Während der Schulungssitzung (Mai-Juni und Dezember-Januar) bitten uns Benutzer, jede Minute nach Ausleihen von bis zu 500 Dokumenten zu suchen. Dokumente werden in Dateien in verschiedenen Formaten geliefert, deren Komplexität unterschiedlich ist. Um ein Dokument auf Ausleihe zu überprüfen, müssen wir zuerst seinen Text aus der Datei extrahieren und uns gleichzeitig mit der Formatierung befassen. Die Aufgabe besteht darin, eine qualitativ hochwertige Extraktion von halben tausend Texten mit Formatierung pro Minute zu implementieren, während sie selten (oder besser gar nicht) fallen, wenig Ressourcen verbrauchen und nicht die Hälfte des galaktischen Budgets für die Entwicklung und den Betrieb der endgültigen Idee bezahlen.
Ja, ja, natürlich wissen wir, dass Sie aus drei Dingen - schnell, kostengünstig und effizient - zwei auswählen müssen. Das Schlimmste ist jedoch, dass wir in unserem Fall nichts löschen können. Die Frage ist, wie gut wir es gemacht haben ...

Bildquelle: Wikipedia
Uns wird oft gesagt, dass das Schicksal der Menschen von der Qualität unserer Arbeit abhängt. Deshalb muss man Perfektionisten in sich erziehen. Natürlich verbessern wir ständig die Qualität des Systems (in allen Aspekten), da skrupellose Autoren neue Wege finden, um dies zu umgehen. Und ich hoffe, dass der Tag nahe ist, an dem die Komplexität der Täuschung einerseits und das Gefühl der Zufriedenheit durch eine gut gemachte Arbeit andererseits die überwiegende Mehrheit der Studenten dazu veranlassen werden, ihren geliebten Wunsch, herumzuspielen, aufzugeben. Gleichzeitig verstehen wir, dass der Preis für Fehler das mögliche Leiden unschuldiger Menschen sein kann, wenn wir ihn plötzlich vortäuschen.
Warum bin ich Wenn wir Perfektionisten wären, würden wir nachdenklich eine Reihe von Artikeln über die Arbeit des Anti-Plagiat-Systems schreiben. Wir würden sorgfältig einen Veröffentlichungsplan formulieren, um alles auf die logischste und erwartete Weise für den Leser darzulegen:
- Zunächst würden wir über die Struktur unseres Systems sprechen (die fünfte Veröffentlichung zu Habré) und die drei Hauptphasen der Verarbeitung eines Dokuments beschreiben, wenn es auf Ausleihe geprüft wird:
- Extrahieren Sie den Text des Dokuments (Sie sind hier!);
- Suche nach Krediten (Stücke sind bereits in mehreren unserer Artikel enthalten );
- Erstellen eines Berichts über das Dokument (in Plänen).
- Ferner würden wir beginnen, den Leser dem Gerät interessanter Hilfsmechanismen zu widmen, wie der Suche nach übertragbaren Anleihen ( erster Artikel ), der Definition der Paraphrase ( vierter ) und der thematischen Klassifizierung ( zweiter ).
- Und schließlich kamen wir zur Suchmaschine - dem Index der Gürtelrose ( siebter Artikel ).
Ein aufmerksamer Leser muss bemerkt haben, dass wir immer noch nicht unter übermäßigem Perfektionismus leiden. Es ist also an der Zeit, mit der ersten Phase fortzufahren - dem Extrahieren von Text und dem Formatieren von Dokumenten. Dies ist, was wir heute tun werden, auf dem Weg über die Sterblichkeit des Seins und über das Licht am Ende des Tunnels, über die Nichtexistenz von etwas Idealem und über das Streben nach Exzellenz, darüber, einen Plan zu haben und ihm zu folgen und über die Kompromisse, zu denen das Leben uns immer neigt.
Am Anfang war das Wort
Zuerst haben wir aus den Dokumenten nur das extrahiert, was für die Überprüfung auf Ausleihe am notwendigsten ist - den Text der Dokumente selbst. Die Hauptformate wurden unterstützt - docx, doc, txt, pdf, rtf, html. Dann wurden die weniger verbreiteten ppt, pptx, odt, epub, fb2, djvu hinzugefügt, aber es war notwendig, sich zu weigern, in Zukunft mit den meisten von ihnen zu arbeiten. Jeder von ihnen wurde auf seine Weise verarbeitet - irgendwo in einer separaten Bibliothek, irgendwo in einem eigenen Parser. Im Durchschnitt dauerte die Textextraktion etwa Hunderte von Millisekunden. Es scheint, dass die Haupt- und fast die einzige Schwierigkeit beim Extrahieren von Text das „Parsen“ des Formats selbst ist, was insbesondere für binäre PDF- und Doc-Formate gilt (und die proprietäre Natur des letzteren macht die Arbeit damit noch problematischer). Bereits zu diesem Zeitpunkt, als sich unsere Wünsche nur auf das Extrahieren des Textes beschränkten, wurde jedoch klar, dass jede Art des Lesens der benötigten Formate eine Reihe unangenehmer Merkmale mit sich bringt. Die bedeutendsten von ihnen:
- Ausnahmen sind auch bei der Verarbeitung einiger gültiger Dokumente, ganz zu schweigen von der Verarbeitung falsch geformter „defekter“ Dokumente. Was noch mehr Probleme verursacht, ist, dass nativer Code fallen kann und der Umgang mit solchen Situationen in .net-Code schwierig ist.
- Unzureichend hoher Speicherverbrauch, der sowohl benachbarte als auch den aktuellen Prozess, der das „Problem“ -Dokument verarbeitet, beeinträchtigen kann (nicht genügend Speicher in verwaltetem oder nicht verwaltetem Code);
- Zu lange Verarbeitung eines Dokuments, was durch das Fehlen von Stornierungsmechanismen für die meisten Bibliotheken und manchmal durch die Komplexität (sprich: fast unmöglich) des Abbrechens eines nicht verwalteten Codeaufrufs von einem verwalteten verschlimmert wird;
- "Textextraktion aus Dokumenten." Das Generieren des Textes eines PDF-Dokuments (und dieses Format ist der Schlüssel für uns), dessen Analyse wider Erwarten bereits durchgeführt wurde, ist keine triviale Aufgabe. Tatsache ist, dass das PDF-Format ursprünglich hauptsächlich für die elektronische Präsentation von Druckmaterialien entwickelt wurde. Text in PDFs ist eine Reihe von Textblöcken, die sich auf den Seiten eines Dokuments befinden. Darüber hinaus kann der Block ein Textabsatz oder ein einzelnes Zeichen sein. Die Aufgabe, den Text in seiner ursprünglichen Form aus diesem Satz von Blöcken wiederherzustellen, liegt bei der Bibliothek (Code / Programm), die das Dokument liest. Ja, das Format, beginnend mit einer bestimmten Version, bietet die Möglichkeit, die Reihenfolge der Blöcke anzugeben. Leider sind Dokumente mit einer markierten Folge von Textblöcken selten. Daher enthalten PDF-
Textlesebibliotheken eine Reihe von Heuristiken (dies ist hier Standard: maschinelles Lernen, BigData, Blockchain , ...), mit denen Sie den Text in der richtigen Form mit dem einen oder anderen Grad wiederherstellen können. Wie erwartet ist das Ergebnis von Bibliothek zu Bibliothek unterschiedlich .

Unten Bildquelle: Artikel
Top Bildquelle: Hmm ...
Benötigen Sie weitere Daten!
Wenn für die Analyse eines Dokuments zum Ausleihen der Texthintergrund des Dokuments ausreichte, ist die Implementierung einer Reihe neuer Funktionen unmöglich oder sehr schwierig, ohne zusätzliche Daten aus dem Dokument zu extrahieren. Heute extrahieren wir neben dem Texthintergrund auch die Dokumentformatierung und rendern Seitenbilder. Letzteres verwenden wir zur optischen Texterkennung ( OCR ) sowie zur Identifizierung einiger Arten von Bypässen.
Das Formatieren eines Dokuments umfasst die geometrische Anordnung aller Wörter und Zeichen auf den Seiten sowie die Schriftgröße aller Zeichen. Diese Informationen ermöglichen es uns:
- Zeigen Sie den Dokumentüberprüfungsbericht auf schöne Weise an und zeichnen Sie erkannte Anleihen direkt auf das Originaldokument.

- Die Dokumentblöcke (Titelseite, Bibliographie ) genauer zu bestimmen und ihre Metadaten (Autoren, Berufsbezeichnung, Jahr und Arbeitsort usw.) abzurufen;
- Systemumgehungsversuche erkennen.
Um die Verarbeitung von Dokumenten und einer Reihe extrahierter Daten zu vereinheitlichen, konvertieren wir Dokumente aller von uns unterstützten Formate in PDF. Somit wird das Verfahren zum Extrahieren von Dokumentdaten in zwei Schritten ausgeführt:
- Konvertieren Sie ein Dokument in PDF;
- Daten aus PDF extrahieren.
In PDF konvertieren. Bibliotheksauswahl
Da es nicht so einfach ist, ein Dokument in PDF zu konvertieren, haben wir beschlossen, das Rad nicht neu zu erfinden und vorgefertigte Lösungen zu suchen, um die für uns am besten geeignete auszuwählen. Es war zurück im Jahr 2017.
Kriterien für die Auswahl der Kandidaten:
- Bibliothek auf .net, idealerweise .net Core und plattformübergreifend
Spoiler!Infolgedessen war das Ideal in diesem Moment unerreichbar
- Unterstützung für erforderliche Formate - doc, docx, rtf, odf, ppt, pptx
- Stabilität
- Leistung
- Qualität des technischen Supports
- Ausgabepreis
Wir haben die verfügbaren Lösungen analysiert und unter ihnen die 6 für unsere Aufgaben am besten geeigneten ausgewählt:
MS Word Interop, Neevia Document Converter Pro und DynamicPdf erfordern die Installation von MS Office in der Produktion, was uns endgültig und unwiderruflich an Windows binden könnte. Daher haben wir diese Optionen nicht mehr berücksichtigt.
Somit haben wir noch drei Hauptkandidaten, und nur einer von ihnen unterstützt alle benötigten Formate vollständig. Nun, es ist Zeit zu sehen, wozu sie fähig sind.
Zum Testen der Bibliotheken haben wir eine Stichprobe von 120.000 realen Benutzerdokumenten erstellt, wobei das Verhältnis der Formate ungefähr dem entspricht, was wir jeden Tag in der Produktion sehen.
Also die erste Runde. Mal sehen, welcher Anteil der Dokumente erfolgreich in die betrachteten PDF-Bibliotheken konvertiert werden kann. In unserem Fall ist es erfolgreich, keine Ausnahme auszulösen, das 3-Minuten-Timeout einzuhalten und einen nicht leeren Text zurückzugeben.
Syncfusion fiel sofort auf, wodurch nicht nur die kleinste Anzahl von Dokumenten erfolgreich verarbeitet werden konnte, sondern auch der gesamte Prozess auf einige Dokumente übertragen wurde (wodurch Ausnahmen wie OutOfMemoryException oder Ausnahmen aus dem nativen Code generiert wurden, die nicht abgefangen wurden, ohne mit einem Tamburin zu tanzen).
GroupDocs konnte etwa 5,5- mal mehr Dokumente als DevExpress nicht verarbeiten (alles ist auf der obigen Tafel zu sehen). Dies trotz der Tatsache, dass eine einzelne Entwicklerlizenz von GroupDocs ungefähr neunmal teurer ist als eine einzelne Entwicklerlizenz von DevExpress. Das ist übrigens so.
Der zweite ernsthafte Test ist die Konvertierungszeit, die gleichen 120.000 Dokumente:
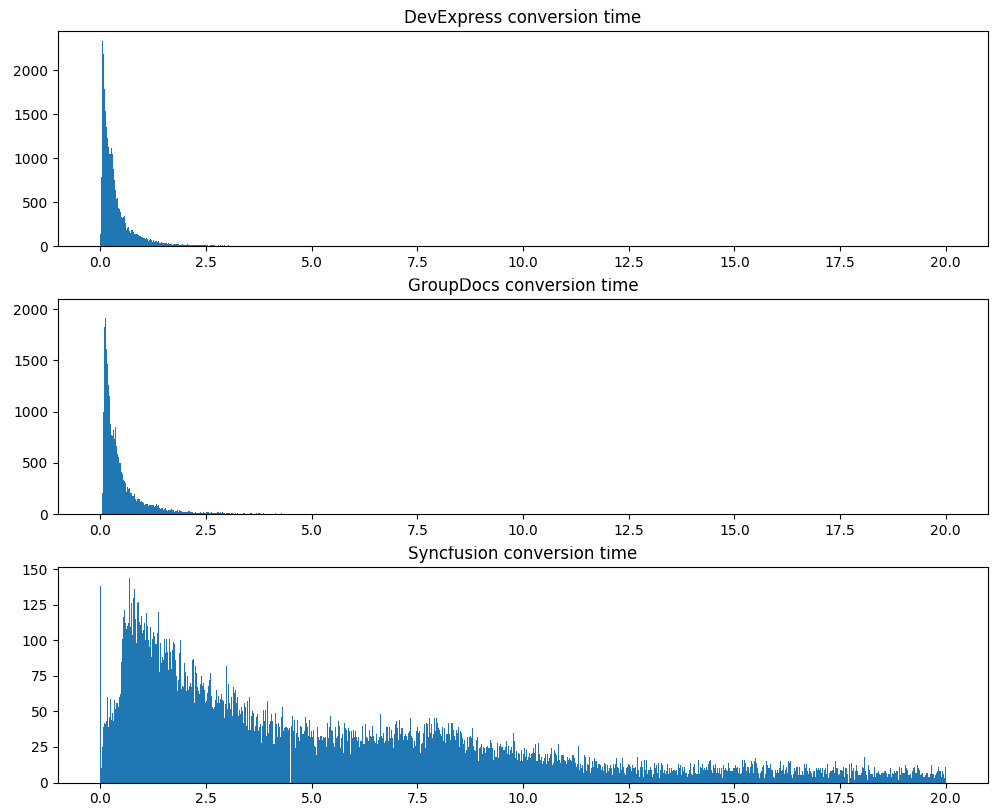
Beachten Sie, dass DevExpress Dokumente nicht nur im Durchschnitt schneller verarbeitet, sondern auch eine viel stabilere Verarbeitungszeit aufweist.
Stabilität und Verarbeitungsgeschwindigkeit bedeuten jedoch nichts, wenn die Ausgabe als PDF schlecht ist. Vielleicht überspringt DevExpress den halben Text? Wir prüfen. Also, die gleichen 120.000 Dokumente, dieses Mal berechnen wir das Gesamtvolumen des extrahierten Textes und den durchschnittlichen Anteil der Wörterbuchwörter (je mehr extrahierte Wörter Wörterbuch sind, desto weniger Müll / falsch extrahierter Text):
Zum Teil war die Annahme richtig. Wie sich herausstellte, können GroupDocs im Gegensatz zu DevExpress mit Fußnoten arbeiten. DevExpress überspringt sie einfach, wenn Sie ein Dokument in PDF konvertieren. Übrigens, ja, der Text aus dem empfangenen PDF wird in jedem Fall mit DevExpress'a extrahiert.
Daher haben wir die Geschwindigkeit und Stabilität der betreffenden Bibliotheken untersucht und nun die Qualität der Konvertierung von PDF-Dokumenten sorgfältig bewertet. Dazu analysieren wir nicht nur das Volumen des zu extrahierenden Textes und den Anteil der darin enthaltenen Wörterbuchwörter, sondern vergleichen auch die aus den empfangenen PDFs extrahierten Texte mit den mit MS Word erhaltenen PDF-Texten. Wir akzeptieren das Ergebnis der Konvertierung eines Dokuments mit MS Word als Referenz-PDF . Für diesen Test wurden ca. 4.500 Paare „ Dokument, Referenz-PDF “ vorbereitet.
Für jedes Paar " Referenz-PDF, Konvertierungsergebnis " haben wir die Ähnlichkeit in der Länge des extrahierten Textes und in den Häufigkeiten der extrahierten Wörter berechnet. Natürlich wurden diese Metriken nur in den Fällen erhalten, in denen die Konvertierung erfolgreich war. Daher berücksichtigen wir die Ergebnisse der Syncfusion hier nicht. DevExpress und GroupDocs zeigten ungefähr die gleiche Leistung. Auf der DevExpress-Seite gibt es einen signifikant höheren Prozentsatz erfolgreicher Conversions, auf der GD-Seite die korrekte Arbeit mit Fußnoten.
Angesichts der Ergebnisse war die Wahl offensichtlich. Bis heute verwenden wir die Lösung von DevExpress und planen in Kürze ein Upgrade auf die 19. Version.
Es gibt ein PDF, Text mit Formatierung extrahieren
So können wir Dokumente in PDF konvertieren. Jetzt haben wir eine andere Aufgabe: DevExpress zum Extrahieren des Textes verwenden und über jedes Wort alle Informationen wissen, die wir benötigen. Nämlich:
- Auf welcher Seite steht das Wort;
- Die Position des Wortes auf der Seite (Einrahmen eines Rechtecks);
- Die Schriftgröße des Wortes (Wortzeichen).
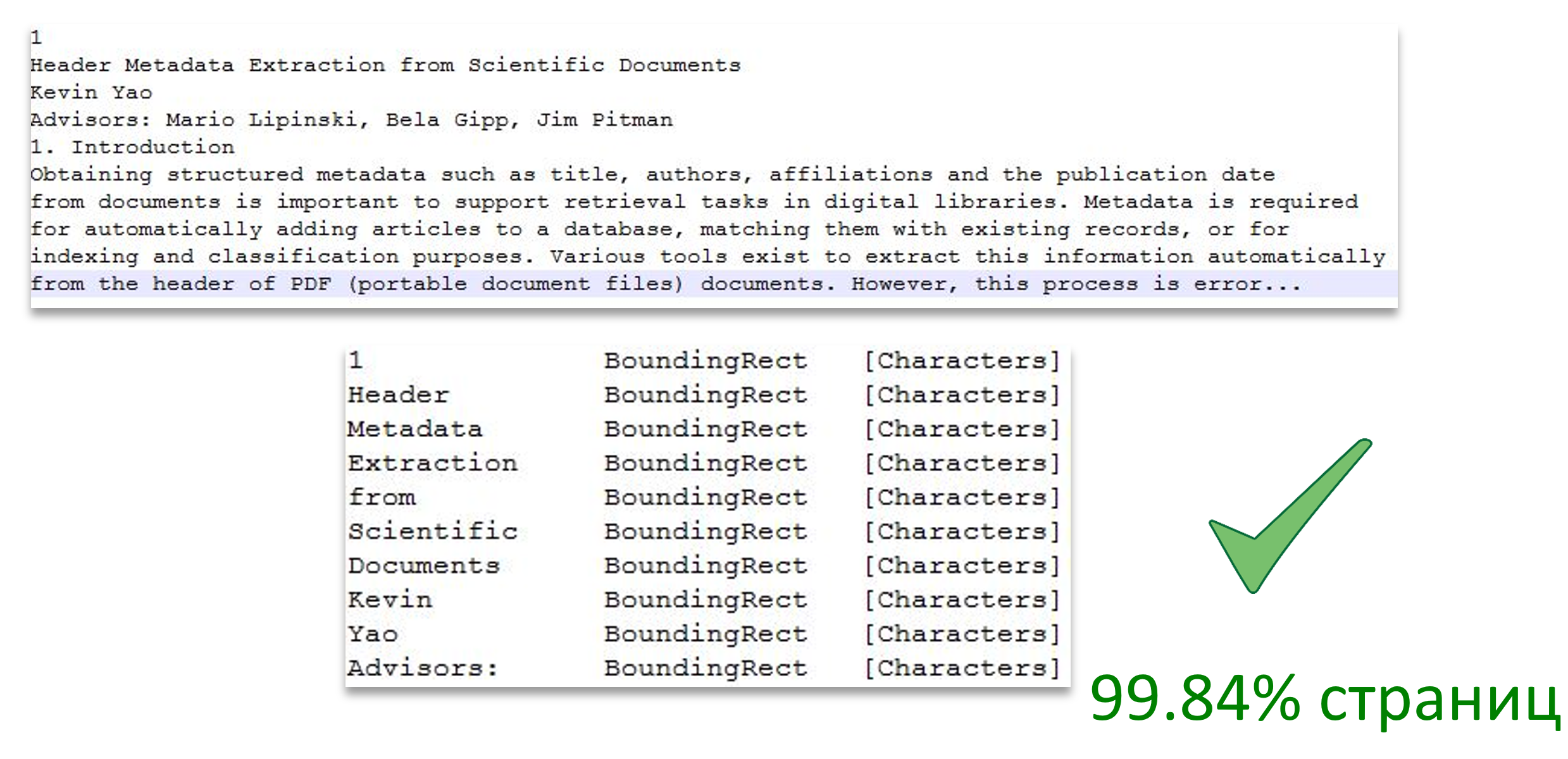
Das Bild zeigt die Aufteilung des Textes in Seiten sowie die Entsprechung eines Textworts zum Seitenbereich.

Bildquelle: Extraktion von Header-Metadaten aus wissenschaftlichen Dokumenten
Es scheint, dass alles einfach sein sollte. Wir schauen uns an, was API DevExpress uns bietet:
- Wir haben eine Methode, die den Text des gesamten Dokuments zurückgibt. Einfache Schnur ;
- Wir haben die Möglichkeit, gemäß dem Dokument zu iterieren. Für jedes Wort können wir bekommen:
- Text des Wortes;
- Die Seite, auf der sich das Wort befindet;
- Das Rahmenrechteck des Wortes;
- Informationen zu den einzelnen Zeichen des Wortes (die Bedeutung des Zeichens, das das Rechteck umrahmt, Schriftgröße, ...).
Okay, alles scheint da zu sein. Nur hier erfahren Sie, wie Sie die erforderlichen Daten für jedes Wort im Text des Dokuments abrufen, das DevExpress zurückgibt. Wir möchten den Text des Dokuments nicht wirklich selbst aus Wörtern sammeln, da wir beispielsweise keine Informationen haben, bei denen nur ein Leerzeichen zwischen den Wörtern und der Zeilenvorschub vorhanden ist. Wir müssen Heuristiken entwickeln, die auf der Position der Wörter basieren ... Der Text ist - hier ist er vor uns bereits zusammengestellt.

Bildquelle: Eureka!
Die naheliegende Lösung besteht darin, die Wörter mit dem Text des Dokuments abzugleichen. Wir schauen - tatsächlich sind die Wörter im Text des Dokuments in derselben Reihenfolge angeordnet, in der sie vom Iterator gemäß den Wörtern des Dokuments zurückgegeben werden.
Wir implementieren schnell einen einfachen Algorithmus zum Abgleichen von Wörtern mit dem Text des Dokuments, fügen Überprüfungen hinzu, ob alles korrekt übereinstimmt, starten ...
In der Tat funktioniert auf den meisten Seiten alles korrekt, aber leider nicht auf allen Seiten.

Top Bildquelle: Sind Sie sicher?
Seitens der Dokumente sehen wir, dass die Wörter im Text nicht in der Reihenfolge sind, in der sie beim Durchlaufen der Wörter des Dokuments ablaufen. Darüber hinaus ist ersichtlich, dass die öffnende eckige Klammer im Text in der Wortliste als schließende Klammer dargestellt wird und sich in einem anderen „Wort“ befindet. Die korrekte Anzeige dieses Textfragments kann durch Öffnen des Dokuments in MS Word angezeigt werden. Interessanter ist, dass Sie, wenn Sie das Dokument nicht in PDF konvertieren, sondern den Text direkt aus dem Dokument extrahieren, die dritte Version des Textfragments erhalten, die weder der richtigen Reihenfolge noch den beiden anderen von der Bibliothek erhaltenen Bestellungen entspricht. In diesem Fragment, wie in den meisten anderen, bei denen ein ähnliches Problem auftritt, liegt der Punkt in unsichtbaren "RTL" -Zeichen, die die Reihenfolge der benachbarten Zeichen / Wörter ändern.
An dieser Stelle sei daran erinnert, dass wir die Qualität des technischen Supports bei der Auswahl einer Bibliothek als wichtig bezeichnet haben. Wie die Praxis gezeigt hat, ist die Interaktion mit DevExpress in dieser Hinsicht sehr effektiv. Das Problem mit dem eingereichten Dokument wurde schnell behoben, nachdem wir das entsprechende Ticket erstellt hatten. Eine Reihe anderer Probleme im Zusammenhang mit Ausnahmen / hohem Speicherverbrauch / langer Dokumentverarbeitung wurden ebenfalls behoben.
Obwohl DevExpress keine direkte Möglichkeit bietet, den Text mit den erforderlichen Informationen für jedes Wort abzurufen, vergleichen wir den Vergleich manchmal unvergleichlich. Wenn wir keine exakte Übereinstimmung zwischen Wörtern und Text herstellen können, verwenden wir eine Reihe von Heuristiken, die kleine Permutationen von Wörtern ermöglichen. Wenn nichts hilft, bleibt das Dokument ohne Formatierung. Selten, aber das passiert.
Tschüss :)