Hallo allerseits! Am kommenden Montag beginnen die Kurse in der neuen Gruppe des
Python Developer- Kurses. Dies bedeutet, dass wir Zeit haben, ein weiteres interessantes Material zu veröffentlichen, das wir jetzt durchführen werden. Gute Lektüre.

Bereits 2003 veröffentlichte Intel den neuen Pentium 4 „HT“ -Prozessor. Dieser Prozessor übertaktete auf 3 GHz und unterstützte die Hyper-Threading-Technologie.

In den folgenden Jahren hatten Intel und AMD Probleme, die beste Desktop-Leistung zu erzielen, indem sie die Busgeschwindigkeit, die L2-Cache-Größe und die Matrixgröße erhöhten, um die Latenz zu minimieren. Im Jahr 2004 wurde das HT-Modell mit einer Frequenz von 3 GHz durch das 580 Prescott-Modell mit Übertaktung auf 4 GHz ersetzt.
Es schien, dass es nur notwendig war, die Taktfrequenz zu erhöhen, aber die neuen Prozessoren litten unter hohem Stromverbrauch und Wärmeableitung.
Liefert Ihr Desktop-Prozessor heute 4 GHz? Dies ist unwahrscheinlich, da der Weg zur Verbesserung der Leistung letztendlich in der Erhöhung der Busgeschwindigkeit und der Erhöhung der Anzahl der Kerne liegt. Im Jahr 2006 ersetzte Intel Core 2 den Pentium 4 und hatte eine viel niedrigere Taktrate.
Neben der Veröffentlichung von Multi-Core-Prozessoren für ein breites Benutzerpublikum geschah 2006 noch etwas anderes. Python 2.5 hat endlich das Licht erblickt! Es kam bereits mit einer Beta-Version des with-Schlüsselworts, die Sie alle kennen und lieben.
Python 2.5 hatte eine wesentliche Einschränkung bei der Verwendung von Intel Core 2 oder AMD Athlon X2.
Es war eine Gil.
Was ist eine GIL?
GIL (Global Interpreter Lock) ist ein boolescher Wert im Python-Interpreter, der durch einen Mutex geschützt ist. Die Sperre wird in der Haupt-CPython-Bytecode-Berechnungsschleife verwendet, um zu bestimmen, welcher Thread gerade Anweisungen ausführt.
CPython unterstützt die Verwendung mehrerer Threads in einem einzelnen Interpreter. Threads müssen jedoch den Zugriff auf die GIL anfordern, um Operationen auf niedriger Ebene ausführen zu können. Dies bedeutet wiederum, dass Python-Entwickler asynchronen Code und Multithreading verwenden können und sich nicht mehr um das Blockieren von Variablen oder Abstürze auf Prozessorebene während Deadlocks kümmern müssen.
GIL vereinfacht die Multithread-Python-Programmierung.

GIL sagt uns auch, dass CPython zwar Multithread-fähig sein kann, jedoch jeweils nur ein Thread ausgeführt werden kann. Dies bedeutet, dass Ihr Quad-Core-Prozessor so etwas tut (mit Ausnahme des blauen Bildschirms hoffentlich).
Die aktuelle Version von GIL
wurde 2009 geschrieben , um asynchrone Funktionen zu unterstützen, und blieb auch nach vielen Versuchen, sie im Prinzip zu entfernen oder die Anforderungen dafür zu ändern, unberührt.
Jeder Vorschlag, die GIL zu entfernen, wurde durch die Tatsache gerechtfertigt, dass das globale Sperren des Interpreters die Leistung von Single-Threaded-Code nicht beeinträchtigen sollte. Jeder, der 2003 versucht hat, Hyperthreading zu aktivieren, wird verstehen, wovon
ich spreche .
Gil Verlassenheit in CPython
Wenn Sie den Code in CPython wirklich parallelisieren möchten, müssen Sie mehrere Prozesse verwenden.
In CPython 2.6 wurde das
Multiprozessor- Modul zur Standardbibliothek hinzugefügt. Multiprocessing maskierte die Generierung von Prozessen in CPython (jeder Prozess mit seiner eigenen GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Prozesse werden erstellt, Befehle werden mit kompilierten Modulen und Python-Funktionen an sie gesendet und dann wieder mit dem Hauptprozess verbunden.
Multiprocessing unterstützt auch die Verwendung von Variablen über eine Warteschlange oder einen Kanal. Sie hat ein Sperrobjekt, mit dem Objekte im Hauptprozess gesperrt und aus anderen Prozessen geschrieben werden.
Multiprocessing hat einen großen Nachteil. Es ist mit einer erheblichen Rechenlast verbunden, die sich sowohl auf die Verarbeitungszeit als auch auf die Speichernutzung auswirkt. Die CPython-Startzeit beträgt auch ohne Site 100-200 ms (weitere Informationen finden Sie unter
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b ).
Infolgedessen verfügen Sie möglicherweise über parallelen Code in CPython, müssen jedoch die Arbeit lang laufender Prozesse, die mehrere Objekte gemeinsam nutzen, sorgfältig planen.
Eine andere Alternative kann darin bestehen, ein Paket eines Drittanbieters wie Twisted zu verwenden.
PEP554 und der Tod von GIL?
Ich möchte Sie daran erinnern, dass Multithreading in CPython einfach ist, in Wirklichkeit jedoch keine Parallelisierung, sondern Multiprocessing parallel ist, jedoch einen erheblichen Overhead mit sich bringt.
Was ist, wenn es einen besseren Weg gibt?Der Schlüssel zur Umgehung der GIL liegt im Namen. Die globale Sperrung des Interpreters ist Teil des globalen Status des Interpreters. CPython-Prozesse können mehrere Interpreter und daher mehrere Sperren haben. Diese Funktion wird jedoch selten verwendet, da der Zugriff nur über die C-API erfolgt.
Eine der Funktionen von CPython 3.8 ist PEP554, eine Implementierung von Unterinterpreten und APIs mit einem neuen
interpreters in der Standardbibliothek.
Auf diese Weise können Sie in einem einzigen Prozess mehrere Interpreter aus Python erstellen. Eine weitere Neuerung von Python 3.8 ist, dass alle Interpreter ihre eigene GIL haben.
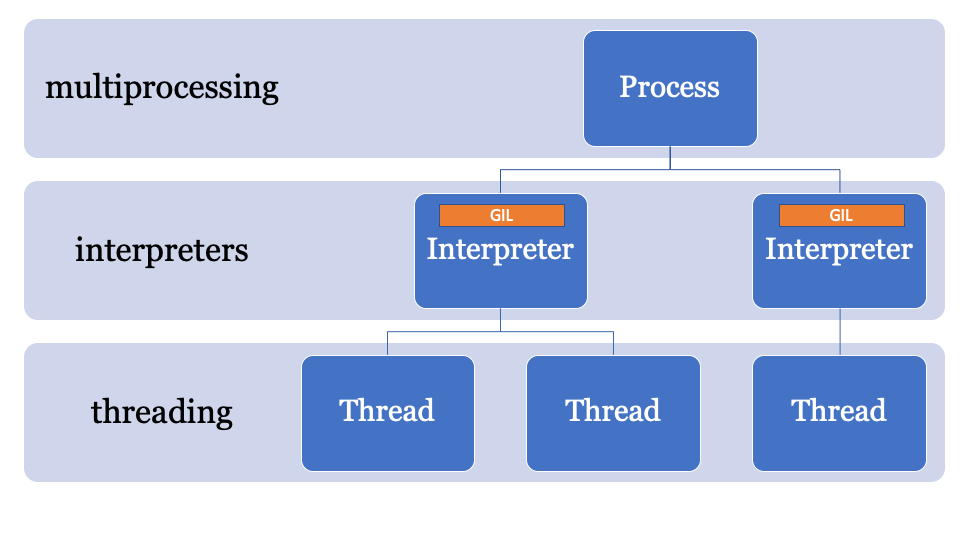
Da der Status des Interpreters eine im Speicher zugewiesene Region enthält, eine Sammlung aller Zeiger auf Python-Objekte (lokal und global), können Subinterpreter in PEP554 nicht auf die globalen Variablen anderer Interpreter zugreifen.
Interpreter, die Objekte gemeinsam nutzen, bestehen wie Multiprocessing darin, sie zu serialisieren und das IPC-Formular (Netzwerk, Festplatte oder gemeinsam genutzter Speicher) zu verwenden. Es gibt viele Möglichkeiten, Objekte in Python zu serialisieren, z. B. das
simplexml Modul, das
pickle Modul oder standardisierte Methoden wie
json oder
simplexml . Jeder von ihnen hat seine Vor- und Nachteile, und alle geben eine Rechenlast.
Es wäre am besten, einen gemeinsamen Speicherplatz zu haben, der durch einen bestimmten Prozess geändert und gesteuert werden kann. Somit können Objekte vom Hauptinterpreter gesendet und von einem anderen Interpreter empfangen werden. Dies ist der verwaltete Speicherplatz für die Suche nach PyObject-Zeigern, auf die jeder Interpreter zugreifen kann, während der Hauptprozess die Sperren verwaltet.
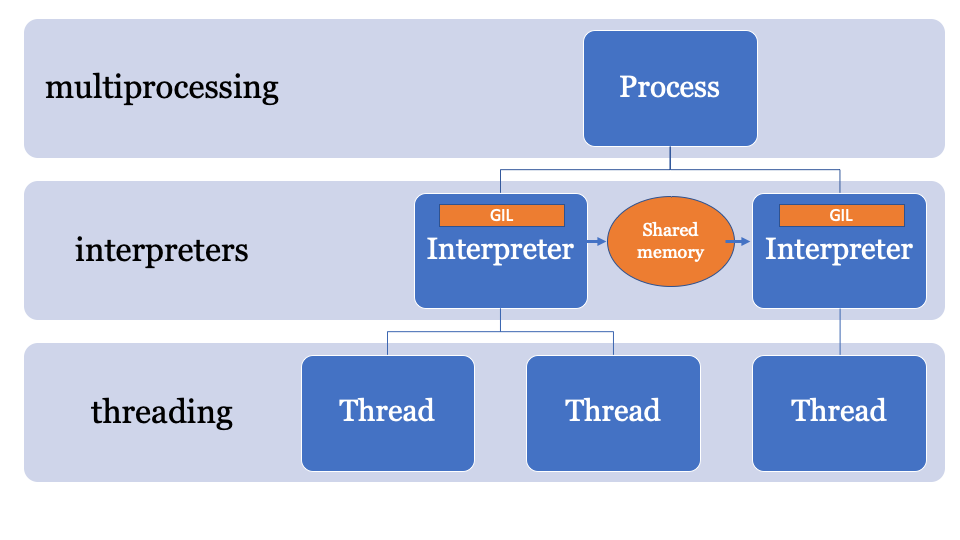
Eine API dafür wird noch entwickelt, aber sie wird wahrscheinlich ungefähr so aussehen:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal
In diesem Beispiel wird NumPy verwendet. Das Numpy-Array wird über den Kanal gesendet, es wird mithilfe des
marshal serialisiert, und der Subinterpreter verarbeitet die Daten (auf einer separaten GIL), sodass möglicherweise ein Parallelisierungsproblem mit der CPU verbunden ist, das für Subinterpreter ideal ist.
Es sieht ineffizient aus
Das
marshal arbeitet sehr schnell, aber nicht so schnell wie das direkte Freigeben von Objekten aus dem Speicher.
PEP574 führt ein neues
Pickle- Protokoll
(v5) ein , das die Fähigkeit unterstützt, Speicherpuffer getrennt vom Rest des Pickle-Streams zu verarbeiten. Bei großen Datenobjekten bedeutet das Serialisieren aller Objekte auf einmal und das Deserialisieren von einem Subinterpreter viel Overhead.
Die neue API kann (rein hypothetisch) wie folgt implementiert werden:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle
Es sieht gemustert aus
Im Wesentlichen basiert dieses Beispiel auf der Verwendung der API von Subinterpretern auf niedriger Ebene. Wenn Sie die
multiprocessing Bibliothek nicht verwendet haben, werden Ihnen einige Probleme bekannt vorkommen. Es ist nicht so einfach wie die Stream-Verarbeitung. Sie können diese Funktion beispielsweise (vorerst) nicht einfach mit einer solchen Liste von Eingabedaten in separaten Interpreten ausführen.
Sobald dieses PEP mit anderen verschmilzt, werden wir wahrscheinlich mehrere neue APIs in PyPi sehen.
Wie viel Overhead hat der Subinterpreter?
Kurze Antwort: Mehr als ein Stream, weniger als ein Prozess.
Lange Antwort: Der Interpreter hat einen eigenen Status, daher muss er Folgendes klonen und initialisieren, obwohl PEP554 die Erstellung von Subinterpreten vereinfacht:
- Module im
importlib __main__ und importlib ; - Der Inhalt des
sys ; - Eingebaute Funktionen (
print() , assert usw.); - Streams;
- Kernel-Konfiguration.
Die Kernelkonfiguration kann leicht aus dem Speicher geklont werden, aber das Importieren von Modulen ist nicht so einfach. Das Importieren von Modulen in Python ist langsam. Wenn das Erstellen eines Subinterpreters das Importieren von Modulen in einen anderen Namespace jedes Mal bedeutet, werden die Vorteile verringert.
Was ist mit Asyncio?
Die vorhandene Implementierung der
asyncio Ereignisschleife in der Standardbibliothek erstellt
asyncio zur Auswertung und
asyncio Status im Hauptinterpreter (und teilt daher die GIL).
Nach dem Kombinieren von PEP554, wahrscheinlich bereits in Python 3.9, kann eine alternative Implementierung der Ereignisschleife verwendet werden (obwohl dies noch niemand getan hat), die asynchrone Methoden in Subinterpretern parallel ausführt.
Klingt cool, wickel mich auch ein!
Nun, nicht wirklich.
Da CPython so lange auf demselben Interpreter ausgeführt wurde, verwenden viele Teile der Codebasis "Laufzeitstatus" anstelle von "Interpreterstatus". Wenn PEP554 jetzt eingeführt würde, gäbe es immer noch viele Probleme.
Beispielsweise gehört der Status des Garbage Collector (in Version 3.7 <) zur Laufzeit.
Bei Änderungen während PyCon-Sprints begann sich der Status des Garbage Collectors auf den Interpreter zu verschieben, sodass jeder Subinterpreter seinen eigenen Garbage Collector hatte (wie es sein sollte).
Ein weiteres Problem ist, dass es einige „globale“ Variablen gibt, die in der CPython-Codebasis zusammen mit vielen Erweiterungen in C verblieben sind. Als die Leute plötzlich anfingen, ihren Code korrekt zu parallelisieren, sahen wir einige Probleme.
Ein weiteres Problem besteht darin, dass die Dateideskriptoren zum Prozess gehören. Wenn Sie also eine Datei zum Schreiben in einem Interpreter geöffnet haben, kann der Subinterpreter nicht auf diese Datei zugreifen (ohne weitere Änderungen an CPython).
Kurz gesagt, es gibt noch viele Probleme, die angegangen werden müssen.
Fazit: Ist GIL noch wahr?
GIL wird weiterhin für Single-Threaded-Anwendungen verwendet. Selbst wenn Sie PEP554 folgen, wird Ihr Single-Thread-Code daher plötzlich nicht mehr parallel.
Wenn Sie parallelen Code in Python 3.8 schreiben möchten, treten Parallelisierungsprobleme im Zusammenhang mit dem Prozessor auf, dies ist jedoch auch ein Ticket für die Zukunft!
Wann?
Pickle v5 und Speicherfreigabe für die Mehrfachverarbeitung werden höchstwahrscheinlich in Python 3.8 (Oktober 2019) verfügbar sein, und Subinterpreter werden zwischen den Versionen 3.8 und 3.9 angezeigt.
Wenn Sie mit den vorgestellten Beispielen herumspielen möchten, habe ich einen separaten Zweig mit dem erforderlichen Code erstellt:
https://github.com/tonybaloney/cpython/tree/subinterpreters.Was denkst du darüber? Schreiben Sie Ihre Kommentare und wir sehen uns auf dem Kurs.