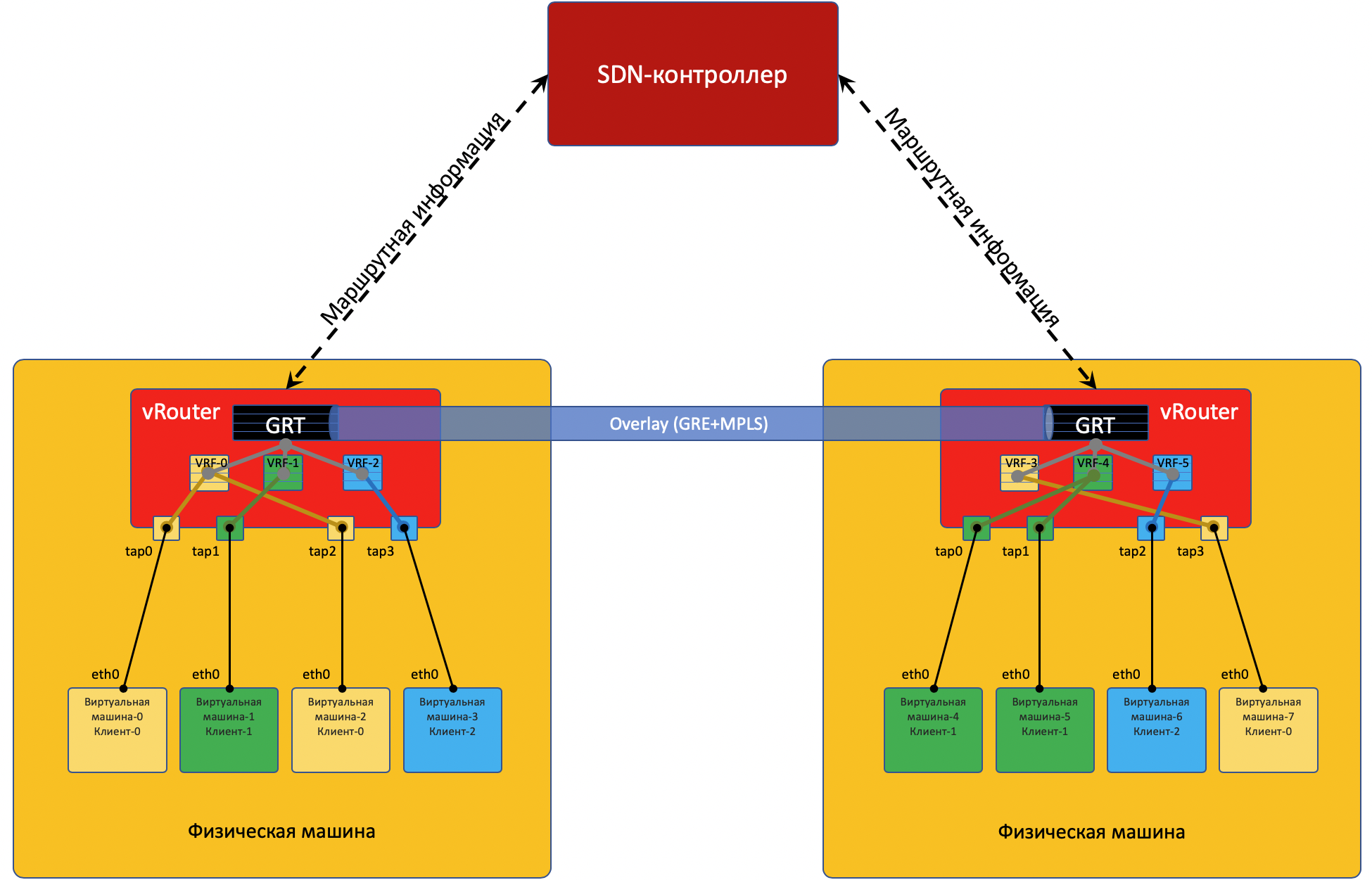
Jede physische Maschine verfügt über einen
vRouter - einen virtuellen Router, der die mit ihr verbundenen Netzwerke kennt und weiß, zu welchen Clients sie gehören - tatsächlich ein PE-Router. Für jeden Client wird eine isolierte Routing-Tabelle verwaltet (VRF lesen). Und tatsächlich führt vRouter Overlay-Tunneling durch.
Ein wenig mehr über vRouter finden Sie am Ende des Artikels.
Jede auf dem Hypervisor befindliche VM ist über die
TAP-Schnittstelle mit dem vRouter dieses Computers verbunden.
TAP - Terminal Access Point - eine virtuelle Schnittstelle im Linux-Kernel, die die Vernetzung ermöglicht.

Befinden sich hinter dem vRouter mehrere Netzwerke, wird für jedes Netzwerk eine virtuelle Schnittstelle erstellt, der eine IP-Adresse zugewiesen ist. Dies ist die Standard-Gateway-Adresse.
Alle Netzwerke eines Clients werden in einer
VRF (einer Tabelle) platziert, unterschiedlich - in unterschiedlich.
Ich werde hier eine Reservierung machen, dass es nicht so einfach ist, und den neugierigen Leser an das Ende des Artikels schicken .
Damit vRouter'y miteinander kommunizieren kann und dementsprechend hinter ihnen befindliche VMs, tauschen sie Routing-Informationen über einen
SDN-Controller aus .
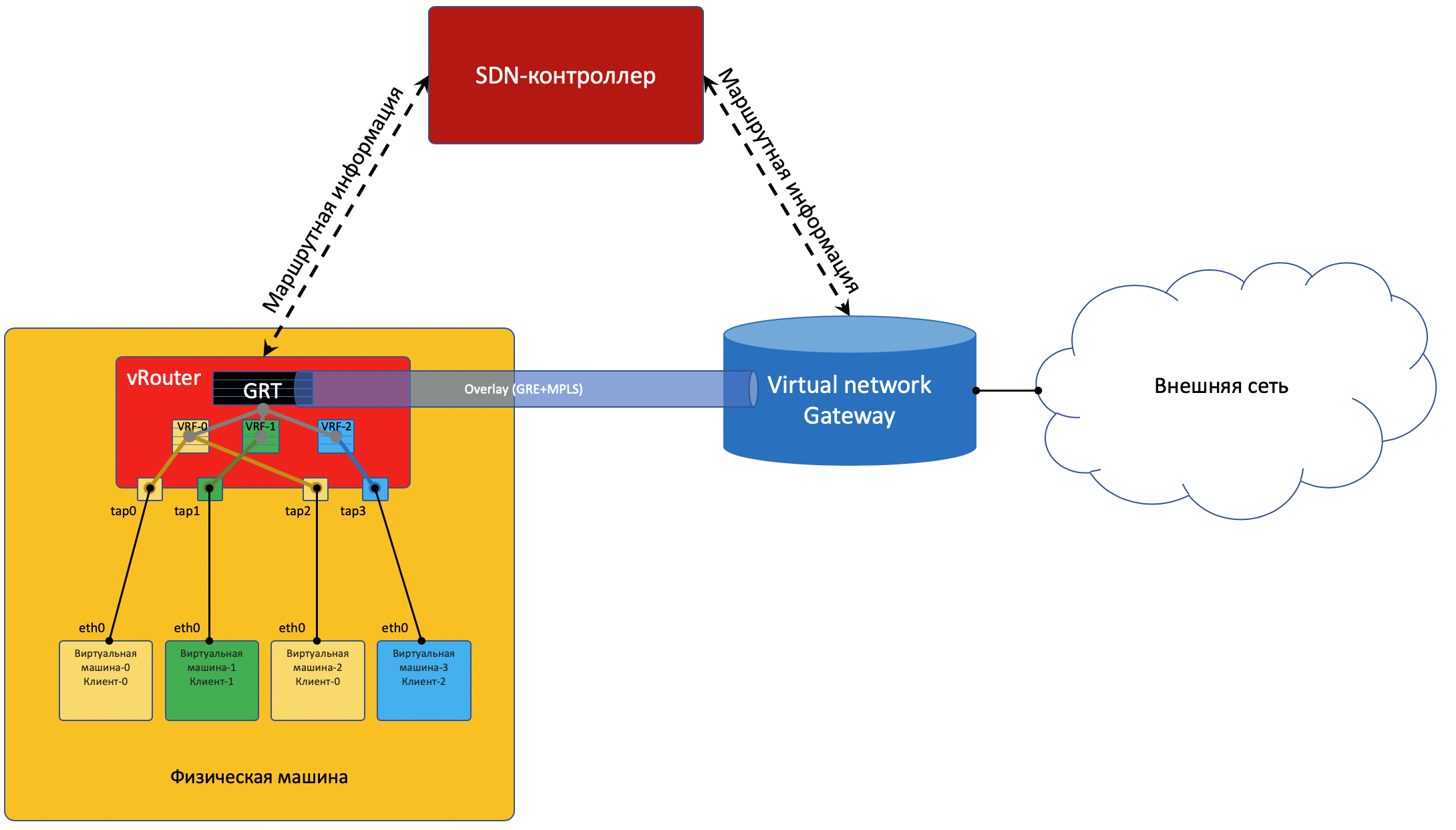
Um in die Außenwelt zu gelangen, gibt es einen Austrittspunkt aus der Matrix - das virtuelle Netzwerk-Gateway
VNGW - Virtual Network GateWay (
mein Begriff ).
Betrachten Sie nun die Beispiele für Kommunikation - und es wird Klarheit geben.
Kommunikation innerhalb einer physischen Maschine
VM0 möchte ein Paket an VM2 senden. Angenommen, dies ist eine einzelne Client-VM.
Datenebene
- VM-0 hat eine Standardroute in seiner eth0-Schnittstelle. Das Paket wird dorthin gesendet.
Diese eth0-Schnittstelle ist über die tap0-TAP-Schnittstelle virtuell mit dem virtuellen vRouter-Router verbunden. - vRouter analysiert, zu welcher Schnittstelle das Paket gelangt ist, dh zu welchem Client (VRF) es gehört, und überprüft die Empfängeradresse anhand der Routing-Tabelle dieses Clients.
- Nachdem vRouter festgestellt hat, dass sich der Empfänger auf demselben Computer hinter einem anderen Port befindet, sendet er das Paket einfach ohne zusätzliche Header an ihn. In diesem Fall verfügt der vRouter bereits über einen ARP-Eintrag.
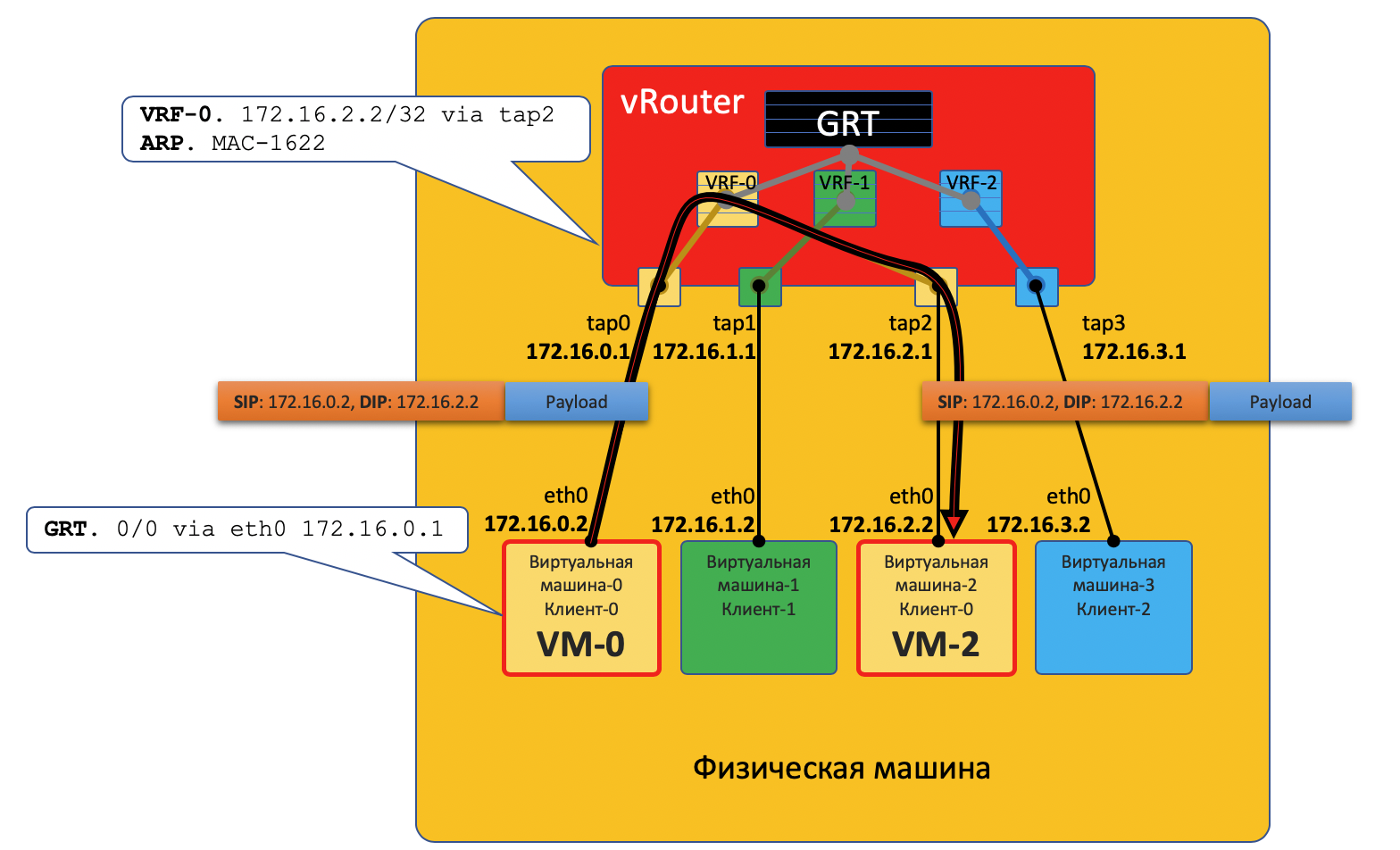
In diesem Fall gelangt das Paket nicht in das physische Netzwerk, sondern wird in vRouter weitergeleitet.
Steuerebene
Wenn die virtuelle Maschine gestartet wird, teilt der Hypervisor ihr Folgendes mit:
- Ihre eigene IP-Adresse.
- Die Standardroute führt über die IP-Adresse des vRouter in diesem Netzwerk.
Über eine spezielle API berichtet der Hypervisor an vRouter:
- Was Sie benötigen, um eine virtuelle Schnittstelle zu erstellen.
- Welche (VM) benötigt, um ein virtuelles Netzwerk zu erstellen.
- An welche VRF soll es gebunden werden (VN).
- Der statische ARP-Datensatz für diese VM gibt an, an welche Schnittstelle die IP-Adresse und an welche MAC-Adresse sie angehängt ist.
Auch hier wird das eigentliche Interaktionsverfahren vereinfacht, um das Konzept zu verstehen.

Somit sieht vRouter alle VMs eines Clients auf einem bestimmten Computer als direkt verbundene Netzwerke an und kann zwischen ihnen selbst routen.
VM0 und VM1 gehören jedoch zu unterschiedlichen Clients und befinden sich in unterschiedlichen Tabellen vRouter'a.
Ob sie direkt miteinander kommunizieren können, hängt von den vRouter-Einstellungen und dem Netzwerkdesign ab.
Wenn beispielsweise die VMs beider Clients öffentliche Adressen verwenden oder NAT auf dem vRouter selbst auftritt, kann auch ein direktes Routing an vRouter durchgeführt werden.
In der umgekehrten Situation ist es möglich, Adressräume zu überqueren - Sie müssen einen NAT-Server durchlaufen, um eine öffentliche Adresse zu erhalten - dies ähnelt dem Zugriff auf externe Netzwerke, die unten beschrieben werden.
Kommunikation zwischen VMs auf verschiedenen physischen Computern
Datenebene
- Der Anfang ist genau der gleiche: VM-0 sendet standardmäßig ein Paket mit dem Ziel VM-7 (172.17.3.2).
- vRouter empfängt es und sieht diesmal, dass sich das Ziel auf einem anderen Computer befindet und über den Tunneltunnel0 erreichbar ist.
- Zunächst wird das MPLS-Etikett zur Identifizierung der Remote-Schnittstelle aufgehängt, sodass auf der Rückseite von vRouter festgelegt werden kann, wo dieses Paket ohne zusätzliche Hooks abgelegt werden soll.

- Tunnel0 hat eine Quelle von 10.0.0.2, der Empfänger: 10.0.1.2.
vRouter fügt dem ursprünglichen Paket GRE- (oder UDP-) Header und eine neue IP hinzu. - Die vRouter-Routing-Tabelle enthält eine Standardroute über die Adresse ToR1 10.0.0.1. Dort und sendet.
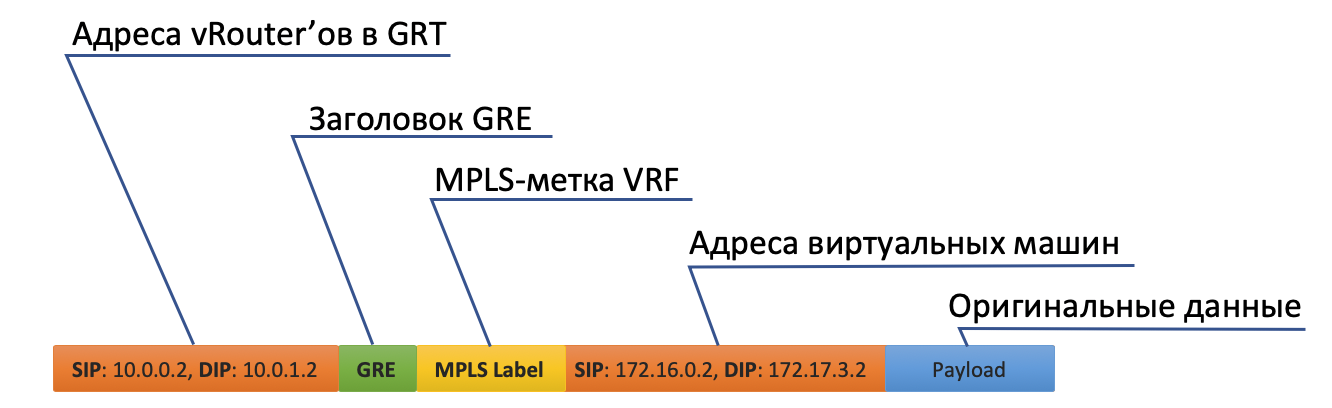
- ToR1 als Mitglied des Underlay-Netzwerks weiß (z. B. über OSPF), wie man zu 10.0.1.2 gelangt, und sendet ein Paket entlang der Route. Bitte beachten Sie, dass ECMP hier enthalten ist. In der Abbildung gibt es zwei Nexsthops, in denen durch Hash unterschiedliche Streams angeordnet sind. Im Falle einer echten Fabrik wird es wahrscheinlich 4 Nextops geben.
Gleichzeitig muss er nicht wissen, was sich unter dem externen IP-Header befindet. Das heißt, unter IP kann es ein Sandwich von IPv6 über MPLS über Ethernet über MPLS über GRE über über Griechisch geben. - Dementsprechend entfernt vRouter auf der Empfangsseite GRE und versteht anhand des MPLS-Labels, an welche Schnittstelle dieses Paket gesendet werden soll, entfernt es und sendet es in seiner ursprünglichen Form an den Empfänger.
Steuerebene
Wenn Sie die Maschine starten, ist alles, was passiert, oben beschrieben.
Und dazu noch Folgendes:
- VRouter weist jedem Client ein MPLS-Tag zu. Dies ist das L3VPN-Service-Label, bei dem Kunden auf dieselbe physische Maschine aufgeteilt werden.
Tatsächlich wird das MPLS-Tag immer vom vRouter'om zugewiesen - schließlich ist nicht im Voraus bekannt, dass der Computer nur mit anderen Computern hinter demselben vRouter'om interagiert, und dies ist höchstwahrscheinlich nicht einmal der Fall.
- vRouter stellt über BGP eine Verbindung zum SDN-Controller her (oder ähnlich - im Fall von TF ist dies XMPP 0_o).
- Während dieser Sitzung teilt vRouter dem SDN-Controller die Routen zu den verbundenen Netzwerken mit:
- Netzwerkadresse
- Verkapselungsmethode (MPLSoGRE, MPLSoUDP, VXLAN)
- Client-MPLS-Label
- Ihre IP-Adresse als Nexthop
- Der SDN-Controller empfängt solche Routen von allen verbundenen vRouter'ov und gibt sie an andere weiter. Das heißt, er fungiert als Routenreflektor.
Das gleiche passiert in die entgegengesetzte Richtung.

Die Überlagerung kann sich mindestens jede Minute ändern. So etwas passiert in öffentlichen Clouds, wenn Clients ihre virtuellen Maschinen regelmäßig starten und ausschalten.
Die zentrale Steuerung übernimmt alle Schwierigkeiten bei der Pflege der Konfiguration und der Steuerung der Switching- / Routing-Tabellen auf vRouter.Grob gesagt fährt der Controller mit allen vRoutern über BGP (oder ein ähnliches Protokoll) herunter und überträgt einfach Routing-Informationen. BGP verfügt beispielsweise bereits über eine Adressfamilie zum Übertragen der MPLS-in-GRE- oder MPLS-in-UDP- Kapselungsmethode .Gleichzeitig ändert sich die Konfiguration des Underlay-Netzwerks in keiner Weise, was im Übrigen viel schwieriger zu automatisieren ist und es einfacher ist, mit einer unangenehmen Bewegung zu brechen.
Gehe nach außen
Irgendwo sollte die Simulation enden und von der virtuellen Welt aus müssen Sie in die reale gehen. Und Sie brauchen ein Münztelefon- Gateway.Es werden zwei Ansätze praktiziert:- Ein Hardware-Router ist installiert.
- - appliance, (-, SDN VNF ). .
— — . , , , , , , , , , .
, , , , ( ). , - , , — .
Mit einem Fuß blickt das Gateway wie eine normale virtuelle Maschine in das virtuelle Overlay-Netzwerk und kann mit allen anderen VMs interagieren. Gleichzeitig kann es die Netzwerke aller Clients auf sich selbst terminieren und dementsprechend ein Routing zwischen ihnen durchführen.Mit dem anderen Fuß schaut das Gateway bereits auf das Backbone-Netzwerk und weiß, wie man zum Internet gelangt.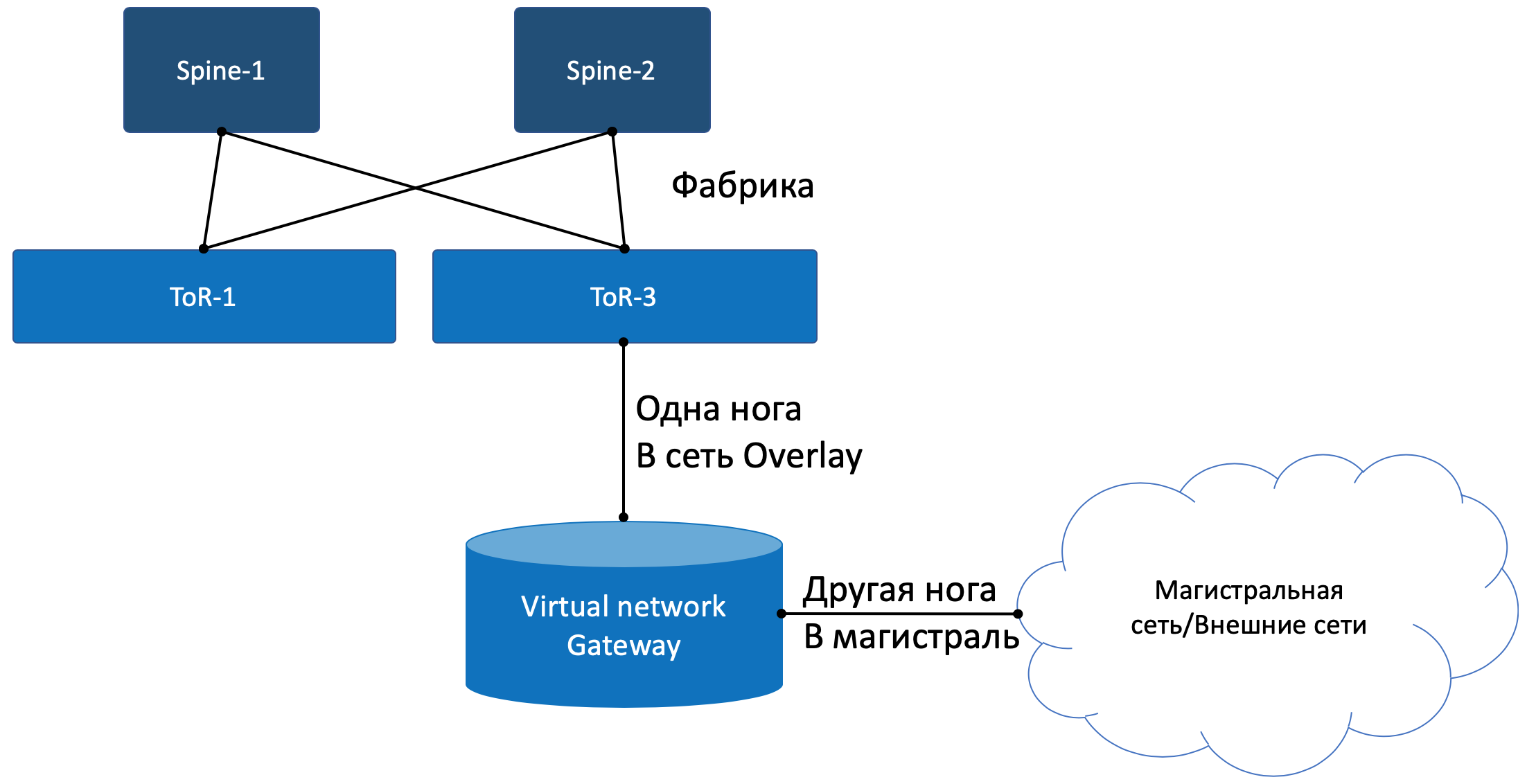
Datenebene
Das heißt, der Prozess sieht folgendermaßen aus:- VM-0 sendet standardmäßig alle im selben vRouter und sendet ein Paket mit einem Ziel in der Außenwelt (185.147.83.177) an die eth0-Schnittstelle.
- vRouter empfängt dieses Paket und sucht in der Routing-Tabelle nach der Zieladresse. Es findet die Standardroute durch das VNGW1-Gateway durch Tunnel 1.
Er sieht auch, dass dies ein GRE-Tunnel mit SIP 10.0.0.2 und DIP 10.0.255.2 ist, und legt zuerst MPLS auf. Das Label dieses Clients, das VNGW1 erwartet.
- vRouter packt das Originalpaket in die MPLS-, GRE- und neuen IP-Header und sendet es standardmäßig an ToR1 10.0.0.1.
- Ein Unterlage-Netzwerk liefert das Paket an das VNGW1-Gateway.
- Das VNGW1-Gateway entfernt die GRE- und MPLS-Tunnel-Header, sieht die Zieladresse, konsultiert die Routing-Tabelle und versteht, dass es an das Internet gerichtet ist - dies bedeutet über Vollansicht oder Standard. Führt bei Bedarf eine NAT-Übersetzung durch.
- Von VNGW bis zur Grenze kann es ein reguläres IP-Netzwerk geben, was unwahrscheinlich ist.
Es kann sich um ein klassisches MPLS-Netzwerk (IGP + LDP / RSVP TE), eine Fabrik mit einer BGP-LU oder einen GRE-Tunnel von VNGW zur Grenze durch das IP-Netzwerk handeln.
Wie auch immer, VNGW1 führt die erforderlichen Kapselungen durch und sendet das Originalpaket an die Grenze.
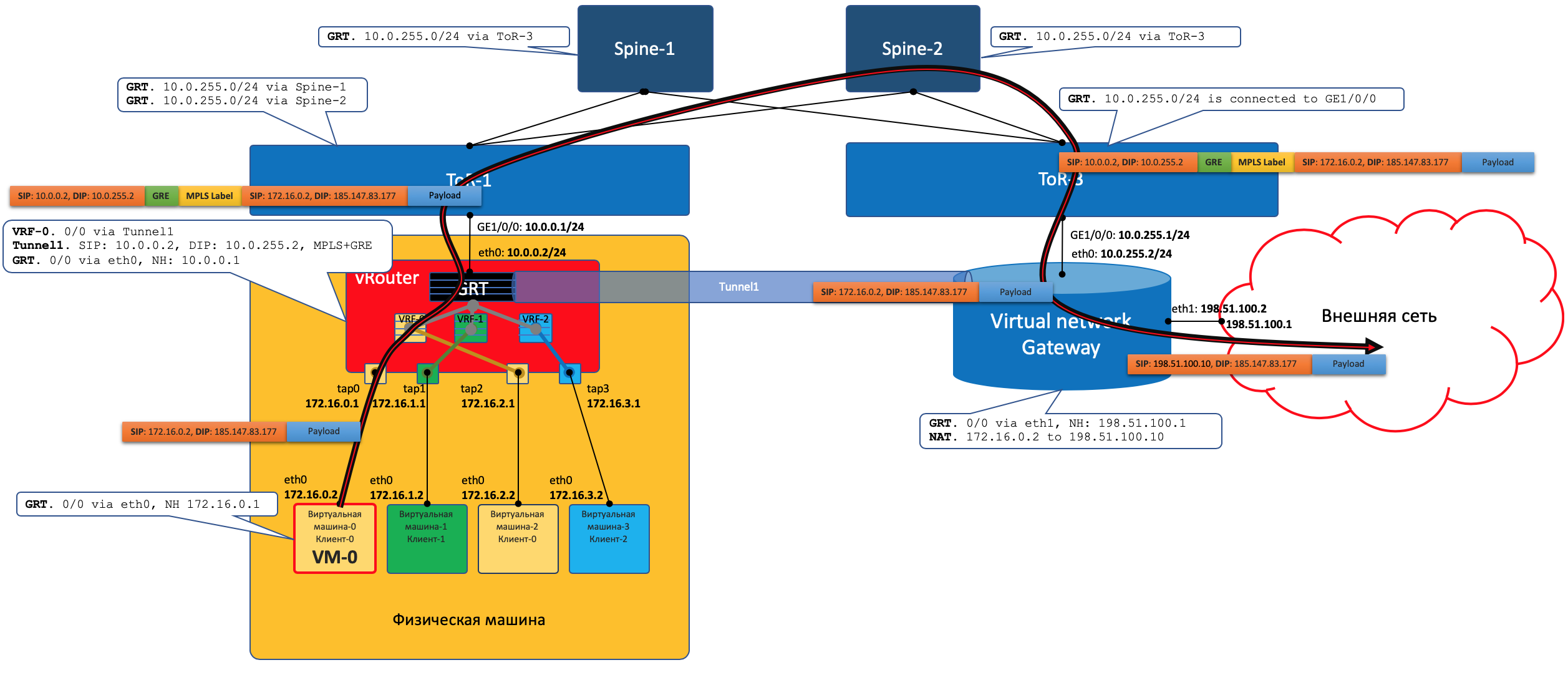 Der Verkehr in die entgegengesetzte Richtung durchläuft dieselben Schritte in der entgegengesetzten Reihenfolge.
Der Verkehr in die entgegengesetzte Richtung durchläuft dieselben Schritte in der entgegengesetzten Reihenfolge.- VNGW1
- , , Tunnel1 (MPLSoGRE MPLSoUDP).
- , MPLS, GRE/UDP IP ToR3 10.0.255.1.
— IP- vRouter', — 10.0.0.2. - vRouter'.
- vRouter GRE/UDP, MPLS- IP- TAP-, eth0 .

Control Plane
VNGW1 erstellt mit dem SDN-Controller eine BGP-Nachbarschaft, von der es alle Routing-Informationen zu Clients empfängt: Welche IP-Adresse (vRouter'om) ist welcher Client und mit welchem MPLS-Label identifiziert es sich?In ähnlicher Weise teilt er dem SDN-Controller die Standardroute mit der Bezeichnung dieses Clients mit und gibt sich als Nexthop an. Und dann kommt diese Standardeinstellung zu vRouter'y.VNGWs leiten normalerweise die Aggregation oder NAT-Übersetzung weiter.Und in die entgegengesetzte Richtung gibt er genau diese aggregierte Route zu einer Sitzung mit Boardern oder Route Reflectors. Und von ihnen erhält eine Standardroute oder Vollansicht oder etwas anderes.In Bezug auf Kapselung und Verkehrsaustausch unterscheidet sich VNGW nicht von vRouter.Wenn Sie den Bereich etwas erweitern, können Sie VNGW und vRouter weitere Netzwerkgeräte hinzufügen, z. B. Firewalls, Farmen zur Verkehrsbereinigung oder -anreicherung, IPS usw.Mithilfe der sukzessiven Erstellung von VRF und der korrekten Ankündigung von Routen können Sie eine beliebige Verkehrsschleife erstellen, die als Service Chaining bezeichnet wird.Das heißt, hier fungiert der SDN-Controller als Routenreflektor zwischen VNGW, vRouter'ami und anderen Netzwerkgeräten.Tatsächlich gibt der Controller jedoch auch Informationen zu ACLs und PBRs (Policy Based Routing) frei, wodurch einzelne Verkehrsströme gezwungen werden, anders zu verlaufen, als es die Route vorschreibt.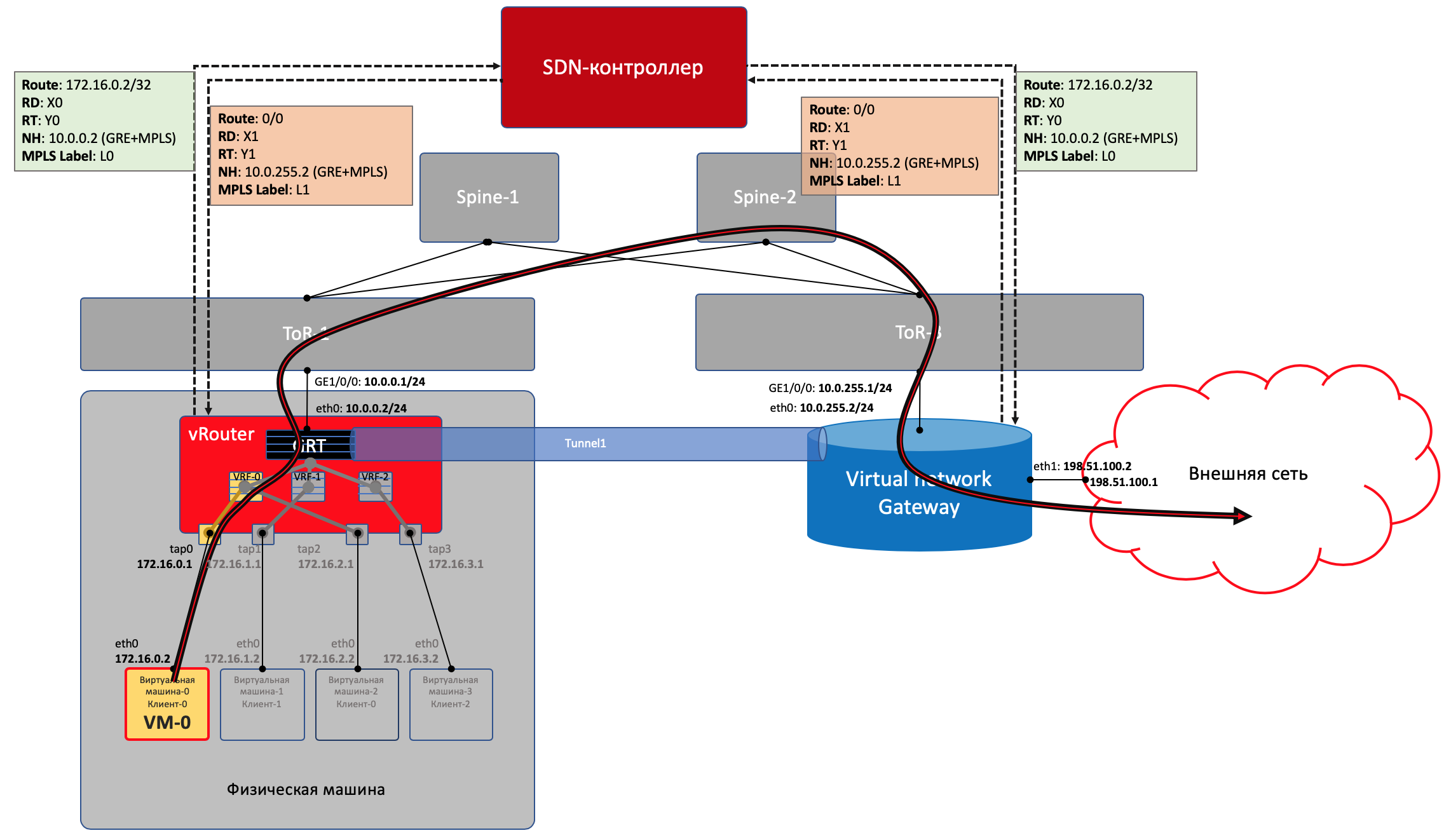
FAQ
Warum machst du immer eine GRE / UDP-Bemerkung?Nun, im Allgemeinen kann man sagen, dass es spezifisch für Wolframgewebe ist - man kann es überhaupt ignorieren.Aber wenn Sie es nehmen, dann unterstützt TF selbst, obwohl es noch ein OpenContrail ist, beide Kapselungen: MPLS in GRE und MPLS in UDP.UDP ist gut, da es im Quellport in seinem Header sehr einfach ist, eine Hash-Funktion vom ursprünglichen IP + Proto + Port zu codieren, die einen Ausgleich ermöglicht.Im Fall von GRE gibt es leider nur externe IP- und GRE-Header, die für den gesamten gekapselten Verkehr gleich sind, und es ist nicht von einem Ausgleich die Rede - nur wenige Menschen können so tief in das Paket schauen.Bis zu einiger Zeit lernten Router, wenn sie wussten, wie man dynamische Tunnel verwendet, nur in MPLSoGRE und erst vor kurzem in MPLSoUDP. Daher müssen Sie immer eine Bemerkung über die Möglichkeit von zwei verschiedenen Einkapselungen machen.Fairerweise ist anzumerken, dass TF die L2-Konnektivität mit VXLAN vollständig unterstützt.Sie haben versprochen, Parallelen zu OpenFlow zu ziehen.Sie betteln wirklich. vSwitch im selben OpenStack macht sehr ähnliche Dinge mit VXLAN, das übrigens auch einen UDP-Header hat.In der Datenebene funktionieren sie ungefähr gleich, die Kontrollebene unterscheidet sich erheblich. Tungsten Fabric verwendet XMPP, um Routeninformationen an vRouter zu übermitteln, während Openflow in OpenStack funktioniert.Kann ich etwas mehr über vRouter erfahren?Es ist in zwei Teile unterteilt: vRouter Agent und vRouter Forwarder.Die erste wird im Benutzerbereich des Host-Betriebssystems gestartet und kommuniziert mit dem SDN-Controller, wobei Informationen zu Routen, VRF und ACL ausgetauscht werden.Die zweite implementiert Data Plane - normalerweise im Kernel Space, kann aber auch auf SmartNICs gestartet werden - Netzwerkkarten mit einer CPU und einem separaten programmierbaren Switching-Chip, mit denen Sie die Last von der CPU des Host-Computers entfernen und das Netzwerk schneller und vorhersehbarer machen können.Ein anderes Szenario ist möglich, wenn vRouter eine DPDK-Anwendung im User Space ist.Der vRouter Agent löscht die Einstellungen in vRouter Forwarder.Was ist ein virtuelles Netzwerk?Ich habe am Anfang des Artikels über VRF erwähnt, dass jeder Mieter an seine VRF gebunden ist. Und wenn dies für ein oberflächliches Verständnis der Arbeit des Overlay-Netzwerks ausreichte, müssen bereits bei der nächsten Iteration Klarstellungen vorgenommen werden.Normalerweise wird in Virtualisierungsmechanismen die virtuelle Netzwerkeinheit (Sie können sie als Eigennamen verwenden) getrennt von Clients / Mandanten / virtuellen Maschinen eingeführt - dies ist eine ziemlich unabhängige Sache. Und dieses virtuelle Netzwerk über die Schnittstellen kann bereits in einem Mandanten, im anderen in zwei, aber zumindest wo verbunden werden. So wird beispielsweise die Dienstverkettung implementiert, wenn Datenverkehr in der gewünschten Reihenfolge über bestimmte Knoten geleitet werden muss, indem einfach virtuelle Netzwerke in der richtigen Reihenfolge erstellt und aufgerufen werden.Daher besteht keine direkte Korrespondenz zwischen dem virtuellen Netzwerk und dem Mandanten.
Fazit
Dies ist eine sehr oberflächliche Beschreibung des Betriebs eines virtuellen Netzwerks mit einer Überlagerung vom Host und vom SDN-Controller. Unabhängig davon, welche Virtualisierungsplattform Sie heute verwenden, funktioniert sie auf ähnliche Weise, sei es VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric oder Juniper Contrail. Sie unterscheiden sich in den Arten der Kapselung und den Headern sowie in den Protokollen zur Übermittlung von Informationen an Endnetzwerkgeräte. Das Prinzip eines auf Software abgestimmten Overlay-Netzwerks, das auf einem relativ einfachen und statischen Underlay-Netzwerk basiert, bleibt jedoch dasselbe.Wir können sagen, dass die Bereiche der Erstellung einer privaten Cloud bis heute das SDN basierend auf dem Overlay-Netzwerk gewonnen haben. Dies bedeutet jedoch nicht, dass Openflow keinen Platz in der modernen Welt hat - es wird in OpenStacke und in derselben VMWare NSX verwendet, soweit ich weiß, verwendet Google es, um das Unterlagennetzwerk zu konfigurieren.Im Folgenden habe ich Links zu detaillierteren Materialien angegeben, wenn Sie das Thema genauer untersuchen möchten.Und was ist unsere Unterlage?Aber im Allgemeinen nichts. Er hat sich nicht den ganzen Weg verändert. Alles, was er im Falle einer Überlagerung vom Host tun muss, ist, Routen und ARPs zu aktualisieren, wenn vRouter / VNGW erscheint und verschwindet, und Pakete zwischen ihnen zu ziehen.Formulieren wir eine Liste der Anforderungen für ein Underlay-Netzwerk.- Um in unserer Situation ein Routing-Protokoll durchführen zu können - BGP.
- , , - .
- ECMP — .
- QoS, , ECN.
- NETCONF — .
Ich habe hier sehr wenig Zeit für die Arbeit des Underlay-Netzwerks selbst aufgewendet. Dies liegt daran, dass ich mich später in der Serie darauf konzentrieren werde und Overlay nur nebenbei berühren werde.Natürlich schränke ich uns alle stark ein, indem ich als Beispiel das in der Klose-Fabrik aufgebaute DC-Netzwerk mit reinem IP-Routing und Overlay vom Host verwende.Ich bin jedoch sicher, dass jedes Netzwerk, das ein Design hat, formal beschrieben und automatisiert werden kann. Es ist nur so, dass ich das Ziel verfolge, die Ansätze zur Automatisierung zu verstehen und nicht alle zu verwirren, um das Problem allgemein zu lösen.Im Rahmen von ADSM lag Roman Gorge und ich, eine separate Ausgabe zur Virtualisierung der Rechenleistung und ihrer Perspektive mit der Netzwerkvirtualisierung zu gehören. Bleib in Kontakt.Nützliche Links
Danke
- Roman Gorge , ehemaliger Hauptmoderator des Linkmeup-Podcasts und jetzt Experte auf dem Gebiet der Cloud-Plattformen. Für Kommentare und Änderungen. Nun, wir freuen uns auf einen tieferen Artikel über Virtualisierung in naher Zukunft.
- Alexander Shalimov , mein Kollege und Experte für die Entwicklung virtueller Netzwerke. Für Kommentare und Änderungen.
- Valentina Sinitsyna , meine Kollegin und Wolfram-Stoff-Expertin. Für Kommentare und Änderungen.
- Artyom Chernobay - Illustrator Linkmeup. Für KDPV.
- Alexander Limonov. Für das Mem "Automat".