Mein Name ist Stas Kirillov, ich bin ein führender Entwickler in der Gruppe der ML-Plattformen in Yandex. Wir entwickeln Tools für maschinelles Lernen und unterstützen und entwickeln die Infrastruktur für sie. Unten ist mein letzter Vortrag über die Funktionsweise der CatBoost-Bibliothek. In dem Bericht habe ich über die Einstiegspunkte und Funktionen des Codes für diejenigen gesprochen, die ihn verstehen oder unser Mitwirkender werden möchten.
- CatBoost lebt auf GitHub unter der Apache 2.0-Lizenz, das heißt, es ist offen und kostenlos für alle. Das Projekt entwickelt sich aktiv weiter, jetzt hat unser Repository mehr als viertausend Sterne. CatBoost ist in C ++ geschrieben, es ist eine Bibliothek zur Gradientenverstärkung in Entscheidungsbäumen. Es werden verschiedene Baumarten unterstützt, einschließlich der sogenannten "symmetrischen" Bäume, die standardmäßig in der Bibliothek verwendet werden.
Was ist der Gewinn unserer ahnungslosen Bäume? Sie lernen schnell, wenden sich schnell an und helfen dem Lernen, widerstandsfähiger gegen Änderungen von Parametern in Bezug auf Änderungen der endgültigen Qualität des Modells zu sein, was die Notwendigkeit der Auswahl von Parametern erheblich verringert. In unserer Bibliothek geht es darum, die Verwendung in der Produktion zu vereinfachen, schnell zu lernen und sofort gute Qualität zu erzielen.

Gradient Boosting ist ein Algorithmus, mit dem wir einfache Prädiktoren erstellen, die unsere Zielfunktion verbessern. Das heißt, anstatt sofort ein komplexes Modell zu erstellen, bauen wir nacheinander viele kleine Modelle.

Wie ist der Lernprozess in CatBoost? Ich werde Ihnen sagen, wie es in Bezug auf Code funktioniert. Zuerst analysieren wir die Trainingsparameter, die der Benutzer übergibt, validieren sie und prüfen dann, ob wir die Daten laden müssen. Da die Daten bereits geladen werden können - beispielsweise in Python oder R. Als Nächstes laden wir die Daten und erstellen ein Raster aus den Rändern, um die numerischen Merkmale zu quantisieren. Dies ist notwendig, um schnell zu lernen.
Kategoriale Merkmale verarbeiten wir etwas anders. Wir kategorisieren Features ganz am Anfang und nummerieren dann die Hashes von Null auf die Anzahl der eindeutigen Werte des kategorialen Features neu, um schnell Kombinationen von kategorialen Features lesen zu können.
Dann starten wir die Trainingsschleife direkt - den Hauptzyklus unseres maschinellen Lernens, in dem wir iterativ Bäume bauen. Nach diesem Zyklus wird das Modell exportiert.
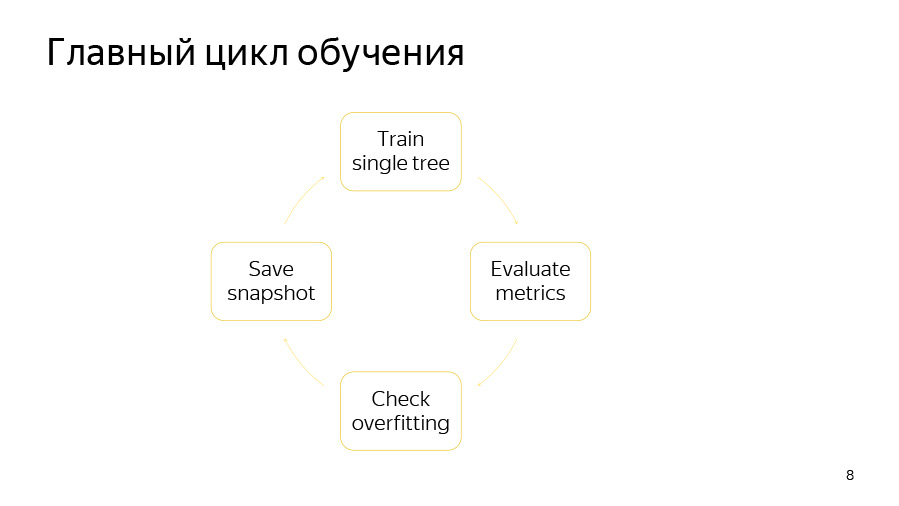
Der Trainingszyklus selbst besteht aus vier Punkten. Zuerst versuchen wir einen Baum zu bauen. Dann schauen wir uns an, welche Art von Qualitätssteigerung oder -abnahme es gibt. Dann prüfen wir, ob unser Umschulungsdetektor funktioniert hat. Dann speichern wir, wenn die Zeit reif ist, den Schnappschuss.

Das Lernen eines einzelnen Baumes ist ein Zyklus durch Baumebenen. Zu Beginn wählen wir zufällig eine Datenpermutation aus, wenn wir geordnetes Boosten verwenden oder kategoriale Merkmale haben. Dann zählen wir die Zähler auf dieser Permutation. Dann versuchen wir gierig, gute Spalten in diesem Baum zu pflücken. Mit Teilungen meinen wir einfach einige binäre Bedingungen: Das eine oder andere numerische Merkmal ist größer als das eine oder andere Wert, oder das eine oder andere Zähler durch ein kategoriales Merkmal ist größer als das eine oder andere Wert.
Wie ist der Zyklus auf gieriger Baumebene angeordnet? Ganz am Anfang ist der Bootstrap fertig - wir wiegen oder probieren die Objekte erneut. Danach werden nur die ausgewählten Objekte zum Erstellen des Baums verwendet. Bootstrap kann auch vor Auswahl jedes Splits nachgezählt werden, wenn die Stichprobenoption auf jeder Ebene aktiviert ist.
Dann aggregieren wir die Ableitungen zu Histogrammen, wie wir es für jeden geteilten Kandidaten tun. Mithilfe von Histogrammen versuchen wir, die Änderung der Zielfunktion zu bewerten, die auftritt, wenn wir diesen geteilten Kandidaten auswählen.
Wir wählen den Kandidaten mit der besten Geschwindigkeit aus und fügen ihn dem Baum hinzu. Dann berechnen wir Statistiken unter Verwendung dieses ausgewählten Baums für die verbleibenden Permutationen, aktualisieren den Wert in den Blättern bei diesen Permutationen, berechnen die Werte in den Blättern für das Modell und fahren mit der nächsten Iteration der Schleife fort.

Es ist sehr schwierig, einen Ort auszuwählen, an dem das Training stattfindet. Auf dieser Folie - sie kann als Einstiegspunkt verwendet werden - werden die Hauptdateien aufgelistet, die wir für das Training verwenden. Dies ist greedy_tensor_search, in dem wir genau die Prozedur für die gierige Auswahl von Splits leben. Dies ist train.cpp, wo wir die Hauptfabrik für CPU-Schulungen haben. Dies ist aprox_calcer, wo die Funktionen zum Aktualisieren der Werte in den Blättern liegen. Und auch score_calcer - eine Funktion zur Bewertung eines Kandidaten.
Ebenso wichtige Teile sind catboost.pyx und core.py. Dies ist der Python-Wrapper-Code. Höchstwahrscheinlich werden viele von Ihnen etwas in den Python-Wrapper einbetten. Unser Python-Wrapper ist in Cython geschrieben, Cython ist in C ++ übersetzt, daher sollte dieser Code schnell sein.
Unser R-Wrapper liegt im R-Package-Ordner. Vielleicht muss jemand einige Optionen hinzufügen oder korrigieren. Für Optionen haben wir eine separate Bibliothek - catboost / libs / options.
Wir sind von Arcadia zu GitHub gekommen, daher haben wir viele interessante Artefakte, denen Sie begegnen werden.


Beginnen wir mit der Struktur des Repositorys. Wir haben einen util-Ordner, in dem die grundlegenden Grundelemente sind: Vektoren, Karten, Dateisysteme, Arbeiten mit Zeichenfolgen, Streams.
Wir haben eine Bibliothek, in der sich die von Yandex verwendeten gemeinsam genutzten Bibliotheken befinden - viele, nicht nur CatBoost.
Der CatBoost- und Contrib-Ordner ist der Code der Bibliotheken von Drittanbietern, auf die wir verlinken.
Lassen Sie uns nun über die C ++ - Grundelemente sprechen, auf die Sie stoßen werden. Das erste sind intelligente Zeiger. In Yandex haben wir THolder seit std :: unique_ptr verwendet, und MakeHolder wird anstelle von std :: make_unique verwendet.

Wir haben unseren eigenen SharedPtr. Darüber hinaus gibt es zwei Formen, SimpleSharedPtr und AtomicSharedPtr, die sich in der Art des Zählers unterscheiden. In einem Fall ist es atomar, was bedeutet, dass mehrere Streams ein Objekt besitzen könnten. So ist es unter dem Gesichtspunkt der Übertragung zwischen Strömen sicher.
Mit einer separaten Klasse, IntrusivePtr, können Sie Objekte besitzen, die von der TRefCounted-Klasse geerbt wurden, dh Klassen, in die ein Referenzzähler integriert ist. Dies dient dazu, solche Objekte gleichzeitig zuzuweisen, ohne zusätzlich einen Steuerblock mit einem Zähler zuzuweisen.
Wir haben auch ein eigenes System für Ein- und Ausgabe. IInputStream und IOutputStream sind Schnittstellen für Eingabe und Ausgabe. Sie verfügen über nützliche Methoden wie ReadTo, ReadLine, ReadAll und im Allgemeinen über alles, was von InputStreams erwartet werden kann. Und wir haben Implementierungen dieser Streams für die Arbeit mit der Konsole: Cin, Cout, Cerr und separat Endl, ähnlich wie std :: endl, dh es löscht den Stream.

Wir haben auch eigene Schnittstellenimplementierungen für Dateien: TInputFile, TOutputFile. Dies ist ein gepufferter Lesevorgang. Sie implementieren gepuffertes Lesen und gepuffertes Schreiben in eine Datei, sodass Sie sie verwenden können.
Util / system / fs.h verfügt über die Methoden NFs :: Exists und NFs :: Copy, wenn Sie plötzlich etwas kopieren oder überprüfen müssen, ob eine Datei wirklich vorhanden ist.

Wir haben unsere eigenen Container. Sie haben vor einiger Zeit auf std :: vector umgestellt, das heißt, sie erben einfach von std :: vector, std :: set und std :: map, aber wir haben auch unsere eigene THashMap und THashSet, die teilweise Schnittstellen haben, die mit unordered_map und kompatibel sind unordered_set. Bei einigen Aufgaben erwiesen sie sich jedoch als schneller, sodass wir sie weiterhin verwenden.

Array-Referenzen sind analog zu std :: span aus C ++. Er erschien zwar nicht im zwanzigsten Jahr, sondern viel früher bei uns. Wir verwenden es aktiv, um Verweise auf Arrays zu übertragen, als ob sie großen Puffern zugewiesen wären, um nicht jedes Mal temporäre Puffer zuzuweisen. Angenommen, wir können zum Zählen von Ableitungen oder einigen Näherungen Speicher für einen vorab zugewiesenen großen Puffer zuweisen und nur TArrayRef an die Zählfunktion übergeben. Es ist sehr praktisch und wir benutzen es oft.

Arcadia verwendet eigene Klassen für die Arbeit mit Zeichenfolgen. Dies ist zum einen TStingBuf - ein Analogon von str :: string_view aus C ++ 17.
TString ist überhaupt nicht std :: sting, es ist eine CopyOnWrite-Zeichenfolge, daher müssen Sie sehr sorgfältig damit arbeiten. Außerdem ist TUtf16String der gleiche TString, nur sein Basistyp ist nicht char, sondern 16-Bit-wchar.
Und wir haben Werkzeuge, um von String zu String zu konvertieren. Dies ist ToString, ein Analogon von std :: to_string und FromString in Kombination mit TryFromString, mit dem Sie den String in den gewünschten Typ verwandeln können.

Wir haben unsere eigene Ausnahmestruktur. Die grundlegende Ausnahme in den Arcade-Bibliotheken ist yexception, die von std :: exception erbt. Wir haben ein ythrow-Makro, das Informationen über den Ort hinzufügt, an dem die Ausnahme bei yexception ausgelöst wurde. Es ist nur ein praktischer Wrapper.
Es gibt ein Analogon von std :: current_exception - CurrentExceptionMessage. Diese Funktion löst die aktuelle Ausnahme als Zeichenfolge aus.
Es gibt Makros für Asserts und Verifizierungen - dies sind Y_ASSERT und Y_VERIFY.

Und wir haben unsere eigene integrierte Serialisierung, sie ist binär und soll keine Daten zwischen verschiedenen Revisionen übertragen. Diese Serialisierung wird vielmehr benötigt, um Daten zwischen zwei Binärdateien derselben Revision zu übertragen, beispielsweise beim verteilten Lernen.
So kam es, dass wir in CatBoost zwei Versionen der Serialisierung haben. Die erste Option funktioniert über die Schnittstellenmethoden Speichern und Laden, die für den Stream serialisiert werden. Eine weitere Option wird in unserem verteilten Training verwendet. Sie verwendet eine ziemlich alte interne BinSaver-Bibliothek, die zum Serialisieren polymorpher Objekte geeignet ist, die in einer speziellen Fabrik registriert werden müssen. Dies ist für verteilte Schulungen erforderlich, über die wir hier wahrscheinlich keine Zeit haben werden.

Wir haben auch unser eigenes analoges boost_optional oder std :: optional - TMaybe. Analog zu std :: variante - TVariant. Sie müssen sie verwenden.

Es gibt eine bestimmte Konvention, dass wir im CatBoost-Code eine TCatBoostException anstelle einer yexception auslösen. Dies ist dieselbe Ausnahme, es wird immer nur eine Stapelverfolgung hinzugefügt, wenn sie ausgelöst wird.
Außerdem verwenden wir das Makro CB_ENSURE, um einige Dinge bequem zu überprüfen und Ausnahmen auszulösen, wenn sie nicht ausgeführt werden. Beispielsweise verwenden wir dies häufig zum Parsen von Optionen oder zum Parsen von vom Benutzer übergebenen Parametern.

Bevor Sie beginnen, empfehlen wir Ihnen, sich mit dem Codestil vertraut zu machen, der aus zwei Teilen besteht. Der erste ist ein allgemeiner Arcade-Codestil, der sich direkt im Stammverzeichnis des Repositorys in der Datei CPP_STYLE_GUIDE.md befindet. Ebenfalls im Stammverzeichnis des Repositorys befindet sich eine separate Anleitung für unser Team: catboost_command_style_guide_extension.md.
Wir versuchen, Python-Code mit PEP8 zu formatieren. Es funktioniert nicht immer, weil für den Cython-Code der Linter bei uns nicht funktioniert und manchmal etwas mit PEP8 passiert.

Was zeichnet unsere Baugruppe aus? Die Arcadia-Assembly war ursprünglich darauf ausgerichtet, die luftdichtesten Anwendungen zu erfassen, dh, dass aufgrund statischer Verknüpfungen nur ein Minimum an externen Abhängigkeiten besteht. Auf diese Weise können Sie dieselbe Binärdatei unter verschiedenen Linux-Versionen verwenden, ohne sie neu zu kompilieren, was sehr praktisch ist. Montageziele werden in ya.make-Dateien beschrieben. Ein Beispiel für ya.make finden Sie auf der nächsten Folie.

Wenn Sie plötzlich eine Bibliothek, ein Programm oder etwas anderes hinzufügen möchten, können Sie erstens einfach in die benachbarten ya.make-Dateien schauen und zweitens dieses Beispiel verwenden. Hier haben wir die wichtigsten Elemente von ya.make aufgelistet. Ganz am Anfang der Datei sagen wir, dass wir eine Bibliothek deklarieren möchten, und listen dann die Kompilierungseinheiten auf, die wir in diese Bibliothek einfügen möchten. Dies können sowohl CPP-Dateien als auch Pyx-Dateien sein, für die Cython automatisch gestartet wird, und dann der Compiler. Bibliotheksabhängigkeiten werden über das PEERDIR-Makro aufgelistet. Es schreibt einfach die Pfade in den Ordner mit der Bibliothek oder einem anderen Artefakt im Verhältnis zum Stammverzeichnis des Repositorys.
Es gibt eine nützliche Sache, GENERATE_ENUM_SERIALIZATION, die benötigt wird, um ToString-, FromString-Methoden für Aufzählungsklassen und Aufzählungen zu generieren, die in einer Header-Datei beschrieben sind, die Sie an dieses Makro übergeben.

Nun zum Wichtigsten - wie man einen Test kompiliert und ausführt. Im Stammverzeichnis des Repositorys befindet sich das Skript ya, das die erforderlichen Toolkits und Tools herunterlädt, und der Befehl ya make - der Unterbefehl make -, mit dem Sie mit dem Schalter -r eine -r-Version und mit dem Schlüssel -d eine Debug-Version erstellen können. Artefakte darin werden weitergegeben und durch ein Leerzeichen getrennt.
Um Python zu erstellen, habe ich hier sofort auf Flags hingewiesen, die nützlich sein könnten. Wir sprechen über das Erstellen mit dem System Python, in diesem Fall mit Python 3. Wenn auf Ihrem Laptop oder Entwicklungscomputer plötzlich ein CUDA Toolkit installiert ist, empfehlen wir für eine schnellere Montage, das Flag –d have_cuda no anzugeben. CUDA baut seit geraumer Zeit auf, insbesondere auf 4-Core-Systemen.

Ya ide sollte schon funktionieren. Dies ist ein Tool, das eine Clion- oder QT-Lösung für Sie generiert. Und für diejenigen, die mit Windows kamen, haben wir eine Microsoft Visual Studio-Lösung, die sich im Ordner msvs befindet.
Zuhörer:
- Haben Sie alle Tests über den Python-Wrapper?
Stas:
- Nein, wir haben separat Tests, die im Pytest-Ordner liegen. Dies sind Tests unserer CLI-Schnittstelle, dh unserer Anwendung. Es stimmt, sie arbeiten mit pytest, das heißt, dies sind Python-Funktionen, bei denen wir einen Subprozess-Check-Aufruf durchführen und sicherstellen, dass das Programm nicht abstürzt und mit einigen Parametern korrekt funktioniert.
Zuhörer:
- Was ist mit Unit-Tests in C ++?
Stas:
- Wir haben auch Unit-Tests in C ++. Sie liegen normalerweise im Ordner lib in den Unterordnern ut. Und sie sind so geschrieben - Unit Test oder Unit Test für. Es gibt Beispiele. Es gibt spezielle Makros zum Deklarieren einer Unit-Test-Klasse und separate Register für die Unit-Test-Funktion.
Zuhörer:
- Um zu überprüfen, ob nichts kaputt ist, ist es besser, sowohl diese als auch diese zu starten?
Stas:
- Ja. Das einzige ist, dass unsere Open Source-Tests nur unter Linux grün sind. Wenn Sie beispielsweise unter dem Mac kompilieren und fünf Tests fehlschlagen, müssen Sie sich keine Sorgen machen. Aufgrund der unterschiedlichen Implementierung des Ausstellers auf verschiedenen Plattformen oder einiger anderer geringfügiger Unterschiede können die Ergebnisse sehr unterschiedlich sein.

Als Beispiel nehmen wir eine Aufgabe. Ich möchte ein Beispiel zeigen. Wir haben eine Datei mit Aufgaben - open_problems.md. Lösen wir das Problem №4 aus open_problems.md. Es wird wie folgt formuliert: Wenn der Benutzer die Lernrate auf Null setzt, müssen wir von TCatBoostException abfallen. Sie müssen die Optionsüberprüfung hinzufügen.
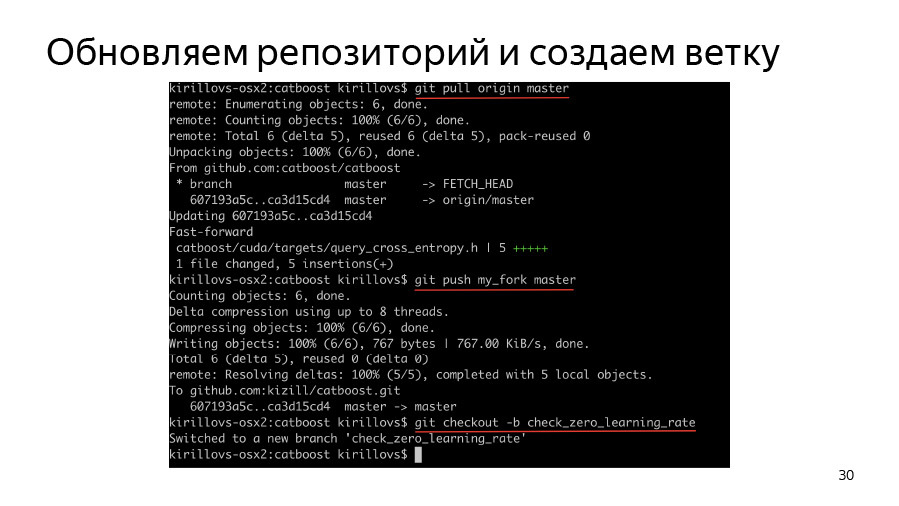
Zuerst müssen wir einen Zweig erstellen, unsere Gabel klonen, den Ursprung klonen, den Pop-Ursprung, den Ursprung in unserer Gabel ausführen und dann einen Zweig erstellen und mit der Arbeit beginnen.
Wie funktioniert das Parsen von Optionen? Wie gesagt, wir haben einen wichtigen Ordner catboost / libs / options, in dem das Parsen aller Optionen gespeichert ist.

Wir haben alle Optionen im TOption-Wrapper gespeichert, sodass wir nachvollziehen können, ob die Option vom Benutzer überschrieben wurde. Wenn dies nicht der Fall ist, behält es einen Standardwert für sich. Im Allgemeinen analysiert CatBoost alle Optionen in Form eines großen JSON-Wörterbuchs, das sich beim Parsen in verschachtelte Wörterbücher und verschachtelte Strukturen verwandelt.

Wir haben irgendwie herausgefunden - zum Beispiel durch Suchen mit einem Grep oder Lesen des Codes -, dass wir die Lernrate in TBoostingOptions haben. Versuchen wir, Code zu schreiben, der CB_ENSURE einfach hinzufügt, dass unsere Lernrate mehr als std :: numeric_limits :: epsilon ist und der Benutzer etwas mehr oder weniger Vernünftiges eingegeben hat.

Hier haben wir nur das CB_ENSURE-Makro verwendet, Code geschrieben und wollen jetzt Tests hinzufügen.

In diesem Fall fügen wir einen Test auf der Befehlszeilenschnittstelle hinzu. Im Ordner pytest haben wir das Skript test.py, in dem es bereits einige Beispiele für Tests gibt. Sie können einfach eines auswählen, das Ihrer Aufgabe entspricht, es kopieren und die Parameter so ändern, dass es abhängig von den übergebenen Parametern zu fallen beginnt oder nicht. In diesem Fall erstellen wir einfach einen einfachen Pool aus zwei Zeilen. (Wir rufen den Datensatz in Pools auf. Dies ist unsere Funktion.) Und dann überprüfen wir, ob unsere Binärdatei wirklich abfällt, wenn wir die Lernrate 0.0 überschreiten.

Wir fügen dem Python-Paket auch einen Test hinzu, der sich unter atBoost / python-package / ut / medium befindet. Wir haben auch große, große Tests, die sich auf Tests zum Erstellen von Python-Radpaketen beziehen.

Weiter haben wir Schlüssel für ya make - -t und -A. -t führt Tests aus, -A erzwingt die Ausführung aller Tests, unabhängig davon, ob sie große oder mittlere Tags haben.
Aus Schönheitsgründen habe ich hier auch einen Filter namens test verwendet. Es wird mit der Option -F und dem später angegebenen Testnamen festgelegt, bei denen es sich möglicherweise um Wildchar-Sterne handelt. In diesem Fall habe ich test.py::test_zero_learning_rate* verwendet, da Sie bei Betrachtung unserer Python-Paket-Tests sehen werden: Fast alle Funktionen nehmen ein Task-Fixture auf. Dies ist so, dass unsere Python-Paket-Tests laut Code sowohl für das CPU- als auch für das GPU-Training gleich aussehen und für GPU- und CPU-Trainertests verwendet werden können.

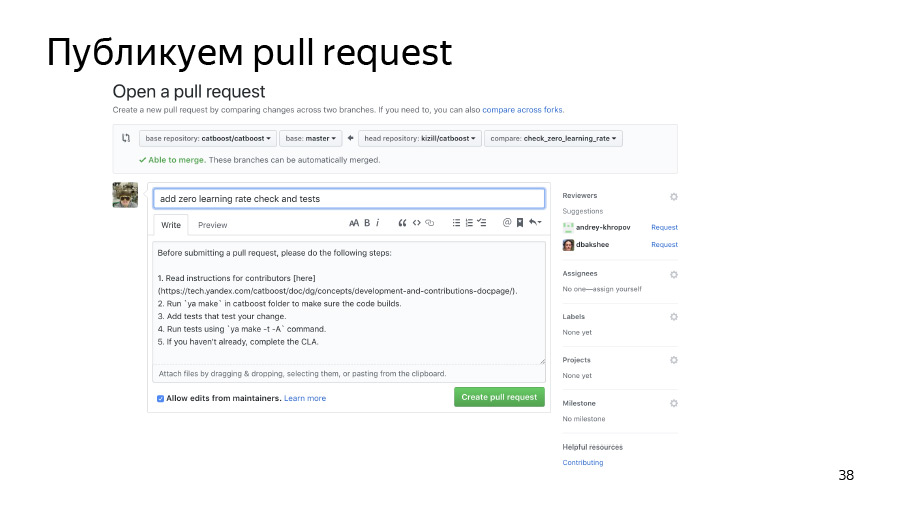
Übernehmen Sie dann unsere Änderungen und verschieben Sie sie in unser gespaltenes Repository. Wir veröffentlichen die Poolanfrage. Er ist bereits beigetreten, alles ist gut.