Hier geht es natürlich um
DevOpsConf . Wenn Sie nicht auf Details eingehen, werden wir am 30. September und 1. Oktober eine Konferenz über die Vereinheitlichung von Entwicklungs-, Test- und Betriebsprozessen abhalten. Wenn Sie darauf eingehen, bitte ich um Katze.
Im Rahmen des DevOps-Ansatzes sind alle Teile der technologischen Entwicklung des Projekts miteinander verflochten, treten parallel auf und beeinflussen sich gegenseitig. Von besonderer Bedeutung ist dabei die Schaffung automatisierter Entwicklungsprozesse, die in Echtzeit geändert, simuliert und getestet werden können. Dies hilft, sofort auf Marktveränderungen zu reagieren.
Auf der Konferenz möchten wir zeigen, wie sich dieser Ansatz auf die Produktentwicklung auswirkt. Wie ist die Zuverlässigkeit und Anpassungsfähigkeit des Systems für den Kunden. Wie DevOps die Struktur und den Ansatz des Unternehmens zur Organisation des Workflows ändert.

Backstage
Für uns ist es wichtig, nicht nur zu wissen, was verschiedene Unternehmen im Rahmen des DevOps-Ansatzes tun, sondern auch zu verstehen, warum dies alles ist. Daher haben wir nicht nur Experten in das Programmkomitee eingeladen, sondern auch Experten, die den DevOps-Diskurs aus verschiedenen Perspektiven betrachten:
- leitende Ingenieure;
- Entwickler
- Timlides;
- CTO.
Dies führt einerseits zu Schwierigkeiten und Konflikten bei der Erörterung von Berichtsanträgen. Wenn ein Ingenieur an der Analyse eines schweren Unfalls interessiert ist, ist es für den Entwickler wichtiger zu verstehen, wie Software erstellt wird, die in den Clouds und Infrastrukturen funktioniert. Indem wir uns einig sind, erstellen wir ein Programm, das für alle wertvoll und interessant ist: vom Ingenieur bis zum CTO.

Die Aufgabe unserer Konferenz besteht nicht nur darin, Berichte mit mehr High-Tech-Qualität auszuwählen, sondern auch das Gesamtbild zu präsentieren: Wie funktioniert der DevOps-Ansatz in der Praxis, auf welche Art von Rechen können Sie bei der Umstellung auf neue Prozesse stoßen? Gleichzeitig erstellen wir den Inhaltsteil und gehen von der Geschäftsaufgabe zu bestimmten Technologien über.
Die Abschnitte der Konferenz bleiben dieselben wie beim
letzten Mal .
- Infrastrukturplattform.
- Infrastruktur als Code.
- Kontinuierliche Lieferung.
- Rückkopplung.
- Architektur bei DevOps, DevOps für CTO.
- SRE-Praktiken.
- Schulung und Wissensmanagement.
- Sicherheit, DevSecOps.
- DevOps-Transformation.
Call for Papers: Welche Berichte suchen wir?
Wir haben das potenzielle Publikum der Konferenz unter bestimmten Bedingungen in fünf Gruppen unterteilt: Ingenieure, Entwickler, Sicherheitsspezialisten, Teamleiter und CTOs. Jede Gruppe hat ihre eigene Motivation, zur Konferenz zu kommen. Wenn Sie sich DevOps von diesen Positionen aus ansehen, können Sie verstehen, wie Sie Ihr Thema fokussieren und wo Sie Schwerpunkte setzen können.
Für Ingenieure , die eine Infrastrukturplattform erstellen, ist es wichtig, die vorhandenen Trends zu verstehen und zu verstehen, welche Technologien derzeit am weitesten fortgeschritten sind. Sie werden daran interessiert sein, die tatsächlichen Erfahrungen mit dem Einsatz dieser Technologien kennenzulernen und sich auszutauschen. Ein Ingenieur hört sich gerne einen Bericht mit einer Analyse eines Hardcore-Unfalls an. Wir werden wiederum versuchen, einen solchen Bericht aufzunehmen und zu polieren.
Für Entwickler ist es wichtig, ein Konzept wie eine
Cloud-native Anwendung zu verstehen. Das heißt, wie man Software so entwickelt, dass sie in den Clouds und verschiedenen Infrastrukturen funktioniert. Der Entwickler muss ständig Feedback von der Software erhalten. Hier möchten wir Fälle darüber hören, wie Unternehmen diesen Prozess erstellen, wie die Softwareleistung überwacht wird und wie der gesamte Bereitstellungsprozess funktioniert.
Für
Cybersecurity-Experten ist es wichtig
zu verstehen, wie der Sicherheitsprozess so eingerichtet wird, dass Entwicklungsprozesse und Änderungen im Unternehmen nicht gestoppt werden. Die Themen zu den Anforderungen, die DevOps an solche Spezialisten stellt, werden interessant sein.
Die Timlids möchten wissen, wie der kontinuierliche Lieferprozess bei anderen Unternehmen
funktioniert . Wie ist das Unternehmen vorgegangen, wie wurden die Entwicklungsprozesse und die Qualitätssicherung innerhalb von DevOps aufgebaut? Interessant sind auch Cloud-native Teamkollegen. Und auch - Fragen zur Interaktion innerhalb des Teams und zwischen Entwicklerteams und Ingenieuren.
Für
CTO ist es am wichtigsten, herauszufinden, wie all diese Prozesse kombiniert und an die Geschäftsanforderungen angepasst werden können. Er stellt sicher, dass die Anwendung sowohl für das Unternehmen als auch für den Kunden zuverlässig ist. Und hier müssen Sie verstehen, welche Technologien unter welchen Geschäftsaufgaben funktionieren, wie der gesamte Prozess aufgebaut wird usw. CTO ist auch für die Budgetierung verantwortlich. Zum Beispiel muss er verstehen, wie viel Geld er für die Umschulung von Spezialisten ausgeben muss, damit diese in DevOps arbeiten können.

Wenn Sie bei diesen Gelegenheiten etwas zu sagen haben, schweigen Sie nicht und
reichen Sie einen Bericht ein . Die Frist für die Einreichung von Beiträgen endet am 20. August. Je früher Sie erscheinen, desto mehr Zeit bleibt für die Fertigstellung des Berichts und die Vorbereitung der Präsentation. Also nicht festziehen.
Wenn Sie nicht öffentlich sprechen müssen,
kaufen Sie einfach
ein Ticket und kommen Sie am 30. September und 1. Oktober, um mit Kollegen zu chatten. Wir versprechen, dass es interessant und inspirierend sein wird.
Wie wir DevOps sehen
Um genau zu verstehen, was wir unter DevOps verstehen, empfehle ich, meinen Vortrag „
Was ist DevOps? “ Zu lesen (oder erneut zu lesen). Als ich durch die Wellen des Marktes ging, beobachtete ich, wie sich die Idee von DevOps in Unternehmen unterschiedlicher Größe verwandelt: von einem kleinen Startup zu multinationalen Unternehmen. Der Bericht basiert auf einer Reihe von Fragen. Wenn Sie diese beantworten, können Sie nachvollziehen, ob Ihr Unternehmen zu DevOps wechselt oder ob irgendwo Probleme auftreten.
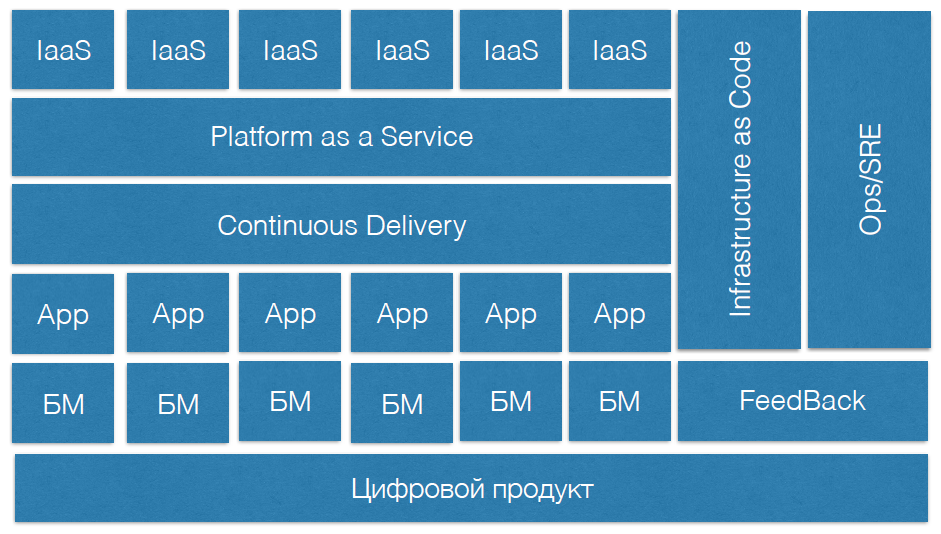
DevOps ist ein komplexes System, das es haben sollte:
- Digitales Produkt.
- Die Geschäftsmodule, die dieses digitale Produkt entwickelt.
- Produktteams, die Code schreiben.
- Kontinuierliche Lieferpraktiken.
- Plattformen als Service.
- Infrastruktur als Dienstleistung.
- Infrastruktur als Code.
- Separate Zuverlässigkeitspraktiken in DevOps.
- Feedback-Praxis, die all dies beschreibt.
Am Ende des Berichts befindet sich ein Schema, das eine Vorstellung vom DevOps-System im Unternehmen vermittelt. So können Sie sehen, welche Prozesse in Ihrem Unternehmen bereits debuggt sind und welche nur erstellt werden müssen.
Den Videobericht können Sie hier ansehen.
Und jetzt gibt es einen Bonus: Mehrere Videos von RIT ++ 2019, die sich auf die häufigsten Probleme der DevOps-Transformation beziehen.
Unternehmensinfrastruktur als Produkt
Artyom Naumenko leitet das DevOps-Team bei Skyeng und kümmert sich um die Entwicklung der Infrastruktur seines Unternehmens. Er erklärte, wie sich die Infrastruktur auf Geschäftsprozesse in SkyEng auswirkt: wie man den ROI dafür berechnet, welche Metriken für die Berechnung ausgewählt werden sollten und wie man daran arbeitet, sie zu verbessern.
Auf dem Weg zu Microservices
Nixys unterstützt engagierte Webprojekte und verteilte Systeme. Sein technischer Direktor Boris Ershov erklärte, wie Softwareprodukte, deren Entwicklung vor etwa fünf Jahren (oder noch länger) begann, auf moderne Schienen übertragen werden können.

In der Regel sind solche Projekte eine besondere Welt, in der es so dunkle und alte Ecken der Infrastruktur gibt, dass die derzeitigen Ingenieure nichts über sie wissen. Und die einmal ausgewählten Ansätze für Architektur und Entwicklung sind veraltet und können Unternehmen nicht das gleiche Tempo bei der Entwicklung und Veröffentlichung neuer Versionen bieten. Infolgedessen wird jede Veröffentlichung des Produkts zu einem unglaublichen Abenteuer, bei dem ständig etwas herunterfällt und an einem unerwarteten Ort.
Die Manager solcher Projekte stehen unweigerlich vor der Notwendigkeit, alle technologischen Prozesse zu transformieren. In seinem Bericht sagte Boris:
- Wie man die für das Projekt geeignete Architektur auswählt und die Infrastruktur aufräumt;
- Welche Werkzeuge sind zu verwenden und welche Fallstricke gibt es auf dem Weg zur Transformation?
- was als nächstes zu tun ist.
Release-Automatisierung oder schnelle und schmerzfreie Bereitstellung
Alexander Korotkov ist ein führender Entwickler des CI / CD-Systems bei CIAN. Er sprach über Automatisierungstools, die die Qualität verbesserten und die Lieferzeit von Code in der Produktion um das Fünffache reduzierten. Solche Ergebnisse konnten jedoch nicht mit nur einer Automatisierung erzielt werden, weshalb Alexander auf Änderungen in den Entwicklungsprozessen aufmerksam machte.
Wie helfen Ihnen Unfälle beim Lernen?
Alexey Kirpichnikov implementiert seit 5 Jahren DevOps und Infrastruktur in SKB Kontur. Drei Jahre lang ereigneten sich in seiner Firma etwa 1.000 Fakaps in unterschiedlichem Ausmaß. Unter ihnen wurden zum Beispiel 36% durch die Einführung einer minderwertigen Version in der Produktion und 14% durch Eisenwartungsarbeiten im Rechenzentrum verursacht.
Wenn Sie so genaue Informationen über Unfälle erhalten, können Sie Berichte (post mortem) archivieren, die die Ingenieure des Unternehmens seit mehreren Jahren hintereinander durchführen. Postmortem schreibt an den diensthabenden Ingenieur, der als erster auf das Signal über den Unfall reagierte und begann, alles zu reparieren. Warum Folteringenieure, die nachts gegen Fakaps kämpfen und Berichte schreiben? Mit diesen Daten können Sie das gesamte Bild sehen und die Infrastrukturentwicklung in die richtige Richtung lenken.
In seiner Rede teilte Alexey mit, wie man ein wirklich nützliches Post-Mortem schreibt und wie man die Praxis solcher Berichte in einem großen Unternehmen umsetzt. Wenn Sie Geschichten darüber lieben, wie jemand es vermasselt hat, schauen Sie sich ein Video der Aufführung an.
Wir verstehen, dass Ihre Vision von DevOps möglicherweise nicht mit unseren Ansichten übereinstimmt. Es wird interessant sein zu wissen, wie Sie die DevOps-Transformation sehen. Teilen Sie Ihre Erfahrungen und Visionen zu diesem Thema in den Kommentaren mit.Welche Berichte haben wir bereits in das Programm aufgenommen?
Diese Woche nahm der Programmausschuss vier Berichte an: über Sicherheit, Infrastruktur und SRE-Praktiken.
Das vielleicht schmerzhafteste Thema der DevOps-Transformation: Wie kann sichergestellt werden, dass die Mitarbeiter der Abteilung für Informationssicherheit die bereits aufgebauten Verbindungen zwischen Entwicklung, Betrieb und Verwaltung nicht ruinieren?
Einige Unternehmen verzichten auf eine Abteilung für Informationssicherheit . Wie kann dann die Informationssicherheit gewährleistet werden? Dies
wird Mona Arkhipova von sudo.su erzählen. Aus ihrem Bericht erfahren wir:
- was und vor wem ist es zu schützen;
- Was sind die routinemäßigen Sicherheitsprozesse?
- Wie sich IT- und IS-Prozesse überschneiden
- Was ist CIS CSC und wie wird es implementiert?
- wie und nach welchen Indikatoren regelmäßige IS-Kontrollen durchzuführen sind.
Der nächste Bericht befasst sich mit der Entwicklung der Infrastruktur als Code. Reduzieren Sie den manuellen Aufwand und verwandeln Sie nicht das gesamte Projekt in Chaos. Ist dies möglich?
Maxim Kostrikin von Ixtens wird diese Frage
beantworten . Seine Unternehmen verwenden
Terraform , um mit der AWS-Infrastruktur zu arbeiten. Das Tool ist praktisch, aber die Frage ist, wie man es verwendet, um das Auftreten eines riesigen Codeklumpens zu vermeiden. Die Erhaltung eines solchen Erbes wird jedes Jahr mehr und mehr kosten.
Maxim wird zeigen, wie Code-Platzierungsmuster zur Vereinfachung der Automatisierung und Entwicklung funktionieren.
Wir werden einen weiteren
Bericht über die Infrastruktur von
Vladimir Ryabov von Playkey hören . Hier werden wir über die Infrastrukturplattform sprechen und lernen:
- wie man versteht, ob die Speicherkapazität effizient genutzt wird;
- wie mehrere hundert Benutzer 10 TB Inhalt empfangen können, wenn nur 20 TB Speicher verwendet werden;
- wie man Daten fünfmal komprimiert und sie Benutzern in Echtzeit zur Verfügung stellt;
- wie man Daten zwischen mehreren Rechenzentren im laufenden Betrieb synchronisiert;
- wie man einen Einfluss von Benutzern auf einander bei der sequentiellen Verwendung einer virtuellen Maschine ausschließt.
Das Geheimnis dieser Magie liegt in der
ZFS- Technologie
für FreeBSD und der neuesten Version von
ZFS unter Linux . Vladimir wird Fälle von Playkey teilen.
Matvey Kukuy von Amixr.IO ist bereit
, anhand von Beispielen aus dem Leben zu
erzählen, was
SRE ist und wie es hilft, zuverlässige Systeme aufzubauen. Amixr.IO leitet Kundenvorfälle über sein Backend weiter. Dutzende von Einsatzteams auf der ganzen Welt haben bereits 150.000 Fälle gelöst. Auf der Konferenz wird Matvey Statistiken und Erkenntnisse austauschen, die sein Unternehmen gesammelt hat, Kundenprobleme lösen und Fakapy analysieren.
Ich fordere Sie erneut auf, nicht gierig zu sein und Ihre Erfahrungen mit DevOps-Samurai zu teilen. Beantragen Sie den Bericht, und wir haben 2,5 Monate Zeit, um eine hervorragende Präsentation vorzubereiten. Wenn Sie ein Zuhörer sein möchten, abonnieren Sie den Newsletter mit Programmaktualisierungen und denken Sie ernsthaft über eine frühzeitige Buchung von Tickets nach, da deren Preise näher an den Konferenzdaten steigen werden.