Früher hatten wir nur wenige Services, und es war ein großer
Erfolg, mehr als einen davon bei der Produktion an einem Tag zu aktualisieren. Dann beschleunigte sich die Welt, das System wurde komplexer und wir verwandelten uns in eine Organisation mit Microservice-Architektur. Jetzt haben wir ungefähr hundert Dienste, und mit der Zunahme ihrer Anzahl steigt auch die Häufigkeit von Veröffentlichungen - mehr als 250 pro Woche.
Wenn neue Funktionen in Produktteams getestet werden, besteht die Aufgabe des Integrationstestteams darin, zu überprüfen, ob die in der Version enthaltenen Änderungen die Funktionalität der Komponente, des Systems und anderer Funktionen nicht beeinträchtigen.

Ich arbeite als Testautomatisierungsingenieur bei Yandex.Money.
In diesem Artikel werde ich über die Entwicklung des Integrationstests von Webdiensten sowie über die Anpassung des Prozesses sprechen, um die Anzahl der Systemkomponenten und die Häufigkeit von Releases zu erhöhen.
Über Änderungen im Release-Zyklus und die Entwicklung des Berechnungsmechanismus wurden von ops und dev in
einem der vorherigen Artikel beschrieben . Ich erzähle Ihnen von der Geschichte der Änderungen in den Testprozessen während dieser Transformation.
Jetzt haben wir ungefähr 30 Entwicklungsteams. Das Team besteht normalerweise aus Produktmanagern, Projektmanagern, Front-End- und Back-End-Entwicklern und Testern. Sie werden durch die Arbeit an Aufgaben für ein bestimmtes Produkt vereint. Für den Service ist in der Regel das Team verantwortlich, das am häufigsten Änderungen daran vornimmt.
End-to-End-Abnahmetests
Vor nicht allzu langer Zeit, mit der Freigabe jeder Komponente, wurden nur Unit- und Komponententests ausgeführt, und danach wurden nur einige der wichtigsten End-to-End-Skripte in einer vollwertigen Testumgebung ausgeführt, bevor der Service in Betrieb genommen wurde. Mit der Zunahme der Anzahl der Komponenten begann die Anzahl der Verbindungen zwischen ihnen exponentiell zu wachsen. Oft - völlig nicht triviale Verbindungen. Ich erinnere mich, wie die Nichtverfügbarkeit des Dienstes für die Ausgabe von Marketingdaten die Benutzerregistrierung vollständig brach (natürlich für kurze Zeit).
Dieser Ansatz zur Überprüfung von Änderungen schlug immer häufiger fehl. Er erforderte, dass alle kritischen Geschäftsszenarien mit Autotests abgedeckt und in einer vollwertigen Testumgebung mit einer zur Veröffentlichung bereitgestellten Komponentenversion ausgeführt wurden.
Okay, Autotests für kritische Szenarien sind erschienen - aber wie werden sie ausgeführt? Es war eine Aufgabe, sich in den Freigabezyklus zu integrieren, was die Zuverlässigkeit durch falsche Testtropfen minimal beeinträchtigte. Andererseits wollte ich die Integrationstestphase so schnell wie möglich durchführen. Es gab also eine Infrastruktur für die Durchführung von Abnahmetests.
Wir haben versucht, die Tools, die bereits zur Ausführung der Komponente im Release-Zyklus und für die Startaufgaben verwendet wurden, maximal zu nutzen: Jira bzw. Jenkins.
Akzeptanztestzyklus
Um die Abnahmetests durchzuführen, haben wir den folgenden Zyklus festgelegt:
- Überwachung eingehender Aufgaben zum Abnahmetest einer Version,
- Ausführen des Jenkins-Jobs zum Installieren des Release-Builds in einer Testumgebung
- Überprüfen Sie, ob der Dienst gestiegen ist.
- Jenkins Job mit Integrationstests starten,
- Analyse der Ergebnisse des Laufs,
- wiederholter Testlauf (falls erforderlich),
- Aktualisieren des Status der Aufgabe - abgeschlossen oder fehlerhaft, unter Angabe des Grunds im Kommentar.
Der gesamte Zyklus wurde jedes Mal manuell durchgeführt. Infolgedessen wollte ich bereits bei der zehnten Veröffentlichung pro Tag schwören, die gleichen Aufgaben zu erledigen, bestenfalls unter meinem Atem, umklammerte meinen Kopf und forderte Baldrianbier.
Bot überwachen
Wir haben erkannt, dass das Verfolgen und Melden neuer Aufgaben in Jira wichtige Prozesse sind, die schnell und einfach zu automatisieren sind. Es gab also einen Bot, der das macht.
Die Daten zum Generieren von Warnungen werden in Form von Push-Benachrichtigungen von Jira bereitgestellt. Nach dem Start des Bots haben wir die Aktualisierung der Dashboard-Seite mit Akzeptanzaufgaben eingestellt und die Breite des Lächelns des Automaten leicht erhöht.
Pinger
Wir haben uns entschlossen, die Überprüfung zu vereinfachen, dass während der Bereitstellung in der Testumgebung keine Montage- oder Installationsfehler aufgetreten sind und dass die gewünschte Version der Komponente ausgelöst wurde und keine andere. Die Komponente gibt ihre Version und ihren Status über HTTP an. Die Überprüfung, ob der Dienst die richtige Version zurückgibt, wäre einfach und verständlich, wenn verschiedene Komponenten nicht in verschiedenen Sprachen geschrieben würden - einige in Node.js, andere in C #. Darüber hinaus haben unsere beliebtesten Dienste auch in Java die Version in einem anderen Format angegeben.
Außerdem wollte ich Echtzeitinformationen und Benachrichtigungen nicht nur über Versionsänderungen, sondern auch über Änderungen der Verfügbarkeit von Komponenten im System. Um dieses Problem zu lösen, wurde der Pinger-Dienst angezeigt, der Informationen über den Status und die Version von Komponenten sammelt, indem er diese zyklisch abfragt.
Wir verwenden ein Push-Modell für die Nachrichtenübermittlung. Auf jeder Instanz der Testumgebung wird ein Agent bereitgestellt, der alle 10 Sekunden Informationen zu den Komponenten dieser Umgebung sammelt und die Daten auf einem zentralen Knoten speichert. Wir gehen zu diesem Knoten, um den aktuellen Status zu erhalten. Mit diesem Ansatz können wir mehr als hundert Prüfstände unterstützen.
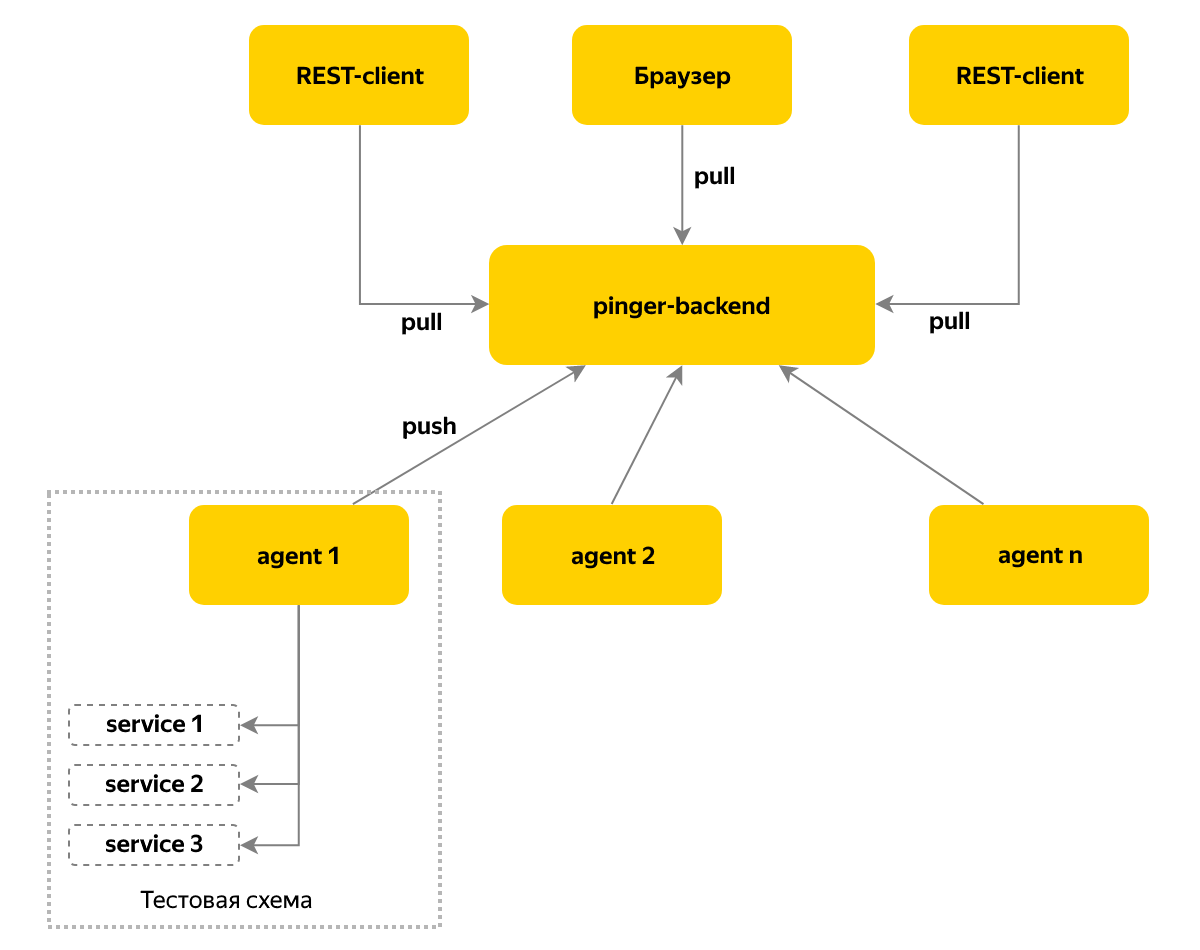
Schließfach
Es ist Zeit für komplexere Aufgaben - automatische Aktualisierung von Komponenten und Ausführen von Tests. Zu diesem Zeitpunkt verfügte unser Team bereits über 3 Testbänke in OpenStack für Abnahmetests. Zunächst musste das Problem der Verwaltung der Ressourcen von Testbänken gelöst werden: Es wäre unangenehm, wenn das Update der nächsten Version beim Ausführen von Tests auf dem System „rollt“. Es kommt auch vor, dass der Prüfstand debuggt wird und Sie ihn dann nicht zur Abnahme verwenden sollten.
Ich wollte in der Lage sein, den Beschäftigungsstatus zu sehen und gegebenenfalls den Stand für die Dauer der Analyse der gefallenen Tests oder bis zum Abschluss anderer Arbeiten manuell zu sperren.
Für all dies ist der Locker-Dienst erschienen. Es speichert den Status des Prüfstands für eine lange Zeit ("beschäftigt" / "frei") und ermöglicht es Ihnen, einen Kommentar zu "beschäftigt" anzugeben, sodass klar ist, dass wir jetzt debuggen, eine Kopie der Testumgebung neu erstellen oder Tests für die nächste Version ausführen. Wir haben auch nachts damit begonnen, Stände zu blockieren - an ihnen führen Administratoren Arbeiten nach einem Zeitplan durch, z. B. Backups und Datenbanksynchronisierung.
Beim Blockieren wird immer die Zeit eingestellt, nach der die Sperre abläuft. Jetzt müssen die Benutzer nicht mehr an der Rückgabe der Stände an den verfügbaren Pool teilnehmen, und die Maschine erledigt alles.
Pflicht
Um die Last gleichmäßig auf die Teammitglieder zu verteilen und die Ergebnisse der Testläufe zu analysieren, haben wir tägliche Schichten entwickelt. Die Begleitperson arbeitet mit den Aufgaben des Abnahmetests von Releases, analysiert gefallene Autotests und meldet Fehler. Wenn der Mitarbeiter versteht, dass er den Aufgabenfluss nicht bewältigt, kann er das Team um Hilfe bitten. Zu diesem Zeitpunkt ist der Rest des Teams mit Aufgaben beschäftigt, die nicht mit Releases zusammenhängen.
Mit der Zunahme der Anzahl der Releases wurde die Rolle des zweiten Vermittlers angezeigt, der sich mit der Hauptvermittlung verbindet, wenn Blockierungen vorliegen oder kritische Releases in der Warteschlange vorhanden sind. Um Informationen über den Fortschritt der Testversionen zu erhalten, haben wir eine Seite mit der Anzahl der Aufgaben in den Zuständen "Öffnen" / "Laufen" / "Warten auf eine Antwort vom Dienst", dem Status der Sperrung von Prüfständen und den auf den Ständen unzugänglichen Komponenten erstellt:
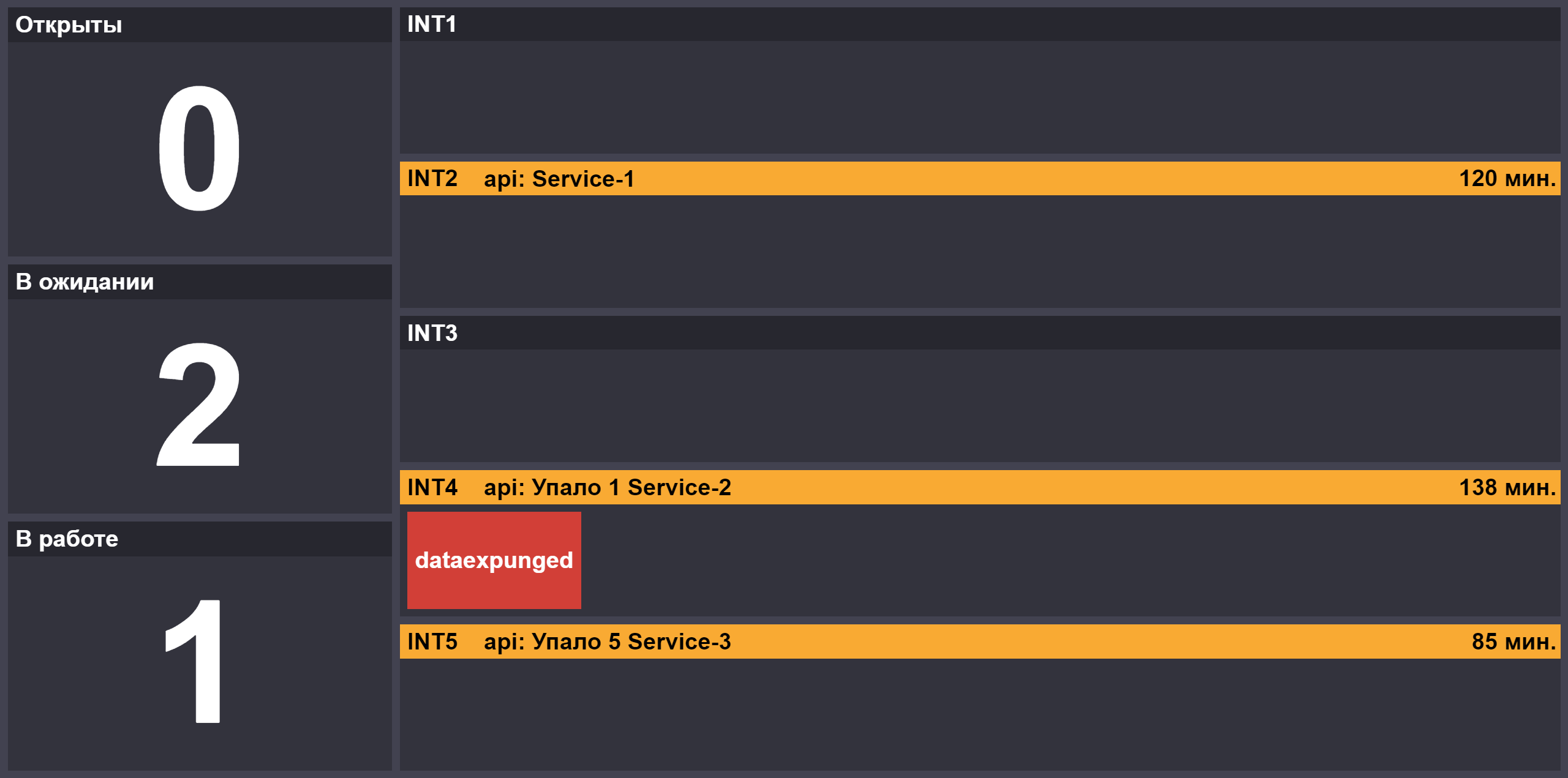
Die Arbeit des Dienstoffiziers erfordert Konzentration, damit er ein Brötchen hat - am Tag des Dienstes kann er einen Platz zum Mittagessen für das gesamte Team in der Nähe des Büros auswählen. Die Bestechungsgelder im Stil sehen besonders lustig aus: "Lass mich dir helfen, die Aufgaben zu erledigen, und heute gehen wir zu
meinem Lieblingsplatz" =)
Reporter
Eine der Aufgaben, auf die wir bei der Einführung der Uhr gestoßen sind, war die Notwendigkeit, Wissen von einem Beamten auf einen anderen zu übertragen, beispielsweise über Tests, die auf eine neue Version fallen, oder über die Besonderheiten der Aktualisierung einer Komponente.
Darüber hinaus haben wir neue Funktionen der Arbeit.
- Es gab eine Kategorie von Tests, die aufgrund von Problemen mit Prüfständen mehr oder weniger häufig fallen. Stürze können aufgrund der längeren Antwortzeit eines der Dienste oder des langen Ladens von Ressourcen im Browser auftreten. Ich möchte die Tests nicht ausschalten. Die angemessenen Mittel zur Erhöhung ihrer Zuverlässigkeit sind erschöpft.
- Wir hatten ein zweites experimentelles Projekt mit Autotests, und es bestand die Notwendigkeit, die Läufe von zwei Projekten gleichzeitig zu analysieren und Allure-Berichte zu betrachten.
- Ein Testlauf kann bis zu 20 Minuten dauern, und Sie möchten die Ergebnisse unmittelbar nach dem Start der ersten Tropfen analysieren. Besonders wenn die Aufgabe kritisch ist und die Mitglieder des Teams, die für die Freilassung verantwortlich sind, hinter Ihnen
stehen und das Messer mit erbärmlichen Augen an den Hals halten .
So entstand der Reporter-Dienst. Darin übertragen wir die Ergebnisse des Testlaufs während des Testprozesses in Echtzeit. Der Dienst verfügt über eine Datenbank mit bekannten Problemen oder Fehlern, die mit einem bestimmten Test verknüpft sind. Außerdem wurde im Wiki-Portal des Unternehmens eine Veröffentlichung eines zusammenfassenden Berichts über die Ergebnisse des Laufs des Reporters veröffentlicht. Dies ist praktisch für Manager, die nicht in die technischen Details der Reporter- oder Allure-Oberfläche eintauchen möchten.
Wenn der Test abstürzt, können Sie im Reporter nach einer Liste verwandter Fehler suchen oder Aufgaben beheben. Solche Informationen verkürzen die Analysezeit und erleichtern den Wissensaustausch über Probleme zwischen Mitgliedern unseres Teams. Aufzeichnungen über erledigte Aufgaben werden archiviert, aber bei Bedarf können Sie sie in eine separate Liste „gucken“. Um interne Services während der Geschäftszeiten nicht zu laden, befragen wir Jira nachts und archivieren Einträge für Probleme mit dem endgültigen Status.
Ein Bonus aus der Einführung von Reporter war die Entstehung einer Laufdatenbank, auf deren Grundlage Sie die Häufigkeit von Stürzen analysieren, Tests nach ihrer Stabilität oder „Nützlichkeit“ in Bezug auf die Anzahl der gefundenen Fehler bewerten können.
Autorun
Als Nächstes haben wir den Start von Tests automatisiert, wenn das Problem des Abnahmetests der Version beim Issue-Tracker auftritt. Zu diesem Zweck wurde der Autorun-Dienst geschrieben, der prüft, ob in Jira neue Akzeptanzaufgaben vorhanden sind, und in diesem Fall den Namen der Komponente und ihre Version anhand des Inhalts der Aufgabe ermittelt.
Für die Aufgabe werden mehrere Schritte ausgeführt:
- Nehmen Sie das Schloss eines der kostenlosen Prüfstände im Locker-Service.
- Starten Sie die Installation der erforderlichen Komponente in Jenkins und warten Sie, bis die Komponente mit der erforderlichen Version ausgelöst wurde.
- Führen Sie Tests durch
- Warten Sie, bis der Testlauf abgeschlossen ist. Während der Ausführung werden alle Ergebnisse in Reporter übertragen.
- Wir fragen Reporter nach der Anzahl der fehlgeschlagenen Tests, mit Ausnahme derjenigen, die aufgrund bekannter Probleme gefallen sind.
- Wenn 0 gefallen ist, übertragen wir die Aufgabe für die Abnahmeprüfung auf „Fertig stellen“ und beenden die Arbeit damit. Alles ist fertig =)
- Wenn es "rote" Tests gibt, übersetzen wir die Aufgabe in "Warten" und gehen zu Reporter, um sie zu analysieren.
Das Umschalten zwischen Stufen erfolgt nach dem Prinzip einer endlichen Zustandsmaschine. Jede Stufe selbst kennt die Bedingungen für den Übergang zur nächsten. Die Ergebnisse der Stufe werden im Aufgabenkontext gespeichert, der für die Stufen einer Aufgabe üblich ist.
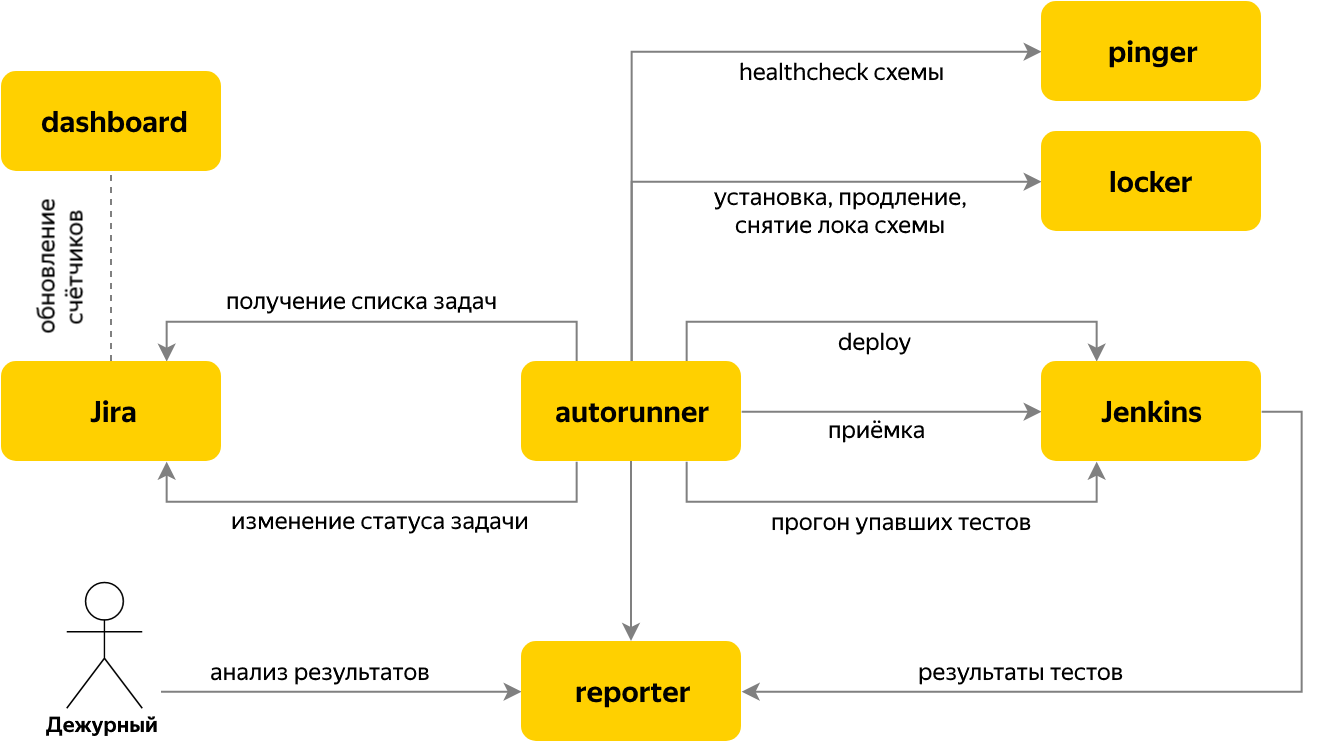
All dies ermöglicht es Ihnen, Releases automatisch entlang der Bereitstellungspipeline zu übertragen, wonach 100 Prozent der Tests grün sind. Aber was ist mit der Instabilität, die nicht durch Probleme in der Komponente, sondern durch die "natürlichen" Merkmale der UI-Tests oder durch die erhöhten Netzwerkverzögerungen im Prüfstand verursacht wird?
Zu diesem Zweck haben wir einen Wiederholungsmechanismus implementiert, den viele Menschen verwenden, aber nur wenige erkennen dies. Retrays werden in der Jenkins-Pipeline als sequentielle Testreihe organisiert.
Nach dem Lauf fordern wir von Reporter eine Liste fehlgeschlagener Tests von Jenkins an - und starten nur fehlgeschlagene Tests neu. Außerdem reduzieren wir die Anzahl der Threads beim Start. Wenn die Anzahl der abgebrochenen Tests im Vergleich zum vorherigen Lauf nicht abgenommen hat, beenden wir Job sofort. In unserem Fall können wir mit diesem Ansatz zum Neustart den Erfolg von Abnahmetests um etwa das Zweifache steigern.
Schnellblock
Das resultierende Akzeptanztestsystem ermöglichte es uns, mehr als 60% der Freisetzungen ohne menschliches Eingreifen durchzuführen. Aber was tun mit dem Rest? Bei Bedarf erstellt die Telefonzentrale einen Fehlerbericht über die zu testende Komponente oder die Aufgabe, Tests für das Entwicklungsteam zu reparieren. Manchmal - erstellt einen Fehler in der Prüfstandskonfiguration an die Betriebsabteilung.
Aufgaben zum Korrigieren von Tests blockieren häufig den korrekten Durchgang automatischer Tests, da irrelevante Tests immer „rot“ sind. Die Tester der Entwicklungsteams sind dafür verantwortlich, neue Tests zu schreiben und vorhandene zu aktualisieren. Sie nehmen Änderungen durch Pull-Anforderungen an das Projekt mit automatischen Tests vor. Diese Änderungen unterliegen einer obligatorischen Überprüfung, die vom Prüfer und vom Autor einige Zeit in Anspruch nimmt. Ich möchte irrelevante Tests vorübergehend blockieren, bis die Aufgabe in ihren endgültigen Status übersetzt wurde.
Zunächst haben wir einen Mechanismus zum Herunterfahren implementiert, der auf Anmerkungen zu Testmethoden basiert. In der Folge stellte sich heraus, dass das Blockieren des Codes aufgrund einer obligatorischen Codeüberprüfung nicht immer bequem ist und möglicherweise länger dauert, als wir möchten.
Aus diesem Grund haben wir die Liste der Aufgaben, die Tests blockieren, auf einen neuen Dienst mit einer Webseite verschoben - Quick-Block. So können Mitglieder des für die Komponente verantwortlichen Teams den Test schnell blockieren. Vor dem Start rufen wir diesen Dienst auf und erhalten eine Liste der unter Quarantäne gestellten Tests, die wir in den Status "Übersprungen" übersetzen.
Zusammenfassung
Wir sind von der Annahme von Releases im manuellen Modus zu einem fast vollautomatischen Prozess übergegangen, der durch Abnahmetests von mehr als 50 Releases pro Tag durchgeführt werden kann. Dies hilft dem Unternehmen, die Zeit für die Veröffentlichung von Änderungen zu verkürzen, und unser Team kann Ressourcen zum Experimentieren und Entwickeln von Testwerkzeugen finden.
In Zukunft planen wir, die Zuverlässigkeit des Prozesses zu erhöhen, indem wir beispielsweise Anforderungen aus der obigen Liste auf zwei Instanzen jedes Dienstes verteilen. Auf diese Weise können Sie Tools ohne Ausfallzeiten aktualisieren und neue Funktionen nur für einen Teil der Abnahmetests hinzufügen. Darüber hinaus achten wir auf die Stabilisierung der Tests selbst. In der Entwicklung ein Ticketgenerator für Refactoring-Tests mit der niedrigsten Erfolgsquote.
Die Verbesserung der Zuverlässigkeit von Tests erhöht nicht nur das Vertrauen in sie, sondern beschleunigt auch das Testen von Releases, da Neustarts von heruntergefallenen Skripten fehlen.